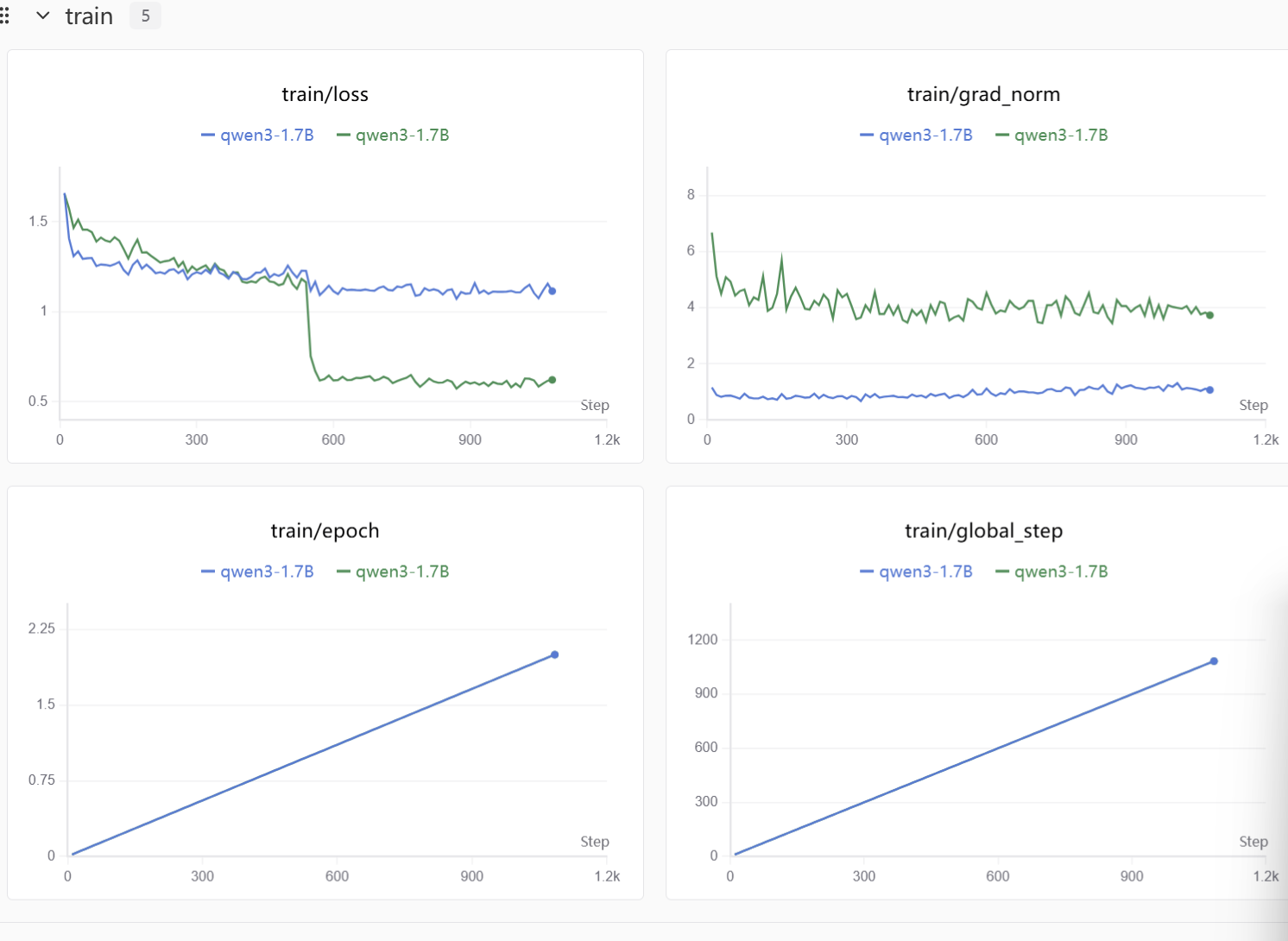
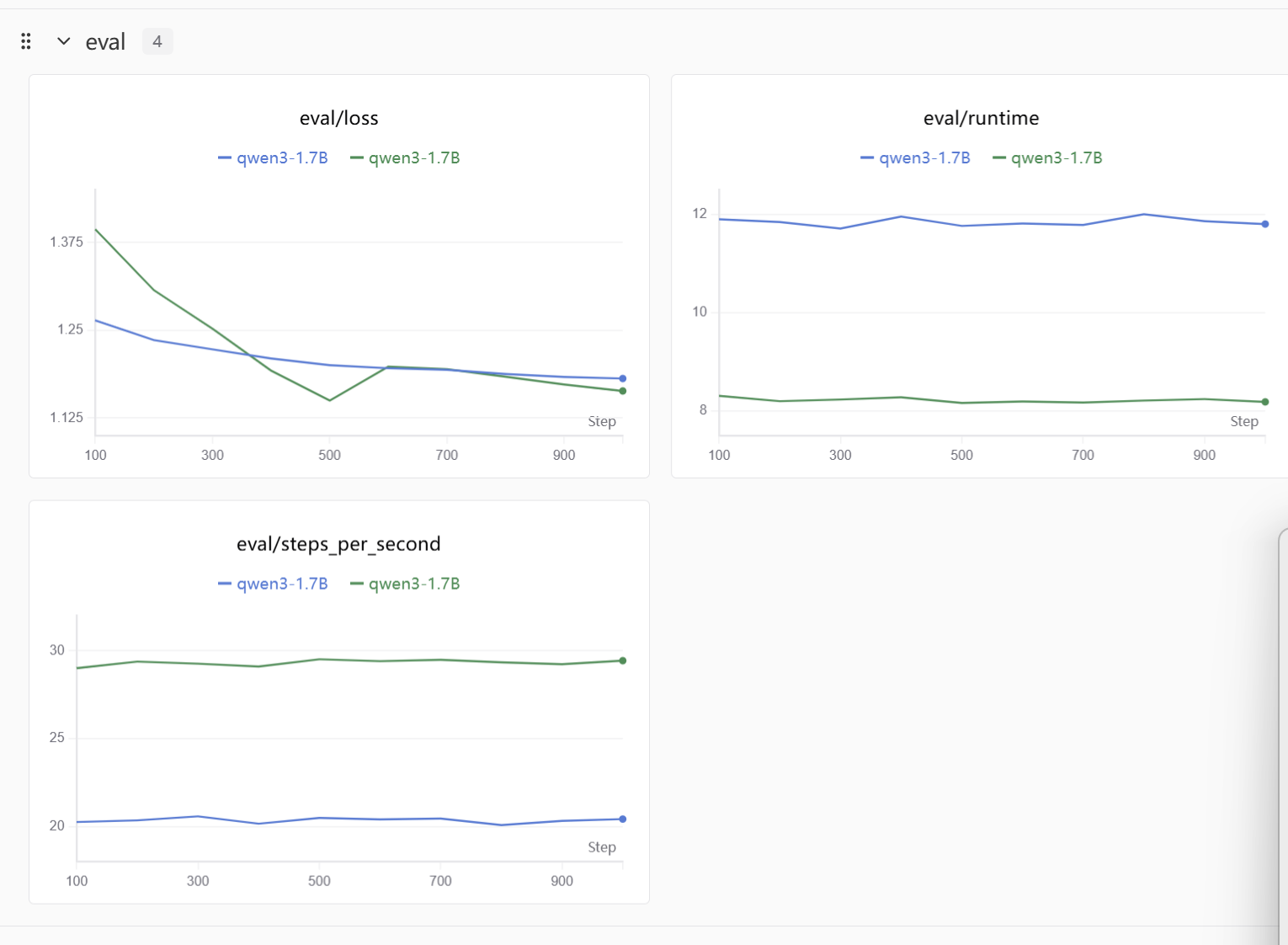
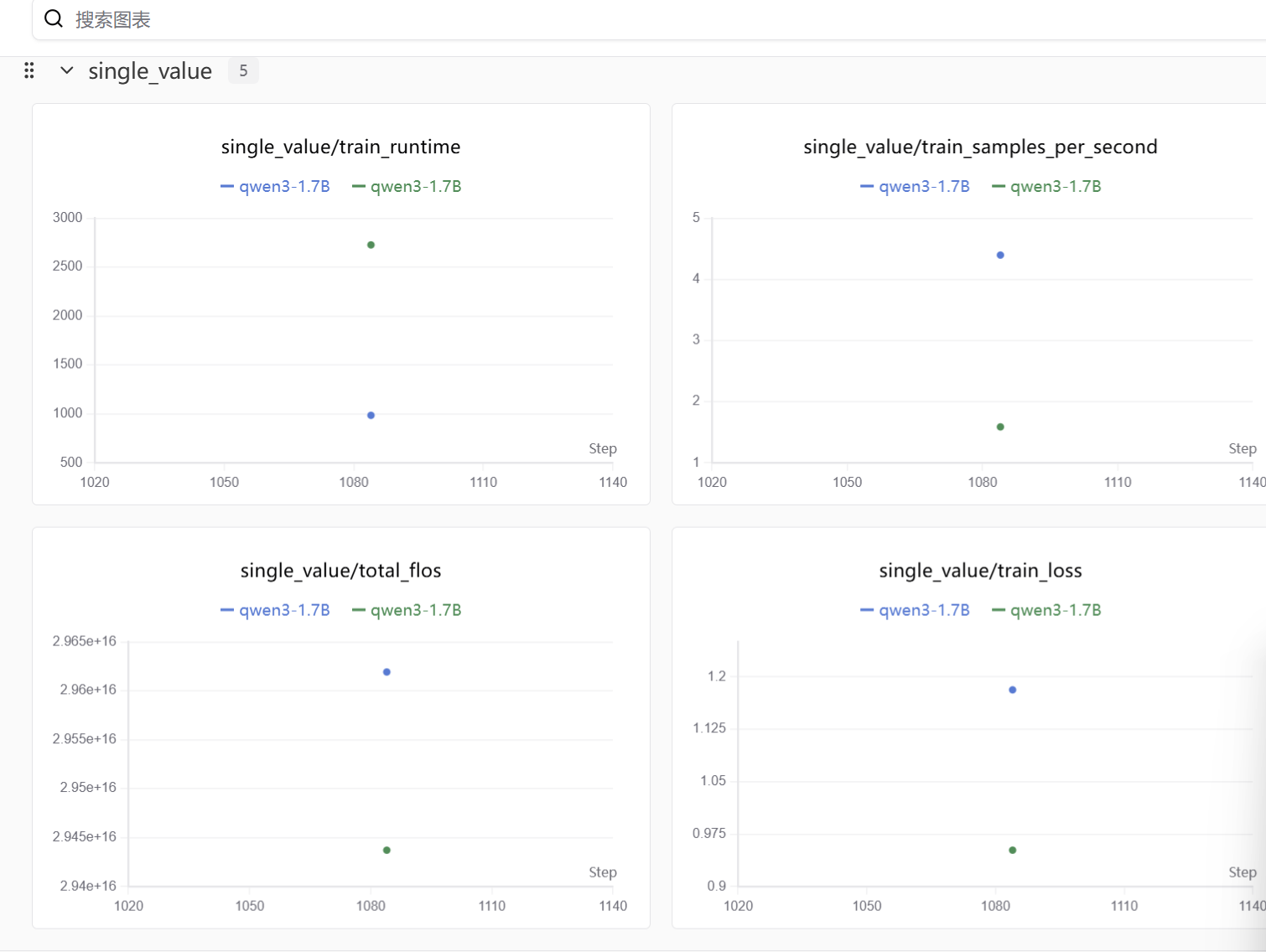
整体微调流程
1. 整体目标
-
使模型能够根据用户输入的医学问题,先给出
<think>思考过程,再输出最终答案,以提升回答的专业性和可解释性。 -
使用 LoRA(Low-Rank Adaptation)进行高效参数微调,降低显存和计算开销。
2. 关键模块与技术
数据预处理
-
原始数据格式:
{"question":..., "think":..., "answer":...} -
下载
{ "instruction": "系统提示(医学专家)", "input": "问题", "output": "<think>思考过程</think> \n 答案" } -
下载
<|im_start|>system\n{PROMPT}<|im_end|> <|im_start|>user\n{input}<|im_end|> <|im_start|>assistant\n{output}并生成对应的
input_ids、attention_mask和labels(其中系统部分和用户部分的labels设为-100,不参与损失计算)。
模型与 LoRA 配置
-
使用
snapshot_download从 ModelScope 下载 Qwen3-1.7B 模型。 -
加载模型时启用
device_map="auto"和torch.bfloat16以节省显存。 -
配置 LoRA:
-
目标模块:
q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj(覆盖了自注意力和前馈网络的关键线性层)。 -
秩
r=8,lora_alpha=32,dropout=0.1。
-
训练参数
-
批次大小:
per_device_train_batch_size=1,梯度累积4步,实际 batch size 为 4。 -
学习率
1e-4,训练 2 个 epoch。 -
启用梯度检查点(
gradient_checkpointing=True)以进一步降低显存占用。 -
使用
DataCollatorForSeq2Seq动态填充序列。 -
日志与模型保存间隔:每 10 步记录日志,每 100 步评估验证集,每 400 步保存一次模型。
实验跟踪
- 集成
swanlab:记录超参数、训练过程中的 loss、以及训练后的模型预测示例(前 3 条验证集样本)。
3. 流程总结
-
下载模型并加载 tokenizer 和模型。
-
配置 LoRA 并封装模型。
-
转换原始 JSONL 数据集为微调格式。
-
使用
Dataset.map进行 tokenization 预处理。 -
设置
TrainingArguments并创建Trainer。 -
开始训练。
-
训练结束后对验证集前 3 条进行推理,将结果记录到 swanlab。
总结
swanlab可以看到最终得结果,整体感觉星图算力的操作不复杂,很容易微调入门,致力于微调大模型的伙伴们可以试试~