专栏: 🎉《C++》

前言
前一篇文章:《【高阶数据结构】哈希表 》中我们已经分析了哈希表结构,以及如何用开放定址法和链地址法(哈希桶)设计实现哈希表,最主要的就是:怎样避免哈希冲突,显然,哈希桶完胜开放定址法。所以,我们今天进一步完善哈希桶的结构,然后来自己封装unordered_set和unordered_map。
目录
[1.1、unordered_set / unordered_map](#1.1、unordered_set / unordered_map)
[💦插入 / 遍历比较:](#💦插入 / 遍历比较:)
[3.1、unordered_set 封装](#3.1、unordered_set 封装)
[3.2.1、重载operator ](#3.2.1、重载operator[ ])
4.2、对应位置处的数据个数------bucket_size
一、常见接口详解(C++标准库)
文档:《unordered_set》,《unordered_map》
这个我们已经是 老生常谈了💤
1.1、unordered_set / unordered_map
unordered_set和unordered_map的接口几乎完全相同,所以我们以unordered_set为例讲解:
cpp
// 头文件:
#include<unordered_set>
#include<unordered_map>|-------------------------------------------------------------------|---------------------------|
| 构造相关接口(常用) ||
| unordered_set ( const unordered_set& ust ); | 拷贝构造 |
| unordered_set ( InputIterator first, InputIterator last ) | 迭代器区间构造 |
| unordered_set ( initializer_list<value_type> il) | 初始化列表构造 |
| 其他接口(常用) ||
| size_type size() | 计算哈希表中的数据个数 |
| size_type count ( const key_type& k ) | 统计值为k的数据个数 |
| pair<iterator,bool> insert ( const value_type& val ) | 插入(注意返回值类型) |
| iterator erase ( const_iterator position ) | 删除 |
| 迭代器 ||
| iterator begin() const_iterator begin() const | 返回哈希表第一个存储有效数据位置的迭代器。 |
| iterator end() const_iterator end() const | 返回哈希表最后一个位置之后位置的迭代器 |
1.2、接口测试
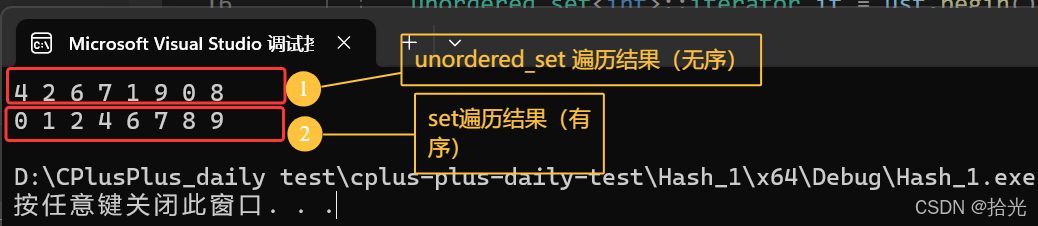
unordered---无序,由于数据是根据映射关系映射到哈希表中的,所以说哈希表中的数据是无序的。同时,unordered_set和unordered_map不支持数据冗余。数据需要重复,就要用:unordered_multiset和unordered_multimap
💦插入 / 遍历比较:
cpp
void test01()
{
// unordered_set(无序)
unordered_set<int> ust({ 4,2,6,7,9,1,8,0 }); // 初始化列表构造
// 利用迭代器遍历
unordered_set<int>::iterator it = ust.begin();
while (it != ust.end())
{
cout << *it << " ";
it++;
}
cout << endl;
// set(有序)
set<int> st({ 4,2,6,7,9,1,8,0 });
set<int>::iterator begin = st.begin();
while (begin != st.end())
{
cout << *begin << " ";
begin++;
}
cout << endl;
}
💦性能测试
cpp
void test02()
{
size_t N = 10000000;
unordered_set<int> us;
set<int> st;
vector<int> v;
v.reserve(N);
srand(time(0));
for (size_t i = 0; i < N; i++)
{
v.push_back(rand() + i);
}
// 插入数据性能比较
int begin1 = clock();
for (auto e1 : v)
{
us.insert(e1);
}
int end1 = clock();
cout << "unordered_set insert: " << end1 - begin1 << endl;
int begin2 = clock();
for (auto e2 : v)
{
st.insert(e2);
}
int end2 = clock();
cout << "set insert: " << end2 - begin2 << endl;
// 插入数据个数
cout << "unordered_set size: " << us.size() << endl;
cout << "set size: " << st.size() << endl;
// 查找性能
int begin3 = clock();
for (auto e3 : v)
{
us.find(e3);
}
int end3 = clock();
cout << "unordered_set find: " << end3 - begin3 << endl;
int begin4 = clock();
for (auto e4 : v)
{
st.find(e4);
}
int end4 = clock();
cout << "set find: " << end4 - begin4 << endl;
// 删除性能
int begin5 = clock();
for (auto e5 : v)
{
us.erase(e5);
}
int end5 = clock();
cout << "unordered_set erase: " << end5 - begin5 << endl;
int begin6 = clock();
for (auto e6 : v)
{
st.erase(e6);
}
int end6 = clock();
cout << "set erase: " << end6 - beg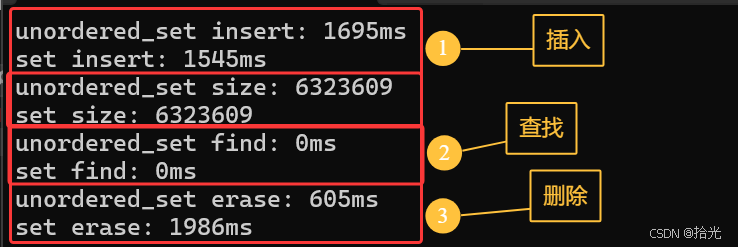
二、哈希桶实现(进阶)
对哈希桶的实现,我们复用前面的代码逻辑,同时再添加一个迭代器,就大功告成了。
听到这里如果你还有点蒙,请移步:《【高阶数据结构】哈希表 》
2.1、模板参数说明
由于我们要用哈希表封装unordered_set和unordered_map。
所以,对于数据类型就不能够写死。
即我们实现的模板既要适配unordered_set的key值类型,还要适配unordered_map的key_value(键值对)的类型。
解决方案:用一个 T 来指代哈希表的数据类型,你传什么类型我就是什么类型。

猜你又要说:你用 T 指代数据类型,那我的 key(键值)怎么搞?
 好办,不是有仿函数嘛。
好办,不是有仿函数嘛。
我给你的模板参数加一个仿函数。
仿函数:"我在unordered_set和unordered_map中给你把 key 传过来"。
总感觉还差点什么,就是感觉不对劲。
 但你是对的!
但你是对的!
哈希表最重要的就是:把数据映射到对应的位置,然后才能挂数据(哈希桶)。
你要知道,哈希表底层核心载体是数组。
你要挂数据,得找到数组的下标不是。
我们主要用取余数的方法来找到key应该映射到数组的哪个位置,即key对应的下标。
【高阶数据结构】哈希表 一文中已经做了详细地介绍。
那好,5 % 11 = 5,那key = -9,key = "string"呢,我可没说我的key是什么类型。

你取模是个啥,和数组的下标有什么关系。
好办,不是有仿函数嘛。
我给你的模板参数再加一个仿函数。
仿函数:"我把所有的key都给你转成无符号整形(unsigned int)"。
 到这里,哈希表的所有模板参数就到欧克了。
到这里,哈希表的所有模板参数就到欧克了。
代码框架如下:
cpp
// K --------键值(key)类型
// T --------哈希实际存储的数据类型
// keyOfT --------仿函数:获取key值
// Hash ----------将不同类型的key转换为对应的unsigned int类型的值
template<class K, class T, class keyOfT, class Hash>
class Hash_Bucket
{
typedef HashNode<T> Node;
public:
// 构造
Hash_Bucket()
:_tables(__stl_next_prime(0))
, _size(0)
{}
private:
vector<Node*> _tables; // Node*类型的数组
size_t _size = 0; // 记录数据个数
};2.2、获取键值---仿函数
由于我们在查找,比较过程中都需要用到key,而哈希表的模板中 T 为一个泛型。
所以,我们在unordered_set和unordered_map各自的类中实现一个获取key的仿函数。
方便模板类中使用key。

我们知道:仿函数其实就是一个类,重载了operator()(给不知道的小伙伴补充一下)。
对于unordered_set,key就是其存储的数据,直接返回即可。
对于unordered_map,存储的是一个pair类型的对象,key就是pair对象的第一个值,返回first即可。
 上代码:
上代码:
cpp
// ---------------unordered_set 的仿函数-----------------------
struct keyOfSet
{
const K& operator()(const K& key)
{
return key;
}
};
// ---------------unordered_map 的仿函数-----------------------
struct keyOfMap
{
const K& operator()(const pair<K, V>& kv) // const修饰返回值,因为键值不能修改
{
return kv.first;
}
};2.3、迭代器
好吧,今天的重头戏来了---------迭代器!

不简单,确实不简单。
模板参数跟Hash_Bucket差不多。
需要注意:迭代器有普通迭代器和const迭代器,所以,也不能写死。
这就需要再增加几个模板参数,保证模板是泛型的。
 抽象,属实抽象,增加啥呢?
抽象,属实抽象,增加啥呢?
你得想想,普通迭代器和const迭代器有什么不同呢:
那不就是数据类型嘛,毕竟迭代器类型就是根据数据类型决定的。
再提示一下:迭代器里面需要实现重载*(解引用操作符),重载->,重载 == 和 != ,以及重载++。== 和 != 返回值为bool;++返回值为迭代器;就剩下 * 和 -> 了。
也就是说:*(解引用)的返回值为T&还是const T&;->的返回值是 T* 还是 const T*。
好办,再增加几个模板参数嘛!
用Ref指代T&和const T& ,Ptr指代T* 和 const T*。用两个泛型类型
既然迭代器是一个类模板,那他有什么成员变量吗?
 这也是我们理解迭代器的关键!!!
这也是我们理解迭代器的关键!!!
实际上迭代器底层就是一个指向当前节点的指针。
有了这个节点的指针,我们才能实现:
*(解引用操作符),>, == 和 != ,++这些操作。
所以,这个模板里面肯定要有一个节点的指针。
剧透一下:重载operator++时由于要取模,就要获取哈希表的大小,即_tables.size()。

所以,我们还需要一个指向哈希表的指针,通过这个指针我们才能获取哈希表的大小。
对于第二个成员变量(指向哈希表的指针)。
需要我们结合使用场景来确定。
但第一个成员变量几乎就是众多迭代器的不可或缺的一员。

迭代器框架如下:
cpp
// Ref--------------指代T& 还是 const T&
// Ptr--------------指代T* 还是 const T*
template<class K, class T, class Ref, class Ptr, class keyOfT, class Hash>
struct HTIterator
{
typedef HashNode<T> Node;
typedef Hash_Bucket<K, T, keyOfT, Hash> Hash_Bucket;
typedef HTIterator<K, T, Ref, Ptr, keyOfT, Hash> Self;
Node* _node; // 当前位置的节点
const Hash_Bucket* _ht; // 用来找_tables,_tables.size()来确定哈希表的大小,方便取模
HTIterator(Node* node,const Hash_Bucket* ht)
:_node(node)
,_ht(ht)
{ }
// ...
};2.3.1、重载operator++
你肯定会好奇:为什么只有++呢?
这是因为,这里的迭代器是单向迭代器。

 为什么是单向的?
为什么是单向的?
因为哈希表上挂的每个桶不都是单链表嘛,可不就是单向的。
那怎么找到当前节点下一个位置的迭代器?
需要我们分情况讨论,相信大家已经见怪不怪了。
1)当迭代器在桶的中间部分时:让当前节点的指针更新到下一个节点即可。
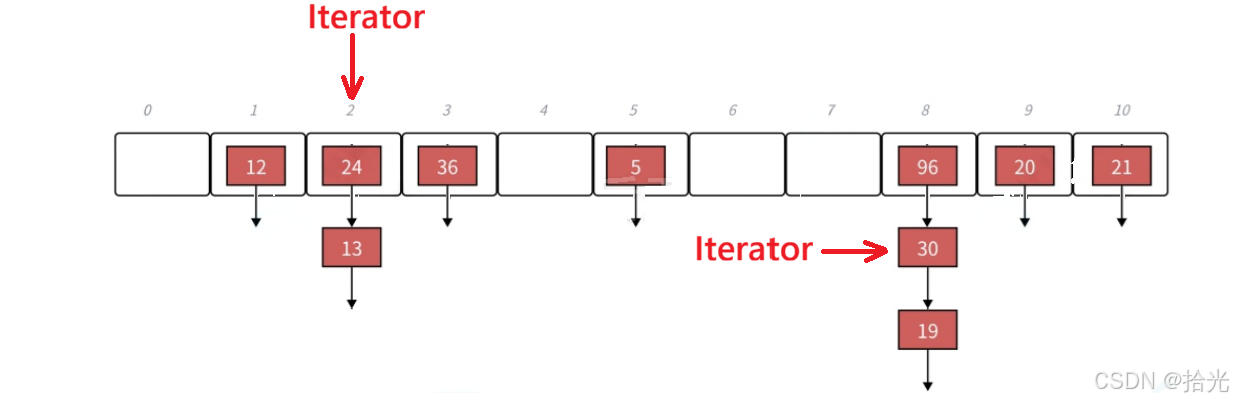
2)当前节点已经是桶的最后一个节点或当前节点就是该位置的唯一一个节点:
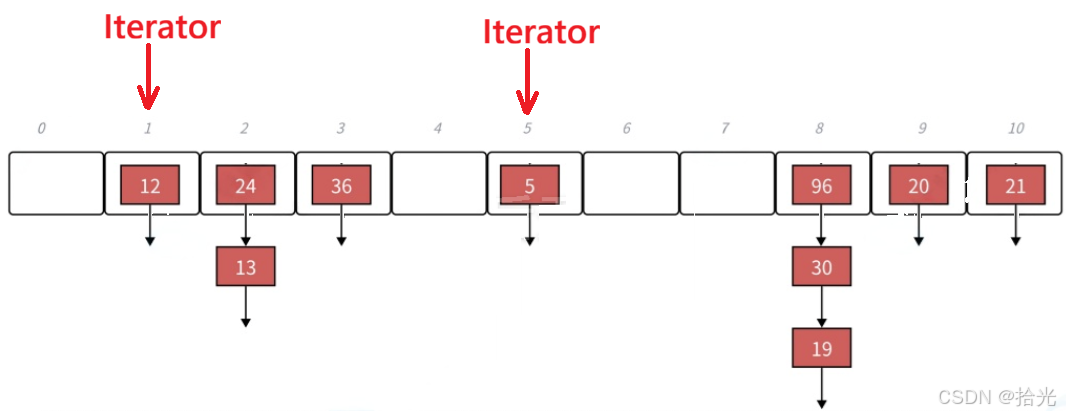
这时候,就需要我们向哈希表的后面找第一个不为空的位置,然后指向节点的指针更新。
 你说巧不巧:哈希表后面所有的位置都是空的。
你说巧不巧:哈希表后面所有的位置都是空的。
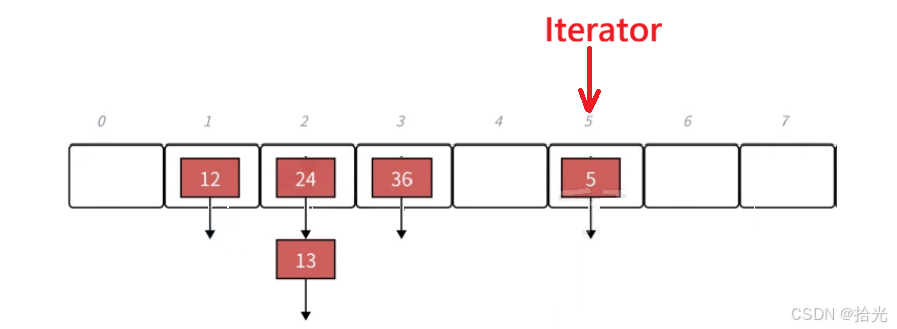
势必就会找到结尾,此时就需要我们让指向节点的指针指向 nullptr,然后返回。
cpp
Self& operator++()
{
// 当前桶还有节点
if (_node->_next)
{
_node = _node->_next;
}
// 当前桶只有一个节点,找下一个不为空的桶
else
{
keyOfT kot; // 仿函数
Hash hash; // 仿函数
size_t hashi = hash(kot(_node->_data)) % _ht->_tables.size(); // 定位到当前的桶
++hashi; // 向后寻找
while (hashi < _ht->_tables.size())
{
_node = _ht->_tables[hashi]; // _node指向下一个桶
// 下一个桶不为空
if (_node)
break;
// 这个桶仍为空,继续向后找
else
hashi++;
}
// 如果hashi 定位到哈希表的结尾,标记节点为空
if (hashi == _ht->_tables.size())
{
_node = nullptr;
}
return *this; // 返回++后的迭代器
}
}极其极其细心的小伙伴又会发现:_tables不是Hash_Bucket的私有成员变量吗?
你怎么还光明正大的用上了。

必须表扬,这位同学非常细心,能成大事。那怎么办呢?
前面不是学过友元函数嘛。
我们可以试着将迭代器的类声明为Hash_Bucket的友元类。
你还别说,真就成了。
cpp
// 友元声明
template<class K, class T, class Ref, class Ptr, class keyOfT, class Hash>
friend struct HTIterator; // --------在前面加上friend2.3.2、重载其他
cpp
// 重载*
Ref operator*()
{
return _node->_data;
}
// 重载 ->
Ptr operator->()
{
return &_node->_data;
}
// 重载 ==
bool operator==(const Self& s) const
{
return _node == s._node;
}
// 重载 !=
bool operator!=(const Self& s) const
{
return _node != s._node;
}三、封装
接下来我们直接封装,这就变得非常easy了。
只需要用一个哈希表的对象调用我们在哈希表中实现的接口就好了。
 努力就会收获😅
努力就会收获😅
3.1、unordered_set 封装
cpp
#include"Hash_Bucket.h"
template<class K,class Hash=HashFun<K>>
class UnorderedSet
{
// --------------------仿函数--------------------------------
struct keyOfSet
{
const K& operator()(const K& key)
{
return key;
}
};
//----------------------------------------------------------
public:
typedef typename Hash_Bucket<K, const K, keyOfSet, Hash>::Iterator iterator;
typedef typename Hash_Bucket<K, const K, keyOfSet, Hash>::ConstIterator const_iterator;
// ----------------------------普通迭代器-------------------------
iterator begin()
{
return _ht.Begin();
}
iterator end()
{
return _ht.End();
}
// ----------------------------const迭代器------------------------
const_iterator begin() const
{
return _ht.Begin();
}
const_iterator end() const
{
return _ht.End();
}
pair<iterator, bool> insert(const K& key) // -----------插入
{
return _ht.Insert(key);
}
iterator find(const K& key) // -------------查找
{
return _ht.Find(key);
}
bool erase(const K& key) //--------------删除
{
return _ht.Erase(key);
}
private:
Hash_Bucket<K, const K, keyOfSet, Hash> _ht; // 成员变量(哈希表类对象)
};3.2、unordered_map封装
3.2.1、重载operator
重载operator 我们再啰嗦几句:
只有 unordered_map / map重载operator ;
需要支持插入 + 查找 + 修改,的功能。
cpp
#include"Hash_Bucket.h"
template<class K,class V,class Hash=HashFun<K>>
class UnorderedMap
{
// ---------------------------仿函数--------------------------------
struct keyOfMap
{
const K& operator()(const pair<K, V>& kv) // const修饰键值,键值不能修改
{
return kv.first;
}
};
// ---------------------------------------------------------------------
public:
typedef typename Hash_Bucket<K, pair<const K, V>, keyOfMap, Hash>::Iterator iterator;
typedef typename Hash_Bucket<K, pair<const K, V>, keyOfMap, Hash>::ConstIterator const_iterator;
// --------------------------普通迭代器----------------------------
iterator begin()
{
return _ht.Begin();
}
iterator end()
{
return _ht.End();
}
// -------------------------const迭代器--------------------------------
const_iterator begin()const
{
return _ht.Begin();
}
const_iterator end()const
{
return _ht.End();
}
V& operator[](const K& key) // --------------------重载operator[]
{
pair<iterator, bool> ret = insert({ key,V() });
return ret.first->second;
}
pair<iterator,bool> insert(const pair<K, V>& kv) //--------------插入
{
return _ht.Insert(kv);
}
iterator find(const K& key) //-------------------------查找
{
return _ht.Find(key);
}
bool erase(const K& key) // ----------------------删除
{
return _ht.Erase(key);
}
private:
Hash_Bucket<K, pair<const K, V>, keyOfMap, Hash> _ht; // 成员变量
};四、拓展接口说明(C++标准库)
unordered_set和unordered_map对于这些接口功能也相同,下面以unordered_map为例讲解。

4.1、哈希表大小------bucket_count

cpp
void test01()
{
unordered_map<string,string> str;
vector<string> v({ "sort","left","insert","hdszm","a","b","c","d","e"}); // 9个数据
size_t count = str.bucket_count();
cout << "bucket_count: " << count << endl;
// 向str对象插入数据
for (auto e : v)
{
str.insert({ e,e }); // 构造pair对象插入(多参数默认类型转换)
}
// 更新count
count = str.bucket_count(); // 调用bucket_count() 函数
cout << "bucket_count: " << count << endl;
}
不难看出:bucket_count函数就是来获取当前哈希表的大小的。
初始大小为8,当我们插入9个数据后,扩容为64。
4.2、对应位置处的数据个数------bucket_size

cpp
void test02()
{
unordered_map<string, string> str;
vector<string> v({ "sort","left","insert","hdszm","a","b","c","d"});
size_t size = str.bucket_size(2);
cout << "bucket_size: " << size << endl;
// 向str对象插入数据
for (auto e : v)
{
str.insert({ e,e }); // 构造pair对象插入(多参数默认类型转换)
}
// 更新size
size = str.bucket_size(2); // 调用bucket_size() 函数
cout << "bucket_count: " << size << endl;
}
返回 n (即下标)位置处插入的数据个数。
4.3、找数据所在位置------bucket

cpp
void test03()
{
// 初始化列表构造
unordered_map<string, string> mymap = { {"us","United States"},{"uk","United Kingdom"},
{"fr","France"},{"de","Germany"}
};
for (auto& x : mymap)
{
cout << "Element [" << x.first << ":" << x.second << "]";
cout << " is in bucket #" << mymap.bucket(x.first) << std::endl;
}
cout << "us: " << ('u' + 's') % 8 << endl;
cout << "uk: " << ('u' + 'k') % 8 << endl;
cout << "fr: " << ('f' + 'r') % 8 << endl;
cout << "de: " << ('d' + 'e') % 8 << endl;
}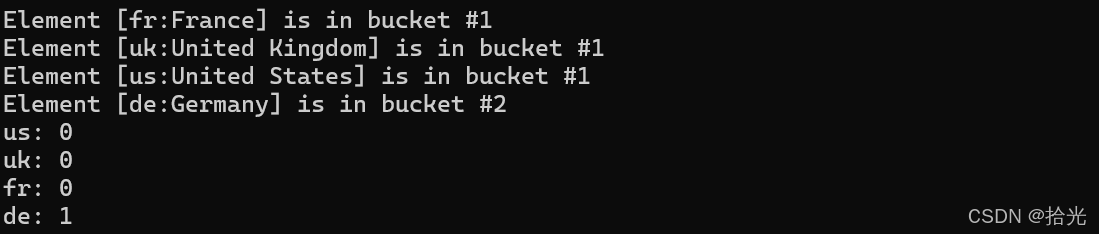
返回key在哈希表中的相对位置,即数组的下标+1。
4.4、负载因子------load_factor
cpp
void test04()
{
unordered_map<string, string> mymap = { {"us","United States"},{"uk","United Kingdom"},
{"fr","France"},{"de","Germany"}};
cout << "load_factor = " << mymap.load_factor() << std::endl;
}
即4/8=0.5。
4.5、扩容------rehash/reserve
cpp
void test05()
{
unordered_map<std::string, std::string> mymap1;
unordered_map<std::string, std::string> mymap2;
mymap1.rehash(20);
mymap2.reserve(20);
cout << "mymap1_rehash: " << mymap1.bucket_count() << endl;
cout << "mymap2_reserve: " << mymap2.bucket_count() << endl;
}
五、完整代码
<<"HashTables.h">>
cpp
#pragma once
#include<iostream>
#include<vector>
using namespace std;
// 仿函数,用来将负数,double等类型的数据先转化为无符号整形,因为只有unsigned int才能取模
template<class K>
struct HashFun
{
int operator()(const K& key)
{
return (size_t)key; // 强转
}
};
// 模板函数:特化,专门处理字符串
template<>
struct HashFun<string>
{
size_t operator()(const string& key)
{
size_t ch = 0;
auto it = key.begin();
for (size_t i = 0; i < key.size(); i++)
{
ch += *it * 131; // 由于字符串转为unsigned int,取模后容易重复,为了使哈希值更分散,对每个字符的ASCII值乘以一个131
it++;
}
return ch;
}
};
template<class T>
struct HashNode
{
T _data;
HashNode<T>* _next;
HashNode(const T& data)
:_data(data)
, _next(nullptr)
{
}
};
// 前置声明:Hash_Bucket实现在HTIterator之后
template<class K, class T, class keyOfT, class Hash>
class Hash_Bucket;
template<class K, class T, class Ref, class Ptr, class keyOfT, class Hash>
struct HTIterator
{
typedef HashNode<T> Node;
typedef Hash_Bucket<K, T, keyOfT, Hash> Hash_Bucket;
typedef HTIterator<K, T, Ref, Ptr, keyOfT, Hash> Self;
Node* _node;
const Hash_Bucket* _ht; // 用来找_tables,_tables.size()来确定哈希表的大小,方便取模
HTIterator(Node* node,const Hash_Bucket* ht)
:_node(node)
,_ht(ht)
{ }
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
bool operator==(const Self& s) const
{
return _node == s._node;
}
bool operator!=(const Self& s) const
{
return _node != s._node;
}
Self& operator++()
{
// 当前桶还有节点
if (_node->_next)
{
_node = _node->_next;
}
// 找下一个不为空的桶
else
{
keyOfT kot; // 仿函数
Hash hash; // 仿函数
size_t hashi = hash(kot(_node->_data)) % _ht->_tables.size(); // 定位到当前的桶
++hashi; // 向后寻找
while (hashi < _ht->_tables.size()) // _tables为Hash_Bucket的私有成员变量,需要将HTIterator声明为Hash_Bucket的友元
{
_node = _ht->_tables[hashi]; // _node指向下一个桶
// 下一个桶不为空
if (_node)
break;
// 这个桶仍为空,继续向后找
else
hashi++;
}
// 如果hashi 定位到哈希表的结尾,标记节点为空
if (hashi == _ht->_tables.size())
{
_node = nullptr;
}
return *this; // 返回++后的迭代器
}
}
};
template<class K, class T, class keyOfT, class Hash>
class Hash_Bucket
{
typedef HashNode<T> Node;
// 友元
template<class K, class T, class Ref, class Ptr, class keyOfT, class Hash>
friend struct HTIterator;
public:
typedef HTIterator<K, T, T&, T*, keyOfT, Hash> Iterator;
typedef HTIterator<K, T, const T&, const T*, keyOfT, Hash> ConstIterator;
// 构造
Hash_Bucket()
:_tables(__stl_next_prime(0))
, _size(0)
{}
// 析构
~Hash_Bucket()
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
Iterator Begin()
{
if (_size == 0)
{
return End();
}
size_t hashi = 0;
while (hashi < _tables.size())
{
if (_tables[hashi])
return Iterator{ _tables[hashi],this };
else
hashi++;
}
return End();
}
Iterator End()
{
return { nullptr,this };
}
ConstIterator Begin()const
{
if (_size == 0)
{
return End();
}
size_t hashi = 0;
while (hashi < _tables.size())
{
if (_tables[hashi])
return ConstIterator{ _tables[hashi],this };
else
++hashi;
}
return End();
}
ConstIterator End()const
{
return { nullptr,this };
}
// 素数,用来扩容
// 找一个比n大的素数,作为哈希表扩容的大小
inline unsigned long __stl_next_prime(unsigned long n)
{
// Note: assumes long is at least 32 bits.
static const int __stl_num_primes = 28; // __stl_prime_list数组有28个素数
static const unsigned long __stl_prime_list[__stl_num_primes] = {
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
const unsigned long* first = __stl_prime_list; // 数组起始位置
const unsigned long* last = __stl_prime_list + __stl_num_primes; // 数组末尾的下一个位置
const unsigned long* pos = lower_bound(first, last, n); // 找[first,last)区间中第一个大于或等于 n 的的素数
return pos == last ? *(last - 1) : *pos;
}
// 插入
pair<Iterator,bool> Insert(const T& data)
{
keyOfT kot;
Iterator it = Find(kot(data));
if (it!=End())
{
return { it,false };
}
Hash hash; // 仿函数
// 扩容
if (_size == _tables.size())
{
vector<Node*> newtables(__stl_next_prime(_tables.size() + 1)); // 创建一个新表
// 遍历旧表,将旧表的节点拿下来插入到新表,然后交换
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
size_t hashi = hash(kot(cur->_data)) % newtables.size();
// 头插
cur->_next = newtables[hashi];
newtables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtables); // 交换
}
size_t hashi = hash(kot(data)) % _tables.size();
Node* newnode = new Node(data);
Node* cur = _tables[hashi];
// 头插
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_size;
}
// 查找
Iterator Find(const K& key)
{
Hash hash;
keyOfT kot;
size_t hashi = hash(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return Iterator{ cur, this };
}
cur = cur->_next;
}
return End();
}
// 删除
bool Erase(const K& key)
{
Hash hash;
keyOfT kot;
size_t hashi = hash(key) % _tables.size();
Node* cur = _tables[hashi];
Node* prev = nullptr;
while (cur)
{
if (kot(cur->_data) == key)
{
// cur为桶的第一个节点
if (prev == nullptr)
{
_tables[hashi] = nullptr;
}
// 中间节点
else
{
prev->_next = cur->_next;
}
// 释放
delete cur;
--_size;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
private:
vector<Node*> _tables;
size_t _size = 0;
};<<"UnorderSet.h">>和<<''UnorderedMap.h''>>完整代码在其封装模块。
