这篇文章将继续解析太阳花大佬绘制的 YOLOv5 可视化图。没看过骨干网络的建议先看上一篇yolov5骨干网络图解-CSDN博客
太阳花大佬的博文:YOLOv5网络详解_yolov5网络结构详解-CSDN博客
不清楚怎么去掉图片的水印,就先这样了。
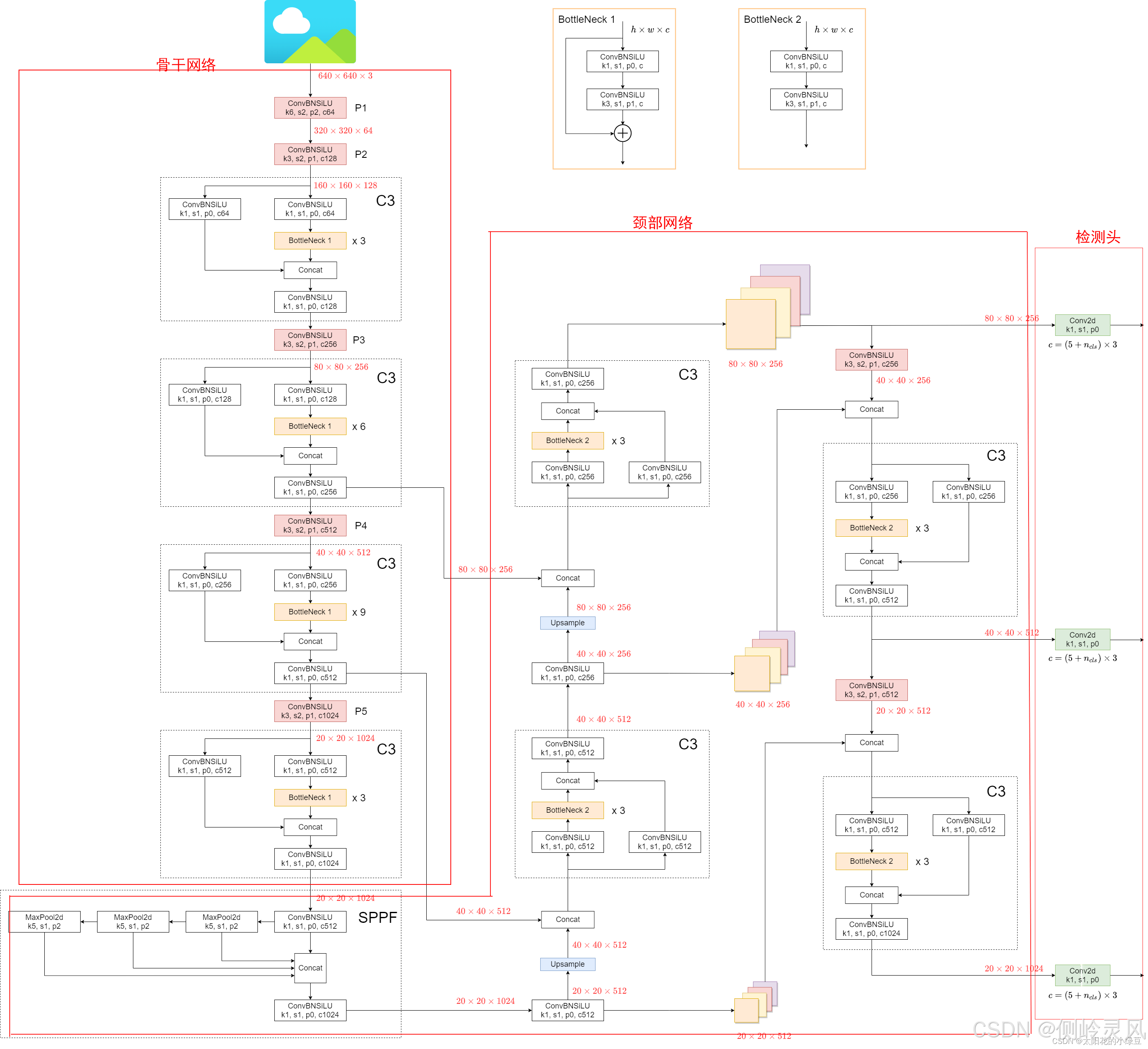
一. SPPF
这个模块包含了一系列的最大池化层(MaxPool2d)和卷积层(ConvBNSiLU),以及一个拼接操作(Concat)。
这个模块和C3有类似之处,都有一个快捷通道和一个深度处理通道。并在Concat处进行通道数拼接操作,形成20*20*2048的张量,再通过一次1024通道数的1*1卷积降低通道数到1024。
1. MaxPool2d
MaxPool2d是一种最大池化操作,k5值得是池化窗口大小为5x5,s1指的是步长为1,p2指的是填充为2。使用公式计算输出尺寸:
输入特征尺寸为20*20,通道数512,带入公式可计算出输出尺寸依然为20*20,由于MaxPool2d不改变通道数,所以每层池化层的输出通道依然是512。
同理,后面两次池化的输出结果依然是20*20*512,那么既然池化并没有改变输出尺寸,那为什么用最大池化而不用1*1卷积呢。
池化层(特别是最大池化)和卷积层(如 1x1 卷积)虽然可以达到类似的通道数调整效果,但它们在特征提取上的作用和目的有显著差异。
- **感受野的扩展,**最大池化 提供了一种有效的方法来增加网络的感受野。尽管在 SPPF 模块中使用的是步长为 1 的最大池化,但通过在输入特征图上应用不同大小的池化核(如 5x5、3x3),它实际上是在不降低特征图分辨率的情况下增加了感受野。这意味着网络能够在保持原有分辨率的同时,观察到更大区域的特征,有助于捕获更广泛的上下文信息。
- 特征的非线性和抽象化, 最大池化 通过从每个池化窗口中选择最强的特征响应,有助于模型捕获最显著的特征,并且还引入了一定程度的非线性。这种非线性是 1x1 卷积无法直接提供的,后者主要用于线性变换通道数,而没有直接的空间筛选效果。
- **多尺度信息的融合,**SPPF 通过使用不同尺寸的池化核来实现多尺度空间特征的融合。这样做可以使网络在不同的尺度上更好地理解图像,这对于检测不同大小的对象尤其重要。在此上下文中,最大池化层不仅是简单的下采样工具,而是一种有效的尺度聚合机制。
- 计算效率, 尽管最大池化和 1x1 卷积在计算上都比较高效,但在这种情况下,++最大池化用于通过保留重要特征的同时提高模型对不同尺度特征的适应性++。
总的来说,SPPF层的最大池化操作是有效增加感受野的办法,使其更适合检测大目标。
那么如果我把SPPF层中的若干个最大池化操作替换为1*1卷积会给模型带来怎样的变化呢。首先要说到1*1卷积的优势:
也就是在特征融合方面的灵活性,模型能够学习从每个通道中提取到的重要信息,提高特征的表达能力。
但是缺点就是会丢失空间的多样性,1*1卷积无法为不同尺寸的区域处理提供帮助,他只能在通道级别进行信息融合,无法增加感受野或捕获更广泛的上下文信息。并且降低模型对尺寸变化的鲁棒性。
这个部分可以根据训练数据的任务需求、数据特点和模型整体的设计目标自行进行调整。
二. 特征整合
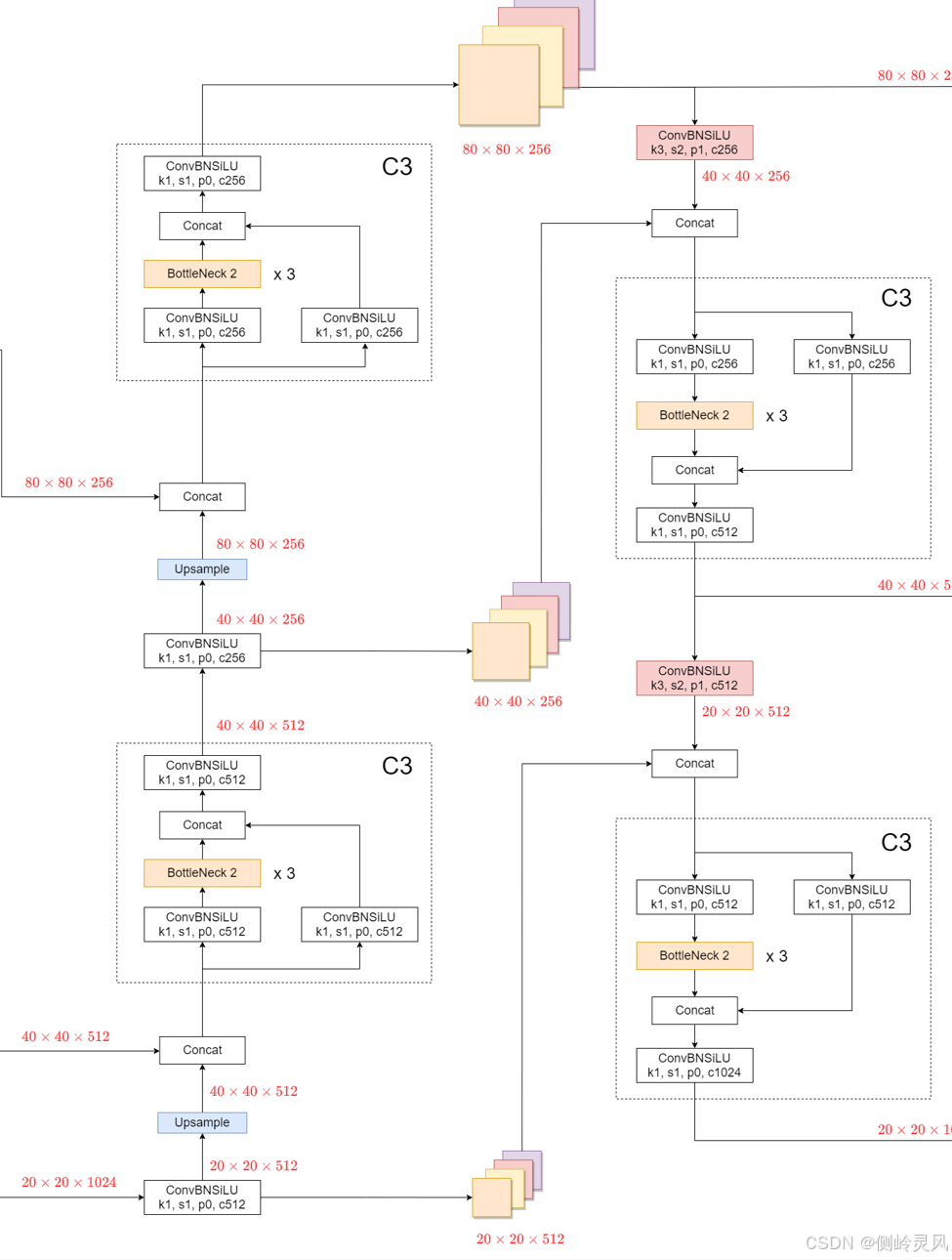
1. 下采样
下采样通过减少输入图像或特征图的空间维度(即像素数量),同时增加其深度(通道数),以便模型可以学习更抽象和全局的特征。
目的:
下采样在神经网络中主要用于逐步减少输入图像的空间维度(即宽度和高度),这样做的好处是:
降低计算复杂度:减少后续层需要处理的数据量,从而减少计算成本。
提高特征的抽象级别:通过减少每层的空间维度,网络可以被迫学习更加全局和抽象的特征,而不是仅仅关注局部的细节。
增强感受野:每经过一次下采样,网络中的神经元对输入数据的感受野增大,有助于捕捉更广泛的上下文信息。
方法:
步幅大于1的卷积:使用卷积操作时,设置大于1的步幅(stride),例如步幅为2的卷积核。这样可以将输入特征图的空间维度缩小。
最大池化(Max Pooling):利用池化操作(如2x2最大池化)来将每个池化窗口内的最大值作为输出,从而减少特征图的尺寸而增加深度。
2. 上采样(Upsample)
上采样通过增加特征图的空间维度,以还原尺寸并使来自底层的高分辨率信息能够与深层特征重新融合,从而改进模型在小尺寸物体上的性能。
目的
上采样在神经网络中的主要目的是放大特征图的空间尺寸,以便能够:
恢复细节和分辨率:在进行了多层下采样之后,上采样有助于恢复接近原始输入尺寸的空间分辨率。
特征融合:将深层次、抽象的特征与浅层次、详细的特征结合起来,特别是在需要精细定位的应用中(如图像分割)。
方法:
反卷积(转置卷积):使用反卷积操作来执行上采样,逆转先前的卷积操作,从而恢复特征图的空间维度。反卷积通过填充输入空间中的间隙来增加特征图的尺寸。
插值方法:例如双线性插值,根据周围像素的值计算新的像素值,从而增加特征图的尺寸。
在yolov5中采用的上采样插值算法是最近邻插值,++若上采样比例为 2++ ,则新图像中的(x, y)位置的像素值将直接取自原图像中的++(floor(x / 2), floor(y / 2))++位置,floor函数实际上就是向下取整。
如果你查看新图像中 (2, 2) 的位置,按照计算,它将从原图(floor(2 / 2), floor(2 / 2)),即 (1, 1) 处获取颜色值。
假设有一个2*2的原图,像素分布如:
现在,把他放大到4*4,根据最近邻插值法,新图的构造会是这样的:
3.特征层级融合
(1)先看上采样融合部分:
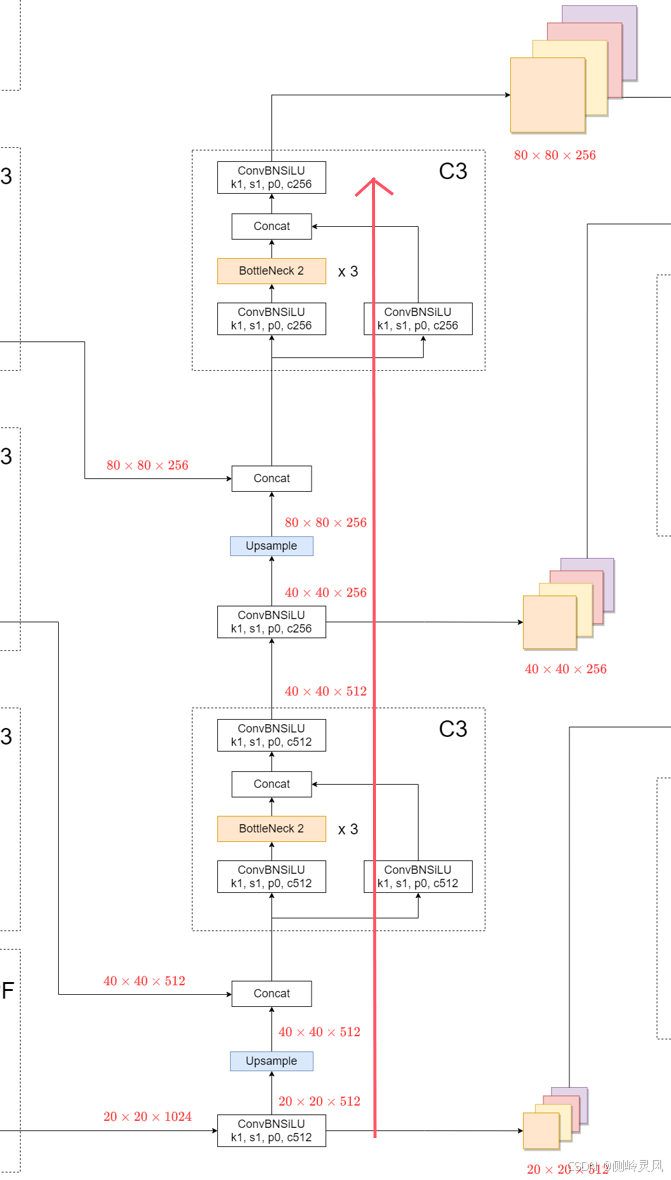
可以看到,浅层的80*80*256的特征张量是由深层中层浅层经过一系列处理并进行特征融合得出的。
其中还经过了C3模块,这里的C3模块的作用是进一步增强特征的表示能力,这意味着网络能够同时学习和利用高层的语义信息和低层的细节信息。通过这种方式,模型能够更好地理解和检测不同尺寸和复杂度的目标,提高特征的多样性和鲁棒性。
经过了上一章骨干网络的讲解,这一部分应该已经可以轻松看懂了。
**简单的来说:**就是将浅层的细节信息和深层的语义信息进行融合,使得浅层特征能够通过跨阶段的连接结构,有效地增强和利用深层特征的语义信息,从而提升目标检测的准确性和鲁棒性。
(2)接下来看下采样融合部分:
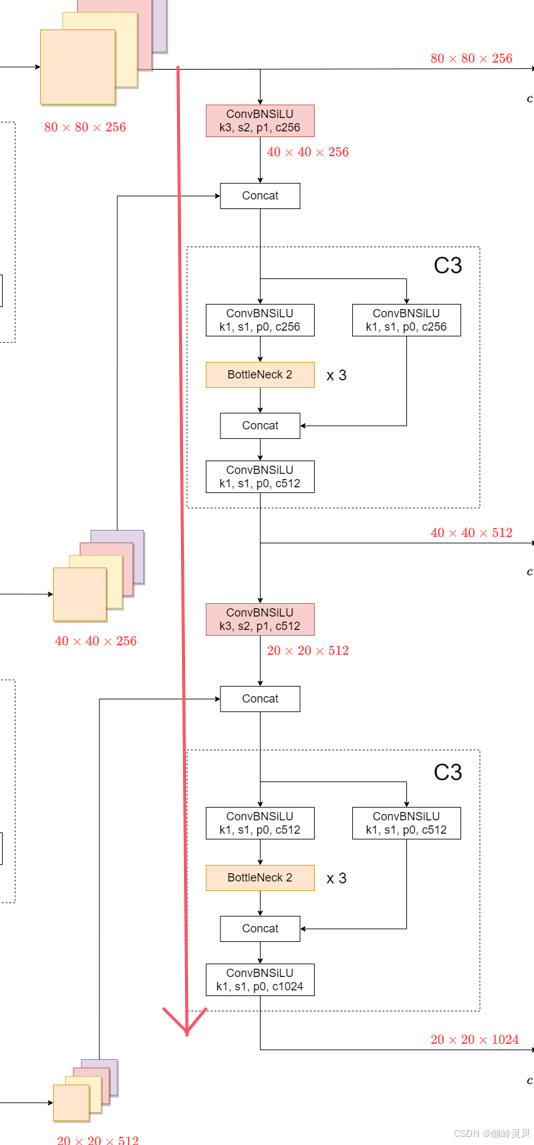
深层的部分则是将原本已经融合好的浅层+中层+深层的特征进行下采样,继续参与特征融合。深层特征经过多次融合 。
复杂的特征融合策略有助于模型在多种环境和条件下的泛化能力。特别是在遇到视觉上变化大的环境时,如不同光照、复杂背景等,这种多层次的特征融合能够提供更多的信息来支持正确的决策。
(3)整合上采样和下采样两个部分:
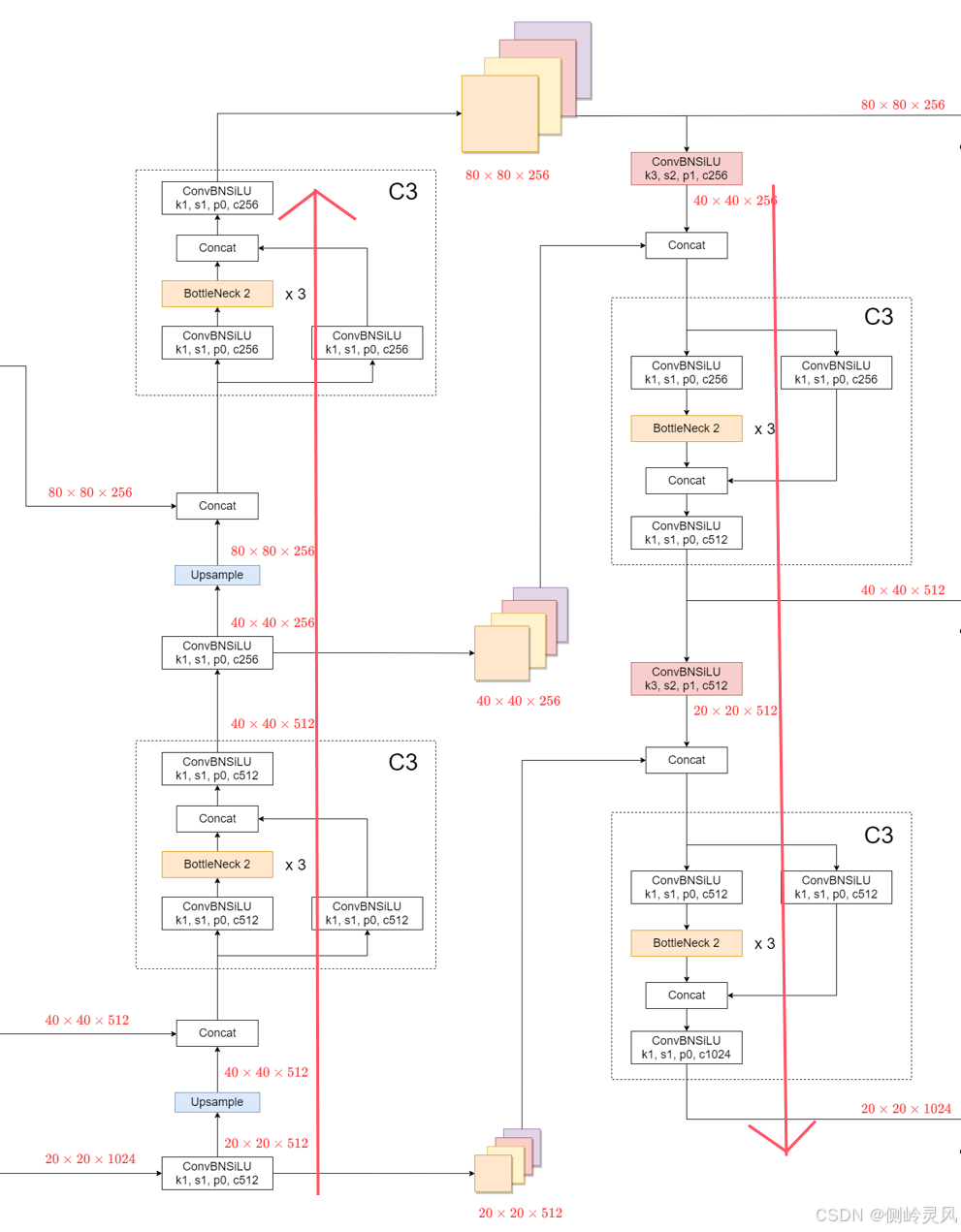
可以发现:
浅层=浅层+中层+深层
中层=浅层+中层+深层+中层
深层=浅层+中层+深层+中层+深层
- 浅层特征:融合了中层和深层的特征后,保留了较高的空间分辨率和细节信息,适合于精确的小物体检测。
- 中层特征:融合了更多层次的特征,包括深层和浅层,使得中层特征具有更丰富的语义信息和上下文理解能力,有助于对复杂场景和大型目标的检测。
- 深层特征:深层特征经过多次融合,最大程度上增强了语义理解的深度和范围。这样的设计优化了对大型和复杂目标的识别能力,使模型能够在复杂场景中实现更为精确的检测。