VGGNet(Visual Geometry Group Network)是由牛津大学视觉几何组(Visual Geometry Group)在2014年提出的深度卷积神经网络模型。它在当年的ImageNet大规模视觉识别挑战赛(ILSVRC)中取得了优异的成绩,并因其简洁而有效的设计成为深度学习领域的经典架构之一。
0 概念
0.1 卷积块
卷积块:由n个卷积层组成------就是连续几次卷积操作提取不同信息。
每个卷积块后面紧跟1个池化层。
0.2 FC
Full Connection全连接层。
1 网络结构
VGG 探索出来的网络由 5 个卷积块(Block)和 3 个全连接层(FC)组成。
VGG16 和 VGG19 是 VGGNet 系列中最经典的两个模型,它们的核心区别在于中间卷积块的"厚度"。VGG19 在 VGG16 的基础上,在中间三个卷积块中分别多堆叠了一层卷积,使得网络更深。
下表详细对比了每一层的结构差异(加粗部分为 VGG19 比 VGG16 多出的层):
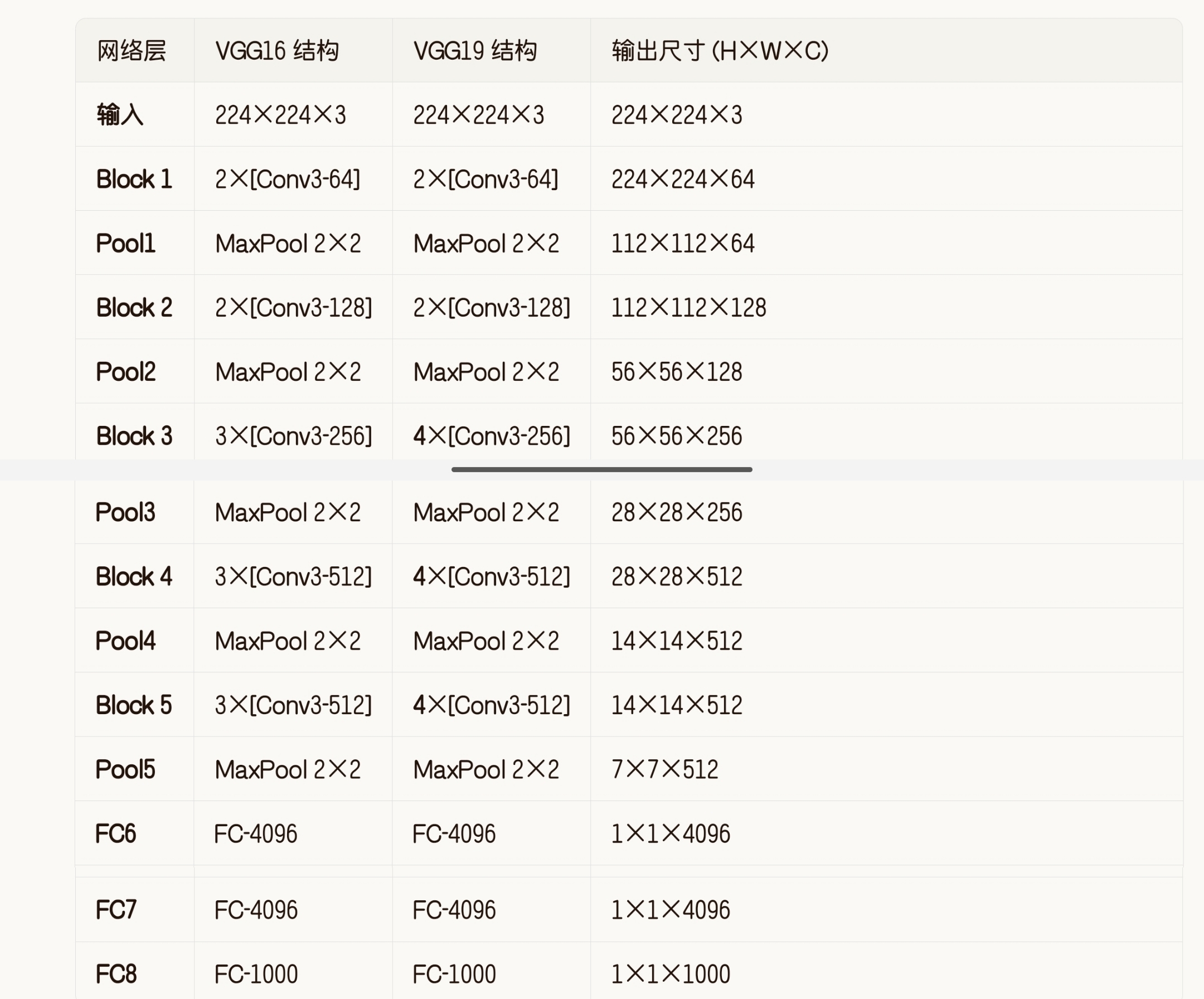
层数差异:
VGG16 包含 13 个卷积层(2+2+3+3+3) + 3 个全连接层 = 16 层;
VGG19 包含 16 个卷积层(2+2+4+4+4) + 3 个全连接层 = 19 层。
参数差异:虽然 VGG19 更深,但两者参数量差距不大(VGG16 约 1.38 亿,VGG19 约 1.47 亿)。这是因为 VGG 的参数主要集中在最后的全连接层(FC6 层占了约 1.02 亿参数),而卷积层只增加了 3 层,对总参数量影响较小。
2 设计逻辑
VGG 的设计遵循"池化一次,通道数翻倍"的原则。每次池化后,特征图尺寸减半,但卷积核数量(通道数)翻倍,以保持计算量的平衡。具体如下:
输入:224×224×3
第一次池化后:112×112×64
第二次池化后:56×56×128
第三次池化后:28×28×256
第四次池化后:14×14×512
第五次池化后:7×7×512
尺寸减半:池化层减少特征图尺寸,降低计算量。
通道翻倍:增加卷积核数量,让网络在更小的空间里提取更丰富的特征信息,弥补因尺寸缩小带来的信息损失。
小细节:
你可能会注意到,最后一次池化后,通道数没有从 512 翻倍到 1024,而是保持 512。这是因为 VGG 作者发现,在当时的硬件条件下,512 通道已经足够提取高层语义特征,再增加通道数对性能提升不大,但计算量会剧增。
VGG11/13/16/19 等多种变体,数字越大通过增加卷积层数,让网络在更深层提取更抽象的特征,理论上表达能力更强,但也更容易过拟合且计算更慢。
3 pytorch代码实现兼容VGG11/13/16/19 等多种变体
c
import torch
import torch.nn as nn
# 定义 VGG 配置字典
cfgs = {
'VGG11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'VGG19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
class VGG(nn.Module):
def __init__(self, vgg_name='VGG16', num_classes=1000, init_weights=True):
"""
参数:
vgg_name: 要构建的 VGG 变体名称,如 'VGG16'
num_classes: 分类类别数,默认 1000
init_weights: 是否初始化权重
"""
super(VGG, self).__init__()
# 1. 构建特征提取层
self.features = self._make_layers(cfgs[vgg_name])
# 2. 构建分类器
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096), # 输入尺寸: 512*7*7
nn.ReLU(True),
nn.Dropout(), # 默认为 Dropout(p=0.5)
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def _make_layers(self, cfg):
"""
根据配置列表构建卷积层
参数:
cfg: 配置列表,数字表示输出通道数,'M' 表示最大池化
"""
layers = []
in_channels = 3 # 输入通道数(RGB图像)
for v in cfg:
if v == 'M':
# 最大池化层
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
# 卷积层
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v # 更新输入通道数为当前输出通道数
return nn.Sequential(*layers)
def _initialize_weights(self):
"""初始化网络权重"""
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
# 特征提取
x = self.features(x)
# 展平
x = torch.flatten(x, 1) # 保持 batch 维度,展平其他所有维度
# 分类
x = self.classifier(x)
return x
# 2. 使用示例
if __name__ == "__main__":
# 创建 VGG16
vgg16 = VGG('VGG16', num_classes=1000)
print("VGG16 结构:")
print(vgg16)
# 创建 VGG19
vgg19 = VGG('VGG19', num_classes=1000)
print("\nVGG19 结构:")
print(vgg19.features) # 打印卷积部分的结构对比
# 测试前向传播
batch_size = 4
dummy_input = torch.randn(batch_size, 3, 224, 224)
# VGG16 输出
output_16 = vgg16(dummy_input)
print(f"\n输入形状: {dummy_input.shape}")
print(f"VGG16 输出形状: {output_16.shape}")
# VGG19 输出
output_19 = vgg19(dummy_input)
print(f"VGG19 输出形状: {output_19.shape}")这就是实现可扩展性的核心:
cfgs = {
'VGG16': 64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', ...,
'VGG19': 64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', ...,
}
数字表示卷积层的输出通道数
'M' 表示最大池化层
只需修改配置列表就能创建不同的 VGG 变体
特征提取器构建( _make_layers 方法):
遍历配置列表,遇到数字就创建卷积层
每个卷积层后面自动跟随 ReLU 激活函数
遇到 'M' 就创建池化层
自动更新输入通道数
输入图片:224×224
经过 5 次池化后:224/(2^5) = 7
最后一层卷积通道数:512
所以展平后维度:512 × 7 × 7 = 25088
扩展使用示例
c
# 1. 创建各种 VGG 变体
vgg11 = VGG('VGG11', num_classes=10) # 用于 CIFAR-10
vgg13 = VGG('VGG13', num_classes=100) # 用于 CIFAR-100
vgg16 = VGG('VGG16', num_classes=1000) # ImageNet
vgg19 = VGG('VGG19', num_classes=1000)
# 2. 加载预训练权重(需要安装 torchvision)
from torchvision import models
pretrained_vgg16 = models.vgg16(pretrained=True)
pretrained_vgg19 = models.vgg19(pretrained=True)
# 3. 自定义分类头(迁移学习)
def get_custom_vgg(num_classes=10):
model = VGG('VGG16', num_classes=num_classes)
# 冻结卷积层(只训练分类器)
for param in model.features.parameters():
param.requires_grad = False
return model
custom_model = get_custom_vgg(num_classes=10)4 探索出来的经验和理论
VGGNet 最核心的探索成果,是确立了"深度"在卷积神经网络中的决定性作用,并总结出了一套"小卷积核 + 模块化"的经典设计范式。这些经验至今仍是深度学习架构设计的基石。
4.1 核心理论:深度决定性能
VGGNet 通过严谨的对比实验,证明了网络深度(层数)是提升模型性能的关键因素。
实验验证:VGG 团队设计了从 11 层到 19 层的多个变体,发现随着层数增加,模型在 ImageNet 上的错误率显著下降。这直接推翻了当时"网络太深难以训练"的普遍认知,为后续 ResNet、DenseNet 等超深网络的发展铺平了道路。
4.2 设计经验:小卷积核的威力
VGGNet 确立了 "用多个小卷积核替代大卷积核" 的设计原则。
3×3 卷积核:VGG 发现,两个 3×3 卷积层的感受野等同于一个 5×5 卷积层,三个 3×3 卷积层的感受野等同于一个 7×7 卷积层。
优势:这种设计不仅减少了参数量(计算量更小),还引入了更多的非线性激活函数(ReLU),让网络具备了更强的特征提取能力。
4.3 架构范式:模块化与通道翻倍
VGGNet 建立了"卷积块 + 池化层"交替的经典架构模式。
模块化设计:将网络划分为多个卷积块(Block),每个块内包含 2-4 个卷积层,块与块之间用池化层连接。这种结构清晰、易于理解和实现。
通道翻倍:每次池化后(特征图尺寸减半),下一个卷积块的通道数翻倍。这种设计平衡了计算量,确保了网络在深层依然能保留足够的信息。
4.4 工程启示:简洁与可复现
VGGNet 证明了简洁的设计往往最有效。
结构极简:整个网络只使用了 3×3 卷积和 2×2 池化两种操作,没有任何复杂的技巧。
可复现性:由于其结构规整,代码实现非常容易,这极大地促进了深度学习在工业界的普及和应用。
5 当代价值
尽管在 ImageNet 准确率上已被更先进的网络超越,但 VGGNet 仍具有不可替代的价值:
教学价值:几乎所有深度学习课程都从 VGG 开始讲解 CNN 设计。
研究基线:新方法常以 VGG 为基线进行对比。
艺术应用:在风格迁移、深度学习艺术中,VGG 的特征图仍是首选。
边缘部署:其规整结构在某些硬件上仍比复杂网络更高效。
6 实验科学的思考
再一次加深了对于深度学习网络结构的实验科学的倾向!!!
没有理论依据,都是马后炮的思考!
目前感觉还处于盲人摸象阶段!!