哨兵 - 通过自动化的手段,来解决主节点挂了的问题
哨兵机制,是通过独立的进程来体现的.和之前redis-server是不同的进程!! redis-sentinel 不负责存储数据,只是对其他的redis-server 进程起到监控的效果
通常哨兵节点,也会搞一个集合(多个哨兵节点构成的)
一、为什么需要 Redis Sentinel?
在 Redis 主从架构中,虽然解决了数据冗余和读写分离的问题,但存在一个致命缺陷:主节点故障后需要人工介入切换。
实际开发中,对于服务器后端开发,监控程序,是非常重要的!!
服务器,要求要有比较高的可用性,7*24运行。服务器长期运行,总会有一些"意外",具体啥时候出现了意外,咱们也不知道。同时,也不能全靠人工来盯着服务器运行
人工切换的痛点非常明显:
-
响应延迟:故障发生后,运维人员需要时间发现问题、确认状态并执行切换,期间业务会持续中断。
-
风险高:人工操作容易出现误判或配置错误,导致切换失败或数据不一致。
-
无法 7×24 保障:夜间或非工作时段故障时,无法及时响应,严重影响业务连续性。
Redis Sentinel(哨兵)就是为了解决这些问题而生的,它是一个分布式的监控和故障转移系统,核心目标是实现 Redis 主从集群的自动化故障检测与转移。
二、Redis Sentinel 核心原理与架构图
1. 完整架构图
bash
┌───────────────────────────────────────────────────────────┐
│ 客户端层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Client 1 │ │ Client 2 │ │ Client 3 │ │
│ └──────────┘ └──────────┘ └──────────┘ │
└───────────────────────────────────────────────────────────┘
│
▼
┌───────────────────────────────────────────────────────────┐
│ Sentinel 集群 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │Sentinel 1│ │Sentinel 2│ │Sentinel 3│ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ (分布式决策) │
└───────────────────────────────────────────────────────────┘
│
▼
┌───────────────────────────────────────────────────────────┐
│ Redis 数据层 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Redis Master │◄─┤ Redis Slave 1│◄─┤ Redis Slave 2│ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ (主从复制同步) │
└───────────────────────────────────────────────────────────┘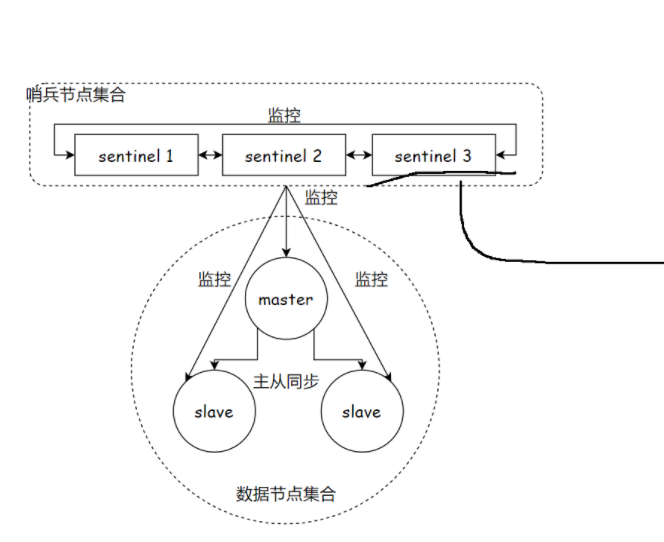
提供了多个单独的redis sentinel进程.
并且这三个哨兵 进程就会监控现有的redis master 和 slave.(监控:这些进程之间,会建立tcp长连接,通过这样的长连接,定期发送心跳包)
借助上述的监控机制,就可以及时发现,某个主机是否是挂了.
如果是从节点挂了其实没关系
如果是主节点挂了,哨兵就要发挥作用了
此时,一个哨兵节点发现主节点挂了,还不够,需要多个哨兵节点来共同认同这件事情。主要是为了防止出现误判。
主节点确实是挂了,这些哨兵节点中,就会推举出一个leader~~由这个leader负责从现有的从节点中,挑选一个作为新的主节点
挑选出新的主节点之后,哨兵节点就会自动控制该被选中的节点,执行slaveof no3.one 并且控制其他从节点,修改slaveof到新的主节点上
哨兵节点会自动的通知客户端程序,告知新的主节点是谁,并且后续客户端再进行写4.
操作,就会针对新的主节点进行操作了.
redis 哨兵核心功能:
-
监控
-
自动的故障转移
-
通知
注意,redis哨兵节点,有一个,也是可以的
- 如果哨兵节点只有一个,它自身也是容易出现问题的
万一这个哨兵节点挂了,后续redis节点也挂了,就无法进行自动的恢复过程了
- 出现误判的概率也比较高
毕竟网络传数据是容易出现抖动或者延迟或者丢包的如果只有一个哨兵节点,出现上述问题之后,影响就比较大
架构说明:
-
客户端层:通过 Sentinel 集群获取主节点地址,自动切换连接,无需硬编码 IP。
-
Sentinel 集群:由 3 个及以上节点组成,负责监控 Redis 节点状态、执行故障转移、通知客户端。
-
Redis 数据层:1 主 2 从的主从架构,主节点处理写请求,从节点同步数据并处理读请求。
2. 哨兵的角色与核心功能
Sentinel 本身是一个独立的 Redis 进程,不存储数据,仅负责监控和管理主从集群,核心功能包括:
-
监控(Monitoring):持续检查主节点和从节点是否正常运行。
-
自动故障转移(Automatic Failover):当主节点故障时,自动选举一个从节点提升为新主节点,并将其他从节点指向新主节点。
-
通知(Notification):通过 API 或脚本通知客户端和运维人员主节点变化,让客户端自动切换到新主节点。
-
配置提供(Configuration Provider):客户端通过哨兵获取当前主节点的地址,无需硬编码 IP 和端口。
3. 哨兵集群的分布式特性
哨兵必须以集群模式部署(建议至少 3 个节点),这是因为:
-
避免单点故障:单个哨兵节点宕机后,其他节点仍能正常工作。
-
提高决策准确性:通过"投票机制"判断主节点是否真的故障,避免网络分区导致的误判。
-
高可用保障:集群模式下,只要超过半数的哨兵节点正常运行,就能完成故障转移。
4. 故障检测与转移的完整流程
(1)故障检测:主观下线与客观下线
-
主观下线(SDOWN):单个哨兵节点通过心跳检测(PING 命令)发现主节点无响应,会将其标记为"主观下线"。这只是单个节点的判断,可能存在网络波动等误判。
-
客观下线(ODOWN) :当超过
quorum(配置的法定人数,通常为哨兵数量的半数加一)个哨兵节点都认为主节点主观下线时,会将其标记为"客观下线",确认主节点真的故障。
(2)Leader 选举:Raft 算法的简化实现
当主节点被标记为客观下线后,哨兵集群会选举一个 Leader 节点,由它来执行故障转移:
-
每个哨兵节点都可以成为候选人,向其他节点发送投票请求。
-
其他节点会投票给第一个收到的请求,确保只有一个 Leader 被选出。
-
获得超过半数投票的节点成为 Leader,负责后续的故障转移操作。
(3)故障转移:从节点提升与配置更新
-
选择新主节点:Leader 会从所有从节点中选择一个最优的节点提升为新主节点,选择优先级如下:
-
优先选择
slave-priority(从节点优先级)最高的节点(默认 100,值越高优先级越高)。 -
若优先级相同,选择复制偏移量(offset)最大的节点(数据最完整)。
-
若偏移量相同,选择运行 ID(runid)最小的节点。
-
-
提升从节点为新主节点 :向选中的从节点发送
SLAVEOF NO ONE命令,使其成为主节点。 -
重定向其他从节点 :向剩余从节点发送
SLAVEOF <new-master-ip> <new-master-port>命令,让它们复制新主节点的数据。 -
更新配置与通知:将新主节点的地址更新到哨兵集群的配置中,并通知客户端切换连接。
三、基于 Docker 快速部署 Sentinel 集群
docker可以认为是一个"轻量级"的虚拟机起到了虚拟机这样的隔离环境的效果,但是又没有吃很多的硬件资源.即使是配置比较拉胯的云服务器,也能构造出好几个这样的虚拟的环境
Docker 是部署 Sentinel 集群的最佳方式之一,它可以隔离环境、简化配置、快速扩缩容。以下是完整的部署步骤:
1. 环境准备
-
安装 Docker 和 Docker Compose。
-
确保宿主机有足够的资源(建议 2C4G 以上)运行 3 个哨兵节点和 3 个 Redis 节点(1 主 2 从)。
2. 编写 Docker Compose 配置
创建 docker-compose.yml 文件,定义 Redis 主从节点和哨兵节点:
XML
version: '3'
services:
# Redis 主节点
redis-master:
image: redis:5.0
container_name: redis-master
ports:
- "6379:6379"
command: redis-server --appendonly yes
# Redis 从节点 1
redis-slave1:
image: redis:5.0
container_name: redis-slave1
ports:
- "6380:6379"
command: redis-server --slaveof redis-master 6379 --appendonly yes
depends_on:
- redis-master
# Redis 从节点 2
redis-slave2:
image: redis:5.0
container_name: redis-slave2
ports:
- "6381:6379"
command: redis-server --slaveof redis-master 6379 --appendonly yes
depends_on:
- redis-master
# 哨兵节点 1
sentinel1:
image: redis:5.0
container_name: sentinel1
ports:
- "26379:26379"
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/etc/redis/sentinel.conf
depends_on:
- redis-master
- redis-slave1
- redis-slave2
# 哨兵节点 2
sentinel2:
image: redis:5.0
container_name: sentinel2
ports:
- "26380:26379"
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/etc/redis/sentinel.conf
depends_on:
- redis-master
- redis-slave1
- redis-slave2
# 哨兵节点 3
sentinel3:
image: redis:5.0
container_name: sentinel3
ports:
- "26381:26379"
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/etc/redis/sentinel.conf
depends_on:
- redis-master
- redis-slave1
- redis-slave23. 编写哨兵配置文件
创建三个哨兵配置文件(sentinel1.conf、sentinel2.conf、sentinel3.conf),内容如下:
bash
port 26379
dir /tmp
sentinel monitor mymaster redis-master 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000配置说明:
-
sentinel monitor mymaster redis-master 6379 2:监控名为mymaster的主节点,地址为redis-master:6379,需要至少 2 个哨兵节点确认故障才会触发转移。 -
down-after-milliseconds:哨兵认为主节点无响应的超时时间(毫秒),默认 30000(30 秒)。 -
parallel-syncs:故障转移后,同时向新主节点同步数据的从节点数量(默认 1,避免网络压力过大)。 -
failover-timeout:故障转移的超时时间(毫秒),默认 180000(3 分钟)。
4. 启动集群
在配置文件目录下执行命令启动所有节点:
bash
docker-compose up -d5. 验证集群状态
-
查看容器运行状态:
docker-compose ps -
检查哨兵监控状态:
docker exec -it sentinel1 redis-cli -p 26379 sentinel master mymaster -
手动模拟主节点故障:
docker stop redis-master,观察哨兵是否自动选举新主节点。
四、Sentinel 生产环境的优化与避坑
1. 部署优化
-
节点隔离:哨兵节点和 Redis 节点应部署在不同的物理机或虚拟机上,避免单点故障影响整个集群。
-
网络分区防护 :通过
sentinel resolve-hostnames yes配置让哨兵使用域名而非 IP 通信,减少网络分区的影响。 -
资源限制:为 Docker 容器设置 CPU 和内存限制,避免单个节点占用过多资源。
2. 配置优化
-
合理设置
quorum:建议设置为哨兵数量的半数加一(如 3 个哨兵节点设置为 2),确保决策的准确性。 -
调整超时时间 :根据业务场景调整
down-after-milliseconds,对延迟敏感的场景可适当缩短(如 10 秒),但需避免误判。 -
开启日志持久化 :配置哨兵日志文件路径(
logfile /var/log/redis/sentinel.log),便于故障排查。
3. 常见问题与解决方案
(1)哨兵误判主节点故障
-
原因:网络波动、主节点 CPU/内存过高导致心跳超时。
-
解决方案 :增加
down-after-milliseconds的值(如设置为 60 秒),或优化主节点性能。
(2)故障转移后客户端无法切换
-
原因:客户端未通过哨兵获取主节点地址,而是硬编码 IP。
-
解决方案:客户端使用哨兵客户端(如 JedisSentinelPool),自动从哨兵获取主节点地址。
(3)从节点同步延迟过高
-
原因:主节点写压力过大、网络带宽不足。
-
解决方案 :增加从节点数量分散读请求,或升级网络带宽,开启主节点的无盘复制(
repl-diskless-sync yes)。
五、 哨兵重新选取主节点的流程.
1. 主观下线
哨兵节点通过心跳包,判定redis服务器是否正常工作.
如果心跳包没有如约而至,就说明redis服务器挂了.
此时还不能排除网络波动的影响,因此就只能是单方面认为这个redis节点挂了
2. 客观下线
多个哨兵都认为主节点挂了.(认为挂了的哨兵节点数目达到法定票数)哨兵们就认为这个主节点是客观下线
比如是否可能出现非常严重的网络波动,导致所有的哨兵都联系不上redis主节点误判成挂了呢??
当然是有的!!!
如果出现这个情况,怕是用户的客户端也连不上redis主节点了.....
此时这个主节点基本也就无法正常工作了.
"挂了"不一定是进程崩了.
只要无法正常访问,都可以视为是挂了.
3. 选出主节点
要让多个哨兵节点,选出一个leader节点由这个leader负责选一个从节点作为新的主节点.

每个哨兵手里只有一票.
当哨兵1第一个发现当前是客观下线之后,就立即给自己投了一票,并且告诉了23,我来负责这个事情.23反应慢了半拍,才发现是客观下线.一看1乐意负责这个事情,立即投了赞成票
23当他们没有投出这个票的时候,收到拉票请求,就会投出去(如果有多个拉票请求,就会投给最先到达的)
如果总的票数超过哨兵总数的一半,选举完成了.(把哨兵个数设置为奇数个节点,就是为了方便投票)
上面投票过程,看谁反应快(谁网络延时小)
4. 此时leader 选举完毕,leader 就需要挑选一个从节点,作为新的主节点.
-
优先级 每个redis数据节点,都会在配置文件中,有一个优先级的设置.slave-priority某个助教老师,是杨校长钦定的。优先级高的从节点,就会胜出
-
offset 最大,就胜出.
offset从节点从主节点这边同步数据的进度.数值越大,说明从节点的数据和主节点就越接近.谁的备课进度更多
- runid 每个redis节点启动的时候随机生成的一串数字 (大小全凭缘分了)(此时,选谁都可以了,随便挑一个)
看谁起的名字好听
六、总结
-
哨兵节点不能只有一个.否则哨兵节点挂了也会影响系统可用性
-
哨兵节点最好是奇数个.方便选举leader,得票更容易超过半数. 大部分情况下3个就够了
-
哨兵节点不负责存储数据,仍然是redis主从节点负责存储.
- 哨兵节点就可以使用一些配置不高的机器来部署.(但是不能搞一个机器部署三个哨兵)
-
哨兵+主从复制解决的问题是"提高可用性 ",不能解决"数据极端情况下写丢失"的问题
-
哨兵+主从复制不能提高数据的存储容量,当我们需要存的数据接近或者超过机器的物理内存,这样的结构就难以胜任了.
redis集群,就是解决存储容量问题的有效方案
Redis Sentinel 是 Redis 主从架构的高可用增强方案,通过自动化的故障检测与转移,解决了人工切换的痛点。在生产环境中,结合 Docker 可以快速部署和管理哨兵集群,提升运维效率。同时,需要深入理解哨兵的原理,优化配置和部署方式,才能保证集群的稳定运行。随着业务规模的增长,还可以进一步演进到 Redis Cluster 架构,实现水平扩容和更高的可用性。