导言:本系列开始记录自己学习LangChain与LangGraph AI应用开发框架的知识点。本文是开始学习LangChain所要了解到的前置知识--大模型的有关内容。
文中部分网址需要magic哦!
一、认识模型
1.1概述
通俗来说模型就是一个可以从海量数据中学习规律的"数学函数"或"程序"。
通过从⼤型数据集中学习模式和洞察,这些模型可以进⾏预测、⽣成⽂本、图像或其他输出,从⽽增强各个⾏业的各种应⽤。
1.2特点:
关键特点:
(1)仅擅长特定的任务
(2)需要标注数据(标准答案),训练这种模型需要⼤量"标准答案"
(3)参数较少(参数是模型从数据中学到的"知识要点"或"内部规则")
二、大语言模型(LLM)
2.1概述:
LLM是基于大规模神经网络通过自监督或半监督方式,对海量文本进行训练的语言模型
2.2名词解释:
(1)神经网络:通过数据训练出来的,由大量参数组成的复杂决策系统(类似大脑中大量的神经元组成判别事物的复杂系统)。采用流水线的工作方式,前一层的输出作为后一层的输入。
(2)⾃监督学习:"完形填空"超级⼤师。⾃监督就是让模型从数据本⾝找规律,⾃⼰给⾃⼰当⽼师。
(3)半监督就是"少量指导+⼤量⾃学"的结合模式。
(4)语⾔模型:⼀个"超级⾃动补全"或"语⾔预测器"
2.3特点
• 规模巨⼤: 它的"脑细胞"(参数)特别多(通常达到数⼗亿甚⾄万亿级别),所以思考问题更复杂、更全⾯,就像⼀⽀百万⼤军和⼀个⼩分队的区别。
• 通⽤性强 : 它不是为单⼀任务训练的。因为它通过"完形填空"学会的是整个语⾔世界的底层规律 (语法、逻辑、知识关联),⽽不是只背会了"猫的图⽚"。所以它能举⼀反三,把底层能⼒灵活应⽤到聊天、翻译、写代码等各种任务上。这种"涌现"能⼒,就像孩⼦通过⼤量阅读后,突然能写出意想不到的优美句⼦⼀样。
• 训练⽅式不同 : 主要使⽤⾃监督学习,从海量⽆标注的原始⽂本中学习。它不依赖⼈⼯⼀张张地给图⽚标"这是猫",⽽是直接从原始⽂本中⾃学,效率极⾼,规模可以做得⾮常⼤。
• 交互⽅式⾰命 : 我们不⽤点按钮、写代码,直接像对⼈说话⼀样给它指令(Prompt) 它就能听懂 并执⾏,⽐如你直接说"写⼀⾸关于春天的诗",它就能给你写出来。
2.4LLM的能力
(1)语言大师:进行理解与创造
(2)知识巨人:拥有全互联网的知识记忆
(3)对逻辑与思维进行快速的代码实现
(4)多模态先知:开启 "全感知" AI 的⼤⻔
2.5LLM的接入方式

(1)API接入:
a.在模型提供商平台注册账号并获取API Key
b.查阅平台中的API调用文档
c.构建HTTP请求
curl调用案例: curl "https://api.openai.com/v1/responses" \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -d '{ "model": "gpt-5", "input": "Write a one-sentence bedtime story about a unicorn." }'openaiAPI参考:https://platform.openai.com/docs/api-reference/introduction
(2)本地部署:
a.获取模型:从 Hugging Face(国外)、魔搭社区(国内)等平台下载开源模型的权重
b.准备环境:配置具有⾜够显存(如 NVIDIA GPU)的服务器,安装必要的驱动和推理框架。
c.选择推理框架:使⽤专为⽣产环境设计的框架来部署模型,例如:
◦ vLLM:特别注重⾼吞吐量的推理服务,性能极佳。
◦ TGI:Hugging Face 推出的推理框架,功能全⾯。
◦ Ollama:⾮常⽤⼾友好,可以⼀键拉取和运⾏模型,适合快速⼊⻔和本地开发。◦ LM Studio:提供图形化界⾯,让本地运⾏模型像使⽤软件⼀样简单。
d.启动服务并调用:框架会启动⼀个本地 API 服务器(如 http://localhost:8000 ),你可以像调⽤云端 API ⼀样向这个本地地址发送请求。
推荐使用Ollama,方便快捷:Ollama
在命令行上对拉取到的模型执行: ollama run (deepseek-r1:1.5b)就可以进行对话了(3)SDK接入
a.python安装所需的库,如 pip install openai
b.安装 OpenAI SDK 后,可以创建⼀个名为 example.py 的⽂件并将⽰例代码复制到其中
from openai import OpenAI client = OpenAI(api_key="your-api-key") response = client.responses.create( model="gpt-5", input="介绍⼀下你⾃⼰。" ) p rint(response.output_text)
2.6接入方式选择:

三、嵌入模型
3.1概述:
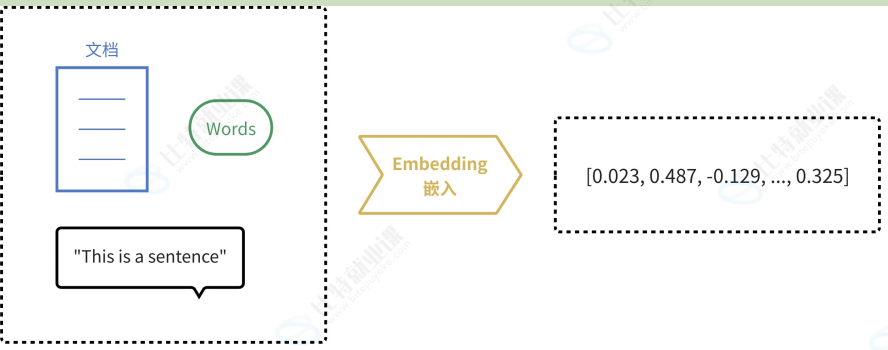
相对于大语言模型这类生成类模型来说,嵌入式模型一般是表达类模型,将用户输入生成一个最佳富含语义的数值表示,这个数值在向量空间中可以是很多维度。
3.2度量语义:
既然是数值我们就可以用数学的方式来度量语义
(1)欧式距离:利用两点间的距离远近表示语义的相近程度
(2)余弦相似度:通过点与原点形成的直线与坐标轴的夹角表示用户表达的大概含义,直线长度表示文本长度。(常用)
3.3应用场景
(1)语义搜索:传统搜索:依赖关键词匹配(搜 "苹果" ,只能找到包含 "苹果" 这个词的⽂档)语义搜索:则能将查询和⽂档都转换为向量,通过计算向量间的相似度来找到相关内容,即使⽂档中没有查询的确切词汇也能被检索到。如下图所⽰,即使知识库中并未直接出现 "笔记本电脑⽆法充电" 这个词组,语义搜索也能通过向量相似度精准地找到该⽂档。
**(2)RAG:(嵌入式 + LLM)**当前⼤语⾔模型应⽤的核⼼模式。当⽤⼾向 LLM 提问时,系统⾸先使⽤嵌⼊模型在知识库(如公司内部⽂档)中进⾏语义搜索,找到最相关的内容,然后将这些内容和问题⼀起交给 LLM 来⽣成答案。这极⼤地提⾼了答案的准确性和时效性。
(3)推荐系统:将⽤⼾(根据其历史⾏为、偏好)和物品(商品、电影、新闻)都转换为向量。喜欢相似物品的⽤⼾,其向量会接近;相似的物品,其向量也会接近。通过计算⽤⼾和物品向量的相似度,就可以进⾏精准推荐。
(4)异常检测:正常数据的向量通常会聚集在⼀起。如果⼀个新数据的向量远离⼤多数向量的聚集区,它就可能是⼀个异常点(如垃圾邮件、欺诈交易)
四、模型平台(了解)
(1)国外:Hugging Face
⼀个知名的开源库和平台,该平台以其强⼤的 Transformer 模型库和易⽤的 API ⽽闻名,为开发者和研究⼈员提供了丰富的预训练模型、⼯具和资源。对于从事 AI 研究的⼈来说,其重要性不亚于 GitHub。
https://huggingface.co/
(2)国内:魔塔社区
魔搭(ModelScope)是由阿⾥巴巴达摩院推出的开源模型即服务(MaaS)共享平台,汇聚了计算机视觉、⾃然语⾔处理、语⾳等多领域的数千个预训练 AI 模型。其核⼼理念是"开源、开放、共创",通过提供丰富的⼯具链和社区⽣态,降低 AI 开发⻔槛,尤其为企业本地私有化部署提供了⼀条⾼效路径
ModelScope 魔搭社区