📖标题:Reinforcing Chain-of-Thought Reasoning with Self-Evolving Rubrics
🌐来源:arXiv, 2602.10885v1
🌟摘要
尽管思维链(CoT)在LLM推理中起着至关重要的作用,但直接奖励它是困难的:训练奖励模型需要大量的人类标记工作,而静态RM则与不断演变的CoT分布和奖励黑客作斗争。这些挑战促使我们寻求一种不需要人类注释工作并且可以逐渐演变的自主CoT奖励方法。受最近自我进化训练方法的启发,我们提出了RLCER(Reinforce Learning with CoT监督via Self-Evolving Rubrics),它通过用自我提出和自我进化的rubrics奖励CoT来增强以结果为中心的RLVR。我们表明,即使没有结果奖励,自我提出和自我进化的rubrics也能提供可靠的CoT监督信号,使RLCER能够超越以结果为中心的RLVR。此外,当用作提示提示时,这些自行提出的规则进一步提高了推理时间性能。项目页面:https://alphalab-ustc.github.io/rlcer-alphalab/
🛎️文章简介
🔸研究问题:能否让大语言模型自主生成并持续优化用于监督思维链质量的评估规则,从而在无需人工标注的情况下提升推理能力?
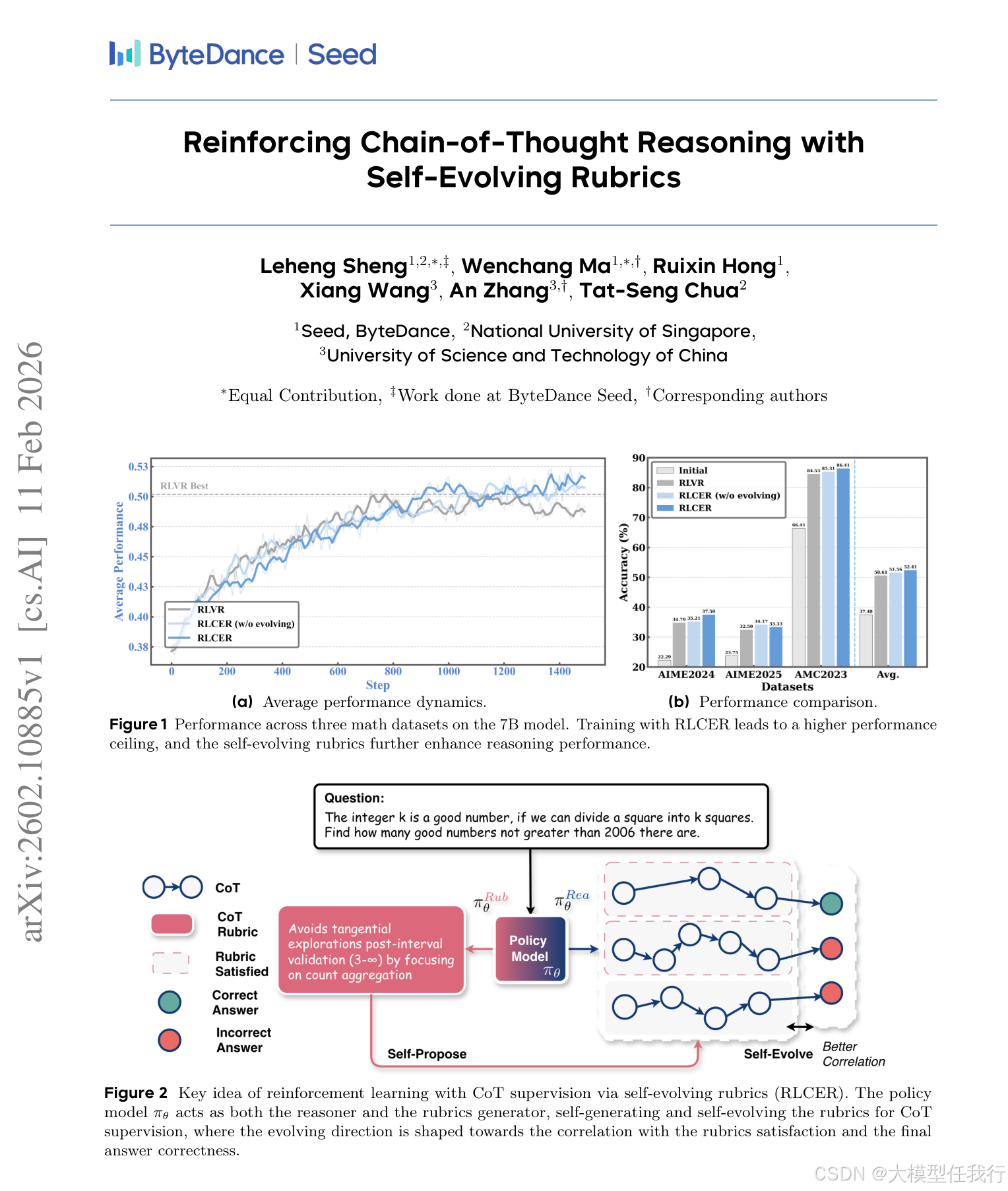
🔸主要贡献:论文提出RLCER框架,首次实现模型自我生成、自我演化自然语言规则(rubrics)以监督思维链质量,并证明其在无结果奖励时仍能提供可靠训练信号。
📝重点思路
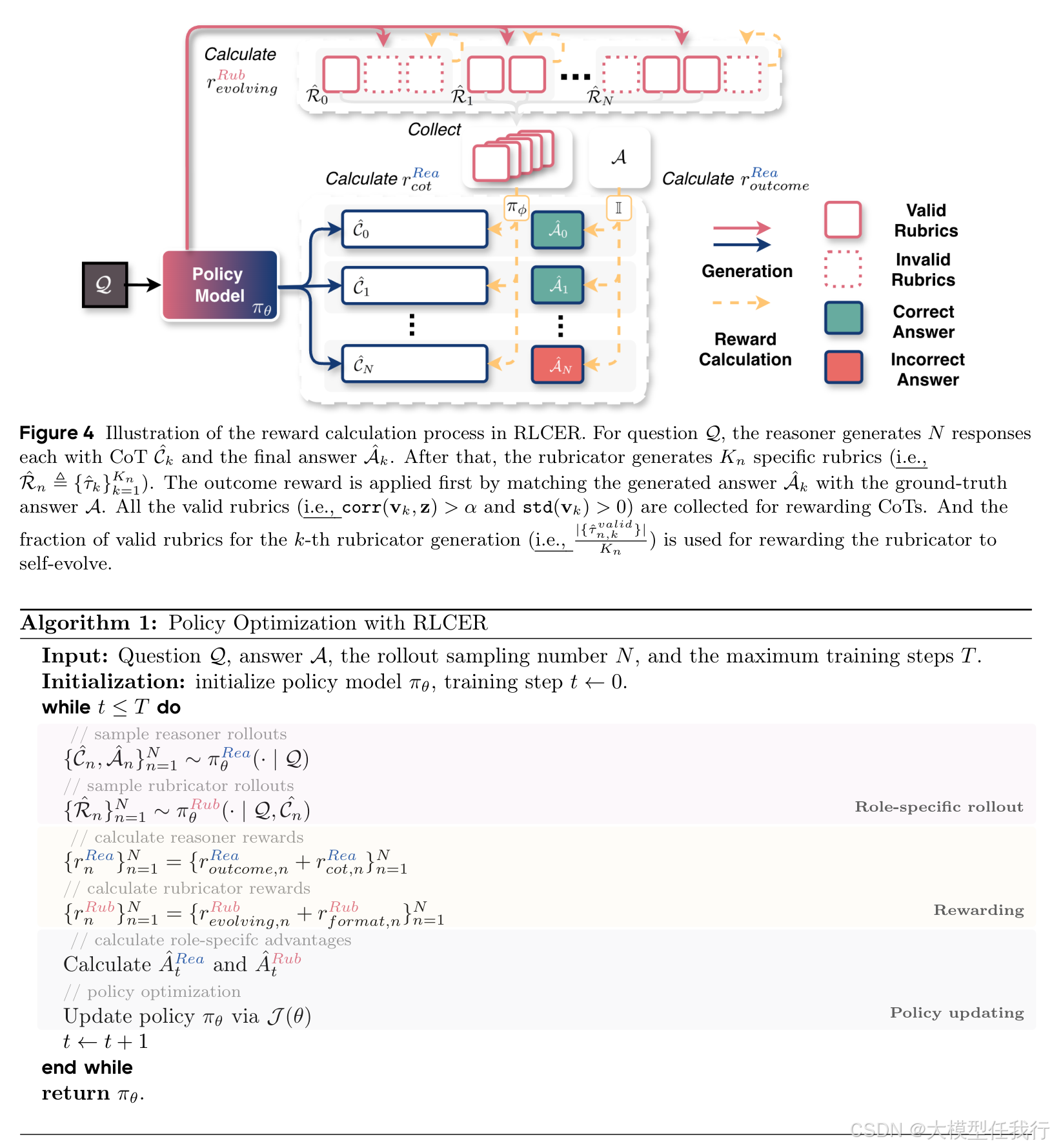
🔸设计双角色单策略架构:同一模型通过不同提示分别担任"推理者"(生成思维链与答案)和"规则师"(基于问题与思维链生成多条可验证的自然语言规则)。
🔸定义"有效规则"标准:仅当某条规则的满足程度与最终答案正确性显著正相关(corr>0.2)且在不同推理路径间具有判别力(std>0)时,才用于奖励思维链。
🔸引入规则演化机制:对规则师施加奖励,使其生成的有效规则占比越高得分越高,驱动规则随训练不断向更相关、更具挑战性的方向演化。
🔸联合优化双角色:使用角色专属优势函数,分别计算推理者与规则师的策略梯度,共享参数更新,实现协同进化。
🔸将生成规则作为推理提示:在推理阶段将训练中演化出的优质规则嵌入提示词,引导模型显式遵循高质量推理规范。
🔎分析总结
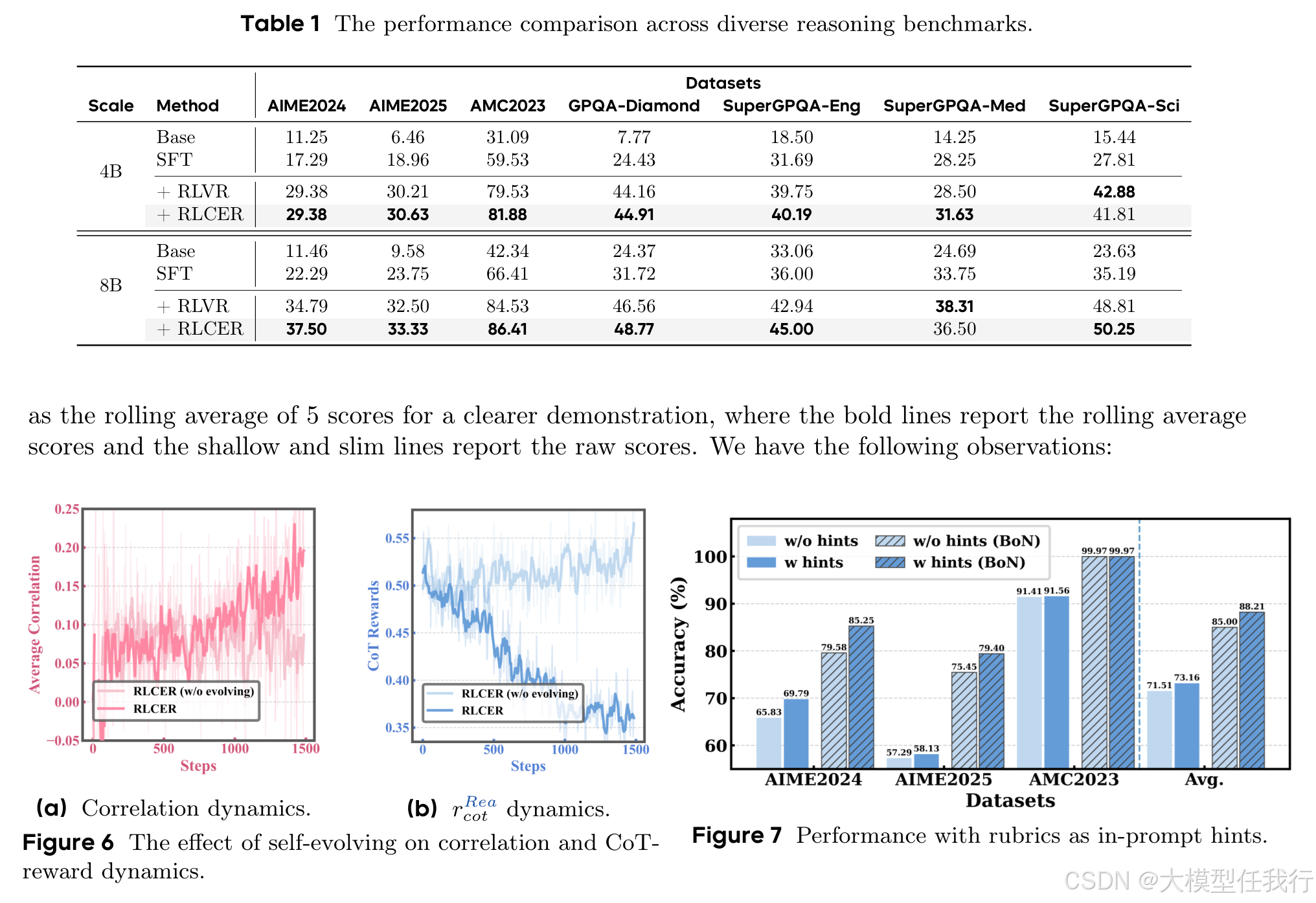
🔸仅用自生成规则奖励思维链(无结果奖励)即可稳定提升性能,证明规则本身蕴含强推理监督信号。
🔸RLCER在多个数学与通用推理基准上均超越传统结果中心型RLVR,尤其在大模型(8B)上增益更显著。
🔸规则演化使规则与答案正确性的平均相关性持续上升,而无效规则占比下降,验证演化机制有效提升规则质量。
🔸规则师奖励随训练递减,表明规则难度自然提升;而对照组规则易被饱和满足,失去判别力。
🔸将演化出的规则作为推理提示,显著提升AIME等难题上的pass@1准确率,证实规则具备可解释、可迁移的指导价值。
💡个人观点
论文将"评估标准生成"本身建模为可学习、可演化的强化学习子任务,核心洞见是高质量思维链的隐含规律可通过模型自身在分布内反复验证而浮现,突破了传统依赖静态人工规则或昂贵奖励模型的范式。
🧩附录