文章目录
Kubernetes-Pod
工作负载
工作负载(workload)是在kubernetes集群中运行的应用程序。无论你的工作负载是单一服务还是多个一 同工作的服务构成,在kubernetes中都可以使用pod来运行它
工作负载分为pod和controllers
-
pod通过控制器实现应用的运行,如何伸缩,升级等
-
controllers 在集群中管理pod
-
pod与controllers之间通过label-selector 相关联,是唯一的关联方式
在pod的yaml里指定pod标签
yaml#定义标签 labels: app: nginx在控制器的yaml里面指定标签选择器匹配标签
yaml#通过标签选择器选择对应的pod selector: matchLabels: app: nginx
Pod介绍
Pod定义和分类
官方文档:https://kubernetes.io/zh-cn/docs/concepts/workloads/pods/
Pod定义
- Pod是Kubernetes集群管理(创建、部署)与调度的最小计算单元,表示处于运行状态的一组容器
- Pod不是进程,而是容器运行的环境
- 一个Pod可以封装一个容器或多个容器(主容器或sidecar边车容器)
- 一个pod内的多个容器之间共享部分命名空间,例如:Net Namespace,UTs Namespace,IPC Namespace及存储资源
- 用户pod默认会被调度运行在node节点之上(不运行在master节点上,但也有例外情况)
- pod内的IP不是固定的,集群外不能直接访问pod
Pod分类
- 静态Pod 也被称为是"无控制器管理的自主式Pod" , 直接由特定节点上的kubelet 守护进程管理, 不需要APIServer 看到他们,尽管大多Pod都是通过控制平面的控制器( 例如,Daemonset)来管理,对于静态Pod来说,kubelet直接监控每一个Pod,并在其失效的时候重启
- 控制器管理的Pod,控制器可以控制Pod的副本数,扩容,缩容,版本的更新和回滚等
Pod查看方法
Pod是一种计算资源,可以通过kubectl get pod来查看
bash
[root@master ~ 14:46:19]# kubectl get pod
No resources found in default namespace.
[root@master ~ 14:46:29]# kubectl get pod -n kube-systemkubectl get pods也可以,不指定namespace,默认是default的namespace
Pod的YAML资源清单
先看一个yaml格式的pod定义文件解释
yaml
#yaml格式的pod定义文件完整内容:
apiVersion:v1 #必选,api版本号,例如v1
kind: Pod #必选,Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace:string #Pod所属的命名空间,默认在default的namespace
labels: #自定义标签
name: string #自定义标签名字
annotations : #自定义注释列表
name: string
spec: #必选,Pod中容器的详细定义(期望)
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 Ifnotpresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用vo1umes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort:int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量值
resources: #资源限制和请求的设置
limits: #资源限制设置
cpu: string #Cpu的限制,单位为core数,将用于docker run--cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #cpu请求,容器启动的初始可用数量
memory: string #内存清求,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpsocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpsocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always | Never | OnFailure] #pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,0nFai1ure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: object #设置NodeSelector表示将该Pod调度到包含这个1abel的node上,以key:value的格式指定
imagePullSecrets: #私有镜像仓库Pu11镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork:false #是否使用主机网络模式,默认为fa1se,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称(volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secret对象到容器内部
secretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: stringyaml格式查找帮助
bash
[root@master ~ 15:00:37]# kubectl explain pod
[root@master ~ 15:00:37]# kubectl explain pod.spec
[root@master ~ 15:00:37]# kubectl explain pod.spec.containersPod创建
命令创建Pod
创建一个名为pod-nginx的pod
bash
[root@master ~ 15:01:38]# kubectl run -h # 获取帮助
[root@master ~ 15:01:38]# kubectl run pod-nginx --image=nginx:1.26-alpine
pod/pod-nginx created
[root@master ~ 15:02:25]# kubectl get pods
NAME READY STATUS RESTARTS AGE
pod-nginx 1/1 Running 0 4sYAML创建Pod
yaml文件
bash
[root@master ~ 15:02:29]# mkdir pod_dir
[root@master ~ 15:02:29]# cd pod_dir
[root@master pod_dir 15:02:34]# vim pod1.yaml
yaml
# polinux/stress 这个镜像用于压力测试,在启动容器时传命令与参数就是相当于分配容器运行时需要的压力
apiVersion: v1 #api版本
kind: Pod #资源类型
metadata:
name: pod-stress #自定义pod名称
spec:
containers: #定义pod中包含的容器
- name: c1 #自定义pod中容器名
image: polinux/stress #启动容器的镜像名
command: ["stress"] #自定义启动容器时要执行的命令(类似dockerfile里的CMD)
args: ["--vm","1","--vm-bytes","150M","--vm-hang","1"] #自定义启动容器执行命令的参数通过yaml文件创建pod
bash
[root@master pod_dir 15:12:11]# kubectl apply -f pod1.yaml
pod/pod-stress created
[root@master pod_dir 15:12:48]# kubectl get pods
NAME READY STATUS RESTARTS AGE
pod-nginx 1/1 Running 0 10m
pod-stress 1/1 Running 0 12s
# 查看pod的详细信息
[root@master pod_dir 15:12:56]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-nginx 1/1 Running 0 11m 10.244.104.12 node2 <none> <none>
pod-stress 1/1 Running 0 73s 10.244.166.136 node1 <none> <none>查看资源占用
bash
[root@master pod_dir 15:13:57]# kubectl top pod pod-stress
NAME CPU(cores) MEMORY(bytes)
pod-stress 55m 150Mi描述pod详细信息
bash
[root@master pod_dir 15:14:32]# kubectl describe pod pod-stress
Name: pod-stress
Namespace: default
Priority: 0
Service Account: default
Node: node1/192.168.108.129
Start Time: Thu, 12 Feb 2026 15:12:44 +0800
Labels: <none>
Annotations: cni.projectcalico.org/containerID: e0491e41a709403a024d6c3d0751a4d3161cfadb4feb73145c59230e7158dd20
cni.projectcalico.org/podIP: 10.244.166.136/32
cni.projectcalico.org/podIPs: 10.244.166.136/32
Status: Running
IP: 10.244.166.136
IPs:
IP: 10.244.166.136
Containers:
c1:
Container ID: docker://e6cd8d6f2a874edd5c56b510b957af26854b7691e8da56c590643c8431af35b7
Image: polinux/stress
Image ID: docker-pullable://polinux/stress@sha256:b6144f84f9c15dac80deb48d3a646b55c7043ab1d83ea0a697c09097aaad21aa
Port: <none>
Host Port: <none>
Command:
stress
Args:
--vm
1
--vm-bytes
150M
--vm-hang
1
State: Running
Started: Thu, 12 Feb 2026 15:12:53 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-6jwc4 (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-6jwc4:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m25s default-scheduler Successfully assigned default/pod-stress to node1
Normal Pulling 2m25s kubelet Pulling image "polinux/stress"
Normal Pulled 2m16s kubelet Successfully pulled image "polinux/stress" in 8.945s (8.945s including waiting)
Normal Created 2m16s kubelet Created container c1
Normal Started 2m16s kubelet Started container c1删除Pod
单个Pod删除
在没有控制器管理的前提下可以直接删除,但是如果有控制器管理,控制器就会重新拉起pod
方法一:根据pod名称删除pod
bash
[root@master pod_dir 15:16:36]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-nginx 1/1 Running 0 14m
pod-stress 1/1 Running 0 3m56s
[root@master pod_dir 15:16:40]# kubectl delete pod pod-nginx
pod "pod-nginx" deleted
[root@master pod_dir 15:17:02]# kubectl get pods
NAME READY STATUS RESTARTS AGE
pod-stress 1/1 Running 0 4m28s方法二:通过yaml文件删除创建的pod
bash
[root@master pod_dir 15:17:12]# kubectl get pods
NAME READY STATUS RESTARTS AGE
pod-stress 1/1 Running 0 5m1s
[root@master pod_dir 15:17:45]# kubectl delete -f pod1.yaml
pod "pod-stress" deleted
[root@master pod_dir 15:18:21]# kubectl get pods
No resources found in default namespace.多个Pod删除
方法一:后面接多个pod名
bash
[root@master pod_dir 16:27:24]# kubectl run nginx1 --image=nginx:1.26-alpine
pod/nginx1 created
[root@master pod_dir 16:28:01]# kubectl run nginx2 --image=nginx:1.26-alpine
pod/nginx2 created
[root@master pod_dir 16:28:17]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx1 1/1 Running 0 34s
nginx2 1/1 Running 0 18s
[root@master pod_dir 16:28:35]# kubectl delete pod nginx1 nginx2
pod "nginx1" deleted
pod "nginx2" deleted
[root@master pod_dir 16:28:57]# kubectl get pods
No resources found in default namespace.方法二:通过awk截取要删除的pod名称(NR>1 从第2行开始取),然后管道传给xargs
bash
[root@master pod_dir 16:29:00]# kubectl run nginx1 --image=nginx:1.26-alpine
pod/nginx1 created
[root@master pod_dir 16:29:16]# kubectl run nginx2 --image=nginx:1.26-alpine
pod/nginx2 created
[root@master pod_dir 16:29:18]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx1 1/1 Running 0 9s
nginx2 1/1 Running 0 7s
[root@master pod_dir 16:29:25]# kubectl get pods | awk 'NR>1 {print $1}' | xargs kubectl delete pod
pod "nginx1" deleted
pod "nginx2" deleted
[root@master pod_dir 16:30:04]# kubectl get pods
No resources found in default namespace.方法三:如果要删除的pod都在同一个非default的命名空间,则可直接删除命令空间
bash
[root@master pod_dir 16:30:07]# kubectl create namespace game
namespace/game created
[root@master pod_dir 16:30:47]# kubectl get ns game
NAME STATUS AGE
game Active 13s
[root@master pod_dir 16:33:59]# kubectl run nginx1 --image=nginx:1.26-alpine --namespace=game
pod/nginx1 created
[root@master pod_dir 16:34:10]# kubectl run nginx2 --image=nginx:1.26-alpine --namespace=game
pod/nginx2 created
[root@master pod_dir 16:34:14]# kubectl get pods -n game
NAME READY STATUS RESTARTS AGE
nginx1 1/1 Running 0 15s
nginx2 1/1 Running 0 11s
[root@master pod_dir 16:34:25]# kubectl delete ns game
namespace "game" deleted镜像拉取策略
由imagePullPolicy参数控制
- Always:不管本地有没有镜像,都要从仓库中下载镜像
- Never:从来不从仓库下载镜像,只用本地镜像,本地没有就算了
- IfNotPresent:如果本地存在就直接使用,不存在才从仓库下载
默认的策略是:
- 当镜像标签版本是latest,默认策略就是Always
- 如果指定特定版本默认拉取策略就是IfNotPresent
将将上面的pod删除再创建,使用下面命令查看信息
bash
[root@master pod_dir 12:00:43]# kubectl apply -f pod1.yaml
pod/pod-stress created
[root@master pod_dir 12:01:16]# kubectl describe pod pod-stress
... ...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 8s default-scheduler Successfully assigned default/pod-stress to node2
Normal Pulling 7s kubelet Pulling image "polinux/stress"可以看见第二行信息还是pulling image 下载镜像
修改yaml文件
bash
[root@master pod_dir 12:02:35]# kubectl delete -f pod1.yaml
pod "pod-stress" deleted
[root@master pod_dir 12:03:13]# vim pod1.yaml
yaml
apiVersion: v1 #api版本
kind: Pod #资源类型
metadata:
name: pod-stress #自定义pod名称
spec:
containers: #定义pod中包含的容器
- name: c1 #自定义pod中容器名
image: polinux/stress #启动容器的镜像名
command: ["stress"] #自定义启动容器时要执行的命令(类似dockerfile里的CMD)
args: ["--vm","1","--vm-bytes","150M","--vm-hang","1"] #自定义启动容器执行命令的参数
imagePullPolicy: IfNotPresent #最后添加这一行再次创建
bash
[root@master pod_dir 12:05:37]# kubectl apply -f pod1.yaml
pod/pod-stress created
[root@master pod_dir 12:05:43]# kubectl describe pod pod-stress
... ...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 10s default-scheduler Successfully assigned default/pod-stress to node2
Normal Pulled 9s kubelet Container image "polinux/stress" already present on machine
Normal Created 9s kubelet Created container c1
Normal Started 9s kubelet Started container c1可以看见不是下载镜像了,直接使用本地已有的镜像进行操作
Pod标签
- 为pod设置标签label,用于控制器通过label来和pod进行关联
- 语法于前面学习node标签几乎一致
通过命令管理pod标签
查看pod标签
bash
[root@master ~ 18:47:08]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-stress 1/1 Running 0 30h <none>打标签
bash
[root@master ~ 18:48:15]# kubectl label pod pod-stress region=nanjing zone=A env=test bussiness=game
pod/pod-stress labeled
[root@master ~ 18:48:29]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-stress 1/1 Running 0 30h bussiness=game,env=test,region=nanjing,zone=A通过等值关系关系标签查询
bash
[root@master ~ 18:48:43]# kubectl get pods -l zone=A
NAME READY STATUS RESTARTS AGE
pod-stress 1/1 Running 0 30h通过集合关系标签查询
bash
[root@master ~ 18:49:48]# kubectl get pods -l "zone in (A,B,C)"
NAME READY STATUS RESTARTS AGE
pod-stress 1/1 Running 0 30h删除标签后验证
bash
[root@master ~ 18:50:24]# kubectl label pod pod-stress region- zone- env- bussiness-
pod/pod-stress unlabeled
[root@master ~ 18:51:15]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-stress 1/1 Running 0 30h <none>总结:
- pod的label与node的label操作方式几乎相同
- node的label用于pod调度到指定label的node节点
- pod的label用于controller关联控制的pod
通过yaml创建pod时添加标签
修改yaml
bash
[root@master ~ 18:51:26]# cd pod_dir/
[root@master pod_dir 18:53:07]# vim pod1.yaml
yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-stress
namespace: default
labels: #添加
env: dev #添加
app: nginx #添加
spec:
containers:
- name: c1
image: polinux/stress
command: ["stress"]
args: ["--vm","1","--vm-bytes","150M","--vm-hang","1"]
imagePullPolicy: IfNotPresent更新并验证
bash
[root@master pod_dir 18:55:24]# kubectl apply -f pod1.yaml
pod/pod-stress configured
[root@master pod_dir 18:55:41]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-stress 1/1 Running 0 30h app=nginx,env=devPod资源限制
准备2个不同限制方式,创建pod的yaml文件
bash
[root@master pod_dir 18:56:45]# vim pod2.yaml
yaml
apiVersion: v1
kind: Namespace
metadata:
name: namespace1
---
apiVersion: v1
kind: Pod
metadata:
name: pod-stress2
namespace: namespace1
spec:
containers:
- name: c1
image: polinux/stress
command: ["stress"]
args: ["--vm","1","--vm-bytes","150M","--vm-hang","1"]
imagePullPolicy: IfNotPresent
resources:
limits:
memory: "200Mi" #运行限制200M
requests:
memory: "100Mi" #启动限制100M运行验证文件
bash
[root@master pod_dir 19:01:45]# kubectl apply -f pod2.yaml
namespace/namespace1 created
pod/pod-stress2 created
[root@master pod_dir 19:05:46]# kubectl get ns
NAME STATUS AGE
default Active 34d
ingress-nginx Active 22d
kube-node-lease Active 34d
kube-public Active 34d
kube-system Active 34d
kubernetes-dashboard Active 34d
metallb-system Active 22d
monitoring Active 22d
namespace1 Active 3m59s
[root@master pod_dir 19:06:03]# kubectl get pods -n namespace1
NAME READY STATUS RESTARTS AGE
pod-stress2 1/1 Running 0 4m19s创建一个超出限额的资源文件
bash
[root@master pod_dir 19:06:12]# vim pod3.yaml
bash
apiVersion: v1
kind: Namespace
metadata:
name: namespace1
---
apiVersion: v1
kind: Pod
metadata:
name: pod-stress3 #名称更换
namespace: namespace1
spec:
containers:
- name: c1
image: polinux/stress
command: ["stress"]
args: ["--vm","1","--vm-bytes","250M","--vm-hang","1"] #超出资源限制
imagePullPolicy: IfNotPresent
resources:
limits:
memory: "200Mi"
requests:
memory: "150Mi" #启动限制改为150M运行文件
bash
[root@master pod_dir 19:12:48]# kubectl apply -f pod3.yaml
namespace/namespace1 unchanged
pod/pod-stress3 created
[root@master pod_dir 19:13:05]# kubectl get pods -n namespace1
NAME READY STATUS RESTARTS AGE
pod-stress2 1/1 Running 0 11m
pod-stress3 0/1 OOMKilled 1 (11s ago) 16s
[root@master pod_dir 19:13:50]# kubectl describe pod -n namespace1 pod-stress3
... ...
State: Terminated
Reason: OOMKilled #原因
Exit Code: 1
Started: Tue, 17 Feb 2026 19:13:48 +0800
Finished: Tue, 17 Feb 2026 19:13:48 +0800
Last State: Terminated
Reason: OOMKilled
Exit Code: 1
Started: Tue, 17 Feb 2026 19:13:19 +0800
Finished: Tue, 17 Feb 2026 19:13:19 +0800
Ready: False
... ...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 52s default-scheduler Successfully assigned namespace1/pod-stress3 to node1
Normal Pulled 3s (x4 over 51s) kubelet Container image "polinux/stress" already present on machine
Normal Created 3s (x4 over 51s) kubelet Created container c1
Normal Started 2s (x4 over 51s) kubelet Started container c1
Warning BackOff 2s (x4 over 44s) kubelet Back-off restarting failed container c1 in pod pod-stress3_namespace1(41087033-5b23-413a-9bb0-5a2b94e883aa)一旦pod中的容器挂了,容器会有重启策略,如下:
- Always:表示容器挂了总是重启,这是默认策略
- OnFailures:表容器状态为错误时才重启,也就是容器正常终止时不会重启
- Never:表示容器挂了不予重启
对于Always这种策略,容器只要挂了,就会立即重启,这样是很耗费资源的。所以Always重启策略是这么做的:第一次容器挂了立即重启,如果再挂了就要延时10s重启,第三次挂了就等20s重启。依次类推
删除资源
bash
[root@master pod_dir 19:15:35]# kubectl delete ns namespace1
namespace "namespace1" deletedPod包含多容器
在yaml的pod中声明两个容器
bash
[root@master pod_dir 19:16:23]# vim pod4.yaml
yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-stress4
namespace: default
labels:
env: dev
app: nginx
spec:
containers:
- name: c1
image: polinux/stress
command: ["stress"]
args: ["--vm","1","--vm-bytes","150M","--vm-hang","1"]
imagePullPolicy: IfNotPresent
# 添加以下内容
- name: c2
image: polinux/stress
command: ["stress"]
args: ["--vm","1","--vm-bytes","150M","--vm-hang","1"]
imagePullPolicy: IfNotPresent启动并验证
bash
[root@master pod_dir 20:54:20]# kubectl apply -f pod4.yaml
pod/pod-stress4 created
[root@master pod_dir 20:54:37]# kubectl get pods
NAME READY STATUS RESTARTS AGE
pod-stress4 2/2 Running 0 5s
# 查看pod的节点分布
[root@master pod_dir 20:54:42]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-stress4 2/2 Running 0 32s 10.244.104.20 node2 <none> <none>在node2中验证,产生了2个容器
bash
[root@node2 ~ 20:55:39]# docker ps -a | grep stress
0833bc375567 df58d15b053d "stress --vm 1 --vm-..." About a minute ago Up About a minute k8s_c2_pod-stress4_default_adc4aaf4-5083-47cd-b5de-73871fb22638_0
c120dcc240f8 df58d15b053d "stress --vm 1 --vm-..." About a minute ago Up About a minute k8s_c1_pod-stress4_default_adc4aaf4-5083-47cd-b5de-73871fb22638_0
e0c2b2c49c5d registry.aliyuncs.com/google_containers/pause:3.9 "/pause" About a minute ago Up About a minute k8s_POD_pod-stress4_default_adc4aaf4-5083-47cd-b5de-73871fb22638_0如果使用的是containerd运行时,则使用以下命令来查看
bashcrictl ps
对Pod中容器进行操作
命令帮助
bash
kubectl exec -h非交互直接执行命令
bash
kubectl exec pod_name -c container_name -- command-c容器名 为可选项,如果pod中只有1个容器则不用指定- 如果是1个pod中有多个容器,不指定默认为指定第1个容器
bash
# 默认命名空间
[root@master pod_dir 20:59:51]# kubectl exec pod-stress4 -- date
Defaulted container "c1" out of: c1, c2
Tue Feb 17 13:00:27 UTC 2026
# 其他命名空间
[root@master pod_dir 21:00:27]# kubectl exec pods/pod-stress -n web-test -- date
# 指定特定容器
[root@master pod_dir 21:02:21]# kubectl exec pod-stress4 -c c1 -- date
Tue Feb 17 13:03:02 UTC 2026
[root@master pod_dir 21:03:02]# kubectl exec pod-stress4 -c c2 -- date
Tue Feb 17 13:03:06 UTC 2026不指定容器名,则默认为pod里的第1个容器
bash
[root@master pod_dir 21:03:06]# kubectl exec pod-stress4 -- touch /abc.txt
Defaulted container "c1" out of: c1, c2交互容器操作
和docker exec几乎一样,会发现刚才创建的abc.txt文件
bash
[root@master pod_dir 21:04:00]# kubectl exec -it pod-stress4 -c c1 -- /bin/bash
# 或者使用`kubectl exec -it pod-stress4 -c c1 -- /bin/sh`
bash-5.0# ls /
abc.txt dev home media opt root sbin sys usr
bin etc lib mnt proc run srv tmp var
bash-5.0# exit
exit同一个pod中两个容器IP地址相同,是共享的10.244.104.20/32
bash
[root@master pod_dir 21:06:22]# kubectl exec -it pod-stress4 -c c1 -- /bin/bash
bash-5.0# ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if147: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1480 qdisc noqueue state UP
link/ether ee:7b:b0:68:27:c3 brd ff:ff:ff:ff:ff:ff
inet 10.244.104.20/32 scope global eth0 `看这里`
valid_lft forever preferred_lft forever
inet6 fe80::ec7b:b0ff:fe68:27c3/64 scope link
valid_lft forever preferred_lft forever
bash
[root@master pod_dir 21:08:00]# kubectl exec -it pod-stress4 -c c2 -- /bin/bash
bash-5.0# ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if147: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1480 qdisc noqueue state UP
link/ether ee:7b:b0:68:27:c3 brd ff:ff:ff:ff:ff:ff
inet 10.244.104.20/32 scope global eth0 `看这里`
valid_lft forever preferred_lft forever
inet6 fe80::ec7b:b0ff:fe68:27c3/64 scope link
valid_lft forever preferred_lft forever验证Pod中容器间网络共享
编写yaml
bash
[root@master pod_dir 21:09:15]# vim pod-nginx.yaml
yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: c1
image: nginx:1.26-alpine
- name: c2
image: nginx:1.26-alpine应用并验证pod信息
bash
[root@master pod_dir 21:12:51]# kubectl apply -f pod-nginx.yaml
pod/nginx created
[root@master pod_dir 21:13:19]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 2/2 Running 1 (4s ago) 9s
[root@master pod_dir 21:13:28]# kubectl describe pod nginx
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 24s default-scheduler Successfully assigned default/nginx to node2
Normal Pulled 22s kubelet Container image "nginx:1.26-alpine" already present on machine
Normal Created 22s kubelet Created container c1
Normal Started 22s kubelet Started container c1
Warning BackOff 14s kubelet Back-off restarting failed container c2 in pod nginx_default(0929cf6c-9749-46da-8ddb-a19970b9790e)
Normal Pulled 2s (x3 over 22s) kubelet Container image "nginx:1.26-alpine" already present on machine
Normal Created 2s (x3 over 22s) kubelet Created container c2
Normal Started 1s (x3 over 22s) kubelet Started container c2发现有一个容器启动失败,主要原因是在同一个网络环境中两个nginx都是用的80端口产生冲突
bash
[root@master pod_dir 21:13:43]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/2 CrashLoopBackOff 4 (18s ago) 119s 10.244.104.21 node2 <none> <none>在node2节点中查看
bash
[root@node2 ~ 21:16:48]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a1cd273869dc 42ce3d3585d4 "/docker-entrypoint...." 21 seconds ago Exited (1) 17 seconds ago k8s_c2_nginx_default_0929cf6c-9749-46da-8ddb-a19970b9790e_5
1e05151ebc0f 42ce3d3585d4 "/docker-entrypoint...." 3 minutes ago Up 3 minutes k8s_c1_nginx_default_0929cf6c-9749-46da-8ddb-a19970b9790e_0查看启动失败容器日志
bash
[root@node2 ~ 21:18:26]# docker logs k8s_c2_nginx_default_0929cf6c-9749-46da-8ddb-a19970b9790e_5
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Sourcing /docker-entrypoint.d/15-local-resolvers.envsh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
2026/02/17 13:16:33 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use)
nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use)
2026/02/17 13:16:33 [emerg] 1#1: bind() to [::]:80 failed (98: Address in use)
nginx: [emerg] bind() to [::]:80 failed (98: Address in use)
2026/02/17 13:16:33 [notice] 1#1: try again to bind() after 500ms
2026/02/17 13:16:33 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use)
nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use)
2026/02/17 13:16:33 [emerg] 1#1: bind() to [::]:80 failed (98: Address in use)
nginx: [emerg] bind() to [::]:80 failed (98: Address in use)
2026/02/17 13:16:33 [notice] 1#1: try again to bind() after 500ms
2026/02/17 13:16:33 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use)
nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use)
2026/02/17 13:16:33 [emerg] 1#1: bind() to [::]:80 failed (98: Address in use)
nginx: [emerg] bind() to [::]:80 failed (98: Address in use)
2026/02/17 13:16:33 [notice] 1#1: try again to bind() after 500ms
2026/02/17 13:16:33 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use)
nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use)
2026/02/17 13:16:33 [emerg] 1#1: bind() to [::]:80 failed (98: Address in use)
nginx: [emerg] bind() to [::]:80 failed (98: Address in use)
2026/02/17 13:16:33 [notice] 1#1: try again to bind() after 500ms
2026/02/17 13:16:33 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use)
nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use)
2026/02/17 13:16:33 [emerg] 1#1: bind() to [::]:80 failed (98: Address in use)
nginx: [emerg] bind() to [::]:80 failed (98: Address in use)
2026/02/17 13:16:33 [notice] 1#1: try again to bind() after 500ms
2026/02/17 13:16:33 [emerg] 1#1: still could not bind()
nginx: [emerg] still could not bind()Pod调度
调度流程
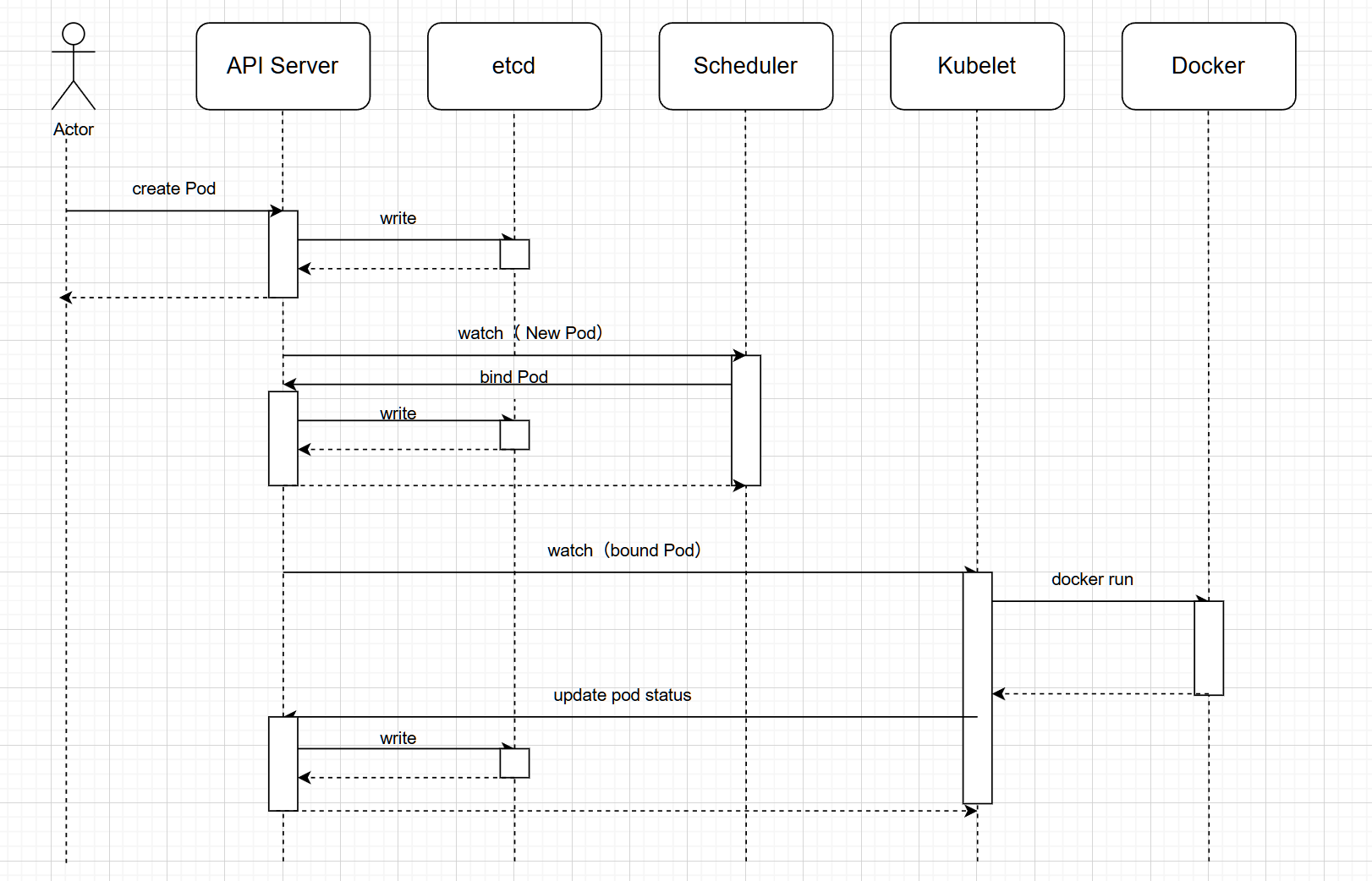
- 通过kubect1命令应用资源清单文件(yaml格式)向api server 发起一个create pod 请求
- api server接收到pod创建请求后,生成一个包含创建信息资源清单文件,api server 将资源清单文件中信息写入etcd数据库
- scheduler启动后会一直watch API server,获取 podspec.NodeName为空的Pod,即判断pod.spec.Node == null,若为null,表示这个Pod请求是新的,需要创建,因此先进行调度计算(共计2步:1、过滤不满足条件的,2、选择优先级高的),然后将信息在etcd数据库中更新,分配结果:pod.spec.Node=nodeA(设置一个具体的节点)
- Kubelet 通过watch etcd数据库(即不停地看etcd中的记录),发现有新的Node出现,如果这条记录中的Node与所在节点编号相同,即这个Pod由scheduler分配给自己,则调用node中的container Runtime, 进而创建container,并将创建后的结果返回到给api server用于更新etcd数据库中数据状态
可以发现每做一步,api Server都需要写入etcd,所以etcd是非常重要的组件,是k8s集群的大脑,etcd若损坏,集群基本废了
调度约束方法
我们为了实现容器主机资源平衡使用,可以使用约束把pod调度到指定的node节点
- nodeName用于将pod调度到指定的node名称上
- nodeSelector用于将pod调度到匹配Label的node上
nodeName
使用nodeName指定节点,不调用scheduler组件资源
编写yaml
bash
[root@master pod_dir 21:51:04]# vim pod-nodename.yaml
yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodename
spec:
nodeName: node2 #直接指向节点名称
containers:
- name: nginx
image: nginx:1.26-alpine应用并验证
bash
[root@master pod_dir 21:52:45]# kubectl apply -f pod-nodename.yaml
pod/pod-nodename created
[root@master pod_dir 21:53:11]# kubectl describe pod pod-nodename | tail -10
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulled 23s kubelet Container image "nginx:1.26-alpine" already present on machine
Normal Created 23s kubelet Created container nginx
Normal Started 22s kubelet Started container nginx可以看见没有使用scheduler,而是直接给运行了,说明nodeName约束生效
bash
[root@master pod_dir 21:54:40]# kubectl get pod -o wide | grep pod-nodename
pod-nodename 1/1 Running 0 105s 10.244.104.22 node2 <none> <none>nodeSelector
该参数需要调用scheduler组件资源,通过标签来选举对应节点
这里我们给node1 节点打上标签 ,为game
bash
[root@master pod_dir 21:56:35]# kubectl label nodes node1 bussiness=game
node/node1 labeled编写yaml文件
bash
[root@master pod_dir 21:56:53]# vim pod-nodeselector.yaml
yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeselect
spec:
nodeSelector:
bussiness: game # 名称匹配
containers:
- name: nginx
image: nginx:1.26-alpine应用并验证
bash
[root@master pod_dir 21:59:33]# kubectl apply -f pod-nodeselector.yaml
pod/pod-nodeselect created
[root@master pod_dir 21:59:47]# kubectl describe pod pod-nodeselect | tail -10
Node-Selectors: bussiness=game
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 32s default-scheduler Successfully assigned default/pod-nodeselect to node1
Normal Pulled 30s kubelet Container image "nginx:1.26-alpine" already present on machine
Normal Created 30s kubelet Created container nginx
Normal Started 30s kubelet Started container nginx发现,经过了scheduler,分配在node1 节点上
Pod生命周期
Pod 遵循预定义的生命周期,起始于 Pending (悬决)阶段, 如果至少其中有一个主要容器正常启动,则进入 Running,之后取决于 Pod 中是否有容器以失败状态结束而进入 Succeeded 或者 Failed 阶段
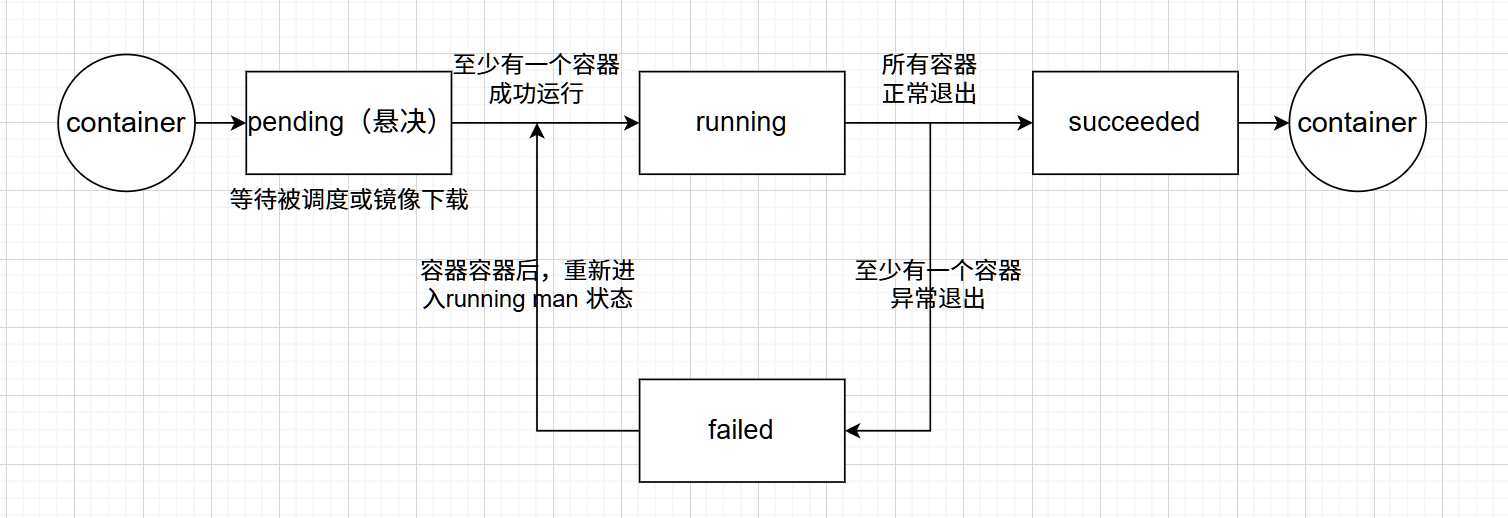
Pod生命周期
- 有些pod(比如运行httpd服务),正常情况下会一直运行中,但如果手动删除它,此pod会终止
- 有些pod(比如执行计算任务),任务计算完后就会自动终止
所以,pod从创建到终止的过程就是pod的生命周期
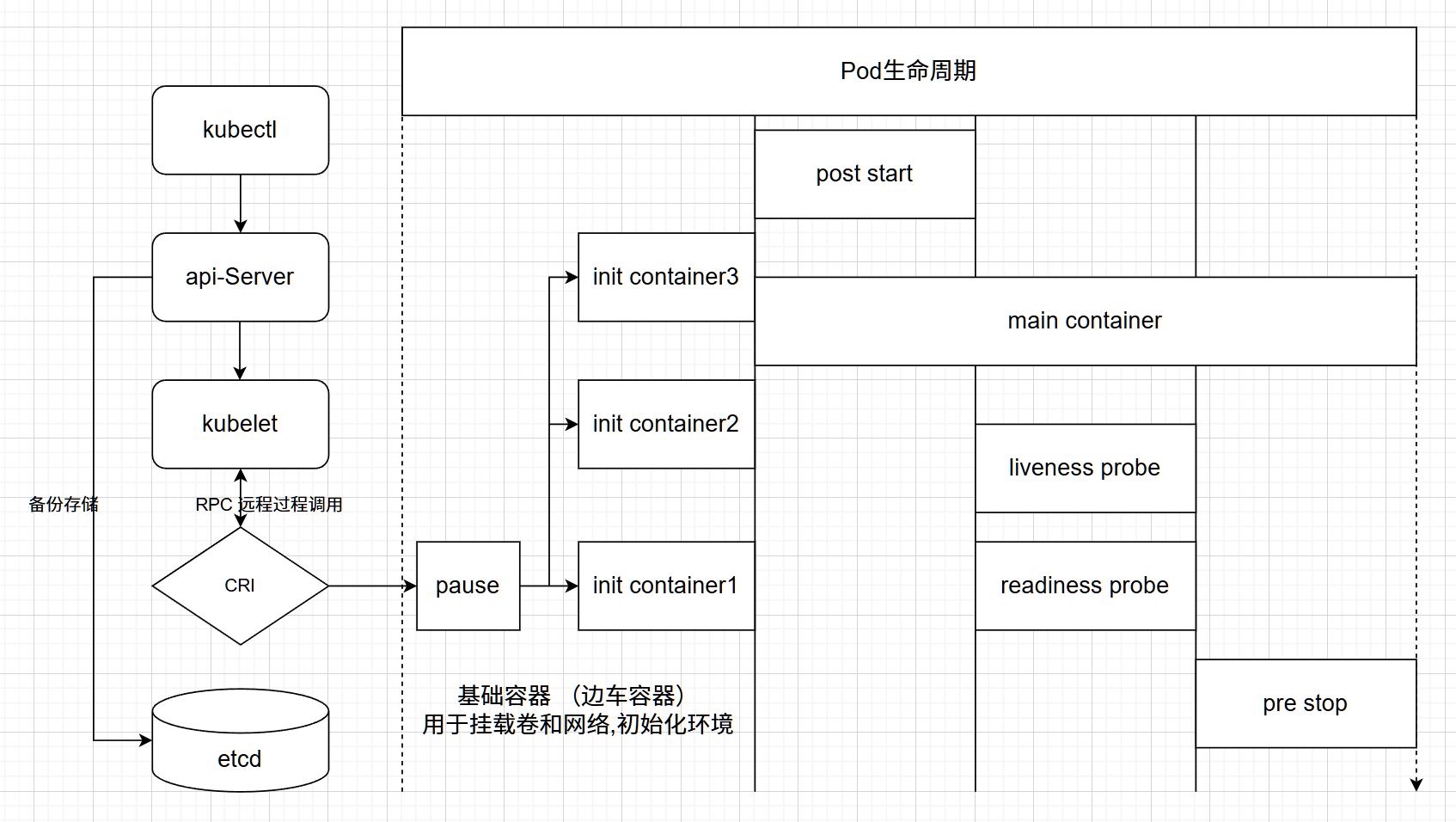
容器启动
- pod中的容器在创建前,有初始化容器(init container)来进行初始化环境
- 初化完后,主容器(main container)开始启动
- 主容器启动后,有一个post start的操作(启动后的触发型操作,或者叫启动后钩子)
- post start后,就开始做健康检查
- 第一个健康检查叫存活状态检查(liveness probe),用来检查主容器存活状态的
- 第二个健康检查叫准备就绪检查(readiness probe),用来检查主容器是否启动就绪
容器终止
- 可以在容器终止前设置pre stop操作(终止前的触发型操作,或者叫终止前钩子)
- 当出现特殊情况不能正常销毁pod时,大概等待30秒会强制终止
- 终止容器后还可能会重启容器(视容器重启策略而定)
容器重启策略
- Always:表示容器挂了总是重启,这是默认策略
- OnFailures:表容器状态为错误时才重启,也就是容器正常终止时不重启
- Never:表示容器挂了不予重启
对于Always这种策略,容器只要挂了,就会立即重启,这样是很耗费资源的。所以Always重启策 略是这么做的:第一次容器挂了立即重启,如果再挂了就要延时10s重启,第三次挂了就等20s重启... 依次类推
HealthCheck健康检查
当Pod启动时,容器可能因为某种错误(服务未启动或端口不正确)而无法访问等
HealthCheck方式
kubelet拥有两个检测器,它们分别对应不同的触发器(根据触发器的结构执行进一步的动作)
| 方式 | 说明 |
|---|---|
| livenessProbe(存活状态探测) | 指示容器是否正在运行。如果存活态探测失败,则 kubelet 会杀死容器,并且容器将根据其重启策略决定未来。 如果容器不提供存活探针,则默认状态为 success |
| readinessProbe(就绪状态探测) | 指示容器是否准备好为请求提供服务。如果就绪态探测失败,端点控制器将从与Pod 匹配的所有服务的端点列表中删除该Pod 的IP地址。 初始延迟之前的就绪态的状态值默认为 Failure。 如果容器不提供就绪态探针,则默认状态为success。 注意:检查后不健康,将容器设置为Noready;如果使用service来访问,流量不会转发给此种状态的pod |
| startupProbe | 指示容器中的应用是否已经启动。如果提供了启动探针,则所有其他探针都会被禁用,直到此探针成功为止。如果启动探测失败,kubelet将杀死容器,而容器依据重启策略进行重启。如果容器没有提供启动探测,则默认状态为success。 |
Probe探测方式
| 方式 | 说明 |
|---|---|
| exec | 执行命令 |
| httpGet | http请求某一个URL路径,查看返回状态码(200为成功,403为服务器拒绝执行请求,404为网页找不到) |
| tcpSocket | tcp连接某一个端口 |
| gRPC | 使用gRPC执行一个远程过程调用。目标应该实现gRPC健康检查。如果响应的状态是 "SERVING",则认为诊断成功。gRPC探针是一个alpha特性,只有在你启动了"GRPC ContainerProbe"特性门控时才能使用 |
liveness-exec案例
准备yaml
bash
[root@master pod_dir 18:21:13]# cat pod-liveness-exec.yaml
yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec
namespace: default
spec:
containers:
- name: liveness
image: busybox
imagePullPolicy: IfNotPresent
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5 # pod启动延迟5秒后探测
periodSeconds: 5 # 每5秒探测1次应用yaml
bash
[root@master pod_dir 18:23:20]# kubectl apply -f pod-liveness-exec.yaml
pod/liveness-exec created通过下面的命令观察
bash
[root@master pod_dir 18:23:29]# kubectl describe pod liveness-exec
... ...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 32s default-scheduler Successfully assigned default/liveness-exec to node2
Normal Pulled 31s kubelet Container image "busybox" already present on machine
Normal Created 31s kubelet Created container liveness
Normal Started 31s kubelet Started container liveness过几分钟再观察
bash
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m25s default-scheduler Successfully assigned default/liveness-exec to node2
Normal Pulled 69s (x2 over 2m24s) kubelet Container image "busybox" already present on machine
Normal Created 69s (x2 over 2m24s) kubelet Created container liveness
Normal Started 69s (x2 over 2m24s) kubelet Started container liveness
Warning Unhealthy 24s (x6 over 109s) kubelet Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
Normal Killing 24s (x2 over 99s) kubelet Container liveness failed liveness probe, will be restarted容器被探针检测失败又会被重新拉起,注意看RESTARTS
bash
[root@master pod_dir 18:25:54]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 2 (22s ago) 2m53s扩展:容器重启策略验证
bash
[root@master pod_dir 18:30:44]# kubectl delete -f pod-liveness-exec.yaml
pod "liveness-exec" deleted
[root@master pod_dir 18:31:36]# vim pod-liveness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec
namespace: default
spec:
restartPolicy: Never
containers:
- name: liveness
image: busybox
imagePullPolicy: IfNotPresent
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
[root@master pod_dir 18:35:29]# kubectl apply -f pod-liveness-exec.yaml
pod/liveness-exec created验证,结果为:容器健康检查出现问题后,不再重启,也不会继续sleep 600秒,而是直接关闭了
bash
[root@master pod_dir 18:36:29]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 0 53s
[root@master pod_dir 18:36:30]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-exec 0/1 Error 0 83s当容器容器健康检查出现问题后,不再重启,pod的状态为error
liveness-httpget案例
编写yaml
bash
[root@master pod_dir 18:42:13]# vim pod-live-httpget.yaml
yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget
namespace: default
spec:
containers:
- name: liveness
image: nginx:1.26-alpine
imagePullPolicy: IfNotPresent
ports: #指定容器端口,这一行不写也行,端口由镜像决定
- name: http #自定义名称,不需要与下面的port:http对应
containerPort: 80 #类似dockerfile里的expose 80
livenessProbe:
httpGet: #使用httpGet方式
port: http #http协议,也可以直接写80端口
path: /index.html #探测家目录下的index.html
initialDelaySeconds: 3 #延迟3秒开始探测
periodSeconds: 5 #每个5s探测一次应用yaml并验证
bash
[root@master pod_dir 18:43:50]# kubectl delete -f pod-liveness-exec.yaml
pod "liveness-exec" deleted
[root@master pod_dir 18:43:09]# kubectl apply -f pod-live-httpget.yaml
pod/liveness-httpget created
[root@master pod_dir 18:43:28]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-httpget 1/1 Running 0 22s
# 交互删除nginx的主页文件
[root@master pod_dir 18:44:04]# kubectl exec -it liveness-httpget -- rm -rf /usr/share/nginx/html/index.html
[root@master pod_dir 18:45:25]# kubectl describe pod liveness-httpget | tail -10
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m38s default-scheduler Successfully assigned default/liveness-httpget to node2
Normal Pulled 27s (x2 over 2m37s) kubelet Container image "nginx:1.26-alpine" already present on machine
Normal Created 27s (x2 over 2m37s) kubelet Created container liveness
Normal Started 27s (x2 over 2m37s) kubelet Started container liveness
Warning Unhealthy 27s (x3 over 37s) kubelet Liveness probe failed: HTTP probe failed with statuscode: 404
Normal Killing 27s kubelet Container liveness failed liveness probe, will be restarted
# 重新启动了
[root@master pod_dir 18:46:34]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-httpget 1/1 Running 1 (57s ago) 3m8sliveness-tcp案例
编写yaml
bash
[root@master pod_dir 18:50:42]# cat pod-live-tcp.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-tcp
namespace: default
spec:
containers:
- name: liveness
image: nginx:1.26-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 82 #容器端口
name: http
livenessProbe:
tcpSocket: #使用tcp连接方式
port: 80 #连接pod的80端口进行探测,跟容器端口无关
initialDelaySeconds: 3
periodSeconds: 5应用yaml并验证
bash
[root@master pod_dir 18:51:37]# kubectl delete -f pod-live-httpget.yaml
pod "liveness-httpget" deleted
[root@master pod_dir 18:51:32]# kubectl apply -f pod-live-tcp.yaml
pod/liveness-tcp created
[root@master pod_dir 18:51:47]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-tcp 1/1 Running 0 32s
# 交互关闭nginx
[root@master pod_dir 18:52:09]# kubectl exec -it liveness-tcp -- /usr/sbin/nginx -s stop
2026/02/21 10:53:13 [notice] 33#33: signal process started
# 再次验证查看
[root@master pod_dir 19:05:45]# kubectl describe pod liveness-tcp
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 9m30s default-scheduler Successfully assigned default/liveness-tcp to node2
Normal Pulled 9m9s (x2 over 9m29s) kubelet Container image "nginx:1.26-alpine" already present on machine
Normal Created 9m9s (x2 over 9m29s) kubelet Created container liveness
Normal Started 9m9s (x2 over 9m29s) kubelet Started container liveness
Warning Unhealthy 40s kubelet Liveness probe failed: dial tcp 10.244.104.24:80: connect: connection refused
[root@master pod_dir 19:05:21]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-tcp 1/1 Running 1 (8m44s ago) 9m5sreadness-httpget案例
编写yaml文件
bash
[root@master pod_dir 19:11:06]# cat pod-read-http.yaml
apiVersion: v1
kind: Pod
metadata:
name: readiness-httpget
namespace: default
spec:
containers:
- name: readiness
image: nginx:1.26-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: http
readinessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 3
periodSeconds: 5应用yaml
bash
[root@master pod_dir 19:11:31]# kubectl apply -f pod-read-http.yaml
pod/readiness-httpget created
[root@master pod_dir 19:11:48]# kubectl get pods
NAME READY STATUS RESTARTS AGE
readiness-httpget 1/1 Running 0 13s
# 交互删除nginx主页
[root@master pod_dir 19:11:50]# kubectl exec -it readiness-httpget -- rm -rf /usr/share/nginx/html/index.html
# 再次验证
[root@master pod_dir 19:13:07]# kubectl describe pod readiness-httpget | tail -10
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m2s default-scheduler Successfully assigned default/readiness-httpget to node2
Normal Pulled 2m1s kubelet Container image "nginx:1.26-alpine" already present on machine
Normal Created 2m1s kubelet Created container readiness
Normal Started 2m1s kubelet Started container readiness
Warning Unhealthy 1s (x8 over 31s) kubelet Readiness probe failed: HTTP probe failed with statuscode: 404
[root@master pod_dir 19:13:39]# kubectl get pods
NAME READY STATUS RESTARTS AGE
readiness-httpget 0/1 Running 0 2m17s
# 恢复删除的文件
[root@master pod_dir 19:13:54]# kubectl exec -it readiness-httpget -- touch /usr/share/nginx/html/index.html
[root@master pod_dir 19:14:35]# kubectl get pods
NAME READY STATUS RESTARTS AGE
readiness-httpget 1/1 Running 0 3m3sreadiness会把pod标记为noready状态,直到文件恢复,才会正常
liveness-readiness综合案例
编写yaml
bash
[root@master pod_dir 19:39:55]# cat live-read.yaml
apiVersion: v1
kind: Pod
metadata:
name: live-read
spec:
restartPolicy: Never
containers:
- name: c1
imagePullPolicy: IfNotPresent
image: nginx:1.26-alpine
ports:
- containerPort: 80
name: http
# 存活探针
livenessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
# 就绪探针
readinessProbe:
httpGet:
port: http
path: /login.html
initialDelaySeconds: 5
periodSeconds: 5应用yaml并验证
bash
[root@master pod_dir 19:40:28]# kubectl apply -f live-read.yaml
pod/live-read created
# pod正常运行,但是没有就绪
[root@master pod_dir 19:40:40]# kubectl get pods
NAME READY STATUS RESTARTS AGE
live-read 0/1 Running 0 8s
# 创建登陆login文件
[root@master pod_dir 19:40:55]# kubectl exec -it live-read -- touch /usr/share/nginx/html/login.html
[root@master pod_dir 19:51:36]# kubectl get pods
NAME READY STATUS RESTARTS AGE
live-read 1/1 Running 0 11mpost-start
启动时钩子:启动资源时容器执行的操作
编写yaml文件
bash
[root@master pod_dir 19:56:21]# cat post-start.yaml
apiVersion: v1
kind: Pod
metadata:
name: poststart
namespace: default
spec:
containers:
- name: c1
image: nginx:1.26-alpine
imagePullPolicy: IfNotPresent
lifecycle:
postStart:
exec:
command: ['mkdir','-p','/usr/share/nginx/html/adc']应用yaml并验证
bash
[root@master pod_dir 19:57:09]# kubectl apply -f post-start.yaml
pod/poststart created
[root@master pod_dir 19:57:27]# kubectl get pods
NAME READY STATUS RESTARTS AGE
poststart 1/1 Running 0 13s
[root@master pod_dir 19:57:30]# kubectl exec -it poststart -- ls -l /usr/share/nginx/html
total 8
-rw-r--r-- 1 root root 497 Feb 5 2025 50x.html
drwxr-xr-x 2 root root 6 Feb 21 11:57 adc
-rw-r--r-- 1 root root 615 Feb 5 2025 index.htmlpre-stop
终止时钩子:容器终止前执行的命令
编写yaml
bash
[root@master pod_dir 20:00:15]# cat pre-stop.yaml
apiVersion: v1
kind: Pod
metadata:
name: prestop
namespace: default
spec:
containers:
- name: c1
image: nginx:1.26-alpine
imagePullPolicy: IfNotPresent
lifecycle:
preStop:
exec:
command: ["/bin/sh","-c","sleep 60000"]应用yaml并验证
bash
[root@master pod_dir 20:00:55]# kubectl apply -f pre-stop.yaml
pod/prestop created
[root@master pod_dir 20:01:01]# kubectl get pods
NAME READY STATUS RESTARTS AGE
prestop 1/1 Running 0 7s
# 删除pod验证
[root@master pod_dir 20:01:08]# kubectl delete -f pre-stop.yaml
pod "prestop" deleted
# 会在这一步等待一定时间才能删除,说明验证成功结论:当出现特殊情况不能正常销毁pod时,大概等待30秒会强制终止