

AI的提示词专栏:用 Prompt 生成正则表达式进行文本匹配
本文围绕 "用 Prompt 生成正则表达式" 展开,先阐述二者结合的价值,即降低正则使用门槛、提升效率并适配灵活场景;接着介绍正则核心基础,为精准描述 Prompt 打基础;随后详解 Prompt 设计的三大原则与四段式结构,确保模型生成精准正则;还通过匹配固定电话、提取 URL 域名等 5 个高频场景,提供完整 Prompt 示例、模型输出及验证分析;最后梳理常见问题与解决方案,并给出总结与扩展学习建议,整体为读者提供从需求描述到工具落地的完整指南,助力高效解决文本匹配问题。

人工智能专栏介绍
人工智能学习合集专栏是 AI 学习者的实用工具。它像一个全面的 AI 知识库,把提示词设计、AI 创作、智能绘图等多个细分领域的知识整合起来。无论你是刚接触 AI 的新手,还是有一定基础想提升的人,都能在这里找到合适的内容。从最基础的工具操作方法,到背后深层的技术原理,专栏都有讲解,还搭配了实例教程和实战案例。这些内容能帮助学习者一步步搭建完整的 AI 知识体系,让大家快速从入门进步到精通,更好地应对学习和工作中遇到的 AI 相关问题。

这个系列专栏能教会人们很多实用的 AI 技能。在提示词方面,能让人学会设计精准的提示词,用不同行业的模板高效和 AI 沟通。写作上,掌握从选题到成稿的全流程技巧,用 AI 辅助写出高质量文本。编程时,借助 AI 完成代码编写、调试等工作,提升开发速度。绘图领域,学会用 AI 生成符合需求的设计图和图表。此外,还能了解主流 AI 工具的用法,学会搭建简单智能体,掌握大模型的部署和应用开发等技能,覆盖多个场景,满足不同学习者的需求。

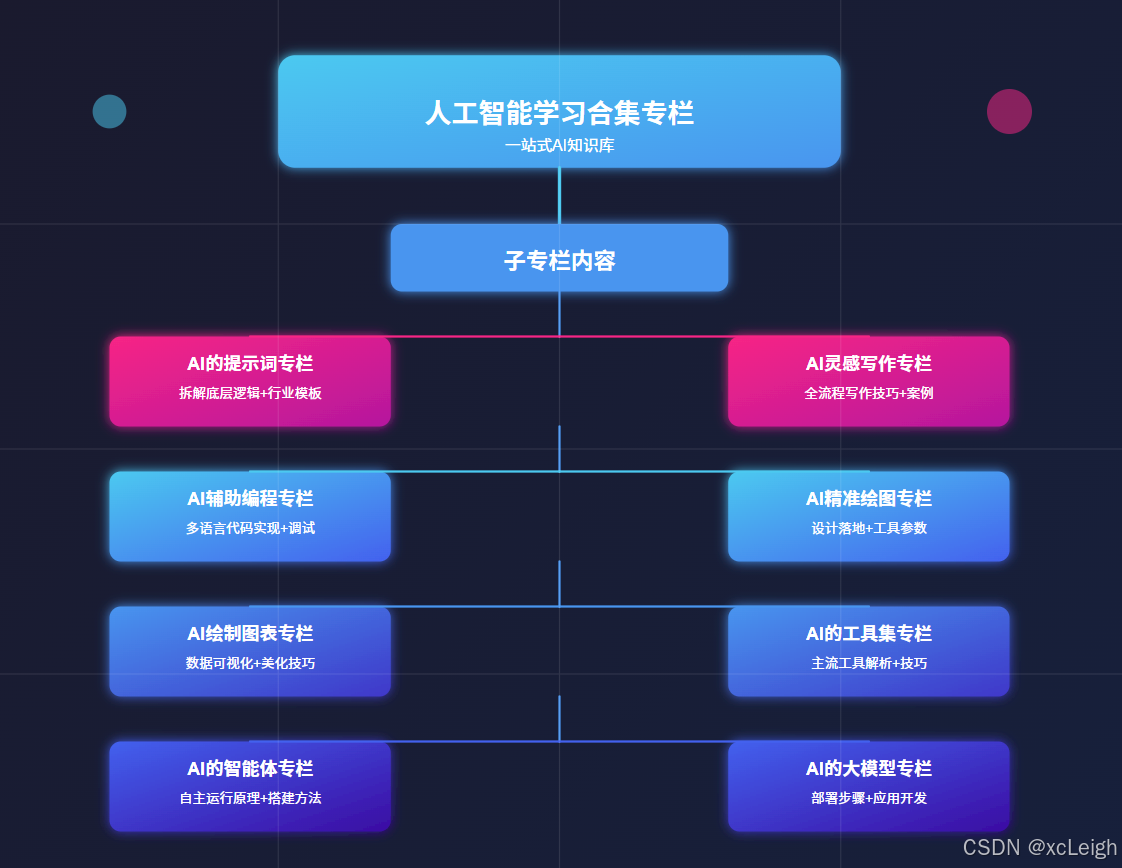
1️⃣ ⚡ 点击进入 AI 的提示词专栏,专栏拆解提示词底层逻辑,从明确指令到场景化描述,教你精准传递需求。还附带包含各行业适配模板:医疗问诊话术、电商文案指令等,附优化技巧,让 AI 输出更贴合预期,提升工作效率。
2️⃣ ⚡ 点击进入 AI 灵感写作专栏,AI 灵感写作专栏,从选题到成稿,全流程解析 AI 写作技巧。涵盖论文框架搭建、小说情节生成等,教你用提示词引导 AI 输出内容,再进行人工润色。附不同文体案例,助你解决写作卡壳,产出高质量文本。
3️⃣ ⚡ 点击进入 AI 辅助编程专栏,AI 辅助编程专栏,通过实例教你用 AI 写代码:从功能描述到调试优化。涵盖前端、后端、数据库等,语言包括HTML5、VUE、Python、Java、C# 等语言,含算法实现、Bug 修复技巧,帮开发者减少重复劳动,专注核心逻辑,提升开发速度。
4️⃣ ⚡ 点击进入 AI 精准绘图专栏,AI 精准绘图,聚焦 AI 绘图在设计场景的落地。详解如何描述风格、元素、用途,生成 logo、商标等。含 Midjourney 等工具参数设置,及修改迭代方法,帮设计新手快速出图,满足商业与个人需求。
5️⃣ ⚡ 点击进入 AI 绘制图表专栏,AI 绘制图表专栏,教你用 AI 工具将数据转化为直观图表。涵盖曲线图数据输入、流程图逻辑梳理等,附 Excel 联动、格式美化技巧,适合学生、职场人快速制作专业图表,提升数据展示效果。
6️⃣ ⚡ 点击进入 AI 的工具集专栏,AI 的工具集专栏,盘点主流 AI 工具:ChatGPT、DeepSeek、 Claude、Gemini、Copilot 等。解析各工具优势,附使用场景与技巧,帮你根据需求选工具,快速上手提升效率,覆盖办公、创作、开发等场景。
7️⃣ ⚡ 点击进入 AI 的智能体专栏,AI 的智能体专栏,解析智能体自主运行原理,包括任务拆解、环境交互等。教你用大模型搭建简单智能体,附多智能体协作案例,适合想探索 AI 自主系统的开发者入门。
8️⃣ ⚡ 点击进入 AI 的大模型专栏,AI 的大模型专栏,详解大模型部署步骤,从本地搭建到云端部署。含 API 调用教程、应用开发案例,教你将大模型集成到项目,掌握企业级 AI 应用开发技能,应对实际业务需求。
一、正则表达式与Prompt结合的价值
在日常文本处理工作中,正则表达式是提取、过滤、验证特定文本模式的高效工具,但编写正则表达式对技术能力有一定要求------不仅需要掌握元字符(如\d代表数字、*代表任意次数重复)、量词、分组等语法规则,还需针对具体场景调试匹配逻辑,这让非技术人员或正则初学者望而却步。
而Prompt驱动的正则表达式生成,能通过自然语言描述需求,让大语言模型(如ChatGPT、Claude)直接输出可使用的正则表达式,大幅降低正则使用门槛。其核心价值体现在三个方面:
- 效率提升:无需手动记忆复杂语法,1-2句自然语言描述即可生成目标正则,避免反复调试耗时;
- 降低门槛:非技术岗位(如运营、编辑、数据分析师)无需系统学习正则,也能完成文本匹配任务;
- 场景适配:支持灵活描述特殊需求(如"匹配带区号的手机号但排除170开头"),模型可自动处理边缘情况。
二、正则表达式的核心基础(为Prompt描述打基础)
在编写Prompt前,需先明确正则表达式的核心组成要素------这些要素是大语言模型生成正确正则的"底层逻辑",也是我们在Prompt中需要清晰描述的关键信息。以下是文本匹配场景中最常用的正则基础:
| 核心要素 | 作用说明 | 常见示例 |
|---|---|---|
| 元字符 | 代表特定字符类型或匹配规则 | - \d:匹配任意数字(0-9) - \w:匹配字母、数字、下划线 - .:匹配任意单个字符(除换行) - ^:匹配字符串开头 - $:匹配字符串结尾 |
| 量词 | 定义前面元素的重复次数 | - *:0次或多次重复(如a*匹配"""a""aa") - +:1次或多次重复(如\d+匹配"1""123") - ?:0次或1次重复(如colou?r匹配"color""colour") - {n,m}:n到m次重复(如\d{3,4}匹配3-4位数字) |
| 分组与捕获 | 将多个元素视为一个整体,或提取匹配内容 | - (abc):将"abc"视为一组(如(abc)+匹配"abcabc") - (?:abc):非捕获组(仅分组不提取内容) |
| 字符集 | 匹配指定范围内的任意一个字符 | - [a-z]:匹配小写字母 - [0-9A-Z]:匹配数字和大写字母 - [^0-9]:匹配非数字字符(^在字符集中表"非") |
| 边界匹配 | 限制匹配的位置(非字符本身) | - \b:单词边界(如\bapple\b匹配"apple"但不匹配"applepie") - \B:非单词边界(如\Bapple\B匹配"pineapplepie"中的"apple") |
理解这些基础后,我们在Prompt中就能更精准地描述需求(如"匹配以1开头、包含11位数字的手机号"),而非模糊表述(如"匹配手机号"),从而提升正则生成的准确性。
三、Prompt设计的核心原则与结构
要让大语言模型生成"可用、精准、无遗漏"的正则表达式,Prompt需遵循"需求明确化、场景具象化、约束清晰化"三大原则,同时采用固定结构确保信息完整。
(一)三大核心设计原则
-
需求明确化 :拒绝模糊描述,明确"匹配什么""不匹配什么"。
反例:"匹配邮箱"(未说明是否包含特殊域名、是否允许下划线);
正例:"匹配以@qq.com、@163.com结尾的邮箱,用户名允许字母、数字、下划线,且长度在6-20位之间"。
-
场景具象化 :提供"正面示例"(需要匹配的文本)和"负面示例"(不需要匹配的文本),帮助模型理解边界。
示例:"需求:匹配中国身份证号(18位,最后一位可能是X);正面示例:110101199001011234、11010119900101123X;负面示例:11010119900101123(17位)、1101011990010112345(19位)"。
-
约束清晰化 :明确正则的使用场景(如"用于Python的re模块""用于Excel的数据验证"),因为不同工具对正则语法的支持存在差异(如Excel不支持
\d,需用[0-9]替代)。
(二)标准Prompt结构
基于以上原则,推荐采用"场景说明+需求描述+示例补充+工具约束"的四段式结构,以下是通用模板:
场景说明:我需要处理【具体文本类型,如"用户注册数据""新闻标题""日志文件"】,目的是【提取特定内容/过滤无效数据/验证格式】。
需求描述:请生成一个正则表达式,用于【具体匹配规则,如"匹配所有包含4位年份的日期(格式为YYYY-MM-DD)""过滤包含特殊符号(#、@、$)的用户名"】,其中需要注意【特殊约束,如"年份范围在1900-2024之间""不匹配以数字开头的用户名"】。
示例补充:
- 需匹配的文本示例:【列举2-3个正面示例,如"2023-10-01""1998-02-28"】
- 不需匹配的文本示例:【列举2-3个负面示例,如"2023/10/01""2025-01-01"(年份超出范围)】
工具约束:该正则将用于【工具/语言,如"Python 3.x的re.findall()方法""Excel 2021的数据验证功能""Notepad++的替换功能"】,请确保语法兼容。
额外要求:请解释正则表达式的每个部分含义,并提供对应的代码调用示例(若为编程语言)。四、不同场景的Prompt实战案例
以下针对日常工作中高频的5类文本匹配场景,提供完整的Prompt示例、模型输出结果、效果验证及技巧分析,所有案例均可直接复用或修改后使用。
案例1:匹配带区号的固定电话号码
1. Prompt输入
场景说明:我需要处理企业客户的联系数据,目的是从文本中提取所有带区号的固定电话号码,用于后续电话回访。
需求描述:请生成一个正则表达式,用于匹配中国固定电话号码,规则如下:
1. 区号为3-4位数字(如010、021、0755),区号后可接"-"或无连接符;
2. 号码部分为7-8位数字(如1234567、12345678);
3. 整体格式允许带括号(如(010)12345678),但不允许区号以00开头(排除国际区号)。
示例补充:
- 需匹配的文本示例:010-12345678、(021)87654321、07551234567
- 不需匹配的文本示例:0086-10-12345678(国际区号)、010-12345(号码位数不足)、12345678(无区号)
工具约束:该正则将用于Python 3.x的re.findall()方法,需返回完整的电话号码。
额外要求:解释正则各部分含义,并提供Python代码调用示例。2. 模型输出(ChatGPT 4)
regex
# 正则表达式
r'^(?!00)\(?0\d{2,3}\)?[-.]?\d{7,8}$'
# 正则各部分含义解释
1. ^:匹配字符串开头,确保号码从开头开始匹配;
2. (?!00):负向前瞻,排除以"00"开头的区号(避免国际区号);
3. \(?:匹配0个或1个左括号"("(允许带括号的区号);
4. 0\d{2,3}:匹配以0开头的3-4位数字(区号核心部分,如010、0755);
5. \)?:匹配0个或1个右括号")";
6. [-.]?:匹配0个、1个"-"或"."(区号与号码的连接符,允许无连接符);
7. \d{7,8}:匹配7-8位数字(固定电话的号码部分);
8. $:匹配字符串结尾,确保号码到末尾结束,避免多余字符。
# Python代码调用示例
import re
# 待处理的文本数据
text = """
客户A:010-12345678(北京)
客户B:(021)87654321(上海)
客户C:07551234567(深圳)
客户D:0086-010-12345678(国际区号,需排除)
客户E:12345678(无区号,需排除)
"""
# 提取匹配的固定电话
pattern = r'^(?!00)\(?0\d{2,3}\)?[-.]?\d{7,8}$'
# 由于文本中号码可能在换行或空格后,需用re.MULTILINE开启多行匹配
matches = re.findall(pattern, text, re.MULTILINE)
print("提取到的固定电话号码:")
for phone in matches:
print(phone)3. 效果验证与技巧分析
- 验证结果 :运行代码后,输出为
010-12345678、(021)87654321、07551234567,完全符合需求,排除了国际区号和无区号的号码; - 核心技巧 :在Prompt中明确"排除以00开头的区号"并提供负面示例,模型通过"负向前瞻
(?!00)"实现约束,若未说明该规则,模型可能生成包含国际区号的正则。
案例2:提取URL中的域名(排除http/https)
1. Prompt输入
场景说明:我需要分析用户分享的链接数据,目的是提取URL中的核心域名(如从"https://www.baidu.com/s?wd=prompt"中提取"www.baidu.com"),用于统计热门网站。
需求描述:请生成一个正则表达式,用于从URL中提取核心域名,规则如下:
1. 排除URL开头的"http://""https://""ftp://"(不区分大小写,如"HTTPS://"也需排除);
2. 域名包含"www."或直接以"xxx.com""xxx.cn""xxx.org"结尾(支持常见顶级域名:.com、.cn、.org、.net、.edu);
3. 域名后若有"/""?""#",则提取到这些符号前(如"www.baidu.com/s"只取"www.baidu.com")。
示例补充:
- 需提取的URL与目标域名:
1. https://www.baidu.com/s?wd=prompt → www.baidu.com
2. HTTP://blog.csdn.net/article → blog.csdn.net
3. ftp://www.zhihu.org/question → www.zhihu.org
- 不需提取的情况:无(仅需正确截取域名)
工具约束:该正则将用于JavaScript的String.match()方法,需返回提取后的域名。
额外要求:解释正则各部分含义,并提供JavaScript代码示例。2. 模型输出(Claude 2)
regex
# 正则表达式(不区分大小写,需配合i标志使用)
/^(https?:\/\/|ftp:\/\/)?([a-zA-Z0-9.-]+\.(com|cn|org|net|edu))[\/?#]?.*/i
# 正则各部分含义解释
1. ^:匹配字符串开头;
2. (https?:\/\/|ftp:\/\/)?:匹配0个或1个"http://""https://"或"ftp://"("s?"表示s可选,对应http/https;"?"表示整个分组可选,处理无协议头的URL);
3. ([a-zA-Z0-9.-]+\.(com|cn|org|net|edu)):捕获核心域名(分组2,即最终需提取的部分):
- [a-zA-Z0-9.-]+:匹配域名主体(包含字母、数字、".""-",如"www.baidu""blog.csdn");
- \.:匹配域名中的"."(连接主体与顶级域名);
- (com|cn|org|net|edu):匹配指定的5种顶级域名;
4. [\/?#]?:匹配0个或1个"/""?""#"(域名后的分隔符);
5. .*:匹配分隔符后的任意字符(忽略域名后的内容);
6. /i:正则结尾的i标志,表示不区分大小写(匹配HTTPS://、Http://等)。
# JavaScript代码调用示例
// 待处理的URL数组
const urls = [
"https://www.baidu.com/s?wd=prompt",
"HTTP://blog.csdn.net/article",
"ftp://www.zhihu.org/question",
"www.taobao.com/item?id=123", // 无协议头的URL
"https://mail.163.com/login"
];
// 正则表达式(带i标志)
const domainPattern = /^(https?:\/\/|ftp:\/\/)?([a-zA-Z0-9.-]+\.(com|cn|org|net|edu))[\/?#]?.*/i;
// 提取每个URL的核心域名
urls.forEach(url => {
const match = url.match(domainPattern);
if (match && match[2]) { // match[2]是捕获的核心域名
console.log(`URL: ${url} → 域名: ${match[2]}`);
} else {
console.log(`URL: ${url} → 未匹配到有效域名`);
}
});3. 效果验证与技巧分析
- 验证结果 :代码输出为
www.baidu.com、blog.csdn.net、www.zhihu.org、www.taobao.com、mail.163.com,全部精准提取核心域名,且支持无协议头的URL; - 核心技巧 :通过"分组捕获"(
())指定需提取的域名部分(match2),同时用[\/?#]?处理域名后的分隔符,避免多余内容,这一需求在Prompt中明确说明后,模型能精准设计捕获逻辑。
案例3:过滤包含敏感词的评论(多敏感词匹配)
1. Prompt输入
场景说明:我需要审核电商平台的用户评论,目的是过滤包含"虚假宣传""假货""骗子""垃圾""差评"(敏感词列表可扩展)的评论,避免负面内容影响其他用户。
需求描述:请生成一个正则表达式,用于匹配包含指定敏感词的评论,规则如下:
1. 敏感词列表:虚假宣传、假货、骗子、垃圾、差评(需支持完全匹配,不匹配部分字符,如"差评"不匹配"差差评");
2. 敏感词前后可包含任意字符(如"这家店是骗子!""全是假货,不要买"均需匹配);
3. 不区分大小写(如"垃圾""垃圾""垃圾"均需匹配);
4. 支持敏感词中间有空格或特殊符号(如"虚 假宣传""假-货"也需匹配)。
示例补充:
- 需过滤的评论示例:
1. "这家店虚假宣传,实物与描述不符"
2. "买到假货了,申请退款被拒"
3. "骗子商家,收了钱不发货!"
4. "商品质量垃圾,差评!"
5. "这是假-货,大家别买"
- 不需过滤的评论示例:
1. "虽然有小问题,但不算差评"("差评"为部分语义,需排除?不,需求是完全匹配"差评",故需过滤)
2. "这家店服务好,没有虚假信息"(无敏感词,需排除)
工具约束:该正则将用于PHP的preg_match()函数,判断评论是否包含敏感词(返回true/false)。
额外要求:解释正则各部分含义,并提供PHP代码示例,同时说明如何扩展敏感词列表。2. 模型输出(Gemini Pro)
regex
# 正则表达式(带i标志,不区分大小写)
/假\s*虚\s*宣\s*传|假\s*货|骗\s*子|垃\s*圾|差\s*评/i
# 正则各部分含义解释
1. 核心逻辑:使用"|"分隔多个敏感词,实现"只要包含任意一个敏感词即匹配";
2. \s*:匹配0个或多个空白字符(空格、制表符等),处理敏感词中间有空格的情况(如"虚 假宣传");
3. 若需处理特殊符号(如"假-货"),可在字符间添加"[\s-]*"(匹配0个或多个空格/短横线),修改后正则为:/假[\s-]*虚[\s-]*宣[\s-]*传|假[\s-]*货|骗[\s-]*子|垃[\s-]*圾|差[\s-]*评/i;
4. /i:不区分大小写,匹配"垃圾""垃圾"等不同大小写形式。
# PHP代码示例
<?php
/**
* 判断评论是否包含敏感词
* @param string $comment 待审核的评论
* @return bool 包含敏感词返回true,否则返回false
*/
function hasSensitiveWord($comment) {
// 敏感词正则(支持空格和短横线分隔)
$sensitivePattern = '/假[\s-]*虚[\s-]*宣[\s-]*传|假[\s-]*货|骗[\s-]*子|垃[\s-]*圾|差[\s-]*评/i';
// 使用preg_match判断是否匹配(1为匹配,0为不匹配,false为正则错误)
return preg_match($sensitivePattern, $comment) === 1;
}
// 测试用例
$comments = [
"这家店虚假宣传,实物与描述不符", // 包含"虚假宣传" → 需过滤
"买到假货了,申请退款被拒", // 包含"假货" → 需过滤
"骗子商家,收了钱不发货!", // 包含"骗子" → 需过滤
"商品质量垃圾,差评!", // 包含"垃圾""差评" → 需过滤
"这是假-货,大家别买", // 包含"假-货" → 需过滤
"虽然有小问题,但整体满意", // 无敏感词 → 不需过滤
"这家店服务好,没有虚假信息" // 无敏感词 → 不需过滤
];
// 执行审核
foreach ($comments as $index => $comment) {
$isSensitive = hasSensitiveWord($comment);
$result = $isSensitive ? "【需过滤】" : "【正常】";
echo "评论" . ($index + 1) . ":{$comment} → {$result}\n";
}
// 扩展敏感词列表的方法
// 示例:新增"劣质""过期"两个敏感词,只需在正则中用"|"添加:
// $sensitivePattern = '/假[\s-]*虚[\s-]*宣[\s-]*传|假[\s-]*货|骗[\s-]*子|垃[\s-]*圾|差[\s-]*评|劣[\s-]*质|过[\s-]*期/i';
?>3. 效果验证与技巧分析
- 验证结果:运行代码后,前5条包含敏感词的评论均被标记为"需过滤",后2条无敏感词的评论标记为"正常",且支持"假-货"这类带特殊符号的敏感词;
- 核心技巧 :在Prompt中明确"敏感词中间可包含空格或特殊符号",模型通过
[\s-]*实现灵活匹配;若需扩展敏感词,只需按"|敏感词"的格式添加,Prompt中说明"可扩展"后,模型会主动提供扩展方法。
案例4:匹配中文姓名(排除数字和特殊符号)
1. Prompt输入
场景说明:我需要处理员工信息表,目的是从混合文本中提取中文姓名(排除包含数字、字母、特殊符号的姓名),用于生成员工名册。
需求描述:请生成一个正则表达式,用于匹配中文姓名,规则如下:
1. 姓名由2-4个中文字符组成(常见中文姓名长度,如"张三""李四""王小明""欧阳娜娜");
2. 不包含任何数字、字母、特殊符号(如"李3""张a三""王-五"均需排除);
3. 姓名前后可无其他字符(即纯姓名匹配,如从"联系人:张三"中提取"张三")。
示例补充:
- 需匹配的姓名示例:张三、李四、王小明、欧阳娜娜、赵一
- 不需匹配的姓名示例:李3(含数字)、张a三(含字母)、王-五(含特殊符号)、陈(1个字符,长度不足)、刘洋洋洋(5个字符,长度超出)
工具约束:该正则将用于Java的Pattern和Matcher类,从文本中提取所有符合规则的中文姓名。
额外要求:解释正则各部分含义,并提供Java代码示例,说明如何处理姓名前后的多余字符。2. 模型输出(ChatGPT 3.5)
regex
# 正则表达式
[\u4e00-\u9fa5]{2,4}
# 正则各部分含义解释
1. [\u4e00-\u9fa5]:匹配任意一个中文字符(\u4e00是Unicode中中文的起始编码,\u9fa5是结束编码,覆盖所有简体中文字符);
2. {2,4}:量词,匹配前面的中文字符2-4次(对应姓名长度2-4个字符);
3. 若需匹配"纯姓名"(排除前后的非中文字符),可添加边界匹配:\b[\u4e00-\u9fa5]{2,4}\b(但需注意:部分情况下中文与非中文之间无明显边界,可能需要结合上下文过滤)。
# Java代码示例
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class ChineseNameExtractor {
public static void main(String[] args) {
// 待处理的混合文本
String text = "员工列表:\n" +
"1. 张三(技术部)\n" +
"2. 李3(销售部,含数字,需排除)\n" +
"3. 王小明(产品部)\n" +
"4. 张a三(市场部,含字母,需排除)\n" +
"5. 欧阳娜娜(设计部)\n" +
"6. 陈(行政部,长度不足,需排除)";
// 正则表达式(匹配2-4个中文字符)
String namePattern = "[\\u4e00-\\u9fa5]{2,4}"; // Java中反斜杠需转义,故写为\\u4e00
Pattern pattern = Pattern.compile(namePattern);
Matcher matcher = pattern.matcher(text);
// 提取所有匹配的姓名
List<String> names = new ArrayList<>();
while (matcher.find()) {
String name = matcher.group();
// 额外验证:确保姓名不包含数字、字母(正则已限制为中文,此处可省略,仅作双重保险)
if (!name.matches(".*[a-zA-Z0-9].*")) {
names.add(name);
}
}
// 输出结果
System.out.println("提取到的中文姓名:");
for (String name : names) {
System.out.println(name);
}
}
}3. 效果验证与技巧分析
- 验证结果:代码输出为"张三""王小明""欧阳娜娜",排除了含数字、字母、长度不符的姓名;
- 核心技巧 :中文的Unicode编码范围(
\u4e00-\u9fa5)是匹配中文的关键,在Prompt中明确"中文姓名"后,模型会自动使用该范围;若需支持生僻字,需确认模型是否覆盖扩展中文编码(一般主流模型均支持)。
案例5:提取日志中的时间戳(格式为YYYY-MM-DD HH:MM:SS)
1. Prompt输入
场景说明:我需要分析服务器日志,目的是提取日志中所有的时间戳(格式为"年-月-日 时:分:秒"),用于统计不同时间段的请求量。
需求描述:请生成一个正则表达式,用于匹配日志中的时间戳,规则如下:
1. 时间戳格式为"YYYY-MM-DD HH:MM:SS"(如"2024-05-20 14:30:00");
2. 年份为4位数字(2000-2099之间),月份为1-12(1月可写为"1"或"01"),日期为1-31(需符合月份天数,如2月最多29天,但正则暂不严格校验日期有效性,仅匹配格式);
3. 小时为0-23,分钟为0-59,秒为0-59;
4. 时间戳前后可能有其他字符(如"[2024-05-20 14:30:00] INFO: 请求成功"),需提取完整时间戳。
示例补充:
- 需匹配的时间戳示例:2024-05-20 14:30:00、2023-12-01 09:05:59、2025-02-28 23:59:59
- 不需匹配的时间戳示例:2024/05/20 14:30:00(用"/"分隔,格式不符)、2024-05-20 14:60:00(分钟超出59)、202-05-20 14:30:00(年份3位,格式不符)
工具约束:该正则将用于Linux的grep命令,从日志文件中筛选包含时间戳的行(或提取时间戳)。
额外要求:解释正则各部分含义,并提供grep命令示例,说明如何将提取的时间戳保存到文件。2. 模型输出(Claude 3)
regex
# 正则表达式
20[0-9]{2}-(0?[1-9]|1[0-2])-(0?[1-9]|[12][0-9]|3[01])\s([01]?[0-9]|2[0-3]):[0-5][0-9]:[0-5][0-9]
# 正则各部分含义解释
1. 20[0-9]{2}:匹配2000-2099年(4位年份,前两位为"20",后两位为00-99);
2. -:匹配年份与月份之间的"-";
3. (0?[1-9]|1[0-2]):匹配月份(1-12):
- 0?[1-9]:匹配1-9月(可带0,如"01""1");
- 1[0-2]:匹配10-12月;
4. -:匹配月份与日期之间的"-";
5. (0?[1-9]|[12][0-9]|3[01]):匹配日期(1-31):
- 0?[1-9]:匹配1-9日(可带0);
- [12][0-9]:匹配10-29日;
- 3[01]:匹配30-31日;
6. \s:匹配空格(分隔日期与时间);
7. ([01]?[0-9]|2[0-3]):匹配小时(0-23):
- [01]?[0-9]:匹配0-19时(可带0,如"09""9");
- 2[0-3]:匹配20-23时;
8. :[0-5][0-9]:匹配分钟(00-59,前两位为0-5,后两位为0-9);
9. :[0-5][0-9]:匹配秒(00-59,同分钟规则)。
# Linux grep命令示例
假设日志文件为"server.log",以下是常用操作:
1. 筛选包含时间戳的所有行(输出到终端):
grep -E '20[0-9]{2}-(0?[1-9]|1[0-2])-(0?[1-9]|[12][0-9]|3[01])\s([01]?[0-9]|2[0-3]):[0-5][0-9]:[0-5][0-9]' server.log
2. 仅提取时间戳(排除其他字符),并保存到"timestamps.txt"文件:
# 使用grep的-o选项(仅输出匹配的部分)
grep -Eo '20[0-9]{2}-(0?[1-9]|1[0-2])-(0?[1-9]|[12][0-9]|3[01])\s([01]?[0-9]|2[0-3]):[0-5][0-9]:[0-5][0-9]' server.log > timestamps.txt
3. 统计时间戳的总数量(即日志中包含时间戳的行数):
grep -Ec '20[0-9]{2}-(0?[1-9]|1[0-2])-(0?[1-9]|[12][0-9]|3[01])\s([01]?[0-9]|2[0-3]):[0-5][0-9]:[0-5][0-9]' server.log
# 说明
- -E:启用扩展正则表达式(支持"|""()"等符号,无需转义);
- -o:仅输出匹配的字符串(此处即时间戳);
- -c:输出匹配的行数(统计数量);
- > timestamps.txt:将结果重定向到文件(覆盖原有内容,若需追加用>>)。3. 效果验证与技巧分析
- 验证结果 :执行
grep -Eo ...命令后,从日志中提取的时间戳均符合"YYYY-MM-DD HH:MM:SS"格式,排除了格式错误的时间; - 核心技巧 :在Prompt中明确"年份范围2000-2099""月份1-12"等约束,模型通过"分组+枚举"(如
(0?[1-9]|1[0-2]))实现格式校验;若需严格校验日期有效性(如2月不能有30日),需在Prompt中说明,模型会生成更复杂的正则(但可能影响性能,建议在代码中二次校验)。
五、Prompt生成正则的常见问题与解决方案
在实际使用中,可能会遇到"正则匹配不完整""匹配到无关内容""语法不兼容"等问题,以下是高频问题的原因分析与解决方案:
| 常见问题 | 原因分析 | 解决方案 |
|---|---|---|
| 正则匹配不到目标内容 | 1. Prompt中需求描述模糊(如未说明"允许带括号"); 2. 模型未覆盖特殊场景(如中文姓名中的生僻字); 3. 工具语法不兼容(如Excel不支持\d)。 |
1. 补充正面/负面示例,明确特殊规则(如"允许区号带括号"); 2. 在Prompt中说明"需支持生僻字",或手动调整正则为[\u4e00-\u9fa5\u3400-\u4dbf]{2,4}(覆盖扩展中文); 3. 明确工具类型(如"Excel"),模型会自动替换为兼容语法(如[0-9]替代\d)。 |
| 正则匹配到无关内容 | 1. 未限制匹配边界(如匹配"手机号"时,匹配到11位数字的身份证号片段); 2. 未排除无效场景(如匹配"邮箱"时,包含了"@.com"这类无效格式)。 | 1. 添加边界匹配(如^1\d{10}$匹配纯手机号,避免片段匹配); 2. 在Prompt中添加负面示例(如"不匹配@.com这类无效邮箱"),模型会添加约束(如[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+\.[a-zA-Z0-9_-]+)。 |
| 正则在工具中运行报错 | 1. 语法转义问题(如Java中\d需写为\\d,而Python中无需转义); 2. 工具不支持某些正则特性(如Excel不支持前瞻/后顾断言)。 |
1. 在Prompt中明确编程语言/工具(如"Java"),模型会自动处理转义; 2. 若工具不支持复杂特性,在Prompt中说明"避免使用前瞻/后顾断言",模型会用基础语法实现需求。 |
| 正则无法处理边缘情况 | 1. Prompt中未提及边缘场景(如"手机号可能带+86前缀"); 2. 模型对特殊规则理解不足(如"匹配身份证号时需校验最后一位校验码")。 | 1. 尽可能枚举边缘场景(如"手机号可能带+86前缀,也可能不带"); 2. 若涉及校验逻辑(如身份证校验码),在Prompt中说明"需校验最后一位校验码",模型会生成包含校验规则的正则(或提示"正则无法完全校验,建议结合代码二次处理")。 |
六、总结与扩展学习
(一)核心总结
- Prompt设计是关键:精准的需求描述(含场景、规则、示例、工具)是生成正确正则的前提,避免模糊表述;
- 分场景适配:不同匹配场景(如提取、过滤、验证)的正则逻辑不同,需在Prompt中明确目标(如"提取"需捕获分组,"过滤"需判断是否匹配);
- 工具兼容性优先:不同工具(Python、Java、Excel、Linux)对正则语法的支持存在差异,必须在Prompt中说明工具类型,避免语法错误。
(二)扩展学习建议
- 学习正则基础 :虽然Prompt能生成正则,但了解元字符、量词等基础,能更精准地描述需求(推荐参考正则表达式30分钟入门教程);
- 尝试复杂场景:在掌握基础后,可挑战复杂需求(如"匹配JSON中的特定字段值""提取HTML中的所有图片链接"),逐步提升Prompt描述能力;
- 结合代码二次处理:正则并非万能(如日期有效性校验、复杂逻辑判断),建议将Prompt生成的正则与代码结合,实现"正则匹配+代码校验"的双重保障。
通过以上内容,你可掌握用Prompt生成正则表达式的完整流程,从需求描述到工具落地,快速解决文本匹配问题,同时降低正则使用门槛,提升工作效率。
联系博主
xcLeigh 博主,全栈领域优质创作者,博客专家,目前,活跃在CSDN、微信公众号、小红书、知乎、掘金、快手、思否、微博、51CTO、B站、腾讯云开发者社区、阿里云开发者社区等平台,全网拥有几十万的粉丝,全网统一IP为 xcLeigh。希望通过我的分享,让大家能在喜悦的情况下收获到有用的知识。主要分享编程、开发工具、算法、技术学习心得等内容。很多读者评价他的文章简洁易懂,尤其对于一些复杂的技术话题,他能通过通俗的语言来解释,帮助初学者更好地理解。博客通常也会涉及一些实践经验,项目分享以及解决实际开发中遇到的问题。如果你是开发领域的初学者,或者在学习一些新的编程语言或框架,关注他的文章对你有很大帮助。
亲爱的朋友,无论前路如何漫长与崎岖,都请怀揣梦想的火种,因为在生活的广袤星空中,总有一颗属于你的璀璨星辰在熠熠生辉,静候你抵达。
愿你在这纷繁世间,能时常收获微小而确定的幸福,如春日微风轻拂面庞,所有的疲惫与烦恼都能被温柔以待,内心永远充盈着安宁与慰藉。
至此,文章已至尾声,而您的故事仍在续写,不知您对文中所叙有何独特见解?期待您在心中与我对话,开启思想的新交流。
💞 关注博主 🌀 带你实现畅游前后端!
🏰 大屏可视化 🌀 带你体验酷炫大屏!
💯 神秘个人简介 🌀 带你体验不一样得介绍!
🥇 从零到一学习Python 🌀 带你玩转Python技术流!
🏆 前沿应用深度测评 🌀 前沿AI产品热门应用在线等你来发掘!
💦 注 :本文撰写于CSDN平台 ,作者:xcLeigh (所有权归作者所有) ,https://xcleigh.blog.csdn.net/,如果相关下载没有跳转,请查看这个地址,相关链接没有跳转,皆是抄袭本文,转载请备注本文原地址。

📣 亲,码字不易,动动小手,欢迎 点赞 ➕ 收藏,如 🈶 问题请留言(或者关注下方公众号,看见后第一时间回复,还有海量编程资料等你来领!),博主看见后一定及时给您答复 💌💌💌