😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本专栏《人工智能》旨在记录最新的科研前沿,包括
大模型、智能体、强化学习等相关领域,期待与你一同探索、学习、进步,一起卷起来叭!🚩Paper:SWE-MiniSandbox: Container-Free Reinforcement Learning for Building Software Engineering Agents
💭开源代码:https://github.com/lblankl/SWE-MiniSandbox
💻时间:202602
💭推荐指数:🌟🌟🌟🌟🌟
往期精彩专栏内容,欢迎订阅:
🔗【免训练&测试时扩展】20260213:Code Agent可控进化
🔗【免训练&测试时扩展】20260213:通过任务算术转移思维链能力
🔗【免训练&测试时推理】20251014:不确定性影响模型输出
🔗【低训练&测试时推理】20251014:测试时针对特定样本进行语言模型优化
🔗【免训练&强化学习】】20250619:训练无关的组相对策略优化
🔗【多智能体&强化学习】20250619:基于统一多模态思维链的奖励模型
🔗【多智能体&强化学习】20250615:构建端到端的自主信息检索代理
🔗【多智能体】20250611:基于嵌套进化算法的多代理工作流
🔗【多智能体】20250610:受木偶戏启发实现多智能体协作编排
🔗【多智能体】20250609:基于LLM自进化多学科团队医疗咨询多智能体框架
🔗【具身智能体】20250608:EvoAgent:针对长时程任务具有持续世界模型的自主进化智能体
介绍
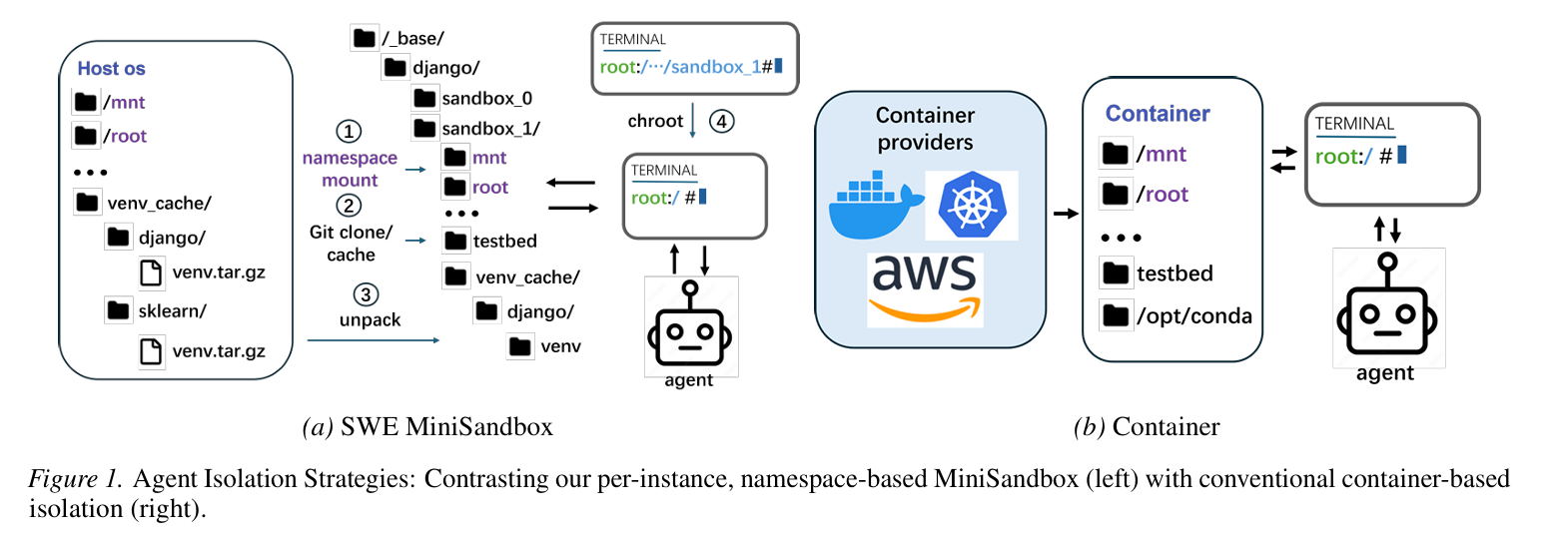
- 研究问题:这篇文章要解决的问题是如何在软件工程(SWE)领域中,通过无容器化的方法进行强化学习(RL)训练,以提高训练效率和可扩展性。现有的基于容器的SWE代理框架虽然有效,但存在
存储开销大、环境设置慢且需要容器管理权限等问题。 - 研究难点:在大规模训练时,
预构建的容器镜像会带来显著的资源开销;容器管理基础设施的限制使得资源受限的研究环境难以扩展;现有的方法在存储和准备时间上的开销较大。 - 相关工作:该问题的研究相关工作有:
SWE-agent框架、SWE-Gym、SWE-smith和SWE-Mirror等方法。这些方法虽然在一定程度上优化了资源使用,但仍然依赖于大量的容器镜像,未能从根本上解决资源开销大的问题。
研究方法
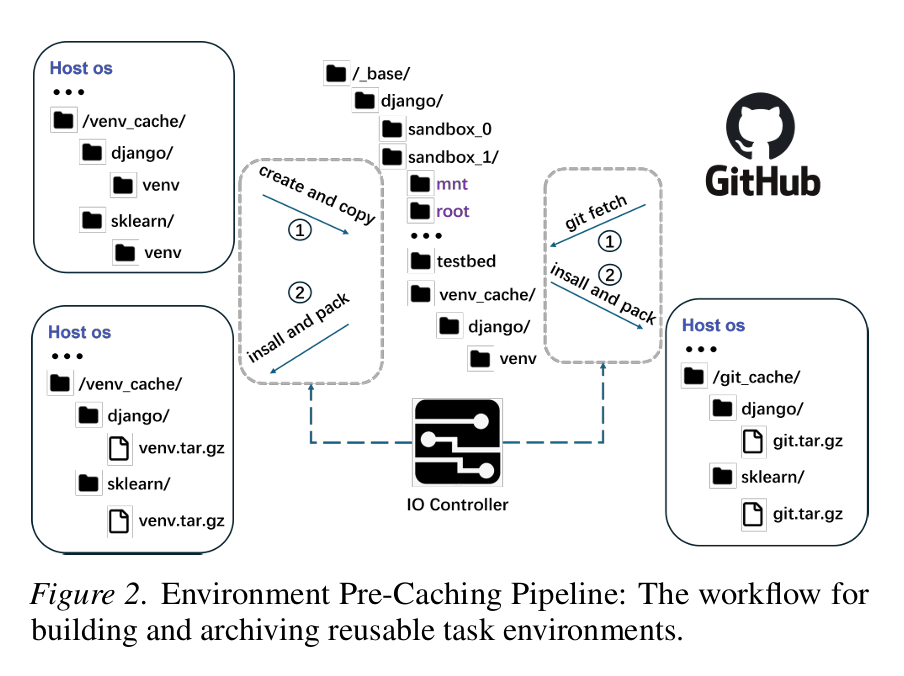
这篇论文提出了SWE-MiniSandbox,一种轻量级的无容器化沙箱系统,用于解决SWE代理的RL训练中的可扩展性和可访问性问题。具体来说,
- 进程和文件系统隔离:SWE-MiniSandbox通过使用每个实例的挂载命名空间和chroot来实现进程和文件系统的隔离,避免了容器化的开销。每个任务在一个独立的终端会话中执行,并且每个实例都有自己的私有目录。
- 环境预缓存管道:设计了一个基于venv的预缓存管道,用于构建轻量级Python虚拟环境、安装任务特定的依赖项,并在运行之间重用压缩的缓存工件。通过将环境和代码库打包成tar.gz归档文件,减少了重复的文件系统操作。
- I/O瓶颈管理:通过有界并发解压缩机制,结合Ray资源标签和线程信号量,限制并行解压缩的数量,避免磁盘I/O饱和。模型假设磁盘提供固定的有效I/O带宽 B B B(以MB/s为单位),并定义了并发解压缩任务的I/O预算模型: ∑ j = 1 C b j ≤ B \sum_{j=1}^C b_j \leq B j=1∑Cbj≤B其中, b j b_j bj表示任务 j j j的平均I/O吞吐量, C C C是并发任务数。
- 与现有SWE工具的集成:SWE-MiniSandbox与SWE-Rex、SWE-agent和SkyRL无缝集成,支持高效和分布式的RL训练。终端管理基于SWE-Rex的pexpect交互层,代理-RL-环境交互在Ray远程函数中实现。
实验设计
实验主要基于SWE-agent、SWE-Rex和SkyRL进行。实验设计包括以下几个方面:
- 数据收集:使用SWE-smith数据集独立收集的5k个黄金(已解决)轨迹,分别使用MiniSandbox框架和
标准容器化框架生成。 - 模型训练:基于这些数据集,使用Qwen2.5-3B-Coder-Instruct和Qwen2.5-7B-Coder-Instruct进行2轮微调,获得四个学生模型。然后在SWE-smith数据集上进行1轮基于策略的RL训练,批量大小为16,回滚次数为8,每次更新产生128个并行隔离环境实例。
- 实验环境:所有实验在一台配备8xB200 GPUs、184个CPU核心和800GBSSD的单节点上进行。容器服务器使用Docker,具有32个CPU核心和2TBSSD。为了公平比较,MiniSandbox的CPU使用量限制在32核以内。
结果分析
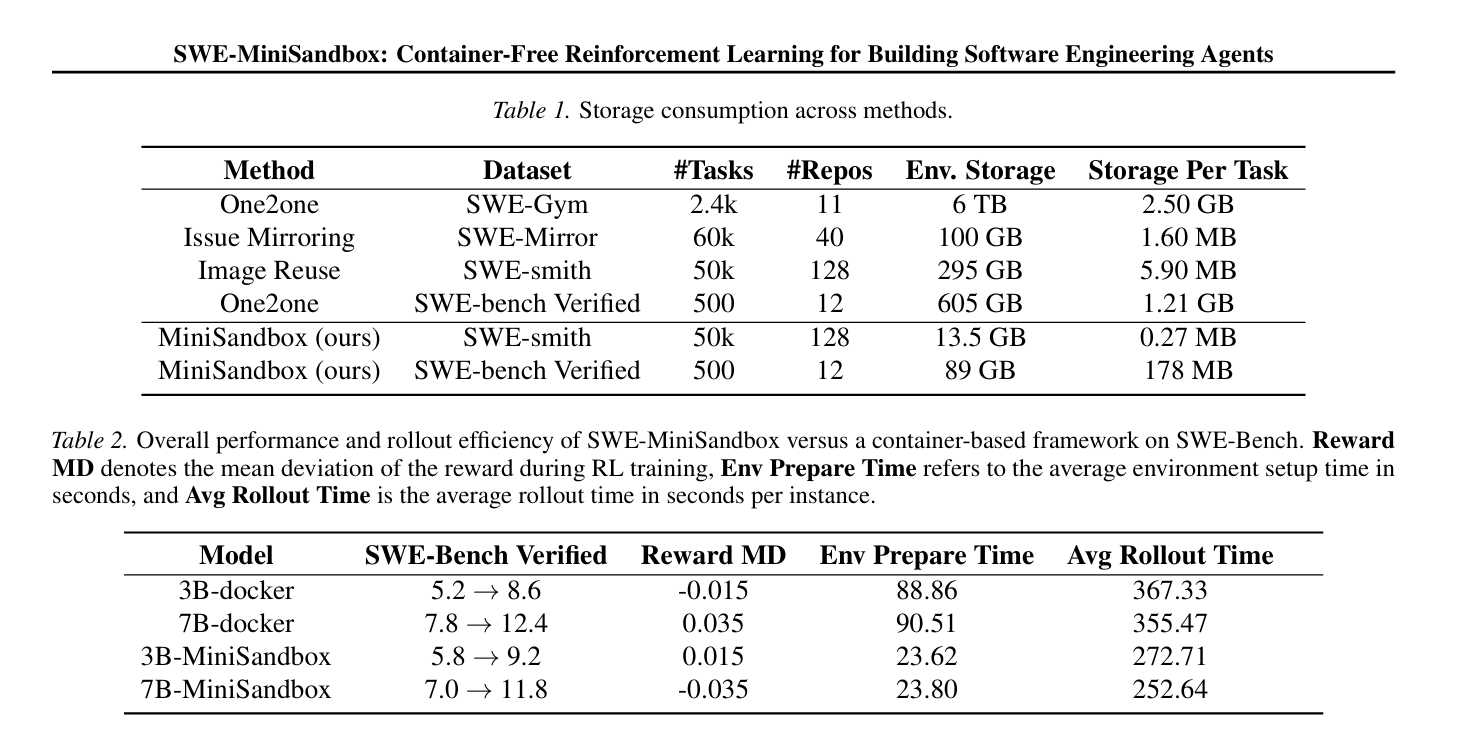
- 存储消耗:MiniSandbox系统消除了存储完整镜像的需求,环境缓存大小减少到图像方法的约5%(SWE-smith)和15%(SWE-Bench Verified)。
- 性能评估:MiniSandbox框架在评估性能上与基于容器的基线相当,表明MiniSandbox中生成的轨迹和后续的RL训练质量相似。
- 效率提升:MiniSandbox的平均环境准备时间仅为容器化设置的25%(23.62秒 vs.88.86秒)。奖励计算时间也更快,环境通信时间和超时时间相当。
- 可扩展性:在多节点实验中,MiniSandbox在高回滚压力下表现出高效的可扩展性。当扩展到单节点上的16个回滚时,I/O和CPU竞争导致所有回滚工作无法完全并行执行。
总体结论
本文提出的SWE-MiniSandbox系统通过无容器化的方法,显著降低了存储和设置开销,同时保持了与常见SWE工具链的兼容性。它支持可扩展的多节点执行,并提供灵活的隔离策略:对于大多数SWE任务,可以使用轻量级的虚拟环境沙箱,而仅对需要更强系统级保证的任务保留容器。总体而言,MiniSandbox旨在降低大规模SWE代理实验的门槛,为资源受限的用户和大规模团队提供一个高效、可访问且可重现的替代方案。未来的研究方向包括探索基于覆盖的文件系统设计,以进一步缓解I/O瓶颈并提高高并发下的吞吐量。
不足与反思
探索基于覆盖的文件系统设计,以进一步缓解剩余的I/O瓶颈并在高并发下提高吞吐量。
📌 [ 笔者 ] 文艺倾年
📃 [ 更新 ] 2026.02.21
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!