体验式强化学习:让模型学会"吃一堑长一智"
一句话总结:论文提出 ERL(Experiential Reinforcement Learning),在强化学习中嵌入"尝试-反思-改进"的显式循环,将稀疏反馈转化为结构化的行为修正,在复杂任务上实现了高达 81% 的性能提升。
📖 开篇:稀疏奖励的困境
强化学习有个老毛病:反馈太稀疏了。
想象一下,你让一个机器人学下棋。传统强化学习的做法是:机器人走了一步,环境说"不对,输了",然后呢?机器人只能自己琢磨:是哪一步走错了?是开局的问题还是中盘的问题?它完全不知道。
这就是信用分配问题(Credit Assignment)------当奖励信号稀疏且延迟时,模型必须隐式地推断"失败应该转化为什么样的行为改变"。这个推断过程对大模型来说极其困难。
人类是怎么学习的?我们失败后会反思:"刚才那步棋走得太急了,应该先稳固防守"。这种显式的反思把模糊的"失败"转化成了具体的"改进方向"。
论文作者的想法是:既然人类靠反思学习,为什么不把这个能力教给大模型?
🧠 核心洞察:三种学习范式的对比
论文把现有的学习方法分成三类:
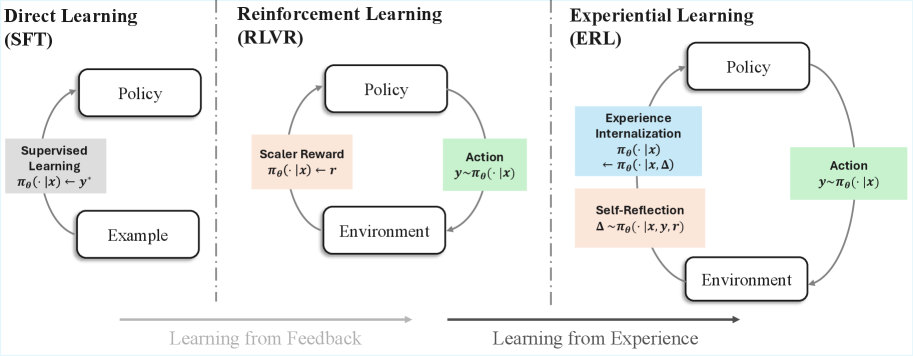
图1:三种学习范式的对比------从直接学习到强化学习再到体验式学习
| 范式 | 核心机制 | 问题 |
|---|---|---|
| 直接学习(SFT) | 从正确答案学习 | 需要高质量标注数据 |
| 强化学习(RLVR) | 从环境奖励学习 | 稀疏奖励下难以信用分配 |
| 体验式学习(ERL) | 从失败反思中学习 | 将反馈转化为显式修正 |
传统 RLVR 的问题是:模型拿到一个"0分",只知道"错了",但不知道"错在哪"。
ERL 的思路是:让模型自己生成一份"错题分析",然后用这份分析指导下一次尝试。这就像学生做完试卷后,老师不讲题,但让学生自己写一份"我为什么错了,下次怎么做"的反思报告。
🏗️ ERL 架构:尝试-反思-巩固的三部曲
核心流程
ERL 的训练循环包含四个关键步骤:
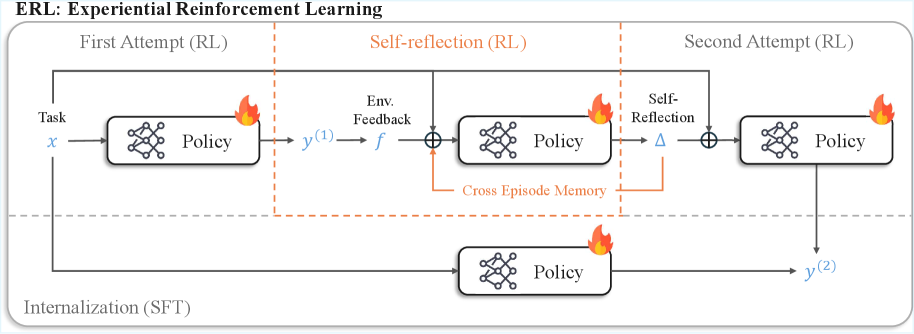
图2:ERL 的完整训练流程------首次尝试、自我反思、二次尝试、经验内化
第一步:首次尝试
模型面对任务 xxx,生成初始回答 y(1)y^{(1)}y(1)。环境返回反馈 f(1)f^{(1)}f(1) 和奖励 r(1)r^{(1)}r(1)。
如果奖励够高(r(1)≥τr^{(1)} \geq \taur(1)≥τ),直接进入强化学习更新。如果不够,进入反思环节。
第二步:自我反思
这是 ERL 的核心创新。模型不是盲目重试,而是先生成一份反思 Δ\DeltaΔ:
Δ∼πθ(⋅∣x,y(1),f(1),r(1),m)\Delta \sim \pi_\theta(\cdot \mid x, y^{(1)}, f^{(1)}, r^{(1)}, m)Δ∼πθ(⋅∣x,y(1),f(1),r(1),m)
这里 mmm 是跨周期记忆(Cross-Episode Memory),存储了之前成功的修正模式。模型可以参考"上次类似情况我是怎么改对的"。
第三步:二次尝试
模型利用反思 Δ\DeltaΔ 作为指导,生成改进后的回答 y(2)y^{(2)}y(2):
y(2)∼πθ(⋅∣x,Δ)y^{(2)} \sim \pi_\theta(\cdot \mid x, \Delta)y(2)∼πθ(⋅∣x,Δ)
如果这次成功了,就把反思 Δ\DeltaΔ 存入记忆 mmm,供以后参考。
第四步:经验内化
这是论文的另一个关键设计:把反思引导的成功行为"内化"到基础策略中。
通过自蒸馏,训练模型仅根据原始输入 xxx 就能直接输出改进后的回答 y(2)y^{(2)}y(2):
Ldistill(θ)=−EI(r(2)\>0)logπθ(y(2)∣x)\mathcal{L}_{\text{distill}}(\theta) = -\mathbb{E}\left\\mathbb{I}(r\^{(2)} \> 0) \\log \\pi_\\theta(y\^{(2)} \\mid x)\\rightLdistill(θ)=−EI(r(2)\>0)logπθ(y(2)∣x)
这意味着:部署时不需要额外的反思步骤,但训练时学到的"改进能力"被保留了下来。
为什么不是简单的"重试"?
论文做了一个关键对比:
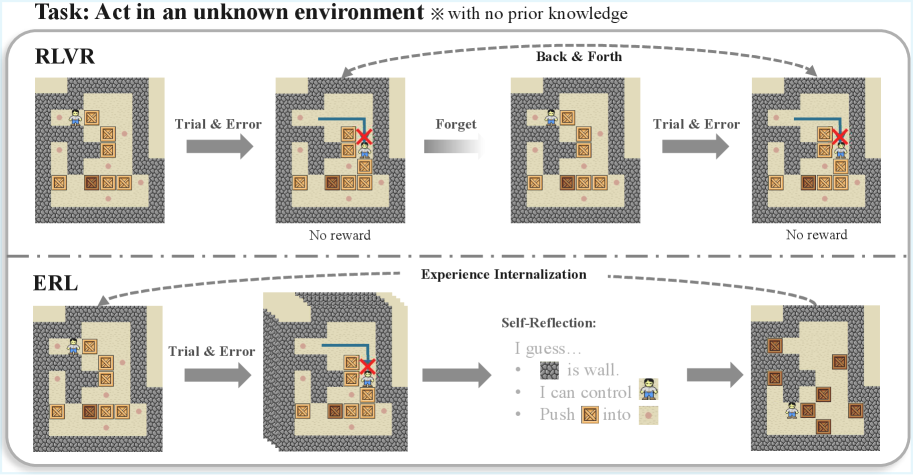
图3:RLVR 是盲目的"试错-忘记-试错";ERL 是有意识的"试错-反思-改进-内化"
RLVR 的问题在于:每次失败后,模型只是随机尝试另一个方向。上次犯的错误没有被"记住",也没有被"分析"。就像一个人考试,每次都凭感觉蒙,从不看错题。
ERL 强制模型在失败后写"反思报告"。这份报告把模糊的"失败"变成了具体的"哪里错了、怎么改"。这种结构化的修正信号比单纯的奖励信号有价值得多。
门控机制:成功的案例不要乱改
论文还设计了一个门控反思机制 :只有当首次尝试失败(r(1)<τr^{(1)} < \taur(1)<τ)时才触发反思。
这避免了"过度优化"的问题------如果第一次就做对了,强制反思反而可能画蛇添足。这个设计体现了作者对训练稳定性的考量。
🔧 训练方法:GRPO + 跨周期记忆
ERL 使用 GRPO(Group Relative Policy Optimization)作为底层优化器。GRPO 是 DeepSeek 团队提出的强化学习算法,特点是省掉了 Critic Model。
传统的 PPO 需要一个价值网络来估计"这个动作好不好",训练成本高。GRPO 的思路是:对同一个问题生成多个候选答案,在组内做相对比较,用组均值和标准差来归一化奖励,计算相对优势。
ERL 在这个基础上做了两件事:
-
将反思和二次尝试纳入训练目标:不是只优化首次尝试,而是让整个"尝试-反思-改进"链条都参与梯度更新。
-
跨周期记忆:把成功的反思模式存起来,后续训练可以复用。这有点像"错题本"------同样的错误不要犯两次。
🧪 实验结果:复杂任务上碾压式优势
任务设置
论文选了三个具有稀疏奖励特点的任务:
| 任务 | 描述 | 奖励设置 |
|---|---|---|
| FrozenLake | 网格导航,避开洞口走到终点 | 到达终点得 1.0,否则 0.0 |
| Sokoban | 推箱子谜题 | 解开得 1.0,否则 0.0 |
| HotpotQA | 多跳问答,需要检索工具 | 精确匹配得 1.0,F1≥0.3 给比例奖励 |
前两个任务的特点是:奖励极度稀疏,模型必须在长序列动作后才能知道结果。这正好测试 ERL 的核心能力------从稀疏反馈中学习。
学习效率对比
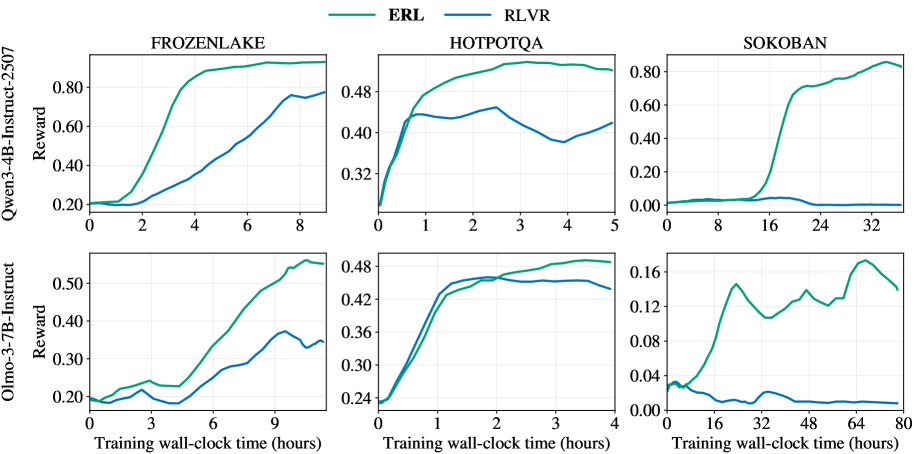
图4:ERL 的学习效率显著高于 RLVR,尤其是在 Sokoban 任务上
从训练曲线可以看出:
- FrozenLake:ERL 收敛更快,最终性能略高
- HotpotQA:两者差距不大(因为这个任务的反馈相对密集)
- Sokoban:ERL 完胜,RLVR 几乎学不动
Sokoban 是最难的------需要长视野规划,一步走错可能全局皆输。RLVR 在这种场景下完全迷失,而 ERL 通过反思机制找到了改进路径。
最终性能对比
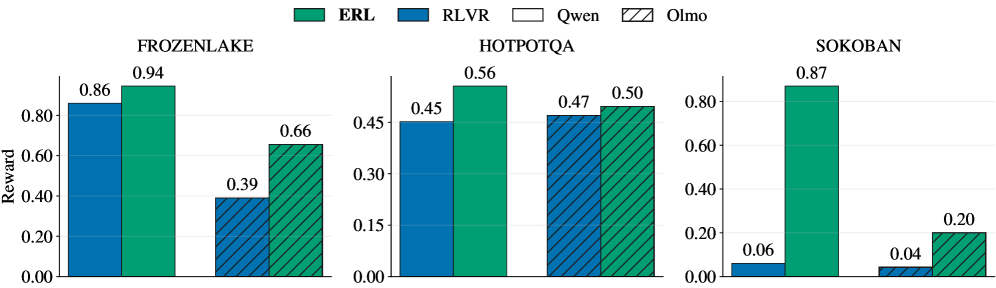
图5:ERL 在所有任务上均优于 RLVR,Sokoban 上差距最大
| 模型 | 任务 | RLVR | ERL | 提升 |
|---|---|---|---|---|
| Qwen3-4B | FrozenLake | 0.86 | 0.94 | +8% |
| HotpotQA | 0.45 | 0.56 | +11% | |
| Sokoban | 0.06 | 0.87 | +81% | |
| Olmo-3-7B | FrozenLake | 0.39 | 0.66 | +27% |
| HotpotQA | 0.47 | 0.50 | +3% | |
| Sokoban | 0.04 | 0.20 | +16% |
Sokoban 上的 81% 提升是最惊人的。这说明在需要复杂规划和错误恢复的场景中,结构化反思机制的价值被放大了。
反思前后的性能变化
论文还比较了反思前后(Pre-refl. vs Post-refl.)的性能:
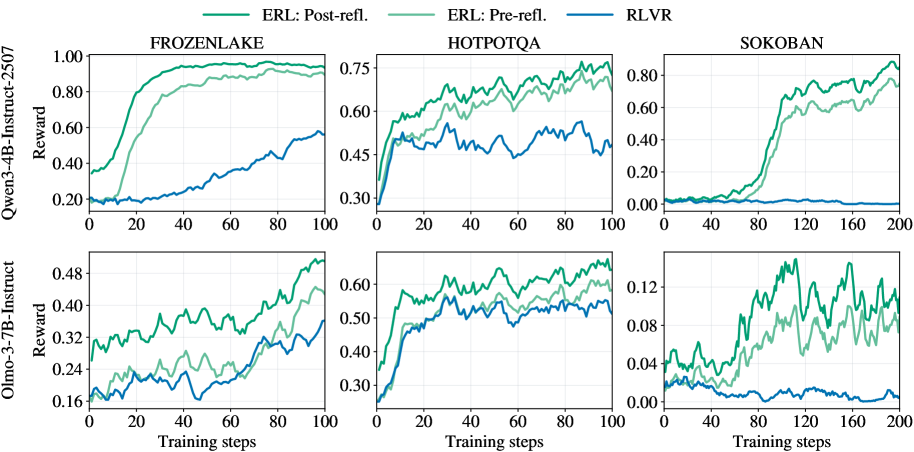
图6:二次尝试(Post-refl.)的性能明显高于首次尝试(Pre-refl.),证明反思确实有效
在 Qwen3-4B 上,反思后的性能在三个任务上分别提升了约 10%、15% 和 60%。这直接证明了反思机制的有效性------它不是白费力气,而是真的帮模型找到了更好的答案。
📊 消融实验:反思和记忆谁更重要?
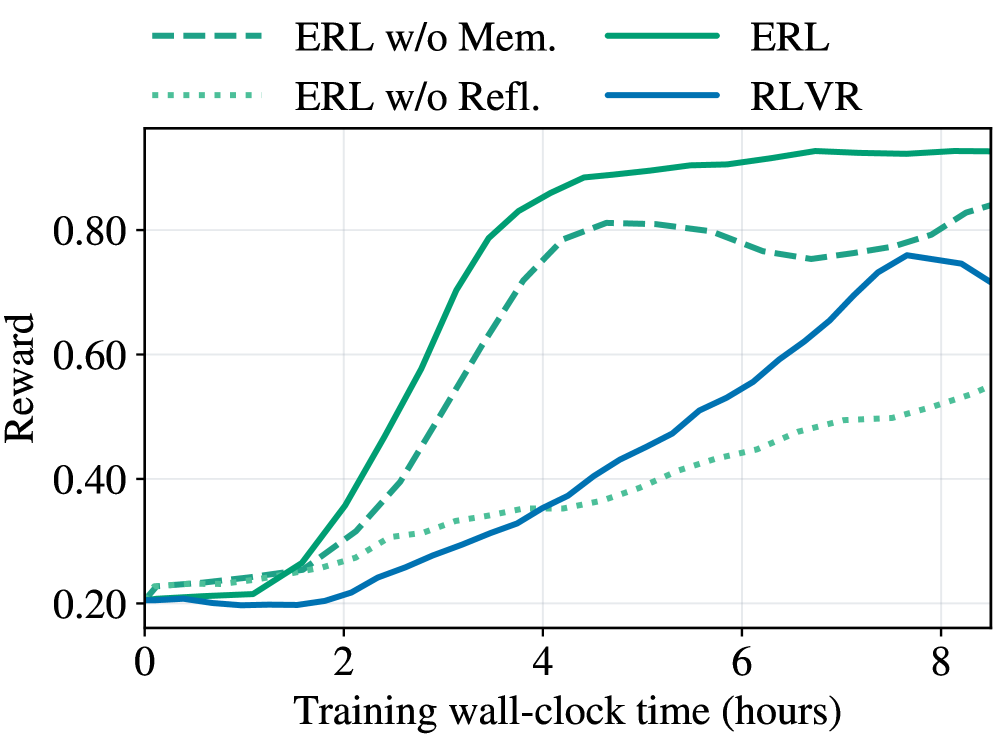
图7:移除反思导致性能大幅下降,移除记忆影响较小
| 变体 | 核心区别 | 性能影响 |
|---|---|---|
| ERL(完整版) | 反思 + 记忆 | 最优 |
| ERL w/o Mem. | 无跨周期记忆 | 略有下降 |
| ERL w/o Refl. | 无结构化反思(只有重试) | 大幅下降 |
关键发现:
反思比记忆重要得多。
移除记忆后,性能只在小幅下降。但移除反思后,性能暴跌。这说明:单纯的"再试一次"是不够的。模型需要显式的反思来指导改进方向,否则就是盲目重试。
💡 我的观点
这个工作的亮点
1. 直觉清晰:把"吃一堑长一智"算法化
"从失败中学习"是人类的核心学习能力。ERL 把这个过程形式化了:失败 → 反思 → 改进 → 内化。这个框架简洁而有力。
2. 零推理成本的设计
很多反思类方法(如 Reflexion、Self-Refine)在推理时需要多轮迭代,增加了延迟和成本。ERL 通过"内化"步骤,把反思能力蒸馏到基础策略中,部署时不需要额外开销。这是一个工程上很务实的设计。
3. 与 GRPO 的良好兼容
ERL 没有发明新的优化器,而是基于 GRPO 做扩展。这意味着它可以被快速集成到现有的 RL 训练流程中。
需要关注的问题
1. 反思质量的上限
反思的质量取决于模型本身的能力。如果模型对某个领域理解不足,它生成的反思可能也是错的。这就像让一个不懂棋的人写棋谱------反思本身可能误导后续尝试。
论文没有深入讨论"反思错误"的情况。在实际应用中,可能需要引入外部验证机制来检查反思的正确性。
2. 计算成本翻倍
ERL 的训练成本大约是 RLVR 的两倍------每个任务要生成两次尝试加一次反思。虽然论文声称计算量相当(ERL 每次生成 4 个样本,RLVR 生成 10 个),但这种比较是否公平还有待商榷。
3. 记忆的负面效应
消融实验中有个有趣的发现:Olmo-3-7B 在 Sokoban 任务上,无记忆版本反而比完整版略好。作者的解释是:早期不准确的反思被记忆传播后反而阻碍了学习。
这提醒我们:记忆是把双刃剑。如果早期的反思质量不高,记忆可能成为"包袱"而非"财富"。引入记忆老化或质量过滤机制可能是必要的。
与其他反思方法的对比
| 方法 | 反思时机 | 推理成本 | 训练成本 |
|---|---|---|---|
| Reflexion | 推理时反思 | 高 | 低 |
| Self-Refine | 推理时迭代 | 高 | 低 |
| ERL | 训练时反思 | 低 | 高 |
ERL 的定位很清晰:用训练时的计算换取推理时的效率。如果你的应用场景对延迟敏感,ERL 是更好的选择;如果你有充足的推理预算,Reflexion 可能更灵活。
工程落地的思考
如果要落地 ERL,我会关注以下几点:
-
反思模板设计:论文没有详细展示反思的格式。在实际应用中,可能需要设计结构化的反思模板(如"错误原因 → 改进策略"),帮助模型生成高质量的反思。
-
记忆管理策略:跨周期记忆需要管理。可以考虑引入记忆淘汰机制,删除过时或低质量的反思。
-
多轮反思:论文只设计了一次反思。在更复杂的任务中,可能需要多轮反思循环。但这会增加训练复杂度。
-
与其他技术的结合:ERL 可以和其他 RL 技术结合,比如奖励塑形(Reward Shaping)、课程学习(Curriculum Learning)等,进一步提升学习效率。
🔗 相关工作对比
| 方法 | 核心机制 | 特点 |
|---|---|---|
| RLVR | 直接从奖励学习 | 简单但稀疏奖励下效果差 |
| Reflexion | 推理时自我反思 | 提升推理效果但增加延迟 |
| Self-Refine | 迭代式自我修正 | 需要多轮推理 |
| Reward Shaping | 设计密集奖励 | 需要领域知识 |
| ERL | 训练时反思 + 内化 | 零推理成本 |
ERL 的独特价值在于:它不需要人工设计奖励函数,也不增加推理成本,却能从稀疏反馈中高效学习。
📚 总结
ERL 的核心贡献是:把"反思"从一个推理时的技巧变成了训练时的能力。
通过显式的"尝试-反思-改进"循环,模型学会了把模糊的失败信号转化为具体的行为修正。这些修正通过内化蒸馏到基础策略中,在部署时无需额外开销。
用一句话概括:失败不可怕,可怕的是失败了不知道为什么。ERL 让模型学会了写"错题本"。
当强化学习遇到稀疏奖励瓶颈时,显式反思可能是打破僵局的关键。
论文信息:
- 标题:Experiential Reinforcement Learning
- arXiv:https://arxiv.org/abs/2602.13949
- 作者:Taiwei Shi, Sihao Chen, Bowen Jiang, Linxin Song, Longqi Yang, Jieyu Zhao