为什么会有排序
排序算法的核心作用就是把混乱的数据变规整,一方面能让查找、去重、合并这些常见操作的效率呈几何级提升,另一方面它也是数据库、搜索引擎、排行榜等各类软件功能的底层基础 ------ 没有排序,很多高效的数据处理逻辑根本无法实现
排序的应用
把一组无序 的数据,按照从小到大 或从大到小 的规则,重新排成有序序列
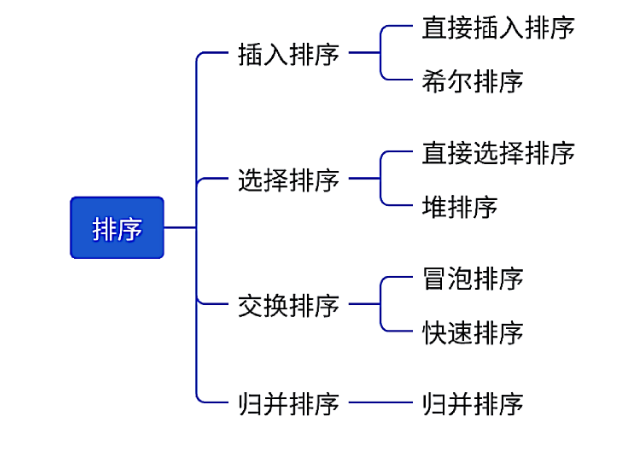
常见的排序算法
直接插入排序
插入排序(Insertion Sort)是一种简单直观的排序算法,它的核心思想特别像我们整理扑克牌的过程:
- 想象你手里抓着一把乱序的牌,从第二张开始,你会把它和前面已经排好序的牌逐一比较,找到它应该插入的位置,然后把它放进去。
- 对于数组来说,就是把数组分为「已排序区间」和「未排序区间」,初始时已排序区间只有第一个元素;然后依次从未排序区间取出元素,插入到已排序区间的合适位置,直到所有元素都完成插入
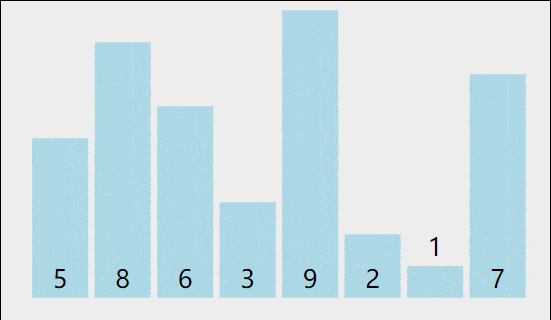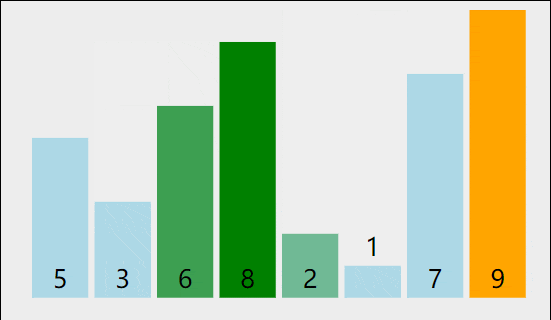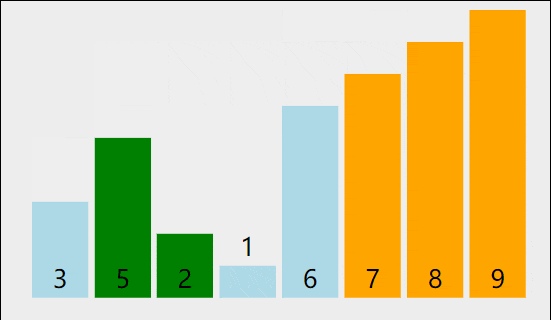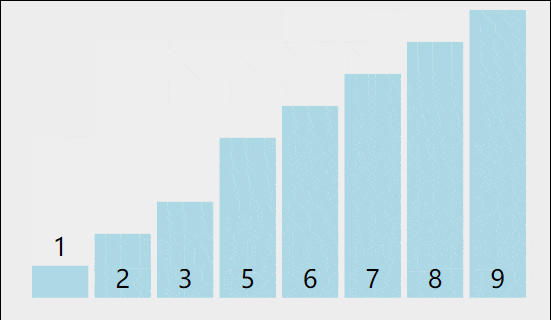
我们可以把第一个想成A把第二个想成B,当A大于B的时候a就要往后挪,B就排在a的前面以此类推的过程,但是如果A比B要小就不动,这里我们可以想像成一个数组的形式,数据量从0到end+1
假如0到end的值是有序的,但end+1的值要插入进去,这个时候就要比较 谁比end+1大,大的就往后移,直到遇到比end+1要小或者等于的值就停下来插入,这里我们还是通过模块的形式呈现
int end = i;
int tmp = a[end + 1];这两行代码是定义倒数第二个下标和最后一个下标 ,为什么我们还要把最后一个值存入一个局部变量?因为如果前一个数比后一个数要大,就会先把前一个数往后移,就会覆盖掉最后一个数
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
a[end + 1] = tmp;这里是我们写的单次 的排序结果,如果前一个数比后一个数要大,就往后移,然后插入到前一个数的位置,然后end就自减1,回到当前位置的前一个数,如果前一个数比后一个数要小就停止,依次循环,直到end移动到0的左边结束,但是这里我们只写了单次的并没有写循环所以我们要把循环写在外面
void InsertSort(int* a, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}为什么外层循环我们的I要小于n-1呢?因为i是下标,当i到达n-1这个位置的时候说明下标已经到了最后一个数,但是到了最后一个数我们怎么和他最后一个数后面那个数比较?所以这个时候就会报错,我们就把循环定在n-1之前的那个位置才能保证最后一个数存在这个数组里面
现在我们来测试一下
//声明
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#pragma once
void PrintSort(int* a, int n);
void InsertSort(int* a, int n);
#define _CRT_SECURE_NO_WARNINGS
#include"Sort.h"
void TestInsertSort()
{
int a[] = { 7,8,3,5,4,1,2,6,9 };
int sc = sizeof(a) / sizeof(a[0]);
InsertSort(a, sc);
PrintSort(a, sc);
}
int main()
{
TestInsertSort();
return 0;
}
直接插入排序的时间复杂度
最好情况:当i=0的时候外层循环执行1次,内层循环i=0时进入while循环都是前一个大于当前这个数就会执行break语句,然后交换,不管i是几,每一次进入while循环都执行break语句的话说明i每一次都执行一次,时间复杂度就是O(N)
最坏情况:当i=0的时候外层循环执行1次,内层循环i=0时进入while循环执行1次,当i=1的时候外层循环执行1次,内层循环i=1时,前面的数小于当前数就会执行if语句,end自减1,再次进入while循环,直到end小于0,所以i=1时进入while循环执行2次,当i=2时就执行while3次,时间复杂度就是O(N^2)
希尔排序
插入排序的优化版,通过「分组预排序 + 逐步缩小间隔」提升效率 ------ 先按大间隔将数组分成多个子序列做插入排序(让数组 "基本有序"),再不断缩小间隔,最终间隔为 1 时做一次插入排序此时效率极高
希尔排序的作用
当一个数组比较接近有序的 时候直接插入排序是挺有用的 ,但是假设一个数组是完全逆序也就是最坏情况的时候,每次要排序的数字都需要一直判断到开头才能插入,使得时间复杂度为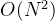 ,这种复杂度不是我们能接受的,所以希尔排序就出现了
,这种复杂度不是我们能接受的,所以希尔排序就出现了
希尔排序逻辑分析
把数组按递减的间隔(gap) 分组做插入排序,先让数组「基本有序」,最后间隔缩到 1 时做一次普通插入排序,用 "大步快调 + 小步微调" 的方式,大幅降低插入排序的时间成本
希尔排序代码实现
我们就将整个代码分开进行讲解,在实现预排序之前我们先把每一组的排序代码实现一遍我们就以gap = 3,gap是几就间隔几组
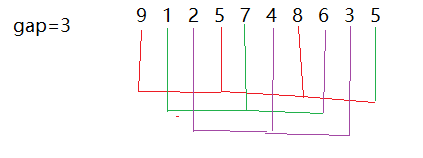
后一个数比前一个数要小就交换位置
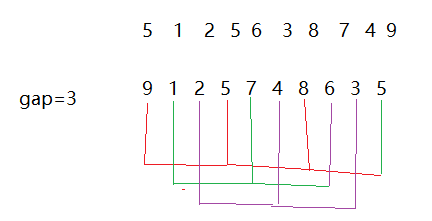
目前他并没有有序,但是他相比之前是不是更接近有序了,大的数到后面去了小的数就更接近前面了,那现在我们进行插入排序就更快了,如果我们把gap设大一点,就很快到大的值就到后面去了
void ShellSort(int* a, int n)
{
int gap = 3;
for (int j = 0; j < gap; j++)
{
for (int i = j; i < n - gap; i+=gap)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
但是并没有实现正确的排序,我们先不管结果是否正确,我们先来把三层循环优化成两层循环
void ShellSort(int* a, int n)
{
int gap = 3;
for (int i = 0; i < n - gap; ++i)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}现在我们就来解决排序输出的问题,先说结论:
- gap越大,大的可以越快跳到后面,小的可以越快跳到前面,但越不接近有序
- gap越小,跳得越慢,但越接近有序,当gap==1相当于插入排序
那现在我们就从gap下手
int gap = n;
while (gap > 1)
{
//+1保证最后一个gap一定是1
//gap>1时是预排序
//gap==1时是插入排序
gap = gap / 3+1;这里gap除3是一个比较好的选择,有可能最后的gap会被整除,+1保证最后一个gap一定是1
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3+1;
for (int i = 0; i < n - gap; ++i)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
printf("gap:%2d\n", gap);
PrintSort(a, n);
}
}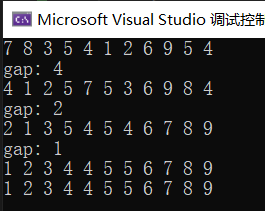
这里就证明了我们之前的结论