字符串哈希
文章目录
- 字符串哈希
-
- 一、前言
- 二、字符串哈希
-
- [2.1 概念](#2.1 概念)
-
- [2.1.1 哈希](#2.1.1 哈希)
- [2.1.2 哈希函数](#2.1.2 哈希函数)
- [2.1.3 冲突/哈希碰撞](#2.1.3 冲突/哈希碰撞)
- [2.1.4 字符串](#2.1.4 字符串)
- [2.1.5 字符串哈希](#2.1.5 字符串哈希)
- [2.2 性质](#2.2 性质)
- [2.3 问题汇总](#2.3 问题汇总)
- [2.4 字符串哈希函数的选取](#2.4 字符串哈希函数的选取)
-
- [2.4.1 概述](#2.4.1 概述)
- [2.4.2 好处](#2.4.2 好处)
- [2.4.3 过程](#2.4.3 过程)
- [2.5 降低哈希碰撞](#2.5 降低哈希碰撞)
- [2.6 例题](#2.6 例题)
-
- [2.6.1 洛谷](#2.6.1 洛谷)
- [2.6.2 leetcode](#2.6.2 leetcode)
- 三、小结
一、前言
今天,是字符串哈希
二、字符串哈希
2.1 概念
2.1.1 哈希
将一个数据,经过哈希函数,映射到一个值域较小,方便比较的范围。(哈希查找)
2.1.2 哈希函数
哈希函数的构造方法(直接定址法等)选择合适的哈希函数,尽可能减少冲突。
哈希函数多使用多项式函数。
cpp
// 一次函数
f(x) = a*x + b;
// 二次函数
f(x) = a*x^2 + b*x + c;
// 三次函数
f(x) = a*x^3 + b*x^2 + c*x + d;2.1.3 冲突/哈希碰撞
将多个数据映射为同一个数字。
注意:冲突无法完全避免,只能尽可能的减少
解决冲突:开放地址法(线性探测法,二次探测法)、链地址法。
2.1.4 字符串
字符串 VS 字符数组
字符串最后默认有一个\0,字符数组没有
-
子串匹配:S是模式串,P是主串,看主串里是否含有模式串
可以将模式串的哈希值求出,将主串中和模式串相等的字串的哈希值求出,进行比较即可
-
子串比较
2.1.5 字符串哈希
通过哈希函数,将字符串转为整数
2.2 性质
- 如果对应的整数(Hash函数值)不一样,两个字符串一定不一样
- 在Hash函数值一样的时候,两个字符串不一定一样(但有大概率一样,且我们当然希望它们总是一样的)。我们将Hash函数值一样但原字符串不一样的现象称为哈希碰撞
2.3 问题汇总
- 如何构造哈希函数
- 如何减少冲突
2.4 字符串哈希函数的选取
2.4.1 概述
通常我们采用的是多项式Hash的方法,对于一个长度为l的字符串s来说,我们可以这样定义多项式Hash函数:其中,M需要选择一个素数(至少要比最大的字符要大),b是一个比最大字符大的整数(ASCII码值比较,根据经验,131 比较好用)
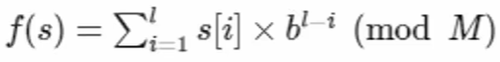
cpp
s = "xyz";
f(s) = xb^2 + yb + z;该函数,实际上是将字符串看成b进制数,和我们平时的将一个某n进制数,变为一个十进制数,相类似。
n进制的数字234,转化为十进制:2 * n^2 + 3 * n^1 + 4 * n^0 = 2 * n^2 + 3 * n + 4
由于算出来的数字可能很大,所以对一个质数M取模(对质数取模,保证冲突相对较低)
2.4.2 好处
方便计算任意子串的哈希值
2.4.3 过程
假设有长度为n的字符串s,假设hash[i]表示子串s[0~i]的哈希值(前缀子串的数组)
cpp
// 求字符串s的哈希值
cin >> s;
n = s.size();
for(int i = 0; i < n; i++)
{
f += s[i] * 27 ^(n-1-i);
}
cout << f;
// 求s的所有子串的哈希值
// 三层循环:枚举起点,枚举终点,求长度,最后一层循环求hash值-
先求前缀子串:
s[0], s[0, 1], s[0~2], ... , s[0~n-1]的哈希值:类似于求前缀和cpp// i = 0时 hash[0] = s[0]; // i > 0时 hash[i] = hash[i-1] * base + s[i]; -
已知前缀子串的哈希值数组,求任意一子串
s[l~r]的哈希值hcpph = hash[r] - hash[l] * base^(r - l + 1)
注意:只针对上面图片显示的哈希函数有这种规律,其他哈希函数就没有了
2.5 降低哈希碰撞
-
对M取模容易出现哈希碰撞,因此M最好是质数
-
M越大,哈希范围也越大,碰撞的可能性越小
M最大可以取多大?
unsigned long long的最大值:2^64 - 1(unsigned long long a;若变量a保存的值超过2^64 - 1会自动对2^64 - 1取余)------自然取余法cpptypedef unsigned long long ull; ull base = 131; ull a[10010]; // a[i]就是第i个字符串对应的哈希值 char s[10010]; int n, ans = 1; ull hashs(char s[]) { int len = strlen(s); ull ans = 0; for(int i = 0; i < len; i++) ans = ans * base + (ull)s[i]; return ans; } int main() { ios::sync_with_stdio(0),cin.tie(0),cout.tie(0); cin >> n; for(int i = 1; i <= n; i++) { cin >> s; a[i] = hashs(s); } sort(a+1, a+n+1); for(int i = 2; i <= n; i++) if(a[i] != a[i-1]) ans++; cout << ans << endl; // 不相等的字符串的数量 return 0; } -
双Hash法:一个字符串用不同的Base和MOD,hash两次,将这两个结果用一个二元组表示,作为一个总的Hash结果。
选择两个10^8级别的质数。只有模这两个数都相等才判断相等。
cppmod1 = 19260817; mod2 = 19660813;cpptypedef unsigned long long ull; ull base = 131; struct data { ull x, y; } a[10010]; char s[10010]; int n, ans = 1; ull mod1 = 19260817; ull mod2 = 19660813; ull hash1(char s[]) { int len = strlen(s); ull ans = 0; for(int i = 0; i < len; i++) { ans = (ans*base + (ull)s[i]) % mod1; } return ans; } ull hash2(char s[]) { int len = strlen(s); ull ans = 0; for(int i = 0; i < len; i++) { ans = (ans*base + (ull)s[i]) % mod2; } return ans; } bool cmp(data a, data b) { return a.x < b.x; } int main() { ios::sync_with_stdio(0),cin.tie(0),cout.tie(0); cin >> n; for(int i = 1; i <= n; i++) { cin >> s; a[i].x = hash1(s); a[i].y = hash2(s); } sort(a+1, a+1+n, cmp); for(int i = 2; i <= n; i++) { if(a[i].x != a[i-1].x || a[i-1].y != a[i].y) ans++; } cout << ans << endl; return 0; }
比较:
- 速度:自然溢出 > 单hash > 双hash
- 安全性:双hash > 单hash
2.6 例题
2.6.1 洛谷
- P3370 【模板】字符串哈希
2.6.2 leetcode
-
28.找出字符串中第一个匹配项的下标
给两个字符串s,p,求s是否是p的子串,并求p在s中出现的第一个位置?
cpp// BF暴力算法(n^2) int flag = 0; for(int i = 0; i < p.size(); i++) // 枚举从p串的i位置开始匹配 { int k = i; int j = 0; for(j = 0; j < s.size(); j++) { if(p[k] == s[j]) { k++; } else { break; } } if(j == s.size()) // 从p中找到s了 { cout << k - s.size() << endl; flag = 1; // 找到答案了 break; } }
三、小结
本篇结合灵神题单等以及我的一些思考等~