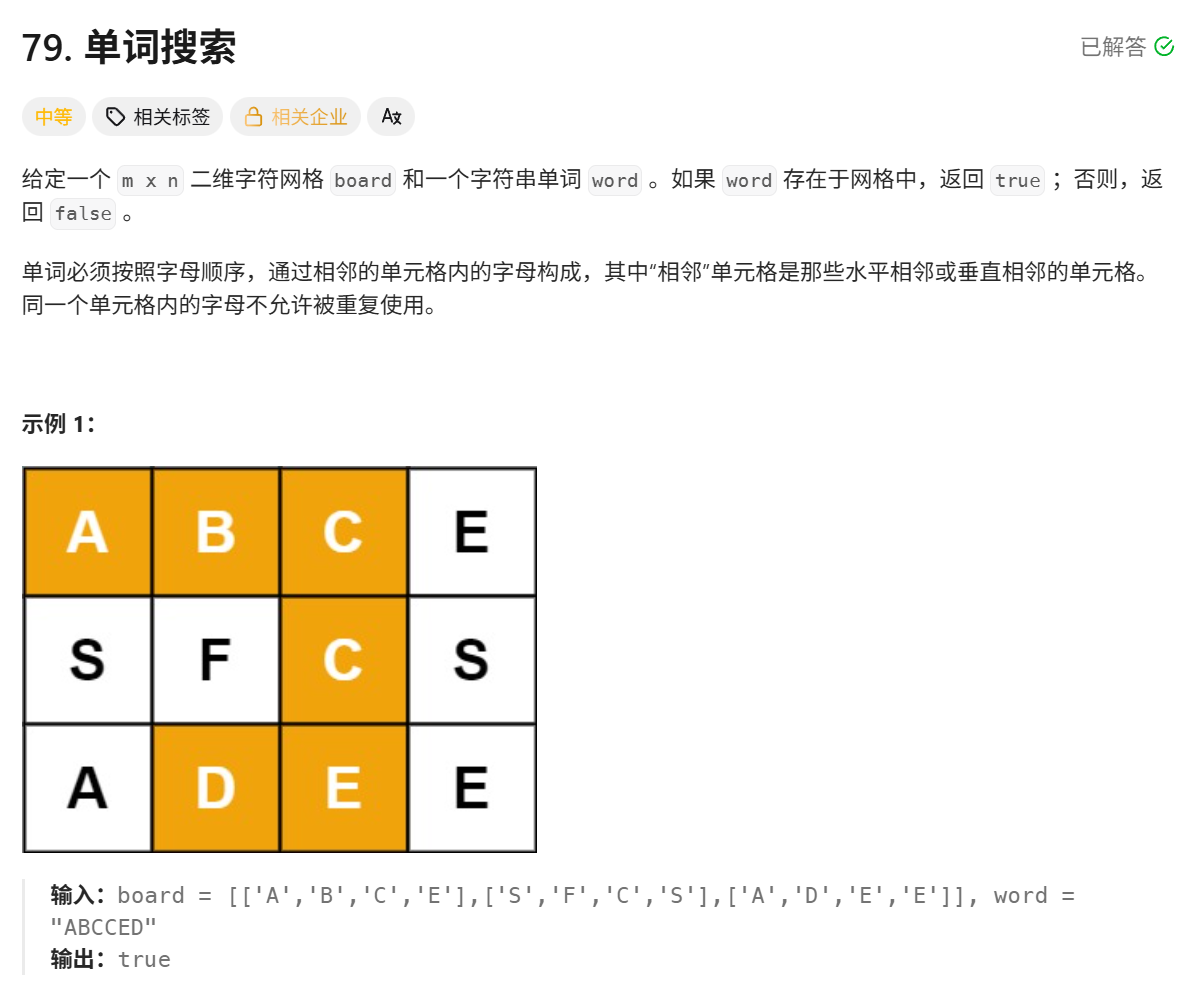
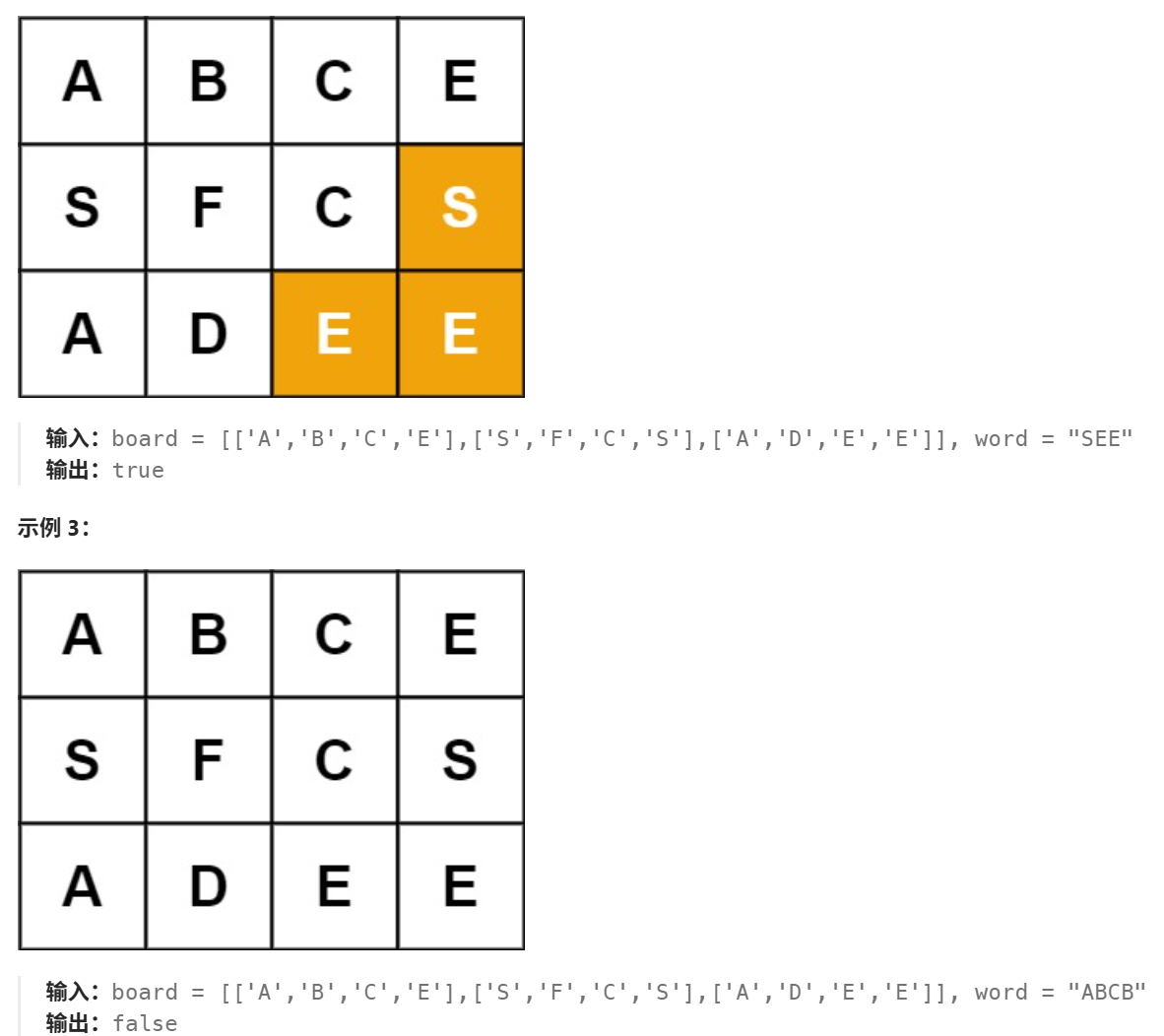
切片回溯(时间超出限制)
bash
tmp | {(i,j)}| 是 Python 集合的并集运算符,表示把 tmp 和 {(i,j)} 合并成一个新的集合
bash
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
m = len(board)
n = len(board[0])
def backtrack(i, j, word, tmp): #(word待选列表,已访问过格子的坐标)
# 匹配完所有字符
if not word:
return True
if i < 0 or i >= m or j < 0 or j >= n:
return False
if (i, j) in tmp:
return False
if board[i][j] != word[0]:
return False
# 四个方向搜索
for dx, dy in [(-1,0),(1,0),(0,-1),(0,1)]:
if backtrack(i+dx, j+dy, word[1:], tmp | {(i, j)}):
return True
return False
# 遍历每个起点
for i in range(m):
for j in range(n):
if backtrack(i, j, word, set()):
return True
return False代码在每一层递归都做了两件"昂贵"的事:
word[1:]:复制字符串,O(L)O(L)O(L)tmp | {(i, j)}:复制集合,O(L)O(L)O(L)
时间复杂度:O(M⋅N⋅3L⋅L)O(M \cdot N \cdot 3^L \cdot L)O(M⋅N⋅3L⋅L)
M,NM, NM,N 为网格大小,LLL 为单词长度。
- 额外的 LLL 开销:字符串切片:word1: 每次都会创建一个长度为 L−1L-1L−1 的新字符串
- 集合拷贝:tmp | {(i, j)} 每次都会复制当前集合中的所有坐标。集合大小最大为 LLL,复制操作耗时 O(L)O(L)O(L)。
- 对比:如果用"原地修改字符"的方法,这部分 O(L)O(L)O(L) 的额外开销可以降到 O(1)O(1)O(1)。空间复杂度:O(L2)O(L^2)O(L2)
空间复杂度:O(L2)O(L^2)O(L2)
- 递归栈深度:O(L)O(L)O(L)
- 堆内存占用:由于每一层都创建了新的 set 和 string,在最深的一条搜索路径上,内存中同时存在着长度分别为 1,2,...,L1, 2, \dots, L1,2,...,L 的集合。总空间消耗约为 1+2+⋯+L=O(L2)1+2+\dots+L = O(L^2)1+2+⋯+L=O(L2)
切片回溯(优化,不超时间)
为什么是if k== len(word):,不是if k== len(word)-1:
k 的语义是:"下一个要匹配的位置"
即 k== len(word): 时
已经没有下一个字符需要匹配了,之前所有字符都匹配成功
不标记会走回头路!
coffeescript
tmp = board[i][j]
board[i][j] = '#'暂时把当前格子变成一个"不可能匹配任何字符"的值,防止下一层递归再次走回这个格子
为什么必须"回溯恢复"?
coffeescript
board[i][j] = tmp那后面从别的起点开始搜索时,这个格子永远是 #,会破坏搜索。
bash
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
m = len(board)
n = len(board[0])
word_len = len(word)
def backtrack(i, j, k): # k 代表当前匹配到 word 的第几个索引
# k 到达最后一位且匹配成功
if k == word_len:
return True
if i < 0 or i >= m or j < 0 or j >= n: # 往上下左右搜,出界
return False
if board[i][j] != word[k]: # 往上下左右搜,匹配不到下一个word字母
return False
# 标记访问(原地修改)
tmp = board[i][j]
board[i][j] = '#'
# 四个方向搜索
for dx, dy in [(-1,0),(1,0),(0,-1),(0,1)]: # 往上下左右搜
if backtrack(i+dx, j+dy, k+1): # 搜到了
return True
# 走到这里,是上下左右,都没搜到
# 撤销标记,回溯恢复
board[i][j] = tmp
return False
# 遍历每个起点
for i in range(m):
for j in range(n):
# 只有首字母匹配才开始搜索
if board[i][j] == word[0]:
if backtrack(i, j, 0):
return True
return False为什么这样就不会超时?
- 指针替代切片:通过 k 传递索引,不再产生新字符串。
- 原地修改替代集合:直接在 board 上改字符(标记为 #),不再创建和拷贝set, 修改一个字符的时间复杂度是 O(1)O(1)O(1)
- 短路返回:if backtrack(...): return
True。一旦找到答案,递归会像多米诺骨牌一样迅速结束,不再继续无谓的搜索。
递归调用栈变化
- 成功路径时栈一层层 return
- 失败路径时逐层撤销
成功路径时栈一层层 return,没有执行恢复操作
因为一旦找到答案,搜索立刻终止,后续路径不再执行
coffeescript
backtrack(0,0,k=0)
标记 A → '#'
↓
backtrack(0,1,k=1)
标记 B → '#'
↓
backtrack(0,2,k=2)
标记 C → '#'
↓
backtrack(..., k=3)
k == len(word)
return True失败路径时逐层撤销,
coffeescript
backtrack(A)
标记 A
↓
backtrack(B)
标记 B
↓
尝试四个方向
全部失败
↓
恢复 B
return False