I.Map类
0x00:介绍
cpp
template <class Key, // map::key_type
class T, // map::mapped_type
class Compare = less<Key>, // map::key_compare
class Alloc = allocator<pair<const Key, T>> // map::allocator_type
> class map;STL是map的关联式容器,按照特定顺序存储关联,由Key 和Value组合而成的元素
𝑣𝑎𝑙={𝑘:𝑣}
它们组合成键值对 ,Key通常用于排序和唯一的表示元素 ,value中存贮与key关联的内容key和value的类型额可以不同,在map内部,key和value通过成员类型value_type绑定
value_type 实际上就是 pair 类型:
cpp
typedef pair value_type;
底层基于红黑树,是一种自平衡的二叉搜索树,能确保在插入和删除元素时维持良好的性能。map 通常被实现为二叉搜索树 ,更准确地说是平衡二叉搜索树(红黑树)
底层基于红黑树,是一种自平衡的二叉搜索树,能确保在插入和删除元素时维持良好的性能。
0x01 pair类型
map 的insert 接口就是是一个value_type,我们先来搞清楚什么是 value_type。
value_type 实际上就是 pair 类型,在 map 中称之为 键值对
cpp
typedef pair<const Key, T> value_type;pair 是在库里面就定义好了的,SGI-STL 中关于键值对 的定义如下
cpp
template<class T1, class T2>
struct pair {
typedef T1 fisrt_type;
typedef T2 second_type;
T1 first;
T2 second;
pair()
: first(T1())
, second(T2())
{}
pair(const T1& a, const T2& b)
: first(a)
, second(b)
{}
};0x02 map插入(insert)
 我们假设 dict 变量的数据类型为 map<string, string>,我们可以如何插入数据呢?
我们假设 dict 变量的数据类型为 map<string, string>,我们可以如何插入数据呢?
① 我们可以直接调用 pair 的构造函数来插入:
cpp
dict.insert(pair<string, string>("sort", "排序"));② 似乎比较麻烦?我们可以用匿名对象的方式来写:
cpp
pair<string, string> kv("insert", "插入");
dict.insert(kv);③ 还有更爽的方式,调用神奇的 make_pair !我们戏称之为 "做对子" :
cpp
dict.insert( make_pair("left", "左边") );make_pair 是一个函数模板,使用时不用声明参数,可自动推导出对应的类型。
cpp
template<class T1, class T2>
pair<T1, T2> make_pair(T1 x, T2 y) {
return (pair<T1, T2>(x, y) );
}④还有更强大的方式插入,直接用 { } :
cpp
dict.insert( {"right", "右边"} );0x03 遍历
cpp
map<string, string>::iterator it = dict.begin();map 的迭代器的底层相似于链表的迭代器。这里的类型真的是很长,写起来很费劲......
还有 auto 关键字
cpp
auto it = dict.begin();下面我们来写遍历部分,我们发现似乎不行:

当然不行!本质上是因为 C++ 不支持一次返回两个值,这里的 * 就是 it->operator*() 。
但是可以打包,我们可以把这些返回值打包成一个结构数据 ------ pair
这里有两种方法,第一种方法就是在 *it 中分别提取 first 和 second:
cpp
auto it = dict.begin();
while (it != dict.end()) {
cout << (*it).first << ":" << (*it).second << " ";
it++;
}
cout << endl;结果如下:
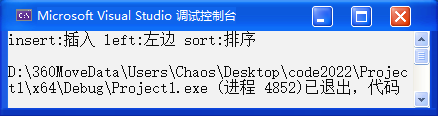
我们可以看到,map 也是会自动排序的。当然,我们还可以用 -> 操作符
cpp
auto it = dict.begin();
while (it != dict.end()) {
cout << it->first << ":" << it->second << " ";
it++;
}
cout << endl;0x04 统计次数方式
现在我们要统计一些数据,比如我们需要统计这些水果的个数:
"苹果", "西瓜", "苹果", "香蕉", "草莓", "柠檬"
"西瓜", "苹果", "柠檬", "柠檬", "西瓜", "橙子"
"草莓", "柠檬", "香蕉", "苹果", "橙子", "柠檬"
我们就可以使用 map 来存储,pair 我们就可以用 string + int 类型来组合
cpp
map<string, int> count_map; // 统计水果的个数我们先用 "最老实" 的方式来进行统计,用迭代器进行检查。
检查很简单,如果这个元素在map 中就次数++,如果不在就将元素 insert 到 map 中:
cpp
map<string,int>CountMap;
for(auto&str:arr){
map<string,int>::iterator it = CountMap.find(str);
if(it!=CountMap.end()){
it->second++;
}
else{
CountMap.insert(make_pair(str,1));//CountMap.insert({str,1});
}打印一下:
cpp
void test_map2() {
string arr[] = {
"苹果", "西瓜", "苹果", "香蕉", "草莓", "柠檬",
"西瓜", "苹果", "柠檬", "柠檬", "西瓜", "橙子",
"草莓", "柠檬", "香蕉", "苹果", "橙子", "柠檬"
};
// 统计
map<string, int> count_map;
for (auto& str : arr) {
map<string, int>::iterator it = count_map.find(str);
if (it != count_map.end()) {
it->second++;
}
else {
count_map.insert(make_pair(str, 1));
}
}
// 打印
for (auto& kv : count_map) {
cout << kv.first << ":" << kv.second << endl;
}
cout << endl;
}结果如下:
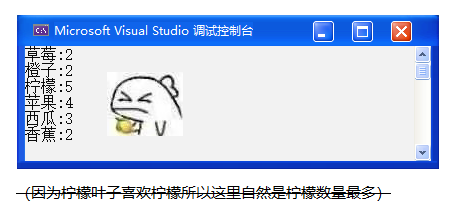
当然,我们也可以这么做:
cpp
for (auto& str : arr) {
pair< map<string, int>::iterator, bool >ret
= count_map.insert(make_pair(str, 1));
}auto一下
cpp
for (auto& str : arr) {
auto ret = count_map.insert(make_pair(str, 1));
}为什么可以这么做呢???
我们来看下 map 的 insert 接口的原型:
cpp
std::pair<iterator, bool>insert(const value_type& value);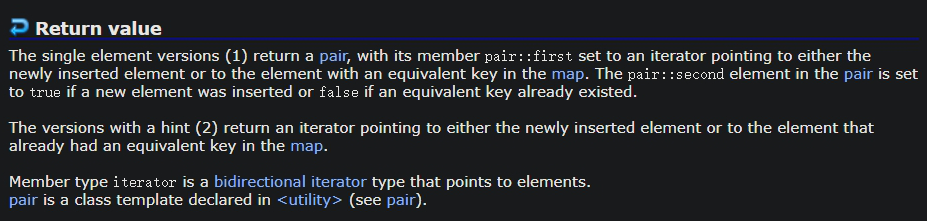
我们可以看到 insert 的返回值是一个 pair<iterator, bool> 类型。
插入成功, second 就是 true;如果插入失败, second 就是 false。
cpp
map<string, int> count_map;
for (auto& str : arr) {
auto ret = count_map.insert(make_pair(str, 1));
if (ret.second == false) {
ret.first->second++;
}
}结果如下:
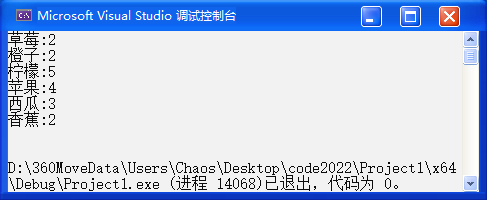
🔑 解读:ret.first->second++ 不好理解?实际上这里是两个pair 嵌套在一块的!一个 pair 是 insert 的返回值,一个 pair 是节点。insert 的返回值里是 pair<iterator, int> ,其中第一个是迭代器,所以我们取first 。而迭代器里是节点 pair<string, int> ,我们要让次数 +1,所以我们节点里我们取 second。
实际运用中这两种方法我们几乎都不用,因为有更加🐂🍺的方式!非常恐怖的方式!
cpp
for (auto& str : arr) {
count_map[str]++;
}下面我们来看一下operator\[\]
0x05 map::operator\[\]
底层:
cpp
mapped_type& operator[] (const key_type& k) {
return (*((this->insert(make_pair(k, mapped_type()))).first)).second;
}好长的一段啊!!!这也太复杂了吧!!!我们让他简洁一些:
cpp
mapped_type& operator[] (const key_type& k) {
pair<iterator, bool> ret = insert(make_pair(k, mapped_type()));
// return (*(ret.first)).second;
return ret.first->second;
}🔑 解读:目的是在关联容器中通过键访问元素,如果元素不存在,则插入一个具有默认值的新元素,并返回对这个元素的引用。首先 const key_type& k 是传入的键,表示要查找或插入的元素的键值 。make_pair(k, mapped_type()) 创建了一个 pair 对象 ,该对象的第一个元素是传入的键 k,第二个元素是使用 mapped_type 的默认构造函数创建的默认值。this->insert(...) 调用关联容器的 insert 函数,该函数用于将一个键-值对插入容器中。返回值是一个pair ,其first 成员指向插入的元素 ,second 成员指示是否插入成功 。(this->insert(...).first) 获取返回的 std::pair 对象的 first 成员,即指向插入的元素的迭代器。*((this->insert(...).first)) 解引用上一步中获取的迭代器,得到插入的元素。(*((this->insert(...).first)).second 再次解引用,获取插入的元素的 second 成员,即与传入的键关联的值。return (*((this->insert(...).first)).second; 返回通过**operator\[\]**访问或插入的元素的引用。
这样就使得operator\[\]的实现:如果是第一次出现,就先插入。插入成功后会返回插入的节点中的次数 0 的引用,对它 ++ 后变为 1。如果是第二次插入,插入失败,会返回它所在节点的迭代器的次数,再 ++。
II.Map算法题
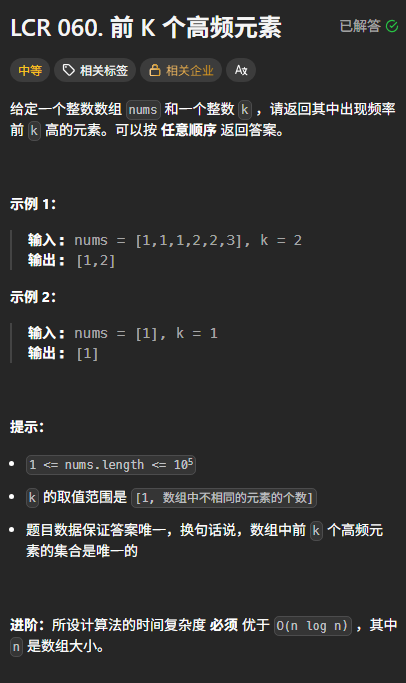
cpp
class Solution {
public:vector<int> topKFrequent(vector<int>& nums, int k) {我们看到题目中提到要记录整数K的出现频率,除了暴力解法的遍历之外,还可以想到使用map<int,int> CountMap 来解决,第一个int表示记录的元素值,第二个int表示出现的次数
那么这道题的解法就很明了了
方法一:TopK问题,我们可以使用堆来求解,这道题我们直接建立一个容量为K的最小堆
cpp
class Solution {
public:
//仿函数,出现频率更高的插入到最小堆
struct Comp{
bool operator()(const pair<int,int> &a,const pair<int,int> &b){
return a.second>b.second;
}
};
vector<int> topKFrequent(vector<int>& nums, int k) {
//定义Map来存储数据和出现次数
unordered_map<int,int> mp;
for(auto m:nums){
mp[m]++;
}
//建立最小堆
priority_queue<pair<int,int>,vector<pair<int,int>>, Comp> pq;
int c=0;//记录堆内元素个数
for(auto m:mp){
if(c<k){
pq.push(m);//堆大小不足K,直接入堆
c++;
}
else{
// cout<<m.first<<" "<<m.second<<endl;
//堆已满K个元素,档期那数字的频率>堆顶最小频率时
if(m.second>pq.top().second){
//cout<<m.second<<endl;
pq.pop();//弹出堆顶
pq.push(m);//加入当前更大频率的数字
}
}
}
//从最小堆中取出前K个元素,存入vector中返回
vector<int> ans;
for(int i=0;i<k;i++){
ans.push_back(pq.top().first);
pq.pop();
}
return ans;
}
};
priority_queue<
pair<int,int>, // 第1个:堆里存什么类型 <数字,频率>
vector<pair<int,int>>, // 第2个:底层容器(固定写法)
Comp // 第3个:比较规则(我们写的最小堆规则)
> pq;方法二:快速选择
cpp
class Solution {
public:
struct Compare{
bool operator()(const pair<int,int>& kv1,const pair<int,int>& kv2)
{
return kv1.second>kv2.second;
}
};
vector<int> topKFrequent(vector<int>& nums, int k) {
//创造一个map来计数,first:int ,因为这是个整数数组
//second:int ,计数
map<int,int>CountMap;
for(auto&e:nums){
CountMap[e]++;
}
//放到vector里面排序
vector<pair<int,int>> v(CountMap.begin(),CountMap.end());
sort(v.begin(),v.end(),Compare());
//前k个
vector<int> ret;
int i = 0;
while(k--)
{
ret.push_back(v[i++].first);
}
return ret;
}
};