## 写在前面:为什么我们需要 AI?
我们得先想明白一个问题。
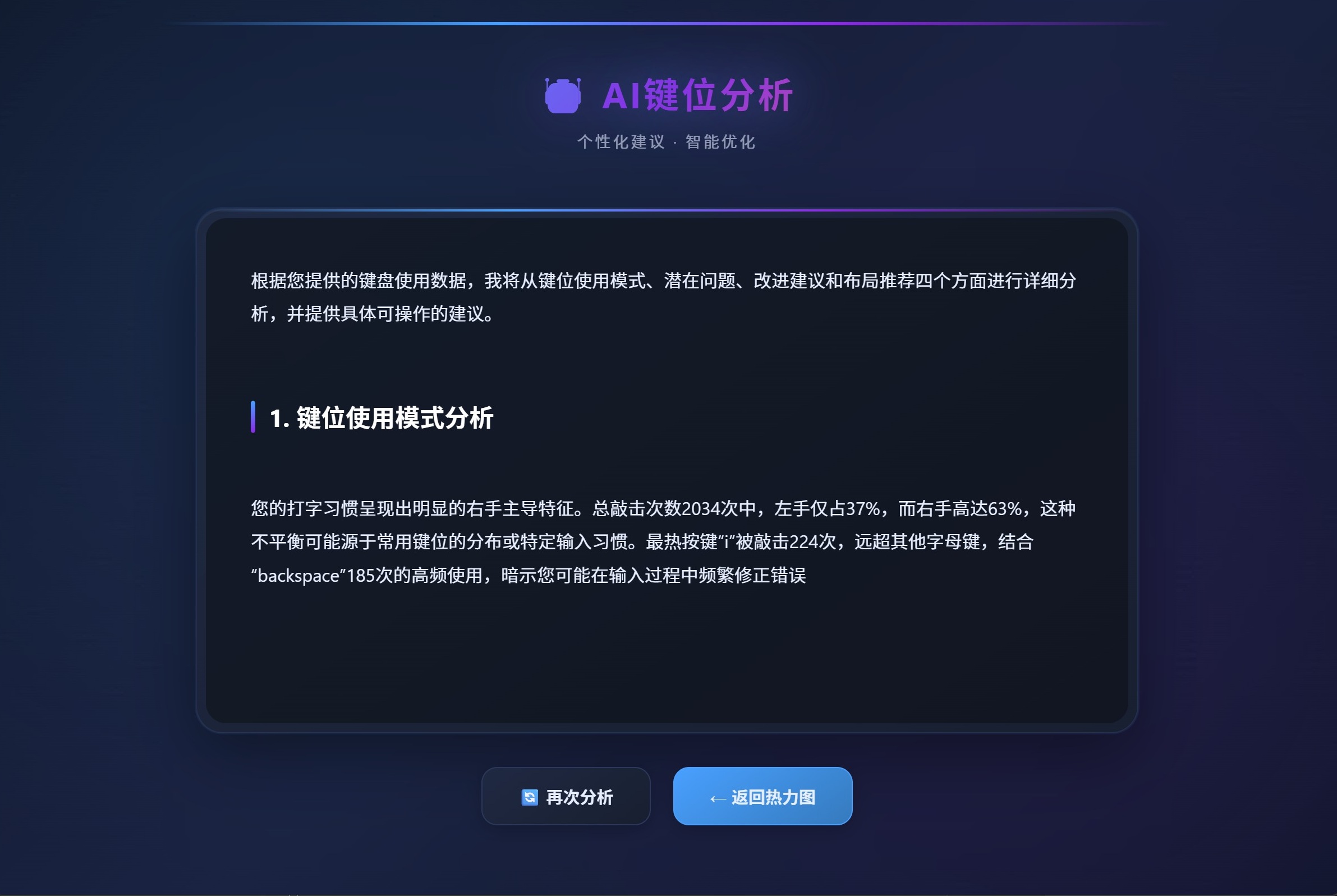
前三篇我们干了什么?我们让 TypeWell 能听见 每一次敲击,能看见 手指的压力分布,还能在累的时候放松一下。
但你想过没有------用户看到满键盘的红红黄黄,看到"左手食指 1024 次",然后呢?
然后他们该干嘛?
这就是我要跟你聊的认知缺口:
数据是数据,知识是知识,行动是行动。这三者之间,隔着一条鸿沟。
普通工具给你数据,让你自己想办法。好一点的工具给你统计,让你自己分析。但 TypeWell 想做的是给你行动指南------直接告诉你"该怎么做"。
这就是 AI 键位分析的价值:把冷冰冰的数字,变成有温度的人话。
开源仓库地址:Gitee TypeWell 雪豹同志
如果对你有帮助,欢迎 Star ⭐️
一、先搭骨架:整个功能的流程设计
写代码之前,我们要先想清楚一件事:用户是怎么用这个功能的?
把你自己想象成一个普通用户:
- 你用了半天 TypeWell,键盘上已经五颜六色了
- 你好奇:"我这样打字到底健不健康?"
- 你点了"AI键位分析"按钮
- 页面跳转,看到一行字:"正在获取你的键盘使用数据..."
- 然后文字开始一行一行往外蹦,像有人在打字一样
- 最后看到:"建议你把 E 键的活儿分给右手中指一点"
这个流程里,藏着几个必须解决的技术问题:
| 用户感受 | 背后技术 |
|---|---|
| 一点按钮就跳转 | 前端跳转逻辑 |
| 页面自动开始分析 | 后端检测页面加载 |
| "正在获取数据" | 进度提示 |
| 文字一行一行蹦 | 流式响应 |
| 像有人在打字 | 实时渲染 |
| 最后给建议 | 提示词工程 |
这一篇,我们就一个一个解决。
二、UI 触发:从点击到开始分析
先看最简单的部分:用户点了按钮,怎么跳转到分析页面?
打开 index.html,找到那个"AI键位分析"按钮:
html
<button class="btn focus-btn" id="aiAnalysisBtn">AI键位分析</button>然后在 script.js 里找到它的点击事件:
javascript
document.getElementById('aiAnalysisBtn').addEventListener('click', function() {
window.location.href = 'ai-analysis.html';
});就这么简单------window.location.href 一赋值,页面就跳了。
思考一下:为什么不用 AJAX 局部刷新,而要整个页面跳转?
因为 AI 分析页面是独立的功能模块 ,有自己的布局、自己的样式、自己的交互逻辑。硬塞在主页里,会让代码乱成一锅粥。分而治之,是程序员的基本素养。
三、自动触发:页面加载完就开始分析
现在用户到了 ai-analysis.html,看到了一个漂亮的加载动画。然后呢?
等着用户再点一次"开始分析"吗?没必要。
好的设计是替用户多想一步 ------用户既然点进来了,就是想分析。那我们就在页面加载完自动开始。
怎么实现?看 main.py 里的 on_page_loaded 方法:
python
def on_page_loaded(self, ok):
if ok:
# 页面加载成功的逻辑
current_url = self.webview.url().toString()
# 关键判断:当前是不是 AI 分析页面?
if 'ai-analysis.html' in current_url:
print("检测到 AI 分析页面,开始分析键盘数据")
self.analyze_keyboard_data() # 自动开始分析
else:
self.update_frontend() # 普通页面就正常更新这里有个重要的思维方法 :根据上下文决定行为。
同一个 on_page_loaded 函数,不能写死一种行为。要根据当前是哪个页面,决定干什么:
- 在主页 → 更新热力图
- 在分析页 → 开始 AI 分析
- 在专注模式 → 啥也不干(动画自己跑)
这就是状态驱动的编程思想。
四、数据准备:喂给 AI 之前要加工
现在进入了 analyze_keyboard_data 函数。第一步是告诉用户"我正在干活":
python
def analyze_keyboard_data(self):
# 第一步:给用户反馈
self.update_frontend_signal.emit('progress', '正在获取键盘使用数据...')为什么要先发这个信号?
因为用户心理有个耐受时间------超过 0.5 秒没反应,就会觉得"卡了"。超过 2 秒没反应,就可能关掉重开。
所以我们要先给个反馈:"我收到了,正在干活,别急。"
4.1 从数据库读数据
python
try:
conn = sqlite3.connect('keyboard_heatmap.db')
c = conn.cursor()
c.execute("SELECT key, count FROM key_usage")
keyboard_data = dict(c.fetchall())
conn.close()这里有个细节:dict(c.fetchall()) 直接把查询结果转成了字典。因为 fetchall() 返回的是 [(key1, count1), (key2, count2)] 这样的列表,传给 dict() 正好变成 {key1: count1, key2: count2}。
思考:为什么不直接用列表,非要转成字典?
因为后面我们要频繁地按键名取值 ------left_hits = sum(keyboard_data.get(key, 0) for key in left_hand_keys)。字典的查询是 O(1),列表查询是 O(n)。一万次按键数据,用列表能卡死。
这就是数据结构决定算法效率的道理。
4.2 处理空数据的情况
python
if total_hits == 0:
self.update_frontend_signal.emit('error', '暂无键盘使用数据,请先使用键盘后再进行分析')
return这里又是一个设计点:用户可能刚打开软件就点进来,数据库里一条数据都没有。这时候强行分析,AI 也只能说"没有数据",没意义。
所以我们要提前拦截,给个友好的提示,然后 return 出去。
防御性编程的思维:不要假设用户会按你的预期操作。
4.3 计算统计指标
接下来是最关键的数据加工环节:
python
# 总次数
total_hits = sum(keyboard_data.values())
# 最热按键
hottest_key = max(keyboard_data, key=keyboard_data.get)
hottest_key_count = keyboard_data[hottest_key]max(keyboard_data, key=keyboard_data.get) 这行代码值得讲一讲:
keyboard_data是字典,直接max()会取最大的键(按字母序)- 但我们想要的是值最大的那个键
- 所以传入
key=keyboard_data.get,告诉 max:比较的时候用keyboard_data.get(每个键)的结果来比
这是 Python 里一个很实用的技巧,记下来。
4.4 左右手分区
python
left_hand_keys = ['q', 'w', 'e', 'r', 't', 'a', 's', 'd', 'f', 'g',
'z', 'x', 'c', 'v', 'b', '1', '2', '3', '4', '5',
'tab', 'caps', 'left shift', 'left ctrl']
right_hand_keys = ['y', 'u', 'i', 'o', 'p', 'h', 'j', 'k', 'l', ';',
'n', 'm', ',', '.', '/', '6', '7', '8', '9', '0',
'-', '=', 'backspace', 'enter', 'right shift', 'right alt']注意看 :这里用的是 left shift 和 right shift,不是统一的 shift。
这就是第一篇里我们保留左右键的原因------为了这一刻的分析。
如果当时我们图省事,把所有 shift 都统一成 shift,现在就分不清左手小指和右手小指谁更累了。
设计的延续性:好的设计要为未来留余地。
python
left_hits = sum(keyboard_data.get(key, 0) for key in left_hand_keys)
right_hits = sum(keyboard_data.get(key, 0) for key in right_hand_keys)
hand_balance = round((left_hits / total_hits) * 100) if total_hits > 0 else 50sum() 里用生成器表达式,比写循环更简洁。keyboard_data.get(key, 0) 保证了即使某个键没出现过,也不会报错,而是返回 0。
五、提示词工程:教 AI 说人话
这是全篇最难的部分,也是 AI 分析能不能用的关键。
很多初学者会这样写提示词:
python
prompt = f"分析这些数据:{keyboard_data}"结果 AI 返回:
根据数据分析,您按了 q 键 23 次,w 键 45 次,e 键 67 次...废话,用户自己不会看吗?
我们要的是洞察,不是复述。
5.1 结构化思维
先想清楚:一份好的键位分析,应该包含哪些内容?
我自己列了个清单:
- 总体情况:今天敲了多少次,大概什么强度
- 左右手平衡:是不是一只手在摸鱼,另一只手在拼命
- 手指负荷:哪根手指最累,哪根最闲
- 异常模式:有没有不合理的按键习惯
- 具体建议:可以怎么改进
- 装备建议:需不需要换键盘
有了这个清单,才知道提示词里该要什么。
5.2 完整的提示词模板
python
def generate_analysis_prompt(self, keyboard_data):
# 前面计算的统计指标
# ...
prompt = f"""请分析以下键盘使用数据,并提供个性化的键位使用建议:
## 一、统计数据
- 总敲击次数:{total_hits}
- 最热按键:{hottest_key} ({hottest_key_count}次)
- 左手敲击:{left_hits} 次
- 右手敲击:{right_hits} 次
- 左右平衡:{hand_balance}% 左手,{100 - hand_balance}% 右手
## 二、详细键位数据(使用频率最高的 20 个按键)
"""
# 按次数排序,只显示前 20
sorted_keys = sorted(keyboard_data.items(), key=lambda x: x[1], reverse=True)[:20]
for key, count in sorted_keys:
prompt += f"- {key}: {count}次\n"
prompt += """
## 三、请从以下维度进行分析
1. **使用模式分析**:用户主要用哪些手指?打字习惯偏向左手还是右手?
2. **潜在风险识别**:是否存在左右手严重不平衡?某根手指负荷是否过重?
3. **具体改进建议**:给出可操作的调整方案,例如"尝试将部分 E 键操作分配给右手中指"
4. **键盘布局建议**:如果适用,推荐更适合用户的键盘布局或设备
## 四、输出要求
- 分析要专业、详细
- 不要使用表格(用户看不懂)
- 语气要像一位温和的健康教练,而不是冷冰冰的机器
- 给出具体、可执行的动作建议
"""
return prompt5.3 提示词设计的四个原则
原则一:结构化
用 ## 一、统计数据 这样的标题把内容分成块。AI 看到这种结构,就知道应该按这个框架输出。
为什么? 因为 AI 的训练数据里,这种格式的文章通常质量较高。你给 AI 什么格式,它倾向于用类似的格式回复。
原则二:给例子
"例如'尝试将部分 E 键操作分配给右手中指'" 这句话很关键。
AI 需要知道你说的"具体建议"长什么样。不给例子,它可能给出"请改善您的打字习惯"这种正确的废话。给了例子,它就知道要模仿这种格式。
原则三:限制范围
"使用频率最高的 20 个按键"------为什么是 20,不是全部?
因为用户根本看不完。人脑的短期记忆容量是有限的,给太多数据,用户反而抓不住重点。少即是多。
原则四:定调子
"语气要像一位温和的健康教练"------这很重要。
同样的内容,用不同的语气说,效果天差地别:
"左手食指负荷过重,建议调整"
(像医生诊断,冷冰冰)
"你左手食指今天辛苦了,按了 1024 次。要不要试试让它休息一下?"(像朋友关心,有温度)
AI 可以模仿这两种语气,关键看你怎么引导。
六、流式响应:让用户看着 AI 思考
提示词准备好了,接下来是怎么调用 API。
6.1 为什么不能在主线程调用?
这是很多初学者会犯的错误:
python
# ❌ 错误示范
def analyze_keyboard_data(self):
response = client.chat.completions.create(...) # 可能耗时 3-5 秒
# 这 3-5 秒里,整个窗口卡死,无法响应任何操作网络请求是不可控的------可能 1 秒返回,也可能 10 秒。在这期间,UI 线程被阻塞,用户点哪里都没反应,体验极差。
黄金法则:任何可能耗时的操作,都要放到子线程。
6.2 子线程的写法
python
def analyze_keyboard_data(self):
# ... 前面的数据准备
# 启动子线程处理 AI 分析
import threading
thread = threading.Thread(target=self.process_ai_analysis, args=(prompt,))
thread.daemon = True # 设为守护线程,主线程退出时自动结束
thread.start()
# 主线程立刻返回,继续处理 UI 事件daemon = True 的意思是:这个线程是"守护"线程。如果主程序退出了,这个线程会自动结束,不会拖后腿。
6.3 流式响应的实现
python
def process_ai_analysis(self, prompt):
"""在单独的线程中处理 AI 分析"""
try:
from openai import OpenAI
# 初始化客户端(注意:这里是模力方舟的地址)
client = OpenAI(
base_url="https://api.moark.com/v1",
api_key="你的 API 密钥", # ⚠️ 提醒读者替换成自己的
)
# 发送请求,启用 stream=True
response = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are a helpful and harmless assistant. You should think step-by-step."
},
{
"role": "user",
"content": prompt
}
],
model="DeepSeek-V3.2-Exp",
stream=True, # ⚠️ 核心参数!
max_tokens=10240,
temperature=0.7,
)
# 处理流式响应
for chunk in response:
# 检查窗口是否正在关闭
if self.is_closing:
break
if len(chunk.choices) == 0:
continue
delta = chunk.choices[0].delta
# 区分推理内容和最终内容
if hasattr(delta, 'reasoning_content') and delta.reasoning_content:
# 推理内容:模型的思考过程
self.update_frontend_signal.emit('reasoning', delta.reasoning_content)
elif delta.content:
# 最终内容
self.update_frontend_signal.emit('content', delta.content)
except Exception as e:
error_msg = f"AI 分析失败:{str(e)}"
self.update_frontend_signal.emit('error', error_msg)这里有几个细节要讲:
细节一:为什么用 hasattr(delta, 'reasoning_content')?
因为不是所有模型都支持推理过程展示。DeepSeek 系列的模型会返回 reasoning_content 字段,里面是模型的"思考过程"。普通模型只有 content。
用 hasattr 判断一下,有就展示,没有就跳过------兼容性思维。
细节二:if self.is_closing: break 的作用
如果用户等得不耐烦,直接关了窗口,这个循环还在跑,浪费资源。所以每拿到一个 chunk,都检查一下窗口还在不在。不在了就赶紧停。
细节三:len(chunk.choices) == 0 的处理
流式响应里,有些 chunk 可能不包含内容(比如心跳包)。直接跳过就行,不影响。
七、线程通信:从子线程到 UI 线程
现在有个问题:子线程里拿到了 AI 返回的内容,怎么更新 UI?
直接写 self.webview.page().runJavaScript(...) 会报错,因为 Qt 不允许在子线程操作 UI。
解决方案是 pyqtSignal。
7.1 定义信号
python
class KeyboardHeatmapApp(QMainWindow):
# 定义信号:参数是 (类型, 内容)
update_frontend_signal = pyqtSignal(str, str)
def __init__(self):
super().__init__()
# 连接信号到槽函数
self.update_frontend_signal.connect(self._update_frontend_slot)思考 :为什么是 pyqtSignal(str, str),不是 pyqtSignal(dict)?
因为信号传递的是跨线程消息,要尽量轻量。传两个字符串,比传一个字典更可靠、更高效。
7.2 发送信号(在子线程里)
python
# 在 process_ai_analysis 里
self.update_frontend_signal.emit('reasoning', delta.reasoning_content)
self.update_frontend_signal.emit('content', delta.content)
self.update_frontend_signal.emit('error', error_msg)
self.update_frontend_signal.emit('progress', '正在获取数据...')第一个参数是类型 ,第二个参数是内容。类型告诉槽函数"这是什么",内容告诉它"具体是什么"。
7.3 接收信号(在主线程里)
python
def _update_frontend_slot(self, update_type, content):
"""这个函数在主线程执行,可以安全地操作 UI"""
if self.is_closing:
return
# 检查当前是不是 AI 分析页面
current_url = self.webview.url().toString()
if 'ai-analysis.html' not in current_url:
return
try:
if update_type == 'content':
escaped = json.dumps(content)
self.webview.page().runJavaScript(
f'window.appendAnalysisResult({{"type": "content", "content": {escaped}}})'
)
elif update_type == 'reasoning':
escaped = json.dumps(content)
self.webview.page().runJavaScript(
f'window.appendAnalysisResult({{"type": "reasoning", "content": {escaped}}})'
)
elif update_type == 'error':
escaped = json.dumps(content)
self.webview.page().runJavaScript(
f'window.updateAnalysisResult({{"error": {escaped}}})'
)
elif update_type == 'progress':
escaped = json.dumps(content)
self.webview.page().runJavaScript(
f'window.updateAnalysisResult({{"progress": {escaped}}})'
)
except Exception as e:
if not self.is_closing:
print(f"更新前端失败: {e}")几个细节:
细节一:json.dumps(content) 的作用
content 是字符串,里面可能包含引号、换行符。直接拼接到 JavaScript 代码里会语法错误。json.dumps 会把这些特殊字符转义成安全的形式。
细节二:为什么有两个前端函数?
appendAnalysisResult:追加内容(用于流式输出)updateAnalysisResult:覆盖内容(用于错误/进度)
职责不同,分开写更清晰。
细节三:try...except 的必要性
runJavaScript 可能失败(比如页面正在关闭)。捕获异常,避免程序崩溃。
八、前端渲染:让文字动起来
现在看前端怎么接收这些内容。
8.1 缓存机制
javascript
// 累积 Markdown 内容
let markdownBuffer = '';为什么要缓存?因为流式输出是一块一块来的,每来一块,我们要把之前的内容加上新内容,重新渲染。
8.2 追加内容
javascript
window.appendAnalysisResult = function(data) {
const analysisResult = document.getElementById('analysisResult');
if (data.type === 'reasoning') {
// 推理内容:追加到缓存
markdownBuffer += data.content;
analysisResult.innerHTML = parseMarkdown(markdownBuffer);
// 给推理内容加灰色样式(通过 CSS)
// 可以在 parseMarkdown 里给特定内容加类,这里简化了
} else if (data.type === 'content') {
// 最终内容:追加到缓存
markdownBuffer += data.content;
analysisResult.innerHTML = parseMarkdown(markdownBuffer);
}
// 自动滚动到底部,让用户看到最新内容
analysisResult.scrollTop = analysisResult.scrollHeight;
};为什么每次都要重新 innerHTML?
因为浏览器不知道你追加了什么,只能重新渲染整个区域。这是最简单的实现,性能也够用(每秒几十次追加,完全没问题)。
8.3 覆盖内容
javascript
window.updateAnalysisResult = function(data) {
const analysisResult = document.getElementById('analysisResult');
if (data.error) {
analysisResult.innerHTML = `
<div class="error-container">
<div class="error-icon">❌</div>
<p class="error-title">分析失败</p>
<p class="error-message">${data.error}</p>
</div>
`;
markdownBuffer = ''; // 清空缓存
} else if (data.progress) {
analysisResult.innerHTML = `
<div class="loading-container">
<div class="loading"></div>
<p class="loading-text">${data.progress}</p>
</div>
`;
// 注意:这里不改变 markdownBuffer
// 因为进度提示只是临时覆盖,AI 返回后要恢复之前的缓存
}
};为什么错误时要清空缓存?
因为出错了,之前的缓存没意义了。留着反而可能让用户困惑。
为什么进度时不改变缓存?
因为进度提示是临时的,等 AI 开始返回内容,我们要用之前的缓存继续追加。
8.4 Markdown 解析
javascript
function parseMarkdown(text) {
let html = text;
// 第一步:保护代码块(防止里面的内容被后面的规则误处理)
const codeBlocks = [];
html = html.replace(/```([\s\S]*?)```/g, function(match, code) {
codeBlocks.push(escapeHtml(code));
return '|||CODE_BLOCK_' + (codeBlocks.length - 1) + '|||';
});
// 第二步:处理标题
html = html.replace(/^###### (.*$)/gm, '<h6>$1</h6>');
html = html.replace(/^##### (.*$)/gm, '<h5>$1</h5>');
html = html.replace(/^#### (.*$)/gm, '<h4>$1</h4>');
html = html.replace(/^### (.*$)/gm, '<h3>$1</h3>');
html = html.replace(/^## (.*$)/gm, '<h2>$1</h2>');
html = html.replace(/^# (.*$)/gm, '<h1>$1</h1>');
// 第三步:处理行内样式
html = html.replace(/\*\*([^*]+?)\*\*/g, '<strong>$1</strong>');
html = html.replace(/\*([^*]+?)\*/g, '<em>$1</em>');
html = html.replace(/`([^`]+)`/g, '<code>$1</code>');
// 第四步:处理链接
html = html.replace(/\[([^\]]+)\]\(([^)]+)\)/g, '<a href="$2" target="_blank">$1</a>');
// 第五步:处理换行
html = html.replace(/\n/g, '<br>');
// 第六步:恢复代码块
html = html.replace(/\|\|\|CODE_BLOCK_(\d+)\|\|\|/g, function(match, index) {
return '<pre><code>' + codeBlocks[parseInt(index)] + '</code></pre>';
});
return html;
}
function escapeHtml(text) {
return text
.replace(/&/g, '&')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/"/g, '"')
.replace(/'/g, ''');
}这个解析器的设计思路:
第一步先保护代码块 ,因为代码块里的内容可能包含 #、* 等 Markdown 语法,如果不保护起来,后面的替换会破坏它们。
最后一步恢复代码块,这时其他语法已经处理完了,可以安全地把代码块放回去。
这就是分层处理的思维:把复杂问题拆成几个简单的步骤,每一步只关注一件事。
九、错误处理:AI 也会犯错
9.1 API 调用失败
python
except Exception as api_error:
error_message = f"AI 分析失败:{str(api_error)}"
self.update_frontend_signal.emit('error', error_message)为什么把错误信息也发到前端?
因为用户需要知道发生了什么。如果是网络问题,用户可以去检查网络;如果是 API Key 问题,用户可以去配置中心修改。透明的错误信息,比"出错了"更有用。
9.2 没有数据
python
if total_hits == 0:
self.update_frontend_signal.emit('error', '暂无键盘使用数据,请先使用键盘后再进行分析')
return这个提示很关键------不是"分析失败",而是"暂无数据,先去用用键盘"。
用户看到这个提示,就知道不是程序坏了,而是自己还没产生数据。引导性的错误提示,比单纯的报错更好。
9.3 用户中途退出
python
if self.is_closing:
break # 停止处理这个检查放在循环里,每拿到一个 chunk 都检查一次。用户关窗口后,最多再处理一个 chunk 就停下,不会浪费资源。
十、完整流程回顾
现在我们从头到尾串一遍:
用户视角:
- 点"AI键位分析"按钮,页面跳转
- 看到"正在获取数据..."
- 看到文字一行一行往外蹦
- 最后看到完整的分析建议
- 不满意可以点"再次分析",重新来一遍
技术视角:
点击按钮 → window.location.href 跳转
↓
页面加载完成 → on_page_loaded 检测到 AI 页面
↓
analyze_keyboard_data() 被调用
↓
发送 'progress' 信号 → 前端显示"正在获取数据..."
↓
从数据库读取数据
↓
如果没有数据 → 发送 'error' 信号 → 前端显示错误
↓
如果有数据 → 生成提示词
↓
启动子线程 process_ai_analysis()
↓
子线程调用模力方舟 API(stream=True)
↓
逐块接收响应
├─ 有 reasoning_content → 发送 'reasoning' 信号
└─ 有 content → 发送 'content' 信号
↓
主线程 _update_frontend_slot 接收信号
↓
runJavaScript 调用前端函数
↓
前端追加内容到 analysisResult
↓
自动滚动到底部
↓
(如果出错)发送 'error' 信号 → 前端显示错误十一、踩坑总结(过来人的血泪史)
| 问题 | 现象 | 原因 | 解决方案 |
|---|---|---|---|
| UI 卡死 | 点分析后窗口无响应 | API 调用在主线程 | 放子线程 |
| 无法更新 UI | 子线程里调 runJavaScript 报错 | Qt 的线程限制 | 用 pyqtSignal |
| 流式不工作 | 等了半天才一次性出现 | 忘了加 stream=True | 检查参数 |
| 推理内容没显示 | 只有最终结果 | 模型不支持 | 用 hasattr 判断 |
| 内容重复 | 同一个内容显示两次 | 前端重复追加 | 检查逻辑 |
| XSS 风险 | AI 返回的内容带 script 标签 | 没转义 | escapeHtml |
| API Key 泄漏 | 代码提交到 GitHub 被发现 | 硬编码在代码里 | 放环境变量 |
| 用户等不及关窗口 | 程序还在后台跑 | 没检查 is_closing | 循环里加判断 |
| 错误提示太模糊 | 用户不知道发生了什么 | 报错信息太简略 | 把具体错误传前端 |
写在最后
这一篇我们讲了这么多,其实核心就是三件事:
- 提示词工程:怎么让 AI 输出有用的健康建议
- 流式响应:怎么让用户看着 AI 思考
- 线程通信:怎么在子线程和 UI 线程之间传数据
但最重要的不是这些代码本身,而是背后的思维方法:
- 分而治之:复杂问题拆成简单步骤
- 状态驱动:根据上下文决定行为
- 防御性编程:不要假设用户会按预期操作
- 兼容性思维:考虑不同模型、不同场景
- 透明错误:给用户有用的信息,而不是敷衍