堆的核心概述
堆&进程
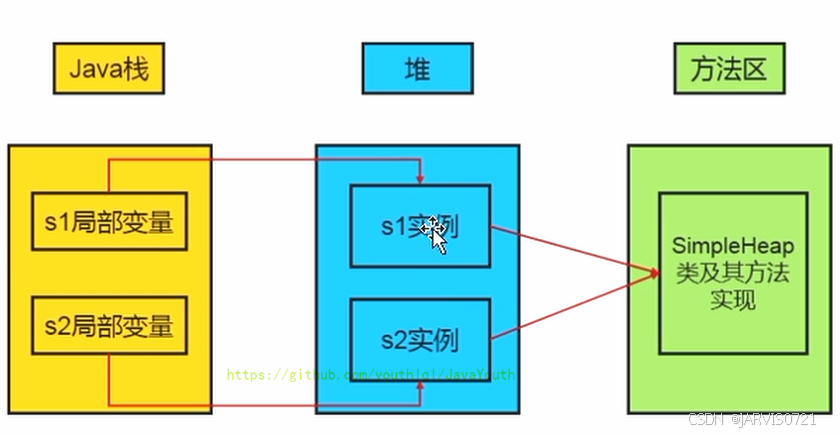
堆对一个JVM进程而言是唯一的------一个进程只有一个JVM实例。一个JVM实例当中对应一个运行时数据区,一个运行时数据区当中只有一个堆和一个方法区。
但是一个进程包含多个线程,他们共享同一个堆空间。

堆是Java内存管理的核心区域。JVM 启动时其初始大小和最大上限就被确定了,运行时JVM可以根据GC压力动提交(commit)、释放(uncommit)物理内存,使已经提交的内存在初始大小和最大上限之间浮动。
JVM规范规定,堆可以处于物理上不连续的内存空间当中,但是在逻辑上被视为连续的。
所有的线程共享堆内存,这里还可以划分线程私有的缓冲区(Thread Local Allocation Buffer,TLAB)
JVM规范当中描述Java堆:所有对象实例、数组都应当存储在运行时分配的堆上。(The heap is the run-time data area from which memory for all class instances and arrays is allocated)
从实际实用角度而言,"几乎"所有对象实例都在堆分配内存,但是并非全部。还有一些对象 在栈上分配内存(逃逸分析、标量替换,这两个情况后续将举例说明)
数组和对象基本上不会存储在栈上(例外情况:逃逸分析+栈上分配),因为栈帧中保存引用,这个引用指向对象/数组在堆当中的位置。
方法结束之后,堆中对象不会立马被移除,仅仅在垃圾回收的时候被移除
-
触发GC时候再进行回收(等待GC请求发起之后,到达下一个安全点执行)
-
堆中对象如果立马被回收会导致严重的线程安全问题
堆内存是执行GarbageCollection垃圾收集器执行垃圾回收的重点区域。
标准JVM实现举例:
public class SimpleHeap {
private int id;//属性、成员变量
public SimpleHeap(int id) {
this.id = id;
}
public void show() {
System.out.println("My ID is " + id);
}
public static void main(String[] args) {
SimpleHeap sl = new SimpleHeap(1);
SimpleHeap s2 = new SimpleHeap(2);
int[] arr = new int[10];
Object[] arr1 = new Object[10];
}
}
堆内存细分
现代垃圾收集器大部分基于分代收集理论设计,堆空间细分为:
-
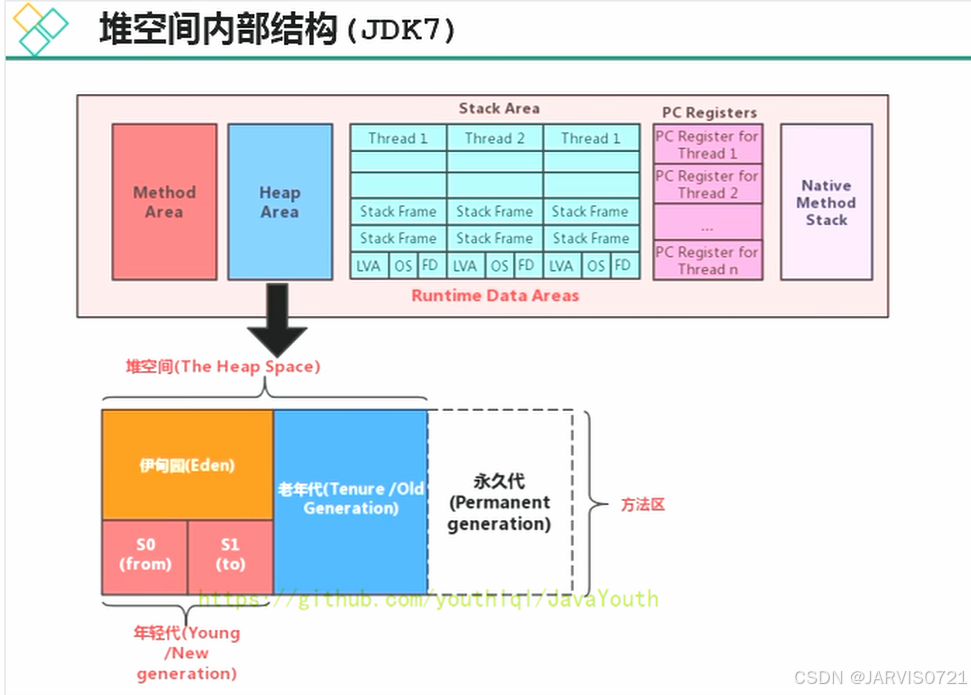
Java7以及之前,堆内存分为2个部分:新生区+养老区
-
堆内存:
-
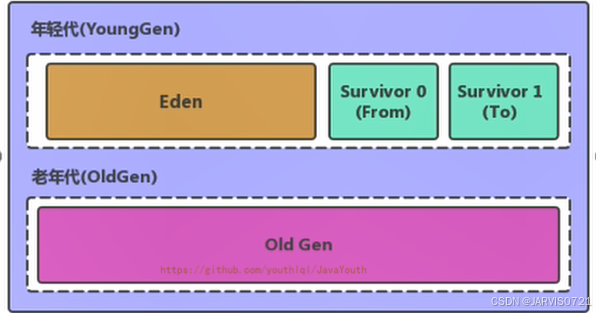
Young Generation Space 新生区 Young/New,进一步划分:
-
Eden区
-
Survivor 区
-
-
Old Generation Space 养老区 Old/Tenure
-
-
Permanent Space 永久区 Perm(实现:JDK7以及之前,复用了JVM启动时分配的堆内存地址空间,从总堆内存当中划分出一块区域。逻辑功能、管理机制都独立于堆),方法区Method Area的具体实现
-
-
Java 8以及之后,堆内存分为2个部分:新生区+养老区
-
堆空间:
-
Young Generation Space 新生区,划分与Java7以及之前相同
-
Old Generation Space 养老区
-
-
Meta Space 元空间 Meta(位于本地内存,物理上逻辑上完全独立于堆内存),方法区的具体实现
-
以上都是基于HotSpot JVM
约定:新生区=新生代=年轻代 养老区=老年区=老年代 永久区=永久代
设置堆内存大小&OOM
设置堆内存
之前讲过,JVM启动时就已经分配好堆内存初始空间和最大空间大小,通过选项"-Xms"和"-Xmx"设置:
-
-Xms 用于表示堆内存初始 内存大小,等价于 -XX:InitialHeapSize
-
-Xmx 用于表示堆内存最大 内存大小,等价于**-XX:MaxHeapSize**
一般我们会将**-Xms** 和**-Xmx**设置为相同的值:
-
原因:假设两个不一样,初始内存小,最大内存大。运行期间若堆内存不够用,会一直扩容到最大内存。内存够用且多了,也会不断进行缩容释放。频繁的扩容和释放造成不必要的压力。这样设置能避免在GC之后调整堆内存导致服务器压力。
-
减少频繁扩容缩容步骤,内存不够直接OOM异常
默认情况下:
-
初始内存大小:物理电脑内存/64
-
最大内存大小:物理电脑 内存/4
public class HeapSpaceInitial {
public static void main(String[] args) {//返回Java虚拟机中的堆内存总量 long initialMemory = Runtime.getRuntime().totalMemory() / 1024 / 1024; //返回Java虚拟机试图使用的最大堆内存量 long maxMemory = Runtime.getRuntime().maxMemory() / 1024 / 1024; System.out.println("-Xms : " + initialMemory + "M"); System.out.println("-Xmx : " + maxMemory + "M"); System.out.println("系统内存大小为:" + initialMemory * 64.0 / 1024 + "G"); System.out.println("系统内存大小为:" + maxMemory * 4.0 / 1024 + "G"); try { Thread.sleep(1000000); } catch (InterruptedException e) { e.printStackTrace(); } }}
输出结果:
-Xms : 123M
-Xmx : 1794M
系统内存大小为:7.6875G
系统内存大小为:7.0078125G原因:
-
笔者本身电脑内存8G
-
两个系统大小内存不一样后续解释
调整参数之后再次查看:
public class HeapSpaceInitial {
public static void main(String[] args) {
//返回Java虚拟机中的堆内存总量
long initialMemory = Runtime.getRuntime().totalMemory() / 1024 / 1024;
//返回Java虚拟机试图使用的最大堆内存量
long maxMemory = Runtime.getRuntime().maxMemory() / 1024 / 1024;
System.out.println("-Xms : " + initialMemory + "M");
System.out.println("-Xmx : " + maxMemory + "M");
try {
Thread.sleep(1000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}输出结果:
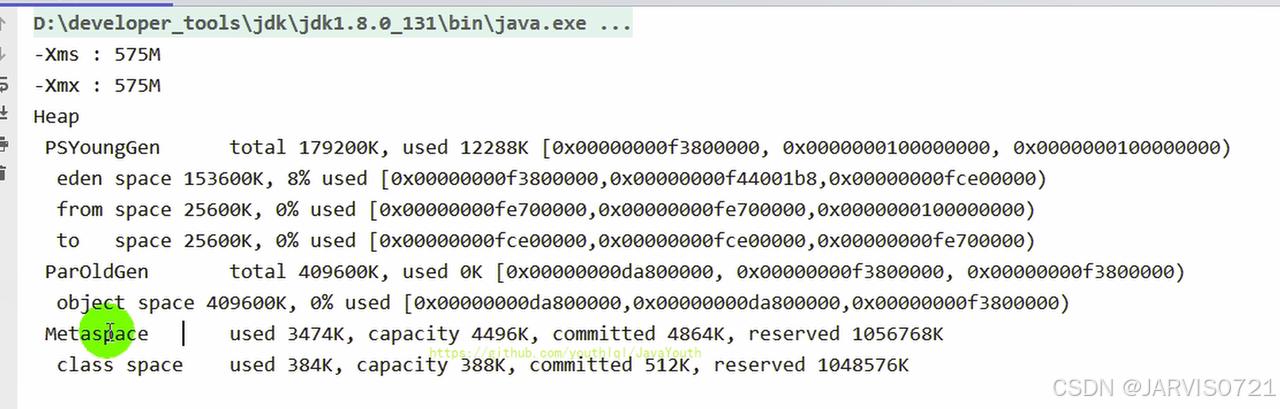
-Xms : 575M
-Xmx : 575M为什么会少25MB?
方式1:通过 jps/jstat -gc 进程id 检查
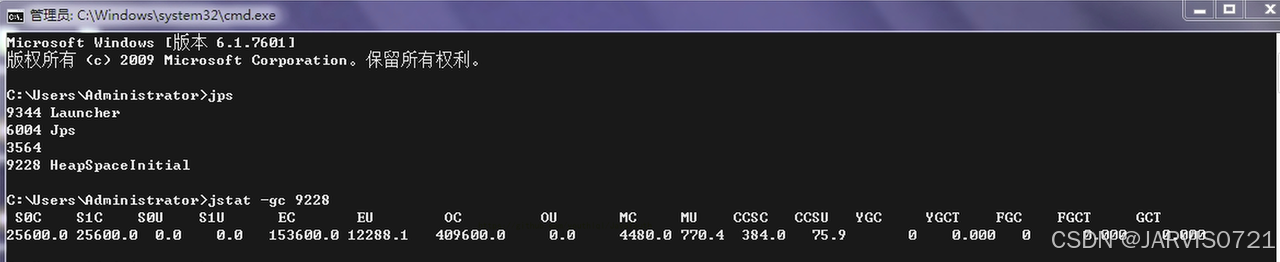
我们计算总容量:
25600+25600+153600+409600 = 614400K
614400 /1024 = 600M
之后我们计算除去S0/S1区之后的容量发现:
25600+153600+409600 = 588800K
588800 /1024 = 575M
和我们之前在java代码当中打印总容量得到575大小一样,也就是说明s0/s1当中一个空闲一个无法使用(后续进行详解)
使用 -XX+PrintGCDetails放入程序的VM参数当中
OOM------OutOfMemory
public class OOMTest {
public static void main(String[] args) {
ArrayList<Picture> list = new ArrayList<>();
while(true){
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
list.add(new Picture(
//拿到一个0~1024*1024范围内的伪随机数
new Random().nextInt(1024 * 1024))
);
}
}
}
class Picture{
private byte[] pixels;
public Picture(int length) {
this.pixels = new byte[length];
}
}我们依旧通过 -XX命令设置堆内存初始大小、最大值为600M
最终输出结果:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at com.atguigu.java.Picture.<init>(OOMTest.java:29)
at com.atguigu.java.OOMTest.main(OOMTest.java:20)
Process finished with exit code 1通过可视化软件查看堆内存变化图:(查看方式见:GitHub - youthlql/JavaYouth: 主要是Java技术栈的文章第五章第二节)
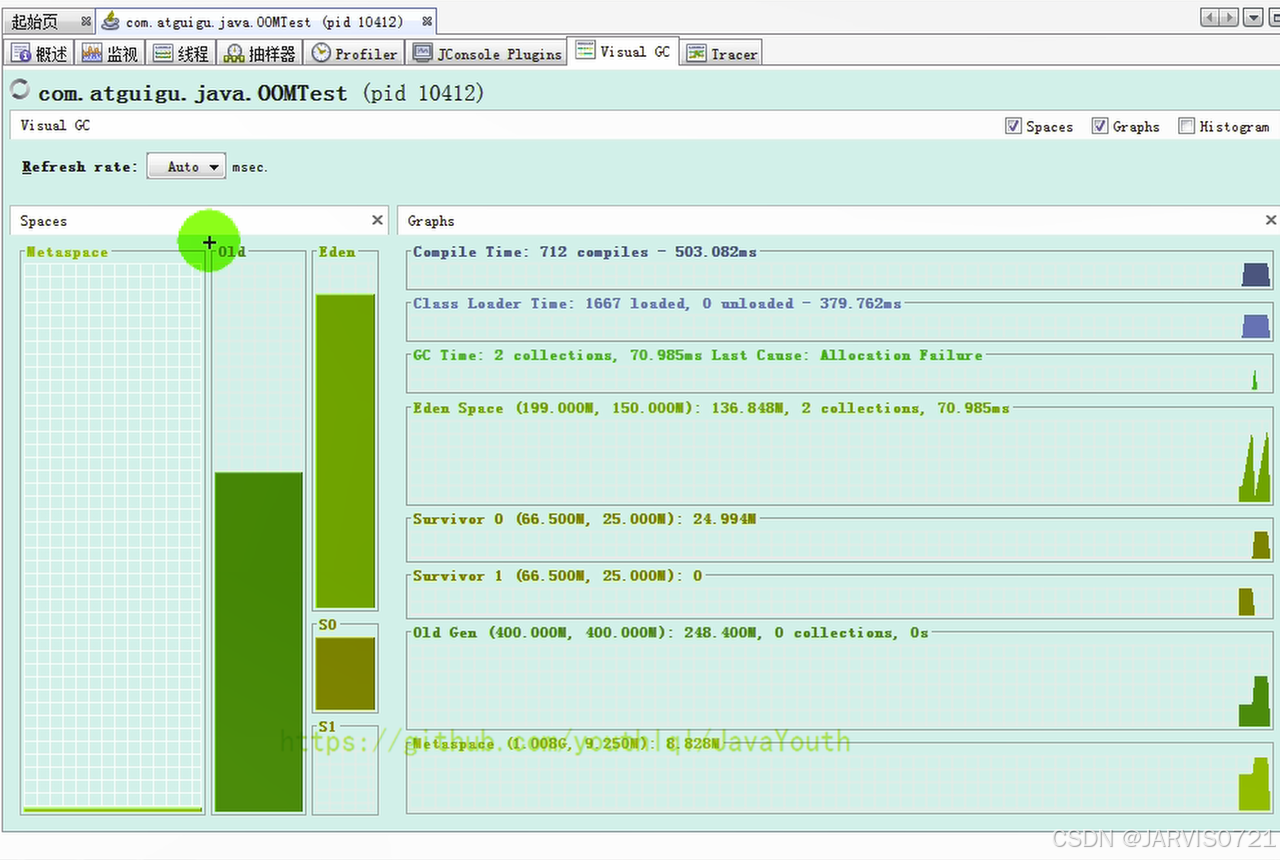
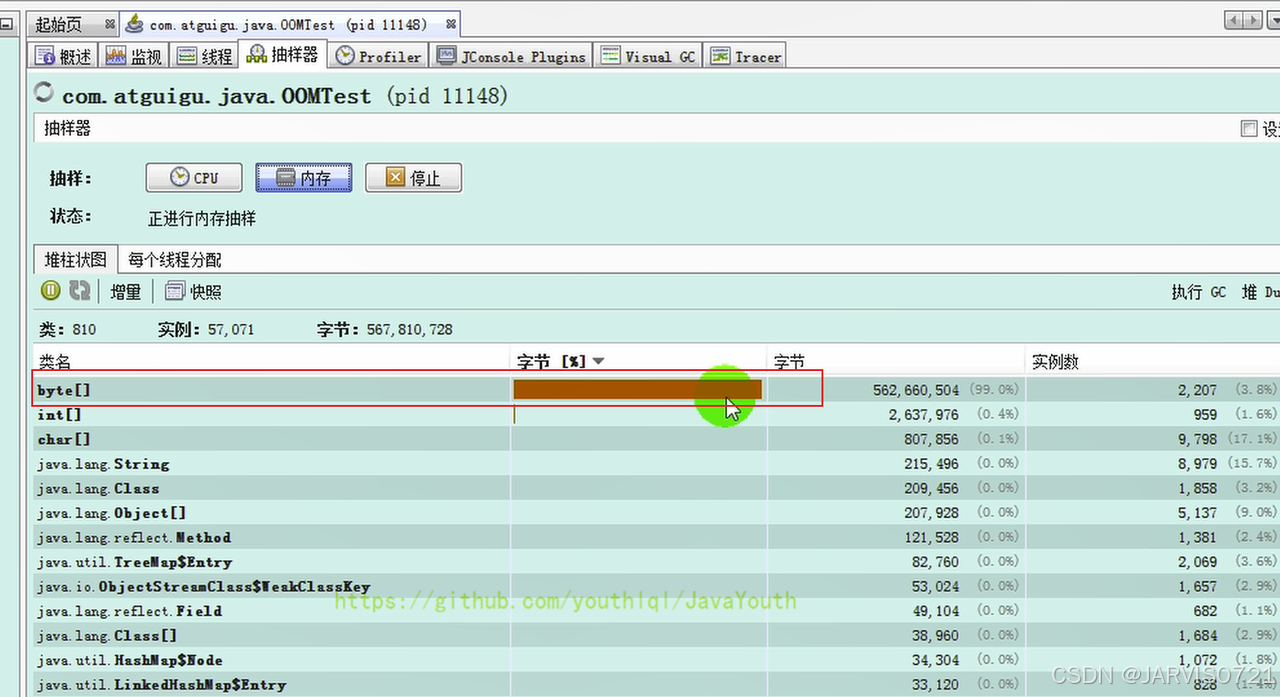
OOM原因:大对象导致内存溢出
年轻代&老年代
存储在JVM当中的Java对象可以被分为两类:
-
生命周期较短的瞬时对象,创建和消亡都非常迅速
-
生命周期长,极端情况与JVM生命周期保持一致
Java堆区进行细分的话可分为 :
-
Young Gen年轻代
-
Old Gen老年代
其中年轻代可以划分为:
-
Eden 空间
-
Survivor0空间(有时称为from区)
-
Survivor1空间(有时称为to区)
-
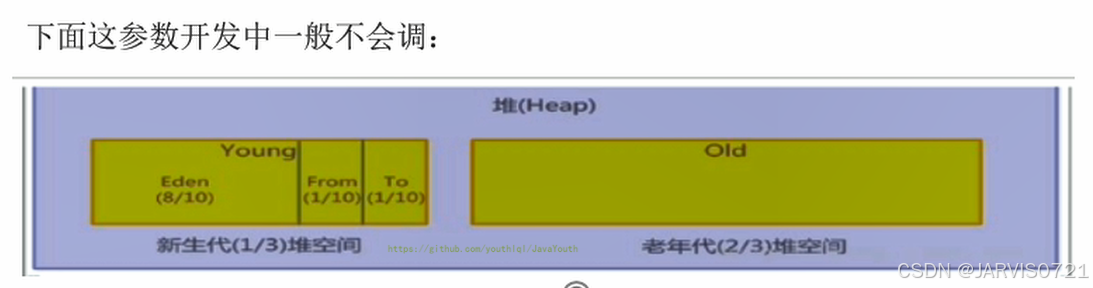
配置新生代&老年代之间的占比:
-
默认
-XX:NewRatio=2,表示新生代占1,老年代占2,新生代占整个堆的1/3 -
可修改为:
-XX:NewRatio=4,表示新生代占1,老年代占4,~
-
-
HotSpot VM当中,Eden空间和另外两个Survivor空间所占比例默认为8:1:1
-
当然可以同样可以通过VM参数选项
-XX:SurvivorRatio -
可以使用
-Xmn设置新生代最大内存大小但是一般默认值即可。 -
几乎所有Java对象都是在Eden区新建的(当对象大小超过设定阈值时将被直接分配到老年代)
-
绝大部分的对象销毁都是在新生代当中进行的,IBM公司专门研究表明,80%的新生代对象都是朝生夕死的
对象分配过程解析
整体流程

步骤1:对象创建→Eden区分配
-
执行new操作时,JVM尝试在Eden区分配内存
-
Eden空间足够→直接分配,对象诞生(部分大对象直接晋升老年代)
-
Eden空间不足,无法分配新对象→触发Minor GC
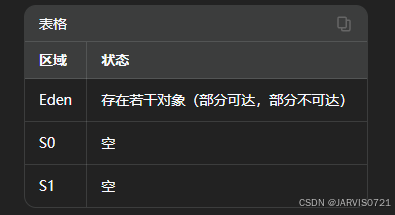
步骤2:第一次MinorGC(初始状态 S0、S1均为空)
GC过程:
-
标记阶段:从GCRoots出发,标记所有可达对象
-
复制阶段:
-
将Eden所有可达对象复制到S0区
-
同时清空Eden区(不可达被全部丢弃)
-
S1为空,任然不变
-
-
角色改变:本次GC之后,S0为目标Survivor区,S1仍然为空闲区
-
此时:
-
Eden:空
-
S0:存放本次GC存活对象(年龄为1)
-
S1:空
-
-
步骤3:再次创建对象→Eden再次填充
-
新对象依旧分配到Eden区
-
一段时间之后,Eden空间再次不足,触发第二次MinorGC
第二次Minor GC前状态:
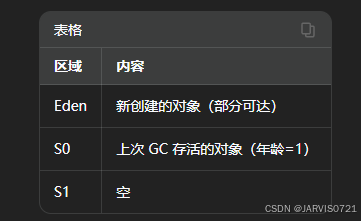
GC过程:
-
标记:同第一次GC一样标记方式标记包括Eden当中和S0当中的所有可达对象
-
复制(核心):
-
将S0所有存活的(可达)对象复制到S1
-
Eden中存活对象复制到S1当中
-
清空Eden和S0(内容全部迁移)
-
-
角色切换:本次GC之后,S1成为目标Survivor区,S0成为空闲区
此时:
-
Eden为空
-
S0:被清空
-
S1:包含两批对象
-
原S0存活对象,年龄为2
-
新Eden存活对象,年龄为1
-
关键:
每次Minor GC都是将存活对象复制到当前空闲的Survivor去当中
即:S0和S1交替作为目标区,实现复制算法的无碎片化内存管理
✔年龄更新规则:
-
每次成功在Suvivor区间复制(经历一次Minor GC之后依旧存活),年龄+1
-
例外:某次GC时,目标Suvivor区间(本次GC计划接收存货对象的空闲Suvivor区)不足→直接晋升老年代
步骤4:对象晋升老年代
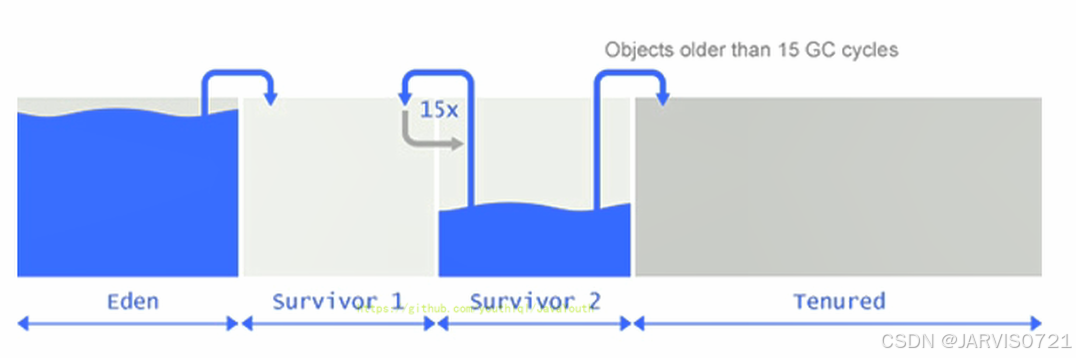
当对象满足以下任意条件,晋升老年代:
-
年龄达到阈值:
-XX:MaxTenuringThreshold=N(默认15),即在Survivor区经历了N次MinorGC仍然存活。 -
Survivor区空间不足:当前MinorGC时目标接收对象的空闲Suvivor区(当前Minor GC的空闲S区)空间不足→提前晋升老年代(称为动态年龄判定)
-
大对象直接进入老年代:通过
-XX:PretenureSizeThreshold设置,超过该大小的对象直接分配老年代(避免新生代频繁复制) -
分配担保失败:Minor GC触发之后执行前检查老年代剩余连续空间<最大可能晋升量(Eden区+from区所有对象)→提前触发Full GC尝试清理整个堆,(为下一次执行MinorGC做准备)FullGC执行时满足条件的新生代对象尝试晋升,若清理之后仍然无法容纳所有待晋升对象则OOM。
步骤5:老年代GC(Major/Full GC)
当老年代空间不足或者显示调用System.gc()→触发Full GC(常称为Major GC)
全面回收:
-
新生代全部清理
-
老年代清理
Full GC之后依旧无法为新对象分配空间→抛出:
java.lang.OutOfMemoryError: Java heap space⚠注意:Full GC会STW,暂停所有应用线程,影响较大
GC分类
我们都知道 JVM的调优的一个环节就是GC垃圾回收,
JVM当中调优GC的核心目标:
-
减少GC频率(尤其避免FullGC)
-
缩短单次STW时间(控制在100ms以内)
-
确保GC行为可以预测、稳定、不退化
注:
GC的退化:
本应该高效执行的GC收集器在运行时,因无法满足其设计前提(空间、时间、并发能力),而自动切换为另一种更保守、耗时、全局STW的GC方式(通常是Full GC),导致延迟/吞吐量断崖式恶化。
|----------|---------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------|-------------------------------------------|-----------------------------------------|
| GC 类型 | 回收范围 | 触发条件 | STW 特性 | 适用收集器 | 面试关键词 |
| Minor GC | 仅新生代(Eden + S0/S1) | Eden 区分配失败(Allocation Failure) | ✅ 必然 STW (毫秒级,通常 < 50ms) | 所有收集器(Parallel/G1/ZGC) | "新生代回收"、"复制算法"、"Survivor 溢出"、"晋升阈值" |
| Mixed GC | 新生代 + 部分老年代 Region | G1 并发标记完成,且老年代占用率 ≥ InitiatingOccupancyPercent(默认 45%) | ✅ 必然 STW(Evacuation Pause) (目标:≤ MaxGCPauseMillis,默认 200ms) | 仅 G1 | "G1 特有"、"增量式老年代回收"、"不会退化为 Full GC(正常时)" |
| Full GC | 整个 Java 堆(新生代 + 老年代) + 元空间(Metaspace) | • 分配担保失败(Minor GC 前老年代空间不足) • 显式调用 System.gc()(若未禁用) • 元空间耗尽(Metaspace OOM) • G1/CMS 退化(Concurrent Mode Failure / Promotion Failed) | ✅ 必然 STW (毫秒~秒级,取决于堆大小和收集器) | Parallel GC, Serial GC, G1(退化时), CMS(退化时) | "最重 GC"、"全局停顿"、"应避免"、"退化标志" |
Minor GC(面试最高频考点)
本质&目标
-
目的:快速清理生命周期短的对象
-
核心算法:复制算法------只复制存活对象,天然无碎片
-
关键约束:确保S区有足够空间,否则触发动态晋升(Dynamic Promotion)
详细流程
|--------|----------------------------------------------------------|-----------------------------------------------------------------------------------------------------------|--------------------------------------------------|
| 步骤 | 操作 | 关键细节 | 面试加分点 |
| ① 触发 | Eden 分配新对象失败 | 不是"填满",而是"无法分配" → 即刻 Minor GC | 强调:分配失败是唯一触发条件 |
| ② 标记 | 从 GC Roots 遍历,标记所有可达对象 | Roots 包括:栈帧局部变量、静态字段、JNI 引用、synchronized 锁对象 | 提及 synchronized 是 Roots → 体现深度 |
| ③ 复制 | 将 Eden + 当前 Survivor(S0 或 S1)中所有存活对象,复制到另一个空的 Survivor 区 | • 目标 Survivor 区必须空闲(S0/S1 交替使用) • 复制时年龄 +1 | 必答:解释为什么需要两个 Survivor(解决"复制时无处可放"问题) |
| ④ 晋升决策 | 对满足条件的对象晋升老年代 | 条件: • 年龄 ≥ -XX:MaxTenuringThreshold(默认 15) • 目标 Survivor 区空间不足(动态晋升) • 对象大小 > -XX:PretenureSizeThreshold | 高频题:"什么情况下对象会提前进入老年代?" → 答三点(年龄、Survivor 溢出、大对象) |
| ⑤ 清理 | 清空 Eden 和原 Survivor 区(逻辑清空,非写 0) | 内存管理:重置 top 指针即可 | 补充:HotSpot 使用"指针碰撞(Bump-the-Pointer)"分配,极快 |
面试常考问题
| Q:Minor GC 会扫描老年代吗? | A:不会。Minor GC 只处理新生代。但为保证安全性,会扫描 老年代对新生代的跨代引用(Remembered Set),防止Minor GC错误回收被老年代对象引用的年轻代对象(即确保可达性不被破坏) ------ 这是 G1/CMS 的优化,Parallel GC 中通过 卡表(Card Table) 实现。 | | Q:为什么要有两个 Survivor 区? | A:避免复制时无处可放。若只有一个 Survivor,复制过程中自身又成为"待复制对象",将陷入死循环。双 Survivor 实现"From/To"角色切换,保证每次都有空缓冲区。 | | Q:如何判断一次 Minor GC 是否健康? | A:看 jstat -gc <pid>: • YGCT(Minor GC 总耗时)/ YGC(次数)≈ 10--30ms → 健康; • S0U/S1U 长期 < S0C/S1C 的 50% → Survivor 未溢出; • OU(老年代使用量)缓慢上升 → 晋升合理。 |
Full GC(面试第二高频)
本质&目标
-
目标:兜底式全栈回收,解决MinorGC无法处理的深度问题
-
核心思想:标记-清除(CMS/Serial Old)或标记-整理(Parallel Old/G1退化)
-
致命弱点:STW时间和堆大小强相关,是系统延迟的最大风险点
五大触发原因(暂时了解)
|-------------|---------------------------------------------------------------|----------------------------------------------------------------------------|----------------------------------------------------------|
| 原因 | 原理 | 如何验证 | 解决方案 |
| ① 分配担保失败 | Minor GC 前,JVM 预估本次晋升量 > 老年代可用空间 → 先触发 Full GC 腾空间 | 日志:Full GC (Ergonomics) | ✅ 增大堆(-Xmx) ✅ 调优 Survivor(-XX:SurvivorRatio=8) |
| ② 显式 GC | System.gc() 被调用(尤其在 NIO Direct Buffer 清理、旧框架中) | 日志:Full GC (System.gc()) | ✅ 加 -XX:+DisableExplicitGC(生产必备) |
| ③ 元空间耗尽 | 动态类加载过多(Spring Boot、Groovy、字节码增强),Metaspace 无空间卸载类 | 日志:java.lang.OutOfMemoryError: Metaspace jstat -gcmetacapacity <pid> | ✅ -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=512m |
| ④ G1/CMS 退化 | G1:晋升失败(Promotion Failed);CMS:并发模式失败(Concurrent Mode Failure) | 日志:Full GC (Allocation Failure)(G1) Full GC (Concurrent Mode Failure)(CMS) | ✅ G1:降低 InitiatingOccupancyPercent ✅ 禁用 CMS(JDK 14+ 已移除) |
| ⑤ 老年代碎片化 | Parallel Old 标记-整理后仍碎片过多,无法分配大对象 | jstat -gc 中 OU 高但 OC(老年代容量)也高 → 碎片 | ✅ 改用 G1/ZGC(自动整理) ✅ 增大老年代(-XX:NewRatio=2) |
面试常考题(暂时了解)
| Q:Full GC 一定比 Minor GC 慢吗? | A:不一定。在 ZGC/Shenandoah 中,Full GC 概念已消失,所有 GC STW < 1ms;在 G1 中,正常 Mixed GC 与 Minor GC 耗时相近。只有 Parallel GC 下,Full GC 因标记-整理老年代,才显著更慢。 | | Q:如何快速定位 Full GC 根因? | A:三步法: 1️⃣ jstat -gc -h10 <pid> 1000 → 看 FGC 是否突增; 2️⃣ jstat -gccause <pid> → 查最后一次 GC 原因(Allocation Failure? System.gc()?); 3️⃣ jmap -histo:live <pid> \| head -20 → 看是否大对象或类加载异常。 | | Q:能否避免 Full GC? | A:可以极大减少,但无法 100% 避免。生产环境应追求: • 0 次/小时(健康) • ≤ 1 次/天(可接受) • > 1 次/小时 → 立即根因分析(通常是内存泄漏或配置错误)。 |
历史术语------ Major GC
很多书籍、早期的Sun文档、大量的JVM课程当中都出现过Major GC,但是Major GC并不是JVM官方属于,在社区语境当中表示对老年代的回收。不同的收集器对老年代的回收实现方式不尽相同,因此Major GC并不是一个可以精确映射到具体GC日志时间的术语。

常见三种GC对比
|---------|--------------------------|-------------------------------|---------------------------------------|
| 维度 | Minor GC | Full GC | Mixed GC(G1) |
| 回收范围 | Eden + S0/S1 | 整个堆 + Metaspace | Eden + 部分老年代 Region |
| 触发频率 | 高(秒级) | 低(小时/天级) | 中(分钟级) |
| STW 时间 | < 50ms | 毫秒~秒级 | ≤ 200ms(可配置) |
| 是否可避免 | ❌ 不可避免(对象创建必然产生) | ✅ 应尽量避免(退化 = 配置失败) | ✅ G1 默认行为,无需干预 |
| 面试必答关键词 | 复制算法、Survivor 溢出、晋升阈值、卡表 | 分配担保、退化、Metaspace、System.gc() | G1 特有、增量回收、InitiatingOccupancyPercent |
GC日志分析
/*
VM参数:
-Xms9m -Xmx9m -XX:+PrintGCDetails
*/
public class GCTest {
public static void main(String[] args) {
int i = 0;
try {
List<String> list = new ArrayList<>();
String a = "atguigu.com";
while (true) {
list.add(a);
a = a + a;
i++;
}
} catch (Throwable t) {
t.printStackTrace();
System.out.println("遍历次数为:" + i);
}
}
}日志输出:
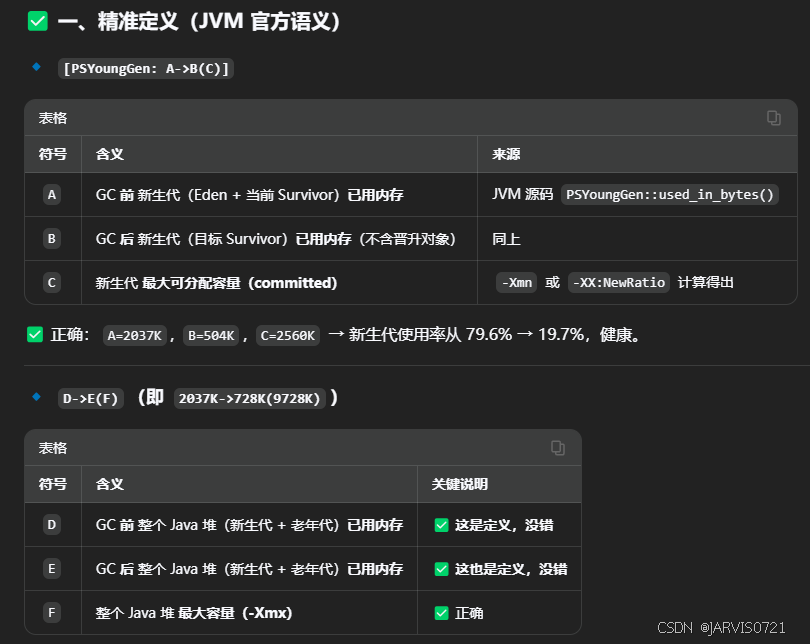
[GC (Allocation Failure) [PSYoungGen: 2037K->504K(2560K)] 2037K->728K(9728K), 0.0455865 secs] [Times: user=0.00 sys=0.00, real=0.06 secs]
[GC (Allocation Failure) [PSYoungGen: 2246K->496K(2560K)] 2470K->1506K(9728K), 0.0009094 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 2294K->488K(2560K)] 3305K->2210K(9728K), 0.0009568 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1231K->488K(2560K)] 7177K->6434K(9728K), 0.0005594 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 488K->472K(2560K)] 6434K->6418K(9728K), 0.0005890 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Allocation Failure) [PSYoungGen: 472K->0K(2560K)] [ParOldGen: 5946K->4944K(7168K)] 6418K->4944K(9728K), [Metaspace: 3492K->3492K(1056768K)], 0.0045270 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
[GC (Allocation Failure) [PSYoungGen: 0K->0K(1536K)] 4944K->4944K(8704K), 0.0004954 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Allocation Failure) java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3332)
at java.lang.AbstractStringBuilder.ensureCapacityInternal(AbstractStringBuilder.java:124)
at java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:448)
at java.lang.StringBuilder.append(StringBuilder.java:136)
at com.atguigu.java1.GCTest.main(GCTest.java:20)
[PSYoungGen: 0K->0K(1536K)] [ParOldGen: 4944K->4877K(7168K)] 4944K->4877K(8704K), [Metaspace: 3492K->3492K(1056768K)], 0.0076061 secs] [Times: user=0.00 sys=0.02, real=0.01 secs]
遍历次数为:16
Heap
PSYoungGen total 1536K, used 60K [0x00000000ffd00000, 0x0000000100000000, 0x0000000100000000)
eden space 1024K, 5% used [0x00000000ffd00000,0x00000000ffd0f058,0x00000000ffe00000)
from space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)
to space 1024K, 0% used [0x00000000ffe00000,0x00000000ffe00000,0x00000000fff00000)
ParOldGen total 7168K, used 4877K [0x00000000ff600000, 0x00000000ffd00000, 0x00000000ffd00000)
object space 7168K, 68% used [0x00000000ff600000,0x00000000ffac3408,0x00000000ffd00000)
Metaspace used 3525K, capacity 4502K, committed 4864K, reserved 1056768K
class space used 391K, capacity 394K, committed 512K, reserved 1048576K
[GC (Allocation Failure) [PSYoungGen: 2037K->504K(2560K)] 2037K->728K(9728K),
0.0455865 secs] [Times: user=0.00 sys=0.00, real=0.06 secs] -
PSYoungGen: 2037K-\>504K(2560K):年轻代总空间为 2560K ,GC之前年轻代占用 2037K ,经过垃圾回收后年轻代占用504K
-
2037K->728K(9728K):堆内存总空间为 9728K ,GC之前整个Java堆占用2037K ,经过垃圾回收后整个Java堆已用728K
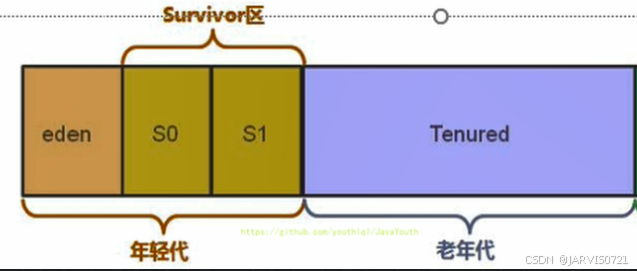
堆空间分代思想
为什么要给Java堆分代?
不同对象生命周期不同,70%~90%对象是临时对象
-
新生代:Eden、两块大小相同的Suvivor区(from区、to区)
-
老年代:存放新生代当中经历多次Minor GC依旧存活的对象
分代的原因:优化GC性能
-
没有分代:所有对象挤在一块,当我们想要进行GC的时候需要扫描所有区域,性能低下
-
很多对象都是朝生夕死的,分代的话,把大部分新创建的对象优先分配在Eden区,并通过Suvivor区进行对象年龄管理(个例这里不讨论),Minor GC需要回收的时候只需要盯住这块存放"朝生夕死"对象的区域------新生代进行回收,无需触碰老年代以及内含的对象,能够很大程度上提升效率。
ThreadLocalAllocationBuffer(线程私有缓冲区,保障线程安全)
为什么需要TLAB
-
对象分配及其频繁(Web请求当中每毫秒创建数万个对象)
-
堆内存分配采用指针碰撞算法:通过移动堆顶指针top进行快速分配,但是这个操作不是原子操作,多线程直接操作可能导致指针错乱。
-
加互斥锁进行分配,每次分配时间较长,性能大打折扣
什么是TLAB
ThreadLocalAllocationBuffer,是HotSpot JVM为每个线程在Eden区内预先分配的一块私有内存缓冲区,用于实现无锁、纳秒级的对象快速分配。
多线程同时分配内存时,使用TLAB能够避免分配阶段的并发冲突(和线程安全问题无关),同时提高内存分配吞吐量------这种内存分配方式称为快速分配策略。
TLAB是默认强制启用的。
TLAB耗尽时,通过CAS/轻量同步申请新的TLAB
TLAB内存布局结构&工作流程
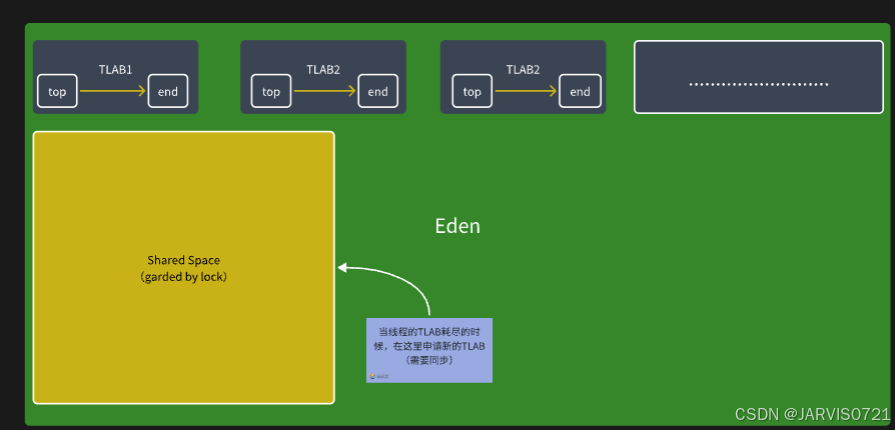
-
每个TLAB是Eden当中一块连续、固定大小的内存
-
top、end为TLAB起始、结束地址,为线程私有变量,存储在Thread对象当中
-
共享区域Shared Space是Eden当中未被划分为TLAB的剩余区域,只有在当前线程TLAB耗
-
尽的时候才会使用(需要同步)
class Thread {
HeapWord* _tlab_start; // 当前 TLAB 起始地址
HeapWord* _tlab_current; // 当前分配指针(top)
HeapWord* _tlab_end; // TLAB 结束地址(end)
size_t _tlab_size; // 当前 TLAB 大小(字节)
};
分配流程
- 线程首次分配:JVM为其在Eden中分配一个TLAB(大小由JVM计算)
- 常规分配:线程执行创建新对象→
tlab_top+=size - TLAB耗尽检测:若
tlab_top(Thread对象当中的tlab_current属性)+size>tlab_end(Thread对象当中的tlab_end属性)→触发allocate_slow - 申请新的TLAB:通过CAS或者轻量锁,在Eden Shared Space中申请新TLAB(极少发生)
- 大对象直接进入Eden:若对象>TLAB剩余空间>TLAB空间一般→直接在Eden共享区分配(不进入TLAB)
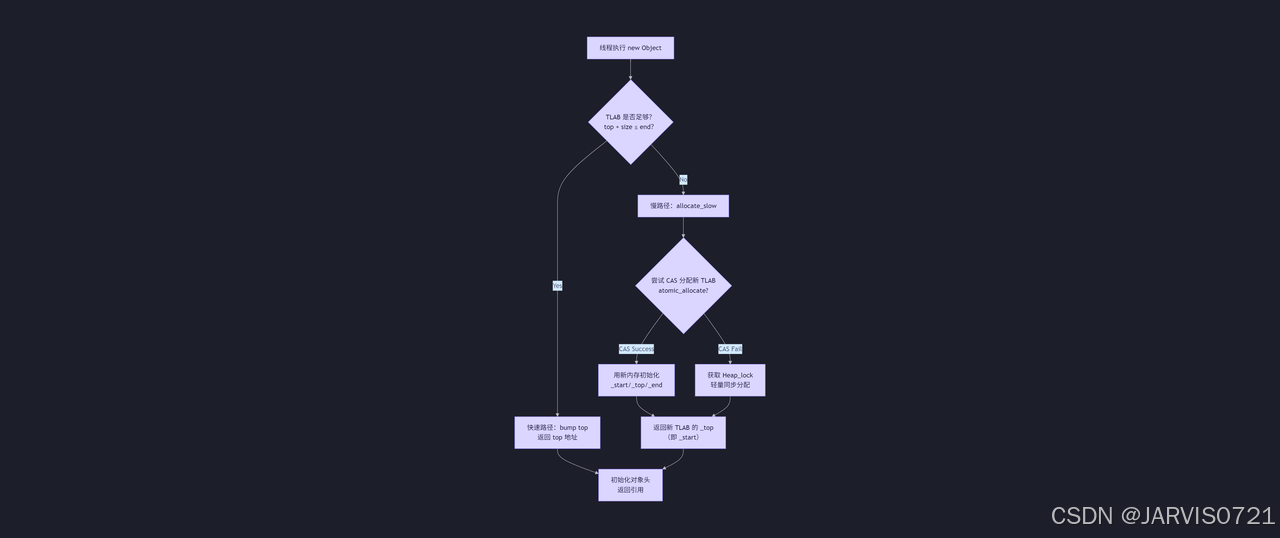
经典流程:
1. [快速路径]
if (_top + size <= _end) {
obj = _top;
_top += size; // 无锁 bump
return obj;
}
2. [慢路径] allocate_slow()
→ 尝试 CAS(&eden_top, old, old+size)
├─ 成功:new_start = old; goto 4
└─ 失败:获取 Heap_lock → 再试一次
3. [分配新块]
new_start = eden_top; // 全局指针值,共享空间当中最靠前的可分配的内存地址
new_end = new_start + size;
4. [初始化线程 TLAB]
_start = new_start;
_top = new_start; // 重置!不是 +=
_end = new_end;
5. [返回地址]
return new_start; // 即对象地址
再说明
-
尽管不是所有对象实例都能在TLAB当中成功分配内存,但是JVM确实将TLAB作为分配内存的首选
-
程序中开发人员可以通过选项
-XX:UseTLAB设置是否开启TLAB空间 -
默认情况,
TLAB非常小,仅占有Eden空间1%,可以通过-XX:TLABWasteTargetPercent设置TLAB空间所占用Eden空间大小
TLAB这么小,存储的是线程对应对象的地址吗?
-
TLAB本身不是对象容器、也不是独立空间,而是Eden区当中一块被划归为某线程专用的连续内存区域。所有在其中分配的对象都真实、物理地存储在这块内存当中
-
TLAB本身占用Eden很小一部分,是因为:绝大多数对象极小(<32B),存活时间极短(95%在Minor GC当中死亡),只需要很小一部分缓冲区满足高频分配需求
堆空间参数设置
堆空间基础参数设置
|--------------|----------------------------------------------------------------|--------------------------------------------------------------------|-------------------------------------------------------------------------------------------|---------------|
| 参数 | 含义 | 行为原理 | 生产建议 | 示例 |
| -Xms<size> | 初始 Java 堆大小(等价于 -XX:InitialHeapSize) | JVM 启动时直接向操作系统申请 size 内存,避免运行中频繁扩容(触发 Full GC 或 stop-the-world 扩容) | ✅ 必须与 -Xmx 相等!(即 -Xms=Xmx) → 防止堆动态伸缩,提升 GC 可预测性、降低延迟抖动 | -Xms4g -Xmx4g |
| -Xmx<size> | 最大 Java 堆大小(等价于 -XX:MaxHeapSize) | JVM 堆内存上限;若对象分配超出此值且 GC 后仍不足,则抛 OutOfMemoryError: Java heap space | ✅ 至少设为物理内存的 50%~75%(容器需预留 OS/其他进程内存) ❌ 不要设为 100%(OS 需内存、Direct Memory、Metaspace 也要用堆外内存) | -Xmx8g |
| -Xmn<size> | 新生代(Young Generation)初始+最大大小(等价于 -XX:NewSize 和 -XX:MaxNewSize) | 新生代 = Eden + 2×Survivor;该参数直接固定新生代大小,覆盖 NewRatio | ✅ 推荐显式设置(而非依赖 NewRatio),便于精准控制 Eden 大小和 TLAB 行为 ✅ 通常设为 -Xmx 的 30%~50%(如 -Xmx8g → -Xmn3g) | -Xmn3g |
新生代精细参数设置(进阶)
|--------------------------------|------------------------------------------------|-----------------------------------------------------------|------------------------------------------------------------------------------------------------------------|----------------------------|
| 参数 | 含义 | 行为原理 | 生产建议 | 示例 |
| -XX:SurvivorRatio=<N> | Eden : Survivor 比例(每个 Survivor 区大小 = Eden / N) | 新生代 = Eden + S0 + S1;SurvivorRatio=8 → Eden:S0:S1 = 8:1:1 | ✅ 默认 8(合理),高分配率服务可调小(如 6)以增大 Survivor,减少晋升; ❌ 不要设为 1(Eden 过小 → 严重破坏,TLAB快速耗尽,分配延迟激增) | -XX:SurvivorRatio=6 |
| -XX:MaxTenuringThreshold=<N> | 对象晋升老年代的最大年龄阈值 | 对象在 Survivor 中每经历一次 Minor GC,年龄 +1;达到 N 则晋升老年代 | ✅ 默认 15(足够大),若观察到 S0U/S1U 长期 >90%,说明 Survivor 溢出 → 可增大此值或调大 Survivor; ✅ 低延迟场景可设为 1(快速晋升,减少 Survivor 复制开销) | -XX:MaxTenuringThreshold=1 |
| -XX:+AlwaysPreTouch | 启动时预触碰(mmap)全部堆内存 | JVM 启动时立即向 OS 申请并锁定 -Xms 大小的物理内存页,避免运行时缺页中断 | ✅ 高性能/低延迟服务强烈推荐(如金融、实时风控) ✅ 容器中需配合 --memory 限制使用,否则 OOMKilled | -XX:+AlwaysPreTouch |
GC策略&日志参数(诊断核心,个人认为了解即可)
|-----------------------------------------------------------|-------------------|-----------------------------------------------------------------|--------------------------------------------------------------------|---------------------------------------|
| 参数 | 含义 | 行为原理 | 生产建议 | 示例 |
| -XX:+UseG1GC | 启用 G1 垃圾回收器 | G1 将堆划分为 Region,可预测停顿时间(-XX:MaxGCPauseMillis),适合大堆(>4GB)和低延迟场景 | ✅ JDK 9+ 默认 GC,所有新项目首选; ✅ 必须配 -XX:MaxGCPauseMillis=200(目标停顿 200ms) | -XX:+UseG1GC -XX:MaxGCPauseMillis=200 |
| -XX:+UseZGC | 启用 ZGC(JDK 11+) | 亚毫秒级停顿(<1ms),支持 TB 级堆,基于染色指针(colored pointer) | ✅ JDK 17+ 生产可用;适合超低延迟场景(如高频交易、游戏服务器); ⚠️ 需 Linux 4.14+、x64/AArch64 | -XX:+UseZGC |
| -Xlog:gc*:file=gc.log:time,tags:filecount=5,filesize=50m | 统一 GC 日志(JDK 10+) | 替代旧版 -XX:+PrintGCDetails,结构化、可过滤、支持多文件轮转 | ✅ 生产环境必开! ✅ 推荐配置:带时间戳、标签、5 文件轮转、单文件 50MB | 见上行完整示例 |
| -XX:+PrintTLAB | 输出 TLAB 分配日志 | 记录每次 TLAB refill、浪费字节数、线程 ID,用于分析分配瓶颈 | ✅ 性能调优阶段开启(非长期运行),定位 Allocation Failure 根源 | -XX:+PrintTLAB |
空间分配担保Space Allocation Guarantee
定义
Parallel GC当中在Minor GC流程当中执行的安全检查:
-
检查此次Minor GC最大可能晋升量(当前Eden区对象+From区对象占用的总内存量,也就是假设他们全部存活)
-
并与老年代当前最大可用连续空间进行比较
-
若前者大于后者:立即终止本次Minor GC,触发FullGC
-
Full GC尝试清理整个堆内存空间,为后续MinorGC创建条件
-
FullGC之后仍然无法容纳所有代晋升对象,JVM抛出OOM异常
-
-
后者大于前者:担保成功正常执行MinorGC
堆是分配对象的唯一选择吗
并不是,现代JVM会通过逃逸分析Escape Analysis ,将满足条件的对象"移出堆",分配到栈上,甚至拆解为标量。
核心前提:什么是"逃逸分析"
HotSpot官方定义
逃逸分析是JVM JIT编译器在方法内联(将方法调用转换为被调用方法的函数体,消除调用开销)之后,对对象动态作用域进行静态推断的过程:判断当前对象是否"逃逸"出当前方法、线程的作用范围。
-
未逃逸→可执行站上分配、标量替换等优化
-
逃逸→必须分配在堆上
经典"逃逸"场景
|------|------------------------------------------|------|-----------------------------------|
| 场景 | 代码示例 | 是否逃逸 | 原因 |
| 方法返回 | return new Object(); | ✅ 是 | 对象引用被返回给调用者,作用域超出本方法 |
| 全局共享 | static List list = new ArrayList(); | ✅ 是 | 对象被 static 字段持有,生命周期 > 方法,且跨线程可见 |
| 线程共享 | new Thread(() -> obj.doWork()).start(); | ✅ 是 | 对象被传入新线程,可能被其他线程访问 |
经典未逃逸模式(优化触发点)
public void method() {
// ✅ 未逃逸:对象仅在本方法栈帧内使用,无任何引用传出
StringBuilder sb = new StringBuilder();
sb.append("hello").append("world");
String s = sb.toString(); // toString() 返回新 String,但 sb 本身未逃逸
}👉sb对象是局部变量,未被返回、未被static字段持有、未被穿入线程→JIT可以对其进行优化
💡关键事实:
逃逸分析由C2 JIT编译器在
-server模式下启用(JDK8+默认开启)必须满足方法被频繁调用(达到 TieredStopAtLevel=4 的编译阈值),JIT才会执行逃逸分析
javac编译器(java代码编译为class文件的编译器)、解释执行不进行逃逸分析------这是JIT的优化行为
三大核心优化技术
栈上分配Stack Allocation
定义
JIT判定对象未逃逸 且 大小可控时,不为其在堆上分配内存,而是直接在当前线程的Java栈帧当中分配空间。
对象随着方法退出自动销毁(无需GC回收)
为什么安全
-
栈帧生命周期==方法调用生命周期
-
未逃逸→对象不会被栈外进行访问→栈上分配没有并发、可见性问题
⚠注意:JDK 17+默认禁用栈上分配(实际收益较为有限) ,标量替换默认开启。
标量替换Scalar Replacement
什么是标量
scalar,也就是不能被再分解成为更小数据的数据量。
定义(高频考点)
当JIT判定对象未逃逸(进行分析的时候包含本对象内嵌的对象都进行逃逸分析(分析到最底层),都拆解为标量),且不需要整体保留其对象身份时,将其拆解为构成他的基本字段(int 、long、Object引用等),直接分配在栈上或者寄存器当中
本质
对象实际上"消失了",只剩下构成他的字段
class Point {
int x, y;
Point(int x, int y) { this.x = x; this.y = y; }
}
public int calc() {
Point p = new Point(1, 2); // ✅ 未逃逸
return p.x + p.y; // ✅ 只访问字段,不需 Point 对象本身
}JIT可能优化为:
// 标量替换后等效代码(无 Point 对象):
int x = 1;
int y = 2;
return x + y;同步消除 Lock Elision→常常被忽略的关键优化
定义
若JIT判定一个synchronized 锁对象未逃逸,该锁不会真正进入操作系统互斥量当中,而是被完全消除。
(逻辑上加上了synchronized但是物理上一行锁指令都没有生成,"这个锁没有必要存在",删除掉所有与这个锁相关的字节码、机器指令)
示例
public String concat(String a, String b) {
StringBuilder sb = new StringBuilder(); // ✅ 未逃逸
synchronized(sb) { // ✅ 锁对象未逃逸 → 同步被消除!
sb.append(a).append(b);
}
return sb.toString();
}代码中我们对sb这个对象加锁
但是这个对象的生命周期就在这个方法当中,并不会被其他线程访问,JIT会优化其为:
public String concat(String a, String b) {
StringBuilder sb = new StringBuilder(); // ✅ 未逃逸
sb.append(a).append(b);
return sb.toString();
}回答
现在我们可以回答了,NO