基于MindSpore 和 MindSpore NLP 的 Segment Anything Model(SAM)通用图像分割推理任务
SAM是由Meta AI于2023年发布的一种革命性图像分割模型,被认为是计算机视觉领域的首个基础模型(Foundation Model)。该模型的核心目标是实现"可提示的分割"(Promptable Segmentation),即通过用户提供的各种提示(如点、框、文本等)来分割图像中的任意目标 。
SAM具备强大的零样本泛化能力,无需针对特定任务进行再训练,即可适应新的图像分布和任务。
本案例的运行环境为:
| Python | MindSpore | MindSpore NLP |
|---|---|---|
| 3.11 | 2.7.0 | 0.5.1 |
数据加载
本案例使用 Meta 官方仓库提供的示例图片 dog.jpg。
数据下载
def download_image(url: str, save_dir: str = ".") -> str:
"""
从 URL 下载图片到 save_dir,返回本地文件路径(字符串)。
"""
save_path = Path(save_dir)
save_path.mkdir(parents=True, exist_ok=True)
filename = (url.rsplit("/", 1)[-1] or "image.jpg")
dst = save_path / filename
try:
resp = requests.get(url, timeout=30)
resp.raise_for_status()
dst.write_bytes(resp.content)
print(f"示例图片已成功下载到: {dst}")
return str(dst)
except Exception as e:
print(f"下载示例图片时出错: {e}")
return ""
# 使用示例
image_url = "https://raw.githubusercontent.com/facebookresearch/segment-anything/main/notebooks/images/dog.jpg"
downloaded_image = download_image(image_url)
if downloaded_image:
print(f"示例图片已保存为: {downloaded_image}")
数据加载
读取图片并设置提示框(BBox)
bbox采用 原图坐标系 :[x1, y1, x2, y2]- 你可以通过修改
bbox来框住想要分割的目标区域 - 本单元会把输入框画在原图上,便于检查是否框选正确
img_path = "dog.jpg" # <-- change to your image path
assert os.path.exists(img_path), f"Image not found: {img_path}"
# Custom bbox in original image coordinates [x1,y1,x2,y2]
bbox = [0, 217, 450, 800] # <-- change if needed, ensure in-bounds
bbox = [int(x) for x in bbox] # keep as Python ints for clarity
image = Image.open(img_path).convert("RGB")
W, H = image.size
print("图片尺寸:", (W, H), "| BBox:", bbox)
plt.figure(figsize=(6,4))
plt.imshow(image)
ax = plt.gca()
rect = patches.Rectangle((bbox[0], bbox[1]), bbox[2]-bbox[0], bbox[3]-bbox[1],
linewidth=2, edgecolor='yellow', facecolor='none')
ax.add_patch(rect)
plt.title("Original image with input box")
plt.axis("off")
plt.show()

模型推理
加载模型
MODEL_ID = "facebook/sam-vit-base"
CACHE_DIR = os.path.expanduser("~/.cache/mindnlp") # or "/tmp/mindnlp"
os.makedirs(CACHE_DIR, exist_ok=True)
# (可选)将其他库的缓存目录对齐到同一路径
os.environ["HF_HOME"] = CACHE_DIR
os.environ["MINDNLP_HOME"] = CACHE_DIR
print("正在加载 SAM ...")
processor = SamProcessor.from_pretrained(MODEL_ID, cache_dir=CACHE_DIR)
model = SamModel.from_pretrained(MODEL_ID, cache_dir=CACHE_DIR)
model.set_train(False)
print("加载完成!")windows下记得修改下CACHE_DIR路径为windows格式
传入图像进行推理
SamProcessor 会自动完成:
- 图像缩放 / 填充(padding)
- 输入提示(BBox)整理为模型需要的张量格式
模型输出包含:
pred_masks:候选掩码iou_scores:每张候选掩码的 IoU 评分(可用于挑选最佳结果)
inputs = processor(images=image, input_boxes=[[bbox]], return_tensors="pt")
outputs = model(**inputs)结果可视化展示
候选掩码可视化
pred_masks = outputs.pred_masks # (B, boxes, M, 256, 256)
iou_scores = outputs.iou_scores # (B, boxes, M)
print("pred_masks 形状:", tuple(pred_masks.shape))
print("iou_scores 形状:", tuple(iou_scores.shape))
# preview low-res candidate masks (M masks at 256x256)
pm = pred_masks[0, 0].asnumpy() # (M, 256, 256)
scores_np = iou_scores[0, 0].asnumpy()
M = pm.shape[0]
fig, axes = plt.subplots(1, M, figsize=(4*M, 4))
if M == 1:
axes = [axes]
for i in range(M):
axes[i].imshow(pm[i] > 0, cmap="gray")
axes[i].set_title(f"Mask {i}\nIoU≈{float(scores_np[i]):.3f}")
axes[i].axis("off")
plt.suptitle("Low-res candidate masks (256×256)")
plt.tight_layout()
plt.show()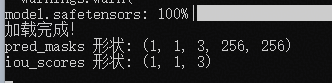

最佳掩码与原图叠加的可视化展示
processor.post_process_masks 会根据预处理时的缩放/填充信息以及原图尺寸,将掩码映射回 原图尺寸,便于直接叠加可视化或后续保存。
最后将最佳掩码以半透明方式叠加到原图并绘制输入框。
upsampled_list = processor.post_process_masks(
pred_masks,
inputs["original_sizes"], # [[H_orig, W_orig]]
inputs["reshaped_input_sizes"], # [[H_in, W_in ]]
)
m = upsampled_list[0] # (boxes, M, H, W) or (M, H, W)
if m.ndim == 4:
m = m[0]
scores_np = iou_scores[0, 0].asnumpy()
best_idx = int(np.argmax(scores_np))
best_score = float(scores_np[best_idx])
best_mask = (m[best_idx].asnumpy() > 0) # (H, W) bool
print("最佳索引:", best_idx, "| IoU:", best_score)
print("最佳掩码形状 (H,W):", best_mask.shape)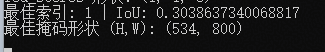

H, W = best_mask.shape
overlay = np.zeros((H, W, 4), dtype=np.uint8)
overlay[best_mask] = np.array([255, 0, 0, 115], dtype=np.uint8) # ~45% alpha
plt.figure(figsize=(8, 6))
plt.imshow(image)
plt.imshow(overlay)
import matplotlib.patches as patches
x1, y1, x2, y2 = bbox
rect = patches.Rectangle((x1, y1), x2 - x1, y2 - y1,
linewidth=2, edgecolor='yellow', facecolor='none')
plt.gca().add_patch(rect)
plt.title(f"IoU: {best_score:.3f}")
plt.axis("off")
plt.tight_layout()
save_path = "dog_segmentation_result.png"
plt.savefig(save_path, dpi=300, bbox_inches="tight")
plt.show()
print("已保存:", save_path)