在后端系统架构中,为了提升读请求性能、减轻数据库压力,我们通常会引入 Redis 等分布式缓存,将热点数据缓存起来,形成「数据库(MySQL)+ 缓存(Redis)」的双层存储架构。
而双写一致性 ,就是指在这种架构下,当数据发生变更时,如何保证 数据库中的数据 与 缓存中的数据 保持一致,避免出现"缓存存旧值、数据库存新值 "或"缓存有值、数据库无值"的脏数据问题,确保业务查询结果的准确性。
前言:MySQL与Redis双写一致性解决方案
保证MySQL和Redis双写一致性,核心是根据业务对"一致性/性能"的要求选择方案,我从核心方案、进阶方案、兜底方案三个维度,结合优缺点和底层逻辑给您讲清楚:
可以根据业务场景选择下述缓存一致性方案:
- 缓存双删:如果公司现有消息队列中间件,可以考虑使用该方案,反之则不需要考虑。
- 先写数据库再删缓存:这种方案从实时性以及技术实现复杂度来说都比较不错,推荐大家使用这种方案。
- Binlog 异步更新缓存:如果希望实现最终一致性以及数据多中心模式,该方案无疑是最合适的。
一、核心方案:延迟双删(最常用,适配80%场景)
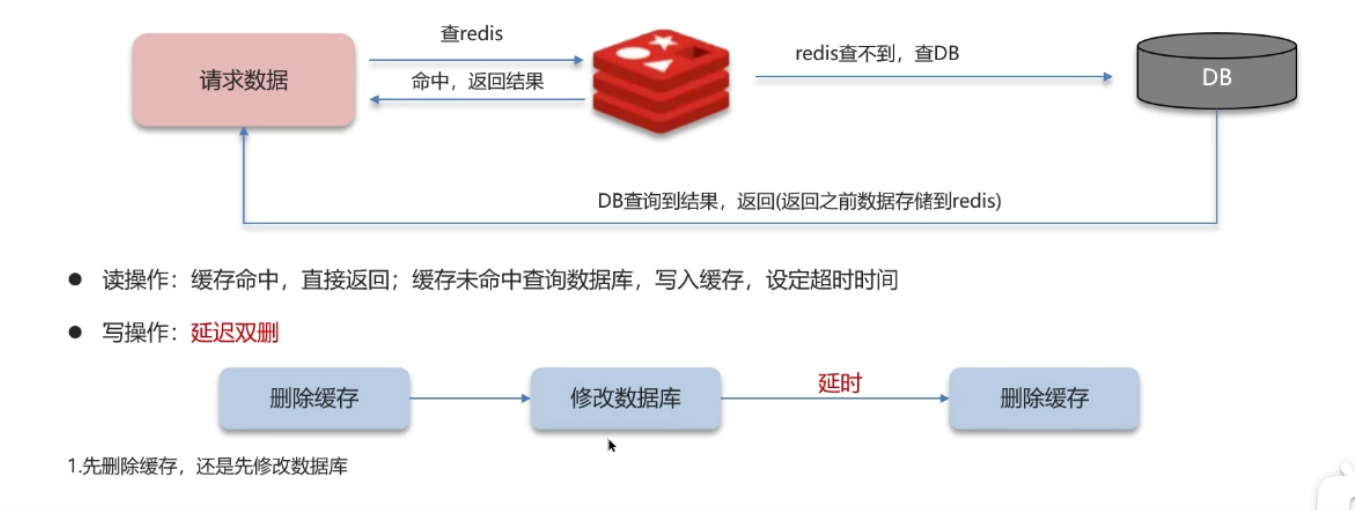
延迟双删其实是对「先删缓存再更新数据库」方案的优化和兜底,而「先更新数据库再删缓存」是另一条独立的主流路径
1. 核心流程
写操作:先删缓存 → 更新数据库 → 延迟N秒(如1-5秒)再删一次缓存
读操作:缓存命中直接返回 → 缓存未命中 → 查数据库 → 回写缓存 → 返回数据
2. 各步骤优缺点
| 步骤 | 优点 | 缺点 |
|---|---|---|
| 先删缓存 | 避免更新DB后,旧缓存被读请求回填 | 极端并发下,仍可能出现脏数据 |
| 更新数据库 | 保证主数据(DB)准确性 | 单步操作,无额外缺点 |
| 延迟删第二次缓存 | 解决并发场景下的脏数据问题 | 增加少量延迟,需控制延迟时长 |
| 读未命中查DB回写缓存 | 保证缓存最终有数据,提升读性能 | 首次读/缓存失效时,有DB查询开销 |

不管是「先操作 Redis(缓存)再操作数据库」,还是「先操作数据库再操作 Redis」,本质上因为两个操作无法原子化执行,且高并发下读 / 写请求的执行顺序不可控,所以必然存在脏数据的可能。
我用两个最典型的并发时序场景,就能说清原因:
场景 1:先删除缓存,再操作数据库(左侧时序)
- 线程 1(写请求):执行第 1 步 → 删除缓存(缓存变为空)
- 线程 2(读请求) :执行第 2 步 → 查询缓存未命中,去数据库查到旧值
20 - 线程 2(读请求) :执行第 3 步 → 把旧值
20写入缓存 - 线程 1(写请求) :执行第 4 步 → 更新数据库为
v=20(这里图里初始 DB 是 20,实际业务里是从旧值更新为新值,核心逻辑不变)
✅ 结果:数据库是新值,缓存里被写入了旧值 → 出现脏数据。
场景 2:先操作数据库,再删除缓存(右侧时序)
- 线程 1(读请求) :执行第 1 步 → 查询缓存未命中,去数据库查到旧值
20 - 线程 2(写请求) :执行第 2 步 → 更新数据库为
v=20(实际业务是从旧值更新为新值) - 线程 2(写请求):执行第 3 步 → 删除缓存(缓存变为空)
- 线程 1(读请求) :执行第 4 步 → 把刚才查到的旧值
20写入缓存
✅ 结果:数据库是新值,缓存里被写入了旧值 → 同样出现脏数据。
不管先操作哪一方,问题的根源都是:
- 操作非原子性:缓存和 DB 的操作是两步独立操作,中间有时间窗口;
- 并发时序不可控:高并发下,读请求可能卡在 "查 DB 拿到旧值" 和 "回写缓存" 之间,写请求刚好完成了更新,导致旧值被写回缓存;
- 缓存回写机制:读请求缓存未命中时,会自动查 DB 并回写缓存,这个 "回写" 动作是脏数据产生的最后一环。
这也是为什么单纯的 "先操作 A 再操作 B" 解决不了问题,需要延迟双删、加锁、异步通知等方案兜底的核心原因。
3. 删两次/延迟删除
- 为什么要删两次缓存?
解决"读请求在写请求更新DB前,已查到旧值并准备回写缓存"的极端场景:
例:① 读请求缓存失效 → ② 读DB拿到旧值 → ③ 写请求删缓存 → ④ 写请求更DB → ⑤ 读请求把旧值写入缓存 → ⑥ 延迟删缓存,清空这个旧值。
第二次删除是为了兜底,清空并发场景下被误写入的旧缓存。 - 为什么要延迟删除?
延迟时长需覆盖"读请求查DB+回写缓存"的耗时(一般1-5秒),确保能删掉"被并发读请求回填的旧缓存",如果立刻删第二次,可能读请求还没完成回写,删了也没用。
二、进阶方案:互斥锁/读写锁(强一致性场景)
互斥锁:强一致、性能低:
读多写少,一般采用缓存
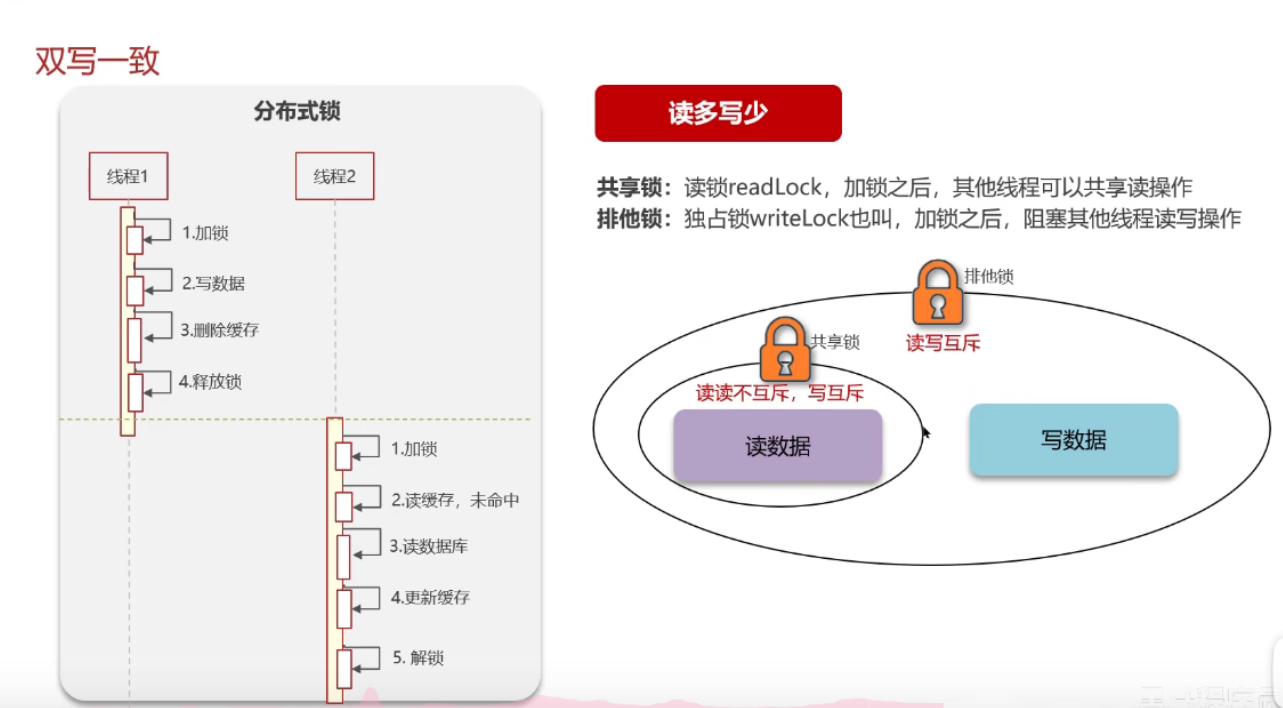
1. 互斥锁(分布式锁,如Redisson RLock)
-
流程:
-
- 写操作加排他锁 → 删缓存 → 更新DB → 释放锁;
- 读操作加共享锁 → 缓存未命中时,加排他锁查DB回写缓存。
-
优点:严格保证数据强一致,无脏数据;
-
缺点:加锁会阻塞请求,降低并发性能,可能出现死锁(需设置锁超时)。
2. 读写锁(Redisson ReadWriteLock)
- 共享锁(读锁):多个读请求可同时加锁,不阻塞,保证读性能;
- 排他锁(写锁):写请求加锁后,阻塞所有读/写请求,保证写操作原子性;
- 适用场景:读多写少、对一致性要求极高的场景(如库存、优惠券);
- 缺点:写请求会阻塞读请求,高并发写场景性能下降。
3.代码实现
核心说明
- 锁粒度 :读写锁使用同一个 key
ITEM_READ_WRITE_LOCK,保证读写互斥、读读共享。 - 写锁逻辑 :写操作加排他锁,期间所有读 / 写请求都会阻塞,保证数据更新的原子性,更新后删除缓存触发下一次读请求重建缓存。
- 读锁逻辑 :读操作加共享锁,多个读请求可并发执行;写锁释放前,读锁会等待,避免读到脏数据。
- 兜底保障 :
finally块中释放锁,确保即使业务异常也不会导致锁泄漏。
排他锁(写锁)
java
public void updateById(Integer id) {
// 获取读写锁
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("ITEM_READ_WRITE_LOCK");
// 获取写锁
RLock writeLock = readWriteLock.writeLock();
try {
// 加写锁
writeLock.lock();
System.out.println("writeLock...");
// 1. 更新业务数据(示例:模拟更新商品信息)
Item item = new Item(id, "华为手机", "华为手机", 5299.00);
try {
// 模拟业务处理耗时
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 2. 删除缓存
redisTemplate.delete("item:" + id);
} finally {
// 释放写锁
writeLock.unlock();
}
}共享锁(读锁)
java
public Item getById(Integer id) {
// 获取读写锁
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("ITEM_READ_WRITE_LOCK");
// 获取读锁
RLock readLock = readWriteLock.readLock();
try {
// 加读锁
readLock.lock();
System.out.println("readLock...");
// 1. 先查询缓存
Item item = (Item) redisTemplate.opsForValue().get("item:" + id);
if (item != null) {
// 缓存命中,直接返回
return item;
}
// 2. 缓存未命中,查询业务数据(示例:模拟从数据库查询)
item = new Item(id, "华为手机", "华为手机", 5999.00);
// 3. 写入缓存
redisTemplate.opsForValue().set("item:" + id, item);
// 4. 返回数据
return item;
} finally {
// 释放读锁
readLock.unlock();
}
}三、高级方案:异步通知(解耦+高可用)
1. MQ异步通知方案
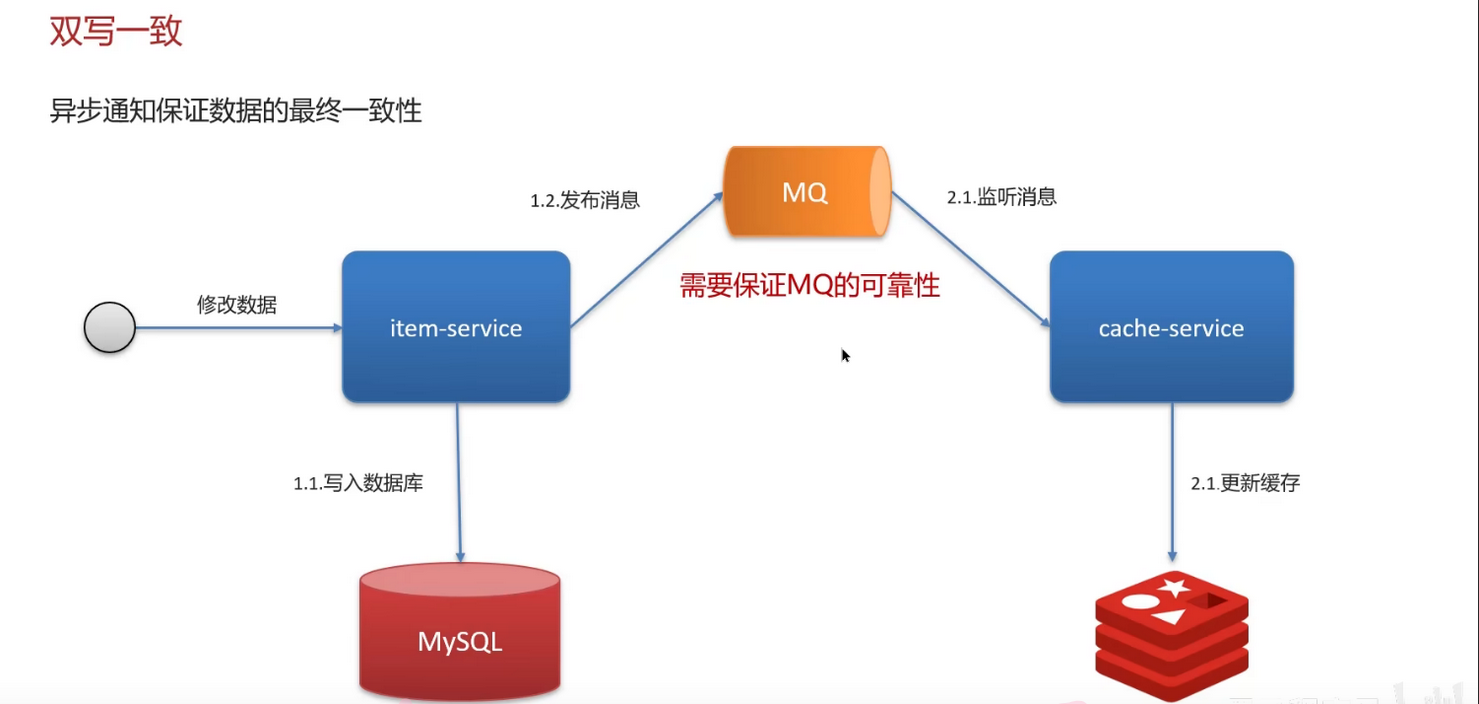
- 流程:更新DB → 发送"删除缓存"消息到MQ → 消费端监听消息 → 删除缓存;
- 核心优势 :利用MQ的持久化+重试机制,保证缓存最终被删除,且业务线程无需等待缓存操作,接口响应快;
- 缺点:有代码侵入(需业务主动发消息),消息延迟可能导致短暂不一致。
2. Canal(阿里)异步同步方案
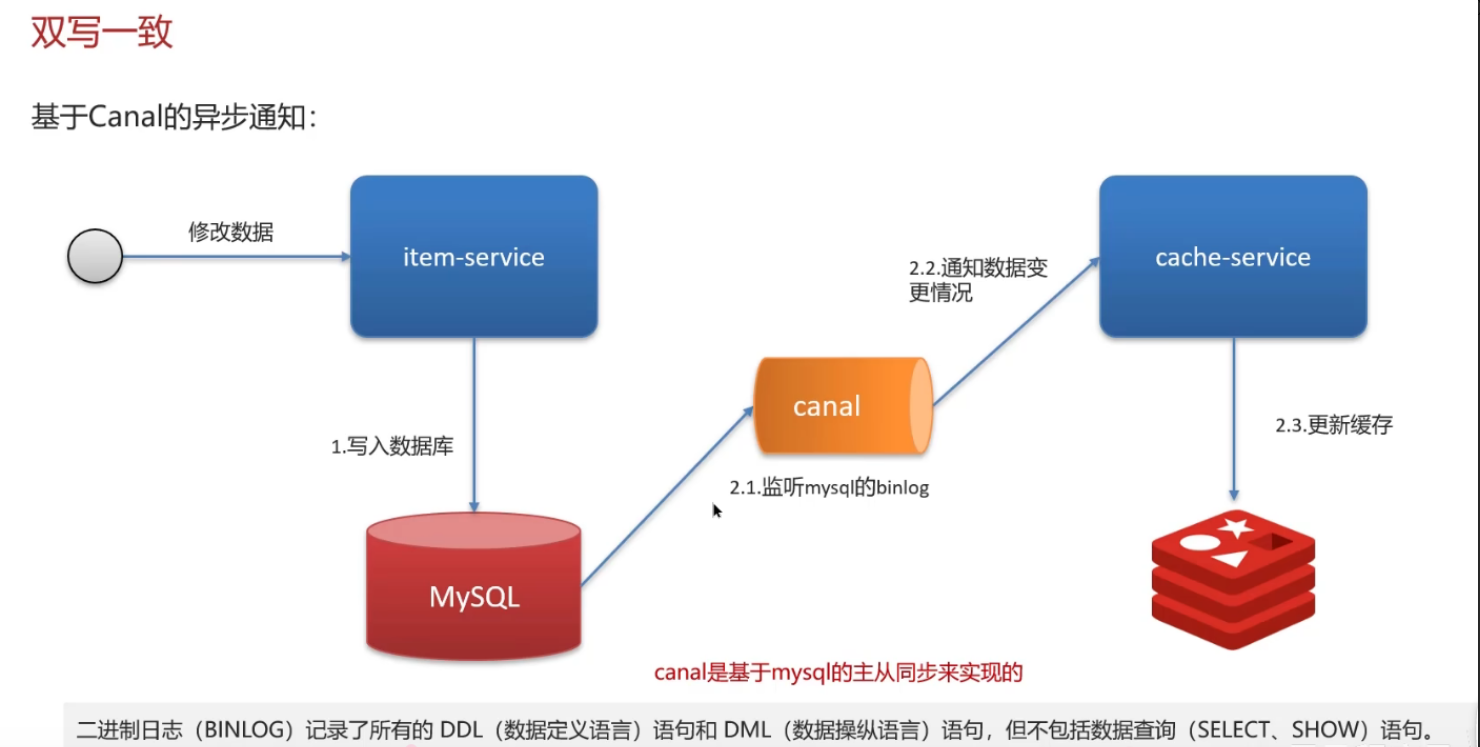
- 原理:Canal伪装成MySQL从库,读取MySQL的Binlog(数据变更日志) → 解析Binlog → 异步更新/删除Redis缓存;
- 优点:零业务代码侵入,Binlog天然有序,能保证更新顺序,一致性更高;
- 缺点:部署维护成本高,Binlog解析有轻微延迟(毫秒级),不适合极致强一致场景。
四、补充方案
- 定时任务兜底:对核心数据,定时从DB全量同步到Redis,修正可能的不一致(适合数据变更频率低的场景);
- TTL兜底:给缓存设置合理过期时间,即使出现脏数据,也会自动过期,保证最终一致;
- 全量更新(不推荐):写操作直接更新DB+更新缓存,优点是简单,缺点是性能差(很多更新无意义)、并发下易出现数据覆盖。
五、总结
- 性能优先、允许短暂不一致:选延迟双删(核心)+ MQ/Canal兜底;
- 强一致性优先、读多写少:选Redisson读写锁;
- 不想侵入业务代码、追求极致解耦:选Canal方案;
- 中小规模业务:延迟双删即可满足需求,无需过度设计。
关键点回顾
- 延迟双删是基础方案,两次删除的核心是解决"并发读回填旧缓存"问题,延迟时长需覆盖读请求回写缓存的耗时;
- 互斥锁/读写锁保证强一致,但牺牲性能,适配库存、优惠券等核心场景;
- MQ/Canal是异步解耦方案,利用MQ可靠性 /Canal零侵入特性,保证最终一致性。