目录规划
为了将这所有博客里的知识点逻辑顺畅地串联起来,特此设计了以下目录结构。这个顺序遵循了"概念引入 -> 基础回归 -> 分类进阶 -> 无监督学习"的学习路径:
- 第一章:启蒙篇------人工智能与机器学习的宏观版图
- 来源博客:人工智能和机器学习
- 核心内容:AI、ML、DL的关系,机器学习的分类(监督/无监督/强化),基本工作流程。
- 第二章:基石篇------预测连续值的线性回归
- 来源博客:线性回归
- 核心内容:一元/多元线性回归,损失函数,梯度下降,代码实战。
- 第三章:进阶篇------解决分类问题的逻辑回归
- 来源博客:逻辑回归
- 核心内容:从回归到分类的跨越,Sigmoid函数,决策边界,代码实战。
- 第四章:直觉篇------基于距离的K-近邻 (KNN)
- 来源博客:KNN算法
- 核心内容:KNN原理,K值选择,距离计算,优缺点分析,代码实战。
- 第五章:探索篇------发现数据内在结构的聚类算法
- 来源博客:聚类算法
- 核心内容:K-Means原理,簇的概念,与分类的区别,应用场景。
- 第六章:总结与展望
- 综合对比五大算法,如何选择适合的模型。
文章目录
- 目录规划
- 第六章:总结与展望------构建你的机器学习工具箱
-
- [6.1 终极对决:五大算法横向对比](#6.1 终极对决:五大算法横向对比)
- [6.2 实战指南:如何选择合适的算法?](#6.2 实战指南:如何选择合适的算法?)
- [6.3 标准工作流:从数据到模型](#6.3 标准工作流:从数据到模型)
- [6.4 常见陷阱与避坑指南](#6.4 常见陷阱与避坑指南)
- [6.5 未来展望:从传统机器学习到深度学习](#6.5 未来展望:从传统机器学习到深度学习)
- [6.6 结语](#6.6 结语)
第六章:总结与展望------构建你的机器学习工具箱
导读:恭喜你!至此,你已经完成了从"预测数值"到"分类决策",再到"无监督探索"的完整机器学习入门旅程。
在前五章中,我们深入剖析了五大核心算法:线性回归、逻辑回归、KNN、K-Means 。但掌握算法只是第一步,真正的挑战在于:面对一个具体的业务问题,我该如何选择最合适的工具?
本章作为全书的终章,将不再引入新公式,而是致力于融会贯通 。我们将提供一份实用的算法选型指南 ,梳理机器学习的标准工作流,并展望未来的发展趋势,助你从"学习者"蜕变为"实践者"。
6.1 终极对决:五大算法横向对比
为了让你一目了然,我们将前五章的核心内容浓缩为一张"武功秘籍"对比表:
| 特性 | 线性回归 | 逻辑回归 | K-近邻 (KNN) | K-Means |
|---|---|---|---|---|
| 学习类型 | 监督学习 | 监督学习 | 监督学习 | 无监督学习 |
| 任务目标 | 回归 (预测连续值) | 分类 (二分类/概率) | 分类/回归 (多分类) | 聚类 (发现分组) |
| 核心思想 | 拟合直线/平面,最小化误差 | Sigmoid映射 + 最大似然估计 | "近朱者赤",基于距离投票 | 迭代更新中心,物以类聚 |
| 模型参数 | w , b w, b w,b (需训练) | w , b w, b w,b (需训练) | 无 (懒惰学习) | 簇中心 (需迭代) |
| 关键超参数 | 无 (或正则化系数) | 正则化系数 C C C | K K K值 (邻居数) | K K K值 (簇数量) |
| 数据要求 | 线性关系,需处理异常值 | 线性可分 (或特征工程) | 必须特征缩放,对噪声敏感 | 必须特征缩放,适合球形簇 |
| 训练速度 | 快 (正规方程) / 中 (梯度下降) | 快 | 极快 (无训练) | 中 (迭代收敛) |
| 预测速度 | 极快 (公式计算) | 极快 (公式计算) | 慢 (需遍历全量数据) | 快 (计算到中心距离) |
| 可解释性 | ⭐⭐⭐⭐⭐ (权重即影响) | ⭐⭐⭐⭐⭐ (概率清晰) | ⭐⭐ (依赖邻居,难解释) | ⭐⭐ (需人工解读簇含义) |
| 典型场景 | 房价预测、销量预估 | 垃圾邮件、疾病诊断 | 推荐系统(简单版)、文本分类 | 用户分群、图像压缩 |
6.2 实战指南:如何选择合适的算法?
当你拿到一个新问题时,请遵循以下决策树:
第一步:我有标签(正确答案)吗?

第二步:我要预测的是什么?

第三步:数据的规模和特征如何?

💡 专家建议:在实际工程中,通常不会只试一个算法。标准的做法是:
- 先用 逻辑回归 或 线性回归 建立一个基线 (Baseline)。
- 再尝试 KNN 或其他更复杂的模型。
- 对比效果,如果复杂模型提升不明显,根据"奥卡姆剃刀原则",选择更简单、更易维护的模型。
6.3 标准工作流:从数据到模型
掌握了算法只是拥有了"武器",要打赢仗还需要"战术"。一个完整的机器学习项目通常包含以下步骤:
- 问题定义:明确业务目标(是预测还是分类?)。
- 数据收集:获取原始数据。
- 数据预处理 (最关键的一步,占80%时间) :
- 清洗:处理缺失值、去除重复值。
- 异常值处理:识别并剔除/修正离群点。
- 特征工程 :
- 编码:将文本类别转为数字 (One-Hot Encoding)。
- 缩放 :KNN 和 K-Means 必做,线性模型建议做。
- 构造:创造新特征 (如:从"出生日期"提取"年龄")。
- 数据集划分 :训练集 (70-80%) + 测试集 (20-30%)。严禁用测试集训练!
- 模型选择与训练:选择合适的算法进行拟合。
- 模型评估 :
- 回归:MSE, RMSE,
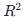 。
。 - 分类:Accuracy, Precision, Recall, F1-Score, ROC/AUC。
- 聚类:SSE, 轮廓系数。
- 回归:MSE, RMSE,
- 调优:调整超参数 (如 KNN 的 K,逻辑回归的 C)。
- 部署与监控:将模型应用到生产环境,并持续监控其表现。
6.4 常见陷阱与避坑指南
在初学者实践中,以下几个错误最高频:
- 忘记特征缩放 :
- 后果:KNN 和 K-Means 完全失效;梯度下降收敛极慢。
- 对策 :只要涉及距离计算或梯度下降,先
StandardScaler准没错。
- 数据泄露 (Data Leakage) :
- 后果:训练时准确率 99%,上线后只有 50%。
- 原因 :在划分训练/测试集之前就做了标准化(导致测试集的信息泄露到了训练集的均值/方差中),或者使用了未来数据作为特征。
- 对策 :严格遵循
Split->Fit on Train->Transform Train & Test的顺序。
- 过度追求复杂模型 :
- 后果:模型过拟合,泛化能力差,且难以解释。
- 对策:Always Start Simple (永远从简单模型开始)。
- 忽视类别不平衡 :
- 后果:在欺诈检测中,模型全部预测"正常",准确率 99%,但毫无用处。
- 对策:关注 Recall/F1 分数,使用重采样或调整分类阈值。
6.5 未来展望:从传统机器学习到深度学习
我们所学的这五种算法构成了传统机器学习 (Traditional Machine Learning) 的基石。它们在结构化数据(表格数据)上依然表现卓越,是工业界的主力军。
但随着数据形态的变化,机器学习也在进化:
- 非结构化数据:面对图像、语音、文本,传统算法往往需要大量的人工特征工程。
- 深度学习 (Deep Learning) :通过神经网络自动提取特征,在计算机视觉 (CNN)、自然语言处理 (Transformer/LLM) 领域取得了颠覆性的成果。
- 强化学习 (Reinforcement Learning):让智能体在与环境交互中学习策略(如 AlphaGo、自动驾驶)。
你的下一步:
- 巩固基础:熟练运用 sklearn 复现本章所有代码。
- 拓展算法:学习决策树、随机森林、XGBoost(表格数据王者)、SVM。
- 拥抱深度:如果对图像/NLP感兴趣,可以开始学习 PyTorch 或 TensorFlow,探索神经网络的世界。
6.6 结语
机器学习不是魔法,它是统计学、线性代数和计算机科学的优雅结合。
- 线性回归教会我们要寻找规律。
- 逻辑回归教会我们要量化不确定性。
- KNN教会我们要参考周围的环境。
- K-Means教会我们在混乱中发现秩序。
希望这套教程能成为你探索人工智能世界的坚实起点。记住,最好的学习方式就是动手去做。找一个你感兴趣的数据集,提出一个问题,然后尝试用今天学到的知识去解决它吧!
祝你在数据科学的道路上,乘风破浪,探索无限可能!
(全文完)