学习笔记|B站UP主 刘二大人 《PyTorch深度学习实践》视频知识点总结
传送门 PyTorch深度学习实践------循环神经网络
1. RNN核心原理与数学表达
1.1 什么是循环神经网络
全连接网络与卷积神经网络均为前馈网络 ,数据单向流动,无法处理序列数据的时序依赖关系;而RNN(循环神经网络) 引入了时序记忆机制,能够保留前一时刻的隐藏状态信息,实现对序列数据(文本、时序信号、语音、序列图像等)的特征提取,特别适合处理具有先后顺序、前后关联的输入数据。
1.2 基础RNN数学计算公式
对于时序输入序列 x t x_t xt( t t t 代表时刻),RNN的核心运算分为两步,核心是隐藏状态的循环传递:
h t = tanh ( W i h x t + b i h + W h h h t − 1 + b h h ) h_t = \tanh(W_{ih}x_t + b_{ih} + W_{hh}h_{t-1} + b_{hh}) ht=tanh(Wihxt+bih+Whhht−1+bhh)
y ^ t = W h o h t + b h o \hat{y}t = W{ho}h_t + b_{ho} y^t=Whoht+bho
符号说明
- x t x_t xt : t t t 时刻的输入特征
- h t h_t ht : t t t 时刻的隐藏状态,承载当前时刻+历史时刻的序列信息
- h t − 1 h_{t-1} ht−1 : t − 1 t-1 t−1 时刻的隐藏状态,实现时序信息传递
- W i h / W h h / W h o W_{ih}/W_{hh}/W_{ho} Wih/Whh/Who:输入-隐藏、隐藏-隐藏、隐藏-输出的权重矩阵
- b i h / b h h / b h o b_{ih}/b_{hh}/b_{ho} bih/bhh/bho:对应权重的偏置项
- tanh \tanh tanh :激活函数,将隐藏状态值压缩至 ( − 1 , 1 ) (-1,1) (−1,1)区间,保证数值稳定
2. 直观流程理解
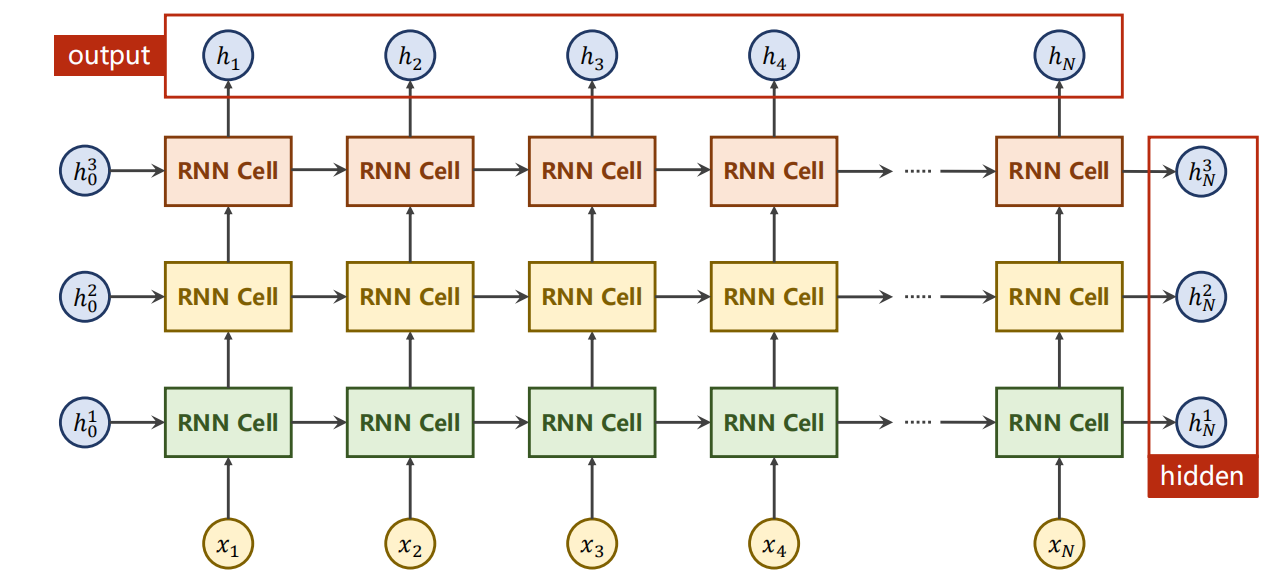
这张图展示的是**多层循环神经网络(Deep RNN)**的展开结构:
2.1 整体结构:多层RNN的时序展开
- 垂直方向 :代表网络层数 (图中是3层RNN堆叠,
num_layers=3) - 水平方向 :代表时序步 (从 x 1 x_1 x1 到 x N x_N xN,共 N N N 个时间步)
- 每一个彩色方块是一个RNN Cell(循环单元),同一层的所有Cell共享一套权重参数
2.2 输入与初始状态
- 最下方的 x 1 , x 2 , ... , x N x_1, x_2, \dots, x_N x1,x2,...,xN:时序输入序列(比如文本的词向量、语音帧、图像行)
- 每层左侧的 h 0 1 , h 0 2 , h 0 3 h^1_0, h^2_0, h^3_0 h01,h02,h03:各层初始隐藏状态(通常初始化为全0向量,承载上一层的记忆)
2.3 信息流动过程
- 第1层(最下方绿色)
- 输入: x t x_t xt + 上一时刻隐藏状态 h t − 1 1 h^1_{t-1} ht−11
- 输出:当前时刻隐藏状态 h t 1 h^1_t ht1,传递给第2层作为输入
- 第2层(中间黄色)
- 输入:第1层输出 h t 1 h^1_t ht1 + 上一时刻隐藏状态 h t − 1 2 h^2_{t-1} ht−12
- 输出:当前时刻隐藏状态 h t 2 h^2_t ht2,传递给第3层
- 第3层(最上方浅红色)
- 输入:第2层输出 h t 2 h^2_t ht2 + 上一时刻隐藏状态 h t − 1 3 h^3_{t-1} ht−13
- 输出:当前时刻隐藏状态 h t 3 h^3_t ht3,同时作为该时刻的输出 h t h_t ht(红色框标注)
2.4 输出与最终隐藏状态
- 输出(红色上框) : h 1 , h 2 , ... , h N h_1, h_2, \dots, h_N h1,h2,...,hN → 每个时序步 t t t 对应一个输出,由最上层RNN Cell 的隐藏状态 h t 3 h^3_t ht3 得到
- 最终隐藏状态(红色右框) : h N 1 , h N 2 , h N 3 h^1_N, h^2_N, h^3_N hN1,hN2,hN3 → 序列结束时,每一层最后一个时刻的隐藏状态,承载了整个序列的全局信息,可用于序列分类等任务
4. One-hot vs Embedding
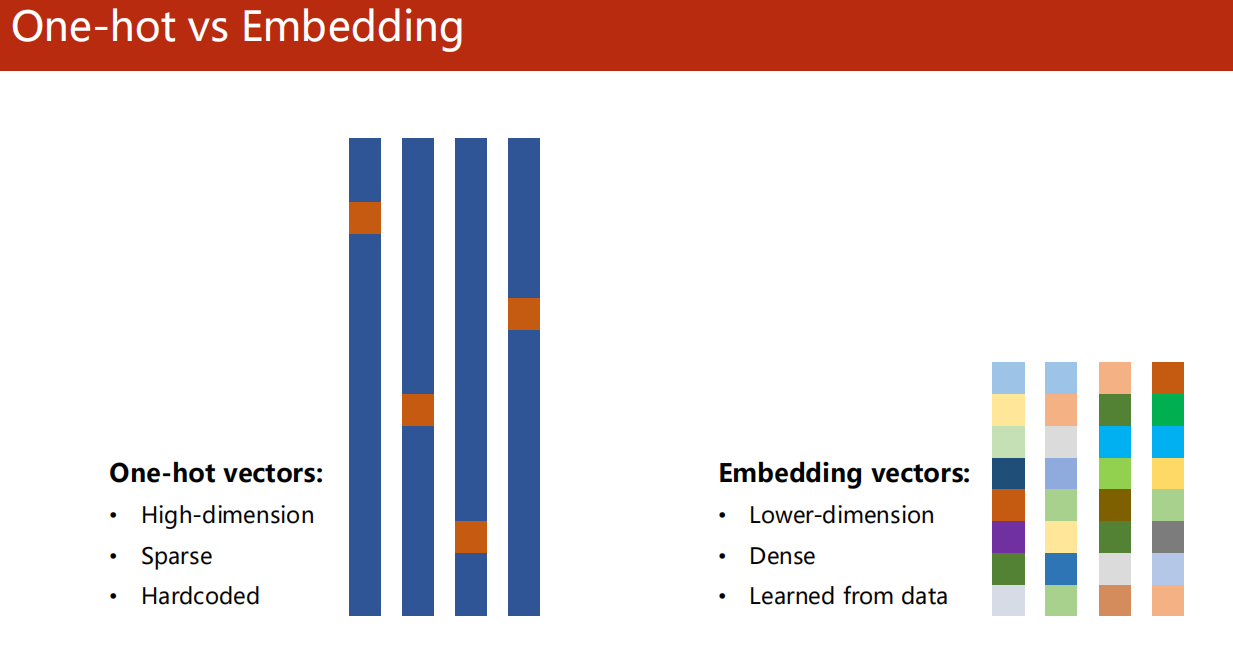
3.1独热编码(One-hot)
独热编码是给每个离散特征 (比如单词、类别)分配一个高维度 的稀疏向量 ,向量维度等于特征总数,且只有对应位置为1、其余全为0。它的核心问题是维度会随特征数量爆炸式增长 ,且完全无法体现特征间的语义关联 (比如"苹果"和"香蕉"的向量毫无相似性),是一种简单但低效的硬编码方式。
3.2 词嵌入(Embedding)
词嵌入是将离散特征映射到低维度 的稠密向量 ,维度可自定义(如50/128维),且向量数值从数据中学习得到 。它能自动捕捉特征的语义关联 (比如"猫"和"狗"的向量更接近),维度可控、信息密度高,是深度学习中处理文本/离散特征的核心方式 ,也是替代独热编码的最优选择。
4. PyTorch RNN核心API与维度说明
课程中针对MNIST手写数字识别任务,将28×28的图像看作28个时序步,每步输入28维特征,借助RNN完成分类,核心API解析如下:
-
torch.nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
- input_size:每一步输入的特征维度(MNIST任务中为28)
- hidden_size:隐藏层神经元数量,自定义设置(控制记忆容量)
- num_layers:RNN堆叠层数,单层设为1即可
- batch_first=True :输入维度格式为 b a t c h _ s i z e , s e q _ l e n , i n p u t _ s i z e batch\\_size, seq\\_len, input\\_size batch_size,seq_len,input_size,适配数据加载习惯
-
输入输出维度:
- 输入: b a t c h , s e q _ l e n , i n p u t _ s i z e batch, seq\\_len, input\\_size batch,seq_len,input_size → 批次大小×时序步长×单步特征数
- 输出隐藏状态: b a t c h , s e q _ l e n , h i d d e n _ s i z e batch, seq\\_len, hidden\\_size batch,seq_len,hidden_size → 每一步的隐藏特征
5. 课程完整源代码(CPU+GPU通用版)
基于MNIST数据集实现RNN手写数字分类,代码贴合课程逻辑,注释详尽,新手可直接运行:
python
import torch
import torch.nn as nn
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
import torch.optim as optim
# 超参数设置
batch_size = 64
input_size = 28 # 每步输入特征维度
seq_len = 28 # 时序步长
hidden_size = 64 # 隐藏层维度
num_layers = 1 # RNN层数
num_classes = 10 # 分类类别
epochs = 10 # 训练轮次
lr = 0.001 # 学习率
# 数据预处理与加载
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 加载MNIST数据集
train_dataset = datasets.MNIST(root='./dataset/mnist', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./dataset/mnist', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 定义RNN模型
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# 定义RNN层
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
# 全连接层:取最后一步的隐藏状态输出
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
# 初始化隐藏状态 h0: [num_layers, batch_size, hidden_size]
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
# RNN前向传播:out包含所有时序步的隐藏状态
out, _ = self.rnn(x, h0)
# 取最后一个时序步的输出做分类
out = out[:, -1, :]
out = self.fc(out)
return out
# 设备配置(GPU/CPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = RNN(input_size, hidden_size, num_layers, num_classes).to(device)
# 损失函数与优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# 训练函数
def train(epoch):
model.train()
running_loss = 0.0
for batch_idx, (data, targets) in enumerate(train_loader):
# 数据维度转换:[batch, 1, 28, 28] → [batch, 28, 28]
data = data.reshape(-1, seq_len, input_size).to(device)
targets = targets.to(device)
# 前向传播
outputs = model(data)
loss = criterion(outputs, targets)
# 反向传播与优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
# 每300个batch打印损失
if batch_idx % 300 == 299:
print(f'[Epoch {epoch+1}, Batch {batch_idx+1}] Loss: {running_loss/300:.4f}')
running_loss = 0.0
# 测试函数
def test():
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data, targets in test_loader:
data = data.reshape(-1, seq_len, input_size).to(device)
targets = targets.to(device)
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
print(f'Test Accuracy: {100*correct/total:.2f}%')
# 主程序
if __name__ == '__main__':
for epoch in range(epochs):
train(epoch)
test()
- 数据维度变换是核心 :MNIST原始数据为 b a t c h , 1 , 28 , 28 batch,1,28,28 batch,1,28,28,需reshape为 b a t c h , 28 , 28 batch,28,28 batch,28,28,适配RNN序列输入格式;
- RNN输出取最后一步隐藏状态 :序列任务中,最后一步的隐藏状态承载了全序列信息,适合分类任务;
- 隐藏状态初始化 :初始时刻无历史信息,默认用全0向量初始化,保证训练稳定。