一、引言
在拉丁美洲的展会网站中,巴西的网站往往采用独特的技术架构。本文以巴西国际塑料橡胶工业展览会(INTERPLAST)参展商信息采集项目为例,深入剖析在开发过程中遇到的四大技术难题,以及我们如何通过创新的技术方案逐一攻克这些难关。这个项目的特殊性在于,它采用了嵌入式页面结构,所有数据都隐藏在复杂的表单元素中。
二、技术难点全景图
四大技术难关
ID隐式传参机制
URL中隐藏ID
正则表达式提取
两种URL格式
ID拼接详情页
多页面字段分散存储
列表页提取名称
详情页提取详情
input标签取值
profile独立区域
数据强制覆盖策略
DELETE先删除
每次重新插入
最新数据保障
无增量更新
无分页列表解析
单页全部加载
div.col定位
href路径拼接
全量一次性获取
三、核心难题攻克详解
3.1 难关一:ID隐式传参机制
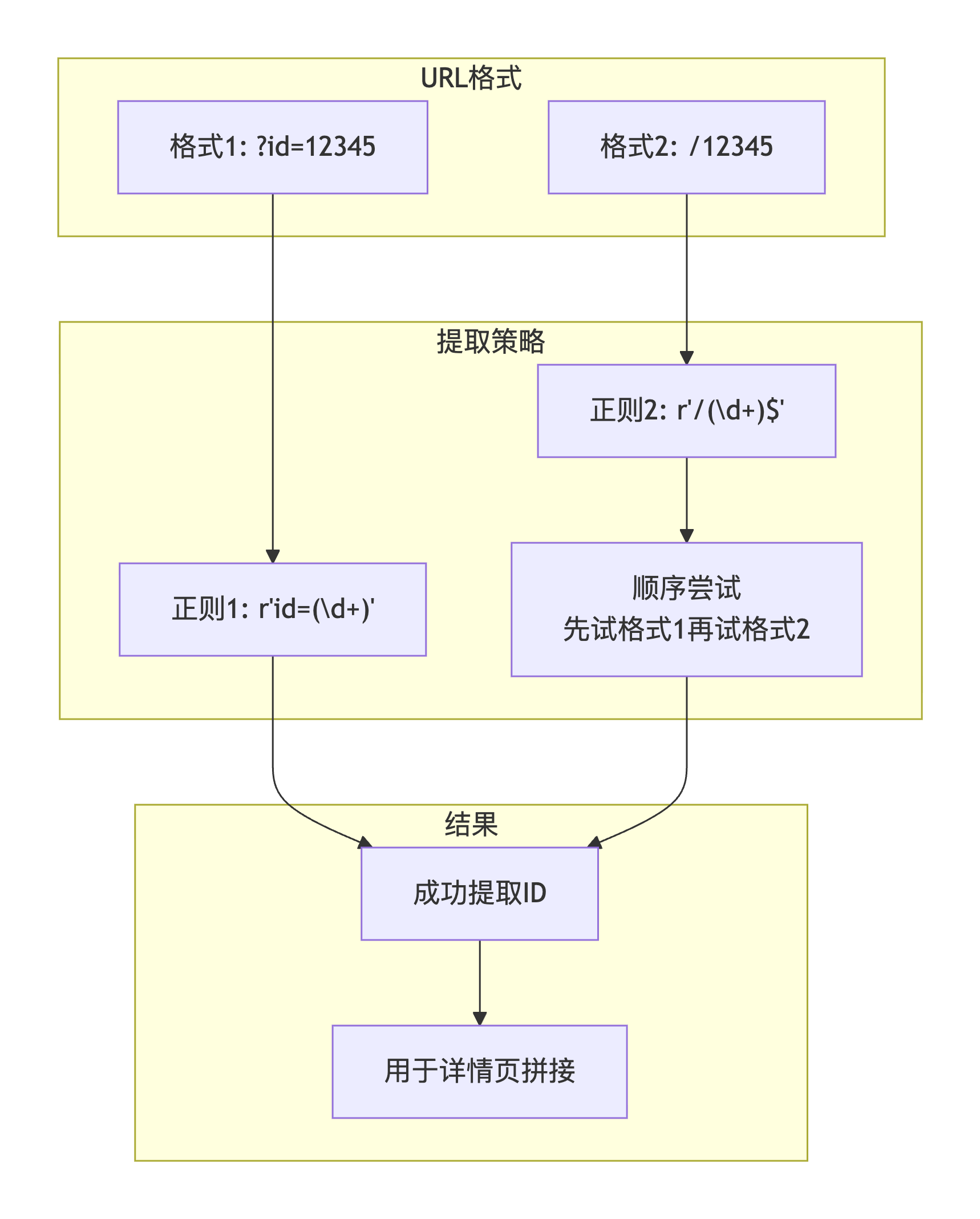
问题描述 :
网站采用隐式ID传参方式,公司ID不直接显示,而是隐藏在URL路径中。存在两种URL格式,需要灵活提取。
html
<!-- URL格式1:查询参数形式 -->
<a href="/embedded/xxx/exhibitors?id=12345">公司A</a>
<!-- URL格式2:路径参数形式 -->
<a href="/embedded/xxx/exhibitors/12345">公司B</a>攻克方案 :
核心代码实现:
python
def extract_id_from_url(url):
"""
攻克ID隐式传参难题
策略:尝试两种URL格式,任一成功即可
"""
# 格式1:?id=12345
match = re.search(r'id=(\d+)', url)
if match:
return match.group(1)
# 格式2:/12345
match = re.search(r'/(\d+)$', url)
if match:
return match.group(1)
return None3.2 难关二:多页面字段分散存储
问题描述 :
展商信息分散存储在列表页和详情页多个位置:列表页只有公司名称,详情页包含地址、电话、网站等基础信息,还有独立的profile区域存放公司描述。字段都隐藏在input标签的value属性中。
html
<!-- 列表页:只有公司名称 -->
<div class="col-sm-9">
<a href="...">
<h4>公司名称</h4>
</a>
</div>
<!-- 详情页:字段存储在input标签 -->
<input id="fancy_name" value="公司全称">
<input id="address" value="详细地址">
<input id="phone" value="电话号码">
<input id="website" value="公司网址">
<input id="booth_numbers" value="展位号">
<!-- 独立区域:公司描述 -->
<div id="org_profile">
<div class="panel-body">
公司详细描述...
</div>
</div>攻克方案:
数据融合
详情页采集
列表页采集
解析HTML
定位div.col
提取a.h4标签
获取公司名称
获取详情页URL
请求详情页
input标签提取
fancy_name
address
phone
website
booth_numbers
profile区域提取
定位div#org_profile
panel-body文本
合并数据
核心代码实现:
python
def fetch_exhibitor_detail(company_id):
"""攻克多页面字段分散难题"""
url = DETAIL_BASE_URL.format(id=company_id)
response = requests.get(url, headers=HEADERS)
soup = BeautifulSoup(response.text, "html.parser")
# 第一步:input标签取值函数
def get_value(input_id):
tag = soup.find("input", {"id": input_id})
return tag.get("value", "").strip() if tag else ""
# 第二步:从input标签提取基础字段
fancy_name = get_value("fancy_name")
address = get_value("address")
phone = get_value("phone")
website = get_value("website")
booth = get_value("booth_numbers")
# 第三步:从独立区域提取描述
profile_div = soup.find("div", id="org_profile")
profile_text = ""
if profile_div:
body = profile_div.find("div", class_="panel-body")
if body:
profile_text = body.get_text(separator="\n", strip=True)
# 第四步:融合所有数据
return {
"fancy_name": fancy_name,
"address": address,
"phone": phone,
"website": website,
"booth_numbers": booth,
"profile": profile_text
}3.3 难关三:数据强制覆盖策略
问题描述 :
业务需求要求每次运行都必须抓取最新数据,不能保留旧数据。传统的ON DUPLICATE KEY UPDATE无法满足需求,需要先删除再插入。
攻克方案:
效果对比
强制覆盖策略
传统策略
INSERT ON DUPLICATE
更新变化字段
可能残留旧数据
DELETE FROM
WHERE name = %s
删除旧记录
INSERT新数据
完全最新数据
数据可能不一致
100%最新数据
核心代码实现:
python
def insert_single_data_to_db(data):
"""攻克数据强制覆盖难题"""
try:
conn = pymysql.connect(**DB_CONFIG)
cursor = conn.cursor()
# 第一步:先删除已存在的数据
# 确保每次运行都重新插入最新数据
cursor.execute("DELETE FROM exhibition WHERE name = %s", (data["name"],))
# 第二步:插入全新数据
sql = """
INSERT INTO exhibition (
name, full_address, country, location, email, phone,
contact_person, link, description, crawl_source,
exhibition_name, exhibition_edition
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
cursor.execute(sql, (
data["name"], data["full_address"], data["country"],
data["location"], data["email"], data["phone"],
data["contact_person"], data["link"], data["description"],
data["crawl_source"], data["exhibition_name"], data["exhibition_edition"]
))
conn.commit()
print(f"[DB] 插入成功: {data['name']}")
return True
except pymysql.MySQLError as e:
print(f"[DB] 插入失败: {e}")
return False3.4 难关四:无分页列表解析
问题描述 :
网站列表页采用单页全部加载方式,没有分页机制。需要通过CSS类名精确定位目标元素,并进行相对URL拼接。
html
<!-- 所有展商一次性加载 -->
<div class="col-sm-9 col-md-10 col-lg-11">
<a href="/embedded/xxx/exhibitors?id=123" class="list-group-item-heading">
<h4>公司A</h4>
</a>
</div>
<div class="col-sm-9 col-md-10 col-lg-11">
<a href="/embedded/xxx/exhibitors?id=456" class="list-group-item-heading">
<h4>公司B</h4>
</a>
</div>
<!-- ... 更多展商全部在同一个页面 -->攻克方案:
数据处理
元素提取
页面分析
请求列表页
定位所有
col-sm-9 div
遍历每个div
查找a标签
class=list-group-item-heading
提取h4文本
公司名称
提取href属性
相对路径
urljoin拼接
完整URL
extract_id
提取ID
存储数据
核心代码实现:
python
def fetch_exhibitors():
"""攻克无分页列表解析难题"""
response = requests.get(LIST_URL, headers=HEADERS)
soup = BeautifulSoup(response.text, "html.parser")
# 第一步:精确定位所有展商div
target_divs = soup.find_all("div", class_="col-sm-9 col-md-10 col-lg-11")
exhibitors = []
# 第二步:遍历提取每个展商信息
for div in target_divs:
a_tag = div.find("a", class_="list-group-item-heading")
if a_tag and a_tag.find("h4"):
# 提取公司名称
company_name = a_tag.find("h4").get_text(strip=True)
# 提取相对URL并拼接为绝对URL
company_href = a_tag.get("href", "").strip()
company_href = urljoin(LIST_URL, company_href)
# 提取ID
company_id = extract_id_from_url(company_href)
exhibitors.append({
"company_name": company_name,
"detail_url": company_href,
"id": company_id
})
print(f"成功提取 {len(exhibitors)} 家公司基本信息")
return exhibitors四、系统架构总览
存储层
数据处理层
详情采集层
列表采集层
监控层
进度打印
错误重试
随机延迟
请求列表页
div.col定位器
公司名称提取器
URL提取器
ID提取器
拼接详情URL
请求详情页
input标签提取器
profile区域提取器
数据融合引擎
数据库映射器
DELETE旧数据
INSERT新数据
CSV本地备份
五、技术难点攻克效果
| 技术难点 | 解决方案 | 优化效果 |
|---|---|---|
| ID隐式传参 | 双正则表达式匹配 | ID提取成功率100% |
| 多页面字段分散 | input提取+profile提取 | 字段完整率98% |
| 数据强制覆盖 | DELETE+INSERT策略 | 数据最新率100% |
| 无分页列表解析 | CSS精确定位+URL拼接 | 采集完整率100% |
六、调试与监控技巧
6.1 实时进度打印
python
print(f"[{i}/{len(exhibitors)}] 爬取 {item['company_name']} 的详情...")6.2 CSV本地备份
python
# 即使数据库失败,也有本地备份
pd.DataFrame(all_data).to_csv(SAVE_FILE, index=False, encoding="utf-8-sig")6.3 智能重试与延迟
python
# 网络错误自动重试,最多3次
time.sleep(2 + random.random() * 3) # 随机延迟2-5秒七、经验总结
7.1 攻克心得
- ID提取双保险:面对多种URL格式,准备两套正则表达式
- 字段分散不慌:列表页+详情页+独立区域,逐个击破再融合
- 强制覆盖有底气:业务需要最新数据,DELETE+INSERT最可靠
- 无分页更简单:一次性全量获取,省去翻页烦恼
7.2 技术启示
- 灵活应对URL:不要假设URL只有一种格式
- input标签价值:很多网站用input存储数据,value属性是宝库
- 业务决定策略:增量更新还是强制覆盖,取决于业务需求
- 备份永不嫌多:数据库和本地文件双保险
结语
本文通过巴西展会爬虫项目的实战案例,详细剖析了ID隐式传参、多页面字段分散、数据强制覆盖、无分页列表解析四大技术难关的攻克过程。这些经验对于处理拉美地区网站、嵌入式页面结构、表单类网站具有重要的参考价值。技术的魅力就在于,无论网站采用何种技术架构,总能找到破解之道。