1. 研究背景
在机器学习回归问题中,特征维度过高可能导致模型过拟合、计算开销增大及可解释性下降。特征选择是解决上述问题的关键手段之一。随机森林(RF)能够评估特征重要性,结合递归特征消除(RFE)可以自动筛选出最优特征子集。BP神经网络作为经典的非线性模型,广泛应用于回归预测。将RF-RFE与BP结合,既能发挥RF在特征选择上的优势,又能利用BP的拟合能力,实现高效准确的回归建模。
2. 主要功能
- 读取Excel格式的特征数据集,自动划分训练集(70%)与测试集(30%)。
- 在训练集上执行RF-RFE特征选择,通过OOB误差确定最佳特征数量,并输出选中的特征索引。
- 根据选中的特征对训练集和测试集进行筛选,并对数据进行Z-score归一化。
- 构建并训练单隐含层BP神经网络,对归一化后的数据进行回归拟合。
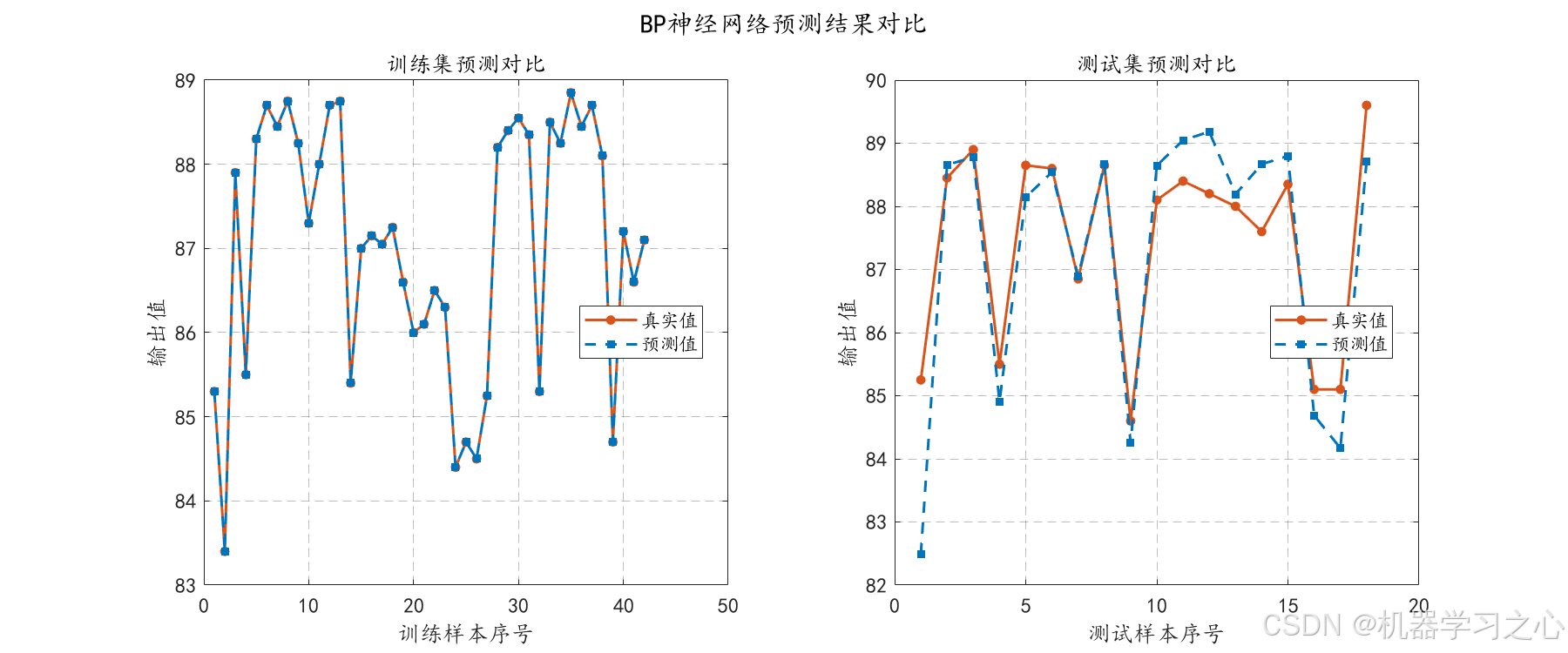
- 对训练集和测试集进行预测,计算RMSE、R²、MAE等评价指标。
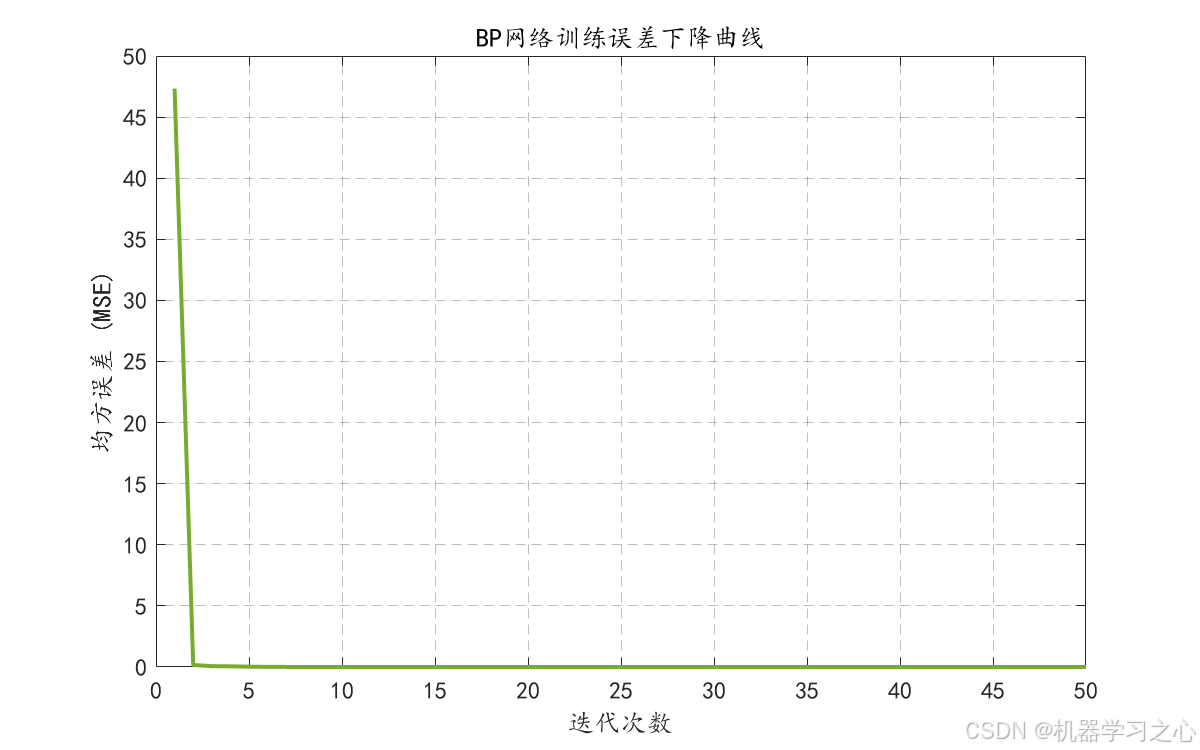
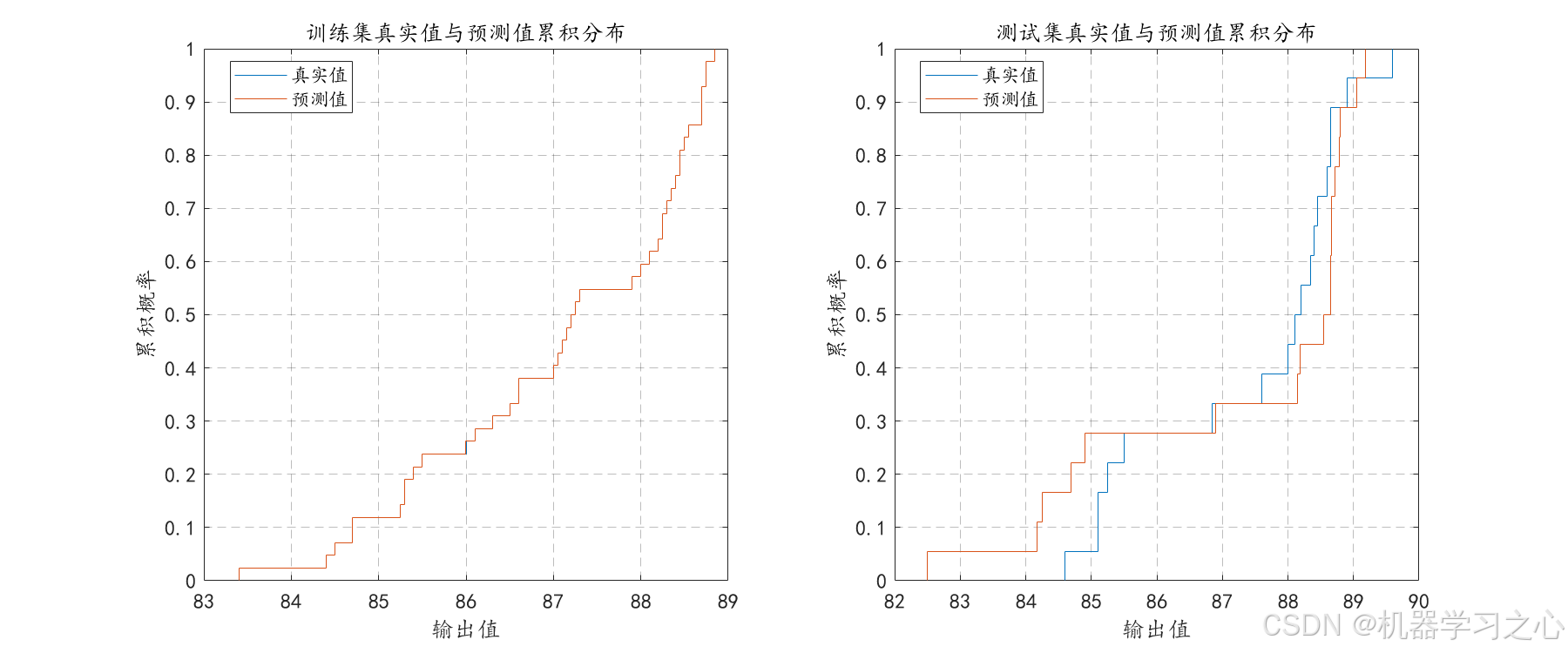
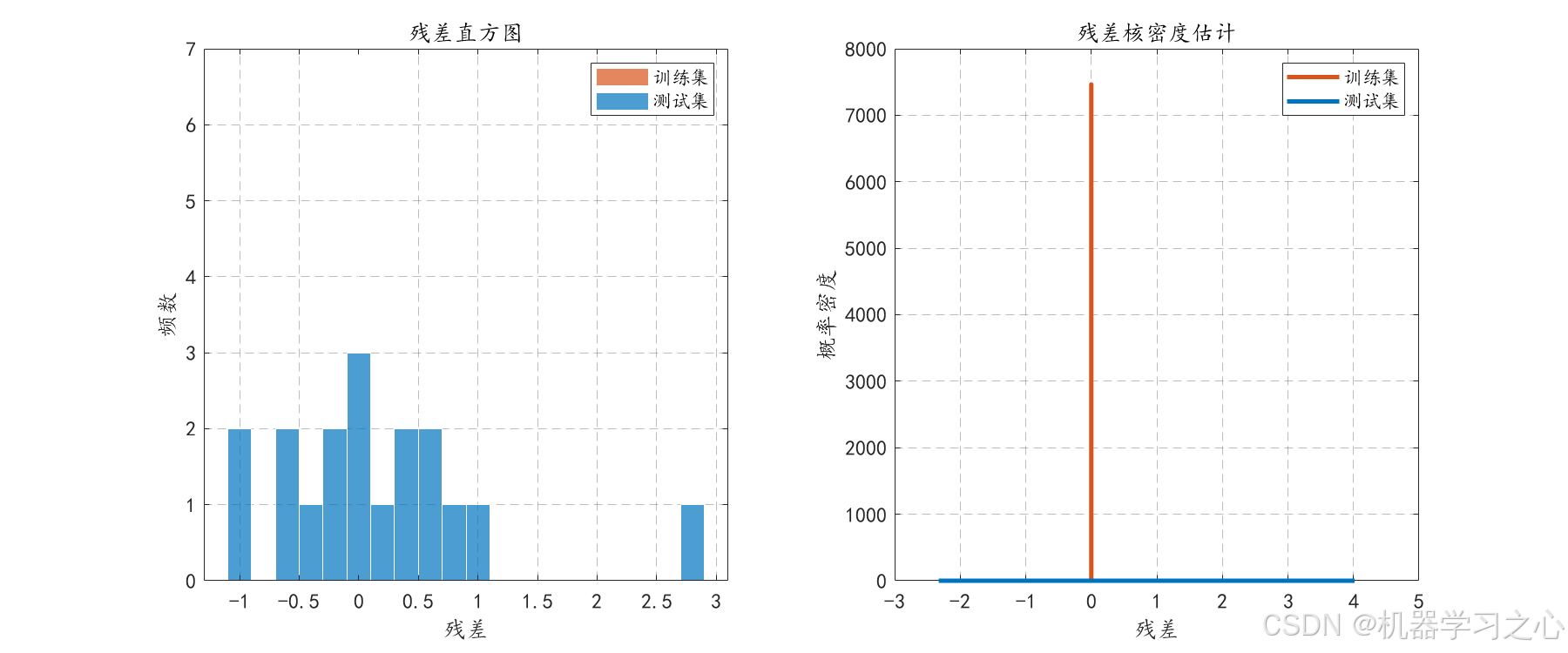
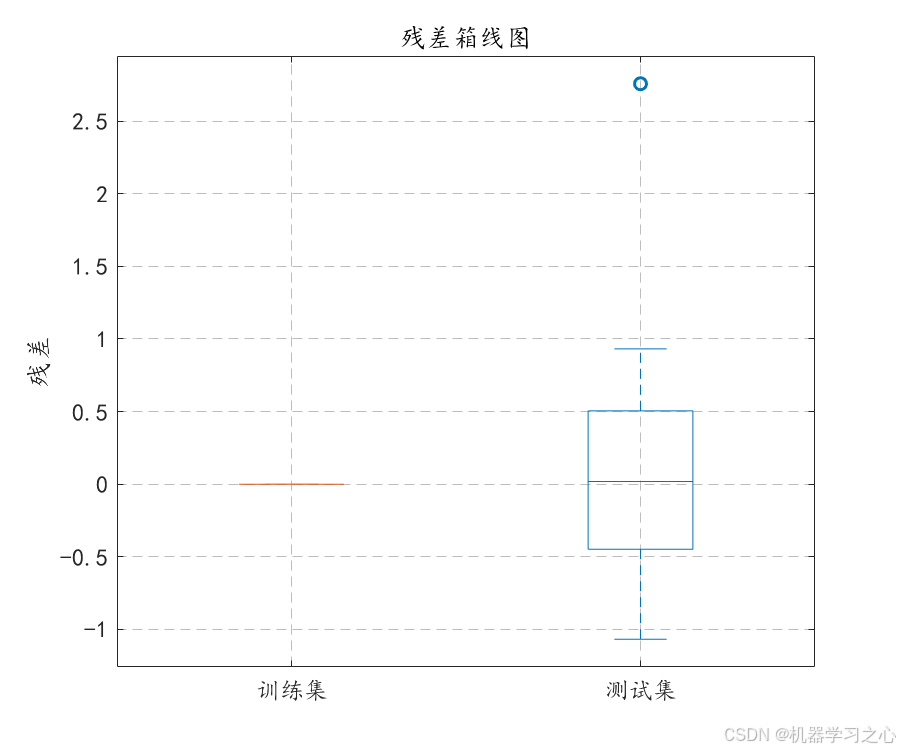
- 生成多种可视化图表(预测对比、散点图、残差分布、Q-Q图、累积分布、训练误差曲线等),全面评估模型性能。
- 保存选中的特征索引至
selected_features.mat,便于后续使用。
3. 算法步骤
-
数据预处理
- 读取Excel文件,提取特征矩阵
X和目标向量y。 - 使用
cvpartition按70%:30%随机划分训练集和测试集,固定随机种子保证可重复性。
- 读取Excel文件,提取特征矩阵
-
RF-RFE特征选择(在训练集上)
- 初始化剩余特征索引为全部特征。
- 循环从全部特征到只剩一个特征,每一步:
- 用当前剩余特征训练随机森林回归模型(100棵树,
MinLeafSize=5)。 - 记录当前模型的袋外(OOB)误差。
- 获取特征重要性(
OOBPermutedVarDeltaError)。 - 剔除重要性最小的特征,更新剩余特征集。
- 用当前剩余特征训练随机森林回归模型(100棵树,
- 找出使OOB误差最小的特征数量
bestNumFeatures。 - 重新执行RFE过程,直至剩余特征数等于
bestNumFeatures,得到最终选中的特征索引。
-
特征筛选与归一化
- 用选中的特征索引筛选训练集和测试集。
- 对训练集特征进行Z-score归一化,保存均值和标准差,并用相同参数归一化测试集特征。
- 对训练集目标值同样进行Z-score归一化,并保存均值和标准差用于反归一化。
-
BP神经网络建模
- 创建
feedforwardnet,隐含层神经元数设为20。 - 设置训练函数为
trainlm(Levenberg-Marquardt),不划分验证集,最大迭代次数500,目标误差1e-6。 - 用归一化后的训练数据训练网络。
- 创建
-
预测与反归一化
- 对训练集和测试集进行预测,将预测结果反归一化还原为原始量纲。
- 计算预测值与真实值之间的RMSE、R²、MAE。
-
结果可视化
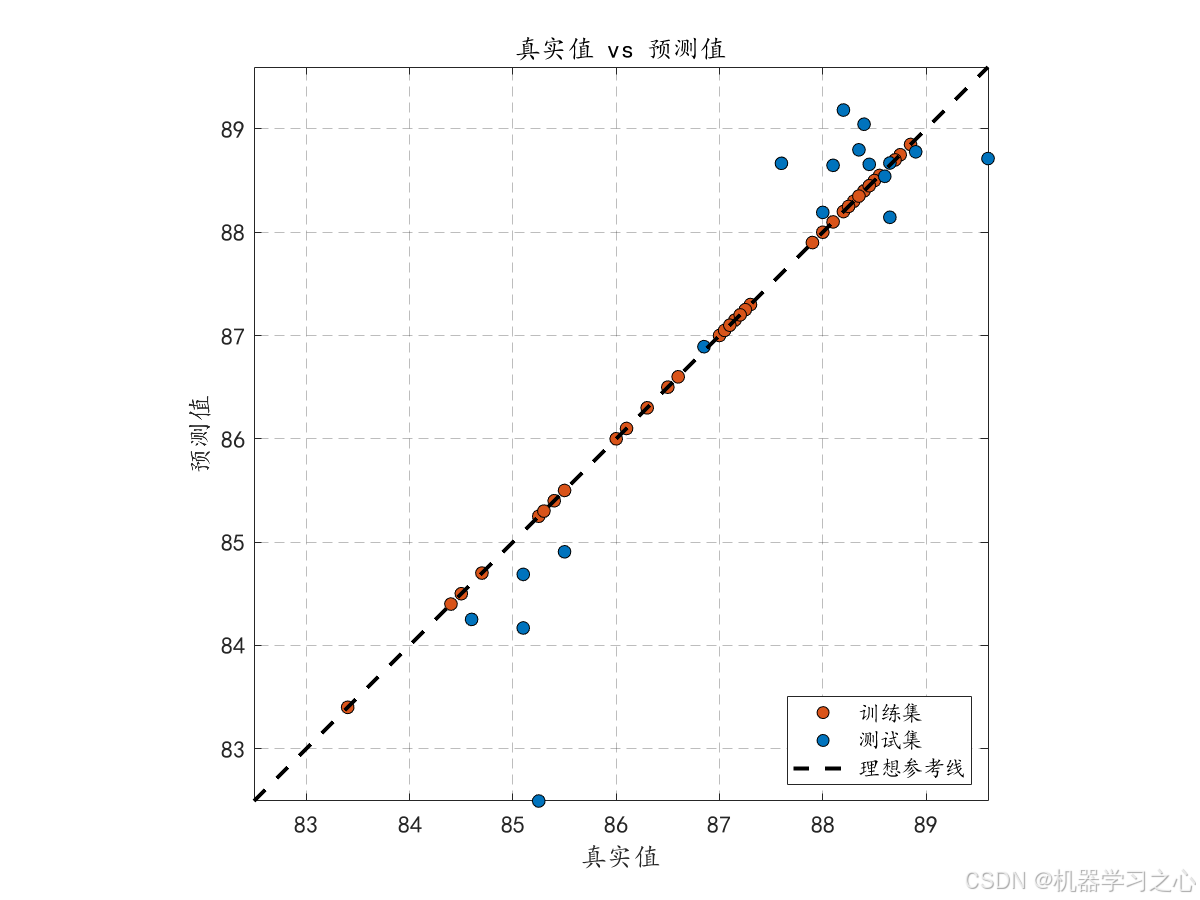
- 绘制训练集/测试集真实值与预测值对比折线图、散点图。
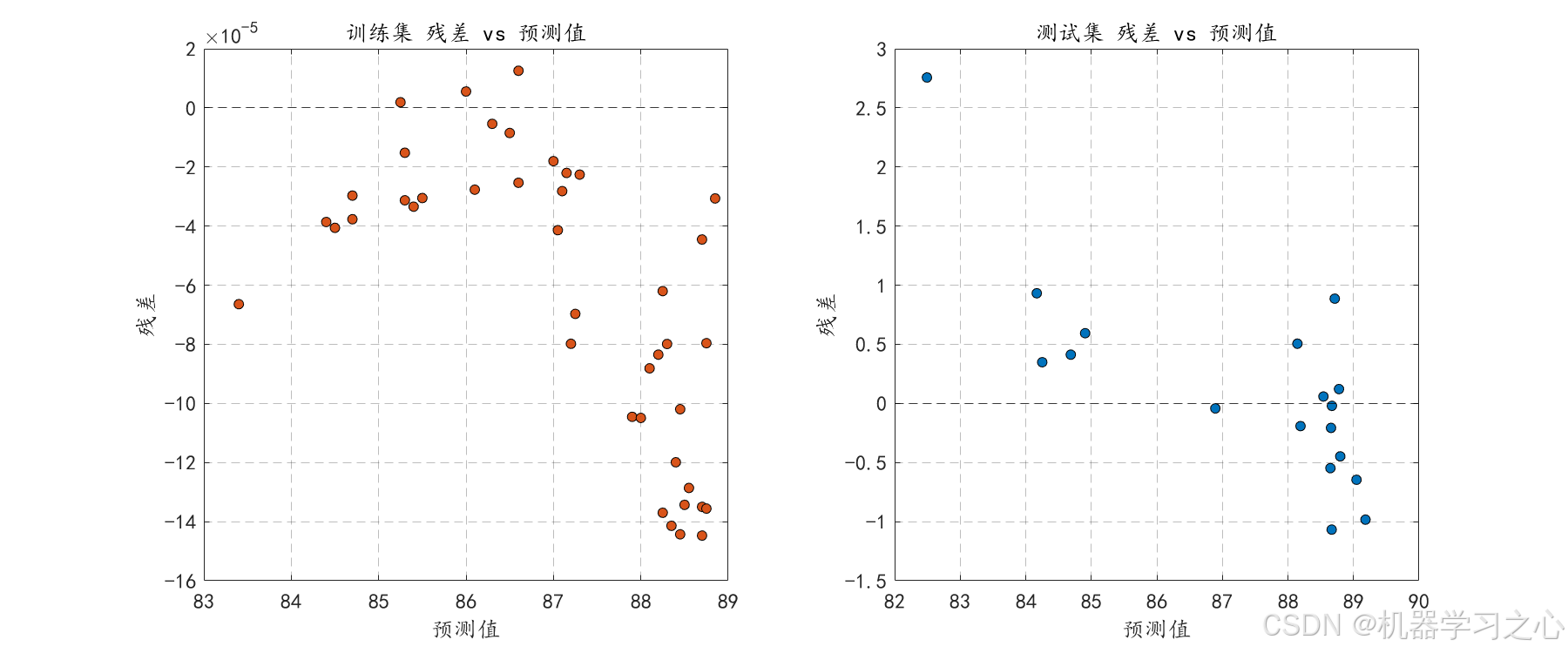
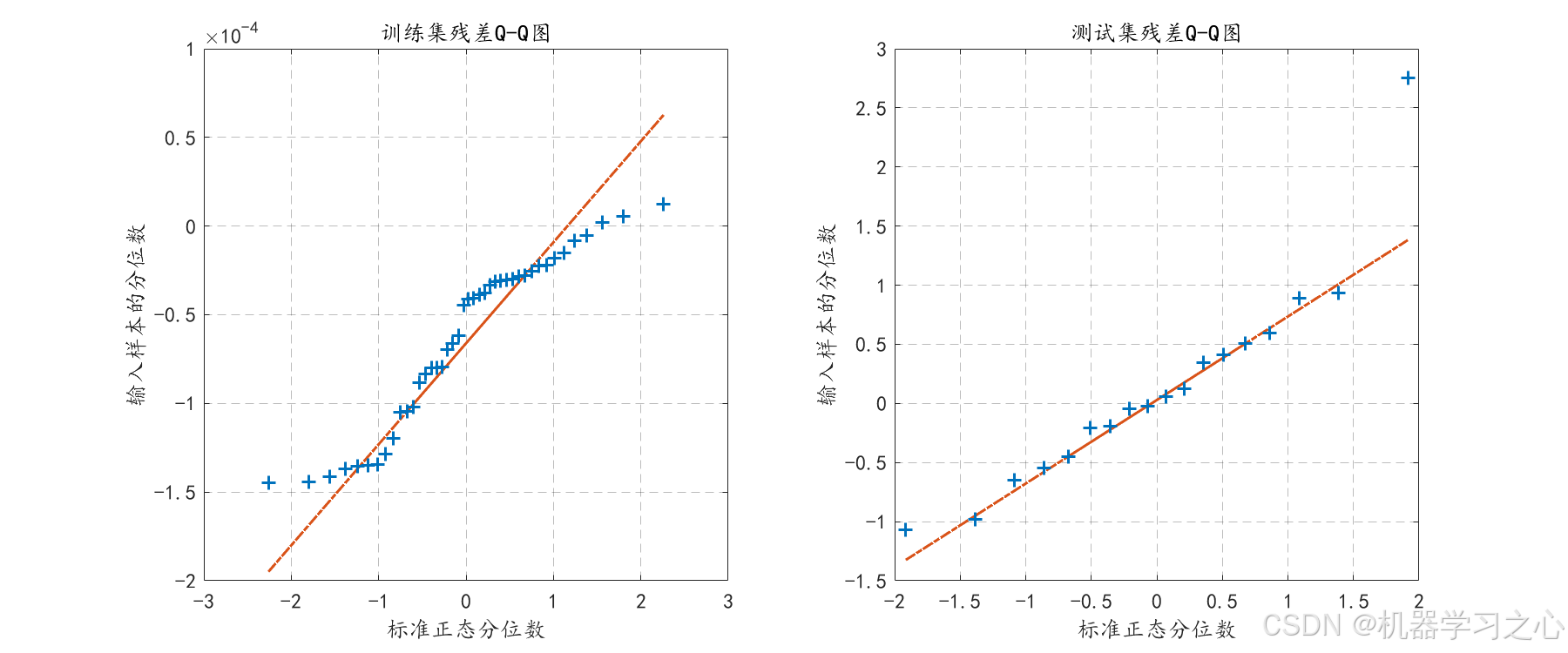
- 绘制残差直方图、核密度估计、箱线图、Q-Q图、残差与预测值散点图。
- 绘制真实值与预测值的累积分布对比图。
- 绘制训练过程中的误差下降曲线。
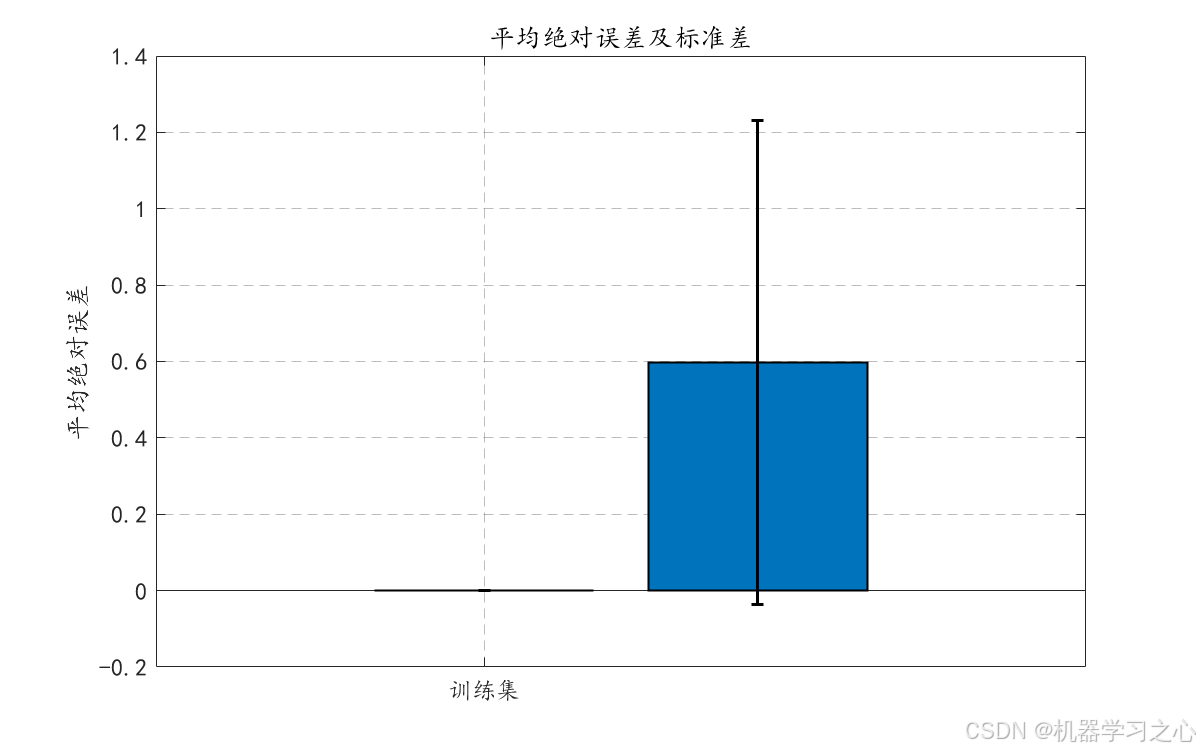
- 绘制平均绝对误差的条形图(含标准差)。
-
保存结果
- 将选中的特征索引保存为MAT文件。
4. 技术路线
RF-RFE特征选择 → 数据归一化 → BP神经网络回归 → 模型评估与可视化
该路线充分利用了随机森林的特征重要性评估能力,通过递归消除冗余特征,降低BP网络的输入维度,同时结合归一化处理消除量纲影响,最后用BP网络进行非线性回归拟合。
5. 公式原理
- 随机森林特征重要性 :通过计算每个特征在OOB样本上随机打乱后模型误差的增加量(
OOBPermutedVarDeltaError)来衡量特征重要性,增加量越大表示特征越重要。 - 递归特征消除(RFE):反复构建模型,每次剔除重要性最低的特征,直至达到预定特征数或满足停止条件。
- BP神经网络
- 前向传播:y^=f2(W2⋅f1(W1⋅x+b1)+b2)\hat{y} = f_2(W_2 \cdot f_1(W_1 \cdot x + b_1) + b_2)y^=f2(W2⋅f1(W1⋅x+b1)+b2)
- 反向传播:通过梯度下降更新权重,最小化损失函数(均方误差MSE)。
- 评价指标
- RMSE:1n∑i=1n(yi−y^i)2\sqrt{\frac{1}{n}\sum_{i=1}^n (y_i - \hat{y}_i)^2}n1∑i=1n(yi−y^i)2
- R²:1−∑(yi−y^i)2∑(yi−yˉ)21 - \frac{\sum (y_i - \hat{y}_i)^2}{\sum (y_i - \bar{y})^2}1−∑(yi−yˉ)2∑(yi−y^i)2
- MAE:1n∑i=1n∣yi−y^i∣\frac{1}{n}\sum_{i=1}^n |y_i - \hat{y}_i|n1∑i=1n∣yi−y^i∣加粗样式
6. 参数设定
| 模块 | 参数名称 | 设定值 |
|---|---|---|
| 数据划分 | 训练集比例 | 0.7 |
| 随机种子 | 42 | |
| RF-RFE | 树的数量 | 100 |
| 最小叶子节点数 | 5 | |
| 特征重要性指标 | OOBPermutedVarDeltaError | |
| BP神经网络 | 隐含层神经元数 | 20 |
| 训练函数 | trainlm (LM算法) | |
| 最大迭代次数 | 500 | |
| 目标误差 | 1e-6 | |
| 验证集划分 | 无(dividetrain) | |
| 归一化 | 方法 | Z-score |
7. 运行环境
- MATLAB版本 :2020
- Statistics and Machine Learning Toolbox(用于
cvpartition、TreeBagger等) - Neural Network Toolbox(用于
feedforwardnet、train等)
- Statistics and Machine Learning Toolbox(用于
- 依赖文件 :
特征选择数据集.xlsx(需位于当前工作目录) - 输出文件 :
selected_features.mat(保存选中的特征索引)
8. 应用场景
该方法适用于各类回归预测问题,特别是当原始特征数量较多且存在冗余时。典型应用包括:
- 金融领域:股票价格预测、信用评分。
- 工业领域:设备剩余寿命预测、产品质量指标预测。
- 能源领域:风力发电功率预测、负荷预测。
- 环境科学:空气质量指数预测、气象要素预测。
- 生物医学:基于基因表达数据的疾病预后预测。
通过特征选择剔除无关或弱相关特征,可有效降低模型复杂度、提高训练效率,并增强模型在新数据上的泛化能力。