写在前面
第一次听说Anthropic的Skills功能时,我和很多同学一样,以为这就是那个"让AI替我写代码"的神器。但当我真正动手实践后才发现,AI工具的真正价值不在于替代思考,而在于放大能力。它让我能把更多精力放在问题分析、方案设计和工程优化上,而不是重复性的体力劳动。

这篇文章记录了我把问题记录分析流程 进行自动化的完整过程。从最初踩的各种坑,到最后找到一个既稳定又省钱的方案,这个过程中我对"什么是好的工程实践"有了更深的理解。谨以此文和大家学习共勉。(文中代码含AI生成,可根据自己的具体需求进行适当调整)
一、问题背景:如何既高效又高质的完成问题记录的分析?
1.1 真实的业务场景
假设某同学在实习期间负责一个B端产品的技术支持工作。每个版本发布后,都需要分析用户反馈的问题记录,找出共性问题,推动产品改进。听起来简单,实际操作起来却相当繁琐:
第一步:登录内网系统
- 需要VPN+双因素认证
- 每次分析都要重新登录
第二步:筛选导出数据
- 按产品、版本、时间范围筛选
- 导出Excel,经常遇到数据量过大需要分批导出
第三步:人工分析整理
- 阅读问题记录内容,分类统计
- 找出高频问题,分析根因
- 整理成报告发给团队
整个过程需要30-60分钟,而且每周都要重复一遍。
1.2 更深层的痛点
并且随着和不同角色的同事交流,能发现这个问题远比表面复杂:
| 角色 | 关注重点 | 现有方案的痛点 |
|---|---|---|
| 研发同学 | 具体的技术问题、异常堆栈 | 需要从大量问题记录中筛选出技术相关的问题 |
| 产品经理 | 共性问题、产品化机会 | 缺乏系统性的问题聚类分析 |
| 技术负责人 | 跨产品对比、趋势分析 | 手动整理跨产品数据太耗时 |
| 核心矛盾 | 同一份数据,不同人需要看不同的"切面" | 传统的固定报表无法满足这种灵活需求。 |
1.3 我的初步想法
既然AI擅长数据分析和文本处理,能不能让它帮我完成这个流程?理想情况下:
- 自动获取问题记录数据
- 智能分类和统计
- 生成针对不同角色的分析报告
但从现实来看,这个方法行不通 :数据在企业内网,AI不能进去。
二、技术探索:踩过的坑与学到的经验
2.1 方案一:让AI"操作浏览器"(Playwright MCP)
我首先想到的是用 Playwright MCP,让 AI 通过 accessibility tree 理解页面结构,自主决策点击、填写、导出等操作。
Playwright MCP(Model Context Protocol) 是微软推出的一个革命性工具,它让大语言模型能够直接"看懂"网页并生成自动化测试脚本。不同于传统的截图识别方式,MCP使用可访问性树来理解页面结构。
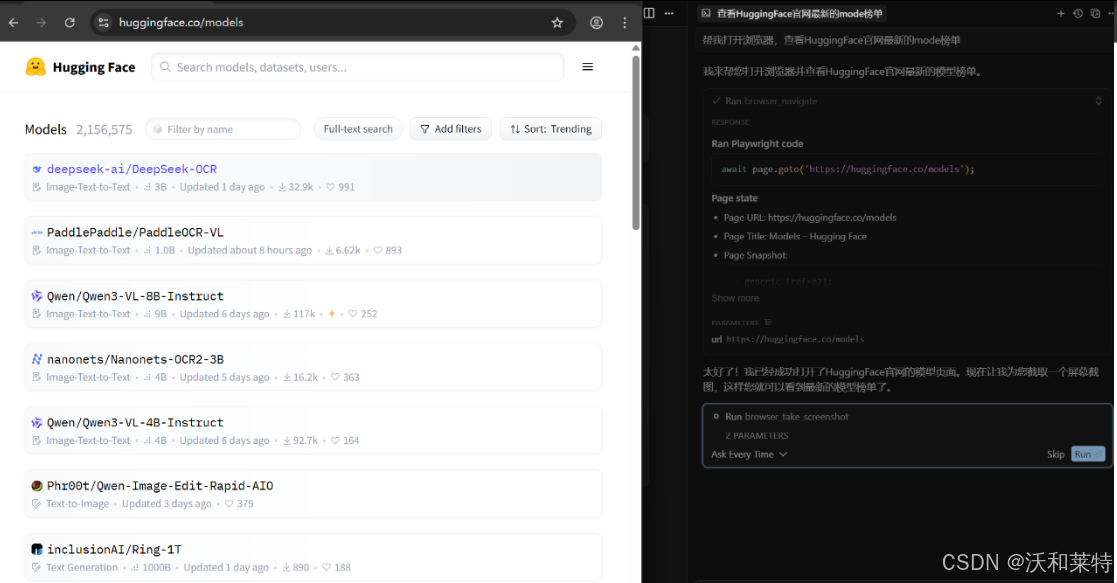
完成相应的配置(Claude Desktop、VS Code、Cursor 等),如果想在代码中使用 MCP Client 连接 Playwright MCP Server,大致的代码结构为:
javascript
import { Client } from '@modelcontextprotocol/sdk/client/index.js';
import { StdioClientTransport } from '@modelcontextprotocol/sdk/client/stdio.js';
// 1. 启动 Playwright MCP Server(stdio 模式)
const transport = new StdioClientTransport({
command: 'npx',
args: ['-y', '@playwright/mcp@latest'],
});
const client = new Client({ name: 'demo', version: '0.1' }, { capabilities: {} });
await client.connect(transport);
// 2. 通过 MCP 协议让 AI 执行浏览器操作
await client.callTool({
name: 'browser_navigate',
arguments: { url: 'https://inner.company.com/workorders' }
});
// 3. 获取 accessibility tree 快照
const snapshot = await client.callTool({
name: 'browser_snapshot'
});
// 4. AI 分析 snapshot 后,决定点击哪个元素
await client.callTool({
name: 'browser_click',
arguments: { element: '导出按钮', ref: 'e12' } // 基于 accessibility tree 的引用
});该方案遇到的问题:
问题1:Token消耗爆炸
Playwright MCP 每一步都要把 accessibility tree(页面的语义化结构树,而非完整 HTML)发给 AI 分析。对于一个中等复杂度的页面,accessibility tree 仍可能有 50KB-100KB,转换成 token 就是几万。我实测了一个15步的登录+导出流程,消耗了 22 万 token。这个成本对于个人学习和小团队来说,根本承受不起。
问题2:稳定性仍存挑战
虽然 MCP 用 accessibility tree 摆脱了对 CSS selector 的依赖,但现代 Web 应用的动态特性依然带来问题:下拉菜单的异步加载导致 AI 误判"元素不存在"; 前端改动按钮文案(如"导出"改"下载"),AI 基于语义的理解就会失效。
问题3:调试困难
当脚本失败时,很难定位问题:是 accessibility tree 解析不完整?还是 AI 对页面语义理解错误?还是网络延迟导致状态不同步?需要比对 tree 快照和页面实际状态来排查。
问题4:数据提取局限
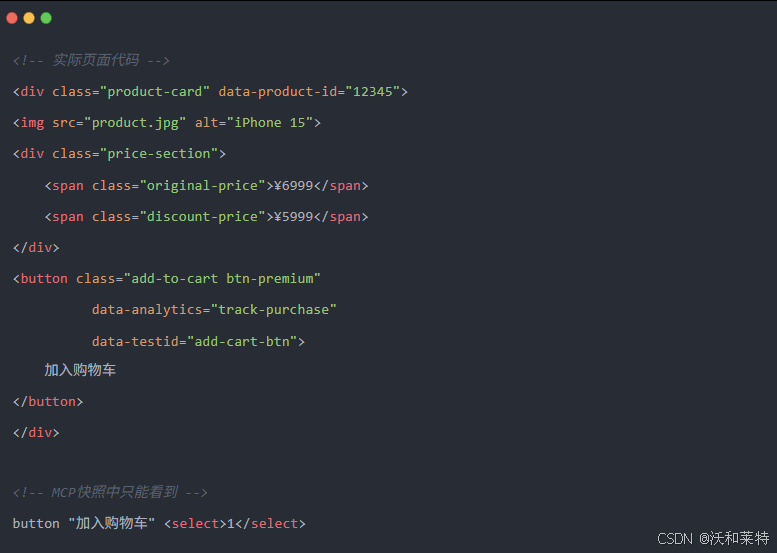
accessibility tree 只包含交互元素的文本标签,不包含 DOM 中的结构化数据(价格、ID、class、data属性)从而丢失了大量DOM细节。比如:如果业务需要提取"折扣价¥5999"或"product-id=12345",MCP 无法直接提供,需要额外编写代码注入页面抓取,这增加了复杂度。
2.2 方案二:更智能的浏览器工具(Agent Browser)
后来我发现 Vercel Labs 推出的 agent-browser ,它针对 AI 操作浏览器做了专门优化:
核心创新:refs 机制
传统方式需要告诉 AI"去找 class 包含 submit 的按钮",agent-browser 会给每个可交互元素打上唯一标签(如 @e1、@e2),AI 直接说"点击 @e2"就行。
bash
agent-browser 的工作流程
agent-browser open https://example.com
agent-browser snapshot -i
# 输出: @e1 button "Submit", @e2 input "Email"
agent-browser click @e1
agent-browser fill @e2 "user@example.com"优势:
Token 消耗降低 90%+:只返回可交互元素的精简快照;
稳定性提升:基于语义化引用(refs),不受 CSS class 变动影响;但仍需重新 snapshot 应对动态内容变化;
Rust 编写 + Node.js Daemon:CLI 层用 Rust 实现高性能,底层仍基于 Playwright 控制浏览器;
实测数据对比:
| 操作 | Playwright MCP | Agent Browser | 效率提升 |
|---|---|---|---|
| 页面快照 | 8,000-50,000 tokens | 500-800 tokens | 90-95% |
| 点击操作 | 8,000-12,000 tokens | 200-300 tokens | 95%+ |
| 表单填写 | 8,000-10,000 tokens | 300-500 tokens | 90%+ |
注:Playwright MCP 消耗取决于 accessibility tree 的完整度;Agent Browser 消耗取决于可交互元素数量。复杂页面(如大型数据表格)可能偏离上述区间。
但核心问题依然存在
即使是agent-browser,只要是"让AI去操作页面",行为就一定存在不确定性。AI需要理解页面结构、决策操作路径、处理异常情况,每一步都可能出错。
尝试了以上两种方案,能够得到的结论是:
适合优先上 Playwright MCP 的场景:需要长期保留登录态;要在真实网站里深度浏览要搜索、点详情、看评论、看图;更重视稳定性和可预期性;不希望折腾 profile 和会话管理;希望独立窗口运行,不影响自己正在用的 浏览器。
适合优先试 agent-browser 的场景:操作多、阅读少;页面是后台系统或工具型 Web App;需要更真实的键盘、hover、drag 交互;希望工具返回更轻,尽量省 token;更习惯 CLI / shell 风格的 agent 工作流;愿意自己把 session、profile 这些细节配置好。
2.3 方案三:退回到"固定脚本"(传统自动化)
既然使用AI工具没有那么大的优势,那如果放弃AI操作,用固定的Playwright脚本呢?
javascript
// 固定selector的脚本
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('http://example.com');
// 高度依赖DOM结构的选择器
await page.locator('.data-table > tbody > tr:nth-child(2) > td:nth-child(3) > .action-btn').click();
// UI微调后,这个选择器可能就失效了
await browser.close();优点:确定性强,执行速度快
缺点:
- 编写成本高,需要深入理解页面DOM
- 维护成本极高,前端迭代频繁
- 健壮性差,对异常处理支持有限
2.4 关键观察:SPA架构下的接口复现
在反复尝试中,我注意到一个现象:
现代Web应用(SPA)的数据,本质上都来自接口请求。页面只是"渲染层",数据在"接口层"。
SPA架构(单页面应用)是一种仅加载一个核心HTML文件的Web应用设计,通过JavaScript动态更新页面内容,无需整页刷新。其核心优势在于流畅的交互体验和高效资源利用,广泛应用于后台系统和移动端应用。
与传统多页面应用(MPA)相比,SPA首次加载资源较多但后续交互更快,适配性强但对SEO优化要求更高。现代前端框架如Vue、React等均以SPA为核心,通过前端路由和异步数据请求实现视图更新。
既然页面能正常渲染并展示了最新的业务数据,说明对应的接口在当前登录态下是可用的,且返回了符合预期的数据结构.
比如可以做个实验:
实验网站:https://jsonplaceholder.typicode.com/
JSONPlaceholder 是一个提在线 REST API 的网站,我们在开发时可以使用它获取一些假数据、假图片。其返回的数据为 JSON 格式,且同时支持 HTTP 和 HTTPS 这两种请求类型。
以 JSONPlaceholder 提供的 /posts/1 接口为例,这是典型的 RESTful API 端点,模拟了真实业务系统中'根据 ID 查询文章'的数据请求。
- 在 Edge DevTools 的 Network 面板中,对问题记录列表接口执行
Copy as fetch - 将代码粘贴到Console中执行
- 成功获取到 JSON 格式的问题记录数据
具体操作如下:
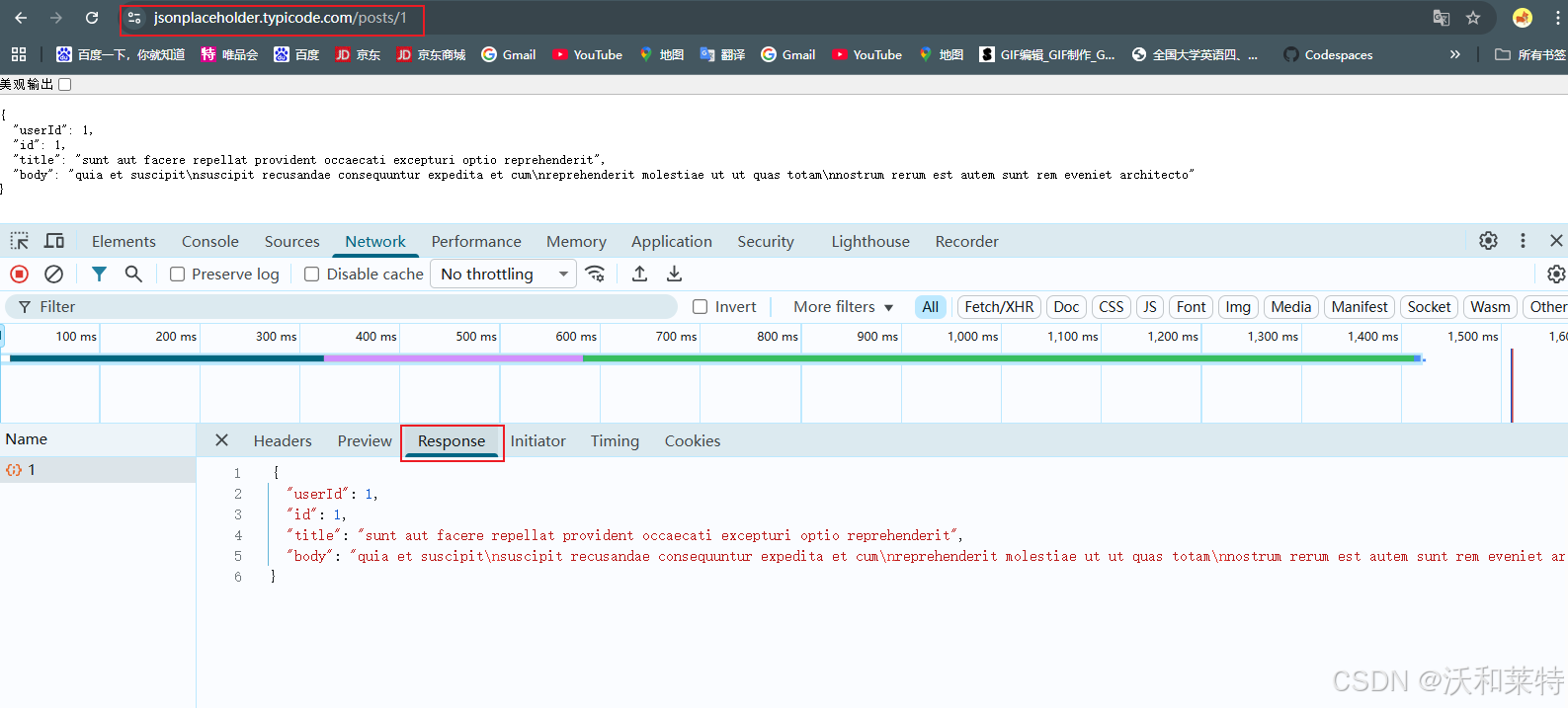
右击后选择copy as fetch
通过 DevTools 的'Copy as fetch'功能,可将浏览器已验证成功的请求(含完整 Headers、Cookie 等上下文)一键转换为 JavaScript 代码。这意味着我们无需手动拼接请求参数,直接复用浏览器当前的登录态和请求配置。
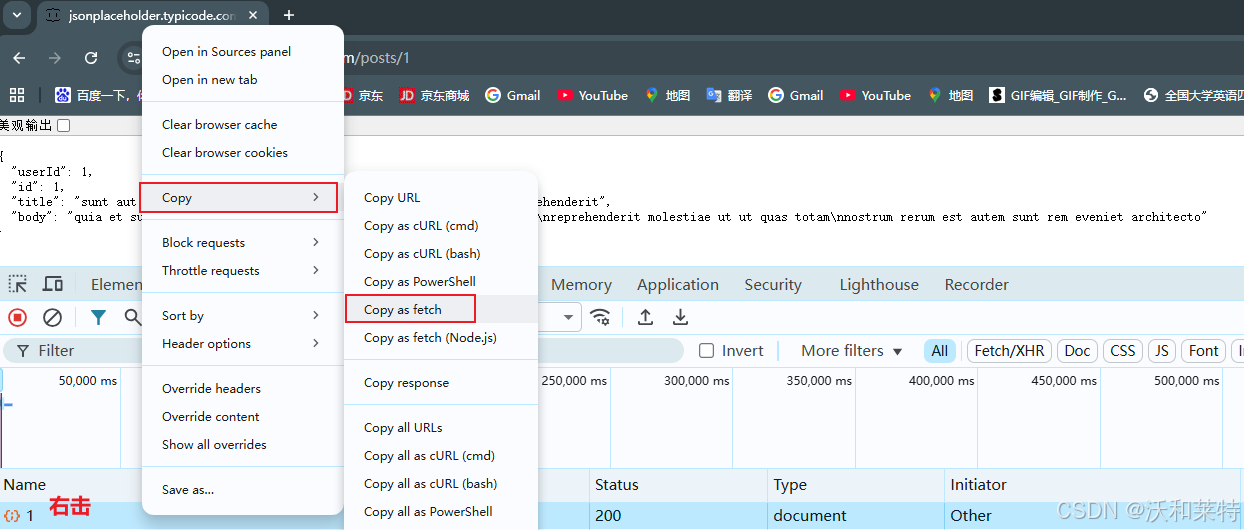
然后将复制的信息粘贴在控制台,然后回车
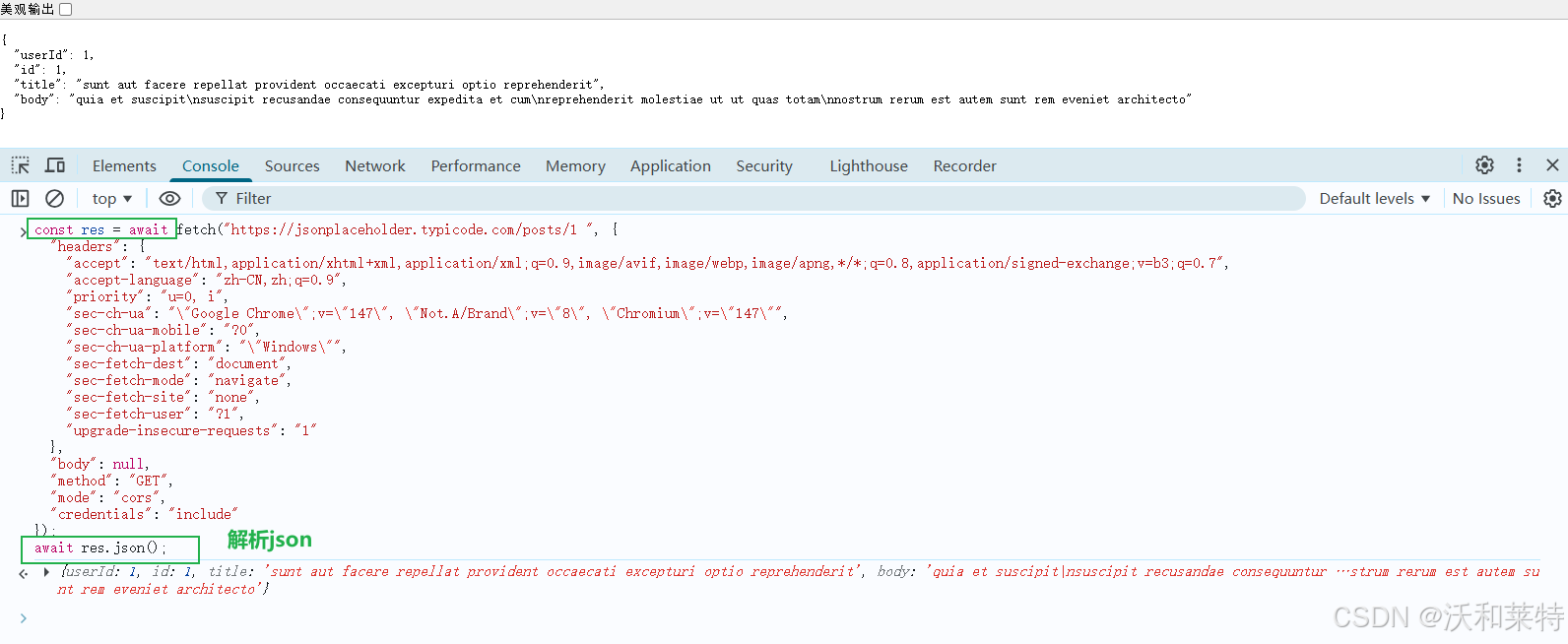
然后点击nextwork功能项,可以看到返回的304状态码信息
首次请求返回 200(OK)并缓存数据,再次执行时服务器返回 304(Not Modified),这是 HTTP 缓存优化机制。无论 200 还是 304,均表明成功获取到结构化的 JSON 数据,验证了接口的可用性。
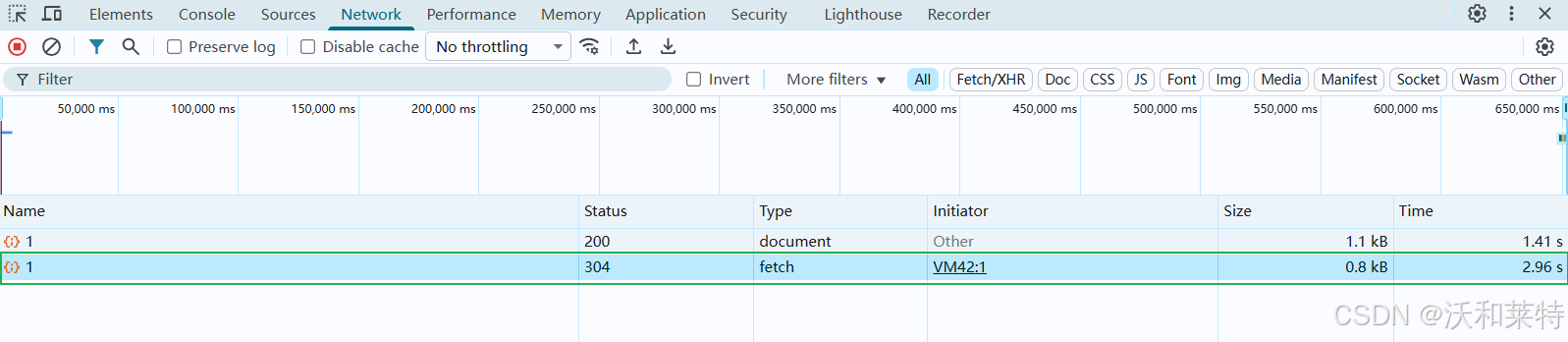
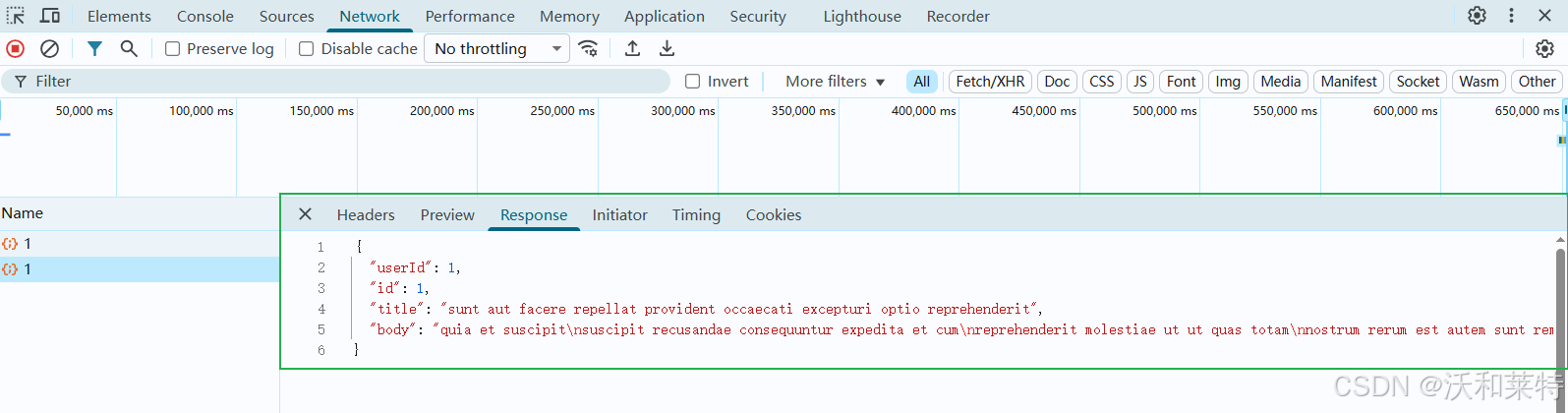
或者是在打开该网站后,直接在开发者模式下的控制台中输入
javascript
// 返回 JSON 的测试接口
const res = await fetch("https://jsonplaceholder.typicode.com/posts/1");
// 查看状态
console.log("状态码:", res.status); // 应该是 200
// 解析 JSON 数据
const data = await res.json();
console.log(data);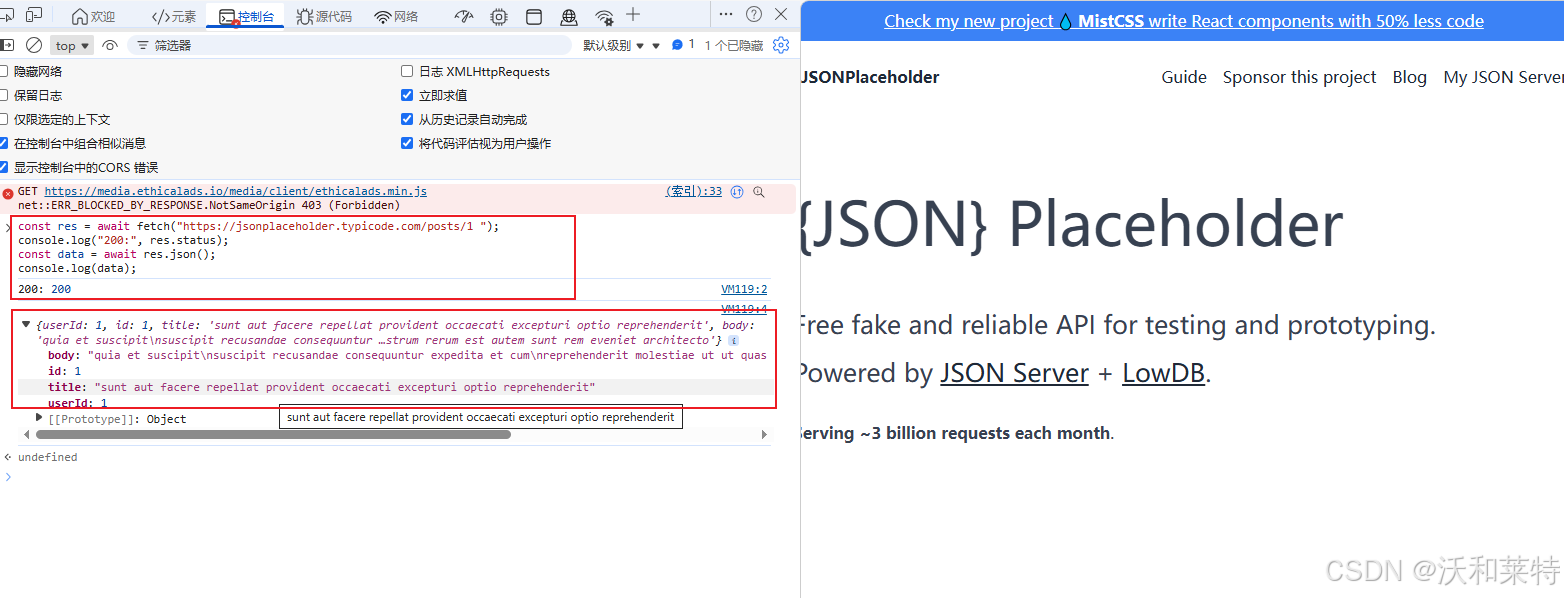
有兴趣的话还可以尝试以下代码:
javascript
// DevTools生成的fetch代码(headers已脱敏,实际包含完整认证信息)
fetch("https://inner.company.com/api/workorders/list", {
"headers": {
"accept": "application/json",
"content-type": "application/json"
// 实际还包含:authorization/x-requested-with/user-agent 等
},
"body": JSON.stringify({
"page": 1,
"pageSize": 50,
"product": "API Gateway"
}),
"method": "POST",
"credentials": "include" // 自动携带当前登录态的cookie
});从这个实验可知:当页面能正常展示数据时,说明对应的接口在当前登录态下已被验证可用。只要浏览器能拿到数据,外部代码也能通过相同接口拿到,且数据格式是结构化的(JSON)而非视觉化的(DOM)
这个实验给了我重要启发 :与其让AI操作UI,不如让AI执行已经验证过的接口请求。
三、最终方案:Copy as fetch + Playwright CDP + Skill封装
我想到了最近很火爆的Skills,也许可以结合'Copy as fetch'获取数据与Playwright CDP控制浏览器,再通过Skill封装将代码封装成标准化执行流程。
Skills(技能文件) 是一种结构化的上下文文档,通常以 Markdown 格式编写,放置在项目仓库的特定目录中,专门用来告诉 AI 编程智能体:"在这个项目里,我们是这样工作的。" 想了解Skills的更多细节,可以参考这篇文章:一文搞懂爆火的SKills原理及实践案例
Skills的Skill 框架规范:

3.1 方案设计
结合前面的探索,可以设计了一个"分层"的解决方案:
核心思想:
- 人做的:首次登录系统(处理 MFA、扫码等复杂认证)、验证最终数据准确性、处理异常边界情况
- 工具做的:利用 Playwright CDP 连接已登录浏览器,复用 Cookie 会话执行标准化的数据获取脚本(稳定、低成本、可复现)
- AI做的:基于获取的结构化 JSON 数据进行模式识别、根因分析、生成改进建议报告(发挥 LLM 的推理与生成优势)
关键技术路径:Copy as fetch(复用浏览器已验证的请求模式)→ Playwright CDP(在保持登录态的页面上下文中执行)→ Skill 封装(标准化执行流程)
3.2 关键技术实现
3.2.1 浏览器端数据获取脚本(Copy as fetch 的代码化复现)
核心逻辑:将 DevTools 中 "Copy as fetch" 得到的请求模式,封装为可在浏览器环境中运行的脚本。通过 credentials: 'include' 自动携带当前登录态 Cookie,无需处理复杂的认证逻辑。
javascript
// scripts/fetch-workorders.js
// 在已登录浏览器的页面上下文中执行(通过 Playwright CDP 注入)
const CONFIG = {
API_BASE: '/api/v1/workorders',
PAGE_SIZE: 100,
MAX_PAGES: 10, // 安全限制,防止无限循环
RETRY_TIMES: 3,
RETRY_DELAY: 1000
};
/**
* 带重试机制的 fetch 封装
* 网络抖动时自动重试,提高稳定性
*/
async function fetchWithRetry(url, options, retryCount = 0) {
try {
const response = await fetch(url, options);
if (!response.ok) {
throw new Error(`HTTP ${response.status}: ${response.statusText}`);
}
return response;
} catch (error) {
if (retryCount < CONFIG.RETRY_TIMES) {
console.log(`请求失败,${CONFIG.RETRY_DELAY}ms后重试(${retryCount + 1}/${CONFIG.RETRY_TIMES})...`);
await new Promise(resolve => setTimeout(resolve, CONFIG.RETRY_DELAY));
return fetchWithRetry(url, options, retryCount + 1);
}
throw error;
}
}
/**
* 获取问题记录数据(分页)
* 完全复用浏览器当前的 Cookie 和 Headers,无需额外认证
*/
async function fetchWorkorders(params = {}) {
const allData = [];
let page = 1;
let hasMore = true;
console.log('开始获取问题记录数据,参数:', params);
while (hasMore && page <= CONFIG.MAX_PAGES) {
console.log(`正在获取第 ${page} 页数据...`);
// 核心:复用浏览器原生的 fetch,自动携带 Cookie
const response = await fetchWithRetry(
`${CONFIG.API_BASE}/search`,
{
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Requested-With': 'XMLHttpRequest'
// 注意:无需手动设置 Cookie,浏览器自动处理
},
credentials: 'include', // 关键:确保发送当前域的 Cookie
body: JSON.stringify({
page,
pageSize: CONFIG.PAGE_SIZE,
product: params.product,
startDate: params.startDate,
endDate: params.endDate,
status: params.status || ['open', 'processing', 'resolved']
})
}
);
const result = await response.json();
if (!result.data || !Array.isArray(result.data.list)) {
throw new Error('接口返回数据格式不符合预期');
}
allData.push(...result.data.list);
hasMore = result.data.list.length === CONFIG.PAGE_SIZE;
console.log(`第 ${page} 页获取完成,本页 ${result.data.list.length} 条`);
page++;
// 防请求过快,避免触发限流
if (hasMore) {
await new Promise(resolve => setTimeout(resolve, 500));
}
}
const finalResult = {
total: allData.length,
data: allData,
meta: {
product: params.product,
dateRange: [params.startDate, params.endDate],
fetchedAt: new Date().toISOString(),
pagesFetched: page - 1
}
};
// 关键:将结果挂载到全局,供外部(Playwright)读取
window.__WORKORDER_RESULT__ = finalResult;
console.log(` 数据获取完成,总计 ${allData.length} 条`);
return finalResult;
}
// 执行入口:支持通过 URL 参数或全局变量注入配置
const params = window.__SKILL_PARAMS__ || {
product: new URLSearchParams(location.search).get('product'),
startDate: new URLSearchParams(location.search).get('start'),
endDate: new URLSearchParams(location.search).get('end')
};
fetchWorkorders(params).catch(err => {
console.error('数据获取失败:', err.message);
window.__WORKORDER_ERROR__ = err.message;
throw err;
});3.2.2 Playwright CDP 执行器(连接已登录浏览器)
Playwright 的 connectOverCDP() 可以连接到以 Debug 模式运行的 Chrome 实例,复用其所有页面上下文(包括登录态)。这相当于用代码实现了 "Copy as fetch" 后手动在 Console 粘贴执行的过程,但实现了自动化和结果捕获。
javascript
// scripts/cdp-runner.js
// 功能:连接已登录的 Chrome,在页面中执行 fetch-workorders.js,捕获 JSON 结果
const { chromium } = require('playwright');
const fs = require('fs');
const path = require('path');
async function runWithCDP(cdpPort, scriptPath, outputPath, params = {}) {
console.log(`连接到 Chrome CDP (端口 ${cdpPort})...`);
let browser;
try {
// 连接到已运行的 Chrome(用户需提前启动并登录)
browser = await chromium.connectOverCDP(`http://localhost:${cdpPort}`);
// 获取默认上下文(Default Context),包含用户的手动登录态
const context = browser.contexts()[0];
if (!context) {
throw new Error('未找到浏览器上下文,请确保 Chrome 已正常启动');
}
// 使用当前已打开的页面(避免新建页面丢失 Cookie)
const pages = context.pages();
const page = pages.find(p => p.url().includes('inner.company.com')) || pages[0];
console.log(`当前页面: ${page.url()}`);
// 注入参数到页面全局变量
await page.evaluate((p) => {
window.__SKILL_PARAMS__ = p;
}, params);
// 读取并执行数据获取脚本(等效于在 DevTools Console 中粘贴执行)
const scriptContent = fs.readFileSync(scriptPath, 'utf-8');
console.log(` 执行脚本: ${path.basename(scriptPath)}...`);
await page.evaluate(scriptContent);
// 等待异步操作完成(脚本会将结果写入 window.__WORKORDER_RESULT__)
await page.waitForFunction(() =>
window.__WORKORDER_RESULT__ !== undefined || window.__WORKORDER_ERROR__ !== undefined,
{ timeout: 120000 } // 2分钟超时,应对大数据量
);
// 提取结果
const result = await page.evaluate(() => window.__WORKORDER_RESULT__);
const error = await page.evaluate(() => window.__WORKORDER_ERROR__);
if (error) {
throw new Error(`脚本执行错误: ${error}`);
}
// 写入文件供后续 AI 分析
fs.mkdirSync(path.dirname(outputPath), { recursive: true });
fs.writeFileSync(outputPath, JSON.stringify(result, null, 2));
console.log(`结果已保存: ${outputPath}`);
console.log(` 共获取 ${result.total} 条记录,${result.meta.pagesFetched} 页`);
return result;
} catch (err) {
console.error('执行失败:', err.message);
throw err;
} finally {
// 重要:保持浏览器运行(不关闭 Chrome),只断开连接
if (browser) await browser.close({ runBeforeUnload: false });
}
}
// CLI 入口
const [,, cdpPort = '9222', scriptPath = './scripts/fetch-workorders.js',
outputPath = `./.output/workorders-${Date.now()}.json`, paramsJson = '{}'] = process.argv;
const params = JSON.parse(paramsJson);
runWithCDP(cdpPort, scriptPath, outputPath, params)
.then(() => process.exit(0))
.catch(() => process.exit(1));3.2.3 Skill 配置文件(标准化执行流程)
yaml
# SKILL.md
name: workorder-analyzer
description: 基于 Copy as fetch + Playwright CDP 的问题记录分析工具。复用已登录浏览器会话,直接调用内网 API 获取数据,规避 AI 操作 UI 的高成本和不稳定性。
version: 1.0.0
author: "你的名字"
## 前置依赖检查
environment:
node: ">=16.0.0"
dependencies:
- playwright: "^1.40.0"
## 执行流程
### 步骤1:启动并登录(人工操作,一次性)
# 终端1:启动 Chrome Debug 模式(保持运行)
macOS:
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome \
--remote-debugging-port=9222 \
--user-data-dir="$HOME/chrome-debug-profile" \
--no-first-run
Windows:
"C:\Program Files\Google\Chrome\Application\chrome.exe" ^
--remote-debugging-port=9222 ^
--user-data-dir="%TEMP%\chrome-debug-profile"
# 在启动的 Chrome 中手动登录问题记录系统(只需做一次,Cookie 会保留)
### 步骤2:执行数据获取(工具自动化)
# 使用 Playwright CDP 连接已登录浏览器,执行数据获取脚本
# 等效于:手动 Copy as fetch → 粘贴到 Console → 执行 → 复制结果
# 但实现了完全自动化
node scripts/cdp-runner.js 9222 \
scripts/fetch-workorders.js \
.output/workorders-$(date +%Y%m%d-%H%M%S).json \
'{"product":"API Gateway","startDate":"2024-01-01","endDate":"2024-03-31"}'
# 验证数据
if [ ! -s .output/workorders-*.json ]; then
echo "数据获取失败,请检查:1) Chrome是否已登录 2) 网络连接 3) 接口权限"
exit 1
fi
echo "数据获取成功"
### 步骤3:AI 分析(自动化)
# 读取获取的 JSON 数据,进行 AI 分析
# 这里可以接入 Claude / GPT-4 等,通过 MCP 或 API 调用
cat .output/workorders-*.json | your-ai-cli analyze \
--template "分析高频问题,提出产品改进建议" \
--output .output/analysis-report.md
## 数据获取脚本说明
scripts:
fetch-workorders.js:
desc: "在浏览器上下文执行的脚本,复用 Cookie 调用 /api/v1/workorders/search"
params:
product: "产品名称(如 API Gateway)"
startDate: "开始日期(YYYY-MM-DD)"
endDate: "结束日期(YYYY-MM-DD)"
status: "问题状态数组(默认 open, processing, resolved)"
## 输出规范
output:
format: "JSON + Markdown"
files:
- "workorders-{timestamp}.json": "原始数据(数组格式)"
- "analysis-report.md": "AI 分析报告(包含统计图表、根因分析、改进建议)"3.2.4 环境检查脚本(辅助工具)
bash
#!/bin/bash
# scripts/check-env.sh
# 检查执行环境是否满足要求
echo "=================="
echo "环境检查"
echo "=================="
# 检查 Chrome CDP
if lsof -Pi :9222 -sTCP:LISTEN -t >/dev/null 2>&1; then
echo " Chrome CDP 正在端口 9222 运行"
# 尝试获取版本
curl -s http://localhost:9222/json/version 2>/dev/null | grep '"Browser"' || true
else
echo "Chrome CDP 未运行"
echo " 请先执行启动命令(见 SKILL.md 步骤1)"
exit 1
fi
# 检查 Node.js 版本
NODE_VERSION=$(node --version 2>/dev/null || echo "none")
if [[ "$NODE_VERSION" != "v16"* && "$NODE_VERSION" < "v18" ]]; then
echo "Node.js 版本 $NODE_VERSION 可能过低,建议 v16+"
else
echo "Node.js 版本: $NODE_VERSION"
fi
# 检查 Playwright
if npm list playwright >/dev/null 2>&1; then
echo " Playwright 已安装"
else
echo " Playwright 未安装"
echo " 执行: npm install playwright"
exit 1
fi
# 检查脚本文件
if [ -f "scripts/fetch-workorders.js" ] && [ -f "scripts/cdp-runner.js" ]; then
echo "执行脚本存在"
else
echo " 执行脚本缺失"
exit 1
fi
echo ""
echo "环境检查通过,可以开始执行数据获取"3.3 项目结构
workorder-analyzer-skill/
├── SKILL.md # Skill 核心定义与执行流程
├── README.md # 项目说明与快速开始指南
├── package.json # Node.js 依赖(playwright等)
├── .gitignore # 忽略.output/、node_modules/等
│
├── scripts/ # 执行脚本
│ ├── fetch-workorders.js # 浏览器端数据获取脚本(Copy as fetch代码化)
│ ├── cdp-runner.js # Playwright CDP执行器(Node.js)
│ ├── check-env.sh # 环境检查(Chrome CDP、Node.js、Playwright)
│ └── install-deps.sh # 一键安装依赖脚本
│
├── config/ # 配置文件(可选)
│ ├── api-endpoints.json # API端点配置
│ └── default-params.json # 默认查询参数
│
├── templates/ # 报告模板
│ └── analysis-template.md # AI分析报告模板
│
├── examples/ # 示例与文档
│ ├── sample-output/ # 示例输出
│ ├── workorders-sample.json
│ └── analysis-report-sample.md
│
└── .output/ # 实际输出目录
├── workorders-latest.json # 最新数据(软链接或复制)
└── 20240314-143052/ # 带时间戳的执行目录(每次执行新建)
├── metadata.json # 执行元数据(时间、参数等)
├── workorders.json # 原始数据(从API获取)
└── analysis-report.md # AI生成的分析报告关键约束
本方案要求目标系统提供可访问的 REST API(SPA 架构下的标准做法)。如果系统完全依赖服务端渲染且无 API 暴露,则仍需退回到浏览器自动化方案。
四、工程化反思
4.1 从"让 AI 做一切"到"人与 AI 的合理分工"
AI从风口席卷成海啸,很容易把人打个"措手不及",在这种大模型百家争鸣的背景下,人类的持续学习和反思显得尤为重要。在探索过程中,我经历了一个重要的认知转变:
最初的误区:试图让 AI 完成所有事情------登录、导航、数据提取、分析。
最终的方案:
- 人做的:登录(涉及安全权限)、验证数据准确性、审核分析报告
- 工具做的:数据获取的执行(稳定、低成本)
- AI 做的:数据分析、报告生成(发挥 AI 优势)
延伸这种思路可知: 在这样的时代里,路径依赖是最大的风险。面对持续发生的变化,最重要的,是始终保持乔布斯所说的那种"初学者心态",不断地去重新理解,并不断尝试与 AI 的新协作方式。
4.2 稳定性优先的工程原则
在企业环境中,稳定性比炫酷更重要。我的方案选择"接口直调"(直接调用已验证的 REST API)而非"AI 操作浏览器"(基于 accessibility tree 的 DOM 操作),核心考量就是稳定性。
稳定性来源:
- 接口契约相对稳定(相比 UI)
- 登录态由浏览器原生维护
- 请求脚本可人工验证
- 错误处理和重试机制
- 输出可追溯(时间戳目录)
4.3 可维护性的长期价值
一个好的工程方案,不仅要解决当前问题,还要考虑长期维护:
可维护性设计:
- 纯文本配置,易于版本管理
- 模块化脚本,职责清晰
- 时间戳组织输出,便于追溯
- 检查脚本前置,快速定位问题
- 详细的注释和文档
五、总结与展望
通过方案的不断改进和探索,让我对"软件工程师"这个角色的理解发生了根本变化:工程师不再只是一个写代码的人,而是变成一个定义软件,并对结果负责的人。 当然,目前我和 AI 的协作方式还谈不上成熟。我仍然需要和它一起确定一个具体的架构、定义模块的边界,并持续检查代码在实践中的可行性,这部分判断工作依然消耗着大量精力。但是我一直相信,随着更成熟的产品形态出现:尤其是更可靠的流程和测试机制,这部分判断成本本身,也很可能会被系统性地消化掉。
5.1 方案成果
通过这个 Skill,原本需要 30-60 分钟的人工流程:
- 打开内网系统
- 多次筛选、导出
- 人工分析、整理
现在变成了 5-10 分钟的自动化流程:
- 一条命令触发 Skill
- 自动完成数据采集与分析
- 输出结构化分析报告,人工快速审核后应用
更重要的是,这个 Skill 具有:
- 可复用性:不同产品、不同版本都能使用
- 可扩展性:轻松适配新的分析维度
- 稳定性:基于接口而非 UI,健壮性高
- 低成本:仅分析环节使用 AI,整体成本降低 95%+
5.2 核心收获
技术层面:
- 深入理解了 SPA 架构下接口与渲染的关系
- 掌握了 Chrome DevTools Protocol 的高级用法
- 实践了"稳定性优先"的工程化设计
- 学会了成本控制和性能优化
思维层面:
- 从"AI 能做什么"转变为"什么问题适合用 AI 解决"
- 认识到工程化思维在 AI 时代依然重要
- 体会到"简单方案"有时比"复杂方案"更有价值
- 培养了成本意识和可维护性意识
5.3 未来优化方向
当然,这个 Skill 还有进一步优化的空间:
- 数据缓存机制:对于不频繁变化的历史数据,引入缓存减少重复请求
- 增量分析:只分析新增问题记录,与历史分析结果合并
- 可视化输出:生成图表而非纯文本报告
- 定时任务:结合 cron 实现定时自动分析
- 多 Skill 协作:将数据获取、分析、报告生成拆分为独立的子模块/Agent,通过标准 JSON 接口协作,实现更灵活的组装
附录
参考项目地址
https://github.com/microsoft/playwright-mcp
https://github.com/heimanba/order-analysis-skill/tree/main