1. 206.反转链表
给你单链表的头节点 head,请你反转链表,并返回反转后的链表。
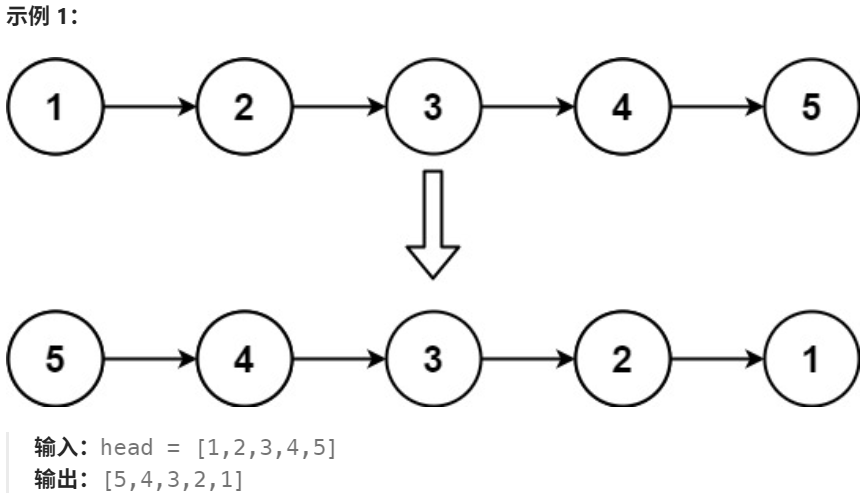
反转完成后:
- pre 为反转前的尾节点,反转后的头结点;
- cur 为反转前的尾节点的后一个节点。
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
// 循环里面四行代码,先得nxt,再翻转,再更改pre和cur
ListNode* pre = nullptr;
ListNode* cur = head;
while(cur){
ListNode* nxt = cur -> next;
cur -> next = pre;
pre = cur;
cur = nxt;
}
return pre;
}
};2. 25.K个一组翻转链表
给你链表的头节点 head ,每 k个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
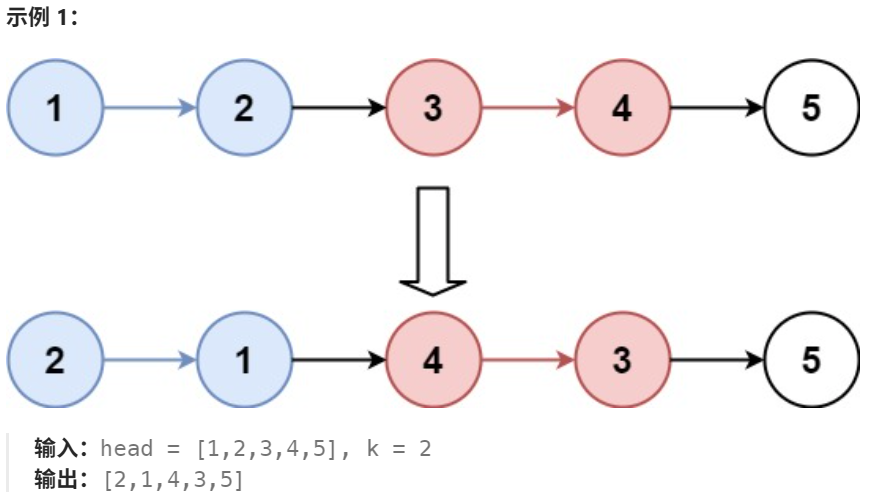
思路: 关键在于理清各个指针的变化,将preTail, curTail, pre, cur连在一起。
- pre 为反转前的尾节点,反转后的头结点;
- cur 为反转前的尾节点的后一个节点,即下一个待反转链表的头结点;
- 每次反转后当前链表的尾部总是 nullptr ,所以:
- 当前反转完成的链表头需要与上一个反转完成的链表尾连接;
- 当前反转完成的链表尾不一定 需要与下一个未反转的链表头连接,因为下一个链表反转后还是会断开 ,但是如果下一个链表长度不够k,就不会反转,导致失去最后一段链表,所以为了避免这个情况,也需要与下一个链表头连接;
- 即:每次反转完成后,与前面的尾相连,与后面的头相连。
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseKGroup(ListNode* head, int k) {
ListNode* cur = head;
int n = 0;
while(cur){
n++;
cur = cur -> next;
}
ListNode* dummy = new ListNode(0, head);
ListNode* preTail = dummy; // 上一个已反转链表的尾
cur = head; // 从头节点开始反转
// 最后k个不用反转
while(n >= k){
n = n - k;
ListNode* pre = nullptr;
ListNode* curTail = cur; // 当前已反转链表的尾就是未反转前的头
for(int i = 0; i < k; i++){
ListNode* nxt = cur -> next;
cur -> next = pre;
pre = cur;
cur = nxt;
}
// 反转完成,此时pre就是新链表的头,cur就是下一个待反转链表的头
preTail -> next = pre;
preTail = curTail;
curTail -> next = cur;
}
return dummy -> next;
}
};3. 23.合并K个升序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。

思路:链表的归并排序,自底向上步长不断增加。
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergerTwoLists(ListNode* head1, ListNode* head2){
ListNode* dummy = new ListNode();
ListNode* cur = dummy;
ListNode* cur1 = head1;
ListNode* cur2 = head2;
while(cur1 && cur2){
if(cur1 -> val > cur2 -> val){
cur -> next = cur2;
cur2 = cur2 -> next;
}else{
cur -> next = cur1;
cur1 = cur1 -> next;
}
cur = cur -> next;
}
cur -> next = cur1 ? cur1 : cur2;
return dummy -> next;
}
ListNode* mergeKLists(vector<ListNode*>& lists) {
if(lists.empty()) return nullptr;
int step = 1;
int n = lists.size();
while(step < n){
int idx = 0;
while(idx < n){
ListNode* head1 = lists[idx];
ListNode* head2 = (idx + step) < n ? lists[idx + step] : nullptr;
lists[idx] = mergerTwoLists(head1, head2);
idx += 2 * step;
}
step *= 2;
}
return lists[0];
}
};4. 148.排序链表
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
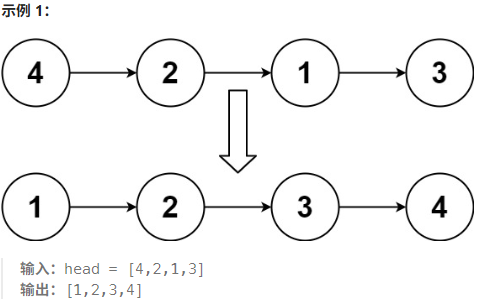
思路:自底向上的归并排序,与上一题相同,外层循环确定步长,内存循环进行合并 。关键在于合并两个链表时要断开每个链表尾部 ,合并后将当前链表头与上一个链表尾连接。
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
// 自底向上的归并排序,大循环判断步长[1, n),小循环cur合并链表,关键在于两个链表的头尾节点,断开与接上
ListNode* mergeTwoLists(ListNode* headA, ListNode* headB){
ListNode* curA = headA, *curB = headB;
ListNode* dummy = new ListNode(0);
ListNode* cur = dummy;
while(curA && curB){
if(curA -> val > curB -> val){
cur -> next = curB;
curB= curB -> next;
}else{
cur -> next = curA;
curA = curA -> next;
}
cur = cur -> next;
}
cur -> next = curA ? curA : curB;
return dummy -> next;
}
ListNode* sortList(ListNode* head) {
int n = 0;
ListNode* cur = head;
while(cur){
n++;
cur = cur -> next;
}
int step = 1;
ListNode* dummy = new ListNode(0, head);
while(step < n){
ListNode* preTail = dummy;
cur = dummy -> next;
while(cur){
// 1. 第1段[head1, tail1]
ListNode* head1 = cur;
for(int i = 1; i < step && cur; i++){
cur = cur -> next;
}
ListNode* tail1 = cur;
// 2. 获取第2段头并与第1段尾断开
ListNode* head2 = nullptr;
if(tail1){
head2 = tail1 -> next;
tail1 -> next = nullptr;
}
// 3. 获取第2段尾
cur = head2;
for(int i = 1; i < step && cur; i++){
cur = cur -> next;
}
ListNode* tail2 = cur;
// 4. 获取下一段头并与第2段尾断开
if(tail2){
cur = tail2 -> next;
tail2 -> next = nullptr;
}
// 5. 合并为[newHead, newTail]
ListNode* newHead = mergeTwoLists(head1, head2);
ListNode* newCur = newHead;
while(newCur && newCur -> next){
newCur = newCur -> next;
}
ListNode* newTail = newCur;
// 6. 与上一段连接
preTail -> next = newHead;
preTail = newTail;
}
step *= 2;
}
return dummy -> next;
}
};5. 146.LRU缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。

思路:需要哨兵头、哨兵尾和一个key到节点的map,注意删除节点和把节点放到链表头时的各个节点的前后指针变化。
cpp
class LRUCache {
public:
struct Node{
int key;
int val;
Node* prev;
Node* next;
Node(int k, int v):key(k), val(v){}
};
unordered_map<int, Node*> key2Node;
Node* dummyHead;
Node* dummyTail;
int size;
LRUCache(int capacity) {
dummyHead = new Node(-1, 0);
dummyTail = new Node(-1, 0);
dummyHead -> next = dummyTail;
dummyTail -> prev = dummyHead;
dummyHead -> prev = nullptr;
dummyTail -> next = nullptr;
size = capacity;
}
int get(int key) {
if(key2Node.count(key)){
// 将该结点提到头
Node* cur = key2Node[key];
cur -> prev -> next = cur -> next;
cur -> next -> prev = cur -> prev;
dummyHead -> next -> prev = cur;
cur -> next = dummyHead -> next;
cur -> prev = dummyHead;
dummyHead -> next = cur;
return cur -> val;
}
return -1;
}
void put(int key, int value){
if(key2Node.count(key)){
Node* cur = key2Node[key];
cur -> val = value;
cur -> prev -> next = cur -> next;
cur -> next -> prev = cur -> prev;
dummyHead -> next -> prev = cur;
cur -> next = dummyHead -> next;
cur -> prev = dummyHead;
dummyHead -> next = cur;
}else{
if(key2Node.size() == size){
// 满了,需要先删除一个
Node* cur = dummyTail -> prev;
cur -> prev -> next = dummyTail;
dummyTail -> prev = cur -> prev;
key2Node.erase(cur -> key);
}
Node* cur = new Node(key, value);
key2Node[key] = cur;
dummyHead -> next -> prev = cur;
cur -> next = dummyHead -> next;
cur -> prev = dummyHead;
dummyHead -> next = cur;
}
}
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/6. 460.LFU缓存
请你为 最不经常使用(LFU)缓存算法设计并实现数据结构。
实现 LFUCache 类:
LFUCache(int capacity)- 用数据结构的容量capacity初始化对象int get(int key)- 如果键key存在于缓存中,则获取键的值,否则返回-1。void put(int key, int value)- 如果键key已存在,则变更其值;如果键不存在,请插入键值对。当缓存达到其容量capacity时,则应该在插入新项之前,移除最不经常使用的项。在此问题中,当存在平局(即两个或更多个键具有相同使用频率)时,应该去除 最久未使用 的键。
为了确定最不常使用的键,可以为缓存中的每个键维护一个 使用计数器 。使用计数最小的键是最久未使用的键。
当一个键首次插入到缓存中时,它的使用计数器被设置为 1 (由于 put 操作)。对缓存中的键执行 get 或 put 操作,使用计数器的值将会递增。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。

思路:每个频率对应一个LRU链表,对其操作时把该节点的频率加1,放到频率更高的LRU链表,需要额外 的对象:频率到链表的map ,当前的最小频率 ,创建新链表的函数。
cpp
class LFUCache {
public:
struct Node {
int key;
int val;
int freq;
Node* prev;
Node* next;
Node(int k, int v) : key(k),val(v){}
};
int minfreq;
int size;
unordered_map<int, Node*> key2Node;
unordered_map<int, pair<Node*, Node*>> freq2lst;
LFUCache(int capacity) {
minfreq = 0;
size = capacity;
}
pair<Node*, Node*> getLst(int freq){
if(!freq2lst.count(freq)){
Node* dummyHead = new Node(-1, -1);
Node* dummyTail = new Node(-1, -1);
dummyHead -> next = dummyTail;
dummyHead -> prev = nullptr;
dummyTail -> next = nullptr;
dummyTail -> prev = dummyHead;
freq2lst[freq] = {dummyHead, dummyTail};
}
return freq2lst[freq];
}
int get(int key) {
if(!key2Node.count(key)){
return -1;
}
Node* cur = key2Node[key];
// 1. 获取原来所在的链表并删除该节点
auto [dummyHead, dummyTail] = getLst(cur -> freq);
cur -> prev -> next = cur -> next;
cur -> next -> prev = cur -> prev;
// 2. 判断原链表是否为空
if(dummyHead -> next -> next == nullptr){
// 判断是否需要更改minFreq
if(minfreq == cur -> freq) minfreq++;
}
// 3. 将该节点插入新链表
cur -> freq++;
tie(dummyHead, dummyTail) = getLst(cur -> freq);
dummyHead -> next -> prev = cur;
cur -> next = dummyHead -> next;
cur -> prev = dummyHead;
dummyHead -> next = cur;
return cur -> val;
}
void put(int key, int value) {
if(key2Node.count(key)){
// 节点已存在,需要提出到新链表
// 1. 获取原来所在的链表并删除该节点
Node* cur = key2Node[key];
auto [dummyHead, dummyTail] = getLst(cur -> freq);
cur -> prev -> next = cur -> next;
cur -> next -> prev = cur -> prev;
// 2. 判断原链表是否为空
if(dummyHead -> next -> next == nullptr){
// 判断是否需要更改minFreq
if(minfreq == cur -> freq) minfreq++;
}
// 3. 将该节点插入新链表
cur -> freq++;
tie(dummyHead, dummyTail) = getLst(cur -> freq);
dummyHead -> next -> prev = cur;
cur -> next = dummyHead -> next;
cur -> prev = dummyHead;
dummyHead -> next = cur;
cur -> val = value;
return;
}
// 节点不存在
// 1.判断是否需要删除
if(key2Node.size() == size){
// 满了,需要删除一个
auto [dummyHead, dummyTail] = getLst(minfreq);
Node* cur = dummyTail -> prev;
dummyTail -> prev = cur -> prev;
cur -> prev -> next = dummyTail;
key2Node.erase(cur -> key);
}
minfreq = 1;
auto [dummyHead, dummyTail] = getLst(minfreq);
Node* cur = new Node(key, value);
cur -> freq = 1;
key2Node[key] = cur;
dummyHead -> next -> prev = cur;
cur -> next = dummyHead -> next;
cur -> prev = dummyHead;
dummyHead -> next = cur;
}
};
/**
* Your LFUCache object will be instantiated and called as such:
* LFUCache* obj = new LFUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/7. 环
7.1 141.环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
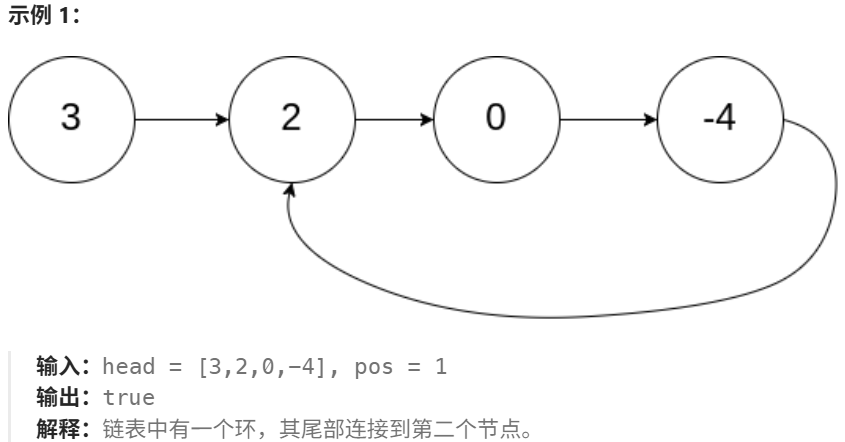
思路:快慢指针,若存在环则双指针会相遇
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool hasCycle(ListNode *head) {
ListNode* slow = head;
ListNode* fast = head;
while(fast && fast -> next){
slow = slow -> next;
fast = fast -> next -> next;
if(slow == fast) return 1;
}
return 0;
}
};7.2 142.环形链表Ⅱ
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始 )。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改链表。
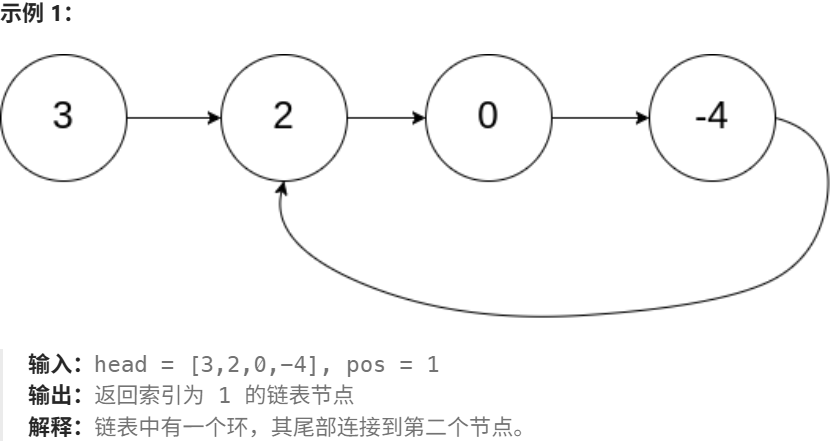
思路:Floyd 判圈算法:快慢指针相遇后,一个指针从头走直到与慢指针相遇即为入环点。
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode* slow = head;
ListNode* fast = head;
while(fast && fast -> next){
slow = slow -> next;
fast = fast -> next -> next;
if(fast == slow){
ListNode* cur = head;
while(cur != slow){
cur = cur -> next;
slow = slow -> next;
}
return cur;
}
}
return nullptr;
}
};7.3 287.寻找重复数
给定一个包含 n + 1 个整数的数组 nums ,其数字都在 [1, n] 范围内(包括 1 和 n),可知至少存在一个重复的整数。
假设 nums 只有 一个重复的整数 ,返回 这个重复的数 。
你设计的解决方案必须 不修改 数组 nums 且只用常量级 O(1) 的额外空间。
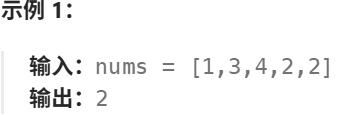
思路:
- 将当前索引 i 上的值 numsi 看作当前节点的 next 指针;
- 索引/节点地址范围 0, n,值/next指针范围 1, n ,于是必定有至少两个节点指向同一个节点,即必定存在环;
- 遍历所有节点作为链表头 ,由于每个链表都必定存在环 ,如果以这个节点为头的链表不是自环 ,则这次遍历必能找到入环点,即重复数。
cpp
class Solution {
public:
int findDuplicate(vector<int>& nums) {
auto next = [&](int i) -> int {
return nums[i];
};
for(int i = 0; i < nums.size(); i++){
// 循环遍历,因为当前节点可能是自环
int slow = i, fast = i;
while(slow != next(slow)){
// 当前节点不是自环,能找到重复数
slow = next(slow);
fast = next(next(fast));
if(slow == fast){
int cur = i;
while(cur != slow){
cur = next(cur);
slow = next(slow);
}
return cur;
}
}
}
return 0; // 不会执行到这里
}
};或者去除外部头结点的遍历:
cpp
class Solution {
public:
int findDuplicate(vector<int>& nums) {
auto next = [&](int i) -> int {
return nums[i];
};
// 循环遍历,因为当前节点可能是自环
int slow = 0, fast = 0;
while(1){
// 0 这个节点必定不可能自环,故不用判断
slow = next(slow);
fast = next(next(fast));
if(slow == fast){
int cur = 0;
while(cur != slow){
cur = next(cur);
slow = next(slow);
}
return cur;
}
}
return 0; // 不会执行到这里
}
};因为 0 不是 next 指针的范围,所以当前索引为0的这个节点的next 不可能是自己,不会是自环,所以必定能找到入环点。
7.4 457.环形数组是否存在循环
存在一个不含 0 的环形 数组 nums ,每个 nums[i] 都表示位于下标 i 的角色应该向前或向后移动的下标个数:
- 如果
nums[i]是正数,向前 (下标递增方向)移动nums[i]步 - 如果
nums[i]是负数,向后 (下标递减方向)移动abs(nums[i])步
因为数组是 环形 的,所以可以假设从最后一个元素向前移动一步会到达第一个元素,而第一个元素向后移动一步会到达最后一个元素。
数组中的 循环 由长度为 k 的下标序列 seq 标识:
- 遵循上述移动规则将导致一组重复下标序列
seq[0] -> seq[1] -> ... -> seq[k - 1] -> seq[0] -> ... - 所有
nums[seq[j]]应当不是 全正 就是 全负 k > 1
如果 nums 中存在循环,返回 true ;否则,返回false。
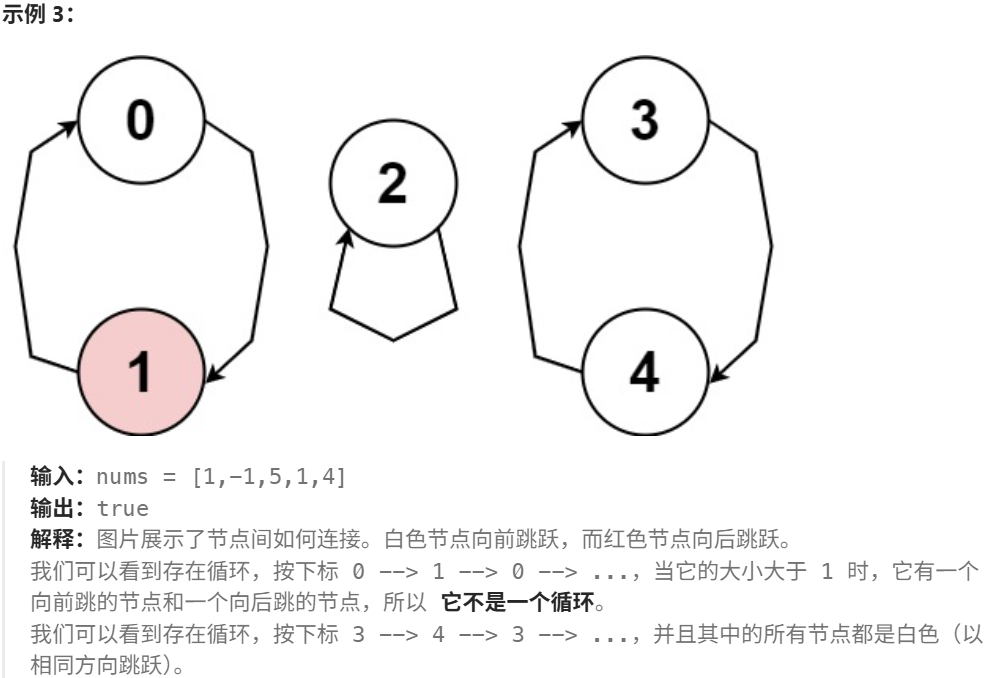
思路:与上一题相同,但是对于循环的定义加了一个额外的条件:方向相同,在判断的时候注意该点即可。
cpp
class Solution {
public:
bool circularArrayLoop(vector<int>& nums) {
int n = nums.size();
auto next = [&](int i){
return ((i + nums[i]) % n + n) % n;
};
for(int i = 0; i < nums.size(); i++){
int slow = i, fast = i;
while(nums[slow] * nums[next(fast)] > 0 && nums[slow] * nums[next(next(fast))] > 0){
// 确保同向
slow = next(slow);
fast = next(next(fast));
if(slow == next(slow)) break; // 防止自环
if(slow == fast) return 1;
}
}
return 0;
}
};