锁基础
原子(atomic)操作
原子操作是一种硬件层面加锁的机制,其可以保证一个协程操作一个变量时,其他协程/线程不能访问,但也仅限于对简单变量的简单操作。
Go的atomic包来提供多种原子操作,达到并发安全。
sema锁
信号量锁
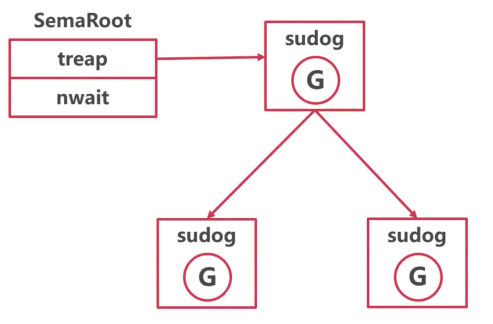
每一个uint32的sema数字,都对应了一个semaRoot结构体:
go
type semaRoot struct {
lock mutex
treap *sudog // 一棵平衡二叉树的根节点
nwait atomic.Uint32 // Number of waiters. Read w/o the lock.
}
type sudog struct {
g *g
next *sudog
prev *sudog
....
}
sema锁操作
获取
go
// 获取sema锁
func semacquire(addr *uint32) {
semacquire1(addr, false, 0, 0, waitReasonSemacquire)
}
func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags, skipframes int, reason waitReason) {
...
if cansemacquire(addr) {
return
}
...
}
func cansemacquire(addr *uint32) bool {
for {
v := atomic.Load(addr) //原子地加载addr
if v == 0 {
return false
}
if atomic.Cas(addr, v, v-1) { //若v>0,原子地减一
return true
}
}
}sema数字>0时,获取sema锁本质cansemacquire中对sema减一
sema==0时,获取锁时cansemacquire返回false,semacquire1继续往后执行:
go
func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags, skipframes int, reason waitReason) {
...
if cansemacquire(addr) {
return
}
s := acquireSudog()
root := semtable.rootFor(addr)//拿到平衡二叉树根节点
...
for {
...
root.queue(addr, s, lifo) //进入树中排队
goparkunlock(&root.lock, reason, traceEvGoBlockSync, 4+skipframes)//休眠协程
if s.ticket != 0 || cansemacquire(addr) {
break
}
}
}释放
释放sema锁本质就是sema值+1,判断树中是否有协程在等待,有则取出协程并唤醒
go
func semrelease(addr *uint32) {
semrelease1(addr, false, 0)
}
func semrelease1(addr *uint32, handoff bool, skipframes int) {
...
atomic.Xadd(addr, 1) //原子地+1
if root.nwait.Load() == 0 {
return
}
...
s, t0 := root.dequeue(addr)//取出协程
...
}故,sema uint32这个值本质上表示的是可以并发获取该锁的协程的数量,这个sema锁可以不止一个协程获得。
sema置为0时,则可以用作一个休眠队列。
Mutex
Mutex结构
**src/sync/mutex.go**中定义了互斥锁的数据结构:
go
type Mutex struct{
state int32 //互斥锁的状态
sema uint32 //信号量,解锁的协程通过释放信号量来唤醒等待信号量的协程
}32位的state:
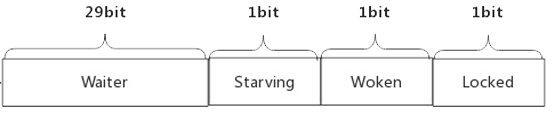
**Waiter**:阻塞等待该锁的协程数**Starving**:表示是否有等待该Mutex的协程处于饥饿状态**Woken**:表示是否有协程在CPU上运行申请加锁,而非阻塞状态**Locked**:表示该Mutex是否被上锁
简单的上锁解锁过程:
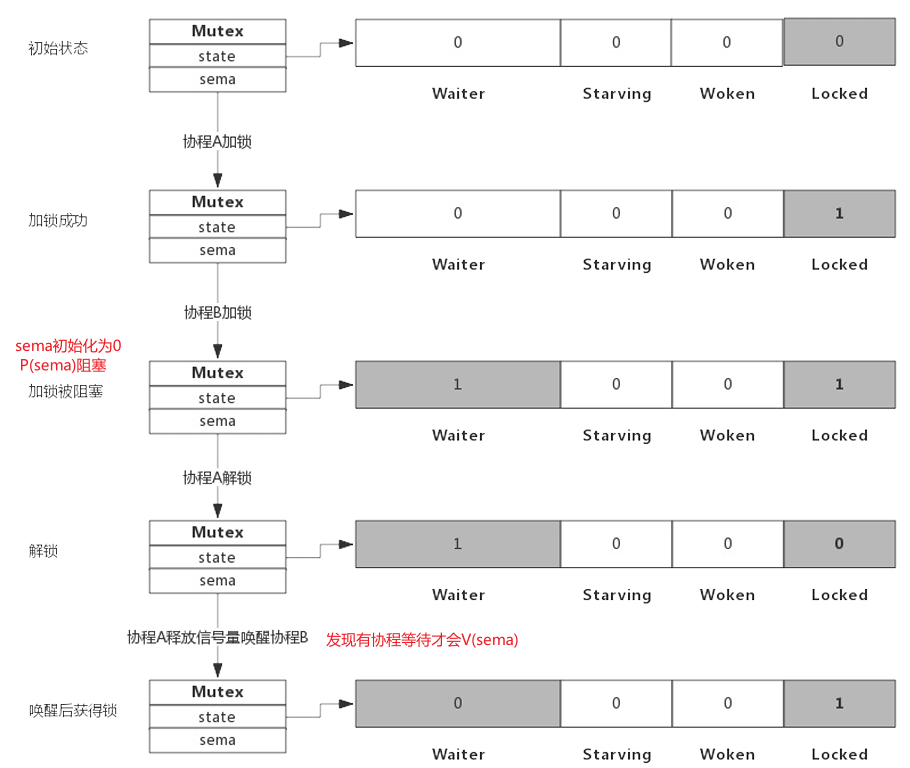
自旋
自旋对应于CPU的 **PAUSE**指令,CPU对于该指令什么都不做,相当于CPU空转,不同于sleep,不需要将协程转为睡眠状态。
加锁时,如果Locked为1,尝试加锁的协程不会马上转入P(sema)阻塞,而是会自旋持续探测Locked是否变为0。自旋时间很短,如果自旋过程中锁被释放,那么这个自旋的协程可以立马获得锁,即使此时有阻塞的协程被唤醒也无法获得锁,只能继续阻塞。
条件
加锁时程序会判断是否可以自旋,无限制的自旋会给CPU过大压力,自旋必须满足以下所有条件:
- 自旋次数要小,通常为4。
- cpu核数要大于1,不然自旋没有意义,因为此时不可能有其他协程释放锁。
- **协程调度机制中的Process数量要大于1,比如使用GOMAXPROCS()将处理器设置为1就不能启用自旋 **
- **协程调度机制中的可运行队列必须为空,否则会延迟协程调度 **
总而言之就是不忙的时候才会启用自旋。
好处
自旋的好处在于可以充分利用CPU,尽量避免协程切换。
当前申请加锁的协程是拥有CPU的,如果在短时间的自旋可以立马获得锁,当前协程就可以继续运行,而不用阻塞切换。
劣势
自旋过程中获得锁,会导致之前被阻塞的协程无法获得锁,如果来申请加锁的协程特别多,每次都通过自旋获得了锁,就会导致之前阻塞的协程很难获得锁,从而进入饥饿状态。
为了避免协程长时间无法获得锁的饥饿状态,1.8版本之后,Mutex添加了Starving状态。
Mutex的模式
正常模式
Mutex的默认模式,该模式下,协程申请加锁不成功不会立即转入阻塞排队,而是判断是否满足自旋的条件,如果满足则会启动自旋过程,尝试抢锁。
饥饿模式
释放锁时,如果发现有阻塞的协程,还会释放一个信号量来唤醒一个等待协程,被唤醒的协程申请锁时,发现锁已经被自旋的协程抢占了,只好再次阻塞。但是阻塞前会判断自上次阻塞到本次阻塞经过了多少时间,如果超过1ms就将Mutex的Starving置为1 ,即将Mutex标记为饥饿模式,然后再阻塞。
处于饥饿模式的Mutex,不会启动自旋过程,一旦有协程释放了锁,就一定会唤醒阻塞的协程,被唤醒的协程将成功获取锁,同时Waiter-1。
Woken
用于加锁和解锁过程的通信。如,一个在自旋过程的协程,此时Woken为1,同时另一协程解锁时判断Woken为1则不会释放信号量。
为何重复解锁要panic
由于Unlock时会可能每次都释放一个信号量,如果重复解锁可能唤醒多个协程。多个协程被唤醒后又会继续在Lock中抢锁,势必会增加Lock实现的复杂度,也会引起不必要的协程切换。
RWMutex
数据结构
**src/sync/rwmutex.go**中定义了读写锁的数据结构:
go
type RWMutex struct{
w Mutex //控制多个写锁,获得写锁要先获得这把锁,
//如果有一个写锁在进行,到来的写锁会阻塞在这
writerSem uint32 //写阻塞等待的信号量,最后一个读者释放锁会释放该信号量
readerSem uint32 //读阻塞等待的信号量,写者释放锁后会释放该信号量
readerCount int32 //记录读者个数
readerWait int32 //记录目前写阻塞时的读者个数,防止写锁饥饿
}接口实现
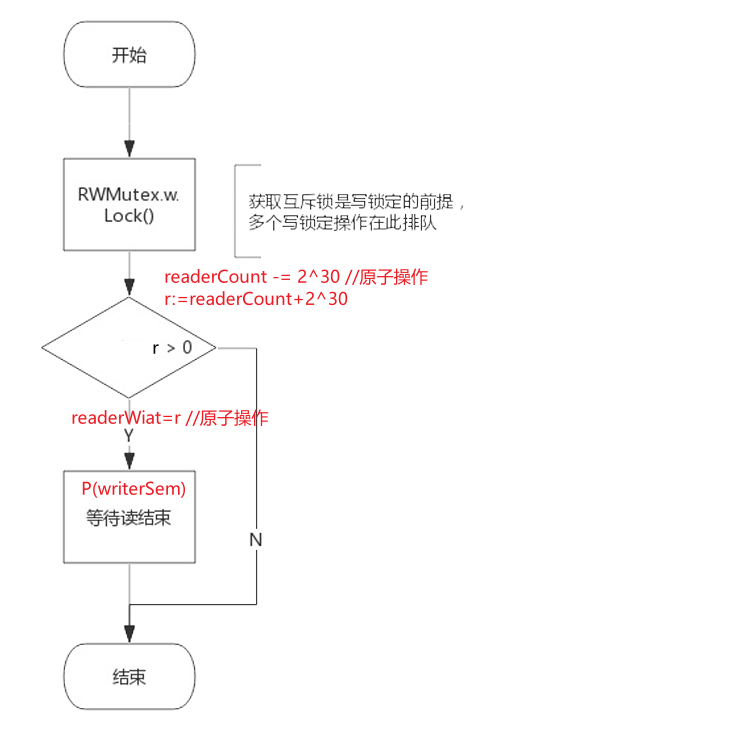
Lock():写锁定
go
func (rw *RWMutex) Lock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
// First, resolve competition with other writers.
rw.w.Lock() //想要获取写锁,首先要获取互斥锁,下面再等待所有读者释放锁
// Announce to readers there is a pending writer.
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders //使用原子操作减去rwmutexMaxReaders将readerCount置为负值,目的是阻止读锁。再加上rwmutexMaxReaders又可以获取原来的读者数。非常精妙
// Wait for active readers.
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 { //如果读者数是0,那么直接获取写锁,不需要等待信号量。 因为写锁获取成功,所以此处简单的加上读者数量即可。(加上读者数量应该不会出现0的情况)
runtime_SemacquireMutex(&rw.writerSem, false) // 续:此处将读者数写入readerWait实际上是用于排队,即当前为止的读者释放后轮到写操作,避免写锁被饿死
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
race.Acquire(unsafe.Pointer(&rw.writerSem))
}
}
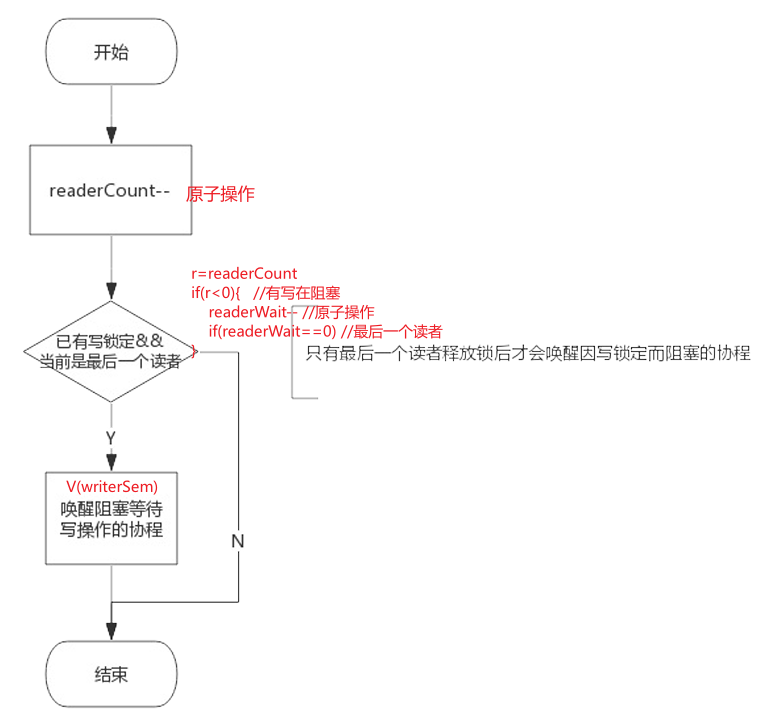
RUnLock():释放读锁
go
func (rw *RWMutex) RUnlock() {
if race.Enabled {
_ = rw.w.state
race.ReleaseMerge(unsafe.Pointer(&rw.writerSem))
race.Disable()
}
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 { //每个读者解锁时,首先将readerCount -1,如果readerCount为负值,说明有协程在等待写锁
if r+1 == 0 || r+1 == -rwmutexMaxReaders {
race.Enable()
throw("sync: RUnlock of unlocked RWMutex")
}
// A writer is pending.
if atomic.AddInt32(&rw.readerWait, -1) == 0 { //将readerWait -1, 并且最后一个读者负责释放一个信号量,来唤醒等待写锁的协程
// The last reader unblocks the writer.
runtime_Semrelease(&rw.writerSem, false)
}
}
if race.Enabled {
race.Enable()
}
}
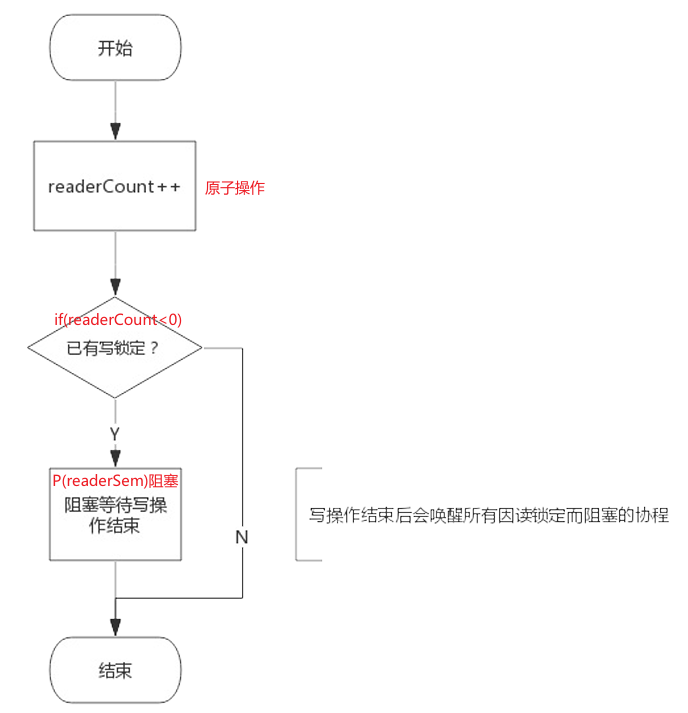
RLock():读锁定
go
func (rw *RWMutex) RLock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
if atomic.AddInt32(&rw.readerCount, 1) < 0 { //读者数量简单+1,如果readerCount为负值,说明有协程持有了写锁,需要等待协程解除写锁后释放信号量解锁
// A writer is pending, wait for it.
runtime_SemacquireMutex(&rw.readerSem, false)
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
}
}
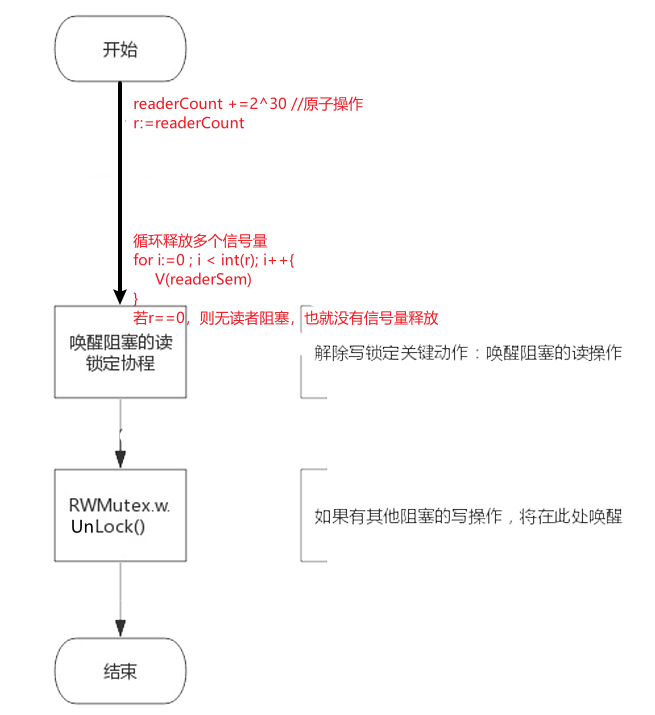
Unlock():释放写锁
go
func (rw *RWMutex) Unlock() {
if race.Enabled {
_ = rw.w.state
race.Release(unsafe.Pointer(&rw.readerSem))
race.Disable()
}
// Announce to readers there is no active writer.
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders) //因为持有写锁期间,读者数量有可能增加,此处将读者数量加上rwmutexMaxReaders,将读者数量转为正值。
if r >= rwmutexMaxReaders {
race.Enable()
throw("sync: Unlock of unlocked RWMutex")
}
// Unblock blocked readers, if any.
for i := 0; i < int(r); i++ { //持有锁期间,读者可能继续到来并阻塞起来,所以这里有多少个读者,释放多少个信号量
runtime_Semrelease(&rw.readerSem, false)
}
// Allow other writers to proceed.
rw.w.Unlock()
if race.Enabled {
race.Enable()
}
}
解析
写操作如何阻止写操作
写操作必须先申请互斥锁w,写者A申请到了互斥锁,则B就只能阻塞等待互斥锁。
写操作如何阻止读操作
写操作申请到互斥锁之后会 **readerCount-=2^30**,直到写解锁才 **readerCount+=2^30**;读操作来时 **readerCount++**后会判断 **readerCount**是否为正,若为负则知道此时有写操作就只能阻塞等待。
**写操作将readerCount变成负值来阻止读操作的。 **
读操作如何阻止写操作
读操作会readerCount++,写操作发现读者不为0,则阻塞等待。
写操作为什么不会被饿死
写操作阻塞时,一方面会将 **readerCount**变为负数,之后到来的读者会阻塞,二方面会用 **readerWait**记录目前的正在读的读者数量,这一批读者结束就会释放信号量,来轮到该写者操作。而写阻塞之后到来的读者只能等到该写操作结束释放信号量来唤醒。