卷积层是卷积神经网络(CNN)的核心组件,而torch.nn.Conv2d作为 PyTorch 中实现二维卷积的核心类,广泛应用于图像分类、目标检测、语义分割等计算机视觉任务。本文将从基础概念、参数详解、使用示例到核心原理,全方位拆解torch.nn.Conv2d,帮助新手快速掌握其用法和底层逻辑。

一、Conv2d 核心作用
torch.nn.Conv2d用于对二维输入(如彩色图像、灰度图像)执行卷积操作,其核心目的是通过可学习的卷积核(过滤器)提取输入数据的局部特征(如边缘、纹理、形状)。例如,对一张3×224×224的 RGB 图像(通道数 × 高度 × 宽度),Conv2d 会用多个卷积核在图像上滑动,计算局部区域的加权和,输出新的特征图。
二、Conv2d 参数详解
torch.nn.Conv2d的完整初始化参数如下(按重要性排序):
python
torch.nn.Conv2d(
in_channels: int, # 输入数据的通道数
out_channels: int, # 输出特征图的通道数(卷积核数量)
kernel_size: Union[int, Tuple[int, int]], # 卷积核尺寸
stride: Union[int, Tuple[int, int]] = 1, # 卷积步长
padding: Union[int, Tuple[int, int], str] = 0, # 填充方式/数量
dilation: Union[int, Tuple[int, int]] = 1, # 空洞卷积的膨胀率
groups: int = 1, # 分组卷积的组数
bias: bool = True, # 是否添加偏置项
padding_mode: str = 'zeros' # 填充模式(默认零填充)
)参数注解如下:
| 参数名 | 是否必填 | 含义与作用 | 通俗理解 |
|---|---|---|---|
| in_channels | 是 | 输入数据的通道数 | 比如 RGB 图片的通道数是 3,灰度图是 1;这个参数告诉卷积层 "输入有多少个通道需要处理" |
| out_channels | 是 | 输出数据的通道数(卷积核的数量 | 每一个卷积核对应输出一个通道,比如设置为 64,就会输出 64 个通道的特征图 |
| kernel_size | 是 | 卷积核的尺寸(整数或元组) | 比如3表示 3×3 的卷积核,(3,5)表示 3 行 5 列的卷积核;卷积核是做卷积计算的 "过滤器" |
| stride | 否 | 卷积核滑动的步长(整数或元组) | 默认值1,步长为 1 表示每次滑 1 个像素,步长为 2 表示每次滑 2 个像素;步长越大,输出特征图越小 |
| padding | 否 | 输入数据四周填充的像素数(整数 / 元组 / 字符串) | 默认值0,可以避免卷积后特征图尺寸缩小,padding='same'会自动填充让输出尺寸和输入一致 |
| dilation | 否 | 卷积核元素之间的间距(膨胀率) | 默认值1,膨胀率为 2 时,3×3 卷积核会变成 5×5 的有效范围(像素间隔 1 个),用于扩大感受野 |
| groups | 否 | 分组卷积的组数 | 默认值1,控制输入和输出通道的连接方式:groups=1:普通卷积(所有输入连所有输出) groups=in_channels:深度卷积(每个输入通道对应一组卷积核) |
| bias | 否 | 是否添加偏置项 | 默认值 True, 卷积计算后加一个可学习的常数,默认 True |
| padding_mode | 否 | 填充模式 | 默认为'zeros'(填充 0),还有'reflect'(反射填充)、'replicate'(复制填充)等 |
三、输出尺寸计算
Conv2d 输出特征图的尺寸是新手最易混淆的点,核心公式如下(仅考虑高 / 宽方向,通道数为out_channels):
假设输入尺寸为H×W(高度 × 宽度),卷积核尺寸Kh×Kw,步长Sh×Sw,paddingPh×Pw,膨胀率Dh×Dw,则输出尺寸H_out×W_out为:
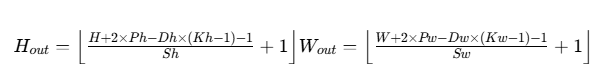
示例计算
输入:H=224, W=224, in_channels=3
Conv2d 参数:kernel_size=3, stride=2, padding=1, dilation=1
计算:
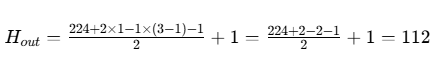
输出尺寸为112×112,通道数为out_channels(如 64)。
四、实战使用示例
这里多啰嗦一下,方便下面代码对照查看。在深度学习中,神经网络的核心数据载体是张量(Tensor),理解张量形状是使用卷积层的基础。例如一个形状为 (1, 3, 640, 640) 的张量,其维度含义为:批次(batch)=1、通道数(channel)=3、高度(height)=640、宽度(width)=640。
1.卷积形状测试(Conv2d 输出尺寸与参数计算)
卷积层是深度学习中处理图像类数据的核心模块,nn.Conv2d 的参数(步长、填充、卷积核大小)直接决定输出张量的形状,而通道数则决定了卷积层的参数总量。以下代码通过实例验证卷积层的输出尺寸和参数数量计算逻辑:
python
import torch
import torch.nn as nn
# ===================== 核心参数说明 =====================
# 输入张量形状:[batch_size, in_channels, height, width]
# - batch_size: 批量大小(这里设为1,代表单张图片)
# - in_channels: 输入通道数(RGB图像为3,灰度图为1)
# - height/width: 特征图的高/宽(这里设为5×5)
# ===================== 定义输入 =====================
input_tensor = torch.randn(1, 3, 5, 5) # 随机生成符合形状的输入张量
# ===================== 定义卷积层 =====================
# 关键参数说明:
# - in_channels=3:必须与输入张量的通道数一致
# - out_channels=64:输出通道数(可理解为使用64个卷积核提取特征)
# - kernel_size=3:卷积核大小(3×3)
# - stride=1:步长(卷积核每次滑动1个像素)
# - padding=1:填充(在特征图边缘填充1圈0,保证输入输出尺寸不变)
conv = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1)
# ===================== 执行卷积操作 =====================
output_tensor = conv(input_tensor)
# ===================== 输出尺寸验证 =====================
print(f"输入尺寸: {input_tensor.shape}") # 输出:torch.Size([1, 3, 5, 5])
print(f"输出尺寸: {output_tensor.shape}") # 输出:torch.Size([1, 64, 5, 5])
# 尺寸不变原因:填充padding=1抵消了卷积核(kernel_size=3)带来的尺寸缩小,步长stride=1无额外缩放
# ===================== 参数数量计算 =====================
# 卷积核参数数量公式:in_channels × out_channels × kernel_size × kernel_size
# 计算过程:3(输入通道)× 64(输出通道)× 3(核高)× 3(核宽)= 1728
print(f"卷积核参数数量: {conv.weight.numel()}") # 输出:1728
# 偏置参数数量:每个输出通道对应1个偏置,因此数量=out_channels=64
print(f"偏置参数数量: {conv.bias.numel()}") # 输出:64
# 卷积层总参数数量:1728 + 64 = 1792
print(f"卷积层总参数数量: {conv.weight.numel() + conv.bias.numel()}") # 输出:1792
# ===================== 补充:输出尺寸通用计算公式 =====================
# 对于nn.Conv2d,输出高/宽的通用公式:
# H_out = floor((H_in + 2×padding - kernel_size) / stride) + 1
# W_out = floor((W_in + 2×padding - kernel_size) / stride) + 1
# 代入本例:H_out = (5 + 2×1 - 3)/1 + 1 = 5,与实际输出一致这里的步长(stride)、填充(padding)都为1时,是下面一个通道的运算过程:
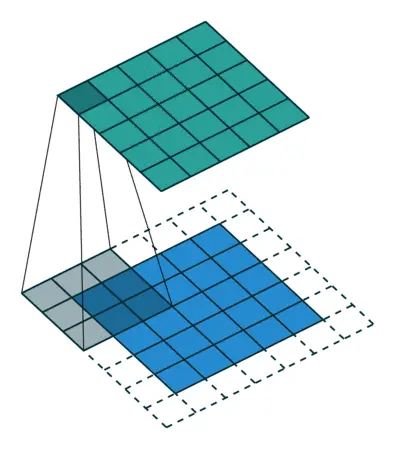
这里的weight即代表模型训练时更新的参数。
2. 卷积值运算测试(单通道卷积计算原理)
上述代码验证了 "形状",而卷积的核心是 "数值运算"。以单通道、无填充、步长 1 的简化场景为例,直观理解卷积的计算过,假设输入单通道特征图为 3×3 矩阵,卷积核为 3×3 矩阵,步长 = 1、填充 = 0:
python
import torch
import torch.nn as nn
# 简化版:单通道卷积数值计算
# 定义单通道输入(3×3)
single_input = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]], dtype=torch.float32).unsqueeze(0).unsqueeze(0) # 形状:[1, 1, 3, 3]
# 定义3×3卷积核(单输入通道、单输出通道)
single_conv = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=0, bias=False)
# 手动设置卷积核参数(方便计算)
single_conv.weight.data = torch.tensor([[[[1, 0, -1],
[1, 0, -1],
[1, 0, -1]]]], dtype=torch.float32)
# 执行卷积
single_output = single_conv(single_input)
# 打印结果
print("\n单通道卷积输入:\n", single_input.squeeze().numpy())
print("卷积核:\n", single_conv.weight.data.squeeze().numpy())
print("卷积输出:\n", single_output.detach().squeeze().numpy()) # 输出:[-6.]
# 计算过程验证
manual_calc = 1*1 + 2*0 + 3*(-1) + 4*1 + 5*0 + 6*(-1) + 7*1 + 8*0 + 9*(-1)
print(f"手动计算结果: {manual_calc}") # 输出:-6这里的卷积运算其实它被称为互相关运算,比如说输入为4*4,卷积核为2,则运算可以表示为:
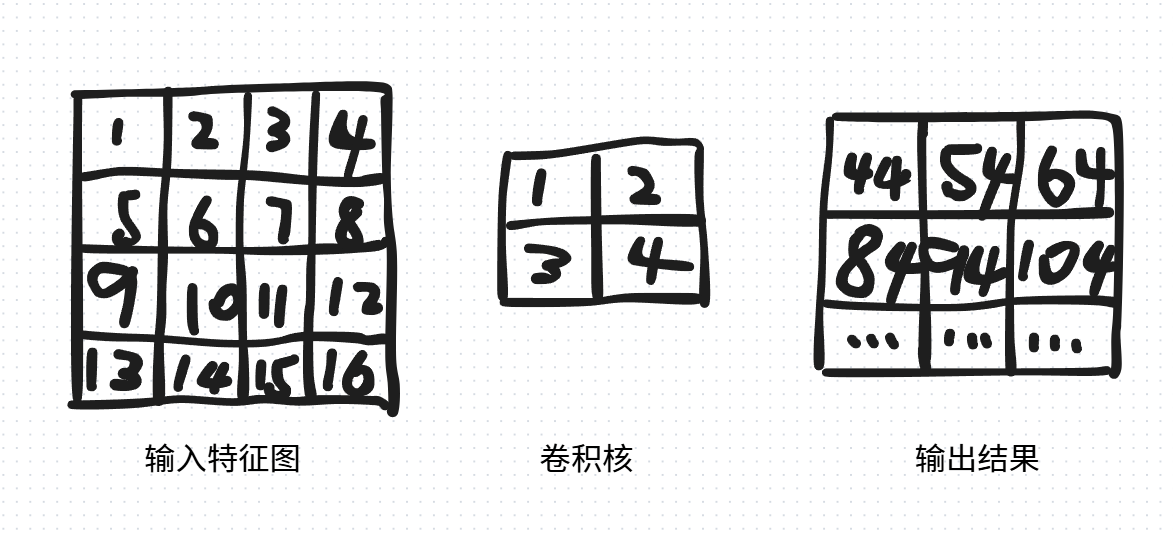
五、核心原理补充
1. 卷积计算的本质
torch.nn.Conv2d的底层计算是互相关运算(与数学上的卷积仅差卷积核翻转,效果等价):对于输入的每个局部区域,与卷积核逐元素相乘后求和,再加上偏置(若有),得到输出特征图的一个像素值。
2. 参数量计算
Conv2d 层的参数量仅与卷积核相关,公式为:
参数量=out_channels * (in_channels / groups * Kh * Kw ) + (bias ? out_channels : 0)示例:
in_channels=3, out_channels=64, kernel_size=3, groups=1, bias=True
参数量 = 64 × (3×3×3) + 64 = 64×27 +64 = 1792。
3. 与 F.conv2d 的区别
torch.nn.Conv2d是层类 ,继承自nn.Module,包含可学习的参数(weight/bias),可通过model.parameters()获取,适合构建网络;torch.nn.functional.conv2d是函数,需手动传入卷积核和偏置,无可学习参数,适合自定义卷积逻辑。
总结
torch.nn.Conv2d的核心参数是in_channels、out_channels、kernel_size,通过stride、padding控制输出尺寸,dilation、groups实现特殊卷积;- 输出尺寸可通过公式精准计算,
padding='same'可快速实现输入输出尺寸一致; - 实际使用中,Conv2d 常与 BatchNorm2d、激活函数组合,且接 BN 时建议关闭偏置以减少冗余参数。