
🎬 个人主页 :艾莉丝努力练剑
❄专栏传送门 :《C语言》《数据结构与算法》《C/C++干货分享&学习过程记录》
《Linux操作系统编程详解》《笔试/面试常见算法:从基础到进阶》《Python干货分享》
⭐️为天地立心,为生民立命,为往圣继绝学,为万世开太平
🎬 艾莉丝的简介:

文章目录
- [1 ~> 准备阶段:进程间通信的概念](#1 ~> 准备阶段:进程间通信的概念)
-
- [1.1 是什么(本质前提)](#1.1 是什么(本质前提))
- [1.2 为什么](#1.2 为什么)
- [1.3 怎么办](#1.3 怎么办)
- [1.4 思维导图](#1.4 思维导图)
- [2 ~> 进程间通信](#2 ~> 进程间通信)
-
- [2.1 进程间通信的定制标准:System V](#2.1 进程间通信的定制标准:System V)
- [2.2 进程间通信的发展](#2.2 进程间通信的发展)
- [3 ~> 管道的特点和情况总结](#3 ~> 管道的特点和情况总结)
-
- [3.1 五种特点](#3.1 五种特点)
- [3.2 四种情况](#3.2 四种情况)
- [3.3 思维导图](#3.3 思维导图)
- [4 ~> 进程池](#4 ~> 进程池)
-
- [4.1 有一个小Bug](#4.1 有一个小Bug)
- [4.2 进程池:以创建10个子进程为例](#4.2 进程池:以创建10个子进程为例)
- [5 ~> 命名管道](#5 ~> 命名管道)
-
- [5.1 客户端不需要建立管道](#5.1 客户端不需要建立管道)
- [5.2 打开和关闭管道之间,客户端可以进行通信](#5.2 打开和关闭管道之间,客户端可以进行通信)
- [5.3 不需要写C语言的\0](#5.3 不需要写C语言的\0)
- [5.4 毫不相干的两个进程的父进程可能不一样](#5.4 毫不相干的两个进程的父进程可能不一样)
- [5.5 目前完成的服务端和客户端代码](#5.5 目前完成的服务端和客户端代码)
- [5.6 最终呈现的服务端和客户端代码](#5.6 最终呈现的服务端和客户端代码)
- [5.7 命名管道的本质](#5.7 命名管道的本质)
- [5.8 命名管道打开的细节问题](#5.8 命名管道打开的细节问题)
- [5.9 命名管道思维导图](#5.9 命名管道思维导图)
-
- [5.9.1 匿名管道(进程池)+(开了个头)命名管道](#5.9.1 匿名管道(进程池)+(开了个头)命名管道)
- [5.10 管道的应用场景](#5.10 管道的应用场景)
-
- [5.10.1 **命名管道实现文件拷贝**](#5.10.1 命名管道实现文件拷贝)
- [5.10.2 定标准](#5.10.2 定标准)
- [5.10.3 System V 标准](#5.10.3 System V 标准)
- [6 ~> 共享内存](#6 ~> 共享内存)
-
- [6.1 原理](#6.1 原理)
-
- [6.1.1 原理思维导图](#6.1.1 原理思维导图)
- [6.1.2 原理理论](#6.1.2 原理理论)
- [6.1.3 共享内存与进程地址空间布局](#6.1.3 共享内存与进程地址空间布局)
- [6.1.4 问题](#6.1.4 问题)
- [6.1.5 思路打开------突破点](#6.1.5 思路打开——突破点)
- [6.2 准备工作:写代码 + 原理](#6.2 准备工作:写代码 + 原理)
-
- [6.2.1 .hpp和header only](#6.2.1 .hpp和header only)
-
- [6.2.1.1 概念区分](#6.2.1.1 概念区分)
- [6.2.2 使用.hpp的原因:写代码工作量小,文件数量少](#6.2.2 使用.hpp的原因:写代码工作量小,文件数量少)
- [6.2.3 shmget](#6.2.3 shmget)
- [6.3 共享内存:代码书写](#6.3 共享内存:代码书写)
-
- [6.3.1 设计问题:这里设计成文件描述符才行](#6.3.1 设计问题:这里设计成文件描述符才行)
- [6.3.2 键值:key](#6.3.2 键值:key)
- [6.3.3 为什么要用这种方式设置key值?](#6.3.3 为什么要用这种方式设置key值?)
- [6.3.4 怎么办?](#6.3.4 怎么办?)
- [6.3.5 约定key值 VS 返回值id](#6.3.5 约定key值 VS 返回值id)
- [6.3.6 新指令:ipcs -m](#6.3.6 新指令:ipcs -m)
- [6.3.7 权限设置](#6.3.7 权限设置)
- [6.3.8 删除共享内存:shmctl](#6.3.8 删除共享内存:shmctl)
- [6.3.9 获取共享内存](#6.3.9 获取共享内存)
- [6.3.10 查看结构体](#6.3.10 查看结构体)
- [6.3.11 挂接函数](#6.3.11 挂接函数)
- [6.4 代码演示(挂接)](#6.4 代码演示(挂接))
- [6.5 共享内存思维导图1](#6.5 共享内存思维导图1)
- [6.6 代码演示(共享内存收尾)](#6.6 代码演示(共享内存收尾))
- [6.7 共享内存补充](#6.7 共享内存补充)
-
- [6.7.1 回顾](#6.7.1 回顾)
- [6.7.2 验证addr在堆栈之间](#6.7.2 验证addr在堆栈之间)
- [6.7.3 删除共享内存之前一般是要去关联](#6.7.3 删除共享内存之前一般是要去关联)
- [6.7.4 我们在使用共享内存的时候。有没有使用系统调用?](#6.7.4 我们在使用共享内存的时候。有没有使用系统调用?)
-
- [6.7.4.1 结论1](#6.7.4.1 结论1)
- [6.7.4.2 结论2](#6.7.4.2 结论2)
- [6.7.4.3 结论3](#6.7.4.3 结论3)
- [6.7.5 共享内存的大小设置](#6.7.5 共享内存的大小设置)
- 结尾

1 ~> 准备阶段:进程间通信的概念
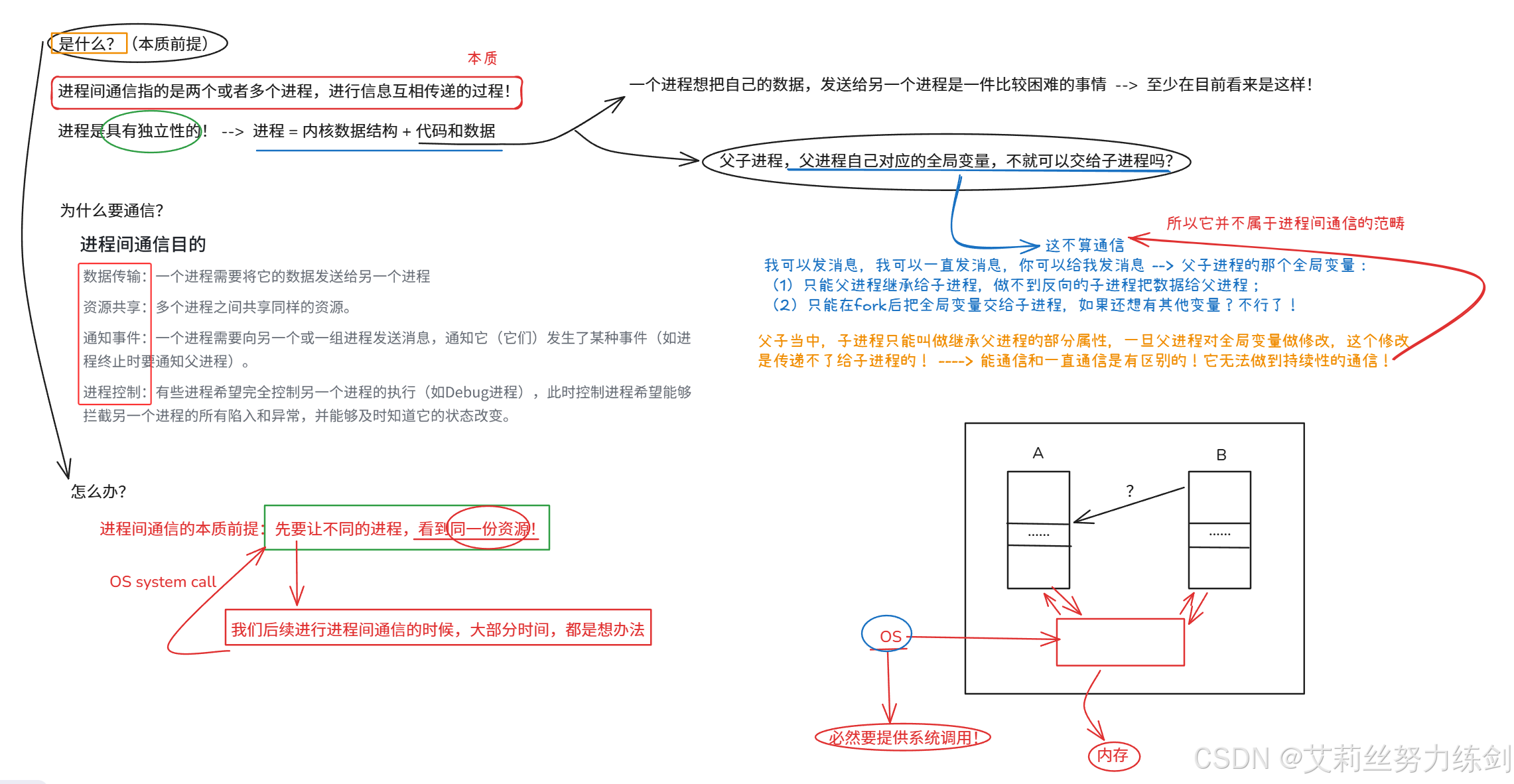
1.1 是什么(本质前提)
进程间通信是什么?进程间通信 指的就是两个或者多个进程,进行信息相互传递的过程!
我们知道:
-
进程是具有独立性的!
-
进程 = 内核数据结构 + 代码和数据
一个进程想把自己的数据,发送给另一个进程,至少在目前是一件比较困难的事情!
那父进程的全局变量,子进程可以看到不算嘛?不算进程间通信------
-
只能父进程~>子进程不是相互的(信息传递)
-
不能持续,后续更改了,子进程也就看不到了!

一个进程挂掉不会影响另外的进程,就算是父子进程也一样!
1.2 为什么
为什么要进行进程间通信,实际上就是要回答进程间通信的目的!
-
数据传输:一个进程需要将它的数据发送给另一个进程。
-
资源共享:多个进程之间共享同样的资源。
-
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
-
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。

1.3 怎么办
进程间通信的本质前提:先让不同的进程,看到同一份资源!
- 我们后续进行进程间通信的时候,大部分时候,都是想办法看到同一份资源!
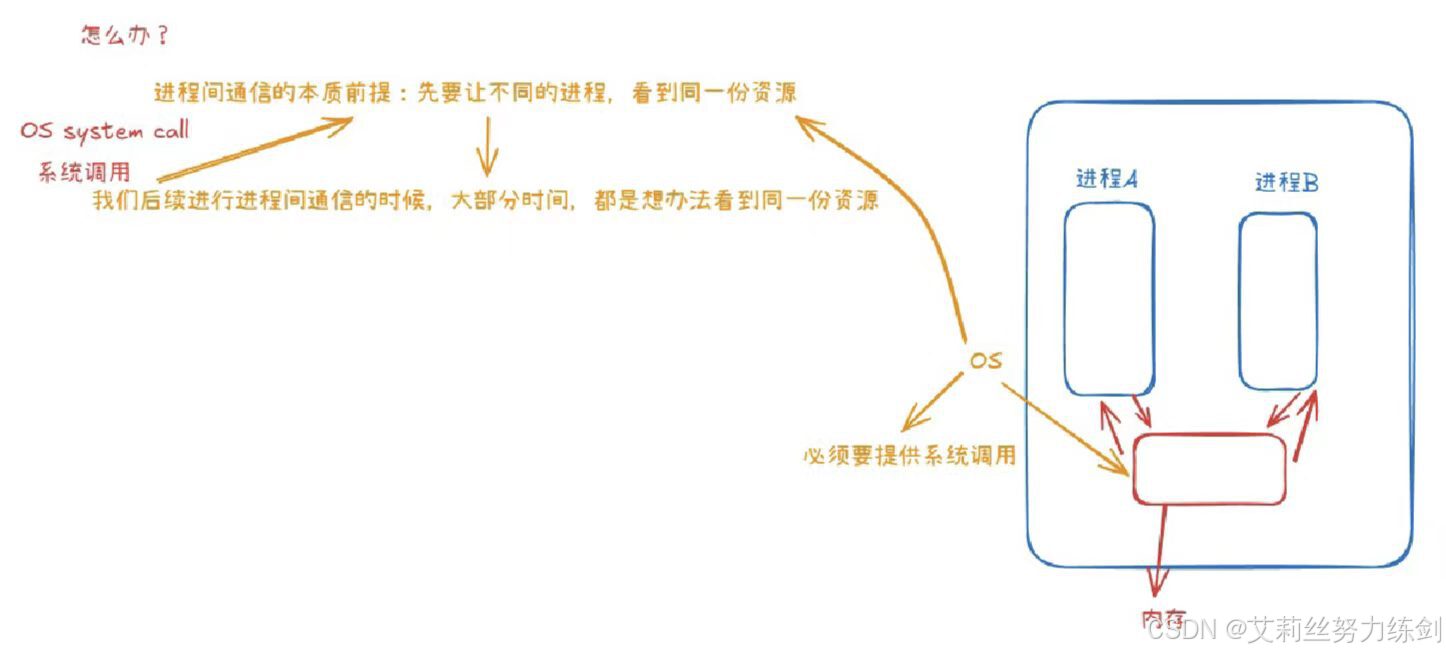
要让不同的进程看到同一份资源,OS必然要提供系统调用!
1.4 思维导图
2 ~> 进程间通信
2.1 进程间通信的定制标准:System V
相对于网络的标准来说,系统的标准就没那么严格了。
在我们的日常生活当中,其实也是有很多标准的,这些标准也不是一开始就可以决定的,有一个发展的过程。

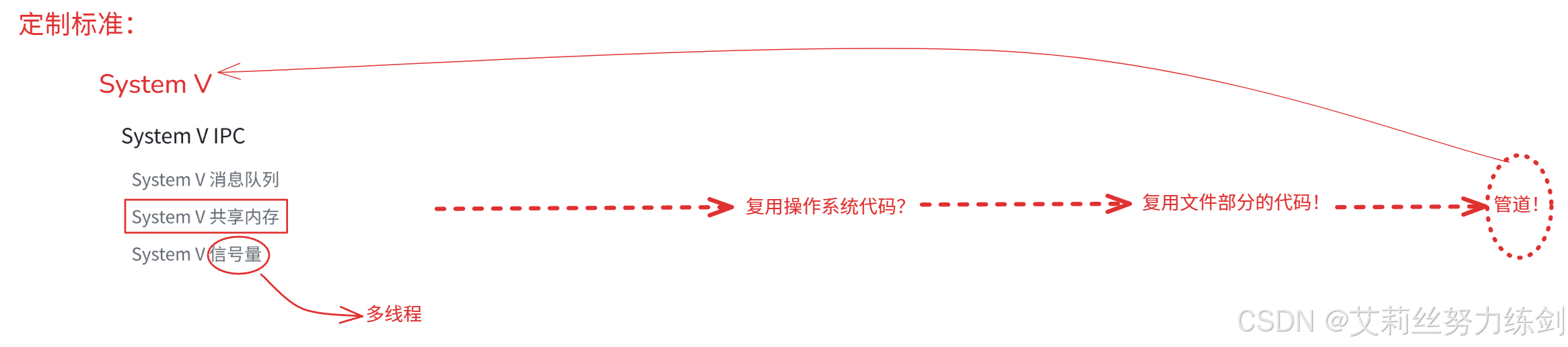
2.2 进程间通信的发展

3 ~> 管道的特点和情况总结
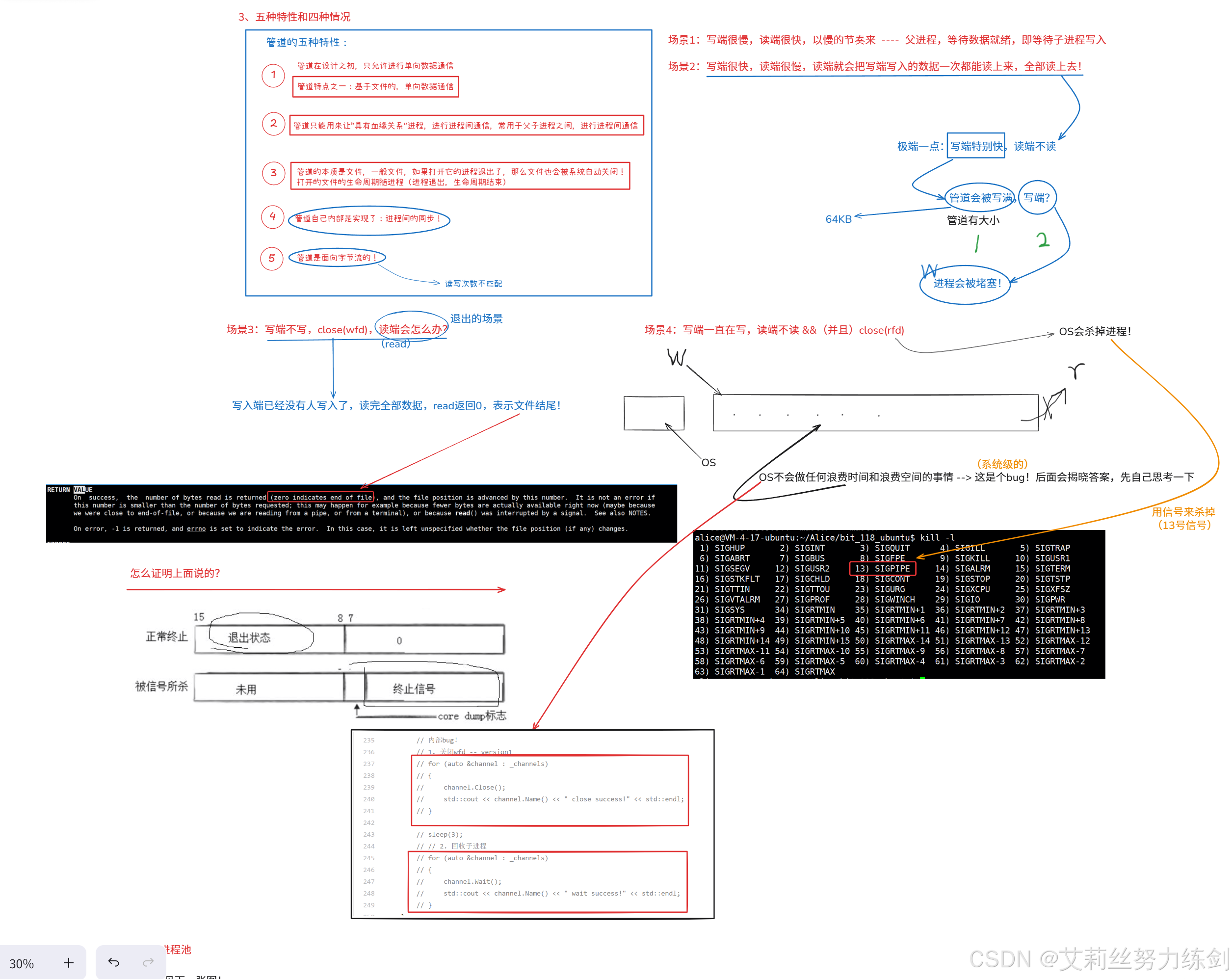
3.1 五种特点
我们总结一下管道的五大特点:

-
1、管道在设计之初,只允许进行单项数据通信。因此,管道特点之一:基于文件的,单向数据通信。
-
2、管道只能用来让"具有血缘关系"进程,进行进程间通信,常用于父子进程之间,进行进程间通信。
-
3、管道的本质是文件,一般文件,如果打开它的进程退出了,那么文件也会被系统自动关闭!打开的文件的生命周期随进程(进程退出,生命周期结束)。
-
4、管道是自己内部实现了:进程间的同步。
-
5、管道是面向字节流的! ~~> 读写次数不匹配。

3.2 四种情况
-
场景1:写端很慢,读端很快,以慢的节奏来 ---- 父进程,等待数据就绪,即等待子进程写入
-
场景2:写端很快,读端很慢,读端就会把写端写入的数据一次都能读上来,全部读上去!
-
场景3:写端不写,
close(wfd),读端会怎么办? -
场景4:写端一直在写,读端不读
&&(并且)close(rfd)。
3.3 思维导图
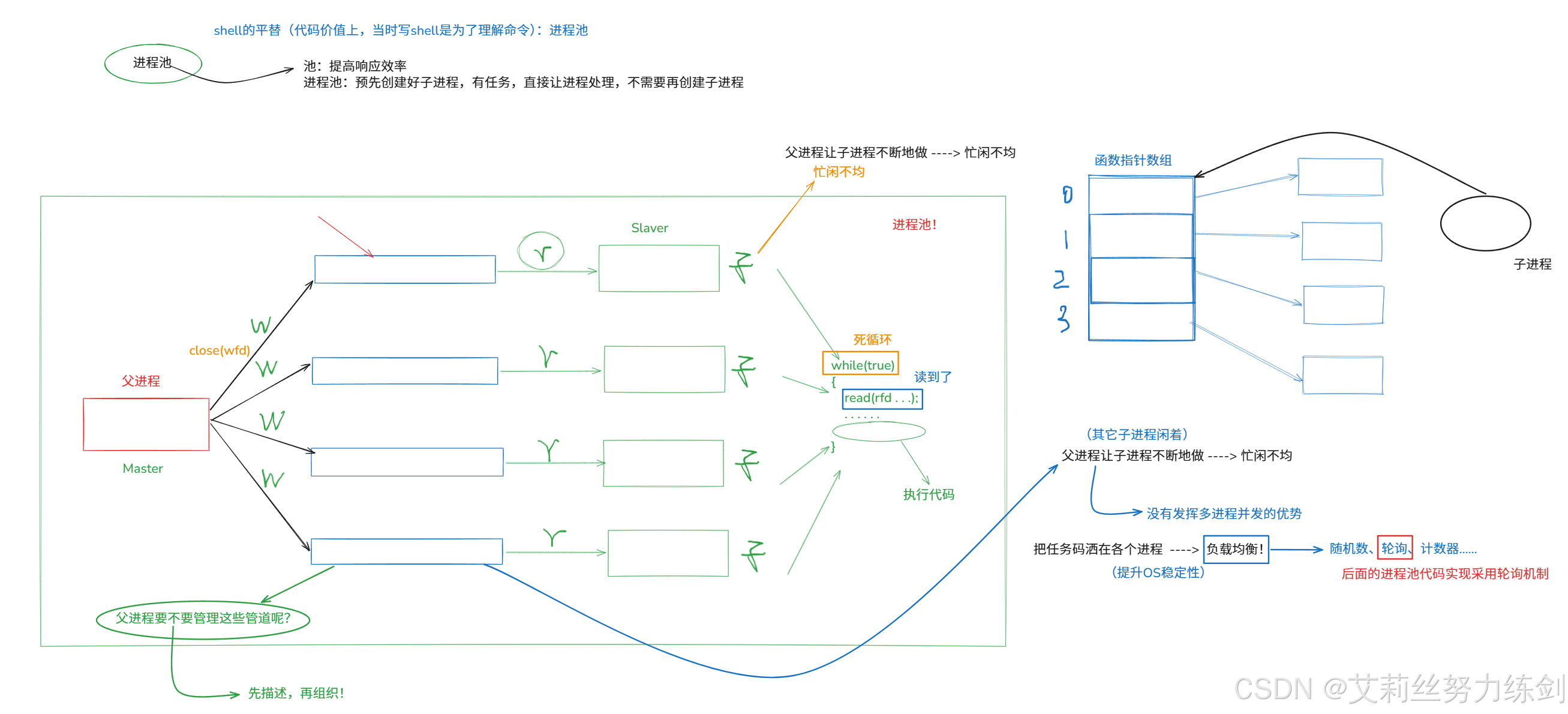
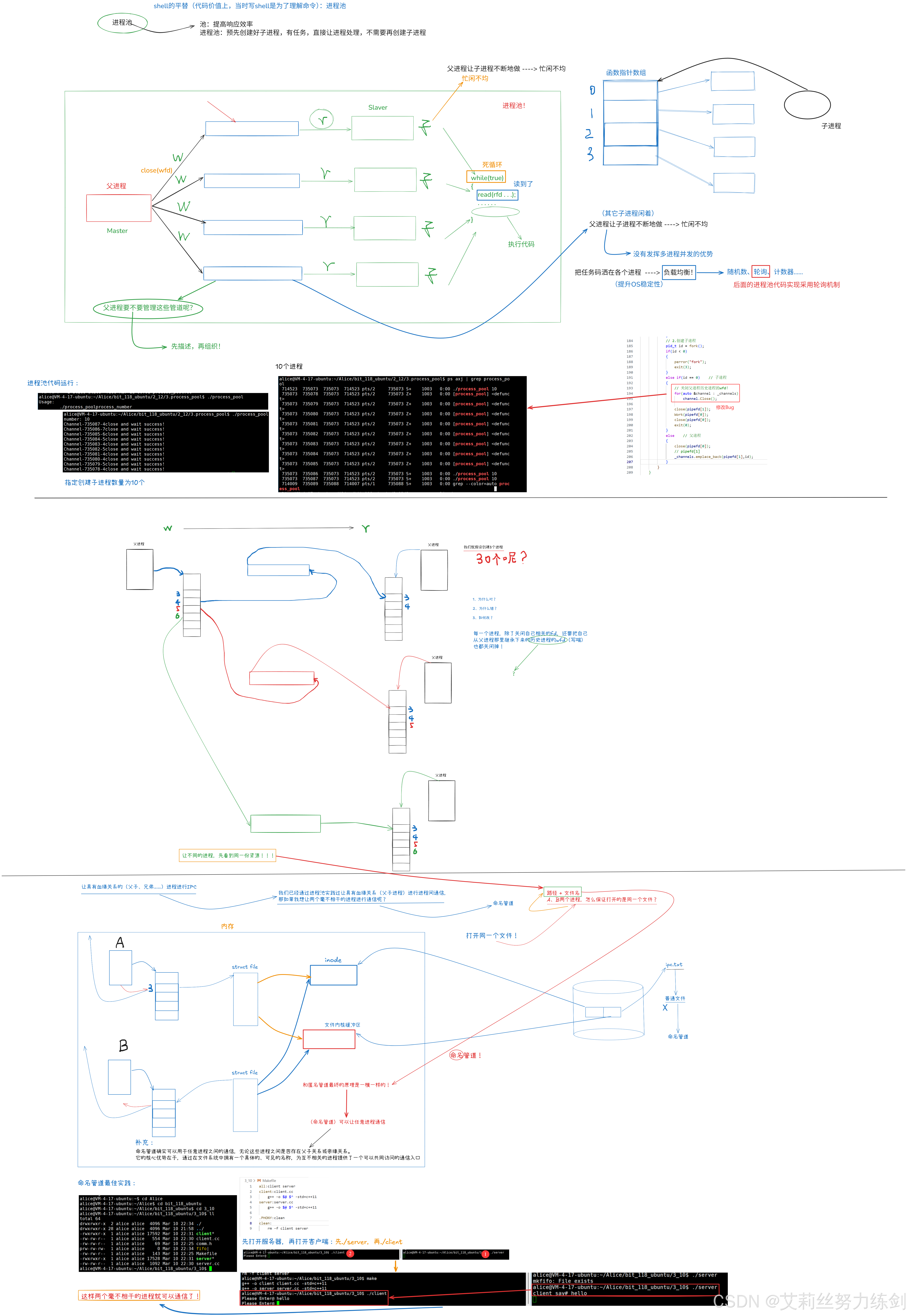
4 ~> 进程池
4.1 有一个小Bug
bash
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/2_12$ ll
total 24
drwxrwxr-x 6 alice alice 4096 Feb 13 15:35 ./
drwxrwxr-x 27 alice alice 4096 Feb 12 10:42 ../
drwxrwxr-x 2 alice alice 4096 Feb 12 12:56 1.test/
drwxrwxr-x 2 alice alice 4096 Feb 12 13:23 2.test/
drwxrwxr-x 2 alice alice 4096 Feb 13 21:10 3.process_pool/
drwxrwxr-x 2 alice alice 4096 Feb 13 15:35 4.my_process_pool/
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/2_12$ cd 3.process_pool
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/2_12/3.process_pool$ make
g++ -o process_pool process_pool.cc -std=c++14
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/2_12/3.process_pool$ ll
total 100
drwxrwxr-x 2 alice alice 4096 Mar 10 17:43 ./
drwxrwxr-x 6 alice alice 4096 Feb 13 15:35 ../
-rw-rw-r-- 1 alice alice 95 Feb 13 20:52 Makefile
-rwxrwxr-x 1 alice alice 80936 Mar 10 17:43 process_pool*
-rw-rw-r-- 1 alice alice 7258 Feb 14 00:26 process_pool.cc
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/2_12/3.process_pool$ ./process_pool
Usage:
./process_poolprocess_number
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/2_12/3.process_pool$ 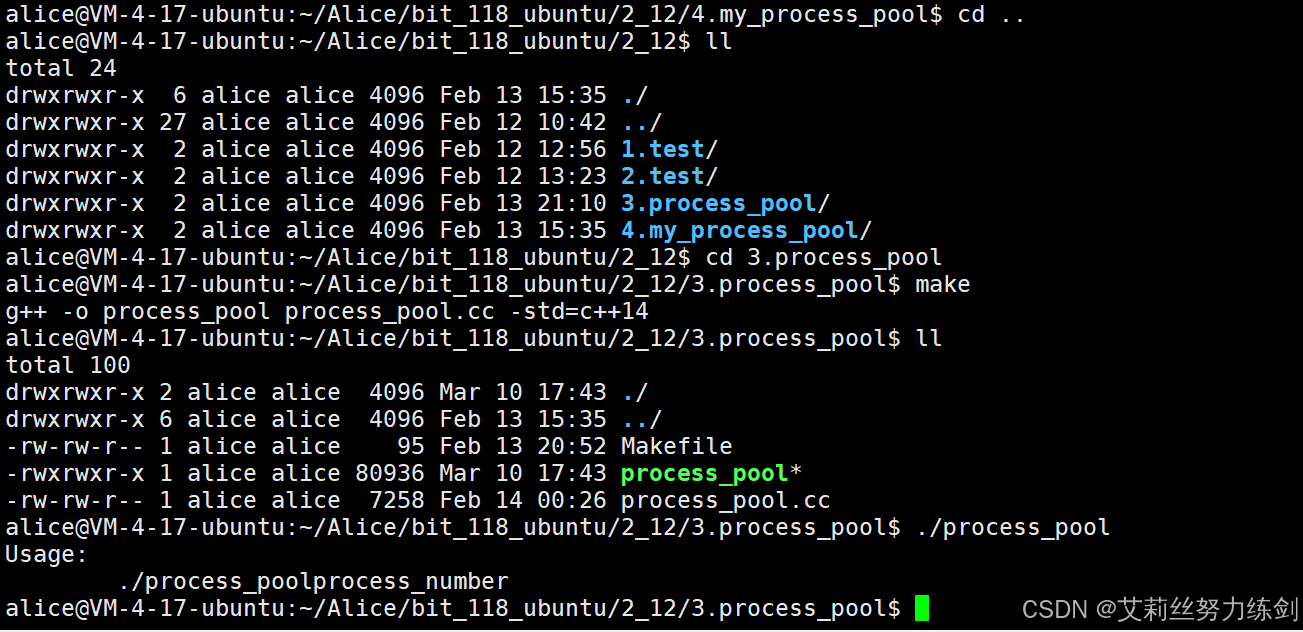
链接VS Code:
我们怎么体现进程间通信的协同?

下面这个函数是子进程的入口函数------
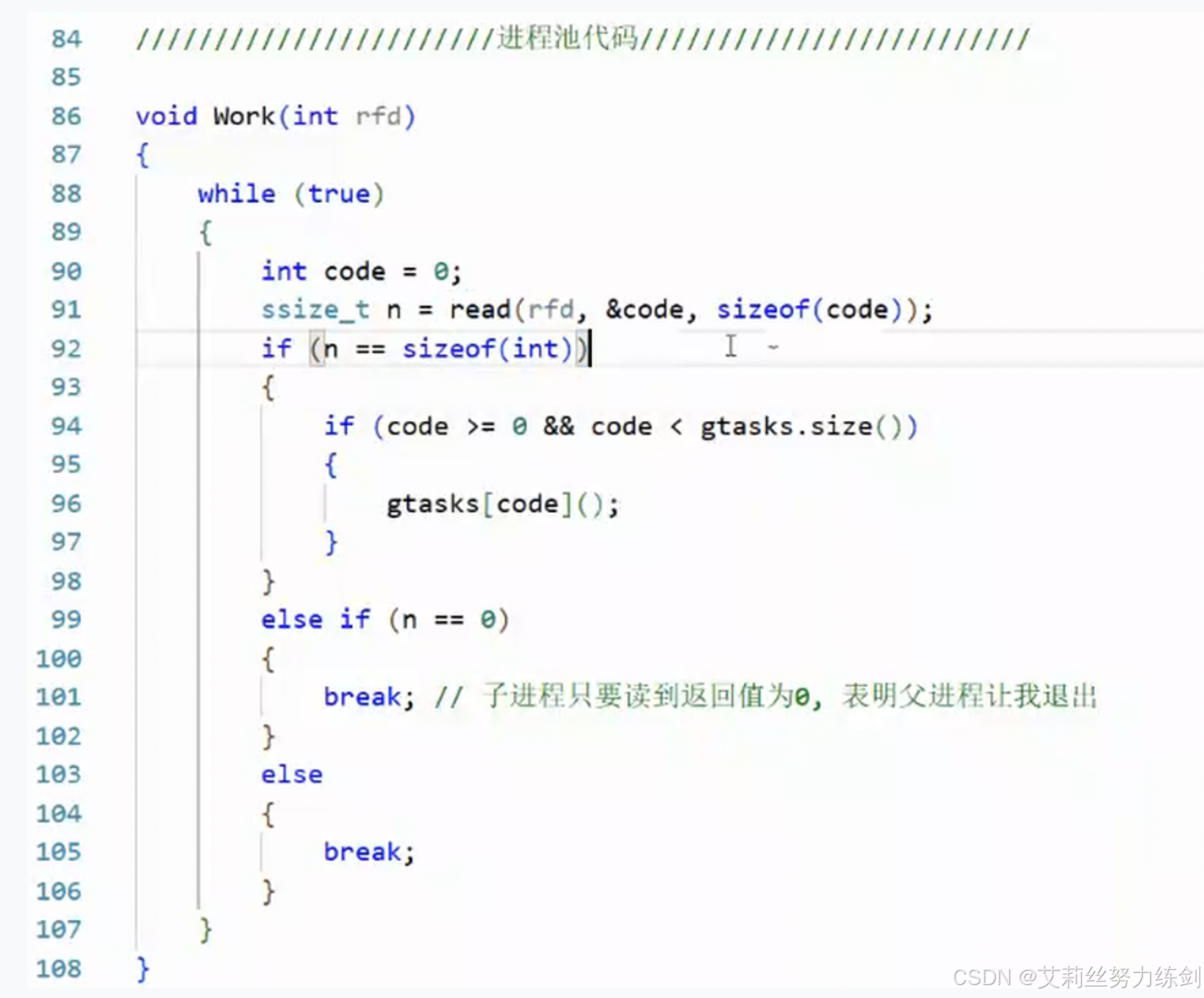
任务是什么?我们以任务码的形式体现------

由此我们形成一张任务表。
至此,有一个任务清单,一个数组,数组下标就是任务。
通道轮询式的被遍历了------

用Close()关闭写端文件描述符,用Wait()等待子进程、回收僵尸进程------
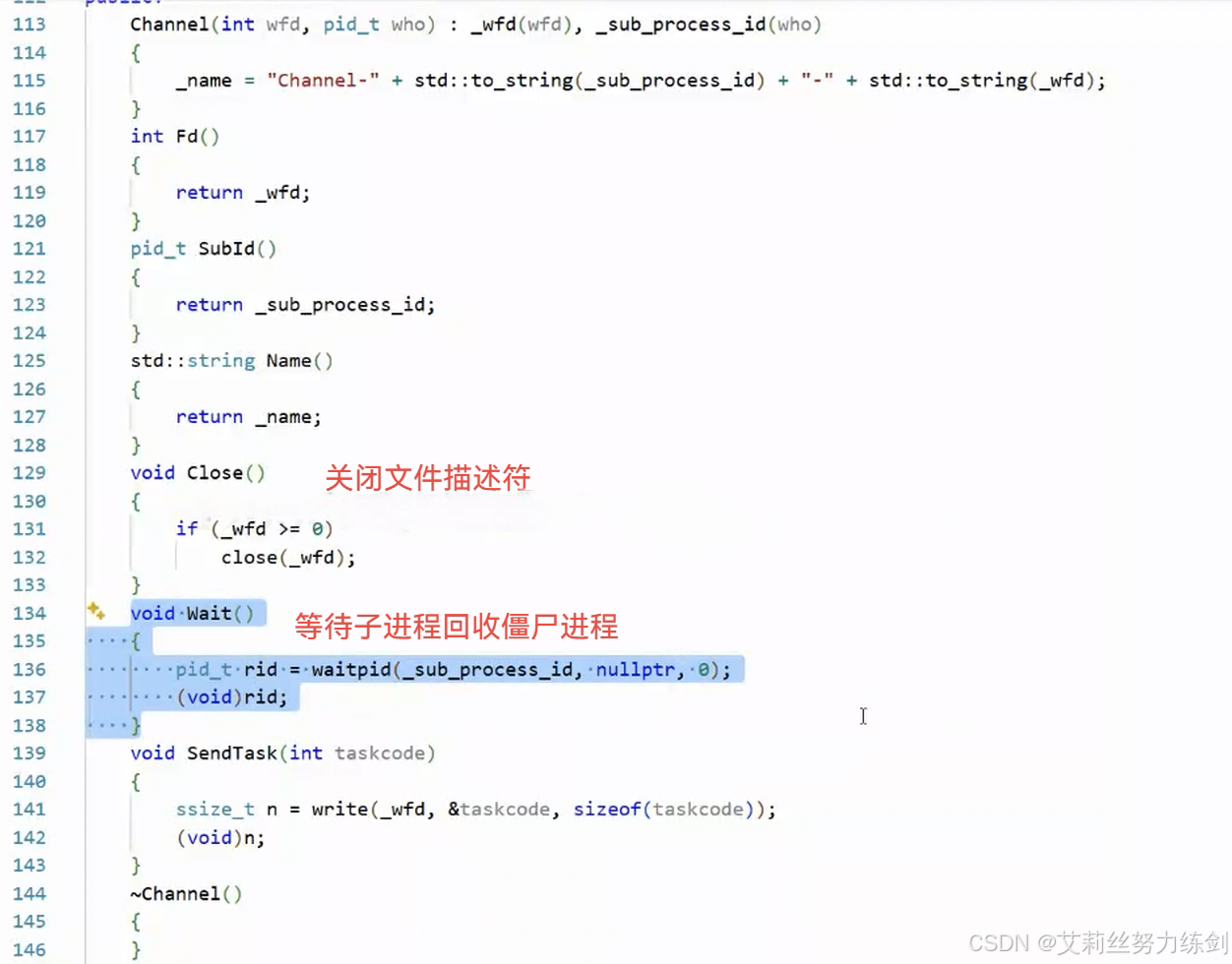
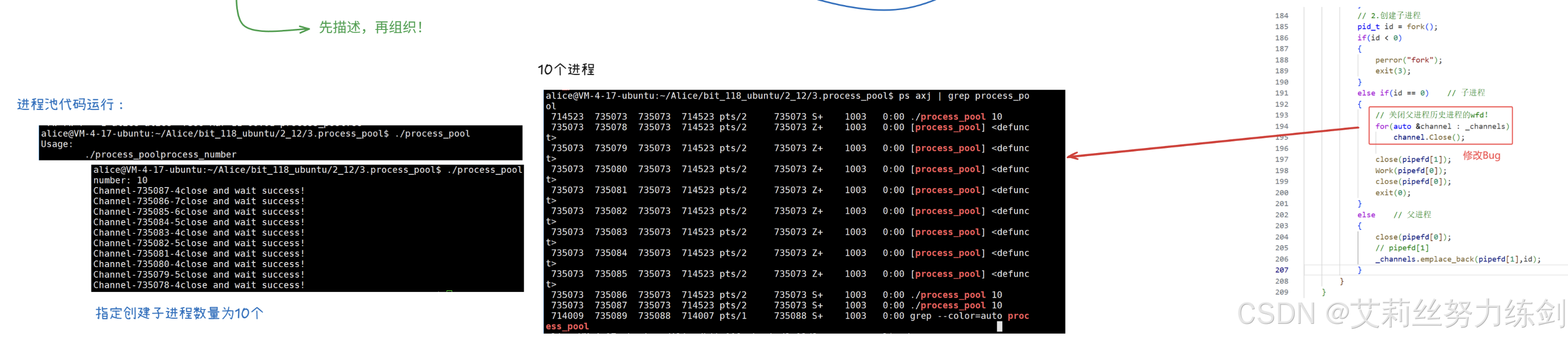
修改一下代码,运行一下,我们发现这里有一个Bug!
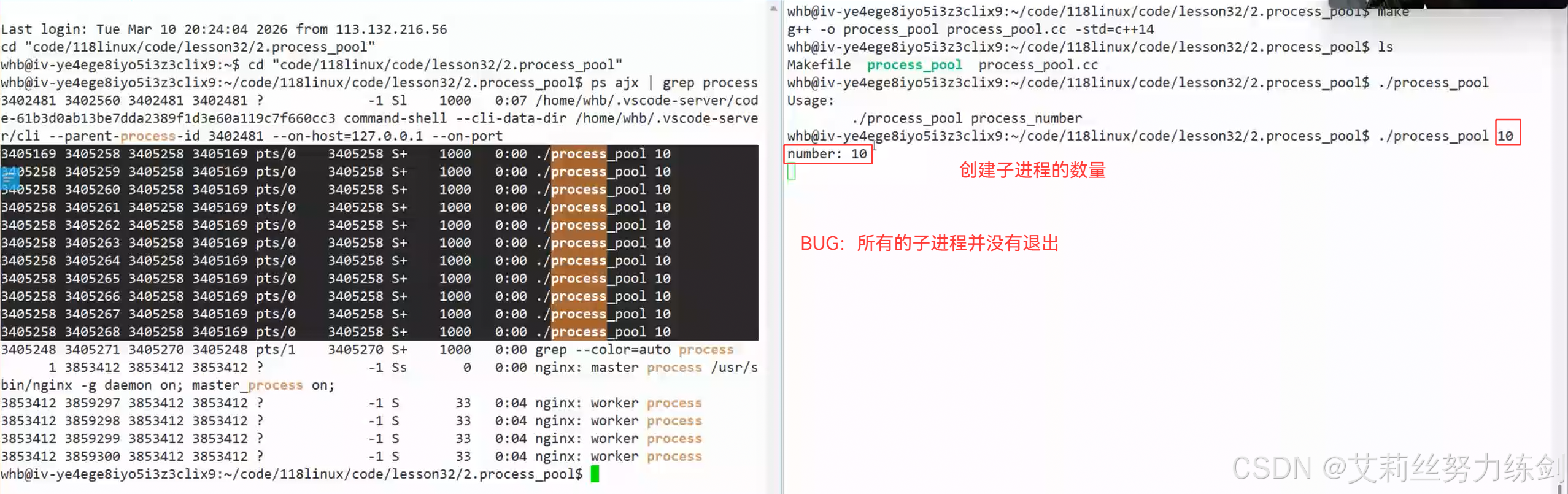
我们只退出了一个子进程,并没有退出所有的子进程(这里有10个),我们查看一下之前写的代码,发现问题就处在这里------
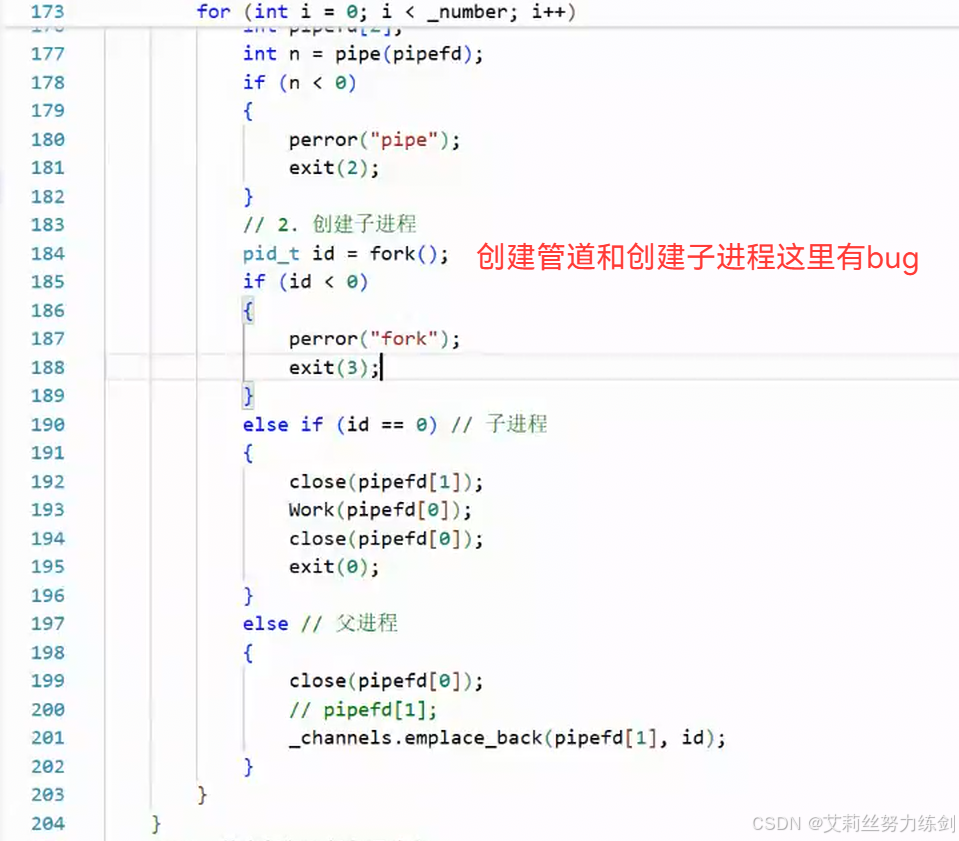
我们只要加一段代码就行------

再运行一下,通道被关闭成功,子进程全部回收------
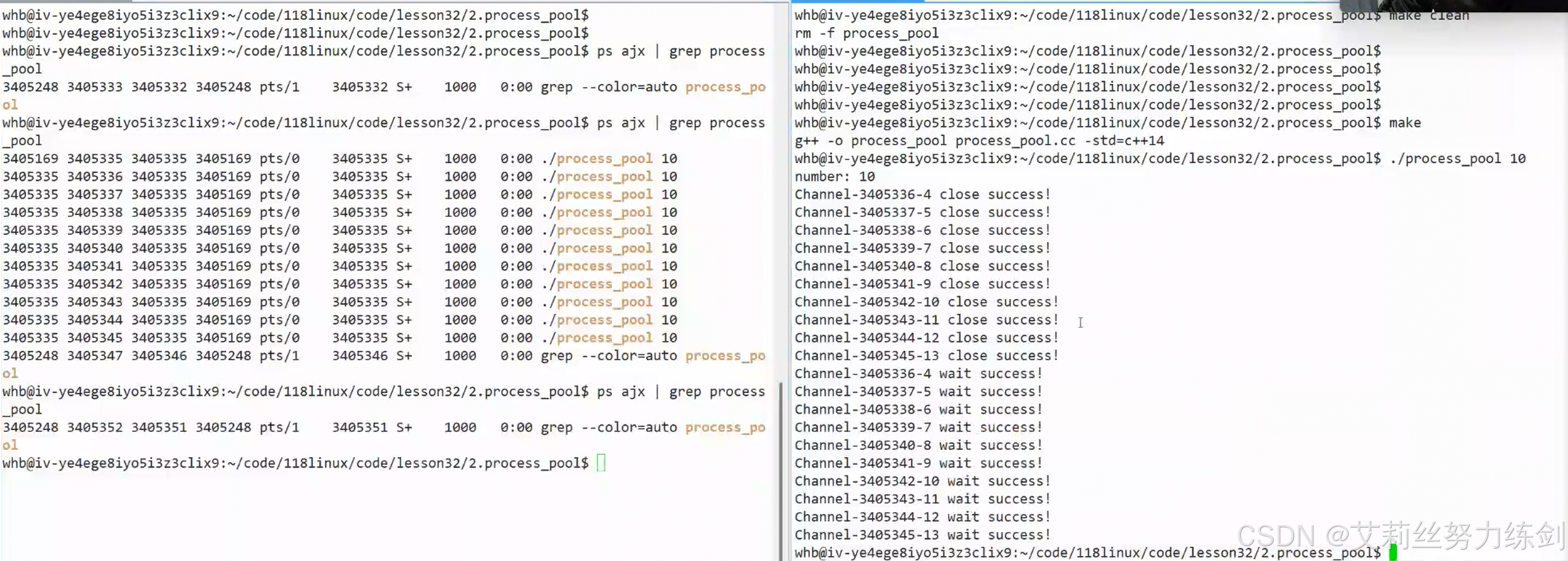
4.2 进程池:以创建10个子进程为例
5 ~> 命名管道
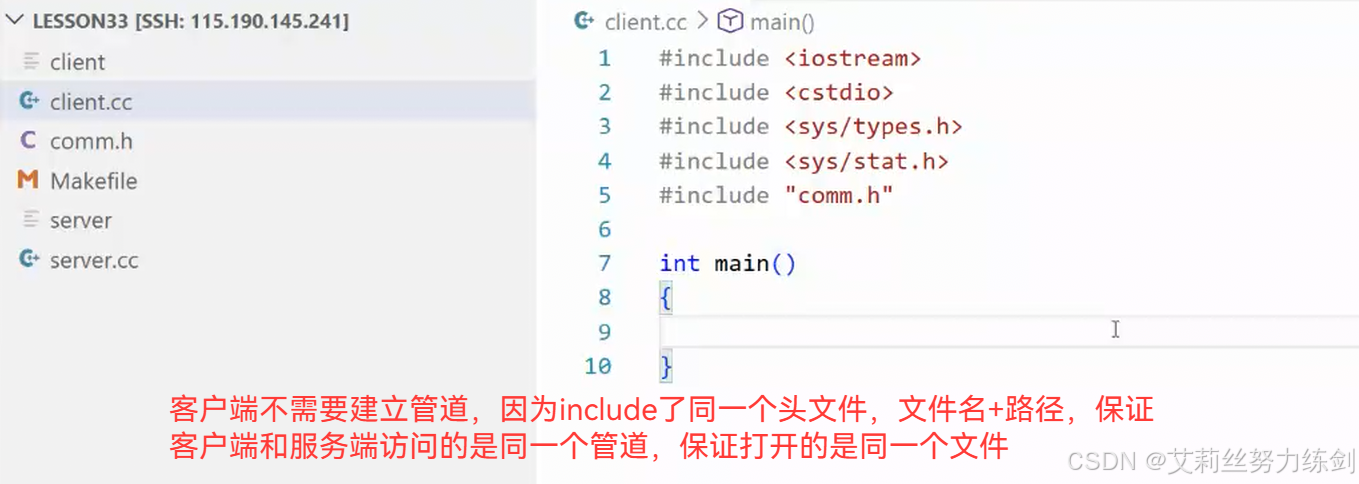
5.1 客户端不需要建立管道
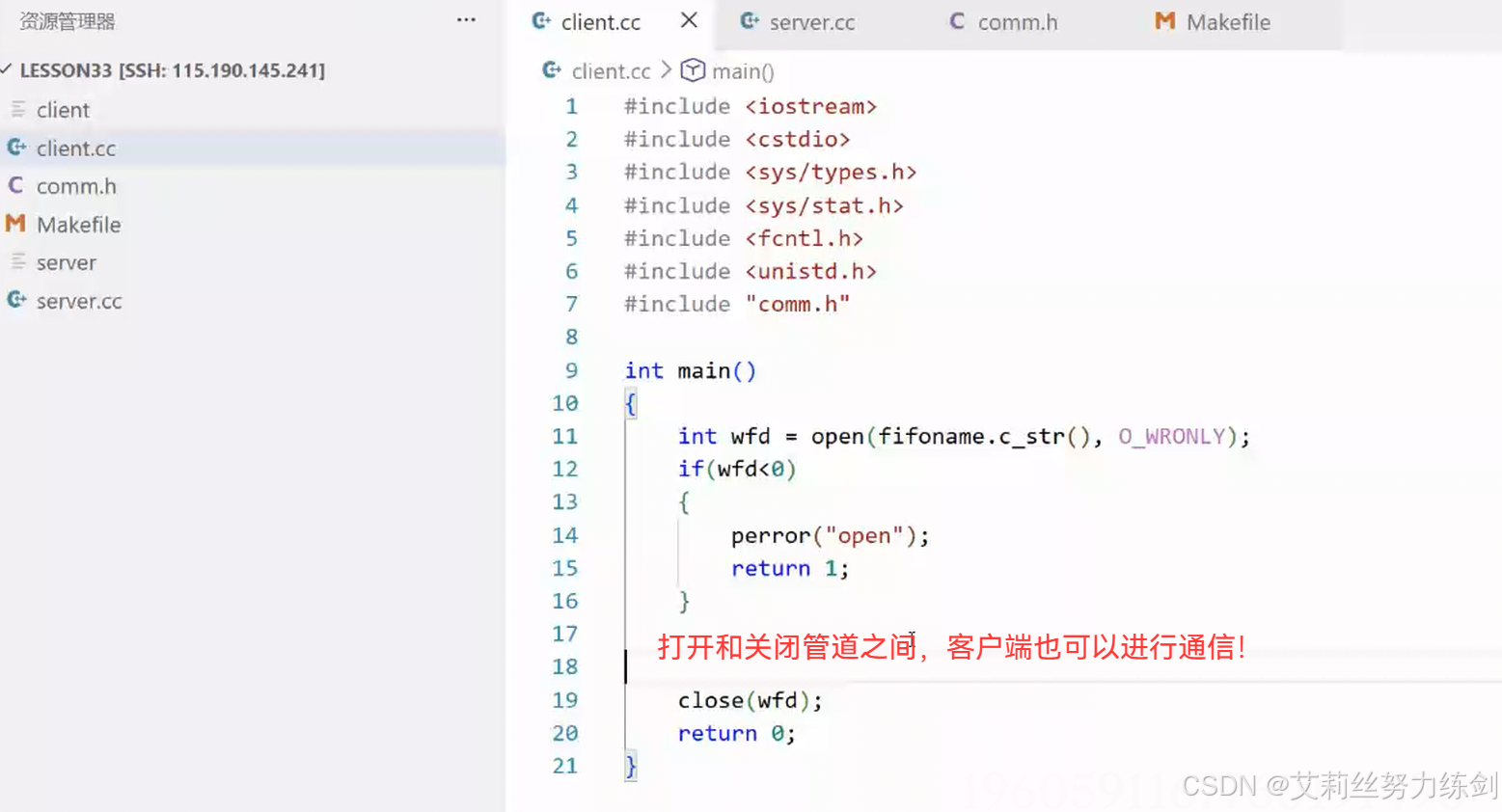
5.2 打开和关闭管道之间,客户端可以进行通信
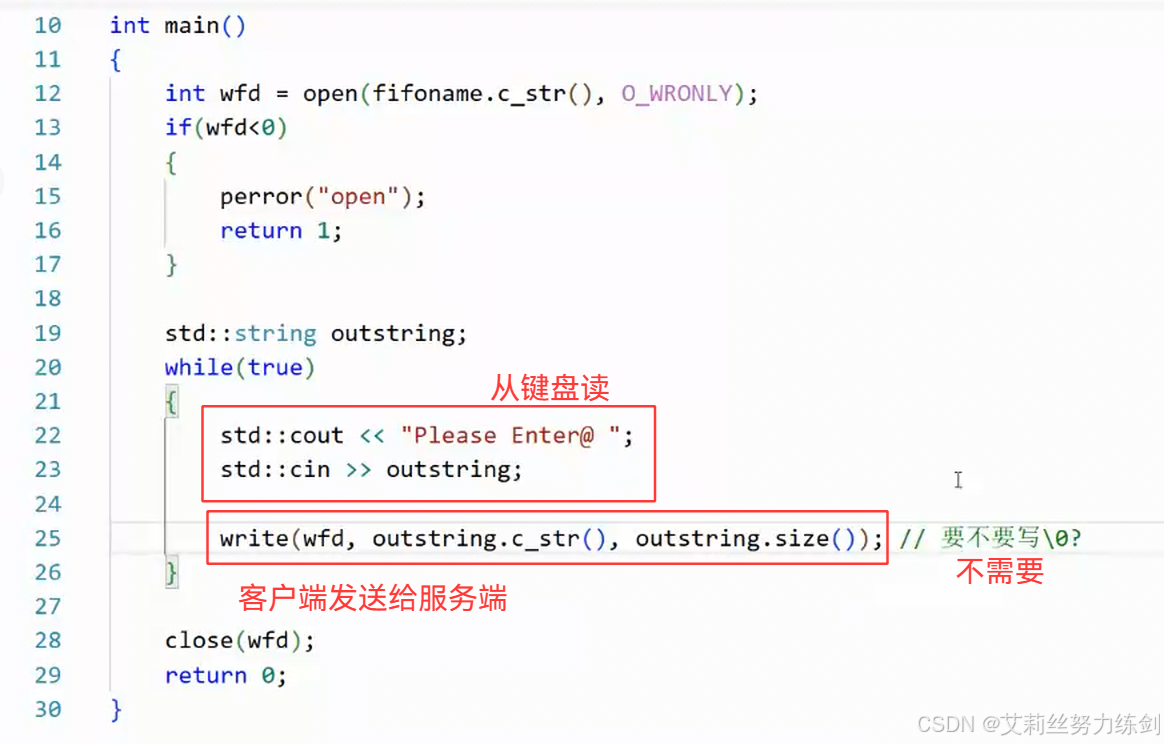
5.3 不需要写C语言的\0
5.4 毫不相干的两个进程的父进程可能不一样
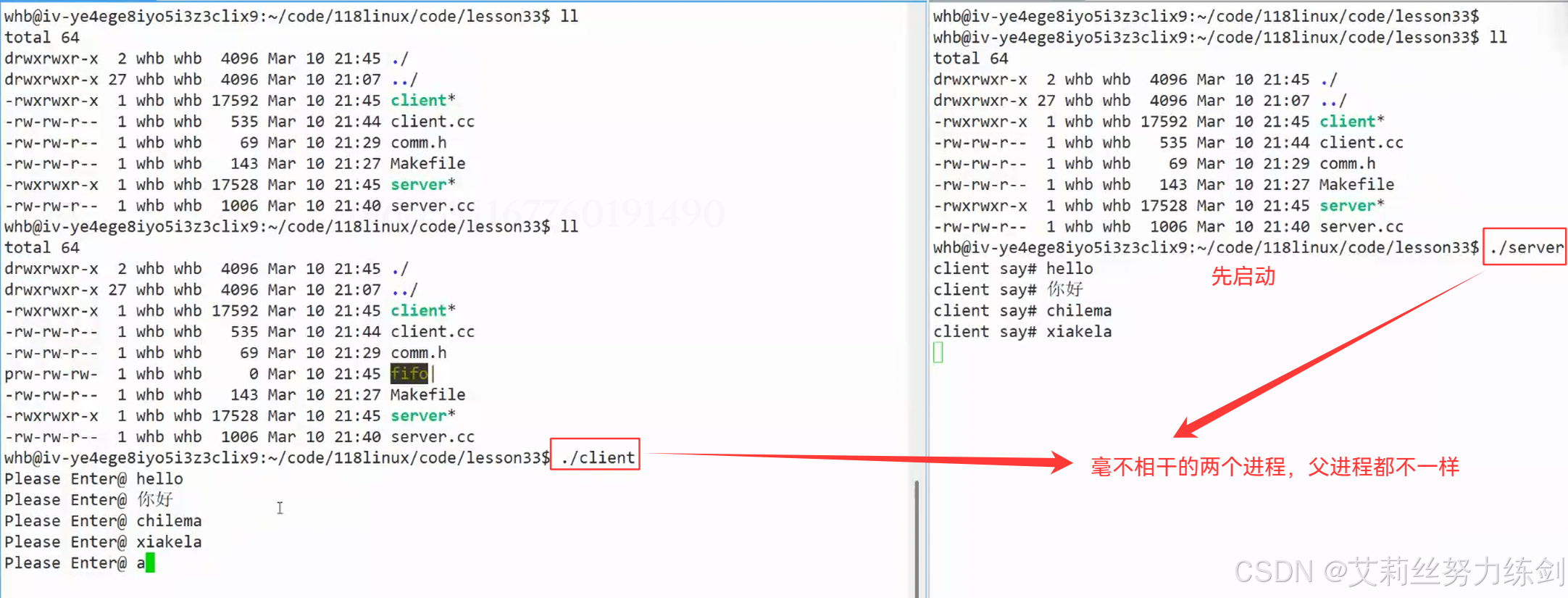
5.5 目前完成的服务端和客户端代码
5.5.1 服务器端 server.cc
cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#define FIFO_NAME "fifo"
int main() {
// 创建 FIFO(如果已存在则忽略错误)
if (mkfifo(FIFO_NAME, 0666) == -1) {
perror("mkfifo");
// 如果文件已存在,可以继续,但最好确认是 FIFO
}
printf("Server waiting for client...\n");
int fd = open(FIFO_NAME, O_RDONLY);
if (fd == -1) {
perror("open");
exit(1);
}
printf("Client connected.\n");
char buf[1024];
ssize_t n;
while ((n = read(fd, buf, sizeof(buf) - 1)) > 0) {
buf[n] = '\0';
printf("client say# %s", buf); // 假设消息自带换行,否则可加换行
fflush(stdout);
}
if (n == -1) perror("read");
close(fd);
unlink(FIFO_NAME); // 可选:删除 FIFO
return 0;
}5.5.2 客户端 client.cc
cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#define FIFO_NAME "fifo"
int main() {
printf("Please Enter@");
fflush(stdout); // 确保提示立即显示
char msg[1024];
if (fgets(msg, sizeof(msg), stdin) == NULL) {
perror("fgets");
exit(1);
}
// 以只写方式打开 FIFO(会阻塞直到有读者)
int fd = open(FIFO_NAME, O_WRONLY);
if (fd == -1) {
perror("open");
exit(1);
}
write(fd, msg, strlen(msg));
close(fd);
return 0;
}5.5.3 Makefile得这样写
bash
all:client server
client:client.cc
g++ -o $@ $^ -std=c++11
server:server.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f client server5.5.4 运行:服务端~>客户端
像这样一来就可以了------

先打开./server,再打开./client------

也就是说先打开服务器 ,再打开客户端。
这样就可以完成毫不相干的进程之间 的单向通信了!

5.6 最终呈现的服务端和客户端代码
5.6.1 服务器端 server.cc
cpp
#include <iostream>
#include <cstdio> // 混编
#include <string>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
#include "comm.h"
int main()
{
std::cout << "open begin" << std::endl;
// int wfd = open(fifoname.c_str(),O_WRONLY);
int wfd = open("fifo", O_WRONLY);
if(wfd < 0)
{
perror("open");
return 1;
}
std::cout << "open end" << std::endl;
std::string outstring;
while(true)
{
std::cout << "Please Enter@ ";
std::cin >> outstring;
write(wfd,outstring.c_str(),outstring.size()); // 要不要写\0?不需要写!
}
close(wfd);
return 0;
}5.6.2 客户端 client.cc
cpp
#include <iostream>
#include <cstdio> // 混编
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
#include "comm.h"
int main()
{
// 1.创建管道文件
umask(0); // 关闭系统的权限,用我们指定的权限
int n = mkfifo(fifoname.c_str(),0666); // 系统调用mkfifo
if(n < 0)
{
if(errno != EEXIST)
{
perror("mkfifo");
return 1;
}
// 文件已存在,忽略错误,继续执行
}
// 2.打开管道文件
std::cout << "open begin" << std::endl;
int rfd = open(fifoname.c_str(),O_RDONLY);
if(rfd < 0)
{
perror("open");
return 2;
}
std::cout << "open end" << std::endl;
char inbuffer[1024];
// 3、进行通信
while(true)
{
ssize_t n = read(rfd,inbuffer,sizeof(inbuffer) - 1);
if(n > 0)
{
inbuffer[n] = 0;
std::cout << "client say# " << inbuffer << std::endl;
}
else if(n == 0)
{
// 写端关闭了
break;
}
else{
perror("read");
break;
}
}
// 4.关闭
close(rfd);
// 5.删除管道文件
unlink(fifoname.c_str());
return 0;
}5.6.3 运行:服务端~>客户端

5.7 命名管道的本质
命名管道的本质其实就是一种符号,让不同的进程找到同一个文件,只需要存在一个inode就可以,不用刷新到磁盘。有缓冲区就行,做刷新时看到是以p为开头的就不会刷新,等另外的进程来读取。
5.8 命名管道打开的细节问题
在使用命名管道的时候,不用担心第一次读的时候读不到东西,在首次打开的时候读端会在open阻塞。在open的时候就已经进行了让读写同步。 server端变成写端也是一样的,都要保持这个同步的。
5.9 命名管道思维导图
如下图所示------
5.9.1 匿名管道(进程池)+(开了个头)命名管道
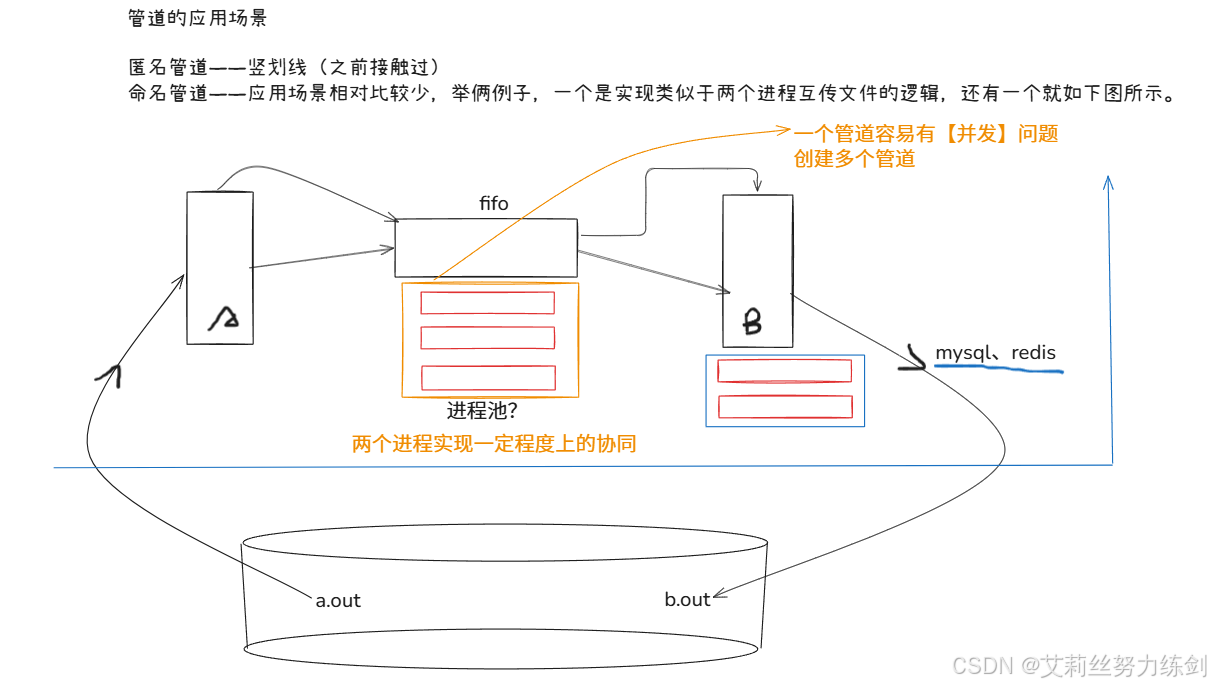
5.10 管道的应用场景
- 匿名管道------竖划线。
- 命名管道------应用场景相对比较少,举俩例子,一个是实现类似于两个进程互传文件的逻辑,还有一个就如下图所示。

5.10.1 命名管道实现文件拷贝
我们也可以把这个例子换成跟网络和数据库关联,并且大家发现这个结构,有点像进程池的,命名管道也可以用来实现进程池。
实现类似于两个进程互传文件的逻辑------
5.10.2 定标准
技术上的问题解决了,下一个矛盾就是怎么让更多人用。
怎么解决这个问题呢,定标准!
朴素点的理解:函数是什么,返回值是什么,结构化的字段怎么定义等等。管你是什么系统,都遵守这个标准。用户不管用的啥都只用学一套就行了。
- 定标准------先不着急设计进程间通信的技术,先定标准
社会层面上,只需要提交一份标准,用户也只需要学习一套通信标准即可。
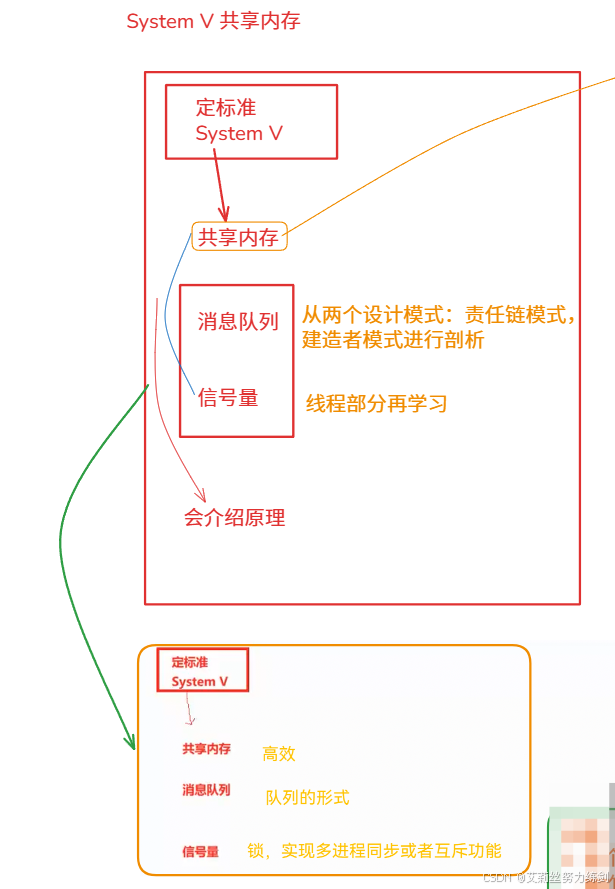
5.10.3 System V 标准
- System V 标准。
- 共享内存:用来进行大块数据通信
- 消息队列:
- 信号量:可以用来实现锁,多进程互斥和同步等
这三种通信技术上在使用层面已经过时了!
但是共享内存还是需要讲一下的!信号量(编码工作)会交待原理。
消息队列就不讲了------标准在很多地方很类似。
但是现在比较过时,现在也包装的比较好了。现在都可以网络通了,我们就讲讲共享内存就行;信号量只讲原理,线程还会再讲讲;消息队列基本就不讲了。
6 ~> 共享内存
共享内存有一个非常重要的东西!我们后面细嗦!
6.1 原理
6.1.1 原理思维导图
- 虚拟地址对物理内存进行读写
- 页表和虚拟地址进行映射
让不同的进程看到同一份资源------动态库就是这样共享的!
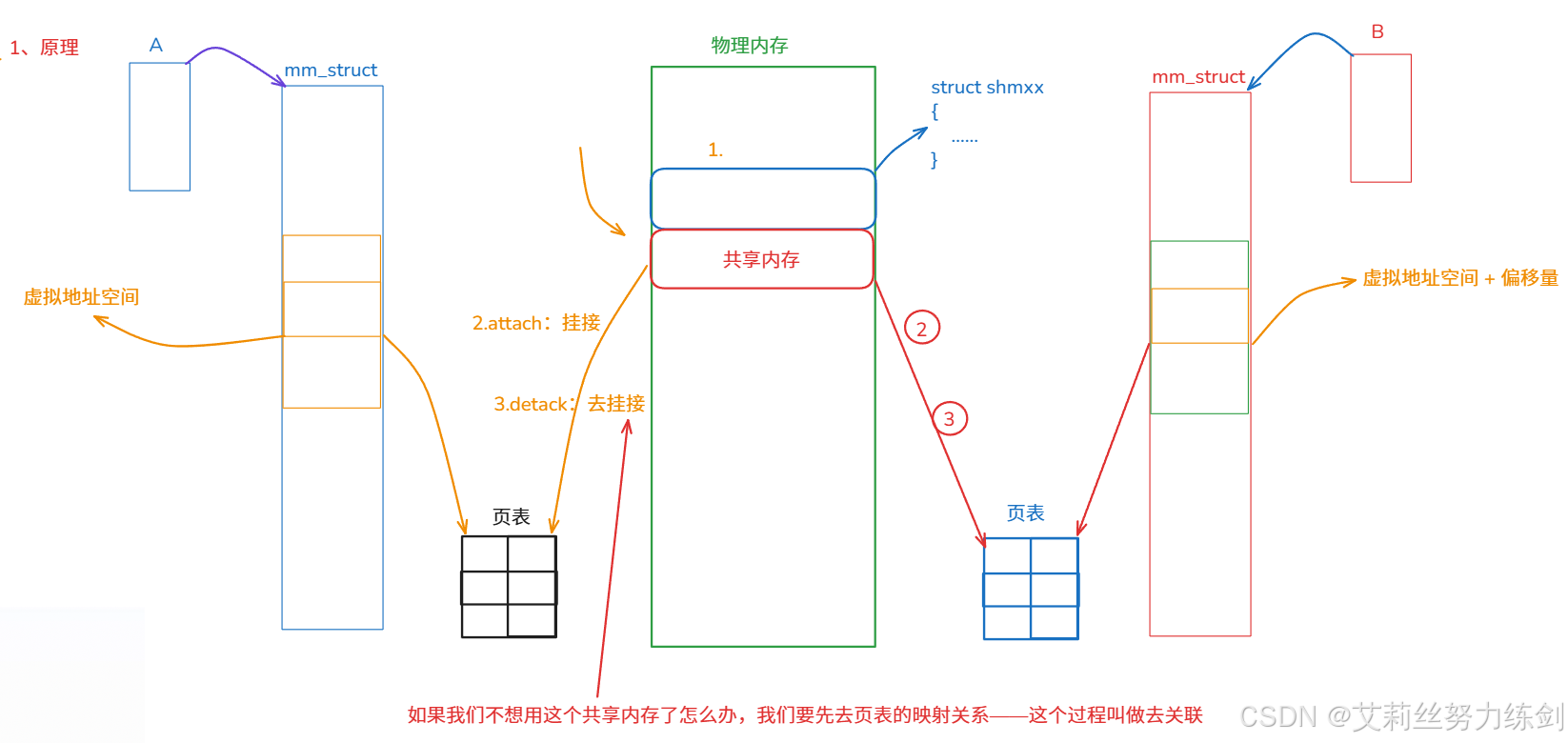
6.1.2 原理理论
我们在物理内存中如果也能开辟一块内存空间 整个物理内存的起始地址和大小我就知道了同时映射到进程A的共享区,得到一个内存块的起始虚拟地址,我们就可以直接通过虚拟地址对这块内存进行读写了所以进程B也可以啊,我也搞一块区域,建议共享内存和虚拟地址空间的映射,都得到了各自的虚拟地址,再加上偏移量就可以访问内存中的任何的区域。我们肯定能做到,动态库不就是共享区这样嘛。我们通过地址空间映射,让不同的进程看到了同一个内存块,这种技术就叫共享内存!
6.1.3 共享内存与进程地址空间布局
bash
argu,environ
栈
共享内存、内存映射和
共享库位于此处
为堆扩展保留
堆
未初始化数据(bss)
初始化数据
文本(程序代码)原图如下所示------
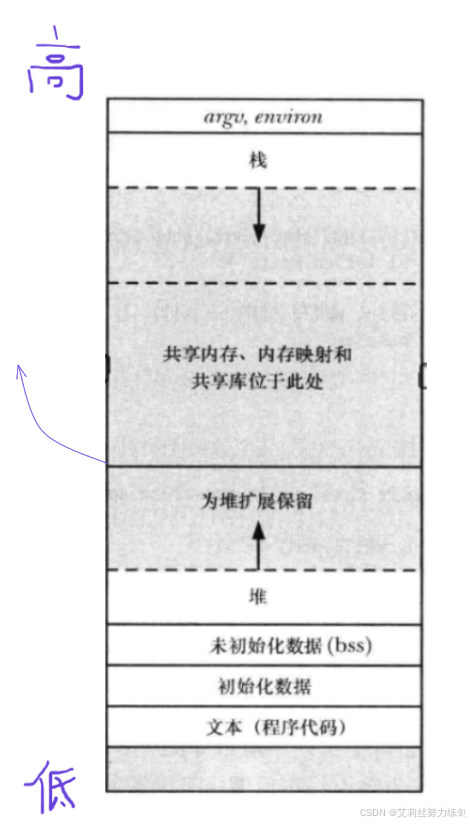
文本(程序代码):存放可执行代码,只读。
初始化数据:已初始化的全局变量和静态变量。
未初始化数据(bss):未初始化的全局变量和静态变量,在程序执行前会被清零。
堆:用于动态内存分配(如malloc),向高地址增长。
为堆扩展保留:堆和共享区之间的空闲区域,供堆向上增长。
共享内存、内存映射和共享库位于此处:即内存映射区,用于映射共享库、文件映射、匿名映射等,通常从高地址向低地址增长(或固定位置)。
栈:存放局部变量、函数调用信息,向低地址增长。
argu, environ:命令行参数和环境变量,位于栈的高地址顶部
堆和栈相对而生,动态库映射到共享区就可以被多个进程共享。
堆和栈相对生长(堆向上,栈向下),而动态库被映射到共享内存区,这样它们在物理内存中只需加载一份,多个进程的页表可以映射到同一物理页,从而节省内存并实现代码共享。
6.1.4 问题
1、整个过程是谁做的?
操作系统OS,那是谁让OS做的呢,操作系统必然会提供系统调用,我们程序员就可以调用系统调用------所以是用户让操作系统做的!
2、共享区这个东西用户可以直接访问嘛?用户可以不需要使用系统调用来读写共享内存(指针)
- 用户用指针就可以直接访问了!
共享区这个不属于内核空间,是属于用户空间的。所以我们用户随便拿个指针就可以直接访问了!意味着我们也可以不需要使用系统调用来读写shm(共享内存)。我们之前使用动态库也可以没系统调用。
- 总结: 创建和"删除"shm需要系统调用,使用shm不需要(类似malloc())。
我们创建管道的时候用了系统调用,使用也用了,这也是和共享内存的差别。用户空间最有代表的就是用户可以直接访问。
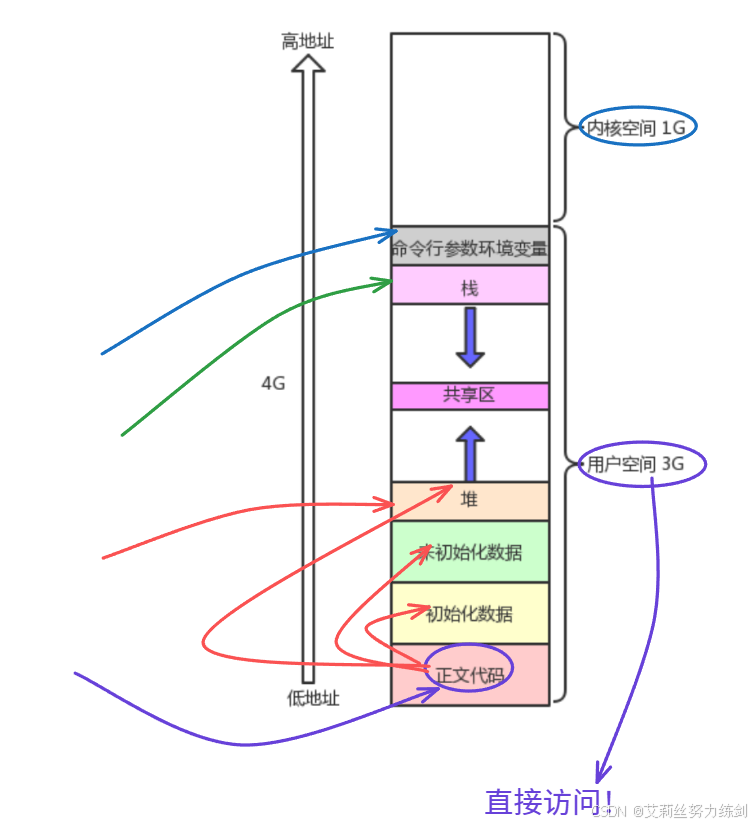
- 用户空间有3G,这些用户都可以直接访问!

访问库函数也是直接访问使用
我们访问库函数也是虚拟地址结合.GOT表就可以直接访问使用。
去关联
- 如果我们不想用这个共享内存了怎么办,我们要先去掉页表的映射关系,这个过程叫做去关联。
6.1.5 思路打开------突破点
需要通信时,不同的进程都想用共享内存通信啊!
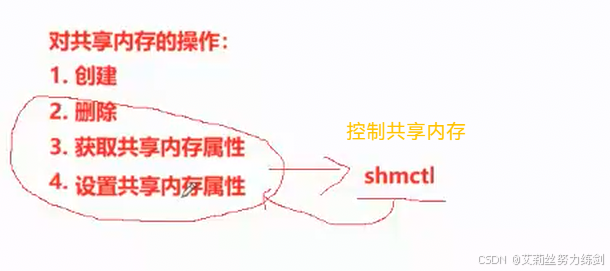
- 内存的存在是可以同时存在多份的
共享内存有不同状态的,删除,创建啥的,操作系统必然要管理共享内存,怎么管理呢,先描述再组织------老生常谈了。
一定会存在一种共享内存的结构体,描述共享内存的信息等等------

肯定有链接信息,我们后面有很多的共享内存结构体对象,就可以用链表啥的组织管理起来了,思路都很类似了,我们后面会介绍的(底层用的数组管理)。
-
不申请内存块都可以------虚拟地址空间的延迟申请。
-
底层用数组把结构体变量统一管理起来
-
在内核当中应该有一个管理共享内存的结构体。
我们谈到共享内存想到的首先不是一个内存块而是内核中有一个描述共享内存的结构体。
把对操作系统的管理转换成对数据结构的增删查改。
- 操作系统是数据结构和算法的集合------数据结构决定算法。
操作系统说到底就是一个数据结构和算法的结合,我们现阶段可以把操作系统想成一个大型数据结构的集合。
6.2 准备工作:写代码 + 原理
6.2.1 .hpp和header only
6.2.1.1 概念区分

6.2.2 使用.hpp的原因:写代码工作量小,文件数量少
- 为啥我们cpp要头源文件分离呢?
为了方便打包成库。
- .
hpp
我们就想写在一起就可以用.hpp,但是这种无法打包成库了。
编译型语言头源分离------方便把头文件打包成库------有历史原因。
.hpp也是源文件,只不过把头文件声明、源文件可以在一个文件里面写了。
.hpp头源混合------不能打包成库了。
联系闭源项目和开源项目。
开源软件 / 项目,把动静态库 + XXX打包给你。
header only:开源的方式,不头源分离了,减少文件量。
写代码工作量小,文件数量少,文件以后多起来可能会有20多个,如果头源分离的话就得有40多个了,很容易搞混。
header only。我们后面会很多时候选择这种做法,节省时间,文件更少点方便看。
只需要有一边负责创建并删除共享内存,另一边获取就可以了,不能两边都创建,乱套了无法进行IPC了。
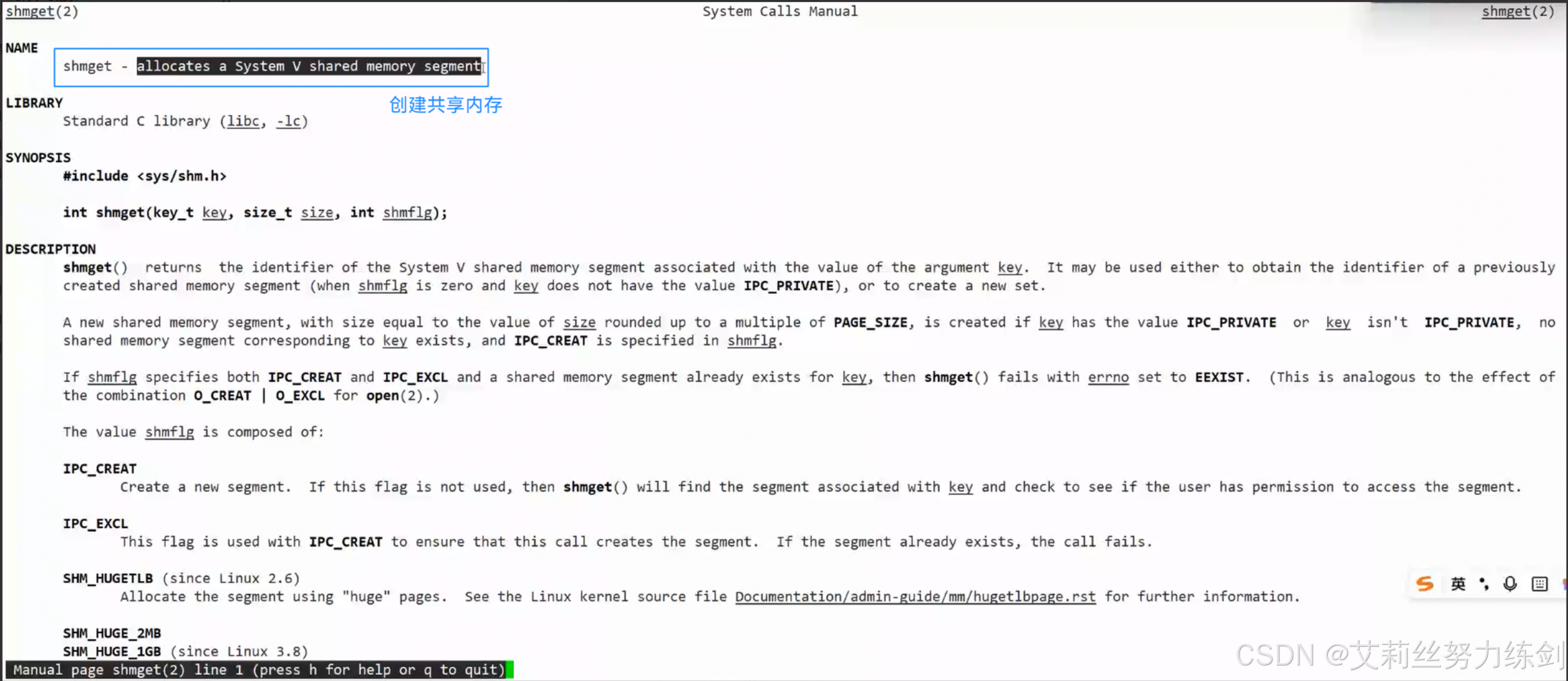
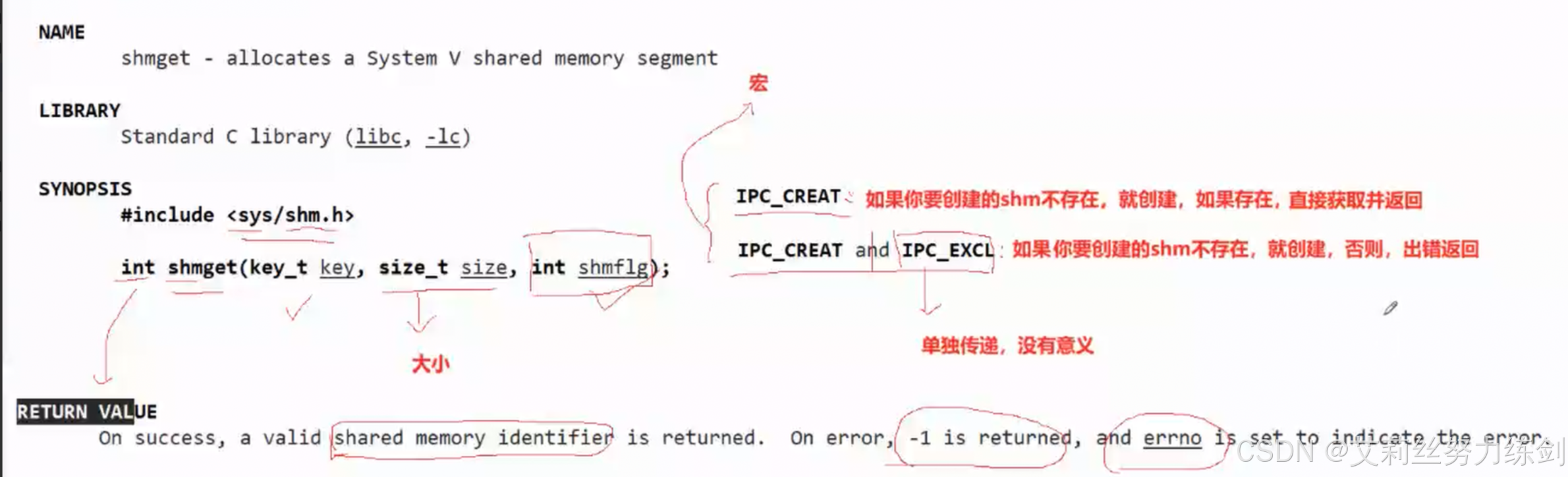
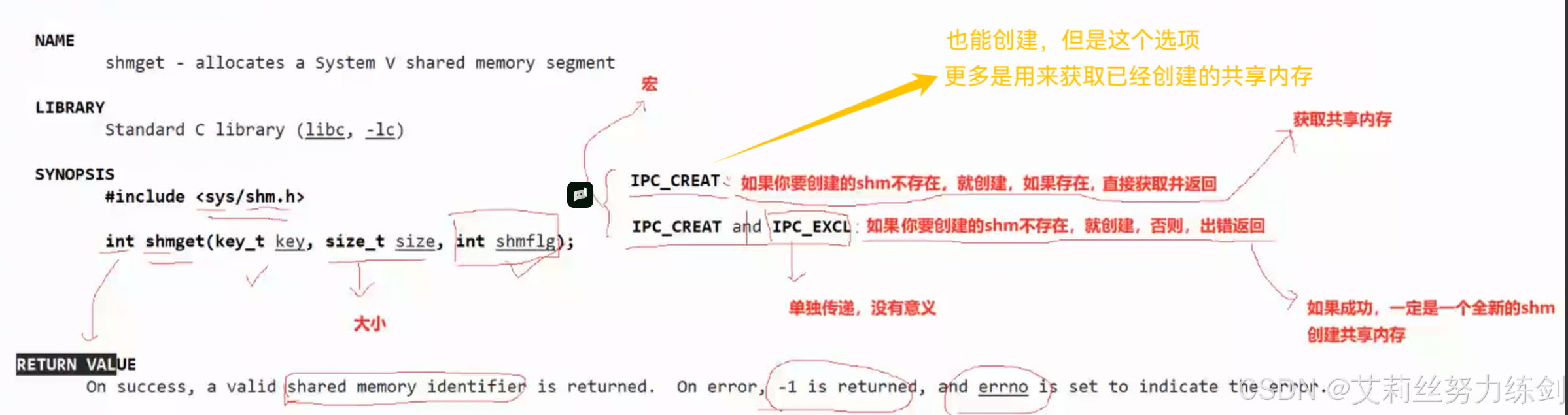
6.2.3 shmget
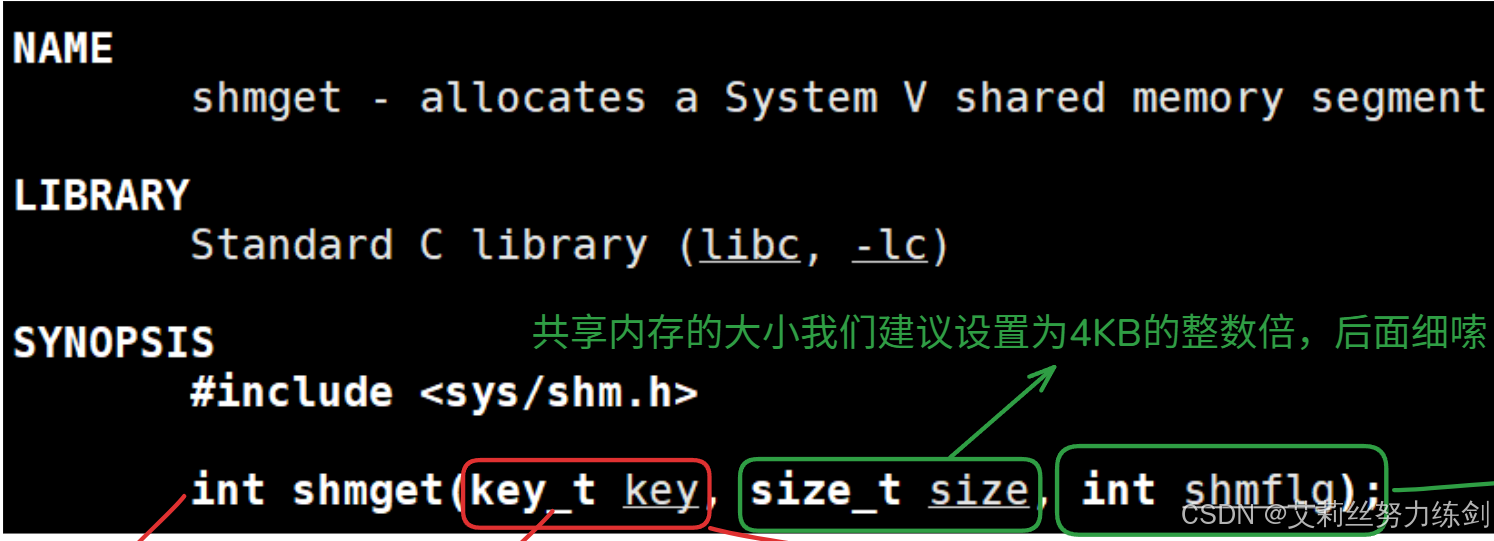
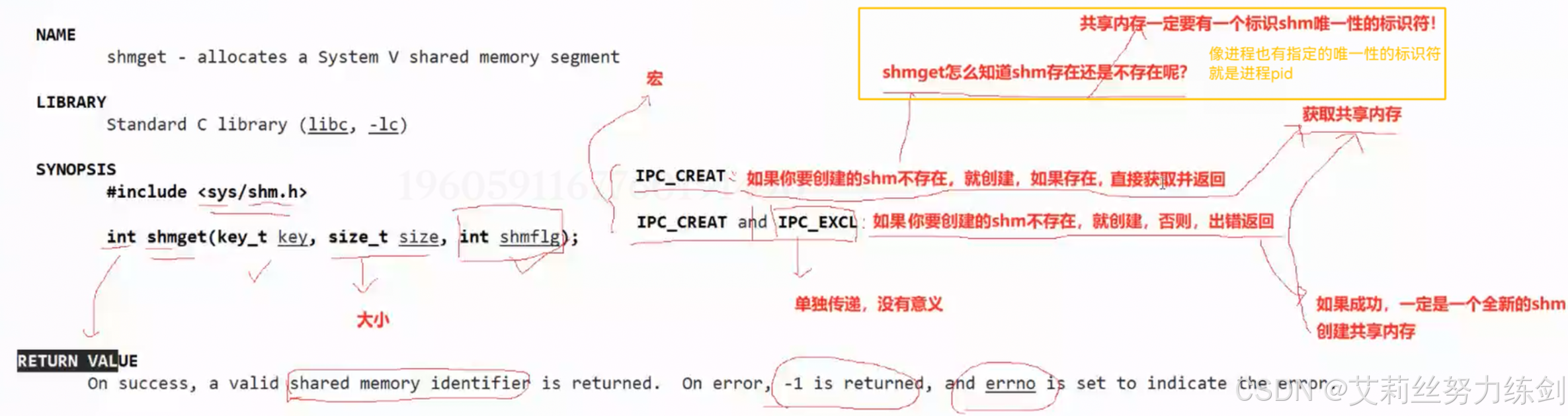
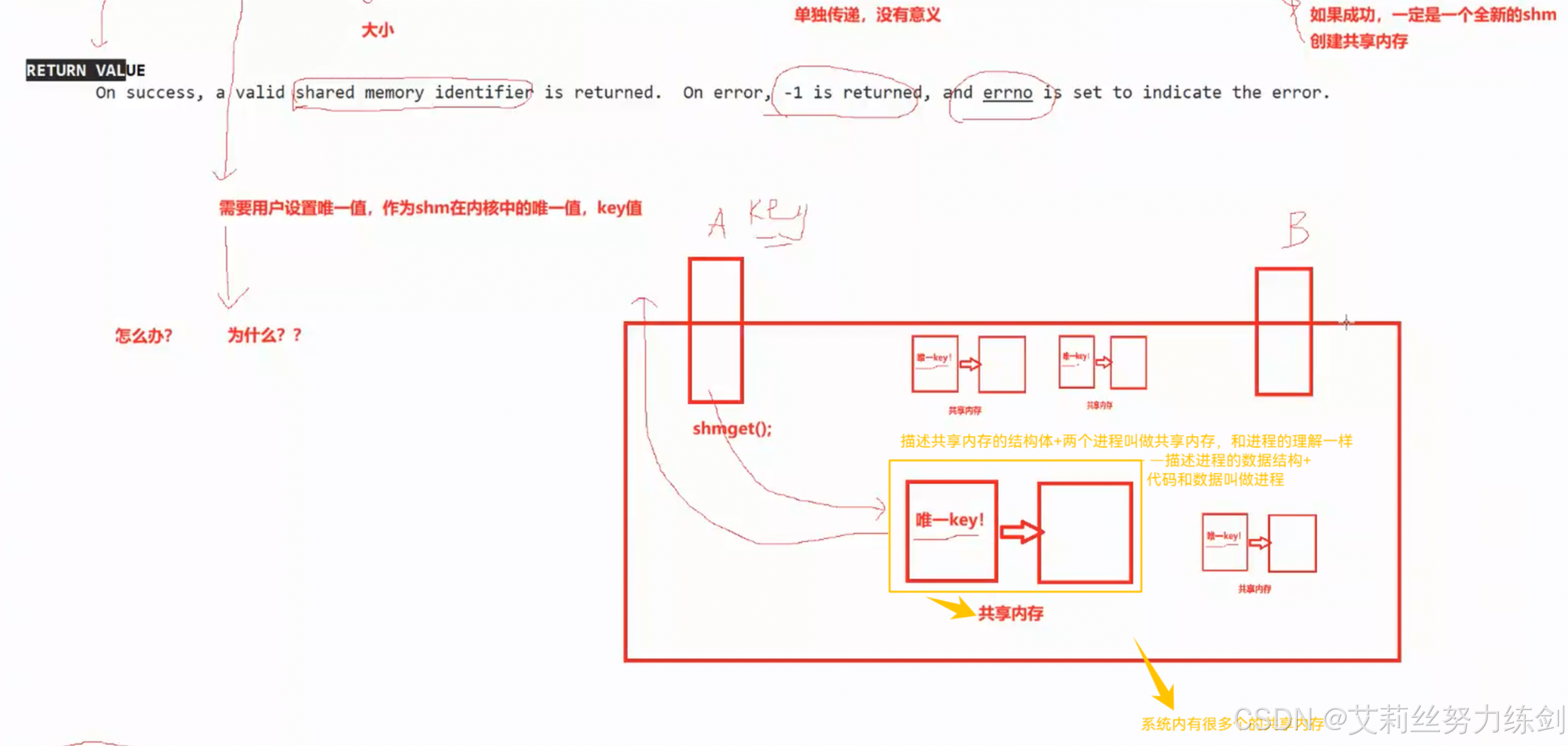
创建成功了就会返回一个共享内存的标识符,也可以叫句柄,但是跟文件描述符可没有关系联系。这也是这种技术会被边缘化的原因之一,要是能跟文件关联上多好
shmget怎么知道shm存在还是不存在呢?所以共享内存一定要有一个标识shm唯一性的标识符!在哪里?在它的结构体里一定有一个唯一标识符的。需要用户设置唯一值,作为shm在内核中的唯一值,我们叫做key值,这点有点违反我们的直觉

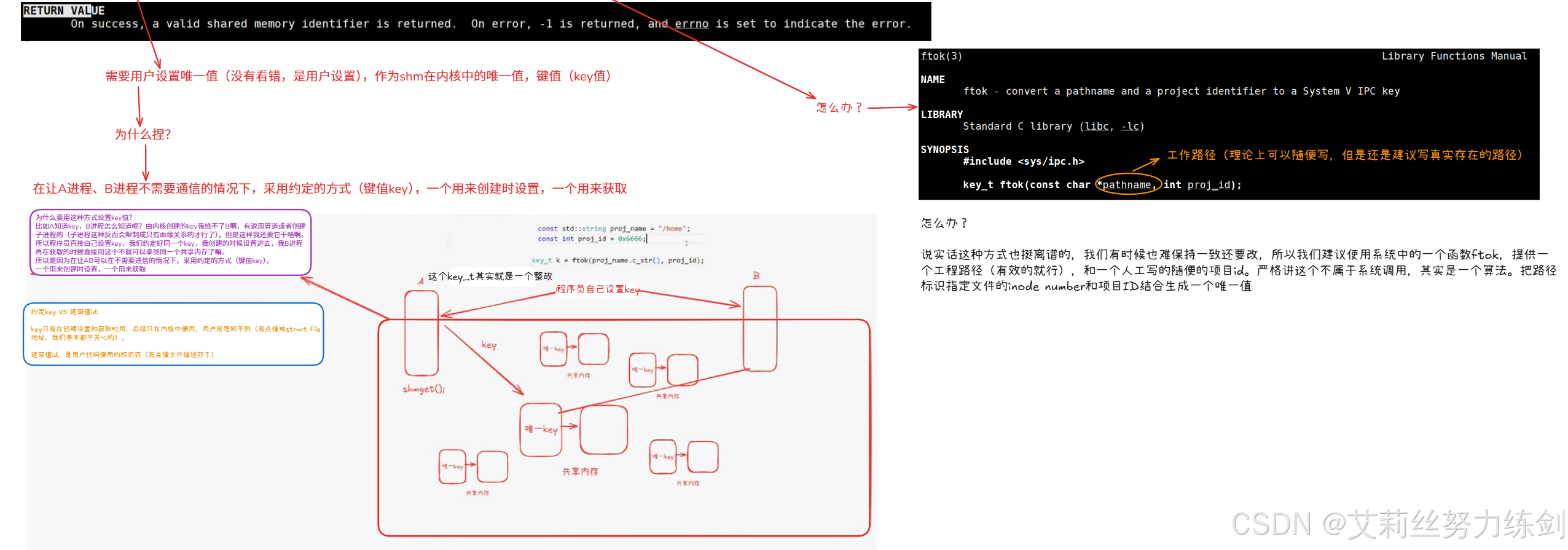
6.3 共享内存:代码书写
以面向对象的形式------
- 不能两个都创建共享内存------这样不能建立进程间通信的信道。
6.3.1 设计问题:这里设计成文件描述符才行
- 共享内存,两个参数问题(共享内存部分最重要的内容)

这两个选项参数分别是:
- 两个选项的应用场景
6.3.2 键值:key
共享内存的结构体里面一定存在一个标识共享内存唯一性的标识符。
- 这个标识符叫做键值(key)
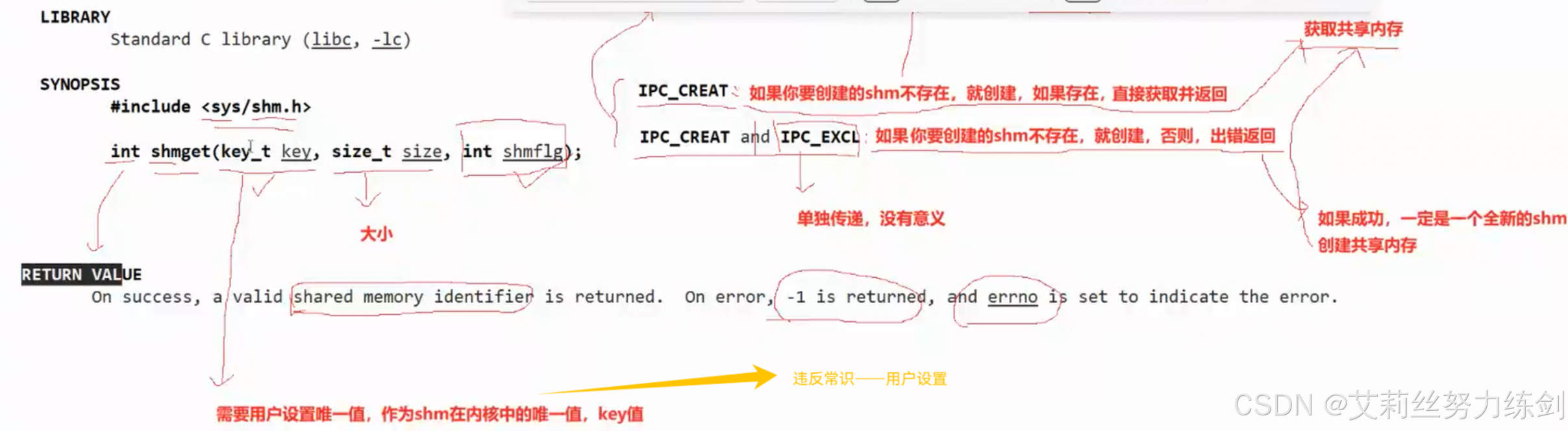
- 为什么用key作为唯一的标识符?
6.3.3 为什么要用这种方式设置key值?

原则上这个键值可以随便写------保证这个键值在系统中唯一------保证不了你就改。
- 这种由用户自己随便设置方式有点挫
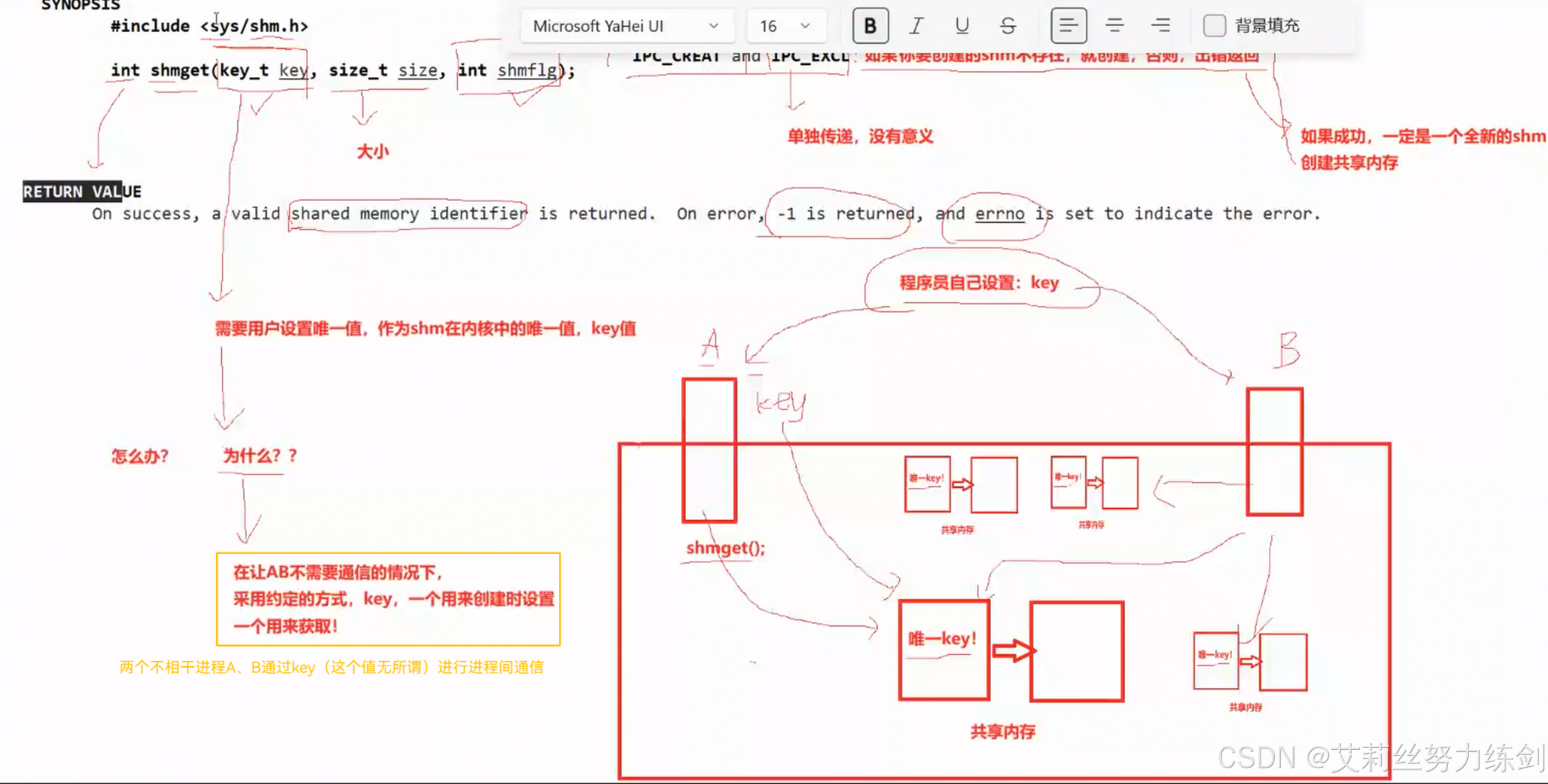
在系统当中有一个接口------
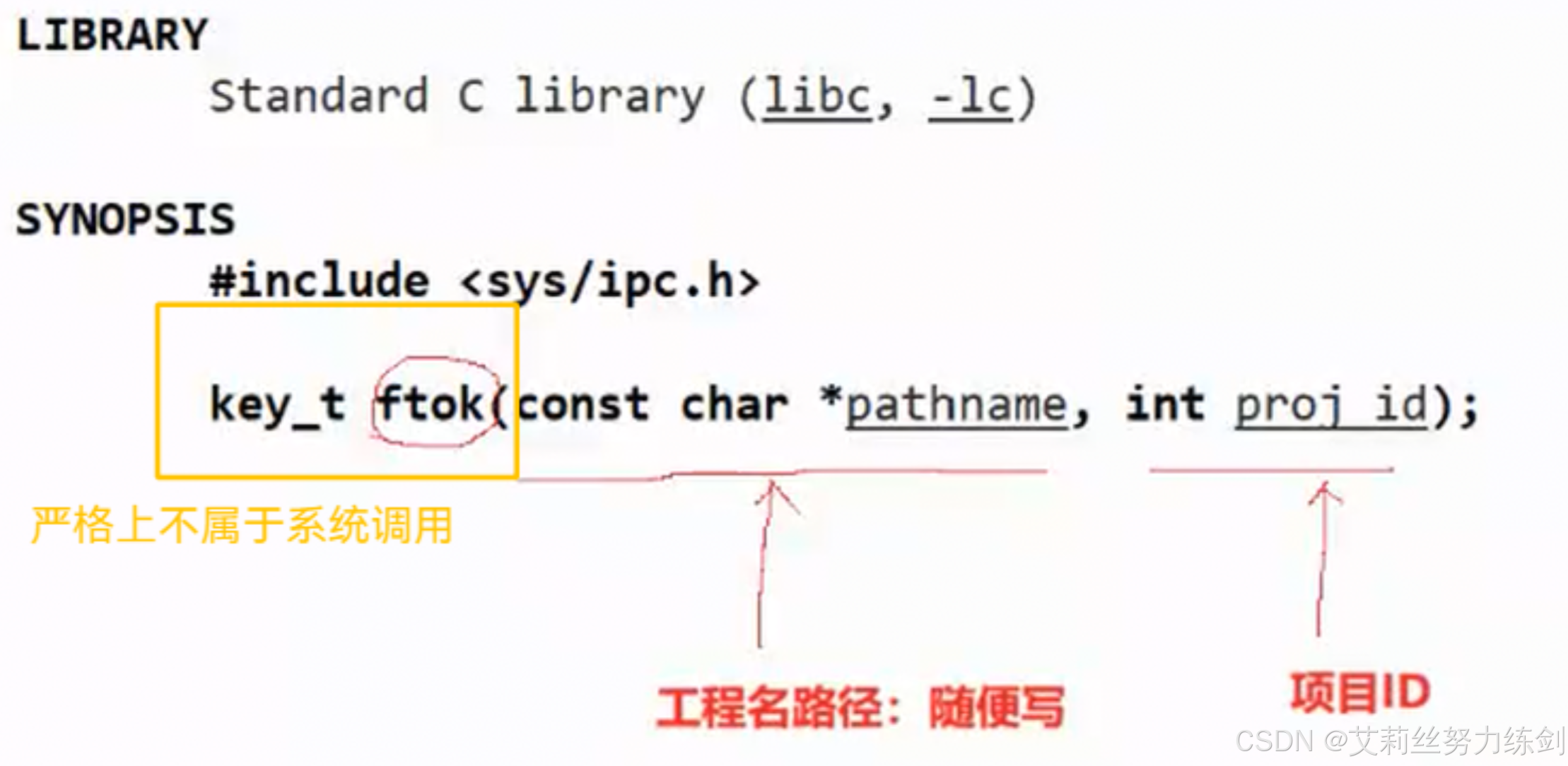
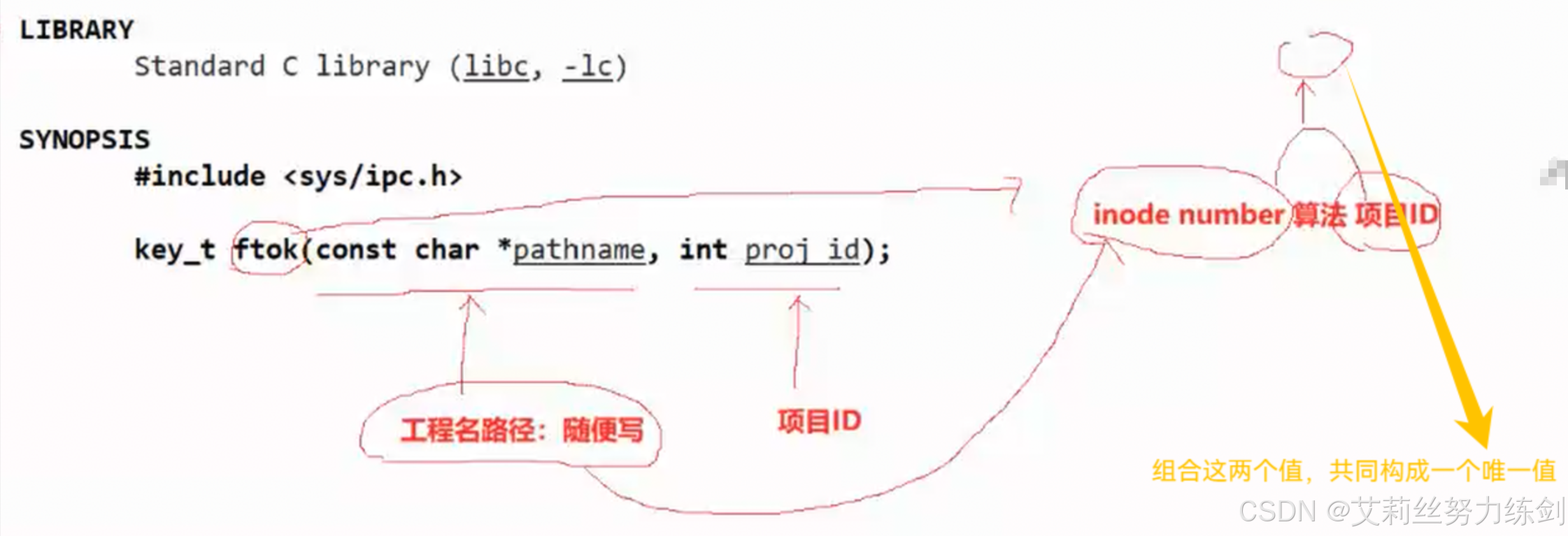
ftok本质上是一个算法
6.3.4 怎么办?
说实话这种方式也挺离谱的,我们有时候也难保持一致还要改,所以我们建议使用系统中的一个函数ftok,提供一个工程路径(有效的就行),和一个人工写的随便的项目id。严格讲这个不属于系统调用,其实是一个算法。把路径标识指定文件的inode number和项目ID结合生成一个唯一值。
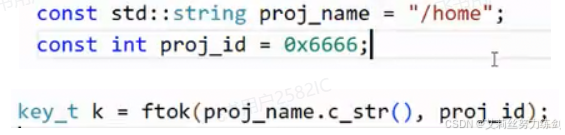
这个key_t其实就是一个整数。
6.3.5 约定key值 VS 返回值id

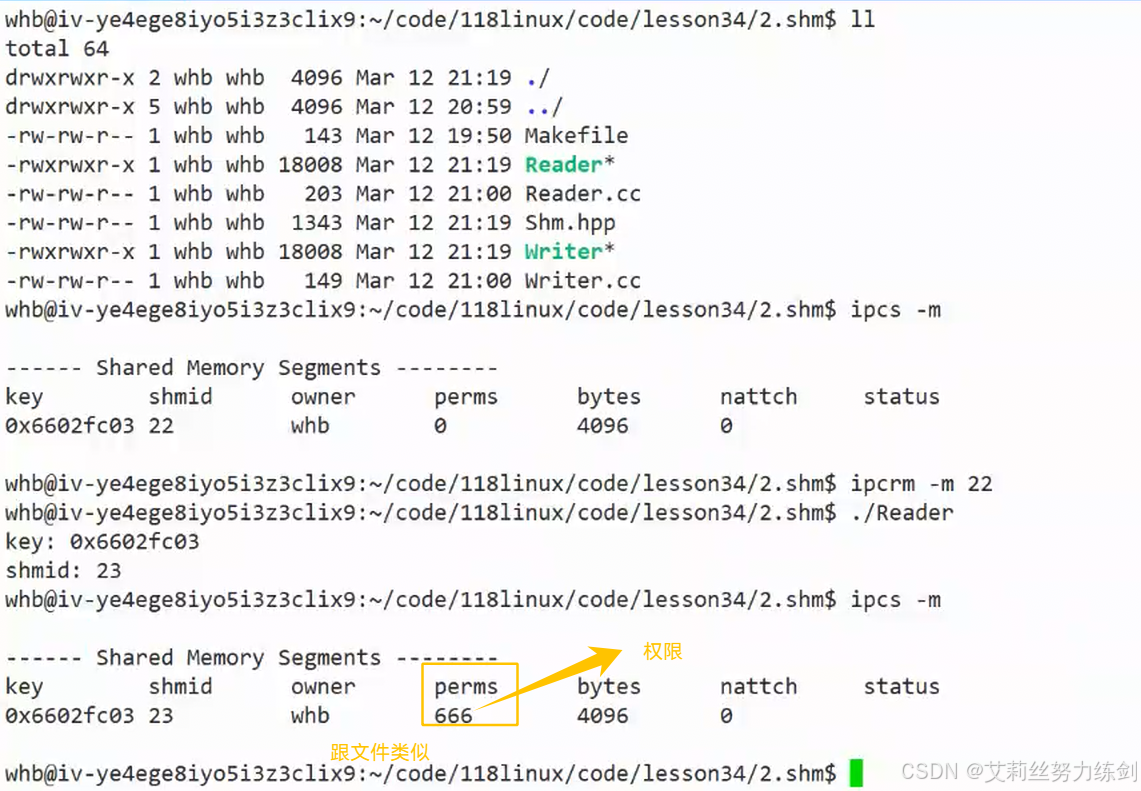
6.3.6 新指令:ipcs -m

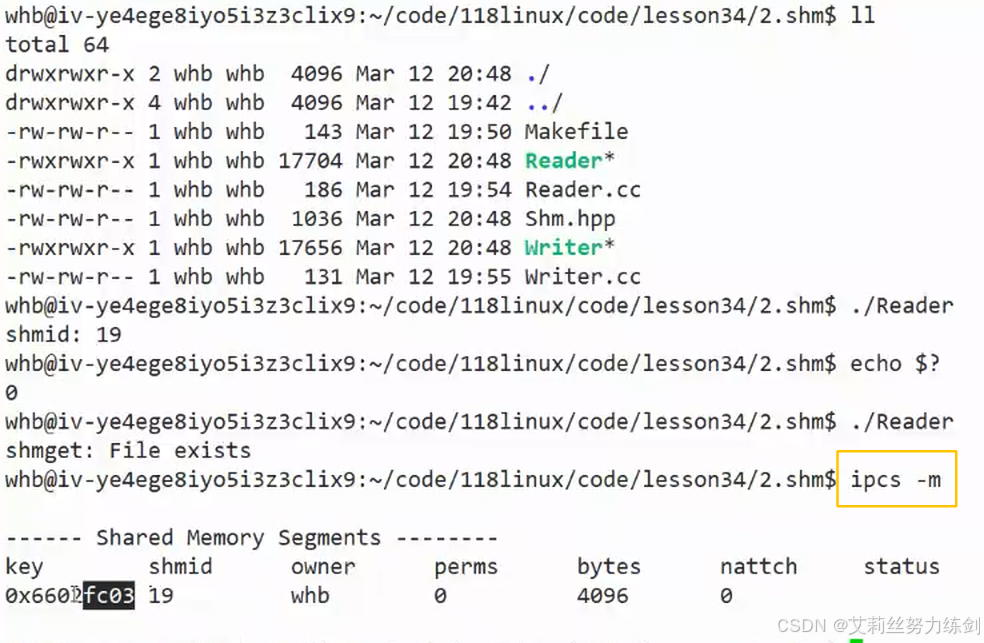

- OS不删除不释放这个共享内存,这个共享内存就还在------除非关机重启!

- (1)用系统调用删除
- (2)用指令删除
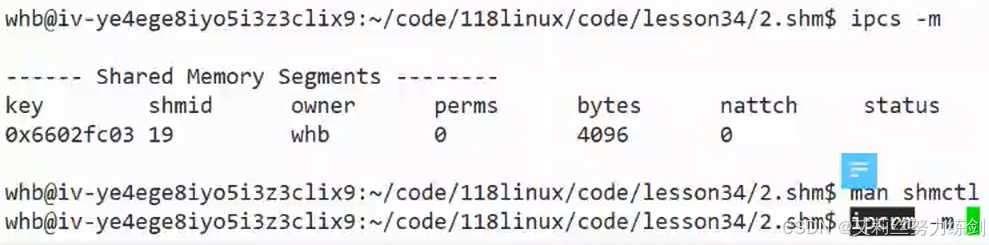
ipcrm也是C语言写的------key值是删除不了的(默认是删除不了的,有的可以,但是最普遍的是删除不了的)------要用id删除。
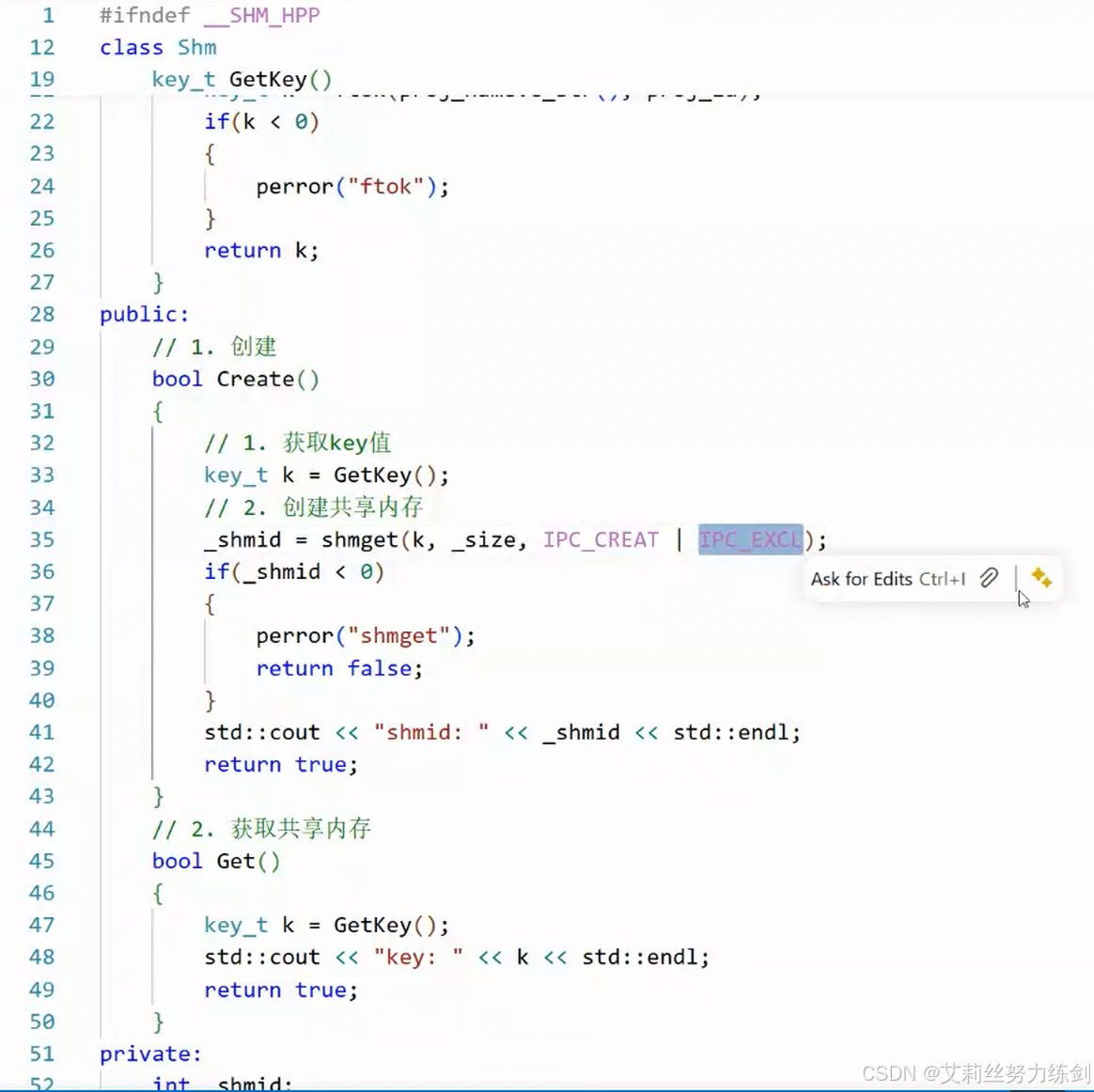
6.3.7 权限设置

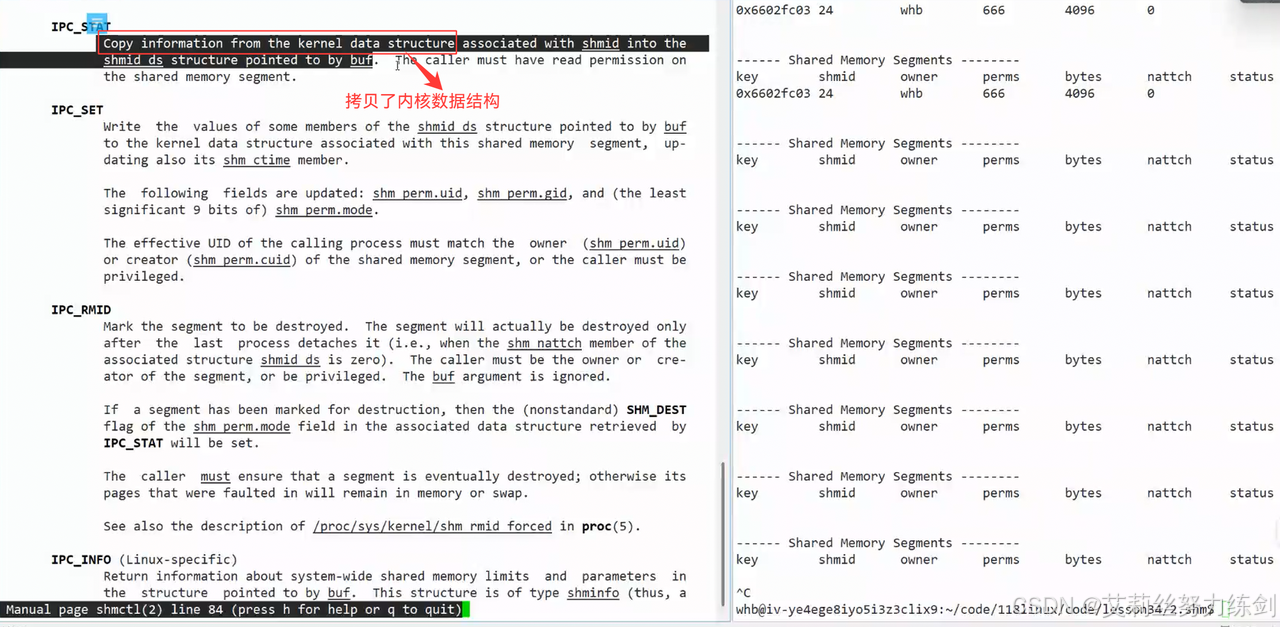
6.3.8 删除共享内存:shmctl
- 现在我们正式来看删除共享内存的系统调用------shmctl
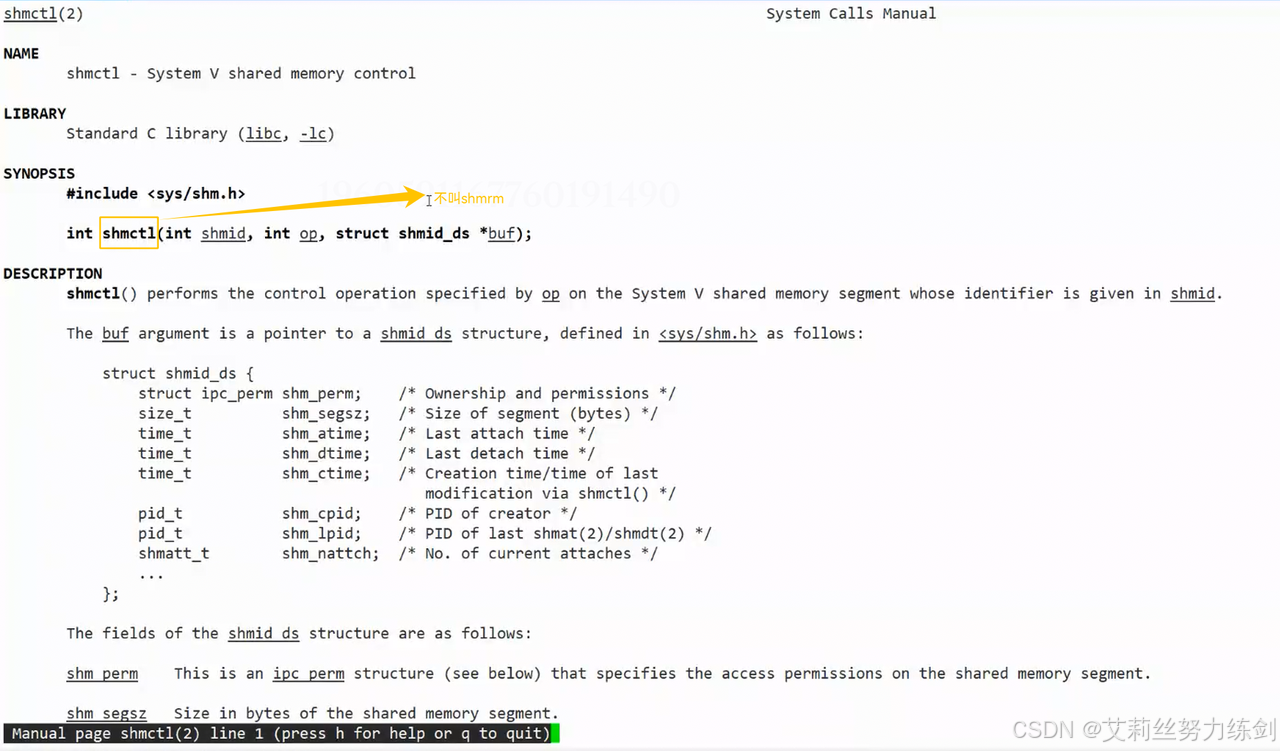

控制共享内存------
- shmctl的参数:
op

前面设置了sleep(5);,共享内存自动删除------
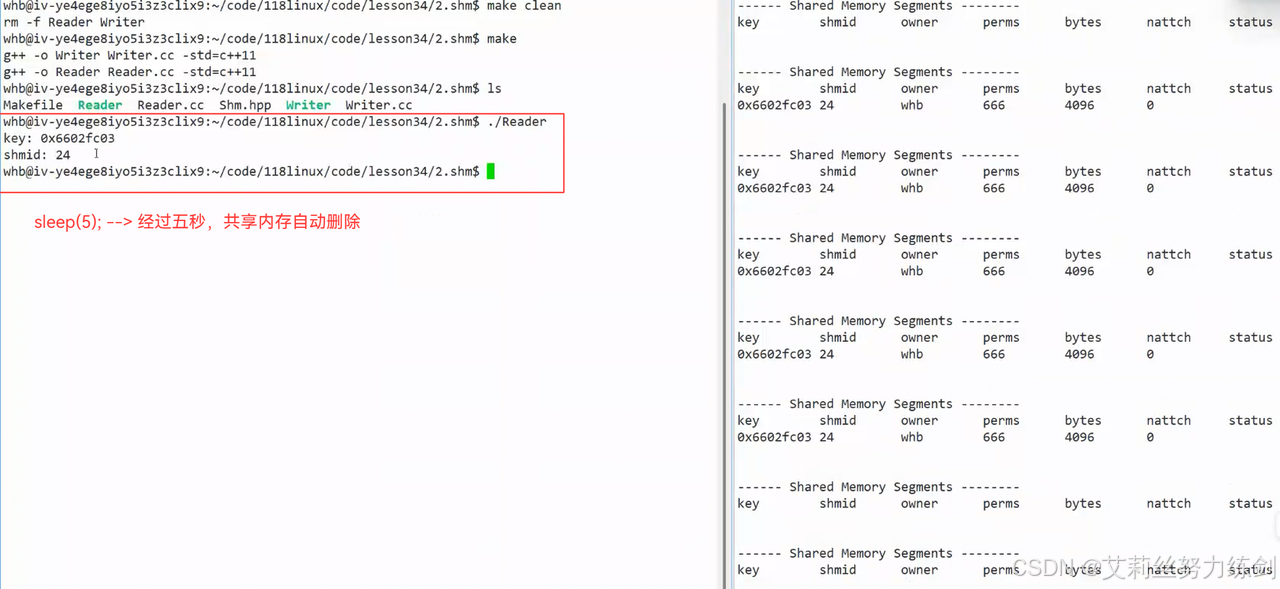
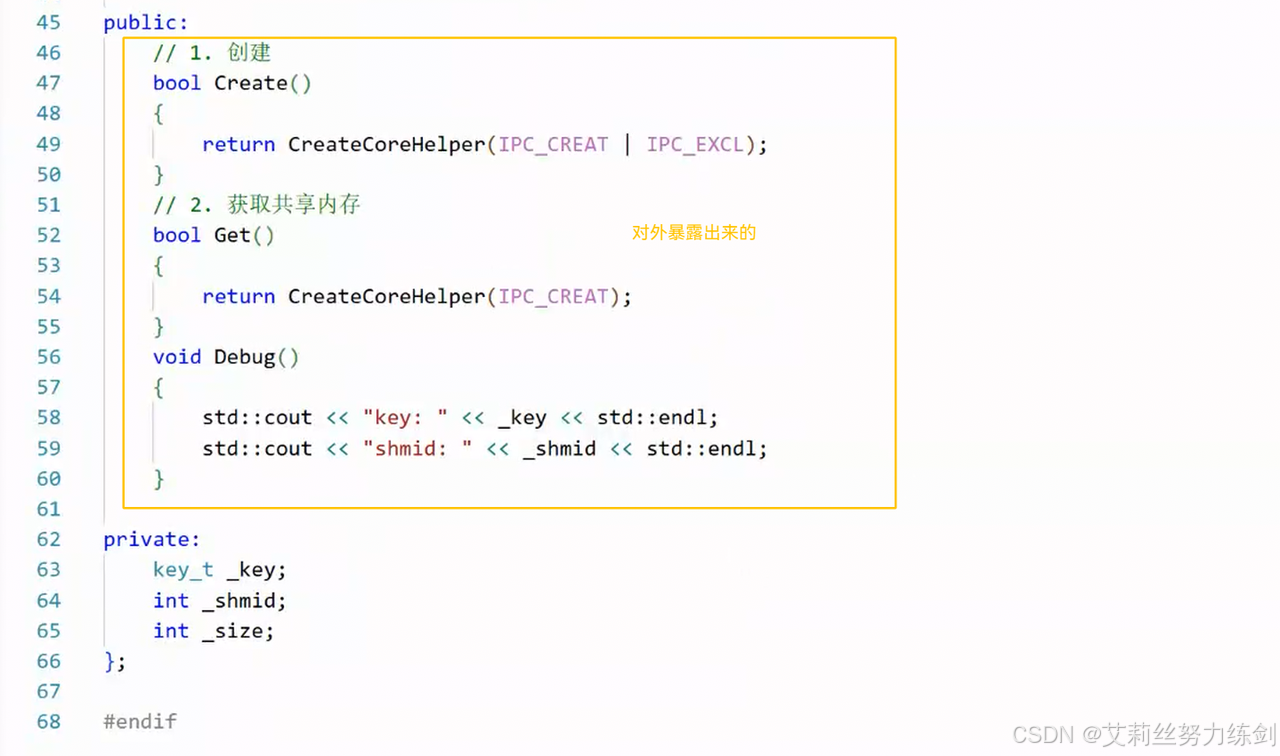
6.3.9 获取共享内存
- 创建和获取只有选项不一样!

暴露和不暴露的代码------
下面这种不是正确的做法------
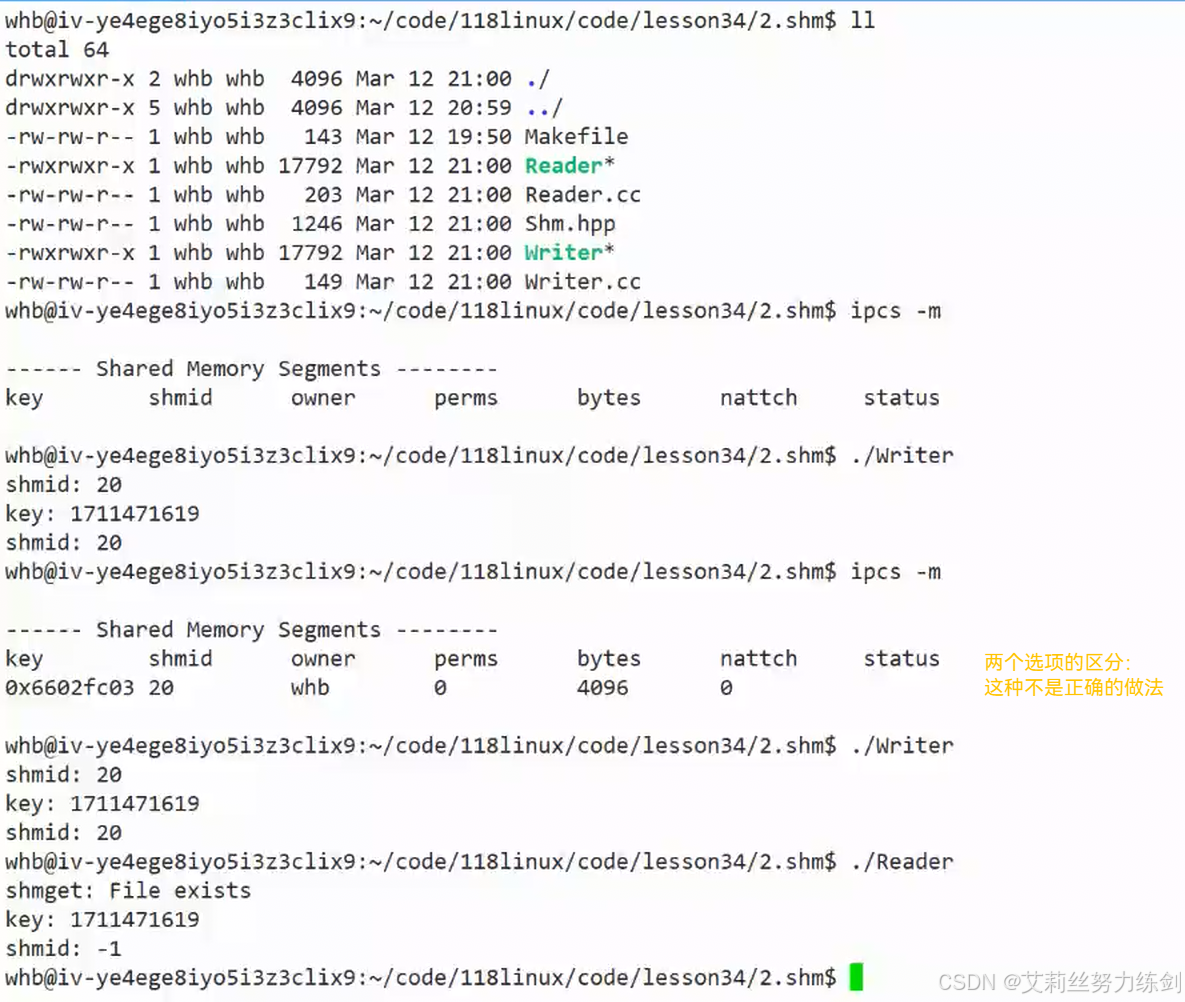
- 键值有点挫,一个十进制一个十六进制
- 共享内存的权限需要设置一下
我们前面说过:"进程问通信的本质前提:先要让不同的进程,看到同一份资源"。
下图中,两个人看到了同一份共享内存------
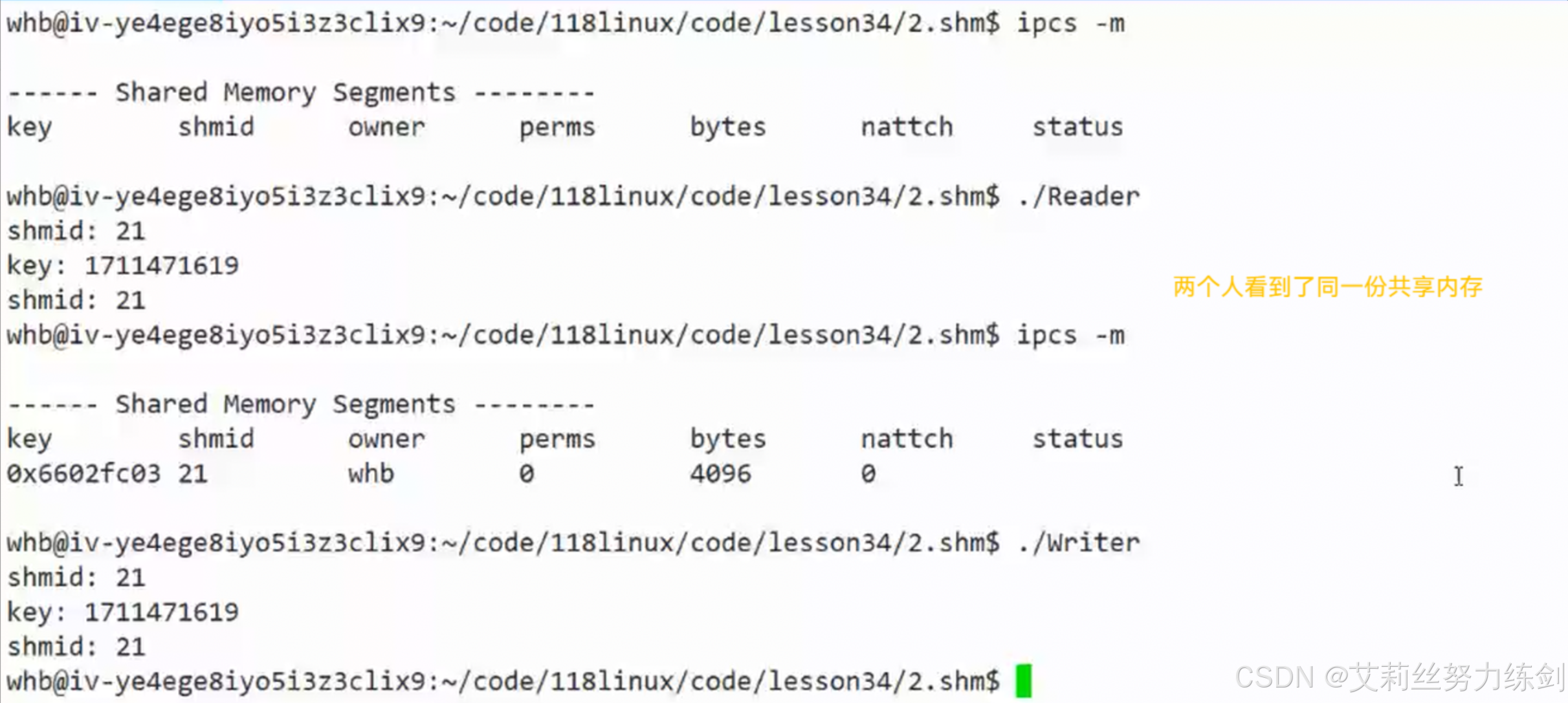
我们此时发现:shmid的值是在线性递增的------
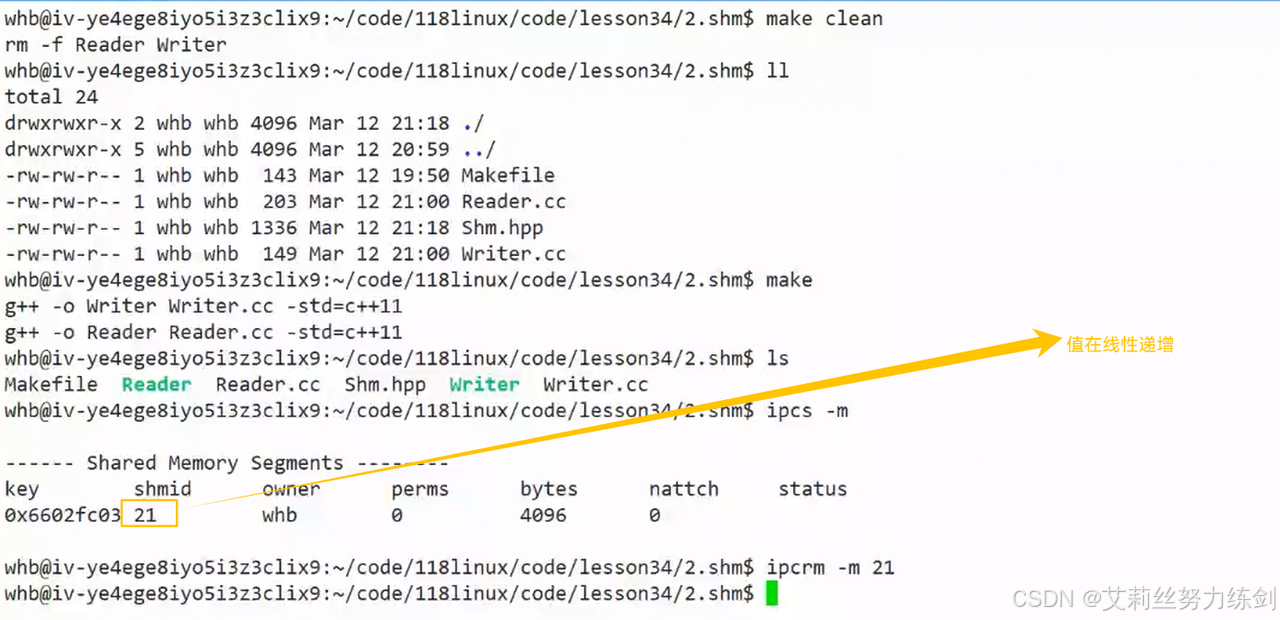
- 获取共享内存的属性
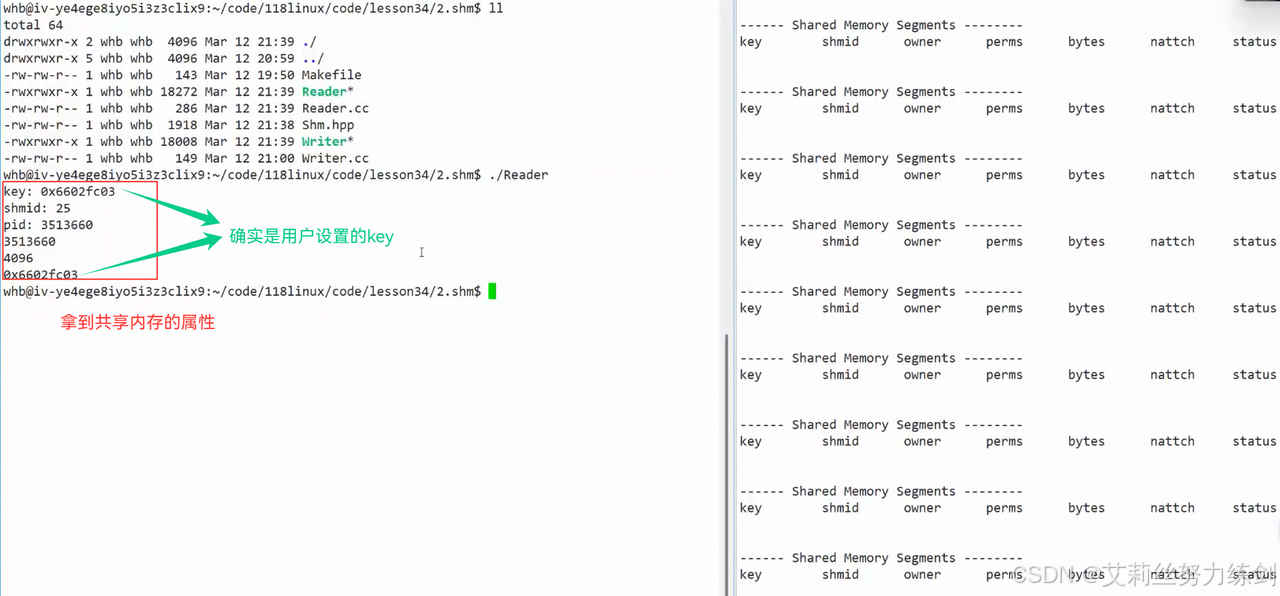
- 把共享内存挂接到指定的虚拟地址空间

操作系统自己也可以调用系统调用,这个挂接的函数第二个参数我们不管,暂时做不到。第三个权限问题,我们也直接设置成0就可以了,不用管了。
注意一下返回值,失败返回-1(强转成void*) ,成功给你一个地址,有点像malloc的返回值,不过一个在堆上一个在共享区。我如果不想通信我甚至能当malloc用,或者给库的来试试看。



6.3.10 查看结构体
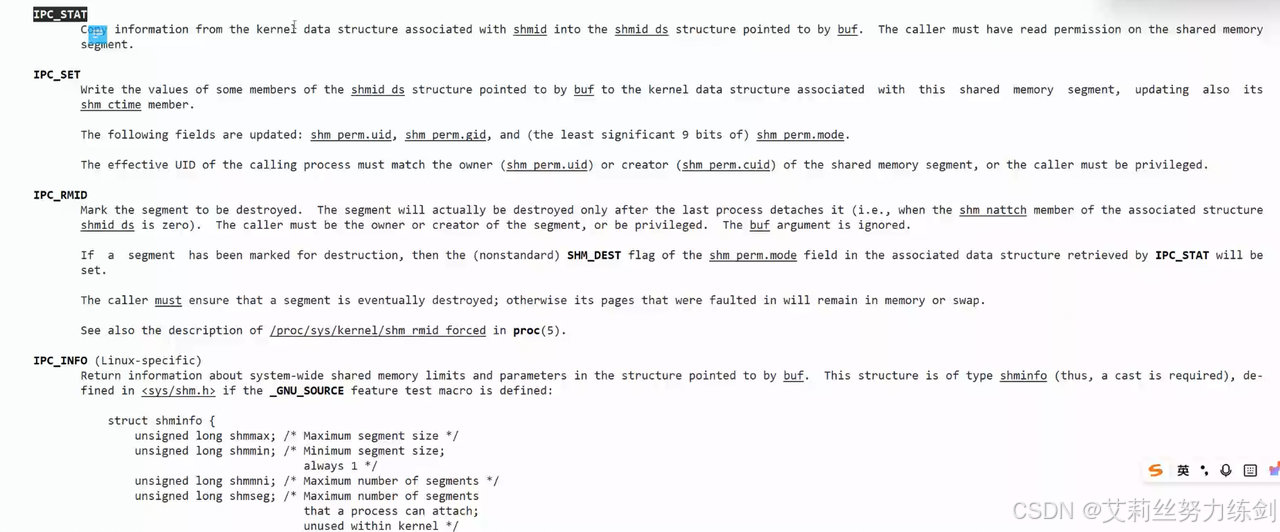
shmid_ds结构体------
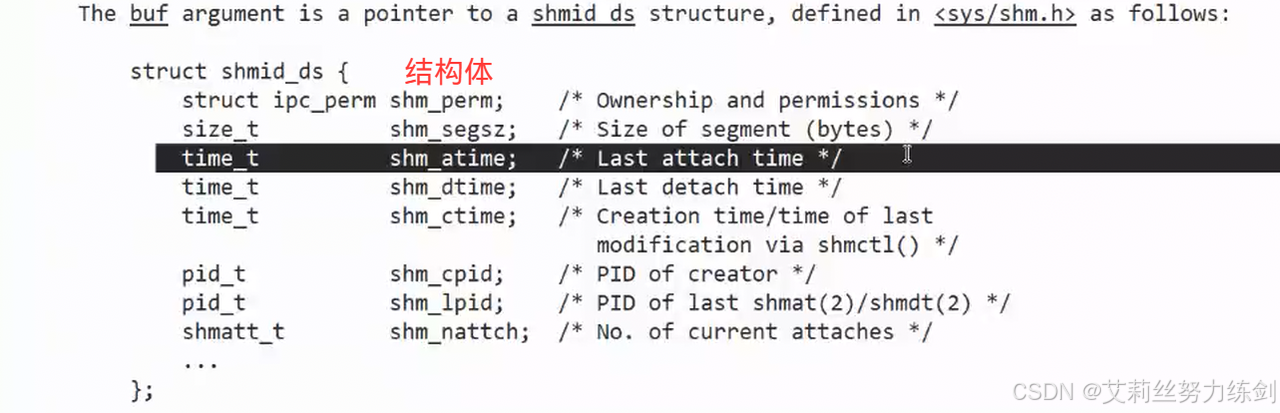
- 用户曾经设置的键值key已经保存在内核中了


6.3.11 挂接函数

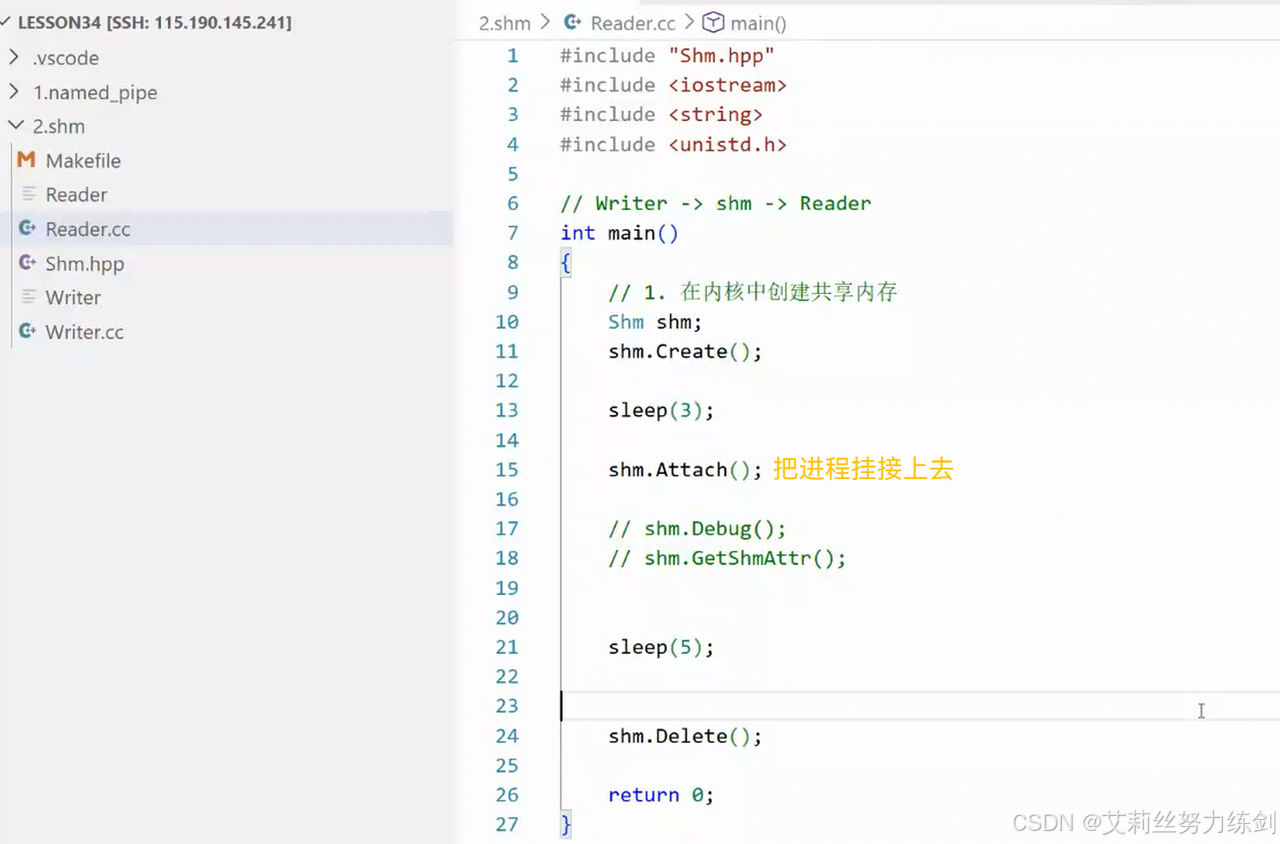
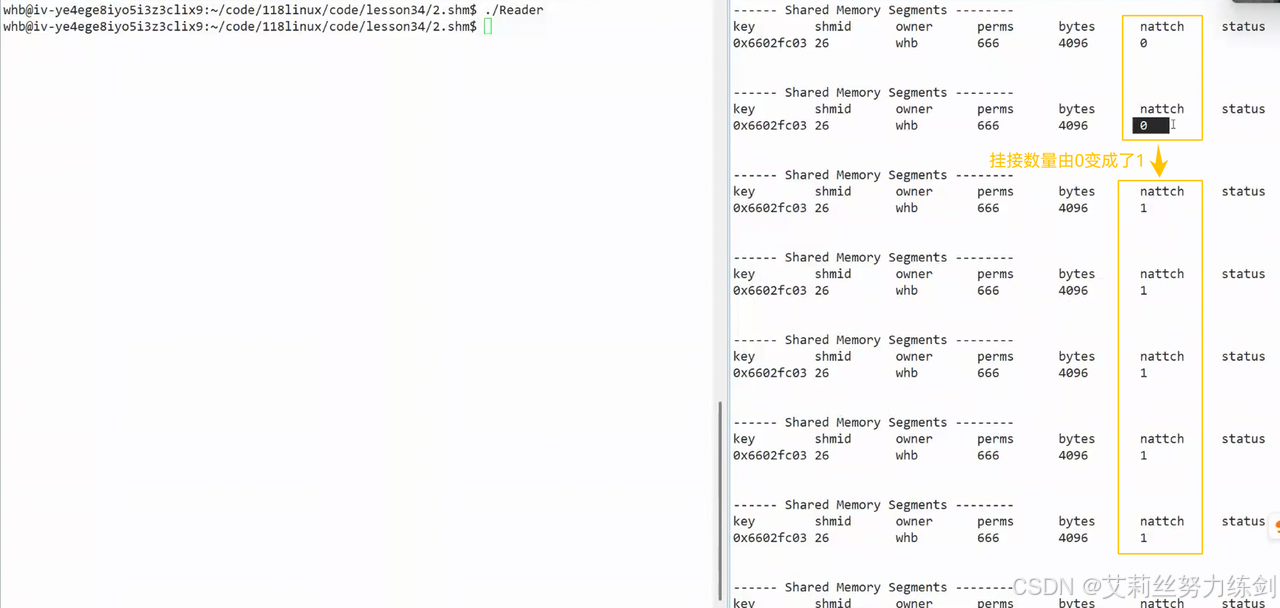
6.4 代码演示(挂接)
Makefile
bash
all:Reader Writer
Reader:Reader.cc
g++ -o $@ $^ -std=c++11
Writer:Writer.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f Reader WriterReader.cc
cpp
#include "Shm.hpp"
#include <iostream>
#include <string>
#include "unistd.h"
// Writer -> shm -> Reader
int main()
{
// 1.在内核中创建共享内存
Shm shm;
shm.Create(); // 这一步才是创建
sleep(3);
shm.Attach();
shm.Debug();
shm.GetShmAttr();
sleep(5);
shm.Delete();
return 0;
}Shm.hpp
cpp
#ifndef __SHM_HPP
#define __SHM_HPP
#include <iostream>
#include <cstdio>
#include <unistd.h>
#include <sys/shm.h>
#include <string>
const std::string proj_name = "/home"; // 工作路径,可以随机,最好是系统存在的路径
const int proj_id = 0x6666; // 项目ID
const int g_size = 4096; // g_size:global size
// 转成十六进制
static std::string ToHex(int data)
{
char hex[64];
snprintf(hex,sizeof(hex),"0x%x",data);
return hex;
}
class Shm
{
public:
// 构造函数和析构函数
Shm(int size = g_size) : _shmid(-1),_size(size),_key(0)
{}
~Shm() {}
private:
key_t GetKey()
{
_key = ftok(proj_name.c_str(),proj_id);
if(_key < 0)
{
perror("ftok");
}
return _key;
}
bool CreateCoreHelper(int flags)
{
// 1.获取key值
key_t k = GetKey();
// 2.创建共享内存
_shmid = shmget(k,_size,flags);
if(_shmid < 0)
{
perror("shmget");
return false;
}
return true;
}
public:
// 1.创建
bool Create()
{
return CreateCoreHelper(IPC_CREAT | IPC_EXCL | 0666);
}
// 2.获取共享内存
bool Get()
{
return CreateCoreHelper(IPC_CREAT);
// return CreateCoreHelper(0);
}
// 3.删除共享内存
bool Delete()
{
int n = shmctl(_shmid,IPC_RMID,NULL);
return n < 0 ? false : true;
}
// 4.保存共享内存属性
void GetShmAttr()
{
struct shmid_ds ds;
int n = shmctl(_shmid,IPC_STAT,&ds);
if(n < 0)
{
perror("shmctl");
return;
}
std::cout << "pid: " << getpid() << std::endl; // 当前进程的 PID - 显示调用此函数的进程 ID
// 创建共享内存的进程 PID - shm_cpid 是创建该共享内存段的进程 ID
std::cout << ds.shm_cpid << std::endl;
// 共享内存段的大小(字节) - shm_segsz 表示共享内存的大小,单位是字节
std::cout << ds.shm_segsz << std::endl;
// 共享内存的 key 值(十六进制)
// - shm_perm.__key 是共享内存的键值,通过 ToHex 函数转换为十六进制显示
std::cout << ToHex(ds.shm_perm.__key) << std::endl;
}
// 挂接
void *Attach()
{
return shmat(_shmid,nullptr,0);
}
// Debug
void Debug()
{
std::cout << "key: " << ToHex(_key) << std::endl;
std::cout << "shmid: " << _shmid << std::endl;
}
private:
key_t _key;
int _shmid;
int _size;
};
#endifWriter.cc
cpp
#include "Shm.hpp"
#include <iostream>
#include "string"
int main()
{
Shm shm;
// 这里不能创建共享内存,创建了就不能建立进程间通信的信道了
shm.Get();
shm.Debug();
return 0;
}运行
bash
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ll
total 64
drwxrwxr-x 2 alice alice 4096 Mar 13 19:00 ./
drwxrwxr-x 29 alice alice 4096 Mar 12 22:20 ../
-rw-rw-r-- 1 alice alice 143 Mar 12 23:04 Makefile
-rwxrwxr-x 1 alice alice 17712 Mar 13 19:00 Reader*
-rw-rw-r-- 1 alice alice 350 Mar 12 22:28 Reader.cc
-rw-rw-r-- 1 alice alice 2233 Mar 13 18:58 Shm.hpp
-rwxrwxr-x 1 alice alice 18008 Mar 13 19:00 Writer*
-rw-rw-r-- 1 alice alice 225 Mar 12 22:30 Writer.cc
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ./Reader
shmget: File exists
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcrm -m 7
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcrm -m
ipcrm: option requires an argument -- 'm'
Try 'ipcrm --help' for more information.
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipc -m
^[[ACommand 'ipc' not found, but there are 25 similar ones.
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcrm -m^C
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ./Writer
key: 0x66020002
shmid: 8
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x66020002 8 alice 0 4096 0
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcs -l
------ Messages Limits --------
max queues system wide = 32000
max size of message (bytes) = 8192
default max size of queue (bytes) = 16384
------ Shared Memory Limits --------
max number of segments = 4096
max seg size (kbytes) = 18014398509465599
max total shared memory (kbytes) = 18446744073709551612
min seg size (bytes) = 1
------ Semaphore Limits --------
max number of arrays = 32000
max semaphores per array = 32000
max semaphores system wide = 1024000000
max ops per semop call = 500
semaphore max value = 32767
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x66020002 8 alice 0 4096 0
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ./Writer
key: 0x66020002
shmid: 8
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x66020002 8 alice 0 4096 0
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcrm -M 0x66020002
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ make clean
rm -f Reader Writer
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ make
g++ -o Reader Reader.cc -std=c++11
g++ -o Writer Writer.cc -std=c++11
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ./Writer
key: 0x66020002
shmid: 9
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ./Reader
^C
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ./Writer
key: 0x66020002
shmid: 10
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ./Writer
key: 0x66020002
shmid: 10
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ./Reader
shmget: File exists
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ./Reader
shmget: File exists
^[[A^C
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x66020002 10 alice 666 4096 0
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ make clean
rm -f Reader Writer
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ make
g++ -o Reader Reader.cc -std=c++11
g++ -o Writer Writer.cc -std=c++11
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ./Reader
shmget: File exists
key: 0x66020002
shmid: -1
shmctl: Invalid argument
^C
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcrm -M 0x66020002
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ./Reader
key: 0x66020002
shmid: 11
pid: 1806810
1806810
4096
0x66020002
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ./Writer
key: 0x66020002
shmid: 12
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ipcrm -M 0x66020002
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ./Writer
key: 0x66020002
shmid: 13
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ ./Reader
shmget: File exists
key: 0x66020002
shmid: -1
shmctl: Invalid argument
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ man 3 shmget
No manual entry for shmget in section 3
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ man 2 shmget
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ man 2 ftok
No manual entry for ftok in section 2
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ man 3 ftok
alice@VM-4-17-ubuntu:~/Alice/bit_118_ubuntu/3_12_shm$ 6.5 共享内存思维导图1

6.6 代码演示(共享内存收尾)
Makefile
bash
all:Reader Writer
Reader:Reader.cc
g++ -o $@ $^ -std=c++11
Writer:Writer.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f Reader WriterReader.cc
cpp
#include "Shm.hpp"
#include <iostream>
#include <string>
#include "unistd.h"
// 信号
#include<signal.h>
// Writer -> shm -> Reader
int main()
{
// 1.在内核中创建共享内存
Shm shm;
shm.Create(); // 这一步才是创建
sleep(100);
char* addr = (char*)shm.Attach();
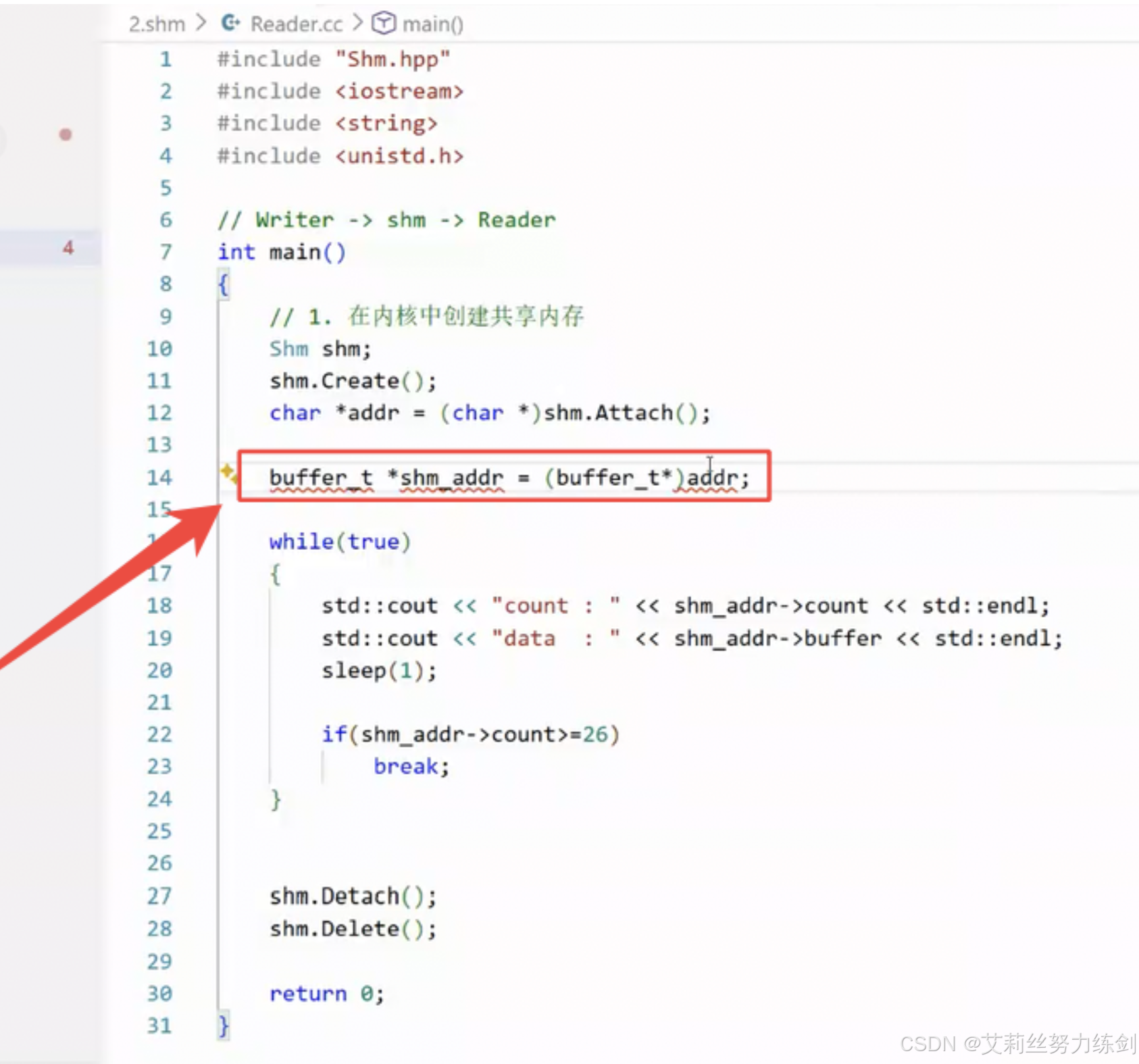
buffer_t *shm_addr = (buffer_t*)addr;
int old = shm_addr->count;
while(true)
{
if(old != shm_addr->count)
{
std::cout << "count : " << shm_addr->count << std::endl;
std::cout << "data : " << shm_addr->buffer << std::endl;
old = shm_addr->count;
}
usleep(50000);
if(shm_addr->count >= 26)
break;
}
// sleep(3);
// shm.Attach();
// shm.Debug();
// shm.GetShmAttr();
// sleep(5);
shm.Detach();
shm.Delete();
return 0;
}Shm.hpp
cpp
#ifndef __SHM_HPP
#define __SHM_HPP
#include <iostream>
#include <cstdio>
#include <unistd.h>
#include <sys/shm.h>
#include <string>
const std::string proj_name = "/home"; // 工作路径,可以随机,最好是系统存在的路径
const int proj_id = 0x6666; // 项目ID
const int g_size = 4096; // g_size:global size
// 转成十六进制
static std::string ToHex(int data)
{
char hex[64];
snprintf(hex,sizeof(hex),"0x%x",data);
return hex;
}
class Shm
{
public:
// 构造函数和析构函数
Shm(int size = g_size) : _shmid(-1),_size(size),_key(0)
{}
~Shm() {}
private:
key_t GetKey()
{
_key = ftok(proj_name.c_str(),proj_id);
if(_key < 0)
{
perror("ftok");
}
return _key;
}
bool CreateCoreHelper(int flags)
{
// 1.获取key值
key_t k = GetKey();
// 2.创建共享内存
_shmid = shmget(k,_size,flags);
if(_shmid < 0)
{
perror("shmget");
return false;
}
return true;
}
public:
// 1.创建
bool Create()
{
return CreateCoreHelper(IPC_CREAT | IPC_EXCL | 0666);
}
// 2.获取共享内存
bool Get()
{
return CreateCoreHelper(IPC_CREAT);
// return CreateCoreHelper(0);
}
// 3.删除共享内存
bool Delete()
{
int n = shmctl(_shmid,IPC_RMID,NULL);
return n < 0 ? false : true;
}
// 4.保存共享内存属性
void GetShmAttr()
{
struct shmid_ds ds;
int n = shmctl(_shmid,IPC_STAT,&ds);
if(n < 0)
{
perror("shmctl");
return;
}
std::cout << "pid: " << getpid() << std::endl; // 当前进程的 PID - 显示调用此函数的进程 ID
// 创建共享内存的进程 PID - shm_cpid 是创建该共享内存段的进程 ID
std::cout << ds.shm_cpid << std::endl;
// 共享内存段的大小(字节) - shm_segsz 表示共享内存的大小,单位是字节
std::cout << ds.shm_segsz << std::endl;
// 共享内存的 key 值(十六进制)
// - shm_perm.__key 是共享内存的键值,通过 ToHex 函数转换为十六进制显示
std::cout << ToHex(ds.shm_perm.__key) << std::endl;
}
// 挂接
void *Attach()
{
return shmat(_shmid,nullptr,0);
}
// Detach:去关联
void Detach()
{
int n = shmdt(_start);
// 返回值自己设置
(void)n;
}
// Debug
void Debug()
{
std::cout << "key: " << ToHex(_key) << std::endl;
std::cout << "shmid: " << _shmid << std::endl;
}
private:
key_t _key;
int _shmid;
int _size;
void *_start;
};
// 重定义
typedef struct data{
int count;
char buffer[26 * 2];
}buffer_t;
#endifWriter.cc
cpp
#include "Shm.hpp"
#include <iostream>
#include <string>
#include <string.h>
Shm shm;
class Init // 定义结构体
{
public:
Init()
{
shm.Get();
addr = (char*)shm.Attach();
std::cout << "addr: " << ToHex((long long)addr) << std::endl;
}
// 析构函数
~Init()
{
shm.Detach();
}
char *Addr()
{
return addr;
}
public:
char* addr;
};
Init init;
int main()
{
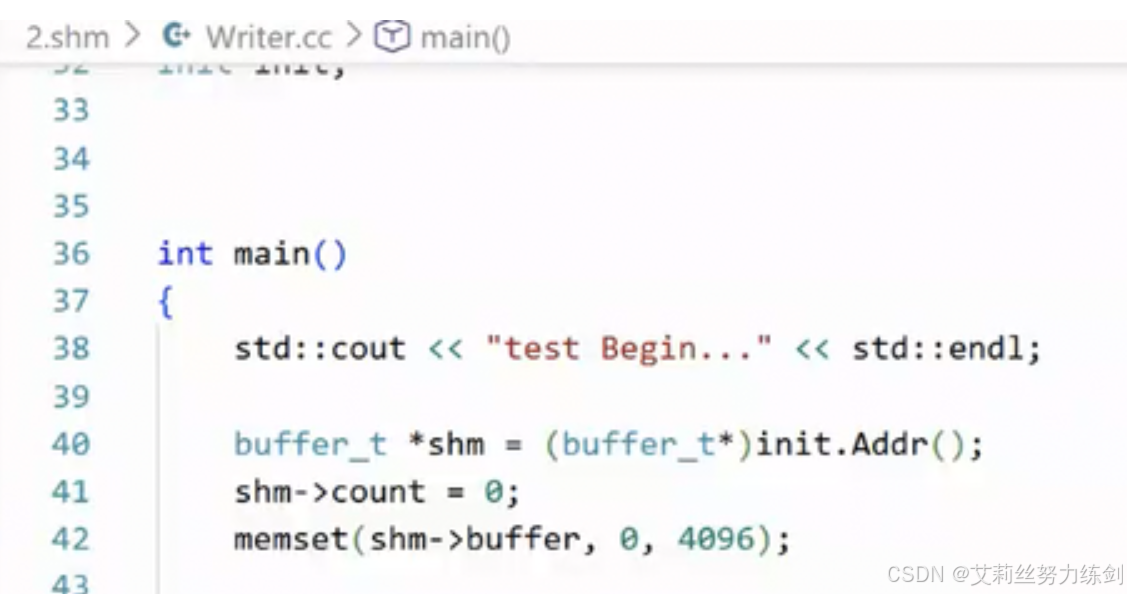
std::cout << "test Begin..." << std::endl;
buffer_t *shm = (buffer_t*)init.Addr();
shm->count = 0;
memset(shm->buffer,0,4096);
char ch = 'A';
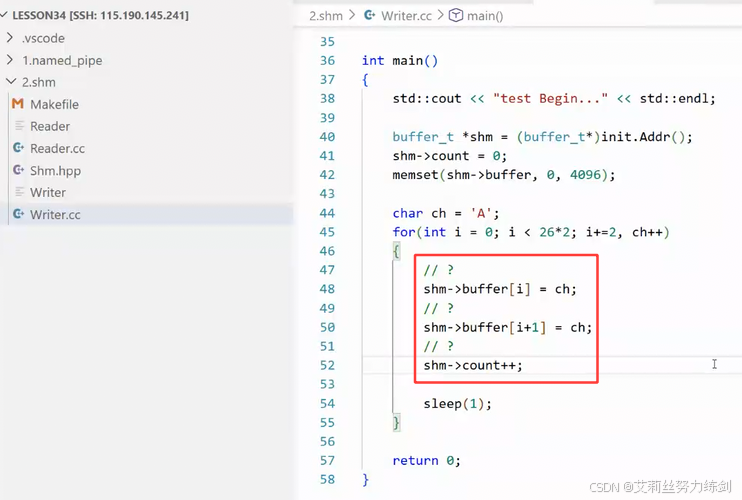
for(int i = 0;i < 26*2;i += 2,ch++)
{
// ?
shm->buffer[i] = ch;
// ?
usleep(2000000);
shm->buffer[i + 1] = ch;
usleep(7000000);
// ?
shm->count++;
usleep(7000000);
sleep(1);
}
return 0;
}6.7 共享内存补充
6.7.1 回顾
共享内存映射到虚拟地址空间的时候,由于虚拟地址空间使用情况不同,两个进程的这个地址一样或者不一样都很正常,反正都在堆栈之间。
因为创建共享内存的过程是OS创建的,所以OS必然要提供系统调用。
系统设置key的无法和目标进程进行进程间通信,变成了"鸡生蛋"问题,所以得由程序员约定key值。
key值只在内核中使用。
共享内存可以挂接到虚拟地址空间里。
共享内存的生命周期随内核,不是随进程!
- 系统调用删除
- 系统指令删除
共享内存是可以同时存在多份的!需要先描述再组织,OS要管理共享内存。
6.7.2 验证addr在堆栈之间
上文中已经获取了共享内存属性、把共享内存挂接到虚拟地址空间,挂接到虚拟地址空间之后会返回一个虚拟地址空间的起始地址------我们可以打印查看一下addr(起始地址),看看地址被映射到了什么地方。
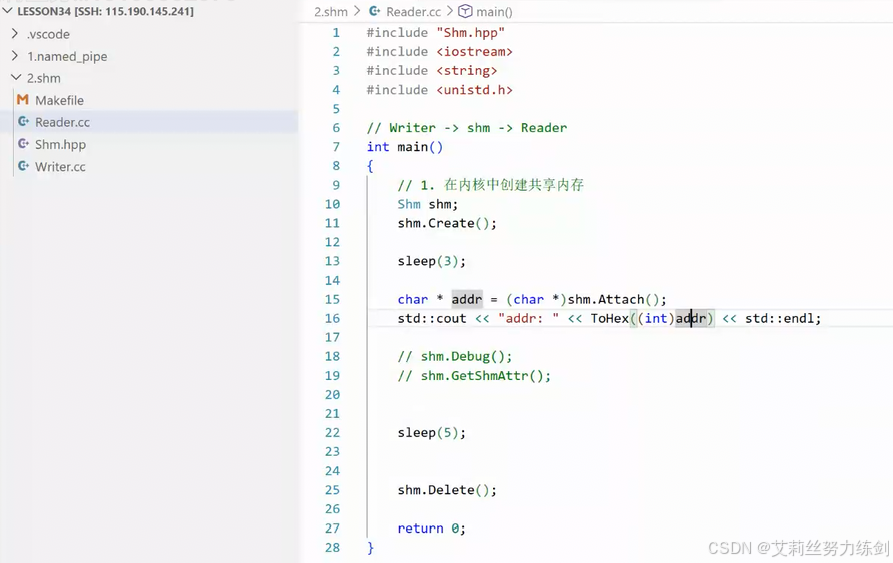
- 创建共享内存成功,attach------

这里addr是有精度损失的!addr的类型是int,我们转成long long:
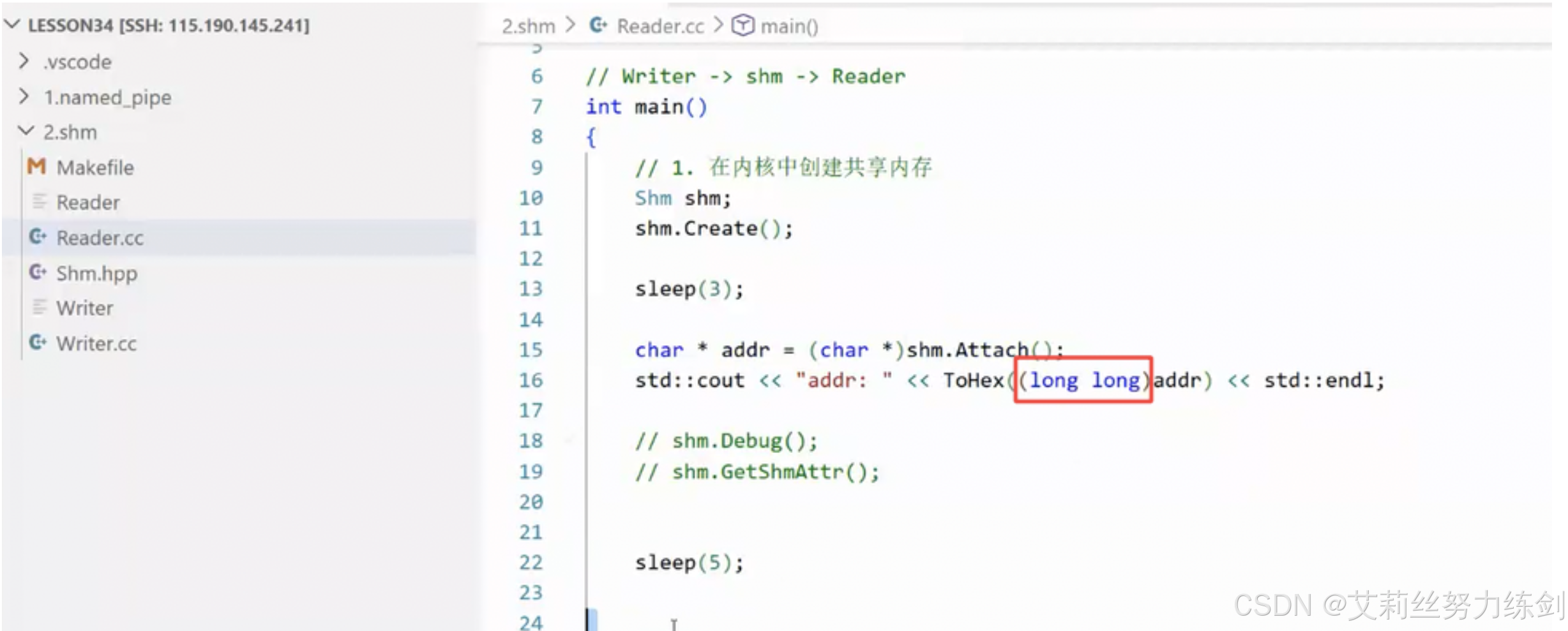
我们运行一下,发现:
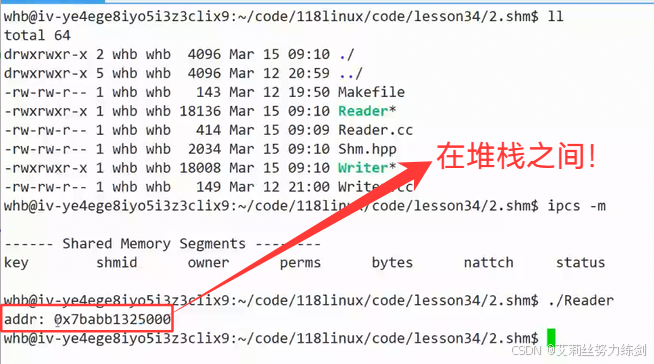
我们也可以去验证一下,看看这个addr的地址是不是在堆栈之间。
6.7.3 删除共享内存之前一般是要去关联

- dt(delete attach):能够去关联
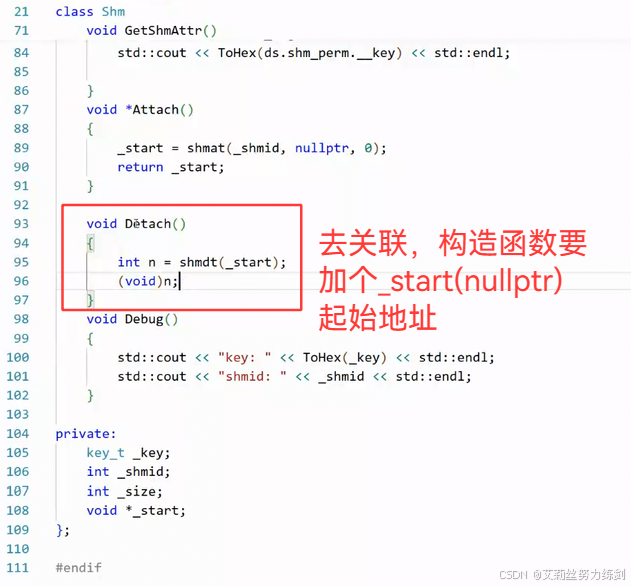
这样我们就把共享内存创建、去关联、删除的系统封装做好了。
作为使用共享内存的一方,只需要获取、关联、去关联(从虚拟地址空间剥离下去):
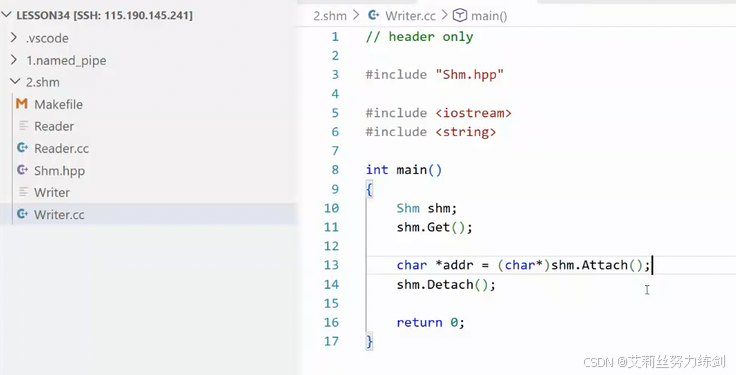
而读取的一方:
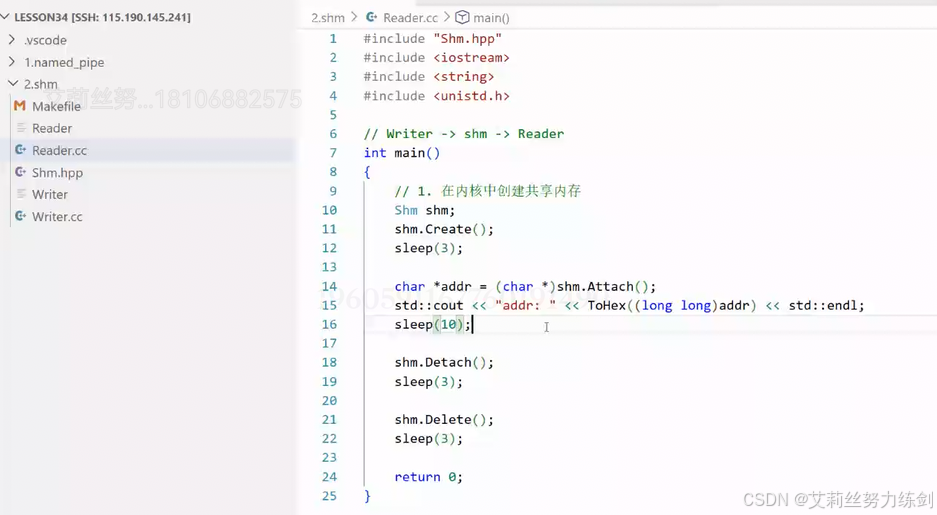
监控开起来,我们可以观察挂接从无到有、从有到无的变化,至此我们就可以完成对共享内存的管理。
我们使用共享内存的过程中,通信了吗?
- 我们没有通信!
我们之前大量的时间都花在让不同的进程看到同一份资源!
为什么这么麻烦呢?因为进程具有独立性!所以要做很多准备工作!
- 共享内存、消息队列、信号量都是如此,这就是进程间通信的特点,通信就是一会儿的事,但是准备工作很多。
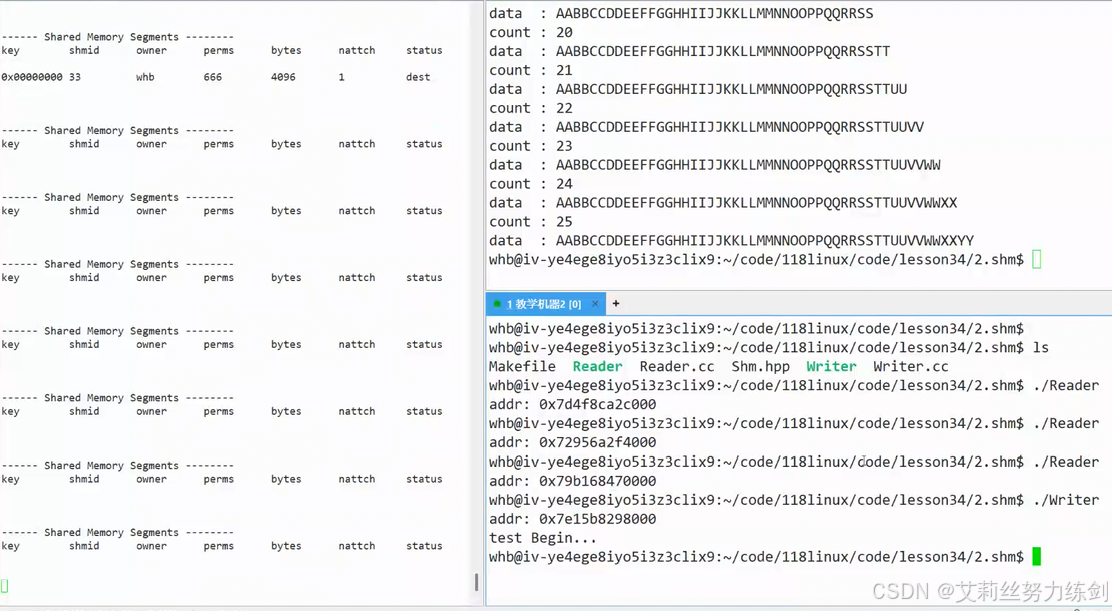
我们可以把共享内存做得更好玩一点,写端向往里写"AA""BB"CC"这样的内容,读端可以让它while(true)一直读取共享内存,或者也可以做得更好玩一点
比如头四个字节作为约定,从4字节的位置往后写(前4字节写对数):
- 放Shm.hpp,这样大家都能够看到了
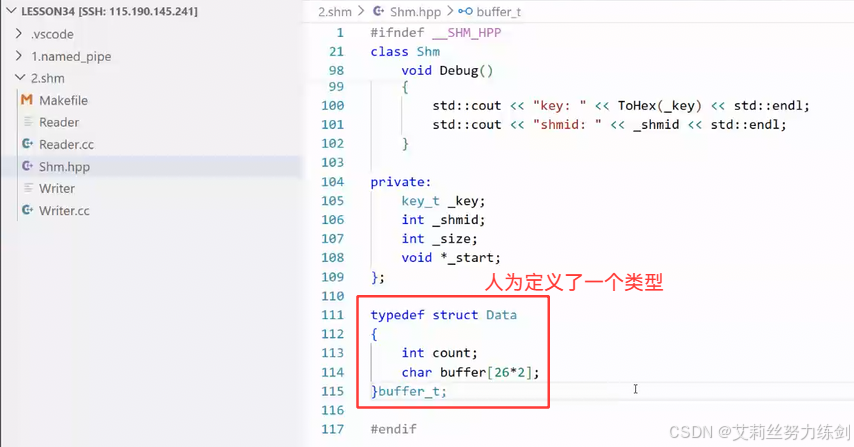
-
双方基于一个相同的结构体变量共享,进行消息互传
-
把共享内存当成了一个结构体。
共享内存,共享结构体变量,用指针强转成我们想要的数据类型,buffer_t(typedef出来的数据类型)------对共享内存可以全部进行定义,设置成4096:
- 好像打印有问题,没有打印ZZ
6.7.4 我们在使用共享内存的时候。有没有使用系统调用?
6.7.4.1 结论1
- 结论1:答案是没有,因为共享内存直接映射到了我们进程自己的用户空间中,用户可以用指针直接访问!
6.7.4.2 结论2
一方直接写入的数据,另一方是直接看到了!!!
- 下面这里就能看到,我们直接用指针进行了访问!
共享内存直接属于映射方!双方都会看到同一份资源!
以前A和B通信要进行两次拷贝,先拷贝给内核,再拷贝给B,这里只要进行一次拷贝!
- 结论2:共享内存是进程间通信中速度最快的,没有之一!
不需要使用系统调用,而且还可以减少拷贝次数!速度是进程间通信中速度最快的!
把内存块映射到地址空间,对方立马就看到了。
- 模拟一下(今天还做不到)让这三个结构体变量同时
我们修改一下代码,效果不够明显,我们多复制几台机器,搞两个(多个)写端------
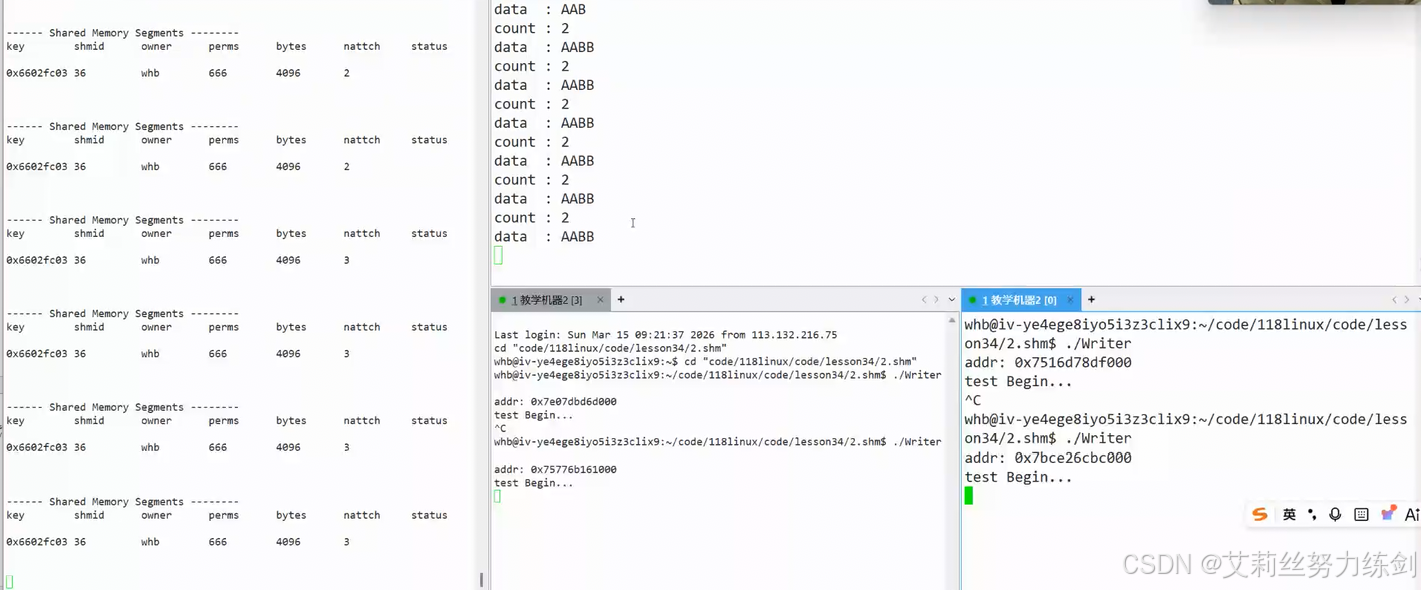
上下对应,明显感觉到有多个写端的时候,另一个写端写的数据被覆盖或者清空:
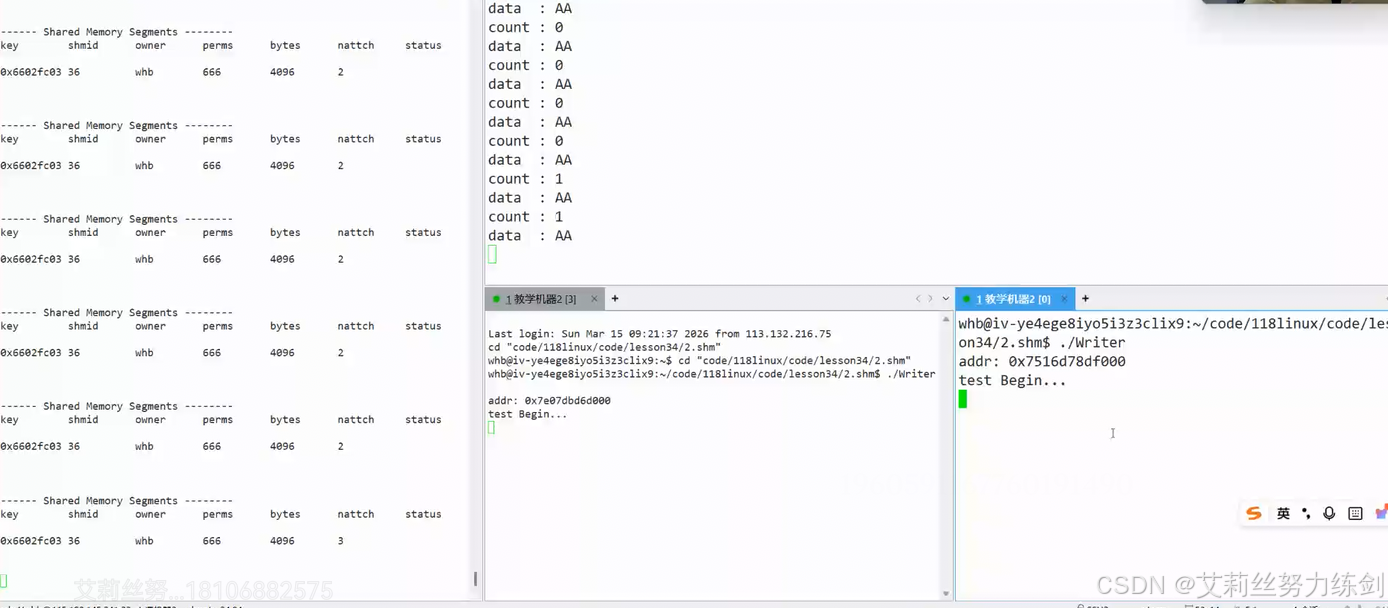
出现了覆盖和清空问题,我们可由此得出结论3.
6.7.4.3 结论3
- 结论3:共享内存没有自带保护机制(不是说正在写/读的时候就不能读写了),任何挂接到地址空间的进程都可以随时访问共享内存!
读端可能在写端只写了一半就把数据取走了------共享内存没有自带保护机制!
怎么保护呢?通过信号量来保护。
真正的实现共享内存保护得利用我们的信号量。
6.7.5 共享内存的大小设置
大小设置建议设置为4096的整数倍。
- 如果设置成非4096的整数倍呢?
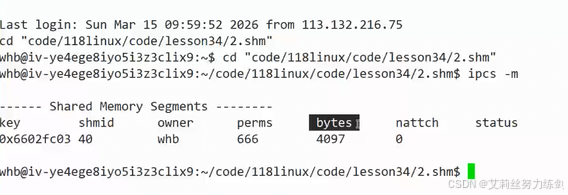
底层操作系统是按4096对齐向上申请的,换言之设置4097,有4095的空间被浪费了。
万一访问越界了,但是因为申请了4096*2,出错了也不知道,你会不会怪操作系统?
- 写的是4097,实际申请的是4096*2
结尾
uu们,本文的内容到这里就全部结束了,艾莉丝在这里再次感谢您的阅读!
结语:希望对学习Linux相关内容的uu有所帮助,不要忘记给博主"一键四连"哦!
往期回顾:
🗡博主在这里放了一只小狗,大家看完了摸摸小狗放松一下吧!🗡 ૮₍ ˶ ˊ ᴥ ˋ˶₎ა
