Ultralytics Docker 安装使用教程(以训练 YOLO26 模型为例)
- 前言
- 环境要求
- 相关介绍
-
- [🐳 Docker 简介](#🐳 Docker 简介)
-
- [💡 核心概念:三大基石](#💡 核心概念:三大基石)
- [⚡ Docker vs 传统虚拟机 (VM)](#⚡ Docker vs 传统虚拟机 (VM))
- [🌟 为什么大家都在用 Docker?(核心优势)](#🌟 为什么大家都在用 Docker?(核心优势))
- [🛠️ Docker 是如何工作的?(技术原理简述)](#🛠️ Docker 是如何工作的?(技术原理简述))
- [🚀 常见应用场景](#🚀 常见应用场景)
- [📝 总结](#📝 总结)
- [Ultralytics Docker 安装使用教程](#Ultralytics Docker 安装使用教程)
-
- [安装 Ultralytics Docker 镜像](#安装 Ultralytics Docker 镜像)
- [在 Docker 容器中运行 Ultralytics](#在 Docker 容器中运行 Ultralytics)
-
- [仅使用 CPU](#仅使用 CPU)
- [使用 GPU](#使用 GPU)
- 关于文件可访问性的说明
- [在 Docker 容器中训练 YOLO26 模型](#在 Docker 容器中训练 YOLO26 模型)
-
- [仅使用 CPU](#仅使用 CPU)
- [使用 GPU](#使用 GPU)
- 常见问题
-
- [RuntimeError: unable to allocate shared memory(shm) for file </torch_29_1189891355_15>: Resource temporarily unavailable (11) Exception in thread Thread-14 (_pin_memory_loop):](#RuntimeError: unable to allocate shared memory(shm) for file </torch_29_1189891355_15>: Resource temporarily unavailable (11) Exception in thread Thread-14 (_pin_memory_loop):)
- 参考
前言
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏、人工智能混合编程实践专栏或我的个人主页查看
- YOLOs-CPP:一个免费开源的YOLO全系列C++推理库(以YOLO26为例)
- PaddleOCR:Win10上安装使用PPOCRLabel标注工具
- 目标检测:使用自己的数据集微调DEIMv2进行物体检测
- 图像分割:PyTorch从零开始实现SegFormer语义分割
- 图像超分:使用自己的数据集微调Real-ESRGAN-x4plus进行超分重建
- 图像生成:PyTorch从零开始实现一个简单的扩散模型
- Stable Diffusion:使用自己的数据集微调 Stable Diffusion 3.5 LoRA 文生图模型
- 图像超分:使用自己的数据集微调Real-ESRGAN-x2plus进行超分重建
- Anomalib:使用Anomalib 2.1.0训练自己的数据集进行异常检测
- Anomalib:在Linux服务器上安装使用Anomalib 2.1.0
- 人工智能混合编程实践:C++调用封装好的DLL进行异常检测推理
- 人工智能混合编程实践:C++调用封装好的DLL进行FP16图像超分重建(v3.0)
- 隔离系统Python:源码编译3.11.8到自定义目录(含PGO性能优化)
- 在线机的Python环境迁移到离线机上
- Nuitka 将 Python 脚本封装为 .pyd 或 .so 文件
- Ultralytics:使用 YOLO11 进行速度估计
- Ultralytics:使用 YOLO11 进行物体追踪
- Ultralytics:使用 YOLO11 进行物体计数
- Ultralytics:使用 YOLO11 进行目标打码
- 人工智能混合编程实践:C++调用Python ONNX进行YOLOv8推理
- 人工智能混合编程实践:C++调用封装好的DLL进行YOLOv8实例分割
- 人工智能混合编程实践:C++调用Python ONNX进行图像超分重建
- 人工智能混合编程实践:C++调用Python AgentOCR进行文本识别
- 通过计算实例简单地理解PatchCore异常检测
- Python将YOLO格式实例分割数据集转换为COCO格式实例分割数据集
- YOLOv8 Ultralytics:使用Ultralytics框架训练RT-DETR实时目标检测模型
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
- Stable Diffusion:在服务器上部署使用Stable Diffusion WebUI进行AI绘图(v2.0)
- Stable Diffusion:使用自己的数据集微调训练LoRA模型(v2.0)
环境要求
- Ubuntu 20.04 LTS
- Docker version 28.1.1
相关介绍
🐳 Docker 简介
Docker 是一个开源的应用容器引擎 ,基于 Go 语言开发,遵循 Apache 2.0 协议。它的核心理念是 "Build, Ship and Run Any App, Anywhere"(在任何地方构建、交付和运行任何应用)。
简单来说,Docker 让开发者可以将应用程序及其所有依赖项(库、配置文件、环境变量等)打包到一个轻量级、可移植的容器中,从而彻底解决"在我机器上能跑,在你机器上就跑不起来"的经典难题。
💡 核心概念:三大基石
理解 Docker,只需掌握这三个核心概念:
| 概念 | 英文 | 比喻 | 说明 |
|---|---|---|---|
| 镜像 | Image | 📦 光盘/安装包 | 一个只读的模板。它包含了运行应用所需的代码、运行时环境、库和配置。例如你列表中的 nvidia/cuda:12.0... 就是一个镜像。 |
| 容器 | Container | 🚀 运行的程序 | 镜像运行时的实例。你可以启动、停止、移动或删除容器。容器之间是相互隔离的。你之前用 docker ps 看到的就是正在运行的容器。 |
| 仓库 | Repository | 🏪 应用商店 | 存放镜像的地方。最著名的是 Docker Hub(类似 GitHub 之于代码),你也可以搭建私有仓库(如你看到的 swr.cn-north-4... 华为云仓库)。 |
关系公式 :
仓库下载镜像→ \rightarrow →镜像启动 → \rightarrow →容器
⚡ Docker vs 传统虚拟机 (VM)
这是理解 Docker 优势的关键。
| 特性 | Docker 容器 | 传统虚拟机 (VM) |
|---|---|---|
| 架构原理 | 操作系统层虚拟化。容器共享宿主机的 Linux 内核,只隔离用户空间。 | 硬件层虚拟化。每个 VM 都有完整的 Guest OS(内核 + 系统)。 |
| 启动速度 | 秒级 (甚至毫秒级) | 分钟级 (需启动完整操作系统) |
| 资源占用 | 极轻 (MB 级内存,GB 级磁盘) | 重 (GB 级内存,几十 GB 磁盘) |
| 性能损耗 | 接近原生 (直接调用宿主机内核) | 有损耗 (需经过 Hypervisor 转换) |
| 隔离性 | 进程/网络/文件系统隔离 (较弱,但足够应用使用) | 完全隔离 (更强,适合多租户安全场景) |
| 典型用途 | 微服务、CI/CD、快速部署、开发环境 | 需要完整 OS 内核、强安全隔离的场景 |
图解差异:
- VM : 应用 A + Binaries/Libs + Guest OS + Hypervisor + Host OS
- Docker : 应用 A + Binaries/Libs + Docker Engine + Host OS
(Docker 省去了厚重的 Guest OS 和 Hypervisor 层)
🌟 为什么大家都在用 Docker?(核心优势)
-
环境一致性 (Consistency)
- 痛点:开发环境是 Ubuntu 20.04 + Python 3.8,生产环境是 CentOS 7 + Python 3.6,导致代码上线就崩。
- Docker 解法 :开发、测试、生产使用完全相同的镜像。"一次构建,处处运行"。
-
轻量高效 (Lightweight)
- 一台物理机可能只能跑 5 个虚拟机,但可以轻松跑几十个甚至上百个 Docker 容器。这对于资源受限的服务器或需要大规模扩缩容的场景(如双 11 流量洪峰)至关重要。
-
快速部署与扩展 (Scalability)
- 启动一个 Web 服务只需几秒钟。配合 Kubernetes (K8s),可以实现秒级自动扩容。
-
隔离性 (Isolation)
- 你可以在同一台服务器上同时运行需要 PHP 5.6 的老项目和需要 Node.js 20 的新项目,它们互不干扰,依赖库冲突不存在了。
- 正如你之前的操作:同时运行 CUDA 11.1 和 CUDA 12.0 的容器,互不影响。
-
版本控制与复用
- 镜像可以像代码一样进行版本管理 (
v1,v2,latest)。如果新版本有问题,一键回滚到旧版本镜像即可。
- 镜像可以像代码一样进行版本管理 (
🛠️ Docker 是如何工作的?(技术原理简述)
Docker 利用了 Linux 内核的三大特性来实现"魔术":
- Namespaces (命名空间) :实现隔离 。
- 让容器觉得自己是独立的,拥有独立的进程树、网络接口、挂载点、用户 ID 等。容器内的 PID 1 不等于宿主机的 PID 1。
- Cgroups (控制组) :实现资源限制 。
- 限制容器能使用的 CPU 时间片、内存大小、磁盘 IO 等,防止某个容器把宿主机资源吃光。
- UnionFS (联合文件系统) :实现分层存储 。
- 镜像是由一层层只读层叠加而成的。当你修改容器文件时,会在最上层创建一个可写层。这使得镜像复用性极高(多个镜像可以共享基础层,节省空间)。
🚀 常见应用场景
- Web 应用部署:Nginx, Tomcat, Node.js 等服务的一键启动。
- 持续集成/持续部署 (CI/CD):在 Jenkins/GitLab CI 中,每次构建都使用干净的容器环境,保证构建结果纯净。
- 微服务架构:将一个大应用拆分成几十个小服务,每个服务独立打包、独立伸缩。
- 数据科学与 AI:正如你在做的,快速拉起包含特定版本 CUDA、cuDNN、PyTorch/TensorFlow 的环境,无需在宿主机痛苦地配置驱动和库。
- 临时测试环境 :测试完数据库新版本或中间件后,直接
docker rm删除,不留垃圾。
📝 总结
Docker 不仅仅是一个工具,它代表了现代软件交付的一种标准方式。它将基础设施代码化,让运维变得像开发一样简单可控。对于开发者而言,它是摆脱"环境配置地狱"的终极武器;对于运维而言,它是实现自动化和弹性伸缩的基石。
Ultralytics Docker 安装使用教程
安装 Ultralytics Docker 镜像
Ultralytics 提供了多个针对各种平台和用例优化的 Docker 镜像:
- Dockerfile: GPU 镜像,非常适合训练。
- Dockerfile-arm64: 适用于 ARM64 架构,适合 Raspberry Pi 等设备。
- Dockerfile-cpu: 仅 CPU 版本,适用于推理和非 GPU 环境。
- Dockerfile-jetson-jetpack4: 针对运行 NVIDIA JetPack 4 的 NVIDIA Jetson 设备进行了优化。
- Dockerfile-jetson-jetpack5: 针对运行 NVIDIA JetPack 5 的 NVIDIA Jetson 设备进行了优化。
- Dockerfile-jetson-jetpack6: 针对运行 NVIDIA JetPack 6 的 NVIDIA Jetson 设备进行了优化。
- Dockerfile-jupyter: 用于在浏览器中使用 JupyterLab 进行交互式开发。
- Dockerfile-nvidia-arm64:适用于NVIDIA ARM64设备,例如Jetson AGX Thor和DGX Spark,支持JetPack 7.0和DGX OS。
- Dockerfile-python: 适用于轻量级应用程序的最小 Python 环境。
- Dockerfile-python-export:扩展了完整导出功能的最小Python镜像,用于YOLO模型转换。
- Dockerfile-conda: 包含 Miniconda3 和通过 Conda 安装的 Ultralytics 包。
- Dockerfile-export:预装了所有导出格式依赖项的GPU镜像,用于模型转换和基准测试。
要拉取最新的镜像,请执行以下操作:
bash
# Pull the latest Ultralytics image from Docker Hub
sudo docker pull ultralytics/ultralytics:latest
在 Docker 容器中运行 Ultralytics
以下是如何执行 Ultralytics Docker 容器:
仅使用 CPU
bash
# Run without GPU
sudo docker run -it --ipc=host ultralytics/ultralytics:latest使用 GPU
bash
# Run with all GPUs
sudo docker run -it --ipc=host --gpus all ultralytics/ultralytics:latest
# Run specifying which GPUs to use
sudo docker run -it --ipc=host --gpus '"device=2,3"' ultralytics/ultralytics:latest字段 -it flag 分配一个伪 TTY 并保持 stdin 打开,允许您与容器交互。The --ipc=host flag 允许共享主机的 IPC 命名空间,这对于在进程之间共享内存至关重要。The --gpus flag 允许容器访问主机的 GPU。
关于文件可访问性的说明
要在容器中使用本地计算机上的文件,可以使用 Docker 卷:
bash
# Mount a local directory into the container
sudo docker run -it --ipc=host --gpus all -v /path/on/host:/path/in/container ultralytics/ultralytics:latest替换 /path/on/host 是本地计算机上的目录路径, /path/in/container 是 Docker 容器内的目标路径。
在 Docker 容器中训练 YOLO26 模型
训练输出保存到 /ultralytics/runs/<task>/<name>/ 默认情况下在容器内部。如果不挂载宿主目录,当容器被移除时,输出将会丢失。
要持久化训练输出:
仅使用 CPU
bash
# Recommended: mount workspace and specify project path
sudo docker run --rm -it -v "$(pwd)":/w -w /w ultralytics/ultralytics:latest \
yolo train model=yolo26n.pt data=coco8.yaml project=/w/runs这将所有训练输出保存到 ./runs 您的宿主机上。
bash
docker run --rm -it -v "$(pwd)":/w -w /w ultralytics/ultralytics:latest
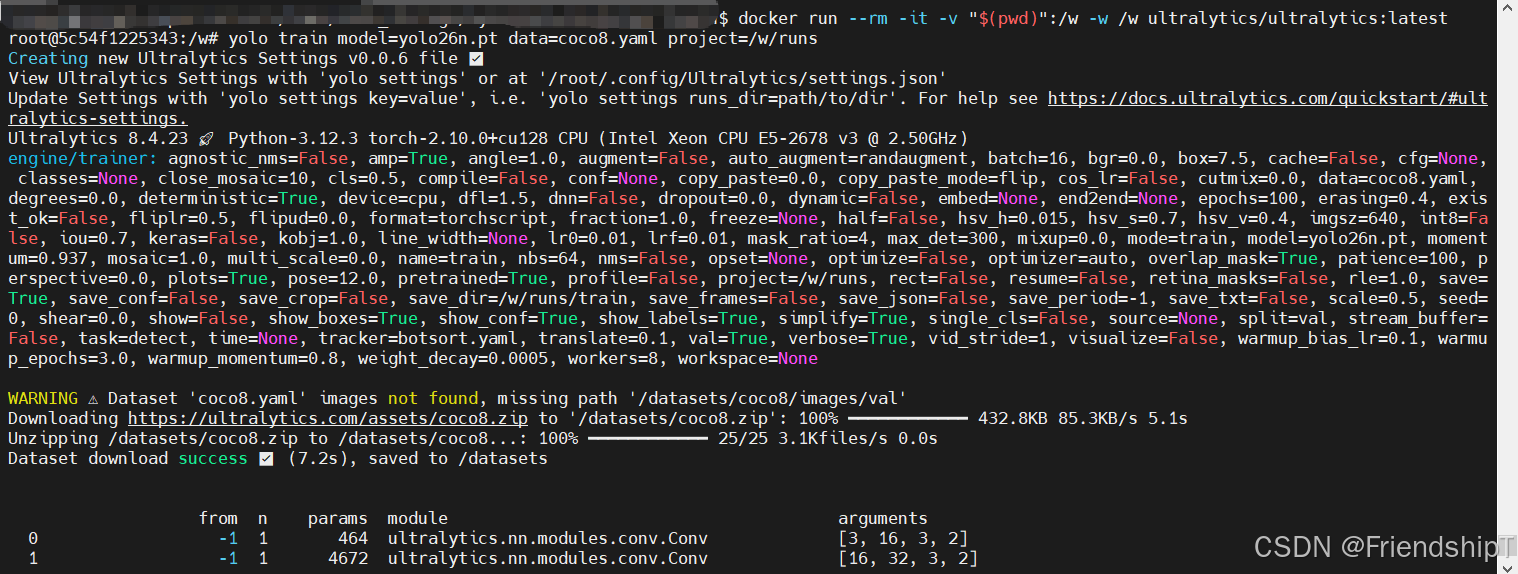
root@5c54f1225343:/w# yolo train model=yolo26n.pt data=coco8.yaml project=/w/runs
Creating new Ultralytics Settings v0.0.6 file ✅
View Ultralytics Settings with 'yolo settings' or at '/root/.config/Ultralytics/settings.json'
Update Settings with 'yolo settings key=value', i.e. 'yolo settings runs_dir=path/to/dir'. For help see https://docs.ultralytics.com/quickstart/#ultralytics-settings.
Ultralytics 8.4.23 🚀 Python-3.12.3 torch-2.10.0+cu128 CPU (Intel Xeon CPU E5-2678 v3 @ 2.50GHz)
engine/trainer: agnostic_nms=False, amp=True, angle=1.0, augment=False, auto_augment=randaugment, batch=16, bgr=0.0, box=7.5, cache=False, cfg=None, classes=None, close_mosaic=10, cls=0.5, compile=False, conf=None, copy_paste=0.0, copy_paste_mode=flip, cos_lr=False, cutmix=0.0, data=coco8.yaml, degrees=0.0, deterministic=True, device=cpu, dfl=1.5, dnn=False, dropout=0.0, dynamic=False, embed=None, end2end=None, epochs=100, erasing=0.4, exist_ok=False, fliplr=0.5, flipud=0.0, format=torchscript, fraction=1.0, freeze=None, half=False, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, imgsz=640, int8=False, iou=0.7, keras=False, kobj=1.0, line_width=None, lr0=0.01, lrf=0.01, mask_ratio=4, max_det=300, mixup=0.0, mode=train, model=yolo26n.pt, momentum=0.937, mosaic=1.0, multi_scale=0.0, name=train, nbs=64, nms=False, opset=None, optimize=False, optimizer=auto, overlap_mask=True, patience=100, perspective=0.0, plots=True, pose=12.0, pretrained=True, profile=False, project=/w/runs, rect=False, resume=False, retina_masks=False, rle=1.0, save=True, save_conf=False, save_crop=False, save_dir=/w/runs/train, save_frames=False, save_json=False, save_period=-1, save_txt=False, scale=0.5, seed=0, shear=0.0, show=False, show_boxes=True, show_conf=True, show_labels=True, simplify=True, single_cls=False, source=None, split=val, stream_buffer=False, task=detect, time=None, tracker=botsort.yaml, translate=0.1, val=True, verbose=True, vid_stride=1, visualize=False, warmup_bias_lr=0.1, warmup_epochs=3.0, warmup_momentum=0.8, weight_decay=0.0005, workers=8, workspace=None
WARNING ⚠️ Dataset 'coco8.yaml' images not found, missing path '/datasets/coco8/images/val'
Downloading https://ultralytics.com/assets/coco8.zip to '/datasets/coco8.zip': 100% ━━━━━━━━━━━━ 432.8KB 85.3KB/s 5.1s
Unzipping /datasets/coco8.zip to /datasets/coco8...: 100% ━━━━━━━━━━━━ 25/25 3.1Kfiles/s 0.0s
Dataset download success ✅ (7.2s), saved to /datasets
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 6640 ultralytics.nn.modules.block.C3k2 [32, 64, 1, False, 0.25]
3 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
4 -1 1 26080 ultralytics.nn.modules.block.C3k2 [64, 128, 1, False, 0.25]
5 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
6 -1 1 87040 ultralytics.nn.modules.block.C3k2 [128, 128, 1, True]
7 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
8 -1 1 346112 ultralytics.nn.modules.block.C3k2 [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5, 3, True]
10 -1 1 249728 ultralytics.nn.modules.block.C2PSA [256, 256, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 119808 ultralytics.nn.modules.block.C3k2 [384, 128, 1, True]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 34304 ultralytics.nn.modules.block.C3k2 [256, 64, 1, True]
17 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 95232 ultralytics.nn.modules.block.C3k2 [192, 128, 1, True]
20 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 463104 ultralytics.nn.modules.block.C3k2 [384, 256, 1, True, 0.5, True]
23 [16, 19, 22] 1 309656 ultralytics.nn.modules.head.Detect [80, 1, True, [64, 128, 256]]
YOLO26n summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
Transferred 708/708 items from pretrained weights
train: Fast image access ✅ (ping: 0.0±0.0 ms, read: 1217.9±368.4 MB/s, size: 50.0 KB)
train: Scanning /datasets/coco8/labels/train... 4 images, 0 backgrounds, 0 corrupt: 100% ━━━━━━━━━━━━ 4/4 223.2it/s 0.0s
train: New cache created: /datasets/coco8/labels/train.cache
albumentations: Blur(p=0.01, blur_limit=(3, 7)), MedianBlur(p=0.01, blur_limit=(3, 7)), ToGray(p=0.01, method='weighted_average', num_output_channels=3), CLAHE(p=0.01, clip_limit=(1.0, 4.0), tile_grid_size=(8, 8))
val: Fast image access ✅ (ping: 0.0±0.0 ms, read: 1454.6±367.6 MB/s, size: 54.0 KB)
val: Scanning /datasets/coco8/labels/val... 4 images, 0 backgrounds, 0 corrupt: 100% ━━━━━━━━━━━━ 4/4 813.7it/s 0.0s
val: New cache created: /datasets/coco8/labels/val.cache
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: AdamW(lr=0.000119, momentum=0.9) with parameter groups 114 weight(decay=0.0), 126 weight(decay=0.0005), 126 bias(decay=0.0)
Plotting labels to /w/runs/train/labels.jpg...
Image sizes 640 train, 640 val
Using 0 dataloader workers
Logging results to /w/runs/train
Starting training for 100 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/100 0G 1.526 3.136 0.02434 31 640: 100% ━━━━━━━━━━━━ 1/1 1.0it/s 1.0s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 3.0it/s 0.3s
all 4 17 0.901 0.653 0.905 0.668
......
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
100/100 0G 0.727 0.6156 0.01141 13 640: 100% ━━━━━━━━━━━━ 1/1 1.3it/s 0.8s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 3.3it/s 0.3s
all 4 17 0.642 0.667 0.739 0.538
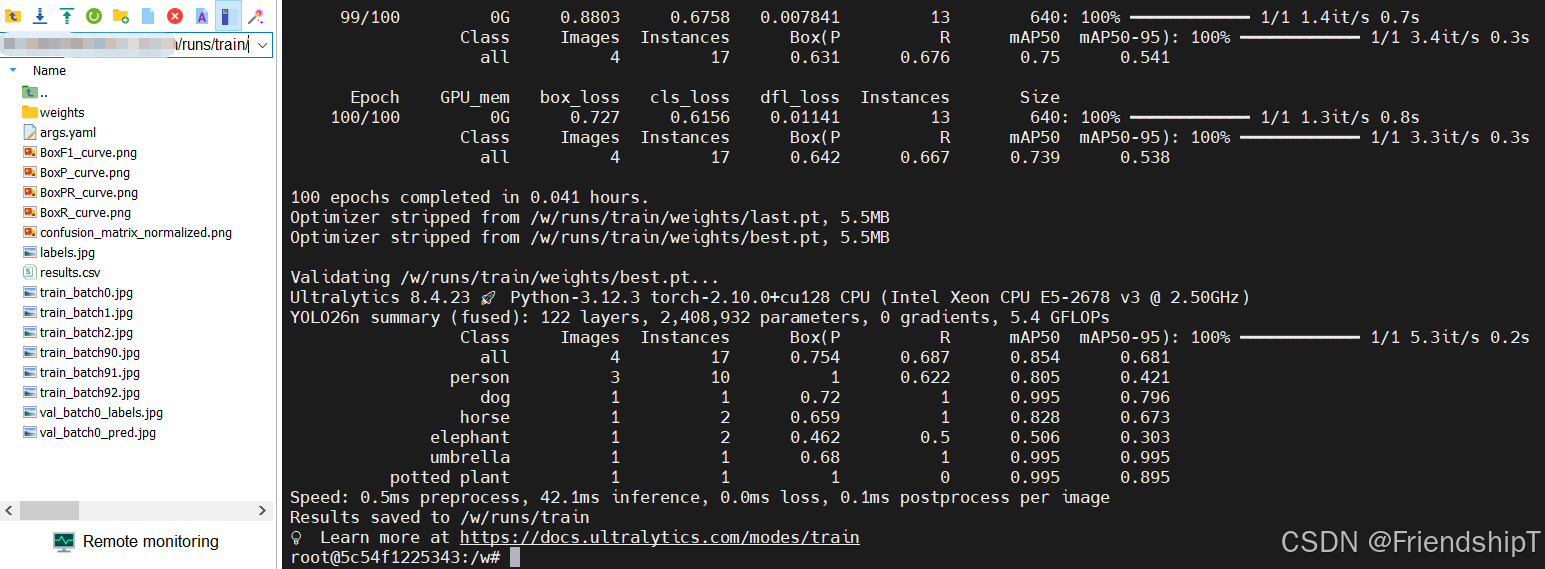
100 epochs completed in 0.041 hours.
Optimizer stripped from /w/runs/train/weights/last.pt, 5.5MB
Optimizer stripped from /w/runs/train/weights/best.pt, 5.5MB
Validating /w/runs/train/weights/best.pt...
Ultralytics 8.4.23 🚀 Python-3.12.3 torch-2.10.0+cu128 CPU (Intel Xeon CPU E5-2678 v3 @ 2.50GHz)
YOLO26n summary (fused): 122 layers, 2,408,932 parameters, 0 gradients, 5.4 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 5.3it/s 0.2s
all 4 17 0.754 0.687 0.854 0.681
person 3 10 1 0.622 0.805 0.421
dog 1 1 0.72 1 0.995 0.796
horse 1 2 0.659 1 0.828 0.673
elephant 1 2 0.462 0.5 0.506 0.303
umbrella 1 1 0.68 1 0.995 0.995
potted plant 1 1 1 0 0.995 0.895
Speed: 0.5ms preprocess, 42.1ms inference, 0.0ms loss, 0.1ms postprocess per image
Results saved to /w/runs/train
💡 Learn more at https://docs.ultralytics.com/modes/train
root@5c54f1225343:/w#使用 GPU
bash
# Recommended: mount workspace and specify project path
sudo docker run --rm -it --gpus all -v "$(pwd)":/w -w /w ultralytics/ultralytics:latest \
yolo train model=yolo26n.pt data=coco8.yaml project=/w/runs workers=0这将所有训练输出保存到 ./runs 您的宿主机上。
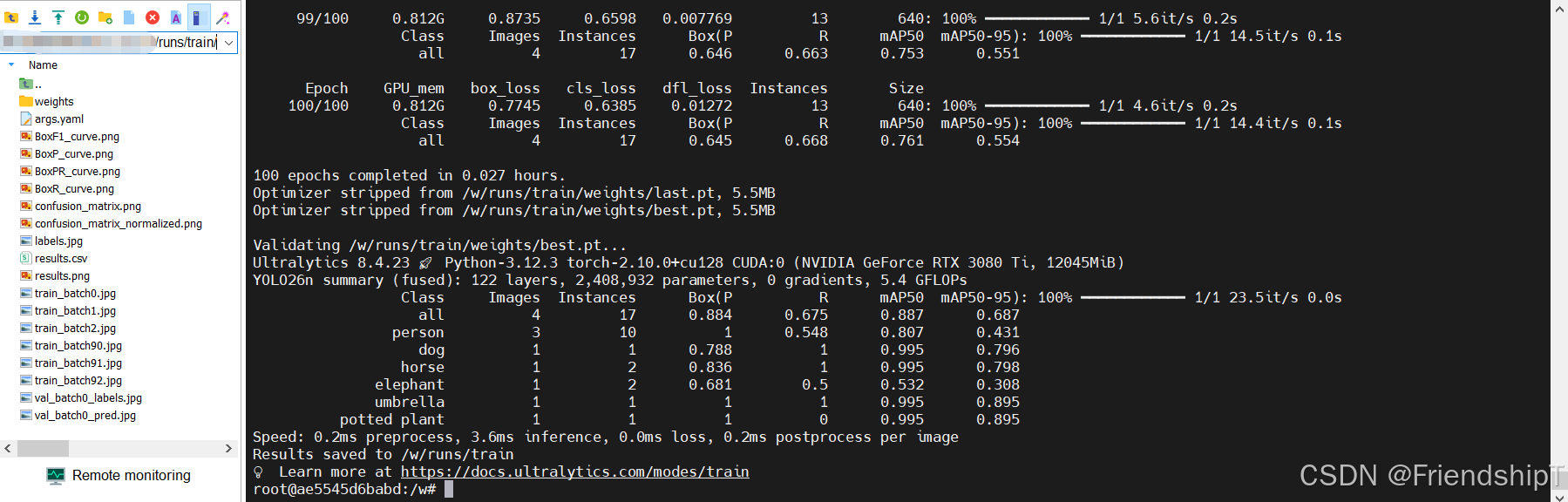
bash
docker run --rm -it --gpus all -v "$(pwd)":/w -w /w ultralytics/ultralytics:latest
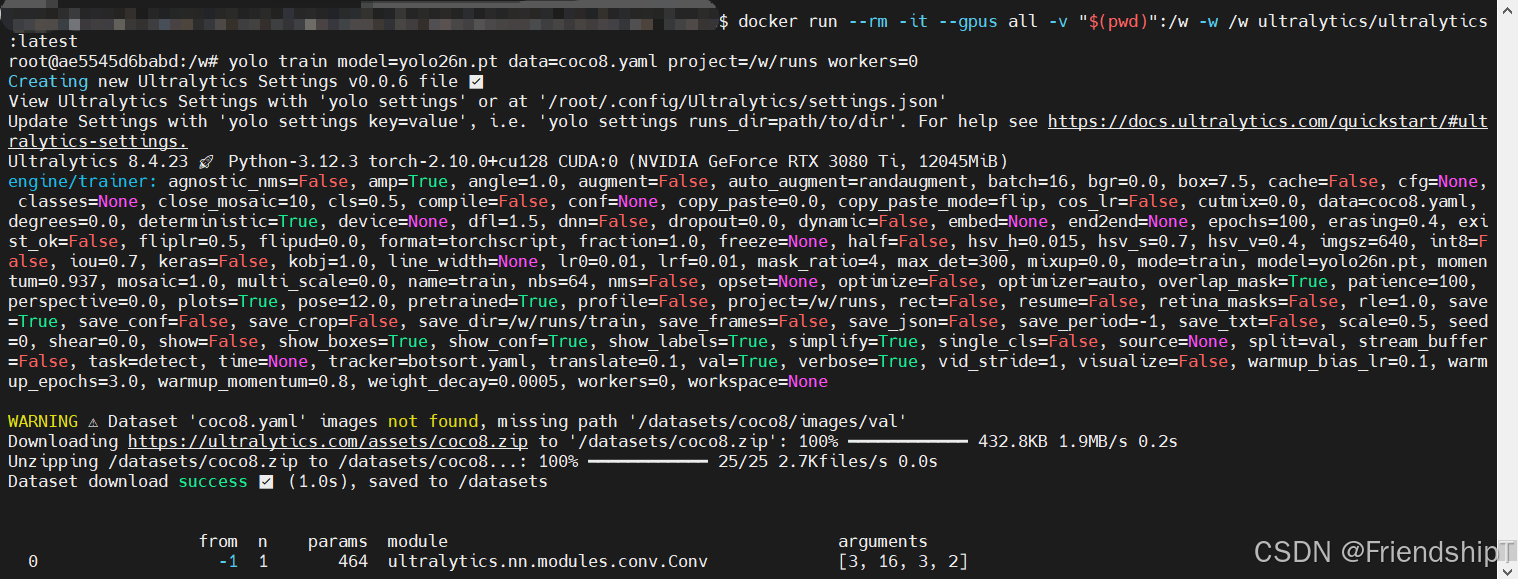
root@ae5545d6babd:/w# yolo train model=yolo26n.pt data=coco8.yaml project=/w/runs workers=0
Creating new Ultralytics Settings v0.0.6 file ✅
View Ultralytics Settings with 'yolo settings' or at '/root/.config/Ultralytics/settings.json'
Update Settings with 'yolo settings key=value', i.e. 'yolo settings runs_dir=path/to/dir'. For help see https://docs.ultralytics.com/quickstart/#ultralytics-settings.
Ultralytics 8.4.23 🚀 Python-3.12.3 torch-2.10.0+cu128 CUDA:0 (NVIDIA GeForce RTX 3080 Ti, 12045MiB)
engine/trainer: agnostic_nms=False, amp=True, angle=1.0, augment=False, auto_augment=randaugment, batch=16, bgr=0.0, box=7.5, cache=False, cfg=None, classes=None, close_mosaic=10, cls=0.5, compile=False, conf=None, copy_paste=0.0, copy_paste_mode=flip, cos_lr=False, cutmix=0.0, data=coco8.yaml, degrees=0.0, deterministic=True, device=None, dfl=1.5, dnn=False, dropout=0.0, dynamic=False, embed=None, end2end=None, epochs=100, erasing=0.4, exist_ok=False, fliplr=0.5, flipud=0.0, format=torchscript, fraction=1.0, freeze=None, half=False, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, imgsz=640, int8=False, iou=0.7, keras=False, kobj=1.0, line_width=None, lr0=0.01, lrf=0.01, mask_ratio=4, max_det=300, mixup=0.0, mode=train, model=yolo26n.pt, momentum=0.937, mosaic=1.0, multi_scale=0.0, name=train, nbs=64, nms=False, opset=None, optimize=False, optimizer=auto, overlap_mask=True, patience=100, perspective=0.0, plots=True, pose=12.0, pretrained=True, profile=False, project=/w/runs, rect=False, resume=False, retina_masks=False, rle=1.0, save=True, save_conf=False, save_crop=False, save_dir=/w/runs/train, save_frames=False, save_json=False, save_period=-1, save_txt=False, scale=0.5, seed=0, shear=0.0, show=False, show_boxes=True, show_conf=True, show_labels=True, simplify=True, single_cls=False, source=None, split=val, stream_buffer=False, task=detect, time=None, tracker=botsort.yaml, translate=0.1, val=True, verbose=True, vid_stride=1, visualize=False, warmup_bias_lr=0.1, warmup_epochs=3.0, warmup_momentum=0.8, weight_decay=0.0005, workers=0, workspace=None
WARNING ⚠️ Dataset 'coco8.yaml' images not found, missing path '/datasets/coco8/images/val'
Downloading https://ultralytics.com/assets/coco8.zip to '/datasets/coco8.zip': 100% ━━━━━━━━━━━━ 432.8KB 1.9MB/s 0.2s
Unzipping /datasets/coco8.zip to /datasets/coco8...: 100% ━━━━━━━━━━━━ 25/25 2.7Kfiles/s 0.0s
Dataset download success ✅ (1.0s), saved to /datasets
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 6640 ultralytics.nn.modules.block.C3k2 [32, 64, 1, False, 0.25]
3 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
4 -1 1 26080 ultralytics.nn.modules.block.C3k2 [64, 128, 1, False, 0.25]
5 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
6 -1 1 87040 ultralytics.nn.modules.block.C3k2 [128, 128, 1, True]
7 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
8 -1 1 346112 ultralytics.nn.modules.block.C3k2 [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5, 3, True]
10 -1 1 249728 ultralytics.nn.modules.block.C2PSA [256, 256, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 119808 ultralytics.nn.modules.block.C3k2 [384, 128, 1, True]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 34304 ultralytics.nn.modules.block.C3k2 [256, 64, 1, True]
17 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 95232 ultralytics.nn.modules.block.C3k2 [192, 128, 1, True]
20 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 463104 ultralytics.nn.modules.block.C3k2 [384, 256, 1, True, 0.5, True]
23 [16, 19, 22] 1 309656 ultralytics.nn.modules.head.Detect [80, 1, True, [64, 128, 256]]
YOLO26n summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
Transferred 708/708 items from pretrained weights
AMP: running Automatic Mixed Precision (AMP) checks...
AMP: checks passed ✅
train: Fast image access ✅ (ping: 0.0±0.0 ms, read: 1221.4±440.6 MB/s, size: 50.0 KB)
train: Scanning /datasets/coco8/labels/train... 4 images, 0 backgrounds, 0 corrupt: 100% ━━━━━━━━━━━━ 4/4 786.9it/s 0.0s
train: New cache created: /datasets/coco8/labels/train.cache
albumentations: Blur(p=0.01, blur_limit=(3, 7)), MedianBlur(p=0.01, blur_limit=(3, 7)), ToGray(p=0.01, method='weighted_average', num_output_channels=3), CLAHE(p=0.01, clip_limit=(1.0, 4.0), tile_grid_size=(8, 8))
val: Fast image access ✅ (ping: 0.0±0.0 ms, read: 1471.6±370.3 MB/s, size: 54.0 KB)
val: Scanning /datasets/coco8/labels/val... 4 images, 0 backgrounds, 0 corrupt: 100% ━━━━━━━━━━━━ 4/4 884.0it/s 0.0s
val: New cache created: /datasets/coco8/labels/val.cache
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: AdamW(lr=0.000119, momentum=0.9) with parameter groups 114 weight(decay=0.0), 126 weight(decay=0.0005), 126 bias(decay=0.0)
Plotting labels to /w/runs/train/labels.jpg...
Image sizes 640 train, 640 val
Using 0 dataloader workers
Logging results to /w/runs/train
Starting training for 100 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/100 0.758G 1.527 3.137 0.02433 31 640: 100% ━━━━━━━━━━━━ 1/1 12.9s/it 12.9s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 4.1s/it 4.1s
all 4 17 0.9 0.653 0.905 0.669
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/100 0.785G 1.157 3.383 0.01394 25 640: 100% ━━━━━━━━━━━━ 1/1 4.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 11.0it/s 0.1s
all 4 17 0.894 0.656 0.905 0.669
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
3/100 0.785G 1.457 3.427 0.01736 12 640: 100% ━━━━━━━━━━━━ 1/1 4.5it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 11.9it/s 0.1s
all 4 17 0.885 0.666 0.906 0.67
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
4/100 0.785G 1.147 2.331 0.01102 39 640: 100% ━━━━━━━━━━━━ 1/1 3.4it/s 0.3s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.4it/s 0.1s
all 4 17 0.872 0.674 0.906 0.667
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
5/100 0.799G 1.356 2.945 0.01353 47 640: 100% ━━━━━━━━━━━━ 1/1 4.1it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.0it/s 0.1s
all 4 17 0.876 0.673 0.906 0.666
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
6/100 0.799G 1.022 2.174 0.01359 19 640: 100% ━━━━━━━━━━━━ 1/1 4.1it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.0it/s 0.1s
all 4 17 0.884 0.676 0.902 0.668
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
7/100 0.799G 1.729 3.396 0.01833 25 640: 100% ━━━━━━━━━━━━ 1/1 4.1it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.2it/s 0.1s
all 4 17 0.868 0.66 0.901 0.662
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
8/100 0.799G 0.9219 2.75 0.0137 24 640: 100% ━━━━━━━━━━━━ 1/1 4.1it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.0it/s 0.1s
all 4 17 0.863 0.679 0.901 0.664
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
9/100 0.799G 1.286 2.588 0.02375 27 640: 100% ━━━━━━━━━━━━ 1/1 4.1it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.9it/s 0.1s
all 4 17 0.851 0.683 0.902 0.665
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
10/100 0.799G 1.002 2.787 0.01226 18 640: 100% ━━━━━━━━━━━━ 1/1 4.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.84 0.684 0.902 0.661
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
11/100 0.799G 1.434 3.341 0.01908 38 640: 100% ━━━━━━━━━━━━ 1/1 2.6it/s 0.4s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.842 0.686 0.902 0.659
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
12/100 0.799G 1.14 3.208 0.01526 31 640: 100% ━━━━━━━━━━━━ 1/1 4.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.84 0.687 0.892 0.66
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
13/100 0.799G 1.356 2.742 0.02337 27 640: 100% ━━━━━━━━━━━━ 1/1 4.1it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.0it/s 0.1s
all 4 17 0.846 0.686 0.89 0.661
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
14/100 0.799G 0.9143 1.534 0.01358 28 640: 100% ━━━━━━━━━━━━ 1/1 4.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.2it/s 0.1s
all 4 17 0.844 0.687 0.89 0.678
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
15/100 0.799G 1.324 2.071 0.01419 29 640: 100% ━━━━━━━━━━━━ 1/1 4.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.848 0.686 0.89 0.672
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
16/100 0.799G 1.416 1.884 0.02003 20 640: 100% ━━━━━━━━━━━━ 1/1 4.3it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.843 0.687 0.889 0.671
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
17/100 0.801G 0.9366 1.971 0.01584 14 640: 100% ━━━━━━━━━━━━ 1/1 4.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.852 0.684 0.889 0.674
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
18/100 0.801G 1.306 2.802 0.02432 32 640: 100% ━━━━━━━━━━━━ 1/1 5.3it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.9it/s 0.1s
all 4 17 0.852 0.684 0.889 0.674
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
19/100 0.807G 1.004 2.505 0.01471 25 640: 100% ━━━━━━━━━━━━ 1/1 3.9it/s 0.3s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.0it/s 0.1s
all 4 17 0.853 0.684 0.888 0.675
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
20/100 0.807G 1.011 1.775 0.01018 40 640: 100% ━━━━━━━━━━━━ 1/1 5.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.6it/s 0.1s
all 4 17 0.853 0.684 0.888 0.675
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
21/100 0.807G 1.332 2.164 0.02082 20 640: 100% ━━━━━━━━━━━━ 1/1 4.1it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.864 0.678 0.889 0.671
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
22/100 0.807G 1.017 2.745 0.01047 40 640: 100% ━━━━━━━━━━━━ 1/1 5.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.9it/s 0.1s
all 4 17 0.864 0.678 0.889 0.671
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
23/100 0.807G 1.014 2.084 0.009994 41 640: 100% ━━━━━━━━━━━━ 1/1 4.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.885 0.675 0.887 0.687
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
24/100 0.807G 1.124 1.661 0.01433 22 640: 100% ━━━━━━━━━━━━ 1/1 5.7it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.885 0.675 0.887 0.687
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
25/100 0.807G 1.153 1.786 0.03377 10 640: 100% ━━━━━━━━━━━━ 1/1 4.5it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.2it/s 0.1s
all 4 17 0.855 0.659 0.882 0.687
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
26/100 0.807G 0.9497 1.809 0.008188 38 640: 100% ━━━━━━━━━━━━ 1/1 5.5it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.3it/s 0.1s
all 4 17 0.855 0.659 0.882 0.687
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
27/100 0.807G 1.158 2.802 0.02154 30 640: 100% ━━━━━━━━━━━━ 1/1 4.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.2it/s 0.1s
all 4 17 0.761 0.673 0.854 0.687
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
28/100 0.807G 1.198 2.263 0.01419 25 640: 100% ━━━━━━━━━━━━ 1/1 5.7it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.761 0.673 0.854 0.687
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
29/100 0.807G 1.017 1.511 0.01143 35 640: 100% ━━━━━━━━━━━━ 1/1 4.0it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.749 0.665 0.854 0.686
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
30/100 0.807G 0.9891 1.789 0.009264 43 640: 100% ━━━━━━━━━━━━ 1/1 5.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.7it/s 0.1s
all 4 17 0.749 0.665 0.854 0.686
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
31/100 0.807G 1.104 1.837 0.01183 34 640: 100% ━━━━━━━━━━━━ 1/1 4.0it/s 0.3s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.761 0.682 0.854 0.678
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
32/100 0.807G 0.9757 1.795 0.01225 23 640: 100% ━━━━━━━━━━━━ 1/1 5.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.7it/s 0.1s
all 4 17 0.761 0.682 0.854 0.678
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
33/100 0.807G 0.984 1.725 0.0143 28 640: 100% ━━━━━━━━━━━━ 1/1 4.0it/s 0.3s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.723 0.687 0.799 0.647
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
34/100 0.807G 1.202 2.268 0.01781 25 640: 100% ━━━━━━━━━━━━ 1/1 5.7it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.2it/s 0.1s
all 4 17 0.723 0.687 0.799 0.647
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
35/100 0.807G 1.082 1.87 0.01773 23 640: 100% ━━━━━━━━━━━━ 1/1 4.3it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.2it/s 0.1s
all 4 17 0.724 0.686 0.84 0.673
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
36/100 0.807G 0.9859 1.457 0.01099 37 640: 100% ━━━━━━━━━━━━ 1/1 5.7it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.724 0.686 0.84 0.673
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
37/100 0.807G 0.8247 1.294 0.01027 35 640: 100% ━━━━━━━━━━━━ 1/1 4.0it/s 0.3s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.694 0.703 0.799 0.648
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
38/100 0.807G 1.043 1.446 0.01061 25 640: 100% ━━━━━━━━━━━━ 1/1 5.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.7it/s 0.1s
all 4 17 0.694 0.703 0.799 0.648
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
39/100 0.807G 1.243 1.849 0.01642 44 640: 100% ━━━━━━━━━━━━ 1/1 4.5it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.2it/s 0.1s
all 4 17 0.709 0.69 0.799 0.643
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
40/100 0.807G 0.6888 1.515 0.008809 24 640: 100% ━━━━━━━━━━━━ 1/1 5.5it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.2it/s 0.1s
all 4 17 0.709 0.69 0.799 0.643
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
41/100 0.812G 1.215 2.49 0.02353 23 640: 100% ━━━━━━━━━━━━ 1/1 4.5it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.671 0.688 0.794 0.64
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
42/100 0.812G 1.123 2.082 0.02025 33 640: 100% ━━━━━━━━━━━━ 1/1 5.6it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.2it/s 0.1s
all 4 17 0.671 0.688 0.794 0.64
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
43/100 0.812G 1.107 1.691 0.01037 32 640: 100% ━━━━━━━━━━━━ 1/1 4.5it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.728 0.666 0.825 0.655
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
44/100 0.812G 0.8885 1.29 0.008639 44 640: 100% ━━━━━━━━━━━━ 1/1 5.9it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.2it/s 0.1s
all 4 17 0.728 0.666 0.825 0.655
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
45/100 0.812G 0.8531 1.469 0.01069 44 640: 100% ━━━━━━━━━━━━ 1/1 4.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.727 0.666 0.831 0.651
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
46/100 0.812G 0.9035 1.627 0.01179 23 640: 100% ━━━━━━━━━━━━ 1/1 5.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.6it/s 0.1s
all 4 17 0.727 0.666 0.831 0.651
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
47/100 0.812G 1.222 1.945 0.01925 24 640: 100% ━━━━━━━━━━━━ 1/1 4.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.0it/s 0.1s
all 4 17 0.671 0.701 0.799 0.637
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
48/100 0.812G 1.044 1.15 0.0107 38 640: 100% ━━━━━━━━━━━━ 1/1 5.5it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.2it/s 0.1s
all 4 17 0.671 0.701 0.799 0.637
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
49/100 0.812G 0.9905 2.705 0.01324 18 640: 100% ━━━━━━━━━━━━ 1/1 4.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.2it/s 0.1s
all 4 17 0.719 0.666 0.799 0.624
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
50/100 0.812G 0.8112 1.097 0.01106 32 640: 100% ━━━━━━━━━━━━ 1/1 5.8it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.2it/s 0.1s
all 4 17 0.719 0.666 0.799 0.624
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
51/100 0.812G 0.6484 1.07 0.008012 26 640: 100% ━━━━━━━━━━━━ 1/1 4.0it/s 0.3s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.718 0.685 0.799 0.62
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
52/100 0.812G 0.9055 1.56 0.008298 16 640: 100% ━━━━━━━━━━━━ 1/1 5.1it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.7it/s 0.1s
all 4 17 0.718 0.685 0.799 0.62
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
53/100 0.812G 0.8651 1.675 0.01241 32 640: 100% ━━━━━━━━━━━━ 1/1 5.0it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.6it/s 0.1s
all 4 17 0.718 0.685 0.799 0.62
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
54/100 0.812G 1.259 1.107 0.02039 20 640: 100% ━━━━━━━━━━━━ 1/1 4.5it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.4it/s 0.1s
all 4 17 0.812 0.63 0.854 0.65
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
55/100 0.812G 0.8247 1.347 0.009189 38 640: 100% ━━━━━━━━━━━━ 1/1 5.8it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.4it/s 0.1s
all 4 17 0.812 0.63 0.854 0.65
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
56/100 0.812G 0.9259 1.498 0.01349 30 640: 100% ━━━━━━━━━━━━ 1/1 4.8it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.8it/s 0.1s
all 4 17 0.812 0.63 0.854 0.65
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
57/100 0.812G 1.17 1.779 0.01375 37 640: 100% ━━━━━━━━━━━━ 1/1 3.8it/s 0.3s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.4it/s 0.1s
all 4 17 0.717 0.676 0.84 0.671
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
58/100 0.812G 0.7989 0.9469 0.006683 47 640: 100% ━━━━━━━━━━━━ 1/1 5.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.9it/s 0.1s
all 4 17 0.717 0.676 0.84 0.671
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
59/100 0.812G 1.122 1.41 0.01336 29 640: 100% ━━━━━━━━━━━━ 1/1 5.6it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.3it/s 0.1s
all 4 17 0.717 0.676 0.84 0.671
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
60/100 0.812G 0.7964 2.026 0.01181 12 640: 100% ━━━━━━━━━━━━ 1/1 4.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.5it/s 0.1s
all 4 17 0.695 0.693 0.84 0.653
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
61/100 0.812G 0.8472 1.19 0.01197 30 640: 100% ━━━━━━━━━━━━ 1/1 5.3it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.9it/s 0.1s
all 4 17 0.695 0.693 0.84 0.653
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
62/100 0.812G 0.9836 1.048 0.01124 33 640: 100% ━━━━━━━━━━━━ 1/1 5.7it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.4it/s 0.1s
all 4 17 0.695 0.693 0.84 0.653
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
63/100 0.812G 0.9918 0.964 0.01938 22 640: 100% ━━━━━━━━━━━━ 1/1 4.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.4it/s 0.1s
all 4 17 0.638 0.712 0.771 0.584
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
64/100 0.812G 0.9514 0.938 0.01209 29 640: 100% ━━━━━━━━━━━━ 1/1 5.9it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.3it/s 0.1s
all 4 17 0.638 0.712 0.771 0.584
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
65/100 0.812G 1.021 1.437 0.01171 19 640: 100% ━━━━━━━━━━━━ 1/1 5.6it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.3it/s 0.1s
all 4 17 0.638 0.712 0.771 0.584
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
66/100 0.812G 0.9052 1.368 0.01215 19 640: 100% ━━━━━━━━━━━━ 1/1 4.3it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.4it/s 0.1s
all 4 17 0.703 0.693 0.852 0.654
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
67/100 0.812G 0.9974 2.192 0.01602 35 640: 100% ━━━━━━━━━━━━ 1/1 5.3it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.703 0.693 0.852 0.654
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
68/100 0.812G 1.444 1.847 0.01922 26 640: 100% ━━━━━━━━━━━━ 1/1 5.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.9it/s 0.1s
all 4 17 0.703 0.693 0.852 0.654
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
69/100 0.812G 0.8414 1.084 0.009178 29 640: 100% ━━━━━━━━━━━━ 1/1 4.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.4it/s 0.1s
all 4 17 0.618 0.7 0.768 0.551
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
70/100 0.812G 0.943 1.195 0.01394 21 640: 100% ━━━━━━━━━━━━ 1/1 5.6it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.3it/s 0.1s
all 4 17 0.618 0.7 0.768 0.551
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
71/100 0.812G 1.176 1.882 0.01665 36 640: 100% ━━━━━━━━━━━━ 1/1 5.0it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.9it/s 0.1s
all 4 17 0.618 0.7 0.768 0.551
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
72/100 0.812G 0.8944 0.6715 0.01548 17 640: 100% ━━━━━━━━━━━━ 1/1 4.0it/s 0.3s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.3it/s 0.1s
all 4 17 0.61 0.65 0.797 0.565
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
73/100 0.812G 0.7808 1.411 0.01798 14 640: 100% ━━━━━━━━━━━━ 1/1 5.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.9it/s 0.1s
all 4 17 0.61 0.65 0.797 0.565
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
74/100 0.812G 1.03 1.134 0.008954 50 640: 100% ━━━━━━━━━━━━ 1/1 5.6it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.5it/s 0.1s
all 4 17 0.61 0.65 0.797 0.565
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
75/100 0.812G 1.138 1.145 0.01177 33 640: 100% ━━━━━━━━━━━━ 1/1 4.5it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.5it/s 0.1s
all 4 17 0.615 0.645 0.796 0.564
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
76/100 0.812G 0.8599 0.9685 0.009842 30 640: 100% ━━━━━━━━━━━━ 1/1 5.6it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.4it/s 0.1s
all 4 17 0.615 0.645 0.796 0.564
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
77/100 0.812G 0.9935 1.473 0.01467 20 640: 100% ━━━━━━━━━━━━ 1/1 5.3it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.4it/s 0.1s
all 4 17 0.615 0.645 0.796 0.564
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
78/100 0.812G 0.8064 1.364 0.01162 34 640: 100% ━━━━━━━━━━━━ 1/1 4.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.5it/s 0.1s
all 4 17 0.61 0.651 0.796 0.563
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
79/100 0.812G 1.308 2.554 0.02999 25 640: 100% ━━━━━━━━━━━━ 1/1 5.7it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.5it/s 0.1s
all 4 17 0.61 0.651 0.796 0.563
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
80/100 0.812G 0.9381 0.8484 0.01104 31 640: 100% ━━━━━━━━━━━━ 1/1 5.0it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.61 0.651 0.796 0.563
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
81/100 0.812G 0.9786 1.19 0.02019 23 640: 100% ━━━━━━━━━━━━ 1/1 4.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.2it/s 0.1s
all 4 17 0.808 0.481 0.754 0.514
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
82/100 0.812G 0.8592 0.9912 0.01046 35 640: 100% ━━━━━━━━━━━━ 1/1 5.9it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.4it/s 0.1s
all 4 17 0.808 0.481 0.754 0.514
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
83/100 0.812G 0.9265 0.798 0.008816 35 640: 100% ━━━━━━━━━━━━ 1/1 5.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.4it/s 0.1s
all 4 17 0.808 0.481 0.754 0.514
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
84/100 0.812G 0.8593 1.378 0.01379 33 640: 100% ━━━━━━━━━━━━ 1/1 4.5it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.3it/s 0.1s
all 4 17 0.948 0.461 0.77 0.525
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
85/100 0.812G 0.7474 0.9419 0.008749 38 640: 100% ━━━━━━━━━━━━ 1/1 5.7it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.5it/s 0.1s
all 4 17 0.948 0.461 0.77 0.525
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
86/100 0.812G 0.8745 1.176 0.01113 33 640: 100% ━━━━━━━━━━━━ 1/1 5.1it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.0it/s 0.1s
all 4 17 0.948 0.461 0.77 0.525
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
87/100 0.812G 1.133 1.005 0.01427 35 640: 100% ━━━━━━━━━━━━ 1/1 5.1it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.1it/s 0.1s
all 4 17 0.948 0.461 0.77 0.525
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
88/100 0.812G 0.4922 0.5255 0.008422 17 640: 100% ━━━━━━━━━━━━ 1/1 4.0it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.4it/s 0.1s
all 4 17 0.944 0.464 0.736 0.5
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
89/100 0.812G 1.143 0.8033 0.009638 34 640: 100% ━━━━━━━━━━━━ 1/1 4.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.9it/s 0.1s
all 4 17 0.944 0.464 0.736 0.5
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
90/100 0.812G 1.307 1.52 0.02047 21 640: 100% ━━━━━━━━━━━━ 1/1 5.1it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.0it/s 0.1s
all 4 17 0.944 0.464 0.736 0.5
Closing dataloader mosaic
albumentations: Blur(p=0.01, blur_limit=(3, 7)), MedianBlur(p=0.01, blur_limit=(3, 7)), ToGray(p=0.01, method='weighted_average', num_output_channels=3), CLAHE(p=0.01, clip_limit=(1.0, 4.0), tile_grid_size=(8, 8))
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
91/100 0.812G 0.8567 0.8736 0.007952 13 640: 100% ━━━━━━━━━━━━ 1/1 5.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 11.5it/s 0.1s
all 4 17 0.944 0.464 0.736 0.5
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
92/100 0.812G 0.8281 0.662 0.01011 13 640: 100% ━━━━━━━━━━━━ 1/1 4.6it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 11.8it/s 0.1s
all 4 17 0.587 0.524 0.714 0.52
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
93/100 0.812G 0.7256 0.5466 0.01088 13 640: 100% ━━━━━━━━━━━━ 1/1 5.7it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 12.1it/s 0.1s
all 4 17 0.587 0.524 0.714 0.52
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
94/100 0.812G 0.9877 0.7393 0.01681 13 640: 100% ━━━━━━━━━━━━ 1/1 5.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 13.9it/s 0.1s
all 4 17 0.587 0.524 0.714 0.52
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
95/100 0.812G 0.69 0.6176 0.005615 13 640: 100% ━━━━━━━━━━━━ 1/1 5.3it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.0it/s 0.1s
all 4 17 0.587 0.524 0.714 0.52
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
96/100 0.812G 0.7447 0.7112 0.009107 13 640: 100% ━━━━━━━━━━━━ 1/1 4.4it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.5it/s 0.1s
all 4 17 0.646 0.663 0.753 0.551
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
97/100 0.812G 0.9583 1.032 0.008361 13 640: 100% ━━━━━━━━━━━━ 1/1 6.2it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.5it/s 0.1s
all 4 17 0.646 0.663 0.753 0.551
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
98/100 0.812G 0.8357 0.5253 0.009686 13 640: 100% ━━━━━━━━━━━━ 1/1 5.8it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.5it/s 0.1s
all 4 17 0.646 0.663 0.753 0.551
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
99/100 0.812G 0.8735 0.6598 0.007769 13 640: 100% ━━━━━━━━━━━━ 1/1 5.6it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.5it/s 0.1s
all 4 17 0.646 0.663 0.753 0.551
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
100/100 0.812G 0.7745 0.6385 0.01272 13 640: 100% ━━━━━━━━━━━━ 1/1 4.6it/s 0.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 14.4it/s 0.1s
all 4 17 0.645 0.668 0.761 0.554
100 epochs completed in 0.027 hours.
Optimizer stripped from /w/runs/train/weights/last.pt, 5.5MB
Optimizer stripped from /w/runs/train/weights/best.pt, 5.5MB
Validating /w/runs/train/weights/best.pt...
Ultralytics 8.4.23 🚀 Python-3.12.3 torch-2.10.0+cu128 CUDA:0 (NVIDIA GeForce RTX 3080 Ti, 12045MiB)
YOLO26n summary (fused): 122 layers, 2,408,932 parameters, 0 gradients, 5.4 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 23.5it/s 0.0s
all 4 17 0.884 0.675 0.887 0.687
person 3 10 1 0.548 0.807 0.431
dog 1 1 0.788 1 0.995 0.796
horse 1 2 0.836 1 0.995 0.798
elephant 1 2 0.681 0.5 0.532 0.308
umbrella 1 1 1 1 0.995 0.895
potted plant 1 1 1 0 0.995 0.895
Speed: 0.2ms preprocess, 3.6ms inference, 0.0ms loss, 0.2ms postprocess per image
Results saved to /w/runs/train
💡 Learn more at https://docs.ultralytics.com/modes/train
root@ae5545d6babd:/w#常见问题
RuntimeError: unable to allocate shared memory(shm) for file </torch_29_1189891355_15>: Resource temporarily unavailable (11) Exception in thread Thread-14 (_pin_memory_loop):
bash
docker run --rm -it --gpus all -v "$(pwd)":/w -w /w ultralytics/ultralytics:latest
root@ce45cfa52d79:/w# yolo train model=yolo26n.pt data=coco8.yaml project=/w/runs
Creating new Ultralytics Settings v0.0.6 file ✅
View Ultralytics Settings with 'yolo settings' or at '/root/.config/Ultralytics/settings.json'
Update Settings with 'yolo settings key=value', i.e. 'yolo settings runs_dir=path/to/dir'. For help see https://docs.ultralytics.com/quickstart/#ultralytics-settings.
Ultralytics 8.4.23 🚀 Python-3.12.3 torch-2.10.0+cu128 CUDA:0 (NVIDIA GeForce RTX 3080 Ti, 12045MiB)
engine/trainer: agnostic_nms=False, amp=True, angle=1.0, augment=False, auto_augment=randaugment, batch=16, bgr=0.0, box=7.5, cache=False, cfg=None, classes=None, close_mosaic=10, cls=0.5, compile=False, conf=None, copy_paste=0.0, copy_paste_mode=flip, cos_lr=False, cutmix=0.0, data=coco8.yaml, degrees=0.0, deterministic=True, device=None, dfl=1.5, dnn=False, dropout=0.0, dynamic=False, embed=None, end2end=None, epochs=100, erasing=0.4, exist_ok=False, fliplr=0.5, flipud=0.0, format=torchscript, fraction=1.0, freeze=None, half=False, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, imgsz=640, int8=False, iou=0.7, keras=False, kobj=1.0, line_width=None, lr0=0.01, lrf=0.01, mask_ratio=4, max_det=300, mixup=0.0, mode=train, model=yolo26n.pt, momentum=0.937, mosaic=1.0, multi_scale=0.0, name=train, nbs=64, nms=False, opset=None, optimize=False, optimizer=auto, overlap_mask=True, patience=100, perspective=0.0, plots=True, pose=12.0, pretrained=True, profile=False, project=/w/runs, rect=False, resume=False, retina_masks=False, rle=1.0, save=True, save_conf=False, save_crop=False, save_dir=/w/runs/train, save_frames=False, save_json=False, save_period=-1, save_txt=False, scale=0.5, seed=0, shear=0.0, show=False, show_boxes=True, show_conf=True, show_labels=True, simplify=True, single_cls=False, source=None, split=val, stream_buffer=False, task=detect, time=None, tracker=botsort.yaml, translate=0.1, val=True, verbose=True, vid_stride=1, visualize=False, warmup_bias_lr=0.1, warmup_epochs=3.0, warmup_momentum=0.8, weight_decay=0.0005, workers=8, workspace=None
WARNING ⚠️ Dataset 'coco8.yaml' images not found, missing path '/datasets/coco8/images/val'
Downloading https://ultralytics.com/assets/coco8.zip to '/datasets/coco8.zip': 100% ━━━━━━━━━━━━ 432.8KB 247.9KB/s 1.7s
Unzipping /datasets/coco8.zip to /datasets/coco8...: 100% ━━━━━━━━━━━━ 25/25 2.5Kfiles/s 0.0s
Dataset download success ✅ (3.6s), saved to /datasets
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 6640 ultralytics.nn.modules.block.C3k2 [32, 64, 1, False, 0.25]
3 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
4 -1 1 26080 ultralytics.nn.modules.block.C3k2 [64, 128, 1, False, 0.25]
5 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
6 -1 1 87040 ultralytics.nn.modules.block.C3k2 [128, 128, 1, True]
7 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
8 -1 1 346112 ultralytics.nn.modules.block.C3k2 [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5, 3, True]
10 -1 1 249728 ultralytics.nn.modules.block.C2PSA [256, 256, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 119808 ultralytics.nn.modules.block.C3k2 [384, 128, 1, True]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 34304 ultralytics.nn.modules.block.C3k2 [256, 64, 1, True]
17 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 95232 ultralytics.nn.modules.block.C3k2 [192, 128, 1, True]
20 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 463104 ultralytics.nn.modules.block.C3k2 [384, 256, 1, True, 0.5, True]
23 [16, 19, 22] 1 309656 ultralytics.nn.modules.head.Detect [80, 1, True, [64, 128, 256]]
YOLO26n summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
Transferred 708/708 items from pretrained weights
AMP: running Automatic Mixed Precision (AMP) checks...
AMP: checks passed ✅
train: Fast image access ✅ (ping: 0.0±0.0 ms, read: 1207.8±417.8 MB/s, size: 50.0 KB)
train: Scanning /datasets/coco8/labels/train... 4 images, 0 backgrounds, 0 corrupt: 100% ━━━━━━━━━━━━ 4/4 717.0it/s 0.0s
train: New cache created: /datasets/coco8/labels/train.cache
albumentations: Blur(p=0.01, blur_limit=(3, 7)), MedianBlur(p=0.01, blur_limit=(3, 7)), ToGray(p=0.01, method='weighted_average', num_output_channels=3), CLAHE(p=0.01, clip_limit=(1.0, 4.0), tile_grid_size=(8, 8))
val: Fast image access ✅ (ping: 0.0±0.0 ms, read: 647.1±221.6 MB/s, size: 54.0 KB)
val: Scanning /datasets/coco8/labels/val... 4 images, 0 backgrounds, 0 corrupt: 100% ━━━━━━━━━━━━ 4/4 772.3it/s 0.0s
val: New cache created: /datasets/coco8/labels/val.cache
Traceback (most recent call last):
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_32_957097612_7>: Resource temporarily unavailable (11)
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_30_3473083899_7>: Resource temporarily unavailable (11)
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_29_329165158_7>: Resource temporarily unavailable (11)
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_34_1039122293_11>: Resource temporarily unavailable (11)
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_31_1079581208_11>: Resource temporarily unavailable (11)
Traceback (most recent call last):
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_33_493726863_11>: Resource temporarily unavailable (11)
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_28_1350585573_11>: Resource temporarily unavailable (11)
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_27_3408460363_11>: Resource temporarily unavailable (11)
Traceback (most recent call last):
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_30_3682893524_11>: Resource temporarily unavailable (11)
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_32_847215339_11>: Resource temporarily unavailable (11)
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_29_682186137_11>: Resource temporarily unavailable (11)
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_34_1685036062_15>: Resource temporarily unavailable (11)
Traceback (most recent call last):
Traceback (most recent call last):
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_31_2467592271_15>: Resource temporarily unavailable (11)
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
RuntimeError: unable to allocate shared memory(shm) for file </torch_27_1291325634_14>: Resource temporarily unavailable (11)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_33_1422681426_15>: Resource temporarily unavailable (11)
Traceback (most recent call last):
File "/usr/local/bin/yolo", line 10, in <module>
Traceback (most recent call last):
sys.exit(entrypoint())
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_28_2365568396_15>: Resource temporarily unavailable (11)
^^^^^^^^^^^^
File "/ultralytics/ultralytics/cfg/__init__.py", line 986, in entrypoint
getattr(model, mode)(**overrides) # default args from model
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/ultralytics/ultralytics/engine/model.py", line 777, in train
self.trainer.train()
File "/ultralytics/ultralytics/engine/trainer.py", line 244, in train
self._do_train()
File "/ultralytics/ultralytics/engine/trainer.py", line 366, in _do_train
self._setup_train()
File "/ultralytics/ultralytics/engine/trainer.py", line 348, in _setup_train
self._build_train_pipeline()
File "/ultralytics/ultralytics/engine/trainer.py", line 273, in _build_train_pipeline
self.test_loader = self.get_dataloader(
^^^^^^^^^^^^^^^^^^^^
File "/ultralytics/ultralytics/models/yolo/detect/train.py", line 98, in get_dataloader
return build_dataloader(
^^^^^^^^^^^^^^^^^
File "/ultralytics/ultralytics/data/build.py", line 326, in build_dataloader
return InfiniteDataLoader(
^^^^^^^^^^^^^^^^^^^
File "/ultralytics/ultralytics/data/build.py", line 67, in __init__
self.iterator = super().__iter__()
^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/utils/data/dataloader.py", line 500, in __iter__
return self._get_iterator()
^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/utils/data/dataloader.py", line 433, in _get_iterator
return _MultiProcessingDataLoaderIter(self)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/utils/data/dataloader.py", line 1159, in __init__
index_queue = multiprocessing_context.Queue() # type: ignore[var-annotated]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/context.py", line 103, in Queue
return Queue(maxsize, ctx=self.get_context())
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/queues.py", line 43, in __init__
self._rlock = ctx.Lock()
^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/context.py", line 68, in Lock
return Lock(ctx=self.get_context())
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/synchronize.py", line 169, in __init__
SemLock.__init__(self, SEMAPHORE, 1, 1, ctx=ctx)
File "/usr/lib/python3.12/multiprocessing/synchronize.py", line 57, in __init__
sl = self._semlock = _multiprocessing.SemLock(
^^^^^^^^^^^^^^^^^^^^^^^^^
OSError: [Errno 28] No space left on device
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_30_374140687_15>: Resource temporarily unavailable (11)
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_32_2667537573_15>: Resource temporarily unavailable (11)
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/queues.py", line 264, in _feed
obj = _ForkingPickler.dumps(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 615, in reduce_storage
fd, size = storage._share_fd_cpu_()
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 449, in wrapper
return fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/storage.py", line 524, in _share_fd_cpu_
return super()._share_fd_cpu_(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: unable to allocate shared memory(shm) for file </torch_29_1189891355_15>: Resource temporarily unavailable (11)
Exception in thread Thread-14 (_pin_memory_loop):
Traceback (most recent call last):
File "/usr/lib/python3.12/threading.py", line 1073, in _bootstrap_inner
self.run()
File "/usr/lib/python3.12/threading.py", line 1010, in run
self._target(*self._args, **self._kwargs)
File "/usr/local/lib/python3.12/dist-packages/torch/utils/data/_utils/pin_memory.py", line 52, in _pin_memory_loop
do_one_step()
File "/usr/local/lib/python3.12/dist-packages/torch/utils/data/_utils/pin_memory.py", line 28, in do_one_step
r = in_queue.get(timeout=MP_STATUS_CHECK_INTERVAL)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/queues.py", line 122, in get
return _ForkingPickler.loads(res)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/multiprocessing/reductions.py", line 540, in rebuild_storage_fd
fd = df.detach()
^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/resource_sharer.py", line 57, in detach
with _resource_sharer.get_connection(self._id) as conn:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/resource_sharer.py", line 86, in get_connection
c = Client(address, authkey=process.current_process().authkey)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/multiprocessing/connection.py", line 525, in Client
answer_challenge(c, authkey)
File "/usr/lib/python3.12/multiprocessing/connection.py", line 953, in answer_challenge
message = connection.recv_bytes(256) # reject large message解决方法
bash
yolo train model=yolo26n.pt data=coco8.yaml project=/w/runs 改为
bash
yolo train model=yolo26n.pt data=coco8.yaml project=/w/runs workers=0即可!
参考
1 https://docs.docker.com/desktop/setup/install/linux/ubuntu/
2 https://docs.ultralytics.com/guides/docker-quickstart/
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏、人工智能混合编程实践专栏或我的个人主页查看
- YOLOs-CPP:一个免费开源的YOLO全系列C++推理库(以YOLO26为例)
- PaddleOCR:Win10上安装使用PPOCRLabel标注工具
- 目标检测:使用自己的数据集微调DEIMv2进行物体检测
- 图像分割:PyTorch从零开始实现SegFormer语义分割
- 图像超分:使用自己的数据集微调Real-ESRGAN-x4plus进行超分重建
- 图像生成:PyTorch从零开始实现一个简单的扩散模型
- Stable Diffusion:使用自己的数据集微调 Stable Diffusion 3.5 LoRA 文生图模型
- 图像超分:使用自己的数据集微调Real-ESRGAN-x2plus进行超分重建
- Anomalib:使用Anomalib 2.1.0训练自己的数据集进行异常检测
- Anomalib:在Linux服务器上安装使用Anomalib 2.1.0
- 人工智能混合编程实践:C++调用封装好的DLL进行异常检测推理
- 人工智能混合编程实践:C++调用封装好的DLL进行FP16图像超分重建(v3.0)
- 隔离系统Python:源码编译3.11.8到自定义目录(含PGO性能优化)
- 在线机的Python环境迁移到离线机上
- Nuitka 将 Python 脚本封装为 .pyd 或 .so 文件
- Ultralytics:使用 YOLO11 进行速度估计
- Ultralytics:使用 YOLO11 进行物体追踪
- Ultralytics:使用 YOLO11 进行物体计数
- Ultralytics:使用 YOLO11 进行目标打码
- 人工智能混合编程实践:C++调用Python ONNX进行YOLOv8推理
- 人工智能混合编程实践:C++调用封装好的DLL进行YOLOv8实例分割
- 人工智能混合编程实践:C++调用Python ONNX进行图像超分重建
- 人工智能混合编程实践:C++调用Python AgentOCR进行文本识别
- 通过计算实例简单地理解PatchCore异常检测
- Python将YOLO格式实例分割数据集转换为COCO格式实例分割数据集
- YOLOv8 Ultralytics:使用Ultralytics框架训练RT-DETR实时目标检测模型
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
- Stable Diffusion:在服务器上部署使用Stable Diffusion WebUI进行AI绘图(v2.0)
- Stable Diffusion:使用自己的数据集微调训练LoRA模型(v2.0)