一、什么是RNN
循环神经网络(Recurrent Neural Network, RNN) 是一类以序列数据 为输入的神经网络。它通过网络内部的结构设计,能够有效捕捉序列数据之间的前后关联特征,输出通常也是序列形式。
序列数据:数据前后有关联关系(文本,股票,语音)
二、RNN的作用与类别
1. RNN的作用
RNN能够充分利用序列数据之间的连续性关系,因此非常适合处理自然界中具有连续性的输入数据,如:
-
人类语言(文本、语音)
-
时间序列数据(股票价格、天气变化)
主要应用领域:自然语言处理(NLP)
-
文本分类
-
情感分析
-
意图识别
-
机器翻译
-
阅读理解
-
文本摘要
2. RNN的类别
(1)按输入输出结构分类
| 类别 | 特点 | 应用场景 |
|---|---|---|
| N vs N | 输入与输出等长 | 生成等长度的上下联诗句、序列标注 |
| N vs 1 | 输入序列,输出单个值 | 文本分类、情感分析 |
| 1 vs N | 输入单个值,输出序列 | 图片生成文字(图像描述)AIGC |
| N vs M | 输入输出长度均可变 | 机器翻译、阅读理解、文本摘要 中英文互译 |
(2)按内部构造分类
-
传统RNN
-
LSTM(长短期记忆网络)
-
GRU(门控循环单元)
三、传统RNN
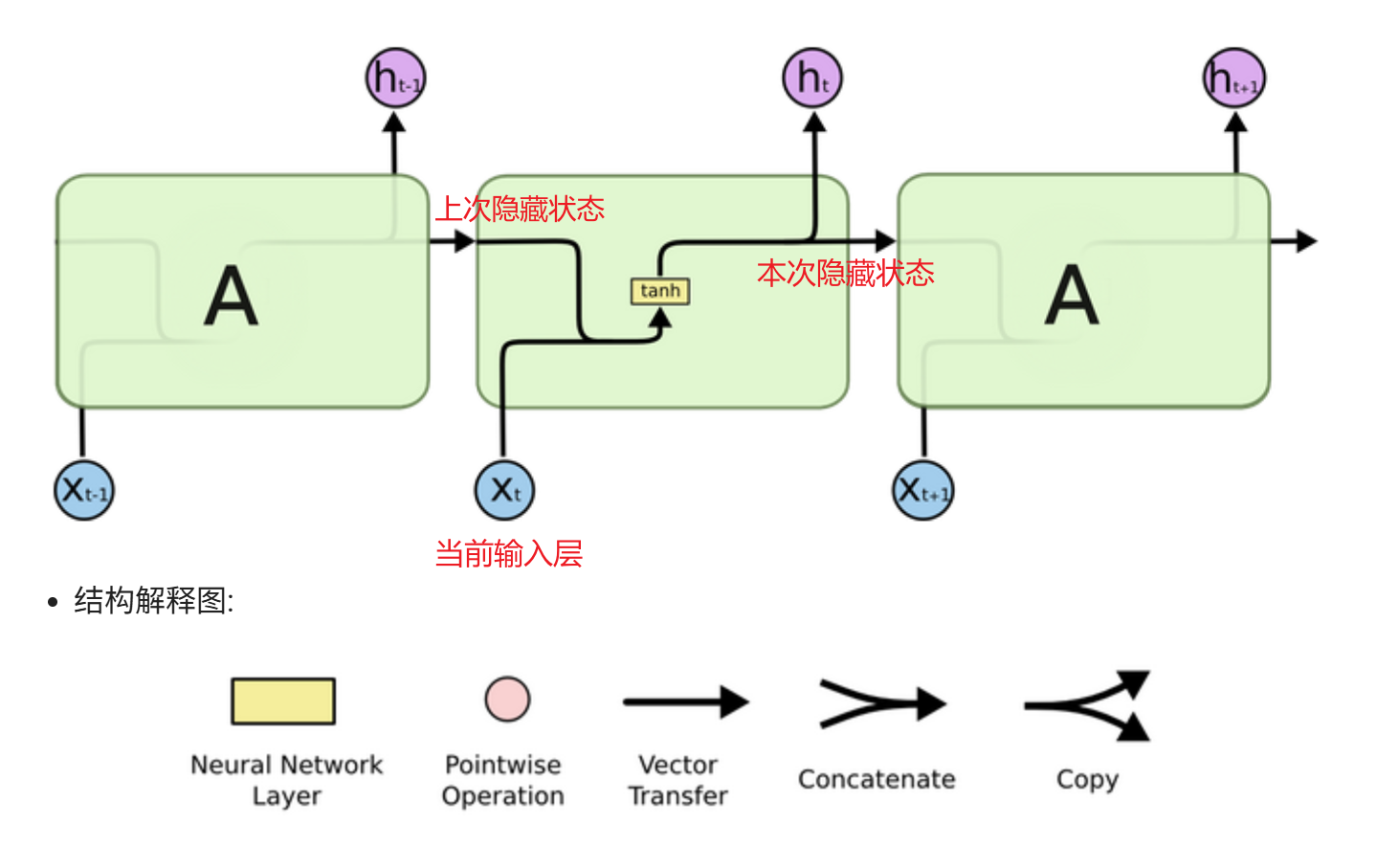
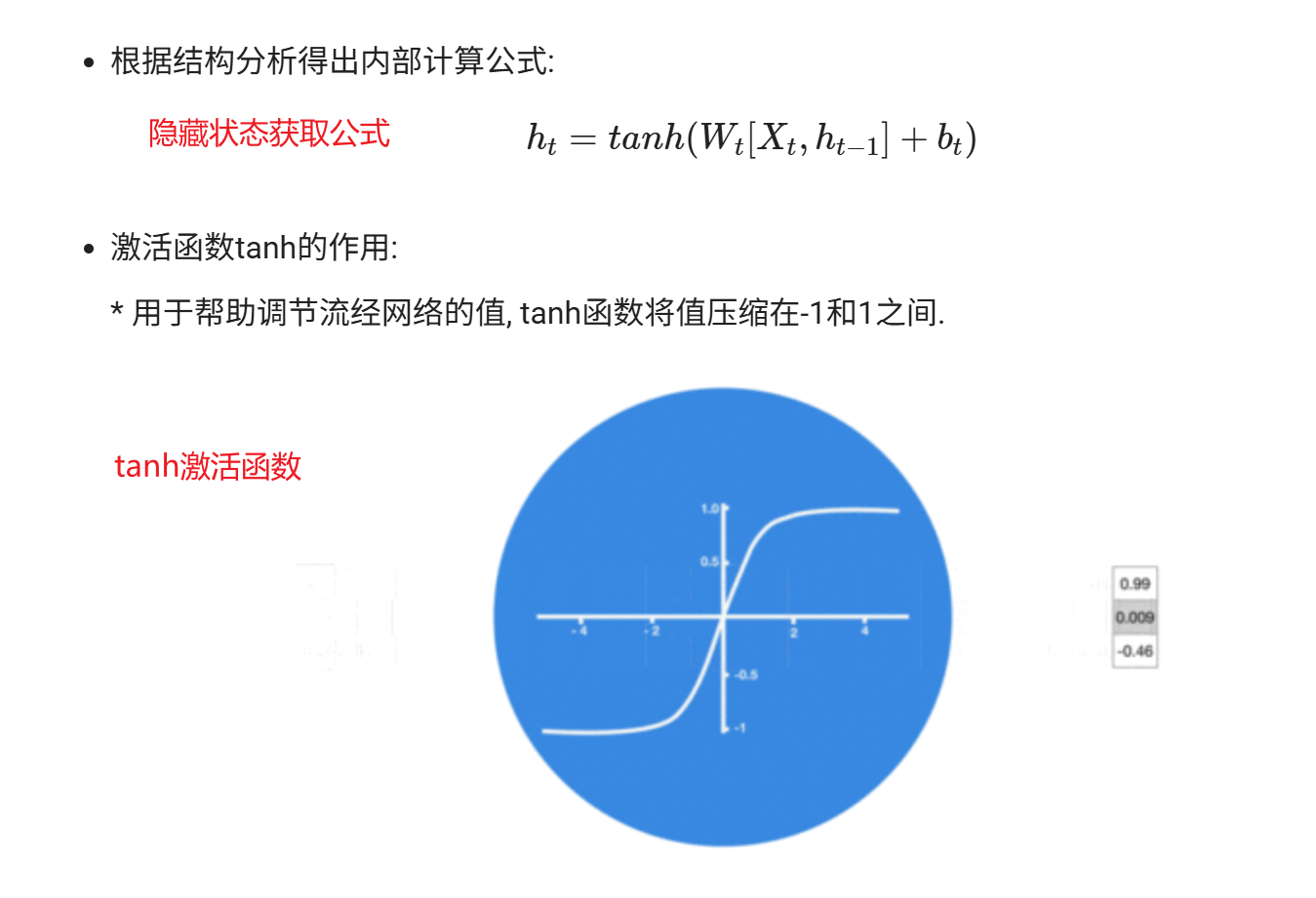
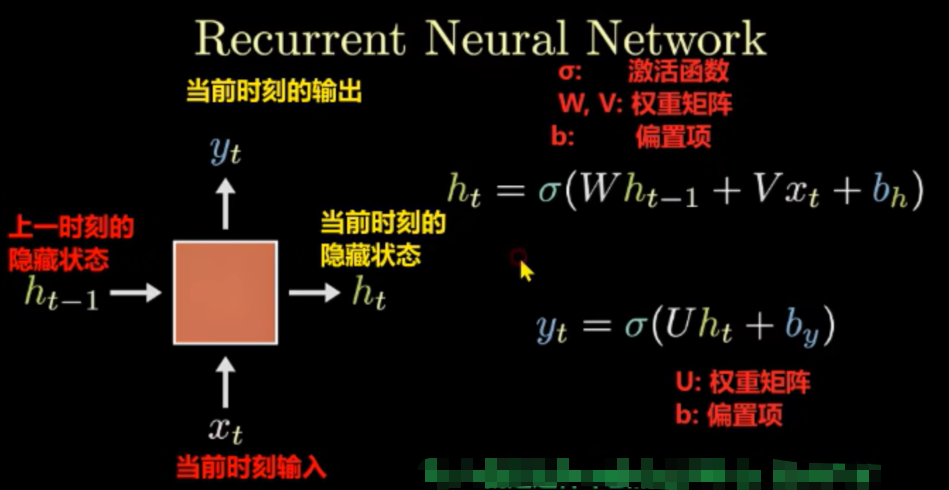
RNN的计算过程是:将上一时刻的隐藏状态与当前输入合并后加权求和,再经过tanh激活得到当前隐藏状态,最后根据任务类型对该隐藏状态进行加权求和后,通过Softmax(多分类取最大值)、Sigmoid(二分类取概率)或直接输出(回归)来得到当前时刻的预测值。
1. 模型结构
-
输入 :上一时刻的隐藏状态 ht−1 + 当前时刻的输入 xt
-
输出 :当前时刻的输出 output + 当前时刻的隐藏状态 ht
2. 模型构建要点
-
隐藏状态在时间步之间传递信息
-
参数共享:所有时间步使用相同的权重矩阵
3. 优点
-
内部结构简单
-
参数量少,计算资源要求低
4. 缺点
-
长序列处理能力差 :当序列过长时,反向传播过程中容易出现梯度消失 或梯度爆炸,导致模型难以捕捉长距离依赖关系。
-
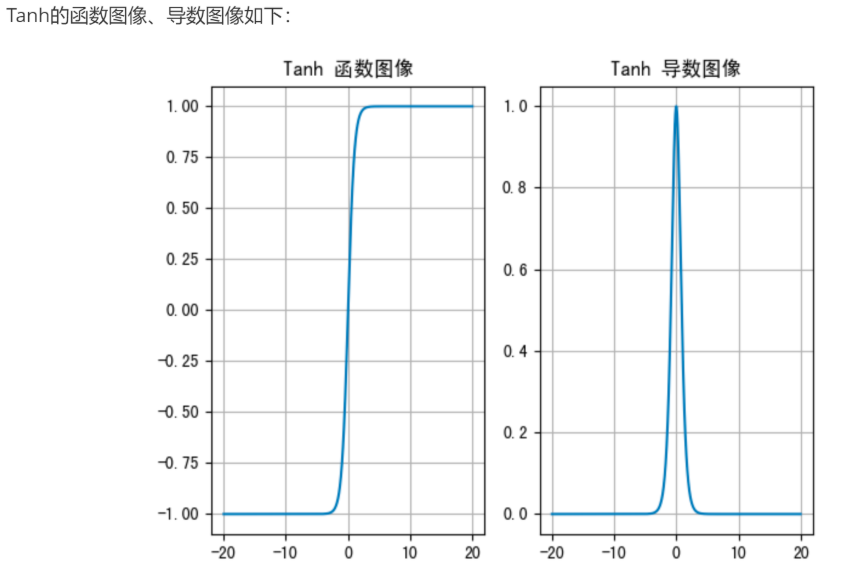
缺点的根本原因: 反向传播链式法则中对tanh激活函数求导的范围在 (0-1],如果传播链路过长,链式法则下的累乘,会导致梯度不断衰减,从而导致梯度消失,无法完成权重w的更新,导致模型能力差,无法传播更新到早期记忆的范畴
-
 python
pythonimport torch import torch.nn as nn def dm_rnn_for_base(): ''' 第一个参数:input_size(输入张量x的维度) 第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数) 第三个参数:num_layer(隐藏层的数量) ''' rnn = nn.RNN(5, 6, 1) #A ''' 第一个参数:sequence_length(输入序列的长度) 第二个参数:batch_size(批次的样本数量) 第三个参数:input_size(输入张量的维度) ''' input = torch.randn(1, 3, 5) #B ''' 第一个参数:num_layer * num_directions(层数*网络方向) 第二个参数:batch_size(批次的样本数) 第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数) ''' h0 = torch.randn(1, 3, 6) #C # [1,3,5],[1,3,6] ---> [1,3,6],[1,3,6] output, hn = rnn(input, h0) print('output--->',output.shape, output) print('hn--->',hn.shape, hn) print('rnn模型--->', rnn) # 程序运行效果如下: output---> torch.Size([1, 3, 6]) tensor([[[ 0.8947, -0.6040, 0.9878, -0.1070, -0.7071, -0.1434], [ 0.0955, -0.8216, 0.9475, -0.7593, -0.8068, -0.5549], [-0.1524, 0.7519, -0.1985, 0.0937, 0.2009, -0.0244]]], grad_fn=<StackBackward0>) hn---> torch.Size([1, 3, 6]) tensor([[[ 0.8947, -0.6040, 0.9878, -0.1070, -0.7071, -0.1434], [ 0.0955, -0.8216, 0.9475, -0.7593, -0.8068, -0.5549], [-0.1524, 0.7519, -0.1985, 0.0937, 0.2009, -0.0244]]], grad_fn=<StackBackward0>) rnn模型---> RNN(5, 6)python# 输入数据长度发生变化 def dm_rnn_for_sequencelen(): ''' 第一个参数:input_size(输入张量x的维度) 第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数) 第三个参数:num_layer(隐藏层的数量) ''' rnn = nn.RNN(5, 6, 1) #A ''' 第一个参数:sequence_length(输入序列的长度) 第二个参数:batch_size(批次的样本数量) 第三个参数:input_size(输入张量的维度) ''' input = torch.randn(20, 3, 5) #B ''' 第一个参数:num_layer * num_directions(层数*网络方向) 第二个参数:batch_size(批次的样本数) 第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数) ''' h0 = torch.randn(1, 3, 6) #C # [20,3,5],[1,3,6] --->[20,3,6],[1,3,6] output, hn = rnn(input, h0) # print('output--->', output.shape) print('hn--->', hn.shape) print('rnn模型--->', rnn) # 程序运行效果如下: output---> torch.Size([20, 3, 6]) hn---> torch.Size([1, 3, 6]) rnn模型---> RNN(5, 6)pythondef dm_run_for_hiddennum(): ''' 第一个参数:input_size(输入张量x的维度) 第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数) 第三个参数:num_layer(隐藏层的数量) ''' rnn = nn.RNN(5, 6, 2) # A 隐藏层个数从1-->2 下面程序需要修改的地方? ''' 第一个参数:sequence_length(输入序列的长度) 第二个参数:batch_size(批次的样本数量) 第三个参数:input_size(输入张量的维度) ''' input = torch.randn(1, 3, 5) # B ''' 第一个参数:num_layer * num_directions(层数*网络方向) 第二个参数:batch_size(批次的样本数) 第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数) ''' h0 = torch.randn(2, 3, 6) # C output, hn = rnn(input, h0) # print('output-->', output.shape, output) print('hn-->', hn.shape, hn) print('rnn模型--->', rnn) # nn模型---> RNN(5, 6, num_layers=11) # 结论:若只有一个隐藏次 output输出结果等于hn # 结论:如果有2个隐藏层,output的输出结果有2个,hn等于最后一个隐藏层 # 程序运行效果如下: output--> torch.Size([1, 3, 6]) tensor([[[ 0.4987, -0.5756, 0.1934, 0.7284, 0.4478, -0.1244], [ 0.6753, 0.5011, -0.7141, 0.4480, 0.7186, 0.5437], [ 0.6260, 0.7600, -0.7384, -0.5080, 0.9054, 0.6011]]], grad_fn=<StackBackward0>) hn--> torch.Size([2, 3, 6]) tensor([[[ 0.4862, 0.6872, -0.0437, -0.7826, -0.7136, -0.5715], [ 0.8942, 0.4524, -0.1695, -0.5536, -0.4367, -0.3353], [ 0.5592, 0.0444, -0.8384, -0.5193, 0.7049, -0.0453]], [[ 0.4987, -0.5756, 0.1934, 0.7284, 0.4478, -0.1244], [ 0.6753, 0.5011, -0.7141, 0.4480, 0.7186, 0.5437], [ 0.6260, 0.7600, -0.7384, -0.5080, 0.9054, 0.6011]]], grad_fn=<StackBackward0>) rnn模型---> RNN(5, 6, num_layers=2)总结一下参数变化,这个地方小编用一个案例作为记忆手段:
-
每批次 5 句话(样本), batch_size = 5
-
每句话(样本 ) 32 个词语(特征), sequence_length = 32
-
输入张量维度 128 input_size = 128 一般是词向量的长度
-
隐藏层张量维度 256 hidden_size = 256 一般自己来定,通常是2的n次幂
-
隐藏层数量 1 num_layer 一般代表着经过几层循环网络层处理,信息是递进的
python
输入 (in) RNN层 输出 (out)
┌─────────┐ ┌─────────┐ ┌─────────┐
│ 32×5×128│ ───→ │ 128维 │ ─────→ │ 32×5×256│
└─────────┘ │ 256维 │ └─────────┘
│ layer=1 │
└─────────┘
↑
隐藏状态 (hn)
┌─────────┐
│ 1×5×256 │
└─────────┘参数说明表格
| 变量 | 维度 | 含义 |
|---|---|---|
| nn | 128 256 1 | 输入大小=128,隐藏层大小=256,层数=1 |
| in | 32×5×128 | 特征数=32,样本=5,每个时间步输入128维 |
| ho | 1×5×256 | 5个样本 当前时间步的隐藏状态(1层,5个样本,256维) |
| out | 32×5×256 | 5个样本其中每个时间步的输出(用于下一个时间步或预测) |
| hn | 1×5×256 | 5个样本最后一个时间步的隐藏状态(用于后续序列初始化) |
四、LSTM(长短期记忆网络)
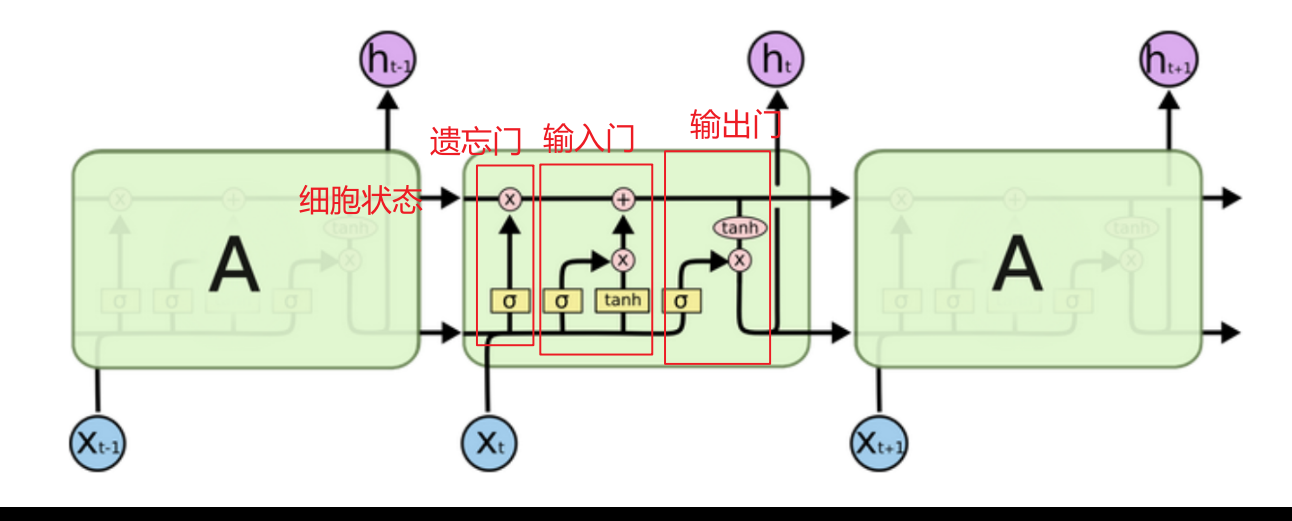
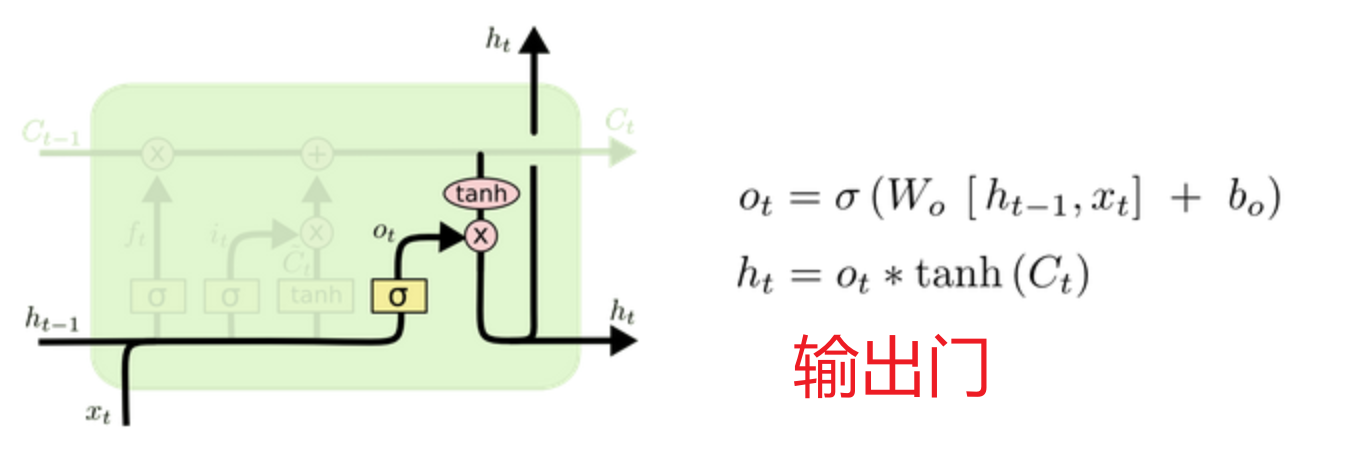
小编的整体理解:
LSTM又称长短时记忆,分为长时C(细胞状态)、短时ht(上一次的隐藏状态)
主要分为遗忘门、输入门 、细胞状态、输出门四部分
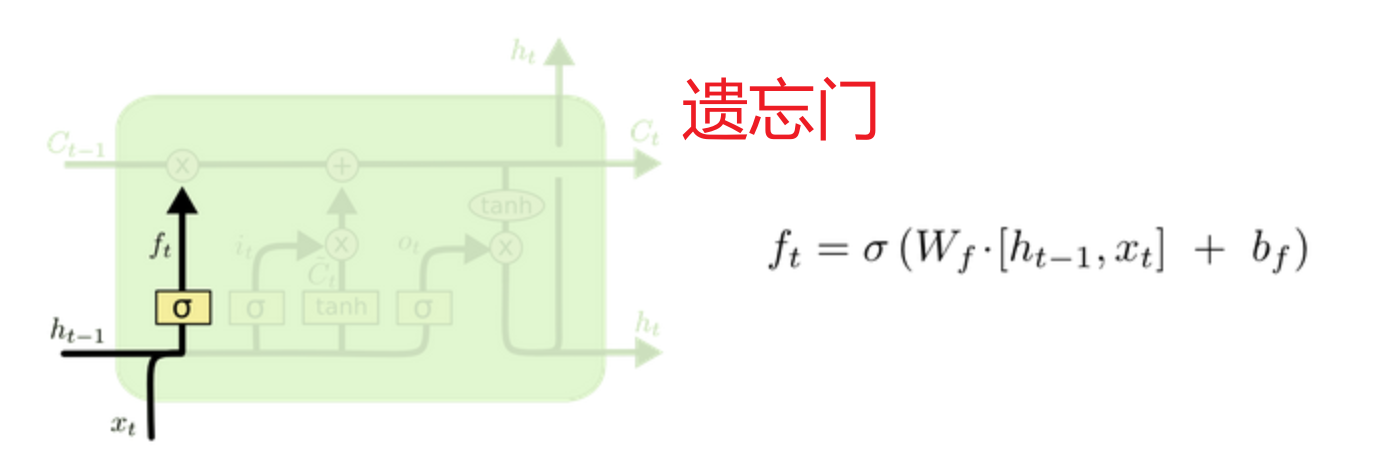
遗忘门:利用 上次隐藏状态和当前输入 加权求和的sigmoid激活函数当作门值(0,1] 过滤细胞状态(历史数据库),意义在于根据 本次输入和上次隐藏 的具体内容决定遗忘掉哪些数据
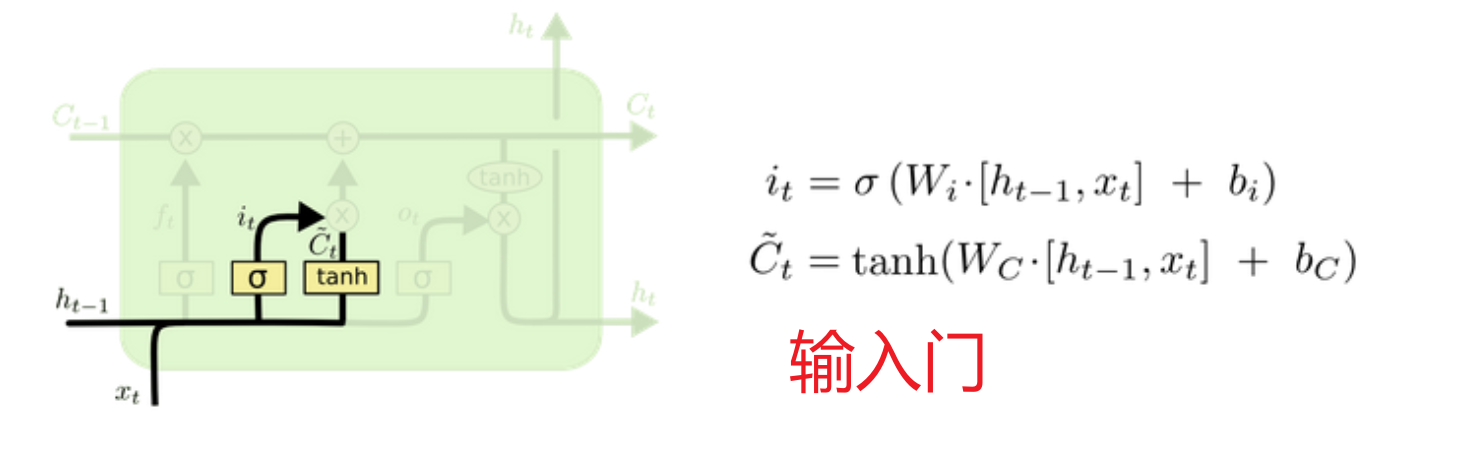
输入门:利用 上次隐藏状态和当前输入 加权求和的tanh激活函数(-1,1]决定留下什么数据当作输入,再利用 sigmoid激活函数当作门值(0,1]过滤当前输入保留多少,意义在于根据 本次输入和上次隐藏 的具体内容决定留下哪些数据进入历史数据库
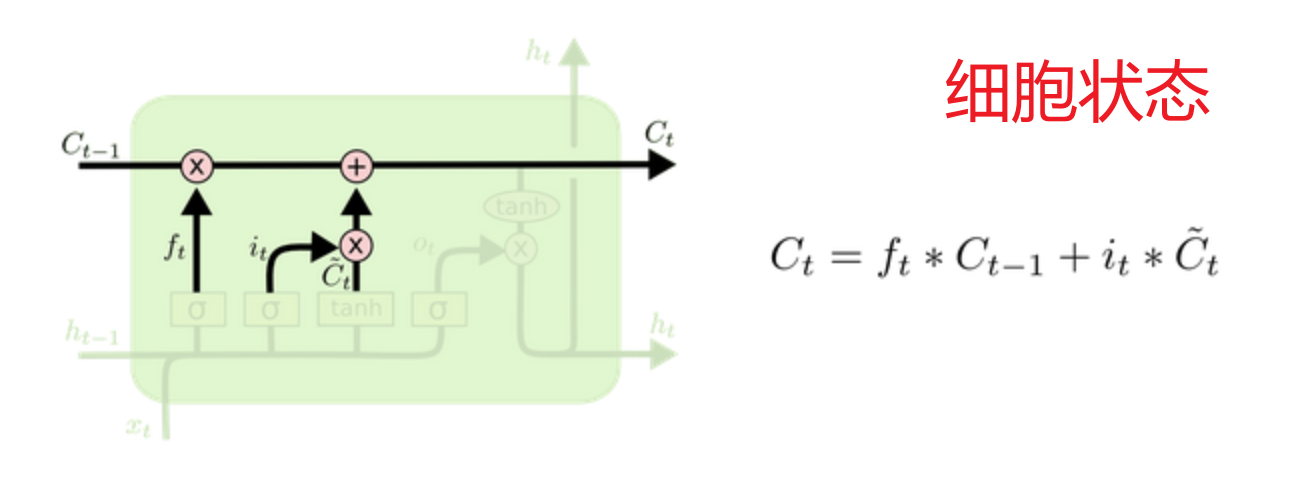
细胞状态:利用遗忘门过滤后的数据 + 输入门过滤后的数据 组合成实时的历史数据库
输出门:利用 细胞状态 数据加权求和的tanh激活函数(-1,1]决定留下什么数据当作本次隐藏,再利用上次隐藏 状态和当前输入加权求和的sigmoid激活函数当作门值(0,1]过滤当前输出保留多少,意义在于根据本次输入和上次隐藏的具体内容决定留下哪些数据当作本次隐藏
简短点说就是
长短时记忆主要分为四部分 遗忘门 输入门 输出门 细胞状态
遗忘门:根据最新输入的激活函数当作门值,决定遗忘掉哪些不重要的信息
输入门:根据最新输入的激活函数决定哪些数据纳入细胞状态
细胞状态:遗忘门过滤后的历史细胞信息 + 输入门过滤后的新信息
输出门:根据最新输入的激活函数和细胞状态的激活函数决定哪些数据当作本次隐藏状态
1. 模型结构
LSTM通过精心设计的门控机制来控制信息的流动,主要包括:
-
遗忘门:决定丢弃哪些信息
-
输入门:决定更新哪些新信息
-
细胞状态:长期记忆的载体
-
输出门:决定输出哪些信息
2. 模型构建要点
-
细胞状态(CtCt)贯穿整个序列,信息可以长期保存
-
三个门控单元协同工作,实现信息的精细化控制
3. 优点
-
相比传统RNN,能够有效捕捉长序列之间的语义关联
-
显著缓解梯度消失/爆炸问题
4. 缺点
-
内部结构复杂,参数量增加
-
训练效率较低,同等算力下比传统RNN慢
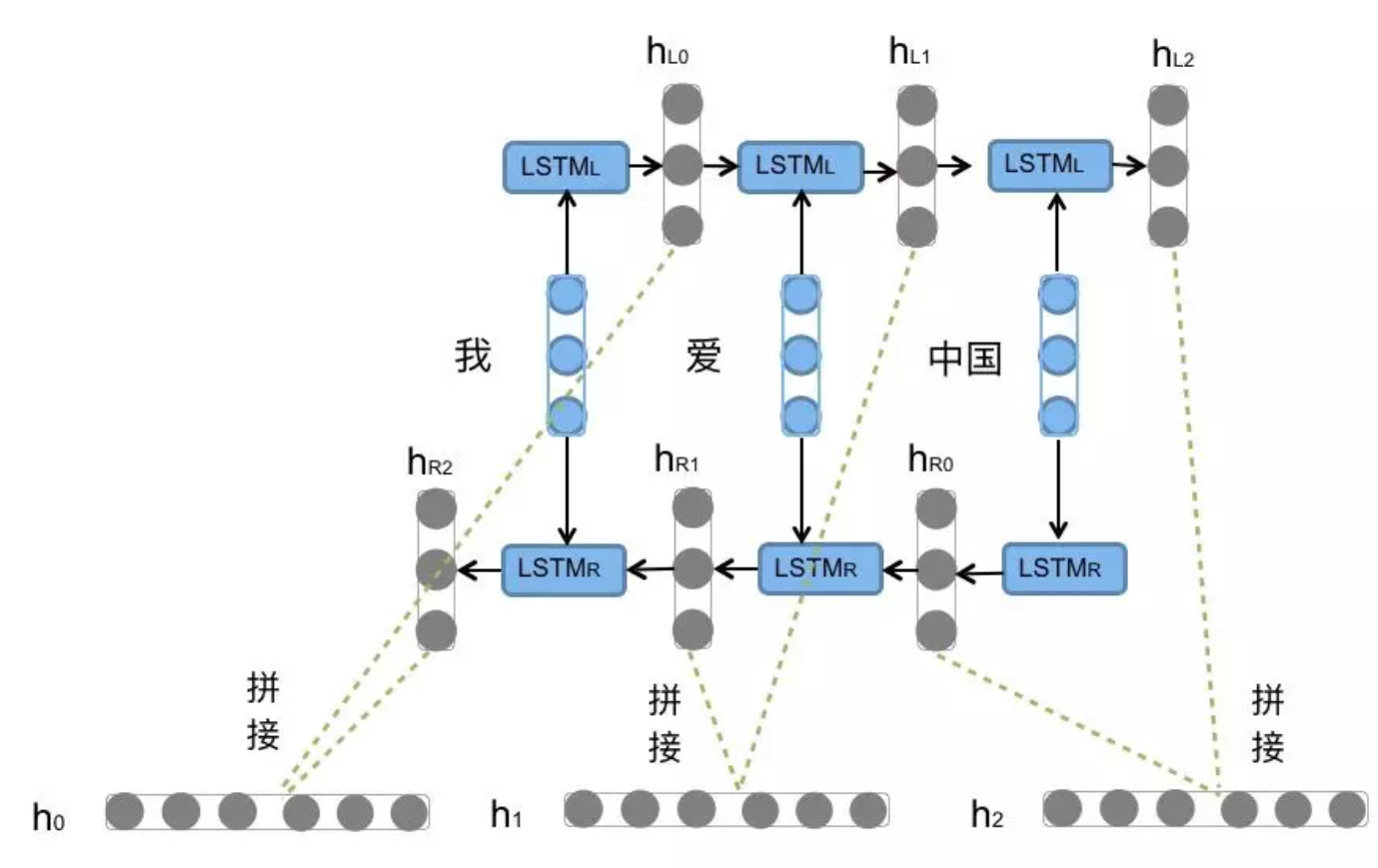
5. BI-LSTM(双向LSTM)
-
原理:将LSTM应用两次,方向相反(正向+反向)
-
输出:将两个方向的LSTM结果拼接
-
作用:能够同时捕捉序列的上文 和下文信息
-
python
# 定义LSTM的参数含义: (input_size, hidden_size, num_layers)
# 定义输入张量的参数含义: (sequence_length, batch_size, input_size)
# 定义隐藏层初始张量和细胞初始状态张量的参数含义:
# (num_layers * num_directions, batch_size, hidden_size)
>>> import torch.nn as nn
>>> import torch
>>> rnn = nn.LSTM(5, 6, 2)
>>> input = torch.randn(1, 3, 5)
>>> h0 = torch.randn(2, 3, 6)
>>> c0 = torch.randn(2, 3, 6)
>>> output, (hn, cn) = rnn(input, (h0, c0))
>>> output
tensor([[[ 0.0447, -0.0335, 0.1454, 0.0438, 0.0865, 0.0416],
[ 0.0105, 0.1923, 0.5507, -0.1742, 0.1569, -0.0548],
[-0.1186, 0.1835, -0.0022, -0.1388, -0.0877, -0.4007]]],
grad_fn=<StackBackward>)
>>> hn
tensor([[[ 0.4647, -0.2364, 0.0645, -0.3996, -0.0500, -0.0152],
[ 0.3852, 0.0704, 0.2103, -0.2524, 0.0243, 0.0477],
[ 0.2571, 0.0608, 0.2322, 0.1815, -0.0513, -0.0291]],
[[ 0.0447, -0.0335, 0.1454, 0.0438, 0.0865, 0.0416],
[ 0.0105, 0.1923, 0.5507, -0.1742, 0.1569, -0.0548],
[-0.1186, 0.1835, -0.0022, -0.1388, -0.0877, -0.4007]]],
grad_fn=<StackBackward>)
>>> cn
tensor([[[ 0.8083, -0.5500, 0.1009, -0.5806, -0.0668, -0.1161],
[ 0.7438, 0.0957, 0.5509, -0.7725, 0.0824, 0.0626],
[ 0.3131, 0.0920, 0.8359, 0.9187, -0.4826, -0.0717]],
[[ 0.1240, -0.0526, 0.3035, 0.1099, 0.5915, 0.0828],
[ 0.0203, 0.8367, 0.9832, -0.4454, 0.3917, -0.1983],
[-0.2976, 0.7764, -0.0074, -0.1965, -0.1343, -0.6683]]],
grad_fn=<StackBackward>)五、GRU(门控循环单元)
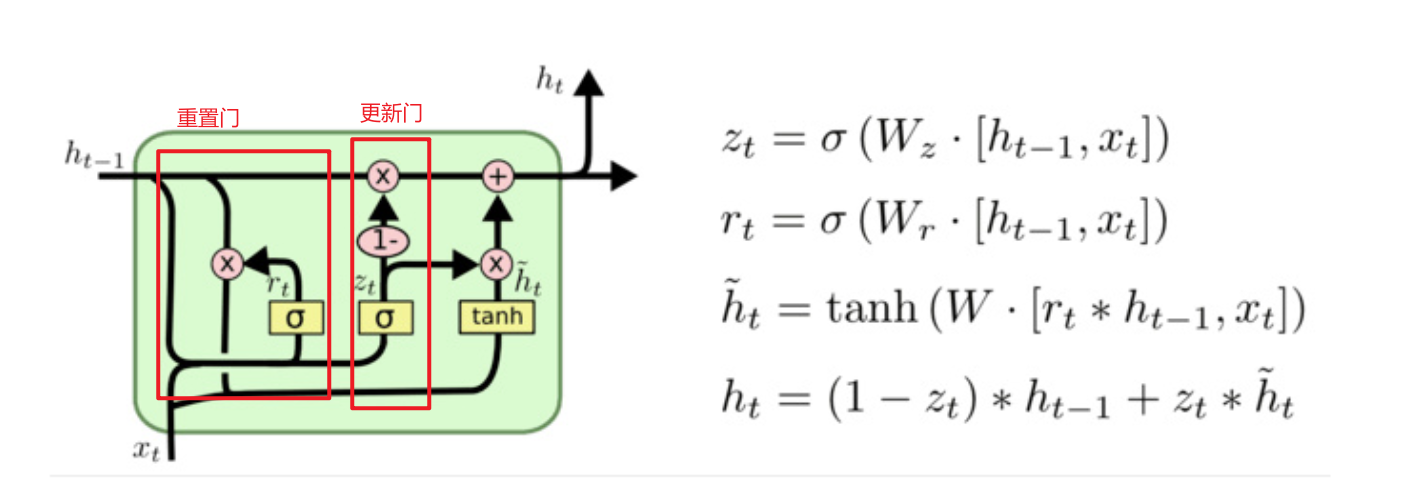
11将LSTM的隐藏状态和细胞状态合并在一起,减少了参数的运算,提高了运算效率
将LSTM的遗忘门和输入们合并为更新门,同时引入重置门
主要分为 重置门和 更新门
重置门:决定 历史信息 和新信息的结合
更新门:决定 历史信息的过滤 和 新信息的加入
1. 模型结构
GRU是LSTM的简化版本,将遗忘门和输入门合并为更新门 ,同时引入重置门:
-
重置门:决定如何将新的输入信息与之前的记忆结合
-
更新门:决定保留多少历史信息和加入多少新信息
2. 模型构建要点
-
结构比LSTM更简单,只有两个门
-
没有独立的细胞状态,隐藏状态直接传递信息
3. 优点
-
与LSTM效果相当,同样能有效抑制梯度消失/爆炸
-
计算复杂度比LSTM低,训练效率更高
4. 缺点
-
仍然不能完全解决梯度消失问题
-
不可并行计算(RNN系列的通病)
-
随着数据量和模型规模增大,成为发展的关键瓶颈
5. BI-GRU(双向GRU)
-
原理:与Bi-LSTM类似,将GRU应用两次(正向+反向)
-
输出:拼接两个方向的GRU结果
python
>>> import torch
>>> import torch.nn as nn
>>> rnn = nn.GRU(5, 6, 2)
>>> input = torch.randn(1, 3, 5)
>>> h0 = torch.randn(2, 3, 6)
>>> output, hn = rnn(input, h0)
>>> output
tensor([[[-0.2097, -2.2225, 0.6204, -0.1745, -0.1749, -0.0460],
[-0.3820, 0.0465, -0.4798, 0.6837, -0.7894, 0.5173],
[-0.0184, -0.2758, 1.2482, 0.5514, -0.9165, -0.6667]]],
grad_fn=<StackBackward>)
>>> hn
tensor([[[ 0.6578, -0.4226, -0.2129, -0.3785, 0.5070, 0.4338],
[-0.5072, 0.5948, 0.8083, 0.4618, 0.1629, -0.1591],
[ 0.2430, -0.4981, 0.3846, -0.4252, 0.7191, 0.5420]],
[[-0.2097, -2.2225, 0.6204, -0.1745, -0.1749, -0.0460],
[-0.3820, 0.0465, -0.4798, 0.6837, -0.7894, 0.5173],
[-0.0184, -0.2758, 1.2482, 0.5514, -0.9165, -0.6667]]],
grad_fn=<StackBackward>)六、总结对比
| 模型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 传统RNN | 结构简单,参数量少,训练快 | 长序列梯度消失/爆炸 | 短序列任务 |
| LSTM | 长序列建模能力强,缓解梯度问题 | 结构复杂,训练慢 | 需要长期依赖的任务(机器翻译、文本生成) |
| GRU | 效果与LSTM相当,效率更高 | 仍存在梯度问题,不可并行 | 平衡效果和效率的中长序列任务 |
| 双向变体 | 同时捕捉上下文信息 | 计算量翻倍 | 需要完整上下文的任务(阅读理解、情感分析) |
未来展望 :RNN系列模型的串行计算 特性限制了其在超大规模数据和模型上的发展。随着Transformer等并行化架构的兴起,RNN在NLP领域的统治地位逐渐被取代,但在某些特定场景(如小规模序列数据、实时性要求高的任务)中,GRU/LSTM仍然是极具竞争力的选择。