使用Ollama运行本地模型,模型参数选择(保姆级图文讲解)

Ollama简介
Ollama官网:Ollama
Ollama 是一个开源工具 ,让你能在本地电脑上轻松运行大型语言模型(如 Llama 3、DeepSeek、Qwen 等)。它简化了 AI 模型的部署和使用过程,无需依赖云端服务。
核心特点
- 简单易用 - 通过几条命令就能下载和运行模型
- 本地运行 - 数据留在本地,隐私安全
- 多模型支持 - 支持 Llama、DeepSeek、Mistral、Qwen 等主流模型
- 跨平台 - 支持 macOS、Linux 和 Windows
- API 服务 - 内置兼容 OpenAI 格式的 API 接口
一、下载安装
下载地址:Download Ollama on Windows
点击下载即可,注意不要用CMD控制台下载,因为卡了文件基本上就要重新下载了
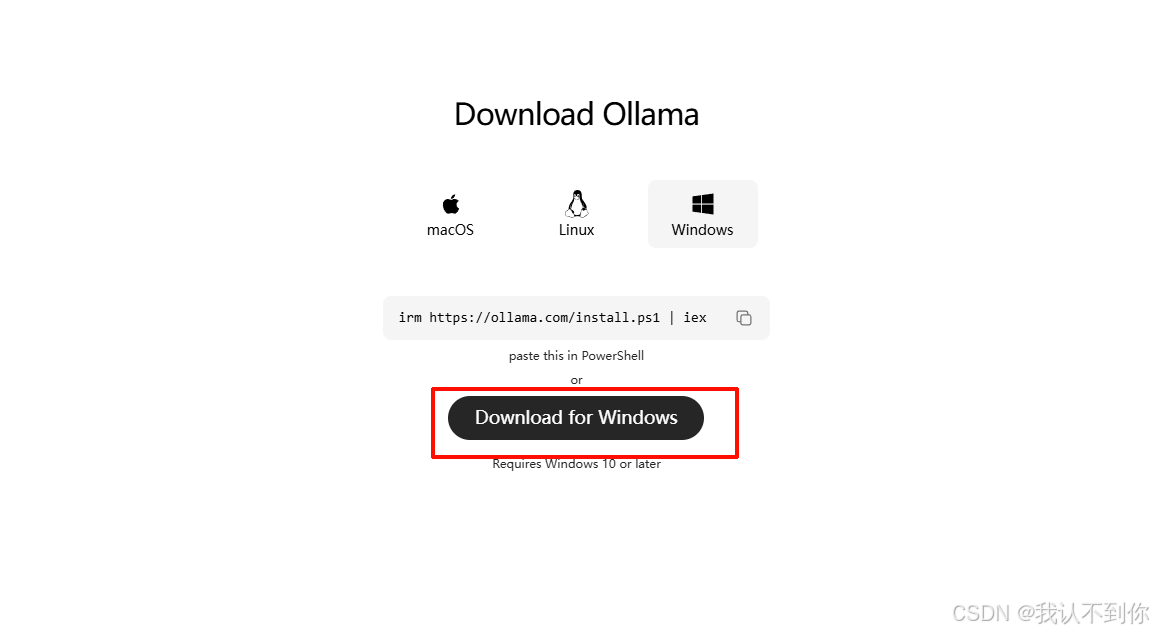
自定义安装路径:使用CMD命令安装
1、打开CMD控制台
2、安装
bash
OllamaSetup.exe /DIR=D:\environment\Ollama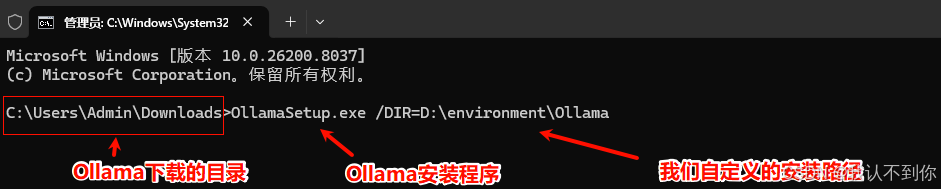
3、回车后安装即可
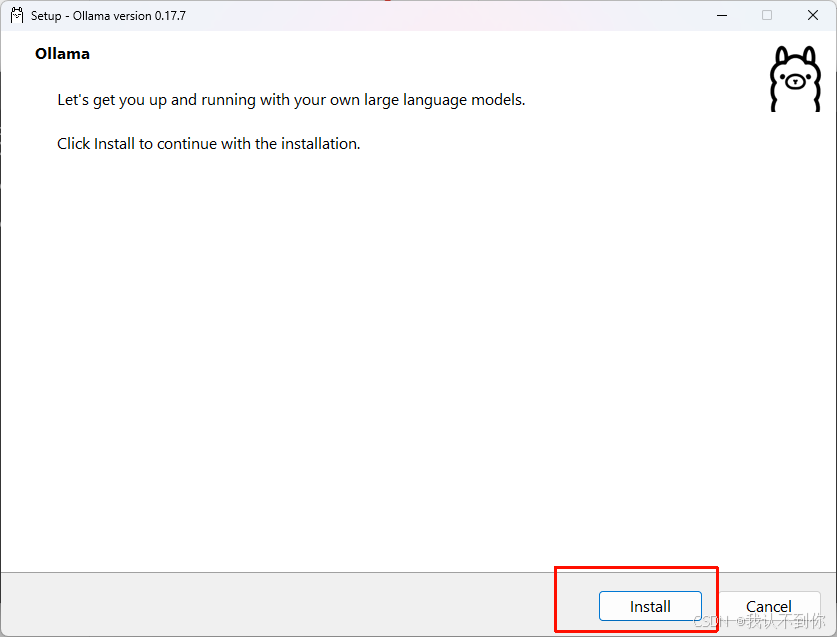
4、设置模型安装路径
注意这个安装路径只跟Ollama官网安装的模型有关系
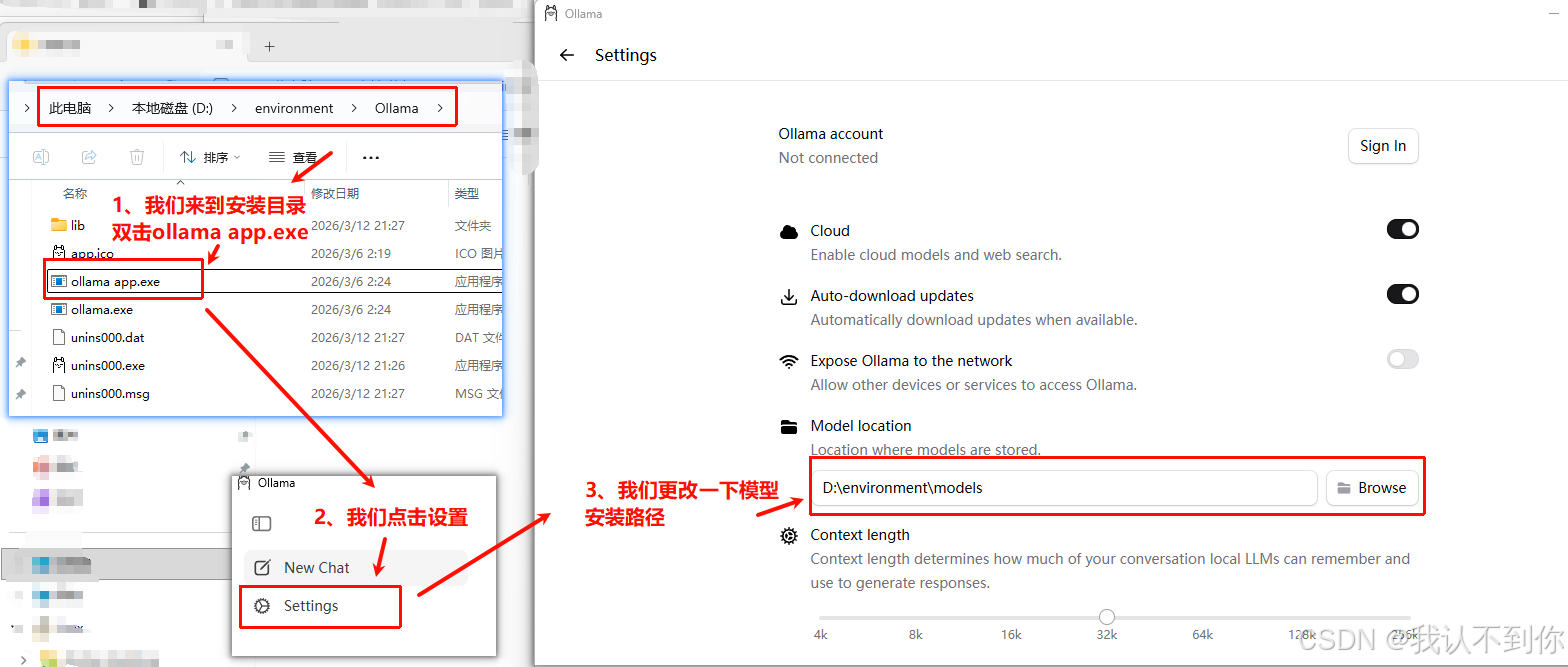
二、模型参数选择(参考)
先说一下我的配置供大家参考(因为后面我有测试样例):AMD显卡 7800xt(16G显存),32G内存,7800X3D(8 核心 / 16 线程)
选择哪个模型参数规模(也就是那个数字后面带的B),主要看你的显卡有多少显存。简单来说,显存是你的预算,模型参数和量化精度是你想买的东西,一定要量入为出。
ps:量化是一种压缩技术,能在牺牲一点点精度的情况下,大幅减少模型对显存的占用,让它能在更多设备上跑起来
| 模型参数规模 | 显存需求 (FP16精度) | 显存需求 (Q5_K_M量化) | 适合做什么? |
|---|---|---|---|
| 1B - 3B | 2 GB - 6 GB | 约 1 GB - 3 GB | 基础的文本生成、摘要、在手机或老旧笔记本上跑跑 |
| 7B - 8B | 约 14 GB - 16 GB | 约 5 GB - 7 GB | 日常的编程辅助、文档问答、头脑风暴(目前性价比最高的选择) |
| 13B - 14B | 约 26 GB - 28 GB | 约 8 GB - 10 GB | 更复杂的推理任务、专业领域的知识问答、高质量的内容创作 |
| 32B - 34B | 约 66 GB | 约 20 GB - 22 GB | 作为本地强大的"副驾驶",处理非常复杂的任务,能力接近顶尖模型 |
| 70B+ | 140 GB+ | 约 35 GB+ | 需要多张专业显卡(如多路A100或H100)才能运行,适合企业和深度研究 |
需要注意的是,AMD显卡在跑AI时没有NVIDIA那么省心,需要依赖ROCm支持,但确实是个高显存、低成本的好选择。
| 你的显存"预算" | 可流畅运行的模型规模 | NVIDIA 推荐型号 | AMD 推荐型号 |
|---|---|---|---|
| 6 GB - 8 GB | 7B-8B模型 (需量化) | RTX 3050/3060 (6GB/8GB) | RX 6600/7600 (需确认ROCm兼容性) |
| 12 GB - 16 GB | 7B-8B (高精度),或 13B-14B (量化) | RTX 3060 (12GB) , RTX 4070/4060 Ti (16GB) | RX 6700/6800 XT (16GB版本) |
| 24 GB | 13B-14B (高精度),或 32B (量化) | RTX 3090/4090 | RX 7900 XTX |
| 32 GB - 48 GB | 32B-34B (高精度) | NVIDIA A6000 (48GB) , RTX 6000 Ada | 需双卡或专业AMD计算卡 (如MI100系列) |
| 48 GB+ | 70B+ 模型 | NVIDIA A100 (80GB) , 多卡方案 | 多卡方案,或大显存计算卡 |
三、Ollama 命令(配合后面案例)(qwen:3.5举例)
字体加粗的是比较重要的
| 命令 | 说明 | 示例 |
|---|---|---|
ollama run |
运行模型。如果不存在则自动拉取。(这个比下面好用)(下文案例会用到) | ollama run qwen:3.5 |
ollama pull |
拉取模型。从库中下载模型但不运行。 | ollama pull qwen:3.5 |
ollama list |
列出模型。显示本地所有已下载的模型。(下文案例会用到) | ollama list |
ollama rm |
删除模型。移除本地模型释放空间。(下文案例会用到) | ollama rm qwen:3.5 |
ollama cp |
复制模型。将现有模型复制为新名称(用于测试)。 | ollama cp qwen:3.5 my-model |
ollama create |
创建模型。根据 Modelfile 创建自定义模型(高级)。(下文案例会用到) | ollama create qwen:3.5 -f ./Modelfile |
ollama show |
显示信息。查看模型的元数据、参数或 Modelfile。 | ollama show --modelfile qwen:3.5 |
ollama ps |
查看进程。显示当前正在运行的模型及显存占用。(下文案例会用到) | ollama ps |
ollama push |
推送模型。将你自定义的模型上传到 ollama.com。 | ollama push my-username/qwen:3.5 |
ollama serve |
启动服务。启动 Ollama 的 API 服务(通常后台自动运行)。 | ollama serve |
ollama help |
帮助。查看任何命令的帮助信息。 | ollama help run |
ollama launch |
用本地模型启动,我后面的文章(不是这篇文章)会讲到用本地模型跑Openclaw并且集成飞书,所以这个命令也比较重要 | Claude Code:ollama launch claude --model qwen3.5 Codex:ollama launch codex --model qwen3.5 OpenCode:ollama launch opencode --model qwen3.5 OpenClaw:ollama launch openclaw --model qwen3.5 |
四、选择我们需要的下载的模型(两种方式)
1、Ollama官网下载
(1、选择模型
我们来到官网:Ollama,搜索我们需要的模型进行下载
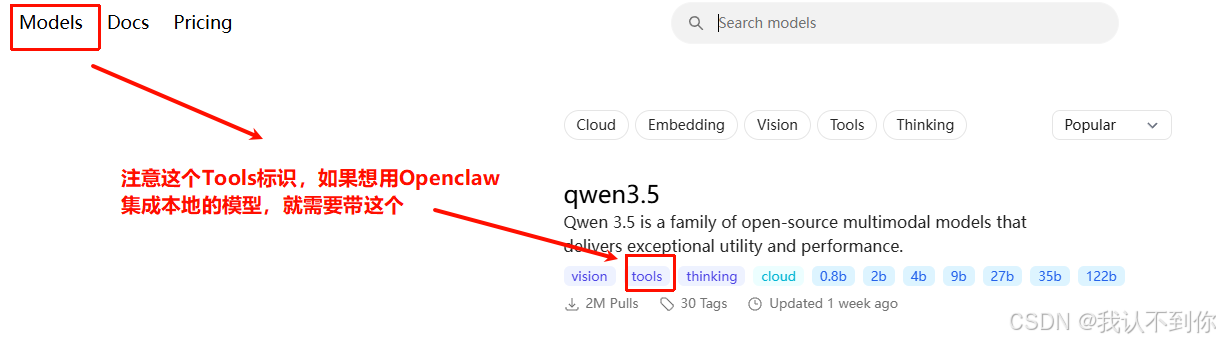
(2、选择Qwen3.5举例
需要运行的话只需要在cmd控制台(之前的打开方式,或者按 win+R 键输入 CMD 回车也行)输入
bash
ollama run qwen3.5会默认安装官方的latest版本,量化版本点击 View all 查看
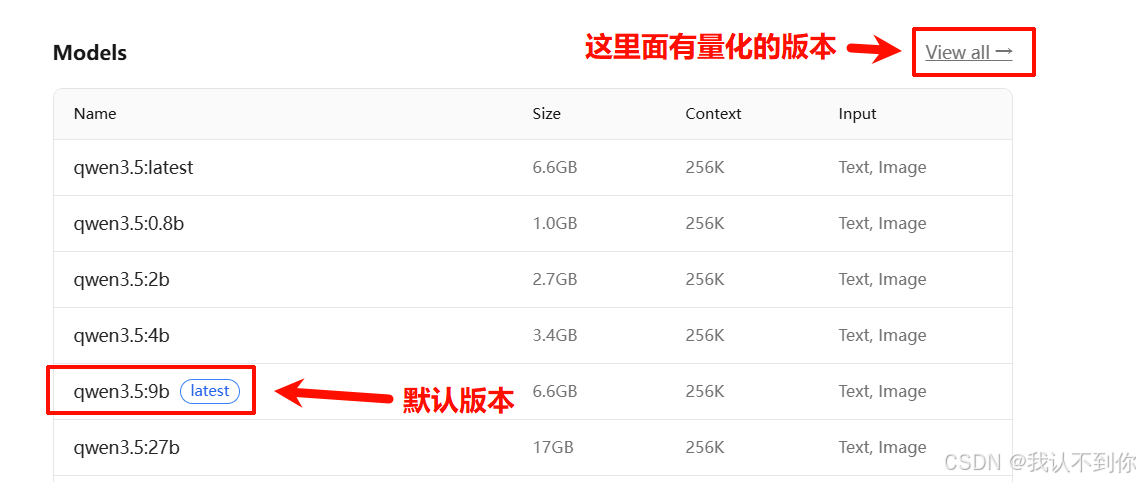
如果我们需要下载自己的版本只需要复制这个Name即可,如下:
bash
ollama run qwen3.5:0.8b(3、脚本下载
因为下载有点慢(每次下载一段时间就会限速)所以我放个bat脚本(就是一个文件的后缀为.bat的文件,文件名随意,保存下段命令后,双击执行即可)给大家使用
当然大家也可以按 ctrl+c(退出当前下载)然后重新输入下载命令即可
逻辑:下载2分钟,中断3秒继续执行,直到下载成功为止
模型、超时时间、重试时间都可以自己调整
bat
@echo off
setlocal enabledelayedexpansion
set MODEL=qwen3.5:4b
set INTERRUPT_SECONDS=120
set RETRY_DELAY_SECONDS=3
echo ========================================
echo Ollama Model Download Script
echo ========================================
echo Model: %MODEL%
echo Interrupt Interval: %INTERRUPT_SECONDS% seconds
echo Retry Delay: %RETRY_DELAY_SECONDS% seconds
echo ========================================
echo.
:download_loop
echo [%date% %time%] Checking if model is already downloaded...
ollama list | findstr /C:"%MODEL%" >nul 2>&1
if %errorlevel% equ 0 (
echo.
echo ========================================
echo [%date% %time%] Download completed!
echo ========================================
goto :end
)
echo [%date% %time%] Starting download...
rem Start ollama pull in a new cmd window and get its PID
for /f %%i in ('powershell -ExecutionPolicy Bypass -Command "$p = Start-Process cmd -ArgumentList '/k','ollama run %MODEL%' -PassThru; $p.Id"') do set DOWNLOAD_PID=%%i
echo PID: !DOWNLOAD_PID!
rem Wait for specified seconds then close the download window
timeout /t %INTERRUPT_SECONDS% /nobreak >nul
taskkill /PID !DOWNLOAD_PID! /F /T >nul 2>&1
timeout /t 1 /nobreak >nul
echo [%date% %time%] Download interrupted, waiting %RETRY_DELAY_SECONDS% seconds before retry...
timeout /t %RETRY_DELAY_SECONDS% /nobreak >nul
echo.
goto :download_loop
:end
echo.
echo Download finished successfully!
pause
endlocal(4、测试
还是通过cmd窗口运行命令
ollama ps查看进程。显示当前正在运行的模型及显存占用。
ollama list列出模型。显示本地所有已下载的模型。
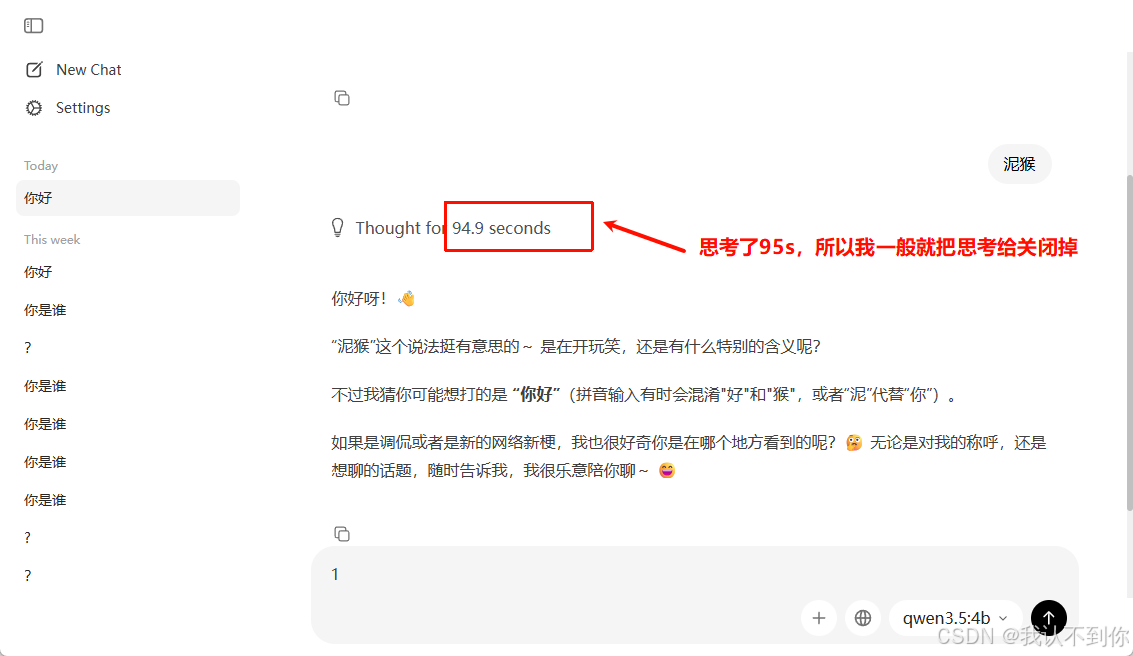
ollama run qwen3.5:4b --think=false运行模型。--think=false 的意思是不开启深度思考(qwen3.5模型是具备思考功能的)
bash
C:\Users\Admin>ollama ps # 这里因为没有启动所以没有显示
NAME ID SIZE PROCESSOR CONTEXT UNTIL
C:\Users\Admin>ollama list
NAME ID SIZE MODIFIED
qwen3.5:4b 2a654d98e6fb 3.4 GB 20 minutes ago
C:\Users\Admin>ollama run qwen3.5:4b --think=false
>>> 你好
你好!有什么我可以帮你的吗?😊
>>> Send a message (/? for help) # 退出的指令是 /bye 然后回车ollama app.exe 运行(就是在Ollama的安装目录下,之前改模型安装路径也打开过)
(5、退出:关闭Ollama就行了
2、第三方下载(魔塔(modelscope)、huggingface)
魔塔:模型库
huggingface:Models -- Hugging Face
因为 huggingface 需要魔法,所以我用魔塔举例,并且选用量化的模型(也是使用Qwen3.5举例)
(1、我们先重点讲一下量化和GGUF文件
GGUF :
是 LLaMA.cpp 团队为支持多种大模型(包括 LLaMA、ChatGLM、Med-Go 等)而设计的一种统一二进制格式,专门用于存储量化后的模型权重。它允许模型在 CPU/GPU 上快速推理,尤其适合本地部署。
量化:
原始大模型(如 Med-Go 32B)使用 FP16/FP32 浮点数存储参数,占用内存极大(例如 32B 模型需约 64GB 显存)。
量化就是将高精度浮点数转换为低精度整数(如 4-bit、5-bit),从而:
- 大幅减少模型体积(从几十 GB 压缩到几 GB)
- 提升推理速度
- 降低对硬件要求(可在普通 PC 上运行)
但代价是:轻微牺牲精度与性能
(2、量化命名规则和含义:
| 格式 | 含义 | 特点 |
|---|---|---|
Q2_K |
2-bit 量化,K 表示使用 "K-quantization" 方案 | 最小体积,速度最快,但精度最低 |
Q3_K_L |
3-bit 量化,L = "Low precision" | 平衡大小与性能 |
Q3_K_M |
3-bit 量化,M = "Medium" | 比 Q3_K_L 更好一些 |
Q3_K_S |
3-bit 量化,S = "Small" | 轻量版,适合资源受限设备 |
Q4_K_M |
4-bit 量化,M = "Medium" | 推荐首选!平衡速度、精度、内存 |
Q4_K_S |
4-bit 量化,S = "Small" | 体积更小,略逊于 M |
Q5_K_M |
5-bit 量化,M = "Medium" | 高精度,适合专业用途 |
Q5_K_S |
5-bit 量化,S = "Small" | 精度稍低,速度快 |
Q6_K |
6-bit 量化 | 几乎接近 FP16 精度,体积较大 |
Q8_0 |
8-bit 量化,无压缩 | 接近原生精度,几乎无损失 |
(3、我们去魔塔选择自己配置匹配的模型进行下载(GGUF文件)
实际尝试,4-bit的版本根本就是乱答,哈哈哈,可以换个模型来玩
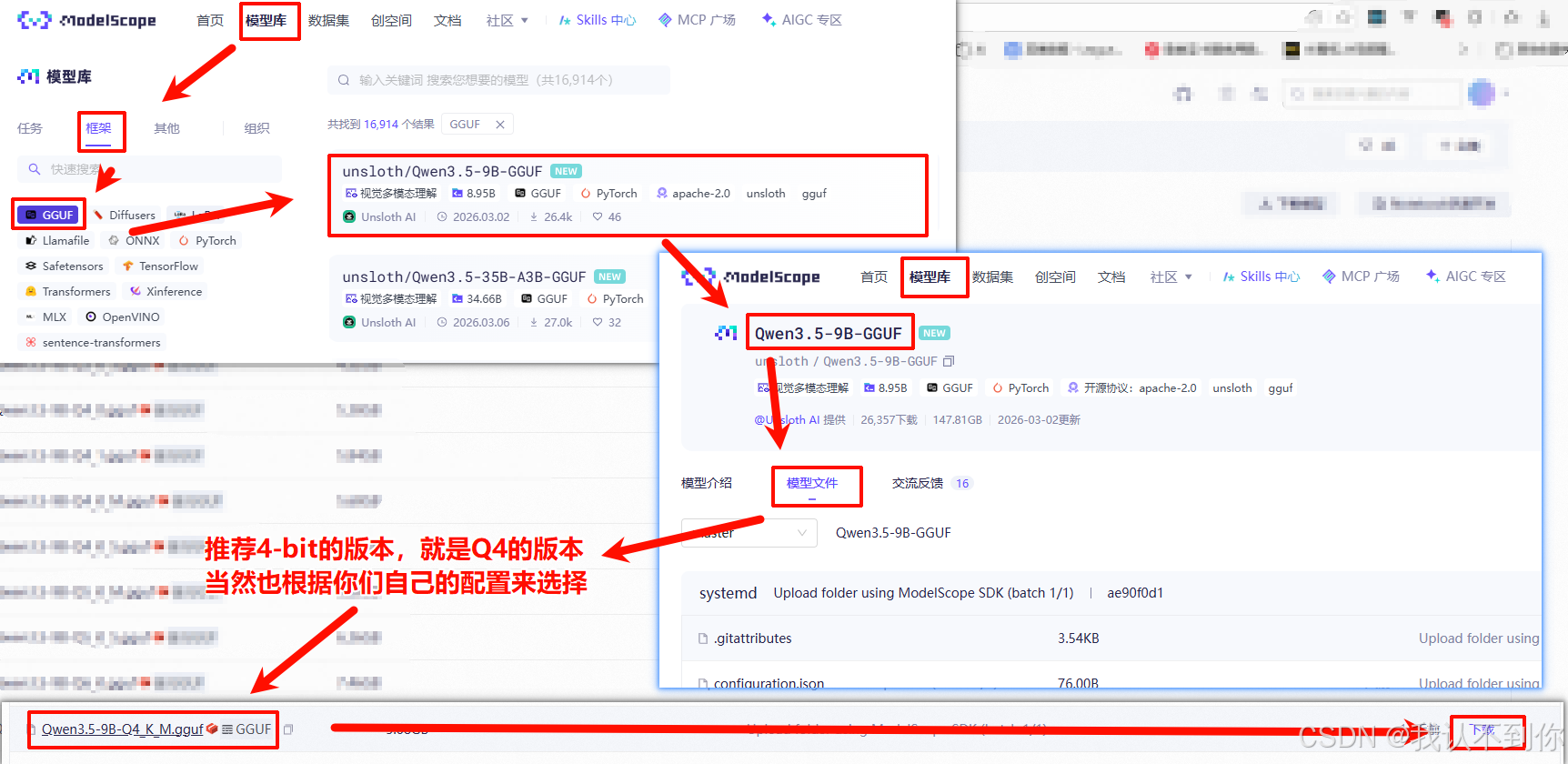
(4、量化模型选择(Qwen3.5举例)
我们既然使用了unsloth量化的模型,就去unsloth 官网看看该怎么选择吧
Unsloth 是一个专门用于加速大型语言模型(LLM)微调 的开源库,同时显著降低显存占用。它的核心目标是让大模型的微调变得更快、更省显存、更易于上手,同时保持甚至提升模型的精度。
根据下面这张表来选择吧
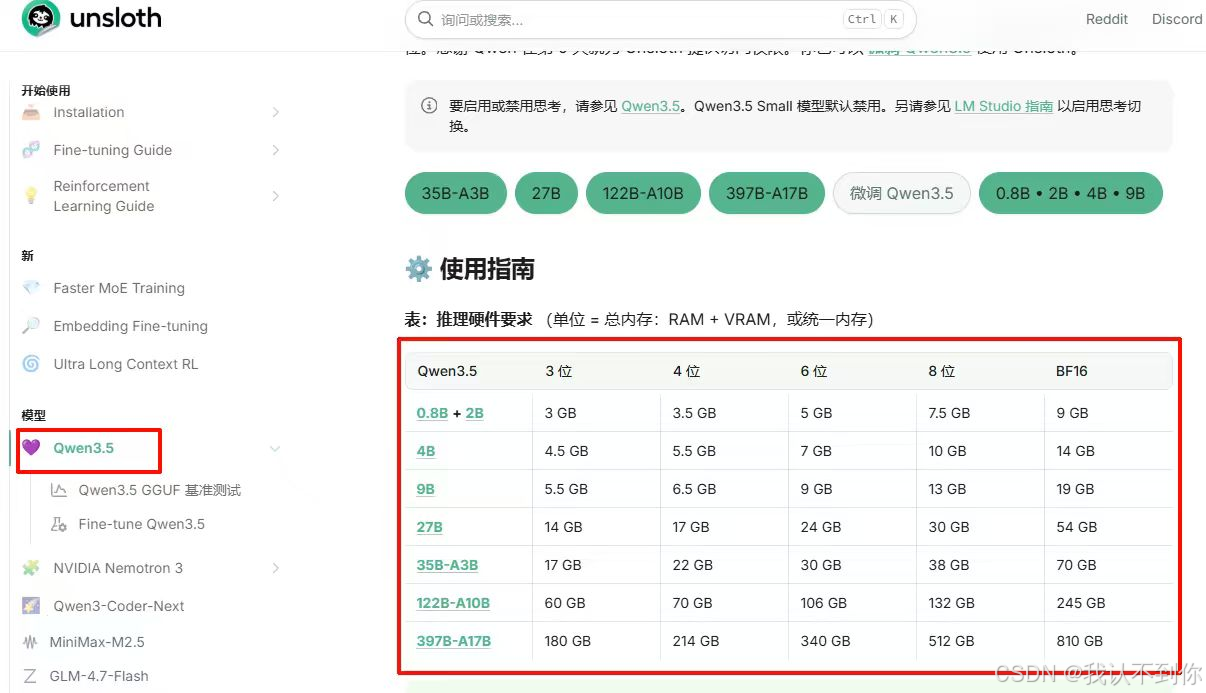
(5、下载完成后测试
打开cmd窗口
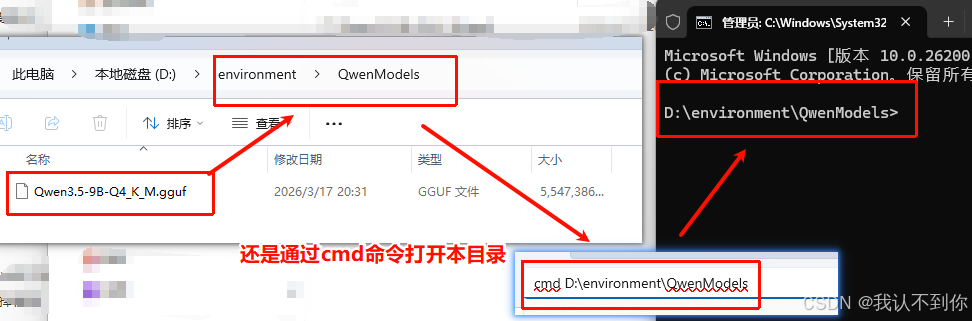
执行 ollama create 命令,运行前记得把 ollama app.exe 打开
ollama create qwen3.5:666 -f ./ModelFile:把模型加载到ollama
ollama create:创建模型。根据 Modelfile 创建自定义模型
qwen3.5:666:自定义模型的名字
-f ./ModelFile:-f是--file的简写 ./ModelFile 指的就是当前文件夹下面的 gguf文件
ollama list:列出模型。显示本地所有已下载的模型。
ollama run qwen3.5:666:运行模型,说实话我选这个4-bit的模型有点拉胯,这里只是作为创建、运行、删除参考
ollama rm qwen3.5:666:删除模型。移除本地模型释放空间。
bash
D:\environment\QwenModels>ollama create qwen3.5:666 -f ./ModelFile
gathering model components
copying file sha256:03b74727a860a56338e042c4420bb3f04b2fec5734175f4cb9fa853daf52b7e8 100%
parsing GGUF
using existing layer sha256:03b74727a860a56338e042c4420bb3f04b2fec5734175f4cb9fa853daf52b7e8
writing manifest
success
D:\environment\QwenModels>ollama list
NAME ID SIZE MODIFIED
qwen3.5:666 7874b6f05a01 5.7 GB 10 seconds ago
qwen3.5:4b 2a654d98e6fb 3.4 GB 44 minutes ago
D:\environment\QwenModels>ollama run qwen3.5:666 # 运行我们创建的模型,由于模型在乱答,所以回答我就不贴出来了
D:\environment\QwenModels>ollama rm qwen3.5:666 # 这里是删除操作
deleted 'qwen3.5:666'
D:\environment\QwenModels>ollama list # 这里可以看见已经被删除了
NAME ID SIZE MODIFIED
qwen3.5:4b 2a654d98e6fb 3.4 GB About an hour ago(6、退出:关闭Ollama就行了
结语
至此Ollama安装本地LLM已经完成了
后续我还会更新Openclaw+Ollama+本地大预言模型调用和Openclaw链接飞书机器人,点赞越多更新越快
后续反向好的话,我会更新 Claude Code(Claude Sonnet 4.6)、Chat GPT 5.4、CodeX 等使用的文章