 摘要
摘要
语言为视觉任务性能的指定与评估提供了一种自然的交互接口。要实现这一潜力,视觉语言模型(VLMs)必须成功融合视觉信息与语言信息。本研究将视觉语言模型与其视觉编码器的直接输出结果进行对比,以此探究模型在跨模态信息融合方面的能力。在一系列以视觉为核心的基准任务(如深度估计、特征匹配)中,我们发现视觉语言模型的表现远逊于其视觉编码器,性能甚至降至接近随机猜测的水平。我们通过对视觉语言模型的整体展开一系列分析,探究上述实验结果的成因,具体分析维度包括:1)视觉表征的退化问题;2)模型对任务提示词的鲁棒性不足;3)语言模型在任务求解过程中所扮演的角色。研究发现,模型在完成这类视觉核心任务时的性能瓶颈正源于第三个维度:视觉语言模型未能有效利用整个模型架构中本可便捷获取的视觉信息,且继承了大语言模型(LLM)中固有的语言先验知识。本研究为开源视觉语言模型的失效模式提供了诊断思路,并提出了一系列评估方法,这些方法将为未来探究视觉语言模型的视觉理解能力提供有益参考。
1. 引言
视觉语言模型 (VLM) 旨在结合大语言模型 (LLM) 与大规模视觉编码器的力量来执行多模态任务。开源 VLM 通常由三个主要部分组成:预训练视觉编码器、投影层(Projector)和 LLM,并通过文本提示(Prompt)提供灵活的交互界面。此前有研究认为,VLM 为理解视觉模型表示及下游应用提供了一种新范式。然而,VLM 在"以视觉为中心"的任务中的表现揭示了视觉与语言集成过程中的严重问题,这提醒我们在对其底层视觉表示下结论时需保持谨慎。
开源 VLM 在许多任务上表现出色,尤其是那些依赖 LLM 内部专家级知识的任务。然而,当 VLM 需要完全依赖图像而非背景知识 时,其表现会大幅下降,往往仅达到随机水平。令人困惑的是,之前的研究表明,这些嵌入在 VLM 中的大型视觉模型,在单独对其表示进行探测(Probing)时,在这些"视觉中心任务"上表现极其优异。此外,我们观察到视觉编码器的性能与其对应的 VLM 在这些任务上的表现毫无相关性 ;最强的视觉表示(通常是 DINOv2)在作为 VLM 内部组件时,往往表现不佳。为了理解这一现象,我们将 VLM 与其视觉编码器进行对比。我们将测试基准定义为**"以视觉为中心"的任务**:即纯粹依靠视觉输入即可解决、无需领域知识的任务。这排除了对 LLM 知识的依赖,更聚焦于视觉表示。我们分析了三个潜在的失效点:视觉表示质量、对提示词的敏感度,以及语言模型利用视觉表示的能力。
核心发现如下:
-
性能普遍下降:从标准的视觉探测策略转向基于 VLM 的评估会导致性能全面下滑,甚至跌至随机水平。这种趋势在不同的视觉编码器预训练策略中普遍存在,且无法保持模型在视觉基准测试中的排名。此外,投影层和 LLM 各层中的视觉表示并未退化,通过视觉探测策略仍能解决任务。
-
提示词微调效果有限:对 VLM 进行提示词微调(Prompt-tuning)虽能略微提升性能,但收益递减,且无法弥补与标准视觉评估策略之间的差距。
-
LLM 的利用能力是瓶颈 :LLM 利用其视觉表示的能力是限制 VLM 性能的关键。在大多数任务中,微调 LLM 比微调投影层或视觉编码器带来的准确率提升更高。VLM 的回答分布在很大程度上反映了其"盲答"(不看图时的回答)偏见。微调 LLM 也是克服这些偏见的最有效手段
2. 评估设置 (Evaluation Setup)
为了研究评估策略对任务性能的影响,我们评估了 4 种不同的视觉骨干网络:DINOv2 L/14 (自监督纯视觉预训练)、ViT-IN1k L/16 (ImageNet 监督预训练)、以及 CLIP L/14 和 SigLIP L/14 (视觉-语言对比预训练)。我们使用了来自 Karamcheti 等人(2024)的检查点,将每个视觉骨干与 Vicuna-v1.5 配对。投影层(Projector)使用 LLaVA v1.5 的数据集进行视觉-语言对齐训练,而 ViT 和 LLM 组件保持冻结(Frozen) 。这样可以确保 VLM 中的视觉权重与原始 ViT 完全一致,从而在保持视觉部分不变的情况下,专门分析 LLM 解码器的影响。此外,为验证普适性,我们还评估了主流 VLM:Qwen-VL、Phi-3-V 和 InternVL。
在训练过程中,左边的"眼睛"(ViT)不动,右边的"大脑"(Vicuna/LLM)也不动。只训练中间那一层极薄的投影层(Projector)。
我们选择了**"以视觉为中心"的任务**,即模型仅需识别输入图像的视觉特征,而不依赖语言知识或领域专家知识。
2.1 深度估计 (Depth Estimation)
使用 CV-Bench 中的**深度排序(Depth Order)**任务。
-
评估 VLM:直接询问两个框出的物体哪个离相机更近。
-
评估视觉编码器 :在其上方训练一个 DPT(Dense Prediction Transformer) 预测头。通过比较预测深度图中两个边界框内的平均深度来得出结论。
2.2 基于对应关系的评估 (Correspondence-based Evaluations)
这些任务测试像素级的匹配能力。给定参考图中的一个点,模型必须在第二张图的 A/B/C/D 四个点中选出对应点。
-
评估视觉编码器 :计算参考点特征与四个候选点特征之间的余弦相似度,选择得分最高者。
-
语义对应(Semantic Correspondence):匹配同类物体但外观不同的部位(如两只不同动物的左腿)。
-
物体功能(Object Affordance):匹配具有相同功能的部位(如不同物体的"把手"),即使它们属于不同类别的物体。
-
底层匹配(Low-level Matching):匹配同一场景在不同光照或视角下的像素点。
2.3 3D 物体感知 (3D Object Awareness)
使用 MOCHI 基准测试物体中心化表示。参与者或模型需在 3 或 4 个选项中识别出包含不同物体的图像。
- 评估视觉编码器 :通过计算 CLS 嵌入向量 的成对余弦相似度,选择平均得分最低的示例。
2.4 艺术风格 (Art Style)
测试模型匹配视觉特征(而非艺术史知识)的能力。给定参考图,从两个选项中选出风格更接近的一张。评估视觉编码器 :计算最后一层 ViT Patch 特征的 Gram 矩阵。该矩阵捕获了空间解耦的纹理信息,代表艺术风格。通过计算风格特征之间的均方误差(MSE)来进行预测
3. 初步观察 (Initial Observations)
3.1 大规模视觉编码器表现优异
 表3
表3
如表 3 所示,大型视觉模型在所有任务上的表现都远超随机水平(例如深度估计达到 88.7%)。这并不意外,因为之前的研究已证明 DINOv2 等模型在以视觉为中心的任务中表现卓越。我们还发现,在需要空间感知的任务中(除"艺术风格"外),DINOv2 始终优于其他编码器 。这证明了视觉编码器提取的表示对于各种视觉任务都非常有用,且这种性能排名与之前的研究一致:纯视觉预训练模型在空间依赖型任务上通常优于视觉-语言预训练模型(如 CLIP)。
3.2 VLM 的表现远逊于其编码器
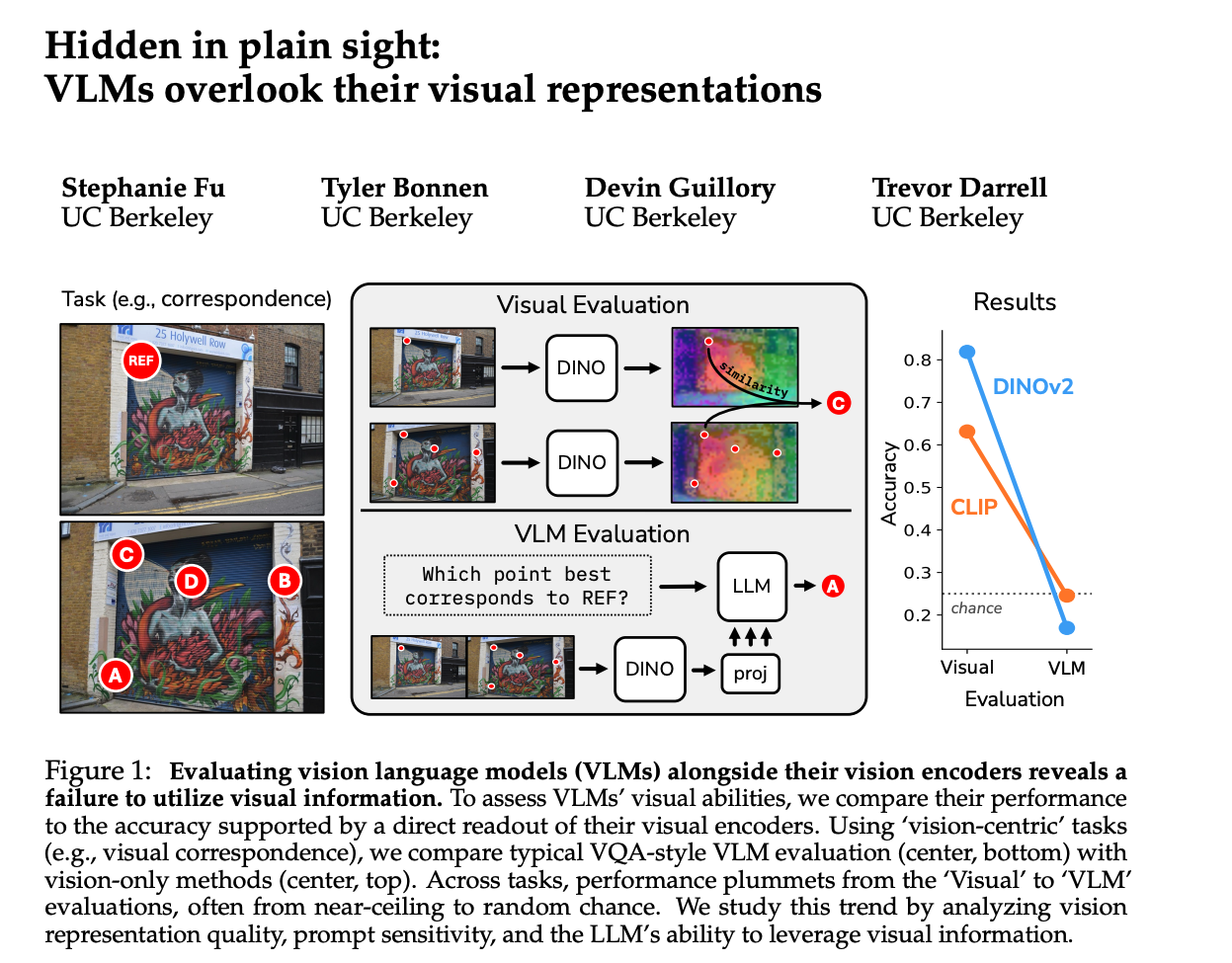
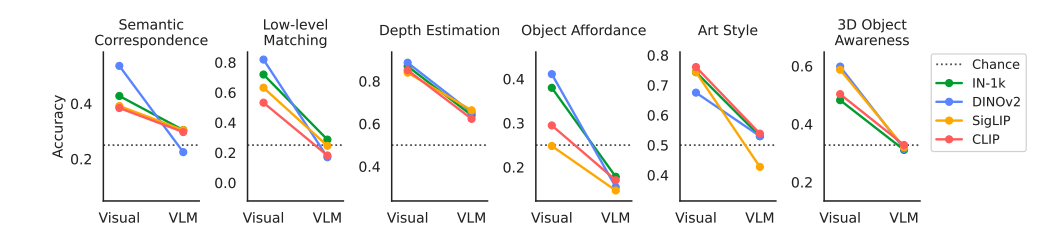 图2
图2
我们的核心观察是:当评估策略从"标准视觉评估"转向"VLM 问答"时,性能出现了普遍骤降。如图 2 所示,性能往往从接近满分跌至随机水平。底层匹配任务跌幅最大(45.5%),深度估计跌幅最小(21.7%)。这表明,在视觉编码器到 LLM 输出的过程中,某些东西(视觉表示质量或其利用能力)**"消失"**了。即使是 InternVL 这样专门为 VLM 训练的视觉编码器,也无法逃脱这种性能骤降。
3.3 VLM 改变了视觉编码器的性能排名
在直接进行视觉探测(Probing)时,DINOv2 几乎在所有任务中都表现最好。然而,一旦转为 VLM 评估,DINOv2 的性能跌幅却不成比例地大。这种不对称的跌幅导致了排名的洗牌。此前有研究结论称 CLIP 式预训练最适合 VLM,但我们的结果表明,这个结论可能下得过早------DINOv2 的潜力只是被 VLM 的集成方式掩盖了。
3.4 VLM 的选择反映了其"盲答"基准
既然视觉编码器接近满分而 VLM 接近随机,VLM 是否根本没看图?我们对比了 VLM 在有视觉输入和完全无视觉输入(盲答)时的答案分布。结果令人震惊:两者的答案分布极其相似(见图 4) 。这说明 VLM 在很大程度上 忽略了图像 ,而只是在重复其 LLM 组件内部固有的偏见。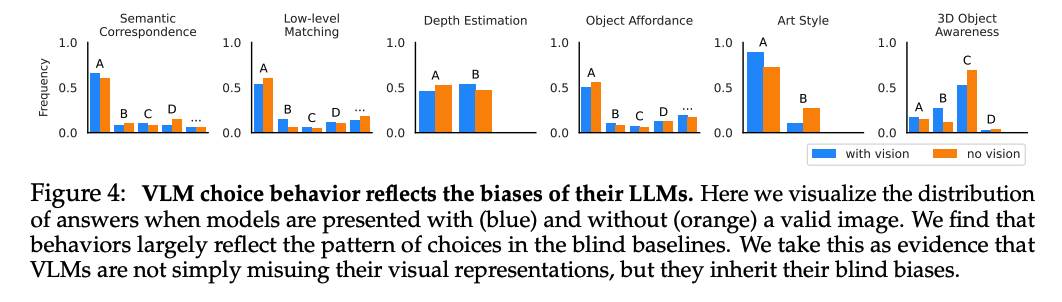
4 视觉语言模型性能分析
4.1 视觉特征在视觉语言模型各层中保持完整性
视觉语言模型性能表现不佳的一个可能原因是视觉表征的退化 ------ 具体来说,投影层和 / 或大语言模型层所执行的变换操作,可能丢弃了与任务相关的视觉信息。若视觉评估策略在视觉语言模型的其余所有层中仍保持有效,则表明相关信息在模型的每个阶段都得到了保留且可被获取。需说明的是,这是一个充分非必要条件:即便视觉表征无法适配我们的探测方法,大语言模型仍可通过其他算法利用这些信息。尽管如此,实验结果仍满足该条件:如图 5 所示,视觉表征在经过投影层(灰色区域)和大语言模型层(白色区域)后仍保持完整,这说明模型性能下降并非由视觉信息丢失导致。
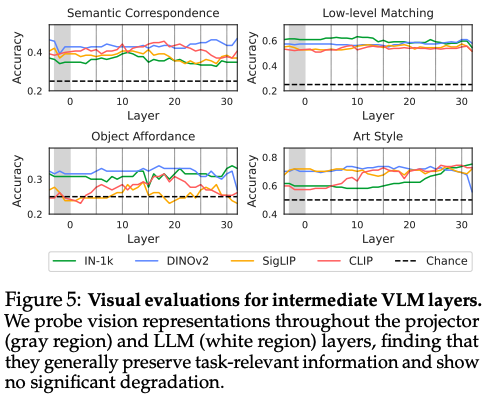
我们还发现了两个值得关注的趋势 / 特例:第一,模型性能的最大幅度变化往往出现在大语言模型的最后一层。DINOv2 的视觉表征在物体功能属性 和艺术风格 任务中,直至最后一层仍保留有效信号,却在该层出现急剧下降;在底层特征匹配 任务中,所有模型的最后一层均出现了类似但幅度更小的性能下降。我们推测,这种变化源于大语言模型在最后一层的优先级转变 ------ 从保留和关注有效特征,转向生成自然语言答案。
第二,基于 ImageNet 监督训练的视觉 Transformer(IN-1k)构建的视觉语言模型,在大语言模型的深层网络中对艺术风格的编码效果反而更好,但其最终任务性能仅为 53%。这一发现进一步印证了视觉语言模型内部的视觉表征质量优异,同时也体现出其视觉问答性能与视觉表征质量的不匹配。
4.2 提示词调优的改进效果微乎其微
若视觉表征并非视觉语言模型性能低下的主因,是否可能是模型对提示词的设计方式高度敏感?为验证这一可能性,我们在原始提示词嵌入中加入可学习的前缀向量进行实验。参考莱斯特等人(2021)的方法,我们在原始提示词嵌入前拼接随机初始化的可训练向量,并在该任务的 1000 个视觉问答样本上完成调优。实验中固定视觉语言模型和原始提示词不变,通过最小化下一个令牌的预测分布与真实分布之间的交叉熵完成训练。实验结果如图 6 所示,训练细节见补充材料。
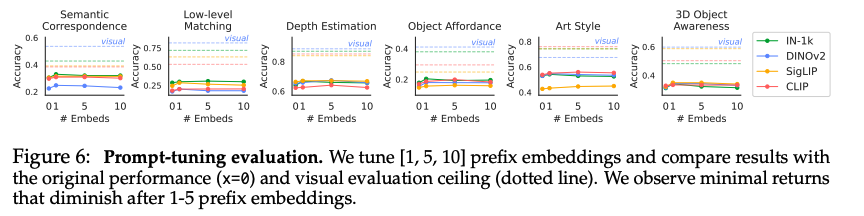
研究发现,仅添加一个前缀嵌入对模型性能的提升微乎其微(见图 6),尤其是在视觉语言模型的性能本就接近随机猜测水平的情况下;同时,增加前缀嵌入的数量(5 个、10 个)进行调优,也并未持续提升模型性能。上述结果表明,即便视觉语言模型已对当前任务完成编码,其在视觉核心任务上的表现仍不尽如人意,这也排除了输入提示词敏感性 作为模型性能瓶颈的可能性。
4.3 大语言模型对视觉表征的利用不足
在排除了视觉语言模型中视觉表征的退化(4.1 节)和对提示词形式的敏感性(4.2 节)这两个性能瓶颈后,我们接下来分析大语言模型本身在任务中的作用。我们在每个视觉核心任务的 5000 个样本上,对视觉语言模型的各个独立组件(视觉 Transformer、投影层、大语言模型)分别进行微调。实验采用与评估套件一致的视觉问答格式,通过低秩适配调优(LoRA)完成训练,同时对各组件的可训练权重矩阵进行控制,确保所有组件的调优参数量一致(均为 1670 万个参数,与投影层全量微调的参数量相当),具体训练和实现细节见补充材料。
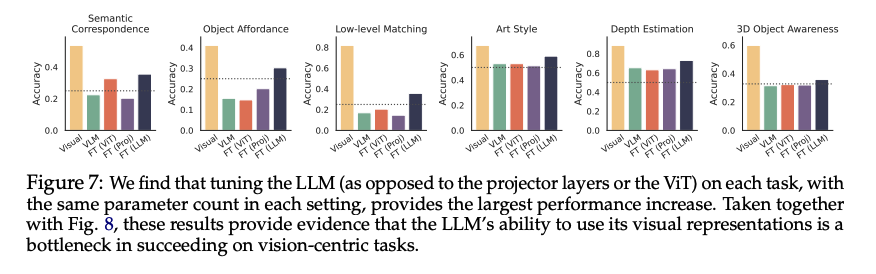 如图 7 所示,相较于对投影层或视觉 Transformer 层的调优,对大语言模型的调优为性能带来了最大幅度的提升。为进一步探究这一效果的成因,我们分析了基于 DINOv2 的视觉表征在大语言模型微调后的注意力分布变化。结果发现,在特征匹配类任务中,微调显著增强了模型对多项选择标签、参考点及其他文本信息的注意力(尤其是在大语言模型的第 4 层)。对投影层或视觉 Transformer 的调优,无法在任意注意力层或注意力头中稳定突出这些关键区域;而对大语言模型的调优,则提升了模型在关键区域定位并利用视觉表征的能力。
如图 7 所示,相较于对投影层或视觉 Transformer 层的调优,对大语言模型的调优为性能带来了最大幅度的提升。为进一步探究这一效果的成因,我们分析了基于 DINOv2 的视觉表征在大语言模型微调后的注意力分布变化。结果发现,在特征匹配类任务中,微调显著增强了模型对多项选择标签、参考点及其他文本信息的注意力(尤其是在大语言模型的第 4 层)。对投影层或视觉 Transformer 的调优,无法在任意注意力层或注意力头中稳定突出这些关键区域;而对大语言模型的调优,则提升了模型在关键区域定位并利用视觉表征的能力。
我们也发现了一个特例:在三维物体感知任务中,调优带来的性能提升并不显著。对此我们提出两点推测:第一,与其他需要局部特征提取的任务(如目标检测框、纹理特征)不同,三维物体感知需要更抽象、更具变异性的特征,轻量级微调难以完整捕捉这类特征;第二,我们基于 ShapeNet 数据集构建的训练数据,无法完美匹配 MOCHI 基准数据集 ------ 后者不仅包含 ShapeNet 的渲染图像,还涵盖了更广泛的物体类型和场景。更多注意力可视化结果见补充材料,可进一步印证上述效应。
4.3.1 大语言模型调优缓解了语言先验偏差
我们在 3.4 节中发现,视觉语言模型不仅在视觉核心任务上表现不佳,还继承了大语言模型的语言偏差。结合前文 "对大语言模型的调优对性能提升效果最优" 的结论,我们通过计算预测分布与真实分布之间的总变分距离,重新验证了这一现象。如表 4.3.1 所示,经过调优的大语言模型生成的答案,与真实分布的总变分距离最小;唯一的特例是深度估计任务 ------ 原始视觉语言模型的预测分布本就与真实分布高度贴合。
综合 4.3 节和 4.3.1 节的实验结果,我们得出结论:大语言模型是视觉语言模型在视觉核心任务中做出准确预测的限制性因素,而其局限性体现在两个方面:一是对视觉显著区域的注意力不足,二是过度依赖大语言模型中固有的、对特定多项选择答案的偏置。需说明的是,我们并非将任务直训作为解决视觉语言模型视觉表征利用能力不足的通用方案;相反,我们通过该方法定位了视觉语言模型的失效原因,并探究了如何通过提升大语言模型对视觉表征的利用能力,使其克服语言先验偏差,进而实现性能的高效提升。
6 讨论 尽管视觉语言模型在基于知识的基准任务上表现亮眼,但在某些方面,这类模型仍未能真正发挥其视觉感知能力。本研究揭示了一个核心问题:视觉编码器生成的表征,与视觉语言模型对该表征的低效利用之间存在严重脱节,这导致模型在视觉核心任务上的性能表现远未达到最优水平。视觉表征单独评估时性能表现优异,可一旦融入视觉语言模型,模型的视觉核心任务能力便会大幅下降,进而依赖自身的语言先验知识完成任务。
现有相关研究主要分为两类:一类将视觉语言模型的性能局限归因于视觉编码器的能力不足,并提出通过编码器集成的方式弥补这一缺陷(Karamcheti 等人,2024;Tong 等人,2024b)。而本研究表明,这一策略难以解决视觉语言模型在视觉表征利用上的根本问题,因为视觉编码器并非模型的性能瓶颈。
另一类研究则将视觉语言模型作为评估视觉表征的交互接口(Tong 等人,2024a)。该策略虽能支持更广泛的基准测试任务,但我们在此提醒:当基于视觉语言模型的评估出现以下两种情况时,不宜对视觉表征的性能下结论------其一,模型评估性能接近随机猜测水平;其二,与视觉编码器直接输出的评估结果相比,各类视觉编码器的性能排名发生变化。现有研究常依据视觉语言模型的实验结果,认为某些视觉编码器的性能始终优于其他类型的编码器(其中最典型的结论为CLIP/SigLIP远优于DINOv2),但本研究结果显示,采用视觉直接评估与基于视觉语言模型的评估两种策略时,视觉编码器的性能排名并不存在相关性。
我们认为,研究中所观察到的视觉语言模型之视觉编码器的性能局限,究其原因,更可能是模型对视觉表征的不当使用,而非视觉表征本身不具备完成当前任务的能力。 本研究证实,视觉语言模型因无法将视觉信息有效融合至其语言模块,最终导致性能表现不佳,但这并非意味着现有视觉编码器足以胜任所有视觉任务。事实上,当前主流的大规模视觉编码器存在诸多已有充分研究佐证的缺陷。例如,在三维形状推理任务中,人类的表现始终优于视觉模型(Bonnen 等人,2024),这表明视觉编码器的性能仍有较大提升空间。
尽管本文提出,视觉语言模型的失效模式更应归因于视觉-语言信息的融合环节,而非视觉编码器本身的性能问题,但我们同样认同现有研究的观点,即研发性能更优的视觉编码器至关重要------因为视觉编码器的能力与性能出色的大语言模型相辅相成,二者共同作用,才能让模型在视觉核心类视觉问答任务中取得理想表现。 最后,尽管本研究对当前视觉语言模型的性能做出了批判性评估,但不可否认,语言仍是指定和评估模型性能的高效交互接口。诚然,许多任务难以仅通过图像进行定义,而借助语言,我们能够对模型的各类复杂视觉能力展开多样化探测。但本研究的结果也提醒研究者:在进行视觉语言模型的设计选型,或通过语言类基准任务推断模型视觉能力时,需保持审慎态度。因为这类评估方式,有可能低估视觉编码器的实际能力,也可能无法真实反映其性能表现。