02计算机组成原理-可信寄存器层
前言
存储器这章最重要的还是前面讲的主存和Cache。这里讲的可信寄存器层和后面一节的虚拟存储器大家也需要了解,只是重要程度没有前面的高。这节讲的可信存储器就是在讲存储器的可信性,之前我们讲的都是关注效率但是我们对于硬件来说我们还得关心它是否能完成我们交给的工作。这就是可信性。从字面来讲,也就是值不值得信任。它包括可靠性 恢复性 维修性 耐久性 安全性等等。
1.失效与恢复
服务状态:
- 服务实现:系统正常运作,提供的服务与用户的需求相符。
- 服务中断:系统出现故障,提供的服务无法满足用户需求。
失效与恢复
失效:系统从服务实现状态转换到服务中断状态的过程。失效可以是永久性的(系统无法自行恢复)或间歇性的(系统可能会自行恢复或需要外部干预来恢复)。
间歇性失效:这类失效使得系统在正常与异常状态之间交替,增加了诊断和修复的难度。它们可能导致数据一致性问题,服务响应不可预测,以及维护成本的上升。准确识别间歇性失效的原因可能需要复杂的日志分析、监控和故障注入测试。
永久性失效:相比而言,一旦发生永久性失效,系统或组件将无法恢复至正常服务状态,除非进行替换或修复。虽然诊断相对直接,但这类失效仍然要求系统设计时要有适当的备份或冗余机制,以减少对服务连续性的影响。
恢复:系统从服务中断状态转换回服务实现状态的过程。
2.可靠性和可用性
可靠性:
可靠性关注的是系统在特定时间内无故障执行其预期功能的能力。可靠性可以通过平均无故障时间(MTTF)来量化,它表示系统从开始运行到发生首次故障的平均时间长度。MTTF越长,表明系统在给定时间内保持不发生故障的能力越强。
年失效率(AFR)是从另一个角度衡量可靠性,它直接给出了系统或设备在一年内预期的失效概率,便于业界比较和理解不同设备的可靠性水平,尤其是在MTTF可能涉及非常大的数值时,AFR提供了更直观的视角。
可用性:
虽然可靠性是关于系统在不出故障的情况下持续工作的能力,可用性则进一步考虑了系统在需要时实际可访问和使用的程度。它不仅涵盖了系统因内部故障而不可用的时间,还考虑了计划内维护、升级以及其他可能导致服务中断的因素。可用性通常用百分比表示,在一个时间段内,系统处于可操作状态的时间占总时间的比例。一个常用的公式是:可用性=(运行时间−停机时间)/运行时间×100%
3.服务中断和度量
服务中断的维修平均时间(MTTR)是衡量系统从发生故障到恢复正常服务状态所需时间的指标,是评估和改善系统维护效率的关键参数。
而平均无故障时间(MTTF)专注于系统或组件在两次故障之间的正常运行时间,两者结合可以得到平均故障间隔时间(MTBF),即系统从一次故障中恢复到下一次故障发生之间的平均时间长度。
不过,根据最新的可靠性工程实践,MTBF的概念已经逐渐被MTTF替代,因为MTTF更准确地描述了单一组件或系统无故障运行的预期时间,避免了MTBF可能引起的混淆,尤其是在考虑维修和恢复时间的情况下。
MTTR (Mean Time to Repair): 指的是系统从故障状态修复到正常工作状态所需的平均时间。这个时间越短,表示系统恢复能力越强。越小越好。
MTBF (Mean Time Between Failure): 是系统连续两次故障之间的平均时间。虽然MTBF经常被提及,但MTTF对于评估系统的无故障运行时间更为直接。越长越好。
可用性是指系统正常工作时间在连续两次服务中断间隔时间中所占的比例,计算公式为:
可用性=MTTF/(MTTF+MTTR)
这个公式清晰地展示了提高系统可用性的两个途径:
一是增加MTTF,即延长系统无故障运行的时间;
二是减少MTTR,即加快故障检测与修复的速度。
提高MTTF:
1.故障避免技术
-
设计优化:在产品设计阶段就考虑到可能的故障模式,采用更加稳健的设计原则,比如减少零件数量、使用已验证的成熟技术、确保良好的散热设计等。
-
材料选择:选用高质量、耐磨损、耐腐蚀的材料,确保组件在恶劣环境下的长期稳定运行。
-
制造质量:实施严格的生产控制和质量检验流程,如六西格玛、零缺陷管理等,确保制造过程中的质量一致性。
-
软件质量保证:通过代码审查、单元测试、集成测试等手段,确保软件无明显缺陷,提高软件的稳定性。
2.故障容忍技术
-
硬件冗余:如前所述,使用磁盘镜像、RAID系统、双电源供应、多路径网络连接等,确保即使某一部分发生故障,系统仍能继续运行。
-
信息冗余:在数据存储和传输过程中加入校验位,如ECC内存、奇偶校验码等,可以检测并纠正错误,减少数据损坏的风险。这里后面会详讲。
-
软件冗余:设计程序的多重实例或热备份服务,当主服务出现问题时自动切换到备用服务,确保服务不间断。
3.故障预报技术
-
实时监控:部署传感器和监控软件,持续收集系统运行的各种参数,如温度、电压、电流、工作负载等。
-
数据分析:运用大数据分析、机器学习算法对收集到的数据进行分析,识别故障发生的早期迹象或趋势。
-
预警系统:建立预警机制,当预测模型判断某组件即将达到故障阈值时,提前发出警告,安排维护或更换。
-
预防性维护:基于故障预报结果,制定并执行预防性维护计划,避免故障实际发生。
结合这些策略,不仅可以有效提高系统的MTTF,还能通过快速响应降低MTTR,最终提升系统的整体可用性和用户体验。
可信性(或者称为系统信任性)虽然不如可靠性和可用性那样可以直接量化,但它更多地涉及用户对系统能够始终如一地、正确地执行其预期功能的信任程度。它包含了安全性、隐私保护、数据完整性等多个维度,这些往往通过设计原则、合规性验证、用户反馈等软性指标来评价,而非简单的数学公式所能概括。增强系统的可信性通常涉及综合措施,比如加强数据加密、实施严格的身份验证机制、透明的错误处理和通知策略等。
4.信息验证
在主机之间进行传递数据的时候,如果距离太远,信息可能会出错,那我们怎么保证这些数据信息的安全呢?后面讲的内容和计算机网络是重合的,大家可以一起复习。
4.1汉明编码(海明编码)
汉明码是一种广泛应用的纠错编码方案,特别适用于检测并纠正存储器中的单比特错误,对于提高数据传输和存储的可靠性至关重要。
汉明距离(Hamming Distance)是衡量两个等长二进制序列差异的一种方法,它简单地统计两个序列中不同位置的比特数。例如,序列0111和1101的汉明距离为2,因为它们在第二和第四位上不同。
在编码设计中,如果码字间的最小汉明距离为2,这意味着任何两个合法码字之间至少有两位不同。然而,这样的编码只能区分完全相同的码字和恰好有一位差异的码字,但无法明确区分是哪一位出错,也无法区分是一位错误还是多位错误。因此,如果要求能够检测并纠正单比特错误,编码方案必须设计得更加巧妙,确保码字间的最小汉明距离至少为3。
检错:检查d位错误,编码的码距要d+1位。原理:


所以需要多加一位来检错。
纠错:纠正d位错误,编码的码距要2d+1位 。原理:
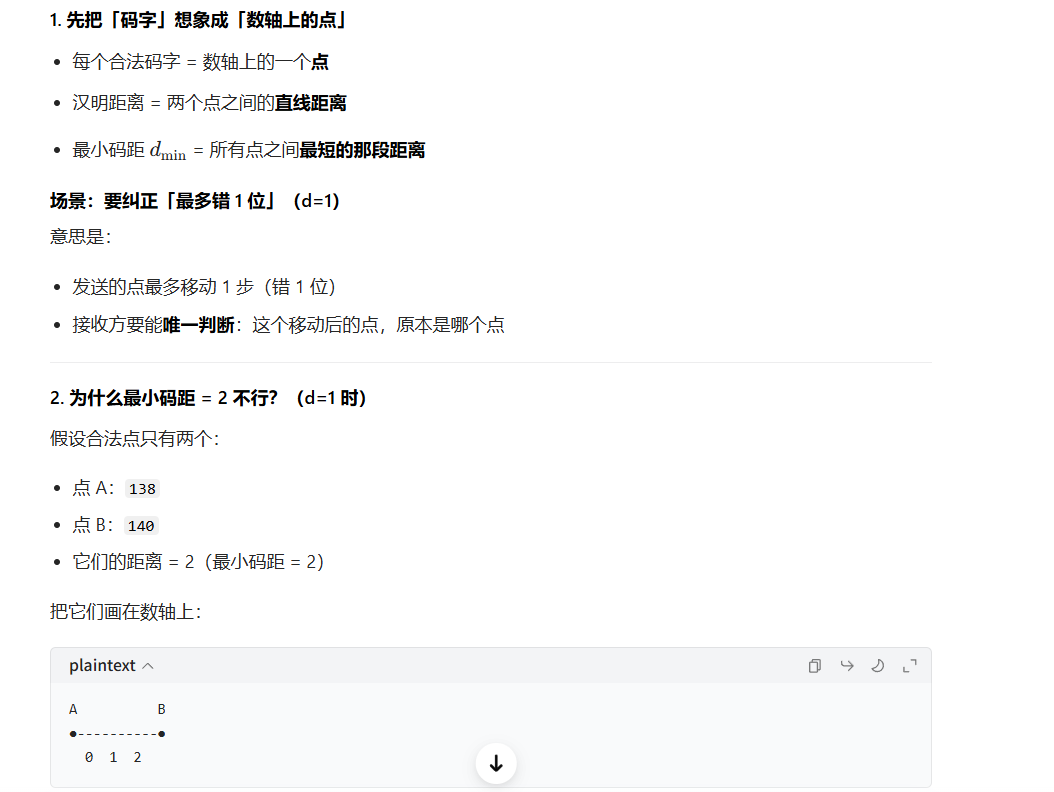
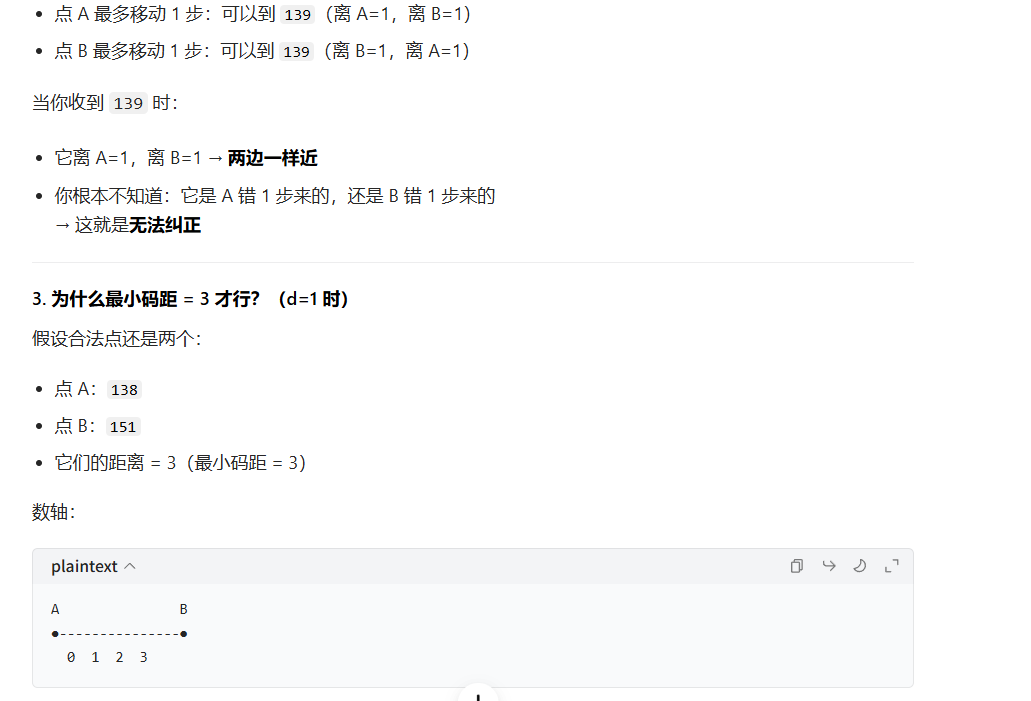
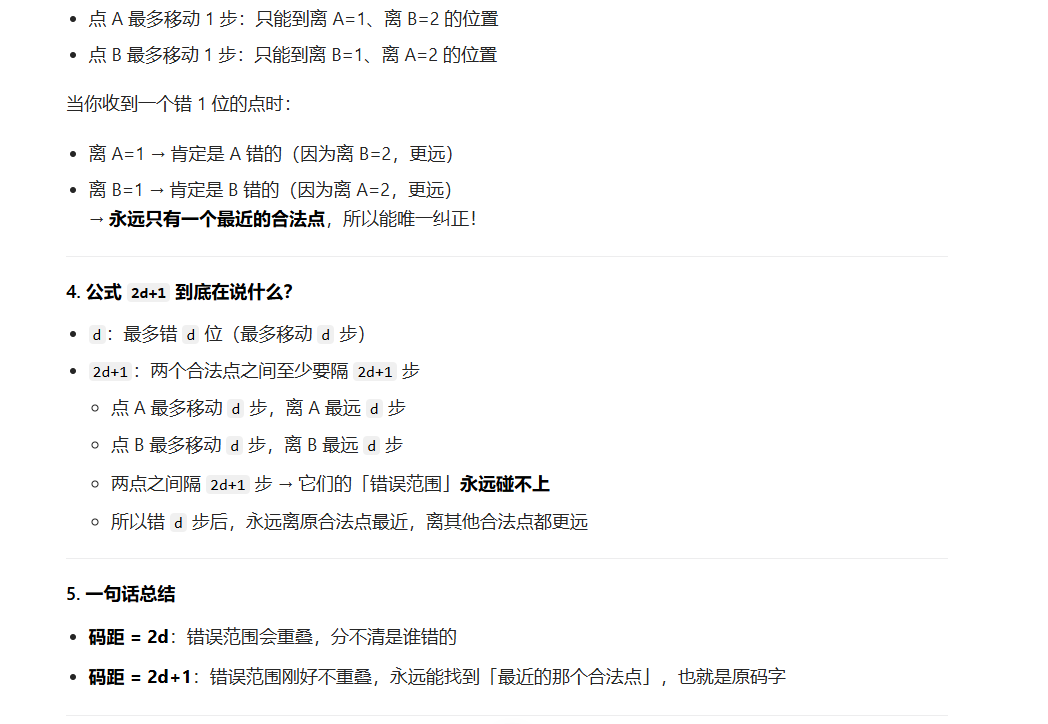
- 检错:只要能认出「这不是正确答案」就行 → 错 d 位也变不成别的答案 → 码距 d+1
- 纠错:要能猜出「它原本是哪个正确答案」 → 错 d 位也离原答案最近 → 码距 2d+1
实际上,汉明码就是一种能够实现单比特错误检测和纠正的编码方案。在汉明码中,通过增加校验位(冗余位)到原始数据中,并精心设计这些校验位的位置和计算方式,使得任意两个合法码字间的最小汉明距离至少为3。这样,即使有一个比特出错,通过计算接收到的码字与所有合法码字之间的汉明距离,可以确定出错的位置并进行纠正,从而保证数据的完整性。
汉明码的设计巧妙地平衡了校验能力和额外开销,是计算机科学和通信领域的一项基础且重要的技术。
汉明使用奇偶校验码进行错误检测。
奇偶校验是一种简单而有效的错误检测方法,尽管它只能检测出数据中有奇数个比特出错的情况,而无法检测偶数个比特错误,也不能确定错误的具体位置。
奇偶校验的工作原理如下:
(1)奇校验: 在数据位之外增加一个校验位,使得整个码字(包括数据位和校验位)中1的个数为奇数。当存储或传输数据时,先计算数据位中1的个数,如果为偶数,则校验位设为1,使总和变为奇数;如果为奇数,则校验位设为0。P=b1^b2^b3...^1,bn代表数据的各个位数,从这个式子中看出,如果数据中有n个1,前面异或出来为1再异或上后面的1算出来为0,即奇数个1校验位为0。反之
(2)偶校验: 与奇校验相反,偶校验确保整个码字中1的个数为偶数。数据位中1的个数如果是奇数,则校验位设为1;如果是偶数,则设为0。P=b1^b2^b3...bn,道理同上。
在读取数据时,再次计算包括校验位在内的码字中1的个数,如果计算结果与预设的奇偶性(奇校验或偶校验)不符,就说明至少有一个比特在存储或传输过程中发生了错误。但是,奇偶校验无法指出是哪一位错了,也无法处理多位同时出错的情况,因此它的错误检测能力有限。比如发送方发1100采用奇校验,则校验位1100 1,如果接收方接收到的是1111 1,按照公式算出来也是1故检验不出来多位的。
故汉明码的基本原理:
- 错误检测与纠正:汉明码的主要目的是检测并纠正数据传输或存储过程中的单一比特错误。
- 校验位:通过在数据位中插入额外的校验位(也称为冗余位或纠错位),汉明码能够检测并纠正错误。
- 汉明距离:汉明码的设计基于汉明距离的概念,即两个等长二进制数之间不同位的数量。在汉明码中,不同有效码字之间的最小汉明距离通常大于1,以确保能够检测和纠正错误。
汉明码的构造
-
分组:数据位和校验位被组织成不同的组,每个组都与一个或多个校验位相关联。即一个校验位对应到几个数据为位。
-
校验位计算:通过异或(XOR)运算计算每个校验位的值,以确保每个数据位都被一个或多个校验位所覆盖。
汉明码的校验与纠错
-
校验:在接收端,通过重新计算校验位的值并与发送的校验位进行比较,可以检测数据中是否存在错误。
-
纠错:如果检测到错误,通过比较不同校验位的状态,可以确定哪个数据位发生了错误,并进行纠正。
实例:
假设我们有4个数据位(D1, D2, D3, D4--0101)和3个校验位(P1, P2, P3)。数据位和校验位按以下方式组织:规定检验位Pi在海明位号为2i-1的位置上,其余各位为信息位: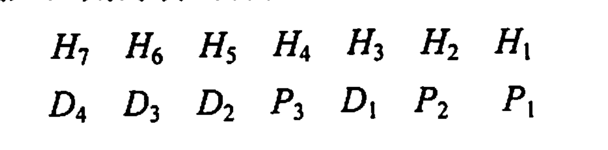
每个数据位用多个检验位进行检验,但要满足条件:被检验数据位的海明位号等于检验该数据位的各检验位海明位号之和。另外,检验位不需要再被检验。检验方式是根据下标的二进制,比如P1的下标是1写出二进制是0001,意味着最后一位是1,那我们就去对照H的下表,H1 H3 H5 H7的下标准换为二进制的最后一位都是1,所以P1就检验对应的数据位:D1,D2,D4。同理大家可以算P2,P3的。
计算校验位: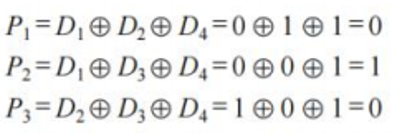
汉明码为:1010010
检验: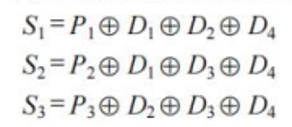
若S3S2S1的值为"000",则说明无错;否则说明出错,且这个数就是错误位的位号,如S3S2S1=001,说明第1位出错,即H1出错,直接将该位取反就达到了纠错的目的。这是根据S2,S3来去推出的S1里的哪里错了,简单的数学推导。
本节博客不是特别重点,但也需了解,本节课大家了解一下奇偶校验码和汉明码,因为408计组的统考大纲删除了这部分内容但是在计算机网络那里还有,大家在这里了解一下,后面再好好体会。大概先写这些吧,今天的博客就先写到这,谢谢您的观看。