引言
在前面的章节中,我们已经揭开了 GPU 大规模并行计算的神秘面纱,并成功编写了基础的 CUDA 程序。利用一维的线程网格(Grid)和线程块(Block),我们学会了如何高效地处理线性的数据数组,例如向量加法。然而,当我们把目光从简单的数组投向广阔的现实世界时,会发现一个不可回避的事实:真实世界的计算问题绝大多数都是多维的。
无论是计算机视觉中由像素矩阵构成的二维高清图像,还是流体力学模拟中复杂的三维空间网格,亦或是深度学习神经网络中庞大的多维张量(Tensor),数据的逻辑结构往往呈现出丰富的空间维度。
如果我们强行用一维的思维去处理这些多维数据,程序员就必须在代码中手动进行繁琐且极耗算力的坐标换算。这不仅会让代码变得晦涩难懂,更容易引入隐蔽的越界错误。更重要的是,它违背了 GPU 编程的核心哲学------让硬件的执行模式尽可能地贴合数据的自然形态。
本章将带领大家实现从"一维线性思维"到"多维空间思维"的跨越。我们将深入探讨物理内存的底层限制,并学习 CUDA 是如何通过优雅的内置变量(如 dim3 结构)原生支持多维线程组织的。
在本章中,你将学习到:
-
内存映射原理: 理解多维逻辑数据是如何被"展平"并存储在一维的物理内存(RAM/VRAM)中的。
-
多维坐标推导: 掌握如何利用
blockIdx和threadIdx等内置变量,计算出线程在全局多维网格中的绝对坐标。 -
图像处理实战: 通过编写经典的"彩色转灰度"核函数,将多维线程直接映射到二维图像的像素点上。
-
边界保护机制: 学习在网格尺寸与数据尺寸不匹配时,如何编写健壮的边界检查代码以防止内存越界。
-
矩阵运算初探: 实现基础的矩阵乘法(Matrix Multiplication),理解多维数据在复杂计算中的内存访问模式,并为后续的性能优化章节埋下伏笔。
掌握多维网格与数据的映射,是编写所有高级 GPU 算法的必经之路。让我们开始这场多维空间的探索之旅吧。
第一章:动机与应用背景
在深入探讨 CUDA 的多维网格和线程块之前,我们必须先理解一个计算机科学中基础但至关重要的矛盾:物理内存的一维性与现实数据的多维性之间的冲突。
1.物理内存的一维本质
计算机的物理内存本质上是线性的,就像一条长长的一维街道。但是,我们在做并行计算时,处理的数据往往是二维的,比如矩阵或图像的像素。
为了把二维的数据存进一维的内存,CUDA(和 C/C++ 一样)采用了行主序 (Row-major order) 的方式。也就是说,系统会先完整地存放第 0 行的所有元素,接着存放第 1 行,依此类推。
你可以看这个 3x3 矩阵的例子:
| 列 0 | 列 1 | 列 2 | |
|---|---|---|---|
| 行 0 | A | B | C |
| 行 1 | D | E | F |
| 行 2 | G | H | I |
在物理内存(一维数组)中,它会被"展平"并按顺序存放为:
[A, B, C, D, E, F, G, H, I]
为了让数以万计的 CUDA 线程准确找到自己负责的数据,我们需要建立二维坐标 到一维数组索引
之间的数学映射。
很自然我们可以得出:
注意: 在编写大规模并行程序时,必须清楚地知道底层数据采用的是哪种主序。如果在一个假设数据是行主序的 CUDA C++ 程序中,错误地按列主序去读取数据,不仅会得到错误的结果,还会引发严重的内存访问性能问题(我们将在此后的"内存合并访问"一章中详细讨论)。
2 多维数据的线性映射 (Row-Major Layout)
那么,如果我们有一张 像素的二维灰度图像,它是如何塞进这一维的内存带子里的呢?
这就需要一种"展平(Flattening)"策略。在 C/C++ 以及 CUDA 中,最标准的做法是行主序(Row-Major Order)。
具体来说,计算机会先将图像的第 行依次存入内存,接着紧挨着存入第
行,然后是第
行......以此类推。
假设图像的宽度为 ,对于图像中任意一个逻辑坐标为
的像素(其中X为列号,
为行号),它在内存中的一维线性索引
的计算公式为:
这个公式是所有多维数据处理的基石。它意味着,为了跨越到下一行( 增加
),我们在物理内存中需要跳过一整行的宽度(
个元素)。

如果我们坚持使用一维的线程结构去处理一张二维的图像,会发生什么?
假设我们有一张宽度为 的二维图像。如果我们启动一个一维的线程块,每个线程有一个唯一的线性索引
。为了让这个线程知道自己应该处理图像中的哪个像素(即行号
和列号
),程序员必须在核函数(Kernel)中手动进行坐标换算:
-
计算行号:
-
计算列号:


这种做法有两个显著的缺点:
-
代码缺乏直观性: 程序员需要不断地在"一维线性空间"和"二维数据空间"之间进行大脑体操,这极易导致索引越界或错位等Bug。
-
性能损耗: 在GPU底层硬件中,整数的除法(
/)和取模(%)运算是非常昂贵的指令,它们消耗的时钟周期远多于加法和乘法。让成千上万个线程在每次访问数据前都执行这些昂贵的指令,是对计算资源的巨大浪费。
3. 破局:多维线程组织
为了解决上述问题,CUDA编程模型优雅地引入了多维网格和线程块的概念。它允许我们直接启动一个二维的线程块去覆盖二维的图像数据。
在多维模型中,线程自身就带有二维坐标属性(例如 threadIdx.x 和 threadIdx.y)。这意味着,线程 可以直接、天然地去处理图像中坐标为
的像素。除法和取模运算被彻底消除了,代码逻辑变得与数据的物理形态完全一致。
在 CUDA 和大多数图形处理场景中,x 通常对应的是列 (Col) 。
我们可以回忆一下数学里的平面直角坐标系:
-
x轴是水平方向的(左右移动),这正好对应矩阵中列 (Col) 的变化。 -
y轴是垂直方向的(上下移动),对应矩阵中行 (Row) 的变化。
所以,习惯上我们会建立这样的映射关系:
-
Col = threadIdx.x -
Row = threadIdx.y
把它们代入我们刚才推导的展平公式,在只有单个二维线程块 (Block) 的情况下,每个线程计算一维内存索引的公式就变成了:
假设矩阵的宽度为 ,对于图像中任意一个逻辑坐标为
的元素(其中
为列号,
为行号),它在内存中的一维线性索引
的计算公式为:
这个公式是所有多维数据处理的基石。它意味着,为了跨越到下一行( 增加
),我们在物理内存中需要跳过一整行的宽度(
个元素)。


第二章:多维线程组织结构
在理解了物理内存布局与多维数据的映射关系后,我们来看看 CUDA 是如何提供原生的多维线程支持的。CUDA 允许程序员以一维、二维或三维的方式来组织网格(Grid)和线程块(Block)。
1.dim3 向量类型
为了定义多维的执行配置,CUDA 提供了一个专门的内置结构体:dim3。它是一个基于无符号整数(unsigned int)的三维向量类型,包含三个成员变量:x、y 和 z。
当你定义一个 dim3 变量时,任何未被显式指定的维度都会被默认初始化为 1。
cpp
// 定义一个 16 x 16 的二维线程块 (z 默认为 1)
dim3 blockDim(16, 16);
// 定义一个包含 4 x 2 个线程块的二维网格 (z 默认为 1)
dim3 gridDim(4, 2);2 CUDA 内置的坐标与维度变量
回顾一下上一章我们讲的:
在 CUDA 编程模型中,执行同一段内核程序(Kernel)的所有线程构成一个网格(Grid) 。由于要处理的数据量通常极其庞大(例如数百万个像素),且硬件资源有限,网格内部被进一步划分为多个大小相同的线程块(Thread Block) 。每个线程块内部又包含多个线程(Thread)。
因此,GPU 的线程模型呈现出经典的两级层次结构:
-
Grid(网格): 由多个 Block 组成。
-
Block(线程块): 由多个 Thread 组成。
当核函数(Kernel)启动后,GPU 硬件会自动为每个线程分配一组内置变量,这些变量就像是线程的"GPS 定位系统",让每个线程都知道自己处于庞大网格中的哪个位置。对于二维组织,我们需要重点关注以下四个内置变量(它们在底层类似于 uint3 类型):
-
gridDim(网格维度): 网格中每个维度上包含的线程块数量 。例如,gridDim.x和gridDim.y。 -
blockDim(线程块维度): 每个线程块中包含的线程数量 。例如,blockDim.x和blockDim.y。 -
blockIdx(线程块索引): 当前线程所在的线程块在网格中的坐标。索引从 0 开始。 -
threadIdx(线程索引): 当前线程在它所属的线程块内部的局部坐标。索引从 0 开始。
为什么不直接用一个巨大的 Block 包含所有线程?这是因为现代 GPU 的硬件架构(流多处理器,SM)对单个 Block 的资源有严格限制。例如,在大多数现代 CUDA 架构中,一个 Block 最多只能包含 1024 个线程。因此,对于规模稍大的多维数据,我们必须将其拆分到多个 Block 中,形成 Grid。
3 核心公式:多维坐标到全局一维索引的映射
这是并行程序设计中最关键的一环。当我们将多维的 Grid 映射到多维的数据(例如一张二维图像)时,我们需要计算出当前线程在整个大网格中的全局唯一坐标,然后再利用 3.1 节学过的内存展平公式,找到其在物理内存中的地址。
接下来,我们需要把视角放大。当处理像 1080p 图片这样包含上百万像素的数据时,一个 Block(硬件限制最多 1024 个线程)是远远不够用的。我们需要用许多个 Block 拼成一个多维网格 (Grid)。
为了在整个网格中准确定位全局的 Col 和 Row,我们需要引入另外两个内置变量:
-
blockDim: 一个 Block 的尺寸(例如blockDim.x代表一个 Block 包含多少列)。 -
blockIdx: 当前 Block 在整个 Grid 中的坐标(从 0 开始)。
我们来算一步:假设我们把图片划分成了多个 大小的 Block(即
blockDim.x = 16)。如果一个线程所在的 Block 的横向索引是 2(即 blockIdx.x = 2),并且该线程在自己 Block 内部的横向索引是 5(即 threadIdx.x = 5)。
你能试着推导出这个线程在整张大图片中真实的全局列号 (Global Col) 吗?
我们可以把处理大图片的整个网格(Grid)想象成一列长长的火车,而线程块(Block)就是火车上的一节节车厢。
我们把刚才的数据套用到这个比喻里:
-
blockDim.x = 16:代表每节车厢里一排有 16 个座位。 -
blockIdx.x = 2:代表你所在的线程位于第 2 节车厢(注意,车厢编号是从 0 开始的,也就是你前面还有第 0 节和第 1 节车厢,共计 2 节完整的车厢)。 -
threadIdx.x = 5:代表你在自己这节(第 2 节)车厢里,坐在第 5 个座位。
要想知道你是整列火车的第几个座位(也就是我们要求的全局列号 Global Col),我们可以分两步来算。
第一步,我们先算出排在你前面的那些完整车厢里,一共有多少个座位。
很显然,2x16 = 32个座位。
这 32 个座位,就代表了在你前面的那些线程块(Block)里一共包含了 32 个线程。在 CUDA 代码里,这个计算过程就是 blockIdx.x * blockDim.x
现在我们进行最后一步:既然你前面的车厢已经占了 32 个座位,而你在当前这节车厢里坐在第 5 个座位(也就是 threadIdx.x = 5)。
把前面的 32 加上你当前的相对位置 5,就是整列火车(整个 Grid)里的全局编号
把我们刚才算的两步合并起来,在 CUDA 程序中计算全局列坐标的标准公式就是:
同理
这样我们就得到了全局的COL和ROW坐标,然后根据之前的公式
现在,我们把这两部分结合起来。把公式里的 替换成我们算出的
,把
替换成
Width 指的是我们要处理的整个二维数据(比如整张图片或整个大矩阵)的总宽度。
换句话说,它代表了实际数据中完整的一行包含多少个元素(也就是总列数)。
请看以下图示,假设我们的网格规模:

对于橙色的块我们可以得到:
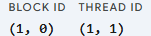
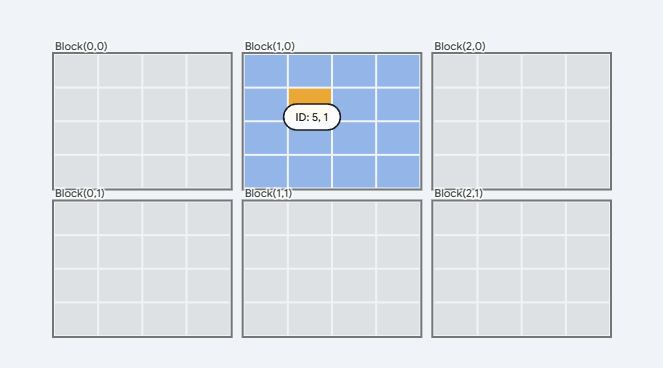
通过公式计算:

可以得出全局ID:

第三章:实践
1.矩阵加法
现在,我们将这些理论结合起来,编写一个真实的 CUDA 内核(Kernel)函数来实现两个二维矩阵的加法运算:。
假设矩阵 A,B 和 C 具有相同的尺寸,宽度为 W(列数),高度为 H(行数),并且在内存中均以行主序存储
在编写代码之前,我们需要先在脑海中建立一幅清晰的映射图: 想象矩阵 是一个由
个方格组成的巨大棋盘。我们将配置一个二维的线程网格(Grid)像一张大网一样覆盖在这个棋盘上。网格中的每一个交叉点(线程),就专门负责计算棋盘上的一个特定方格(即
)。
下面是执行矩阵加法的 CUDA C++ 内核代码。请注意观察我们在 上节推导的坐标公式是如何在代码中应用的。
cpp
// CUDA 内核函数:执行二维矩阵加法
__global__ void matrixAddKernel(float *A, float *B, float *C, int width, int height) {
// 步骤 1:利用内置变量,计算当前线程负责的全局二维坐标 (Col, Row)
int Col = blockIdx.x * blockDim.x + threadIdx.x;
int Row = blockIdx.y * blockDim.y + threadIdx.y;
// 步骤 2:边界检查(防止内存越界访问)
if (Col < width && Row < height) {
// 步骤 3:利用映射公式,将二维坐标展平为一维物理内存索引
int linearIndex = Row * width + Col;
// 步骤 4:在一维内存地址上执行加法操作
C[linearIndex] = A[linearIndex] + B[linearIndex];
}
}-
__global__修饰符: 这告诉编译器,该函数是在设备端(GPU)上执行的,并且可以从主机端(CPU)被调用。 -
坐标计算:
Col和Row的计算完全依赖于硬件提供的寄存器变量,执行速度极快。 -
边界检查
if (Col < width && Row < height): 这是多维并行编程中极其关键的一步。由于线程块的大小(blockDim)通常是固定的(例如),而实际矩阵的宽度和高度往往不能被 16 完美整除。这会导致网格的边缘超出了矩阵的实际边界。如果不加这个
if判断,边缘的线程就会尝试访问非法的内存地址,导致程序崩溃(Segmentation Fault)。 -
一维索引
linearIndex: 完美印证了我们推导的行主序展平公式。
写好了在 GPU 上运行的内核,我们还需要在 CPU 端(Host)正确地配置 dim3 结构并启动它。这是很多初学者容易卡壳的地方。
cpp
// 假设 width 和 height 是矩阵的实际尺寸
int width = 1000;
int height = 800;
// 1. 定义线程块 (Block) 的维度
// 通常选择 16x16 或 32x32,这里一个 Block 包含 256 个线程
dim3 threadsPerBlock(16, 16);
// 2. 定义网格 (Grid) 的维度
// 核心技巧:使用向上取整除法,确保生成的线程总数足以覆盖整个矩阵
dim3 numBlocks(
(width + threadsPerBlock.x - 1) / threadsPerBlock.x,
(height + threadsPerBlock.y - 1) / threadsPerBlock.y
);
// 3. 启动内核
matrixAddKernel<<<numBlocks, threadsPerBlock>>>(d_A, d_B, d_C, width, height);配置技巧:向上取整(Ceiling Division) 在计算 numBlocks 时,我们使用了 (N + M - 1) / M 这种 C++ 中经典的向上取整写法。 如果矩阵宽度 width = 1000,而 threadsPerBlock.x = 16,那么单纯的整数除法 。62 个 Block 只能覆盖
列,最后 8 列将无法被计算。 使用
(1000 + 16 - 1) / 16 = 63,我们将启动 63 个 Block,覆盖 列。多出来的 8 个线程会因为内核函数中的
if (Col < width) 边界检查而直接闲置,从而保证了计算的正确性。
2.RGB转灰度
为了将理论应用于实践,我们来编写一个 CUDA 核函数,将一张 RGB 彩色图像转换为灰度图像。
在代码中,每个线程都会先计算出自己的 、
和
,然后去读取相应的像素。
但在真正读取数据之前,实际的工程代码中通常都必须加一个非常关键的 if 判断来进行边界检查 (Boundary Check)
在计算机视觉中,图像通常被存储为一维数组。
-
输入数据 (RGB): 每一个像素包含红 (R)、绿 (G)、蓝 (B) 三个通道的值(通常为 0~255 的
unsigned char)。在内存中,它们以 R, G, B, R, G, B... 的顺序交错排列。因此,一张宽为 -
输出数据 (灰度): 灰度图像每个像素只有一个亮度值。因此,输出数组的总大小仅为
| 逻辑像素编号 (Index) | 0 | 1 | 2 | ... |
|---|---|---|---|---|
| 物理内存数组存放 | [R, G, B] |
[R, G, B] |
[R, G, B] |
... |
| 真实数组下标 | 0, 1, 2 | 3, 4, 5 | 6, 7, 8 | ... |
我们来找找规律:
-
第 0 个像素的 R 在下标
0 * 3 = 0 -
第 1 个像素的 R 在下标
1 * 3 = 3 -
第 2 个像素的 R 在下标
2 * 3 = 6
所以,对于我们算出来的任意一个逻辑像素 Index,它的 R 通道 在输入数组里的真实下标就是 Index * 3。
对于图像中任意一个坐标为 的像素:
-
灰度图偏移量 (一维索引): 利用我们学到的展平公式:
-
RGB图偏移量: 因为每个彩色像素占用 3 个字节,所以在彩色数组中的起始位置为:
有了这两个偏移量,我们就可以读取 R、G、B 的值,并应用经典的心理学灰度公式进行转换:
下面是该转换过程的 CUDA C++ 核函数代码。请注意观察每个线程是如何通过自己的独立坐标来"认领"属于自己的那个像素的。
cpp
// CUDA 核函数:彩色图像转灰度
__global__
void colorToGreyscaleConversion(unsigned char *Pout, unsigned char *Pin, int width, int height) {
// 1. 计算当前线程的全局二维坐标
int Col = blockIdx.x * blockDim.x + threadIdx.x;
int Row = blockIdx.y * blockDim.y + threadIdx.y;
// 2. 边界检查:确保线程坐标没有超出图像的实际物理尺寸
if (Col < width && Row < height) {
// 3. 计算一维线性内存的读写偏移量
int greyOffset = Row * width + Col;
int rgbOffset = greyOffset * 3;
// 4. 从全局内存中读取 R, G, B 三个通道的值
unsigned char r = Pin[rgbOffset];
unsigned char g = Pin[rgbOffset + 1];
unsigned char b = Pin[rgbOffset + 2];
// 5. 计算灰度值并写入输出数组 (使用浮点数乘法以保证精度)
Pout[greyOffset] = 0.21f * r + 0.71f * g + 0.07f * b;
}
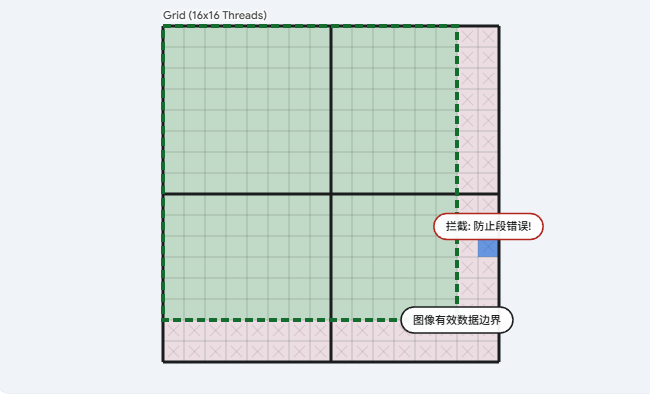
}在上面的核函数中,你可能注意到了一个非常关键的 if (Col < width && Row < height) 语句。为什么我们需要这个边界检查?
GPU 的线程块(Block)在各个维度的尺寸通常被配置为 16 或 32 的倍数(例如 ),这是为了迎合底层硬件架构的执行效率。然而,现实中的图像尺寸是任意的(例如
像素)。
如果我们启动尺寸为 的线程块去处理
的图像,我们在宽度上需要启动
个块,高度上需要
个块。
这意味着 GPU 实际上启动了一个 的线程网格。那些落在
或
区域的线程虽然被硬件激活了,但它们并没有对应的图像像素需要处理 。如果让这些"多余"的线程去执行内存读写,就会导致严重的内存越界错误。因此,
if 语句是保护内存安全的最后一道防线。
为了确保网格能够完全覆盖整个图像,我们在 CPU 端(Host)需要使用向上取整的数学技巧来计算 gridDim。在 C/C++ 中,我们通常使用一种高效的整数算术技巧 (N + M - 1) / M 来替代浮点数的 ceil() 函数。
在 CUDA 编程里,Host 函数(运行在 CPU 上)就像一个物流调度中心。它有一个非常经典的"五步走"标准工作流:
-
分配显存 (Allocate):在 GPU 上为输入的彩色图和输出的灰度图腾出合适的空间。
-
拷贝数据 (Host to Device):把图片数据从 CPU 内存转移到 GPU 显存里。
-
启动核函数 (Launch Kernel) :呼叫我们刚才写的
colorToGrayscaleConversion,设置好 Grid 和 Block 的维度,让成千上万个线程开始并发计算。 -
拷回结果 (Device to Host):计算完成后,把 GPU 里生成好的灰度图数据搬回 CPU 内存,以便后续保存或显示。
-
释放显存 (Free):打扫战场,释放占用的 GPU 空间。
cpp
void convertImage(unsigned char* h_rgb, unsigned char* h_gray, int width, int height) {
// 1. 分配显存 (Allocate)
unsigned char *d_rgb, *d_gray;
cudaMalloc(&d_rgb, width * height * 3);
cudaMalloc(&d_gray, width * height);
// 2. 拷贝数据 (Host to Device)
cudaMemcpy(d_rgb, h_rgb, width * height * 3, cudaMemcpyHostToDevice);
// 3. 设定维度并启动核函数 (Launch Kernel)
dim3 blockSize(16, 16);
dim3 gridSize((width + blockSize.x - 1) / blockSize.x,
(height + blockSize.y - 1) / blockSize.y);
colorToGrayscaleConversion<<<gridSize, blockSize>>>(d_rgb, d_gray, width, height);
// 4. 拷回结果 (Device to Host)
cudaMemcpy(h_gray, d_gray, width * height, cudaMemcpyDeviceToHost);
// 5. 释放显存 (Free)
cudaFree(d_rgb);
cudaFree(d_gray);
}对于初学者来说,"多余的线程"是一个很难通过文字想象的概念。
-
假设我们要处理一张
-
我们配置了
3.最终进阶:矩阵乘法
如果说"彩色转灰度"演示了点对点 (一个像素对应一个计算)的映射,那么"矩阵乘法"则完美展示了多对一 (一行和一列的数据对应一个输出)的内存访问模式。更重要的是,在第三章讲透基础版(Naive)矩阵乘法,是为后续章节引入"共享内存(Shared Memory)和分块(Tiling)优化"做必须的铺垫。
我们来挑战并行计算领域的经典"Hello World"------矩阵乘法 (Matrix Multiplication)!
在深度学习和科学计算中,矩阵乘法是最核心的计算负荷。假设我们需要计算两个方阵的乘积:。其中
、
和
的尺寸均为
。
根据矩阵乘法的数学定义,输出矩阵 中的每一个元素
,都等于矩阵
的第
行与矩阵
的第
列的点积(Dot Product)。
在 CUDA 的多维编程模型中,最自然的做法是:
-
启动一个二维的线程网格,使其维度完全覆盖输出矩阵
-
让网格中的每一个线程
因为矩阵在物理内存中依然是行主序(Row-Major)存储的一维数组,当线程 执行点积运算时,它需要遍历
的一行和
的一列。我们需要一个循环变量
(从
到
)来步进读取数据:
-
读取矩阵
Row * Width + k。 -
读取矩阵
k * Width + Col。 -
写入矩阵
Row * Width + Col。
下面是基础矩阵乘法的核函数代码。请注意观察每个线程是如何通过内部的 for 循环来完成点积运算的:
cpp
// CUDA 核函数:基础矩阵乘法 (方阵 P = M * N)
__global__
void MatrixMulKernel(float* M, float* N, float* P, int Width) {
// 1. 计算当前线程负责的输出元素 P 的全局坐标
int Col = blockIdx.x * blockDim.x + threadIdx.x;
int Row = blockIdx.y * blockDim.y + threadIdx.y;
// 2. 边界检查:确保线程坐标在矩阵尺寸范围内
if (Col < Width && Row < Width) {
float pValue = 0.0f; // 使用局部寄存器累加结果,速度极快
// 3. 执行点积运算:遍历 M 的第 Row 行和 N 的第 Col 列
for (int k = 0; k < Width; ++k) {
// 从全局内存读取 M 和 N 的元素
float mElement = M[Row * Width + k];
float nElement = N[k * Width + Col];
// 累加乘积
pValue += mElement * nElement;
}
// 4. 将最终结果写入全局内存 P 中
P[Row * Width + Col] = pValue;
}
}虽然上述代码逻辑清晰,且完美利用了二维线程模型,但它在实际执行时会面临严重的内存带宽瓶颈 。对于尺寸为 的矩阵,计算每个
的元素需要进行
次全局内存读取。当成千上万个线程同时请求访问全局内存时,GPU 的内存带宽会瞬间被耗尽。如何解决这个问题,将是我们下一章(内存架构与性能优化)的重点。