****论文题目:****A TIME SERIES IS WORTH 64 WORDS: LONG-TERM FORECASTING WITH TRANSFORMERS(一个时间序列相当于64个字:用变压器进行长期预测)
会议:ICLR2023
****摘要:****我们提出了一种有效的基于变压器的多元时间序列预测和自监督表示学习模型设计。它基于两个关键组件:(i)将时间序列分割成子序列级补丁,作为Transformer的输入令牌;(ii)通道独立,其中每个通道包含单个单变量时间序列,该序列在所有序列中共享相同的嵌入和Transformer权重。补丁设计自然有三方面的好处:在嵌入中保留了局部语义信息;在相同的回望窗口下,注意图的计算量和内存使用量呈二次减少;而且该模型可以关注更长的历史。与基于SOTA变压器的模型相比,我们的通道无关补丁时间序列变压器(PatchTST)可以显著提高长期预测精度。我们还将我们的模型应用于自监督预训练任务,并获得了出色的微调性能,优于大型数据集上的监督训练。将一个数据集上的屏蔽预训练表示转移到其他数据集上也可以产生SOTA预测精度。
时间序列值64个词:用Transformer做长期预测的正确姿势------PatchTST详解
一、背景:Transformer做时间序列预测,真的有效吗?
近年来,Transformer模型在NLP、CV、语音等领域取得了举世瞩目的成功,研究者们也将其引入了时间序列预测领域,涌现出Informer、Autoformer、FEDformer、Pyraformer等一批改进模型。然而,2022年Zeng et al. 的一篇论文(DLinear)给整个方向泼了一盆冷水:一个极其简单的单层线性模型,在多个常用基准上竟然能全面超越所有上述复杂的Transformer变体,令人不得不质疑Transformer在时序预测领域存在的意义。
PatchTST的出发点正是正面回应这一挑战:Transformer在时间序列领域的失效,真的是Transformer本身的问题,还是设计方式的问题?
二、问题诊断:以往方法的三大核心缺陷
缺陷1:单点级别输入缺乏语义
以往的Transformer模型几乎无一例外地采用逐点(point-wise) 的输入方式,即把每一个单独的时间步作为一个token喂入Transformer。然而,单个时间步本身并不像NLP中的"词"那样携带完整的语义信息------它只是一个孤立的数值,缺乏上下文。这导致模型难以从局部区域捕获有意义的模式。
缺陷2:计算复杂度高,长历史难以建模
Transformer对序列长度N有O(N²)的时间和空间复杂度。当look-back window(回溯窗口)较长时,计算成本急剧爆炸。实验证明,更长的回溯窗口对预测有益------例如在Traffic数据集上,将L从96扩大到336,MSE从0.518下降到0.397------但高昂的计算代价使得这在实践中难以实现。为此,部分工作不得不采用降采样等方式丢弃数据。
缺陷3:Channel-Mixing方式容易过拟合
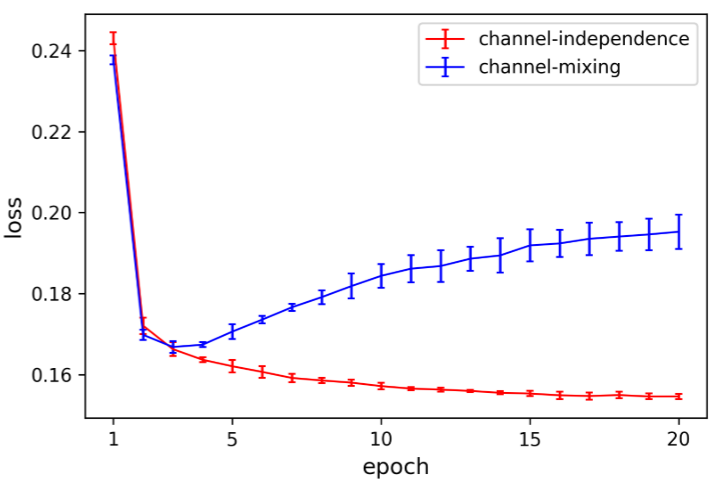
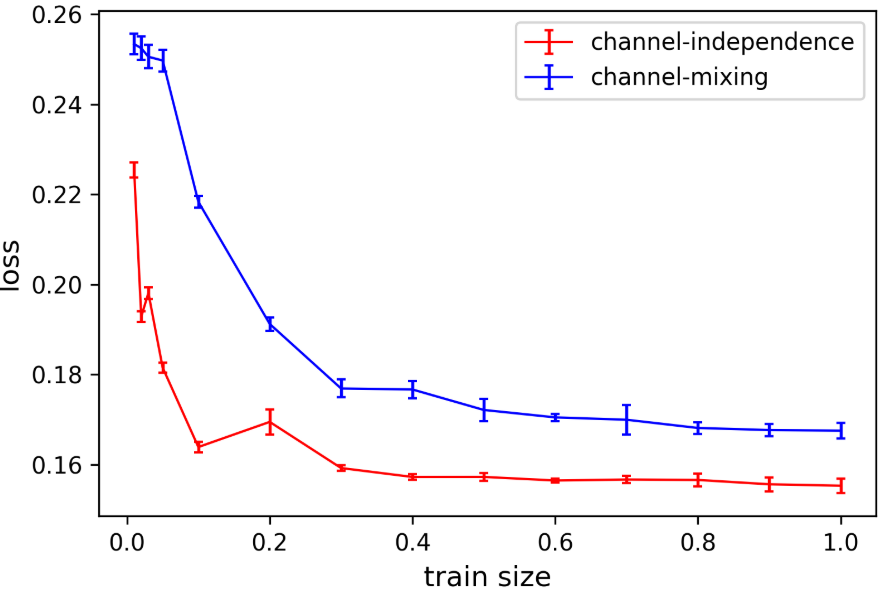
大多数Transformer时序模型采用channel-mixing 方式,将所有通道(变量)的特征拼接成一个token,在一次前向传播中混合所有通道信息。这种方式虽然理论上更灵活,但实践中的问题是:需要大量训练数据才能有效学习跨通道关联,而现有时序数据集普遍规模有限,导致模型容易过拟合(如Figure 7右图所示,channel-mixing模型在训练几轮后测试损失便开始反弹上升)。
三、核心创新:两个简洁而强大的设计
PatchTST的创新可以用一句话概括:借鉴ViT对图像的处理思路,将时间序列切成patch;同时让每个通道独立通过Transformer。具体来说,模型包含两个关键组件:
创新1:Patching(补丁化)
灵感来源:NLP中BERT用subword而非单字符,CV中ViT将图像分成16×16的patch------patch级别的处理已经在多个领域证明了其捕获局部语义的优越性。
PatchTST将每条输入的单变量时间序列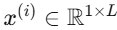 切分成若干patch,patch长度为P,步幅(stride)为S(允许重叠),从而生成
切分成若干patch,patch长度为P,步幅(stride)为S(允许重叠),从而生成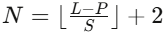 ,每个patch作为一个token送入Transformer。
,每个patch作为一个token送入Transformer。
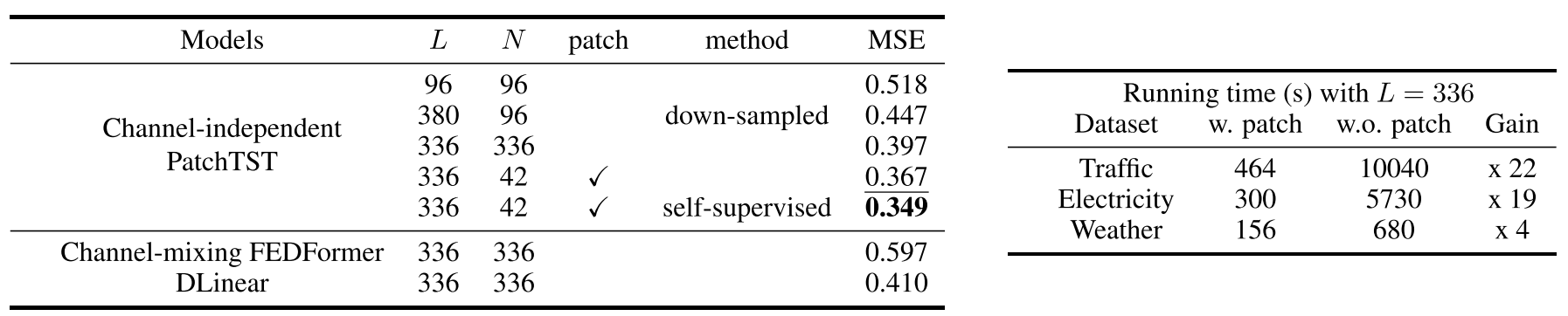
Table 1:Traffic数据集上的案例研究,展示不同L和N下的MSE,以及各数据集patching前后的训练时间对比
这个设计带来了三重收益:
- 语义信息更丰富:每个patch聚合了局部的多个时间步,具备更完整的局部语义,类比于词语比字母更有意义。
- 计算复杂度大幅降低 :token数量从L减少到约L/S,注意力矩阵的计算量降低了S²倍。如表所示,在Traffic数据集上,patch设计(P=16,S=8,L=336)使训练时间缩短了22倍 ;在Electricity上缩短了19倍。
- 能够建模更长历史:在相同计算预算下,patching允许模型接收更长的历史序列。从L=96到L=336,MSE从0.518进一步降到0.367(监督训练)甚至0.349(自监督预训练),说明更长的回溯窗口确实能持续提升性能。
创新2:Channel-Independence(通道独立)
在多变量时间序列中,PatchTST对每个通道单独处理:将M维的多变量输入拆分成M条独立的单变量序列,每条序列独自通过共享权重的Transformer backbone,最后各自输出预测结果再拼接。
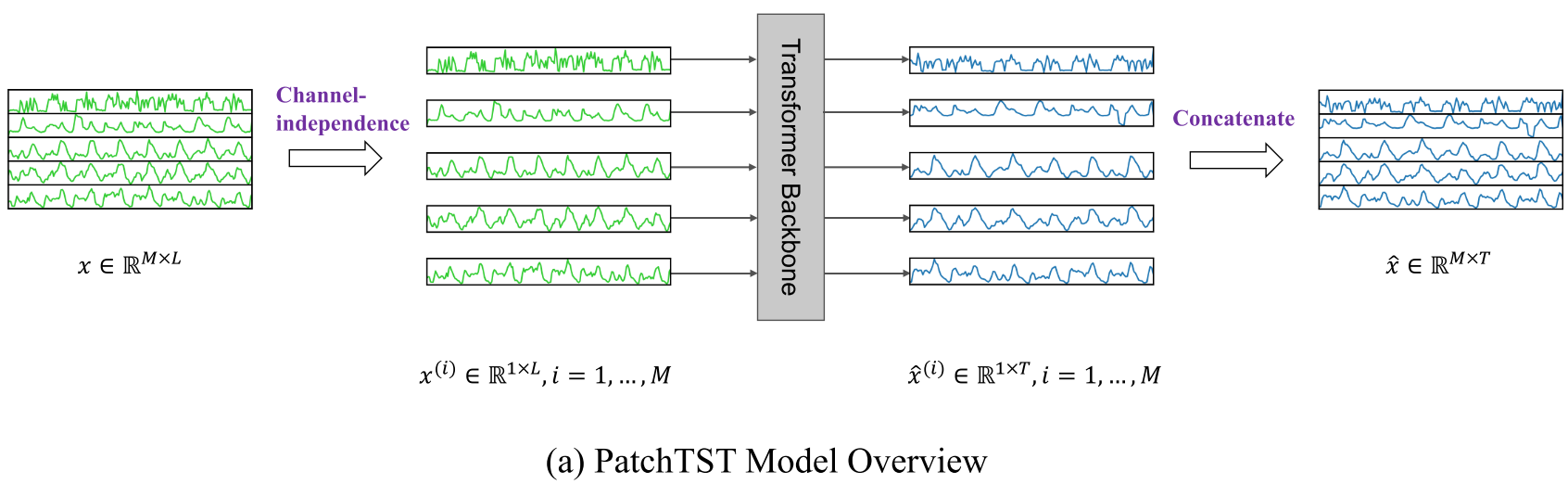
Figure 1(a):PatchTST整体架构图,展示channel-independence的多通道并行处理方式
这一设计的核心优势有三点:
-
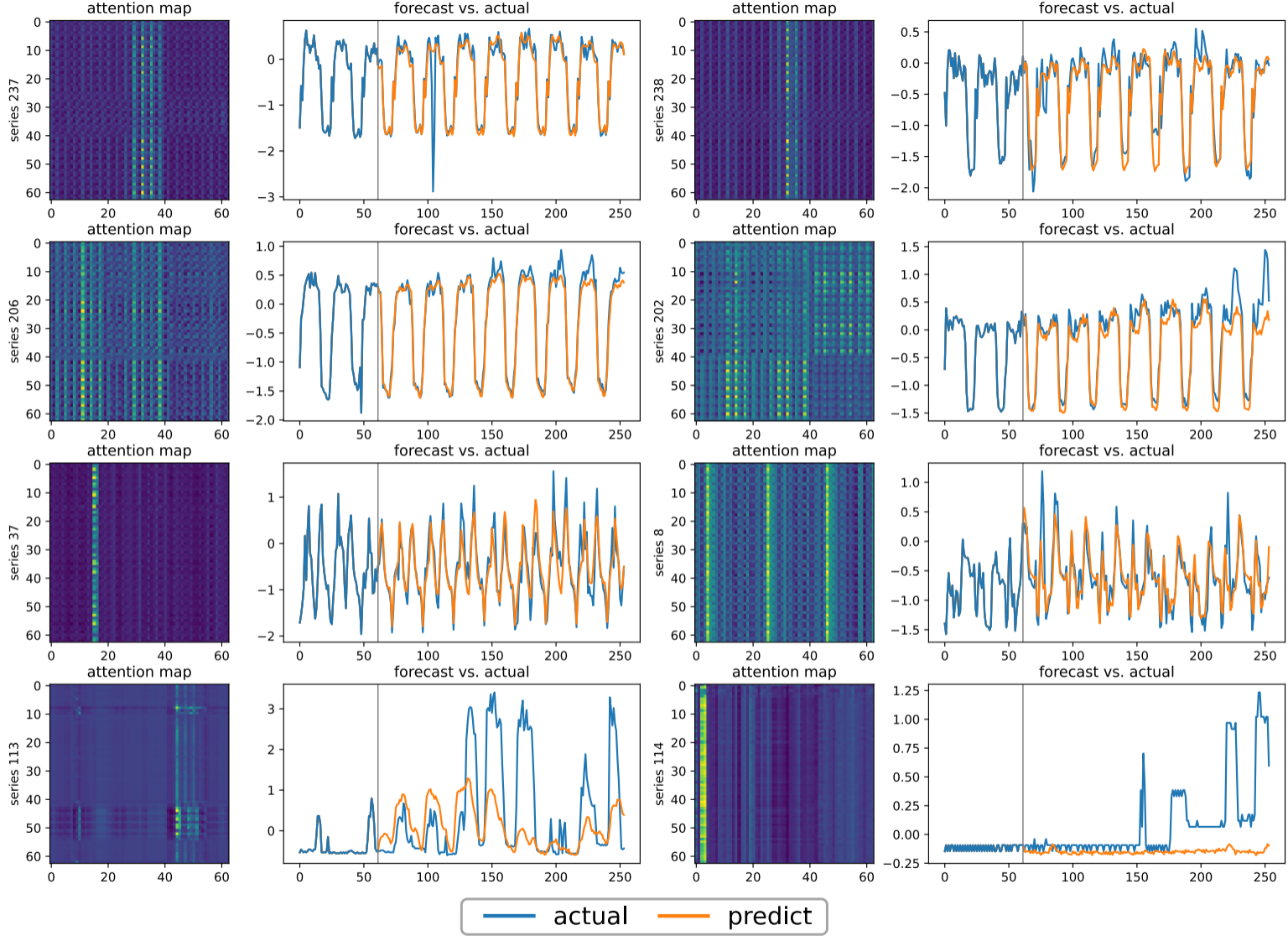
适应性(Adaptability) :每条时间序列可以学习专属于自己的注意力模式。如Figure 6所示,行为相似的序列(如Electricity数据集中的series 11、25、81)会产生相似的注意力图,而不同行为的序列则学到不同的模式------这是channel-mixing方式无法做到的。
-
数据效率更高 :Channel-independent模型只需沿时间轴学习信息,而无需同时学习跨通道和跨时间步的联合关联,因此在数据有限的场景下收敛更快(如Figure 7左图)。
-
不易过拟合:如Figure 7右图所示,channel-mixing模型在训练初期测试损失就开始上升,而channel-independent模型则持续优化、更加稳健。
四、完整模型架构
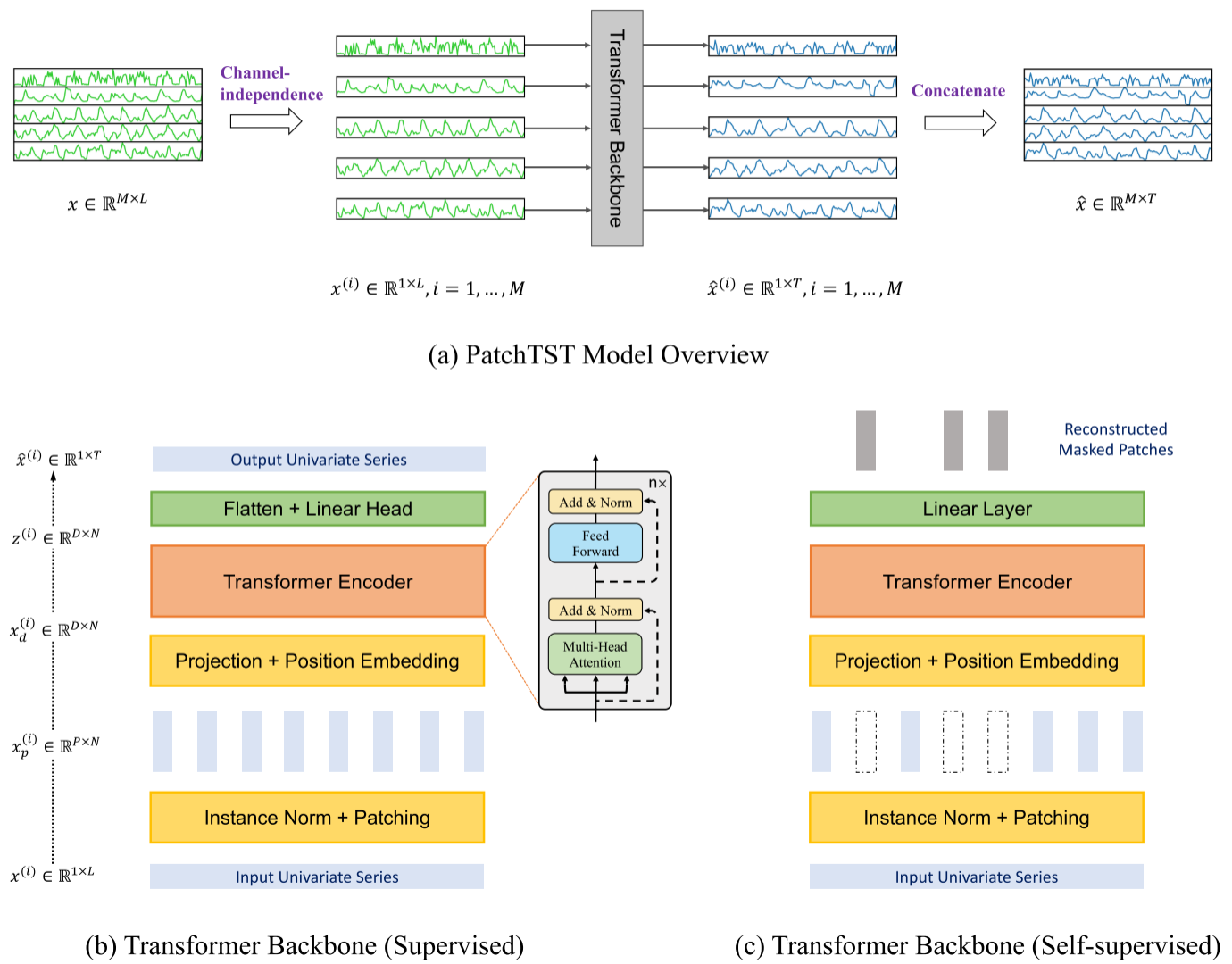
Figure 1(b)(c):监督训练和自监督训练下Transformer backbone的详细结构图
完整的PatchTST流程如下:
- Instance Normalization:对每条输入时间序列做零均值、单位标准差的实例归一化,缓解训练集和测试集之间的分布偏移问题,预测后将均值和标准差还原。
- Patching:将归一化后的序列切成patch(在序列末尾padding最后一个值以凑满patch)。
- 线性投影 + 位置编码 :通过可训练的线性层
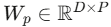 将每个patch映射到D维隐空间,再加上可学习的位置编码
将每个patch映射到D维隐空间,再加上可学习的位置编码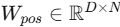 。
。 - Transformer Encoder:使用标准的多头自注意力 + BatchNorm + 前馈网络,堆叠多层(默认3层,隐藏维度D=128,头数H=16)。
- Flatten + Linear Head (监督)或 Linear Layer(自监督重建):展平后通过线性层得到预测序列。
模型有两个版本:
- PatchTST/42:look-back window L=336,patch数N=42,用于与DLinear和其他Transformer的公平对比。
- PatchTST/64:look-back window L=512,patch数N=64,探索更大数据集上的极致性能。
两者均使用 P=16,S=8。
五、自监督表示学习
除了监督训练,PatchTST还支持masked自监督预训练(类比BERT的MLM和MAE的Masked Autoencoder)。
做法简单清晰:
- 将输入序列划分为非重叠的patch
- 随机选取40%的patch,将其值置为0(masking)
- 用与监督模型相同的Transformer Encoder处理,接一个D×P的线性层
- 以MSE损失训练模型重建被遮蔽的patch
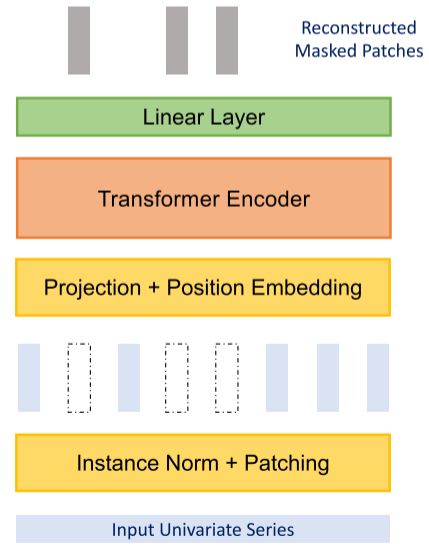
Figure 1(c):自监督backbone结构图,展示被遮蔽patch的重建过程
相比旧方法(TST在单时间步级别masking),PatchTST的patch级别masking更难被简单插值"欺骗",迫使模型学习更高层次的抽象表示。
预训练完成后,有两种微调策略:
- Linear Probing:冻结Encoder,只训练预测头(20 epochs)
- End-to-End Fine-tuning:先做Linear Probing(10 epochs),再微调整个网络(20 epochs)
六、实验结果
6.1 监督长期预测
实验在8个常用数据集上进行:Weather(21个特征)、Traffic(862个特征)、Electricity(321个特征)、ILI(7个特征)以及四个ETT数据集(ETTh1、ETTh2、ETTm1、ETTm2)。预测长度T ∈ {96, 192, 336, 720}(ILI为{24, 36, 48, 60})。
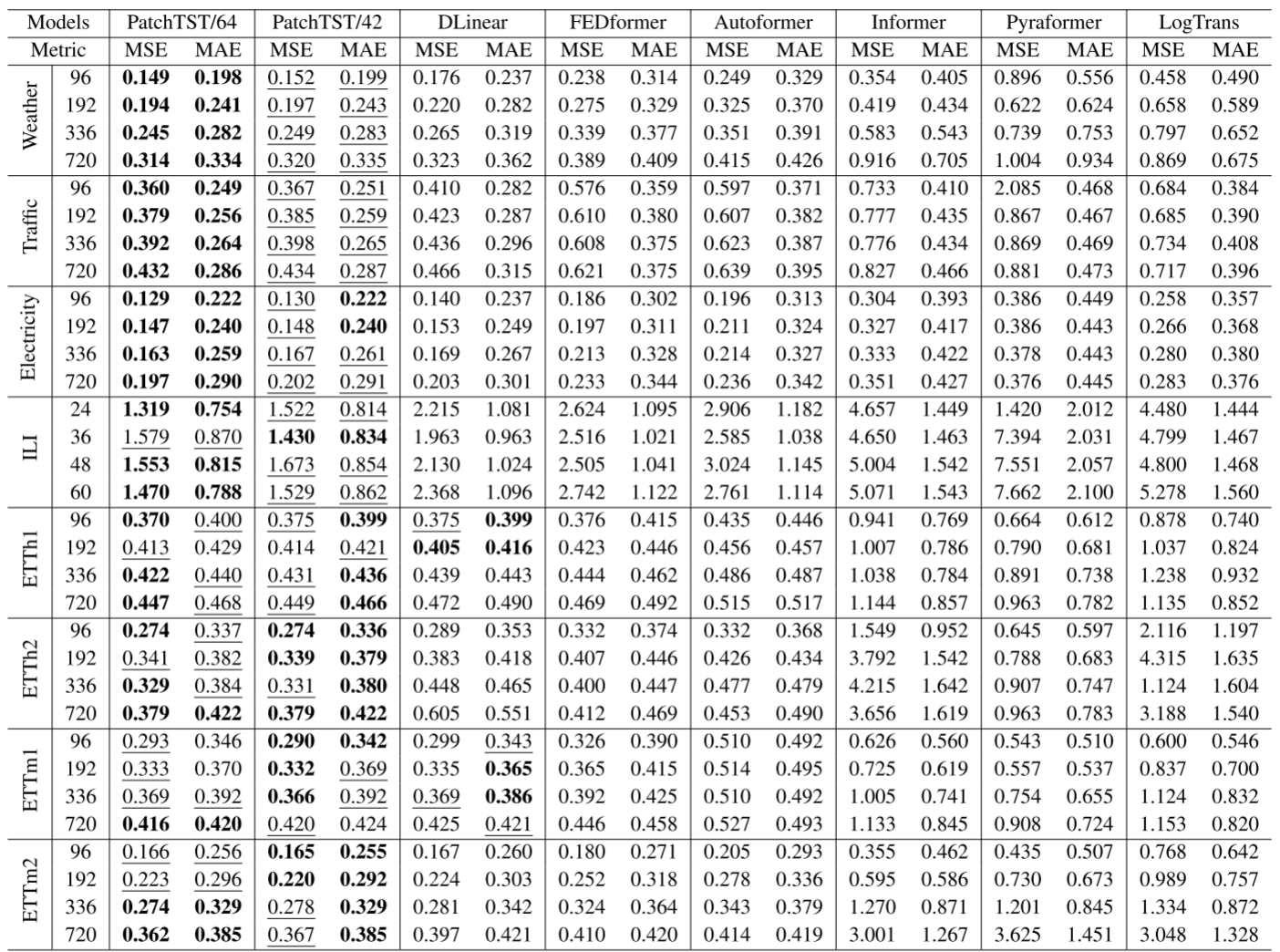
核心结论:
- PatchTST/64 相比最佳Transformer基线,MSE整体降低21.0%,MAE降低16.7%
- PatchTST/42 相比最佳Transformer基线,MSE整体降低20.2%,MAE降低16.4%
- 在大型数据集(Weather、Traffic、Electricity)和ILI上,PatchTST也优于DLinear
- ETT等小数据集上,PatchTST与DLinear差距较小,这与小数据集更易过拟合的特性一致
6.2 自监督预训练与迁移学习
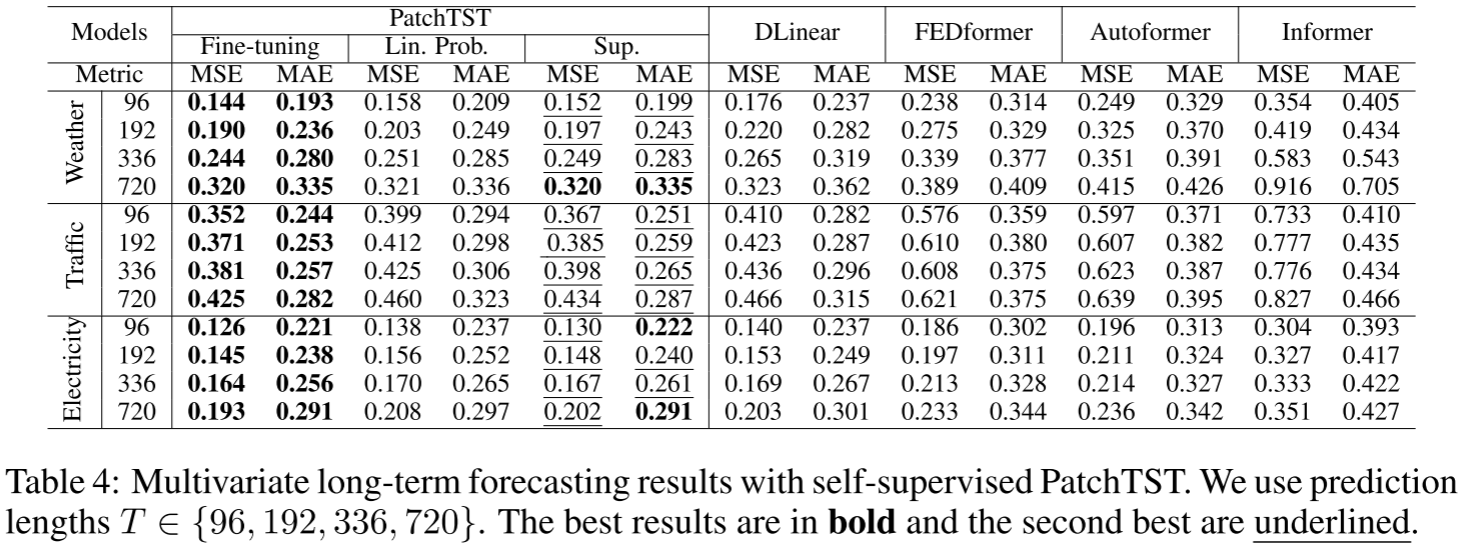
Table 4:自监督PatchTST(含fine-tuning、linear probing、supervised from scratch)与其他模型在Weather、Traffic、Electricity上的对比
自监督 vs 监督训练:在大型数据集上,自监督预训练后端到端微调的PatchTST超越了从头监督训练的版本。仅做线性探测(只训练预测头)的性能就已经能与从头监督训练整个网络相当,且优于DLinear。
迁移学习:
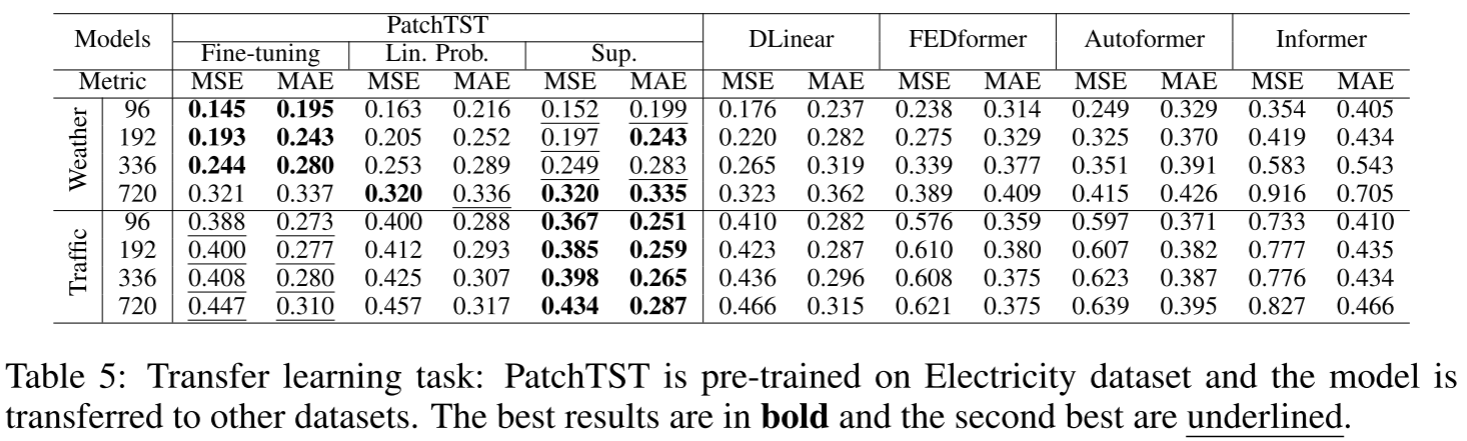
Table 5:在Electricity预训练后迁移到Weather、Traffic的结果
在Electricity上预训练,直接迁移到Weather、Traffic等数据集进行微调,性能仍然优于FEDformer、Autoformer、Informer等监督方法,展示了良好的迁移能力。
与其他自监督方法对比:
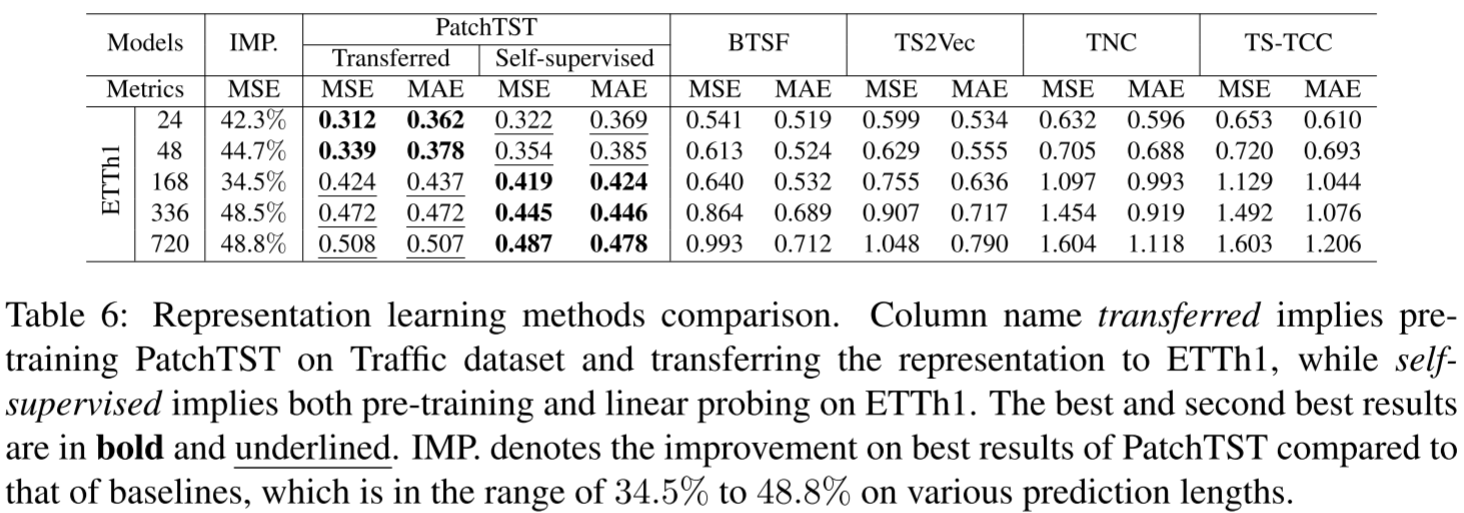
Table 6:在ETTh1上与BTSF、TS2Vec、TNC、TS-TCC的比较,包括transferred和self-supervised两种设置
在ETTh1数据集上与BTSF、TS2Vec、TNC、TS-TCC进行比较,无论是在ETTh1上自监督预训练(self-supervised列),还是在Traffic上预训练后迁移(transferred列),PatchTST均大幅领先,各预测长度上的改进幅度在4.5%到48.8%之间。
6.3 消融实验
Patching与Channel-Independence的贡献
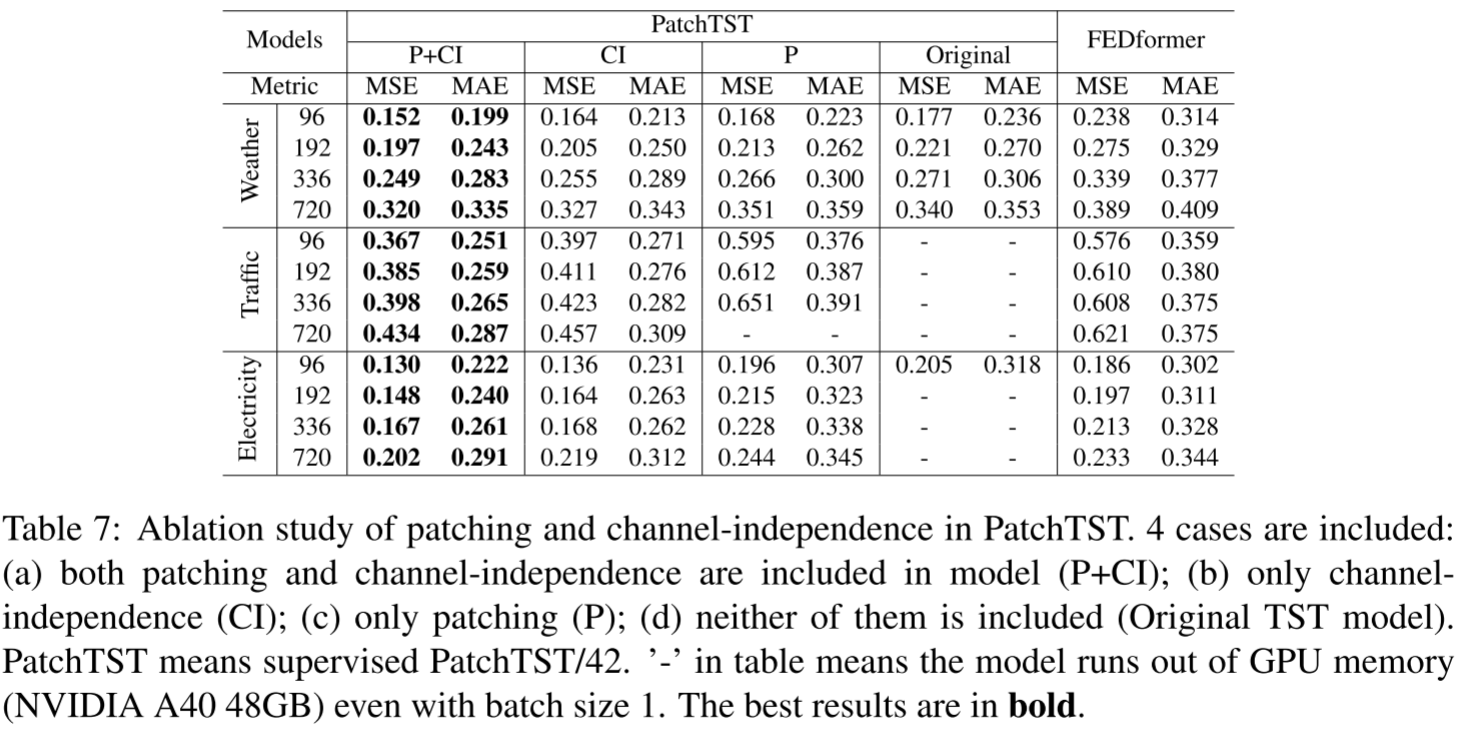
Table 7:消融实验,对比P+CI、仅CI、仅P、原始TST四种配置
在Weather、Traffic、Electricity上,Patching(P)和Channel-Independence(CI)对性能均有独立且显著的贡献。二者结合(P+CI)效果最佳。值得注意的是,仅P的配置(channel-mixing + patching)在Traffic和Electricity的某些设置下直接OOM(显存溢出),体现了channel-independence在大规模多变量场景下的计算优势。
Look-back Window的影响
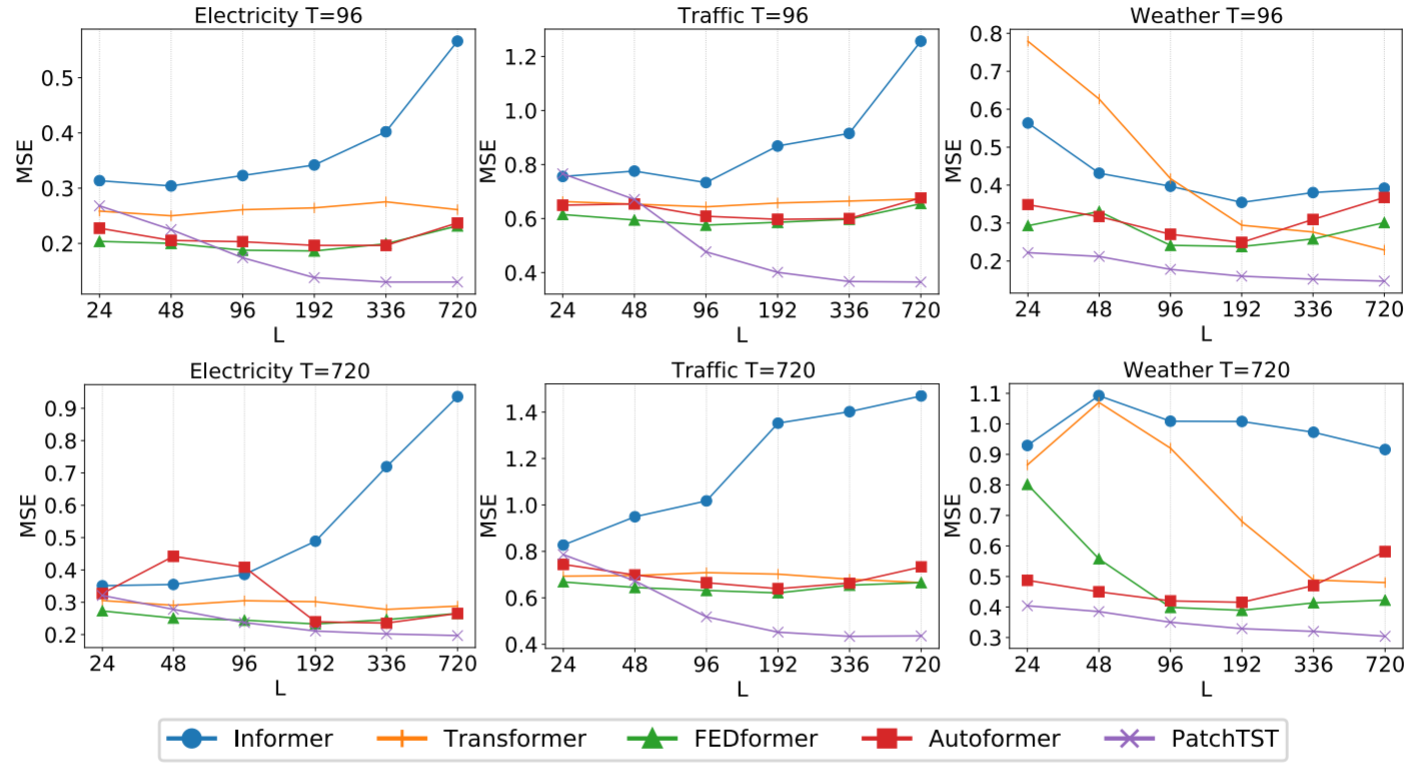
Figure 2:PatchTST vs Informer/Transformer/FEDformer/Autoformer在不同look-back window(24~720)下的MSE,三个大数据集,两个预测长度
这是一个非常直观的对比实验。如图所示:
- 其他Transformer基线几乎不能从更长的回溯窗口中受益,MSE随L增大波动甚至上升
- PatchTST几乎在所有数据集和预测长度上,MSE都随着L的增大而单调下降,充分证明了patching设计让模型真正能够"用上"更长的历史信息
七、深入分析:为什么Channel-Independence更好?
这是本文一个颇具洞见的分析部分。直觉上,channel-mixing模型拥有更多自由度,应该更强------但实验结果恰恰相反,原因有三:
-
适应性更强:Channel-independent模型中,每条时间序列有自己独立的注意力图。Figure 6展示了Electricity数据集中不同序列的注意力模式差异显著,而相关度高的序列(如series 11、25、81)的注意力图确实更相似。Channel-mixing迫使所有序列共享同一套注意力模式,当不同序列行为差异较大时会相互干扰。
-
数据效率更高:Figure 7左图显示,Channel-independent模型随训练数据量增加收敛更快。在数据集规模有限(如Table 2所示,大多数数据集时间步在2万以内)的情况下,这一优势尤为关键。
-
更不容易过拟合:Figure 7右图显示,Channel-mixing模型在仅仅数个epoch后就开始在测试集上过拟合,而Channel-independent模型的测试损失持续下降,表现更稳健。
此外,作者还验证了Channel-Independence不是PatchTST专属的技巧------将其应用于Informer、Autoformer、FEDformer后(记为Informer-CI等),这些模型的性能也得到了普遍提升(Table 15),尽管它们仍不及PatchTST。
八、模型鲁棒性验证
随机种子鲁棒性:在5个不同随机种子(2019-2023)下训练,MSE和MAE的标准差极小(Table 14),大型数据集上尤为稳定。
模型参数鲁棒性:尝试了Transformer层数L ∈ {3, 4, 5}与模型维度D ∈ {128, 256}的6种组合(Figure 5),除ILI这一极小数据集外,其余数据集上的MSE变化幅度均在可接受范围内。
Patch长度鲁棒性:
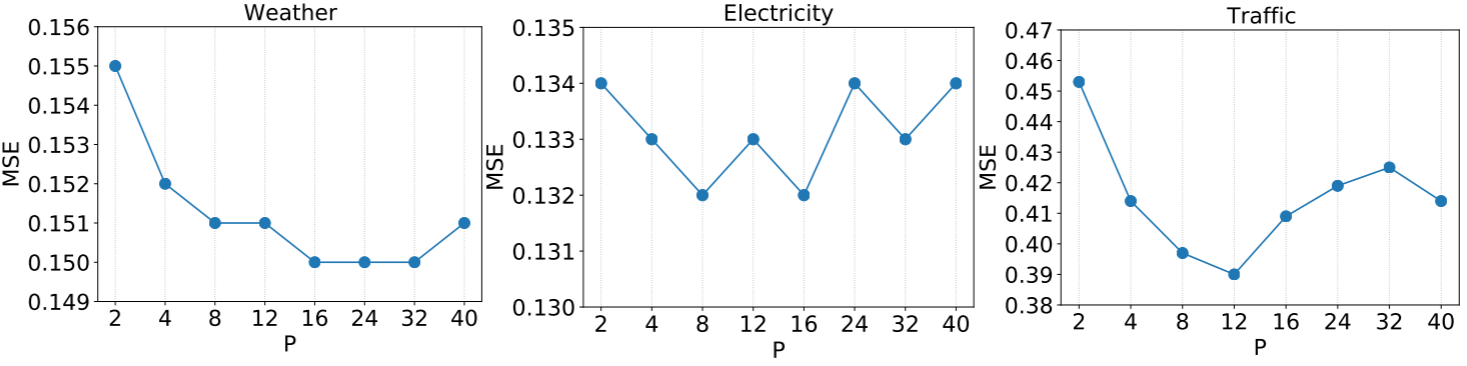
Figure 4:MSE随patch长度P(2~40)变化的曲线,Weather、Electricity、Traffic三个数据集
Figure 4表明,MSE对patch长度P的变化不敏感,P在{8, 16}之间是通用的好选择。这意味着使用者无需花大量时间调节这一超参数。
九、总结与展望
PatchTST通过两个简洁的设计------Patching 和 Channel-Independence ------重新确立了Transformer在时间序列长期预测中的地位,不仅全面超越了之前所有Transformer变体,在大型数据集上也超越了简单但强劲的DLinear,同时还展现出优秀的自监督表示学习和迁移学习能力。
核心贡献总结:
- Transformer用于时序预测是有效的,但需要正确的设计方式
- Patching是一种简单且通用的操作,可轻松迁移到其他模型
- Channel-independence在数据有限的时序场景下往往优于channel-mixing
未来方向:
- Channel-independence目前无法显式建模跨通道依赖,如何将跨通道关联建模与其结合是重要的下一步(例如引入图神经网络)
- PatchTST具备成为时间序列基础模型(Foundation Model)的潜力,值得进一步探索
个人点评:PatchTST是一篇"想清楚了再做"的好论文。它没有引入复杂的新机制,而是回归问题本质------时序数据的局部语义和多变量过拟合问题------用两个直觉清晰、验证充分的设计给出了漂亮的答案。Patching的思路直接借鉴自ViT,而channel-independence的深入分析(数据效率、过拟合、适应性)尤其有说服力,为后续工作提供了重要的设计指导原则。