目前学术界和工业界E2E的技术路线大致如下:
- 直接端到端,例如PLUTO、Tranfuser、VAD
- 模块化端到端,例如 UniAD
- WorldModel
- Diffusion策略,例如 DiffusionDrive
- 大语言模型路线: 例如 driveGPT4,EMMA,Senna
再再细化而言,考虑到不同厂商和车型,是否纯视觉?有Lidar的话如何融合的?端到端模型的训练范式是怎样的,模仿学习/监督学习/强化学习?Loss的设计有何创新?有哪些辅助loss?有无Training Trick来提升训练和推理效果?数据闭环处理上有何方法? 喂给模型的数据有无数据增强,等等。
直接端到端
PLUTO
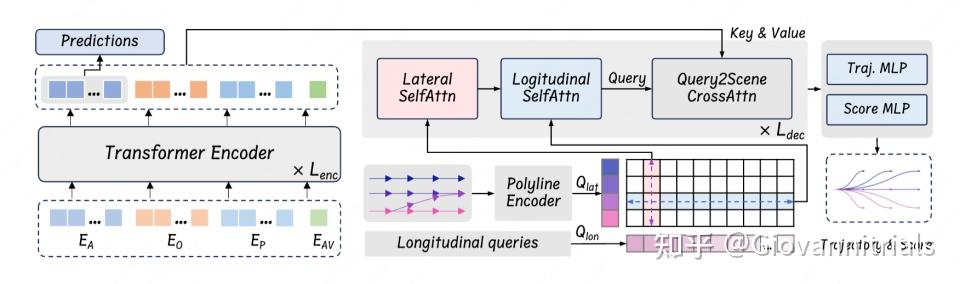
Lateral 和 Longitudinal 的self attention是亮点
- 模仿学习 + 纯视觉
- 引入了一种基于查询的模型架构,该架构能够同时处理横向和纵向的规划动作,从而实现灵活多样的驾驶行为。
- 提升横向行为智能性
- 提出了一种基于微分插值(differential interpolation)的辅助损失计算新方法。这种方法适用于广泛的辅助任务,并允许在基于向量的模型中进行高效的批量计算。
- 仅仅依赖模仿学习损失不足够,施加明确的约束在训练阶段是必要的
- 提出了对比模仿学习(Contrastive Imitation Learning)(CIL)框架,并伴随一系列新的数据增强手段。
- 该CIL框架旨在调节驾驶行为和增强交互学习,同时不会显著增加训练的复杂性。
Transfuser
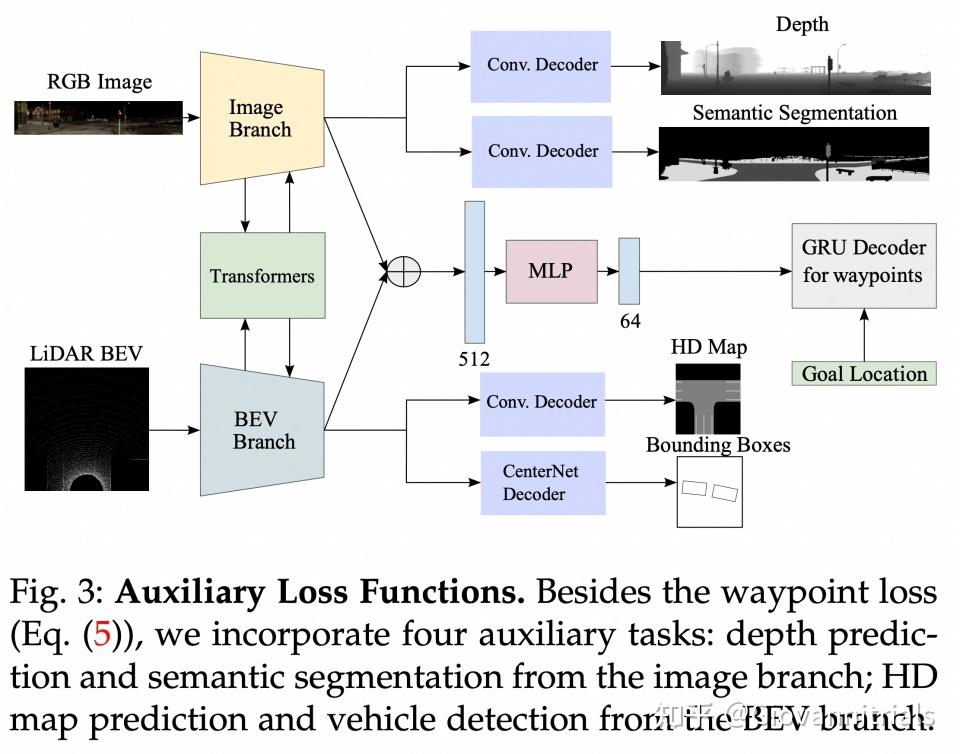
GRU decoder将当前位置和目标位置作为输入,网络可以关注隐态下的相关上下文,预测下一个路点
- 模仿学习 + 多传感器融合(视觉和激光雷达)
- 一种使用自注意将图像和激光雷达表示集成的机制
VAD
GitHub - hustvl/VAD: ICCV 2023 VAD: Vectorized Scene Representation for Efficient Autonomous Driving
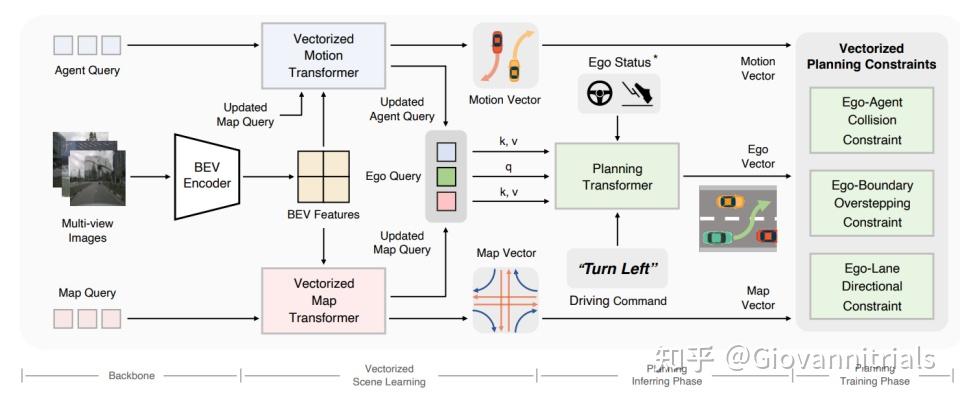
矢量化的表示 + 矢量化的planning约束
- 模仿学习 + 纯视觉
- 一个用于自动驾驶的端到端矢量化范例。VADVAD摈弃了栅格化表征,将驾驶场景建模为完全矢量化的表示,摆脱了计算密集的密集光栅化表示和手工设计的后处理步骤。
- 通过query交互和矢量化的规划约束,隐式和显式地利用矢量化的场景信息,以提高规划的安全性
- 由于矢量化的场景表示和简洁的模型设计,VAD 极大地提高了推理速度
但是
- 多模态运动预测的整合:未完全利用多模态运动预测结果。如何更有效地利用多模态轨迹预测结果,进一步提升规划性能。
- 未融合更多交通信息:例如车道图、交通信号和道路标志,提高系统的鲁棒性和实际适用性。
VADV2
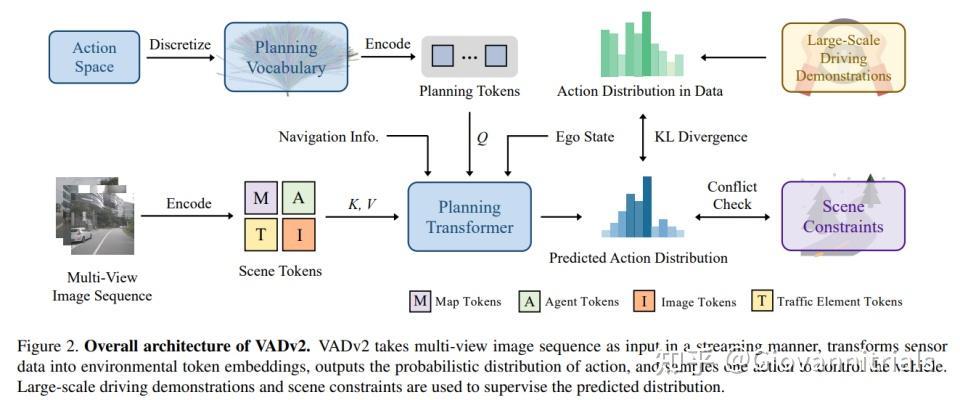
概率规划方法 + 大规模数据的动作分布作为先验
- 模仿学习 + 纯视觉
- 提出了概率规划方法以应对规划中的不确定性。设计了概率场(Probabilistic Field),用于从动作空间映射到概率分布,并通过大规模驾驶演示学习动作分布。
- 基于概率规划,提出了端到端驾驶模型 VADv2,该模型能够将传感器数据转化为环境令牌嵌入,输出动作的概率分布,并采样一个动作来控制车辆。
- Loss: 分布损失:使用KL散度最小化预测分布于数据分布的差异.
较依赖初始的action 分布。
GenAD
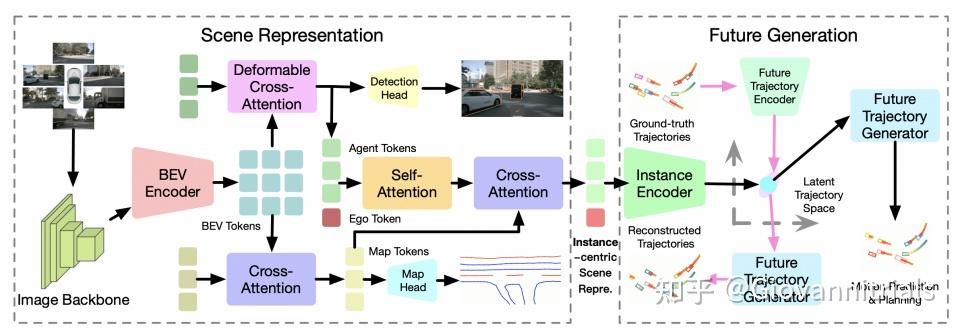
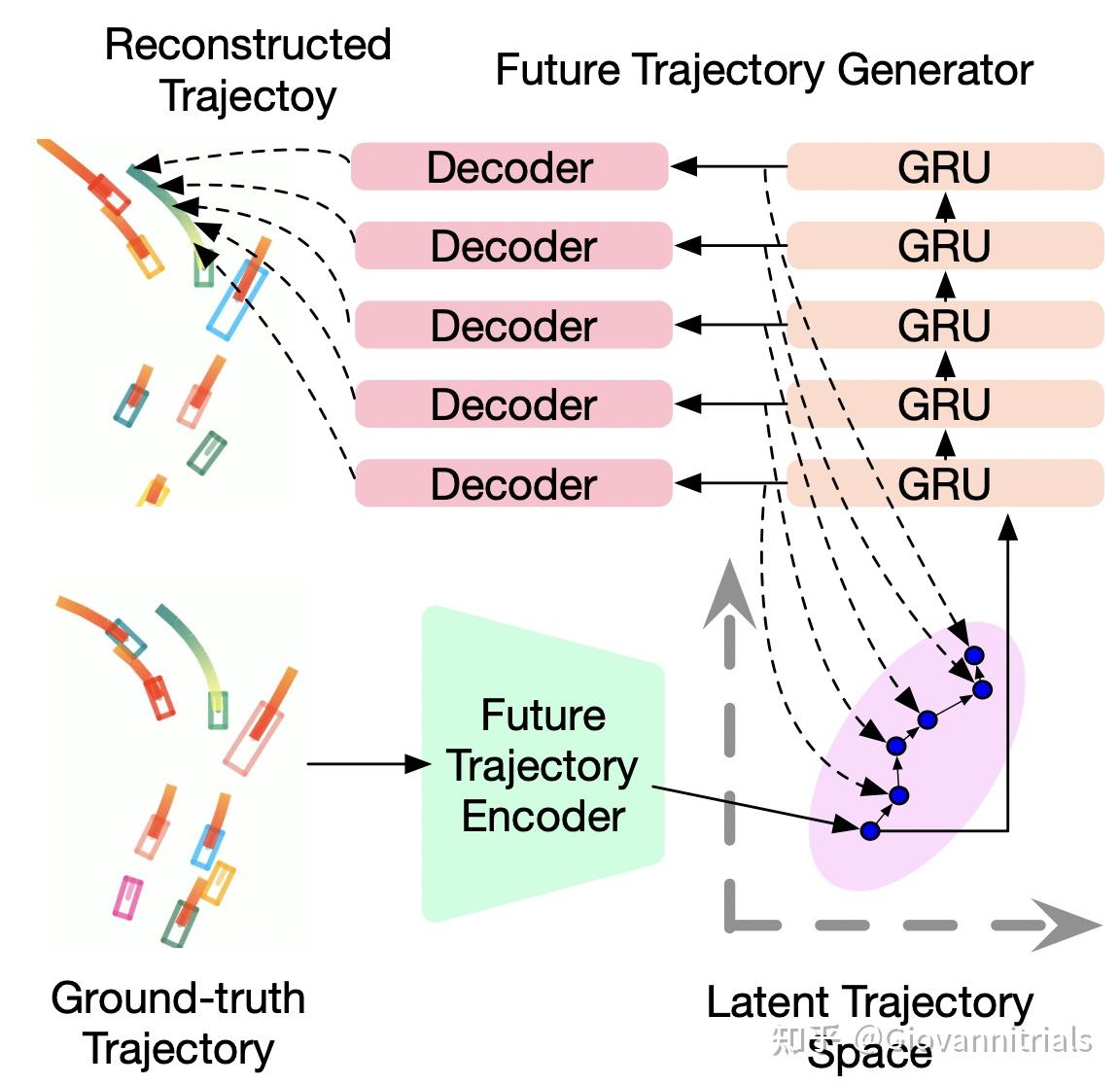
通过VAE将真实的ego未来轨迹映射到隐空间,然后在推理时将解码器的输出通过GRU来预测下一个隐式空间的状态
- 亮点在于: 通过VAE将真实的ego未来轨迹映射到隐空间,然后在推理时将解码器的输出通过GRU来预测下一个隐式空间的状态,最后通过MLP解码出下一个轨迹点。与直接输出整个轨迹的单一解码器(DR方法)相比,航点解码器执行的任务更简单,只负责解码 BEV 空间中的一个位置,而 GRU 模块则在潜在空间 Z中模拟agent的运动。
GoalFlow
CVPR'25 SOTA!中科院&地平线GoalFlow:解锁端到端生成式策略新未来~mp.weixin.qq.com/s/zSa12NsdG4V-pYsMLwyBpw
模块化端到端
UniAD
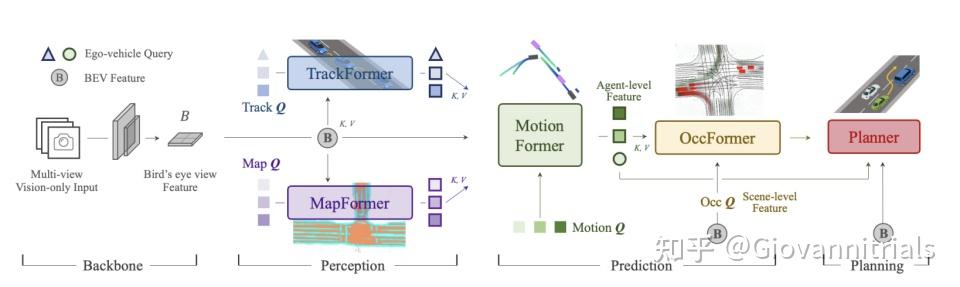
- Backbone: 是多摄像头提取特征,通过BEVFormer转换出BEV特征。
- TrackFormer: 负责检测和跟踪智能体。
- MapFormer: 作为道路要素的语义抽象和执行全景分割。
- MotionFormer: 捕获智能体和maps的交互和预测每个智能体的未来轨迹。
- OccFormer: 以BEV特征作为查询,智能体知识作为键和值,预测多步未来占用。
- Planner: 利用MotionFormer的表达性自我-车辆查询来预测规划结果,并远离OccFormer预测的被占用区域,以避免碰撞。
- 监督学习 + 纯视觉
- 模块化端到端,各个模块可分别训练
- 相比直接end2end有一定可解释性?
强化学习+模仿学习
RAD
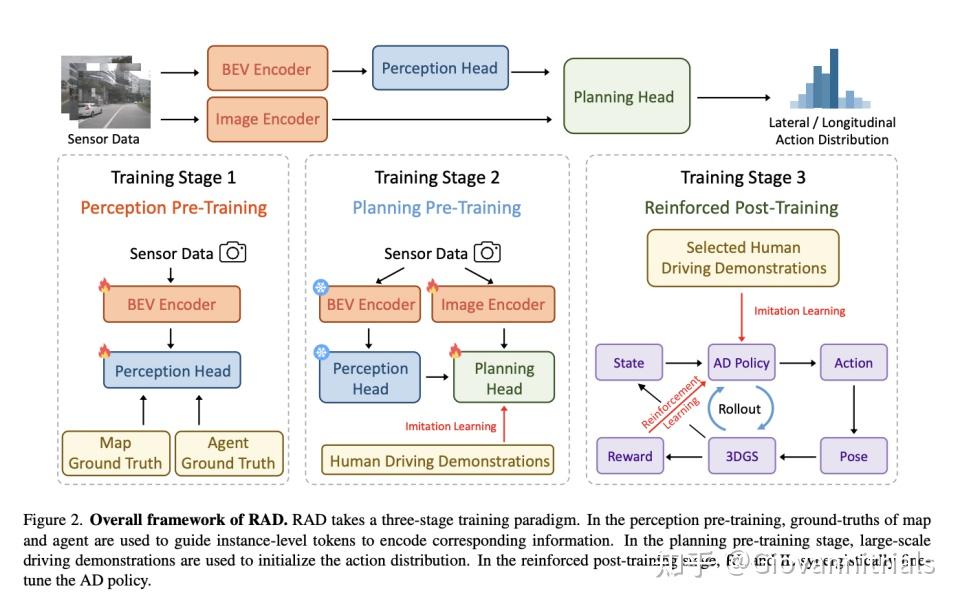
3个stage,感知和规划预训练+RL postrain
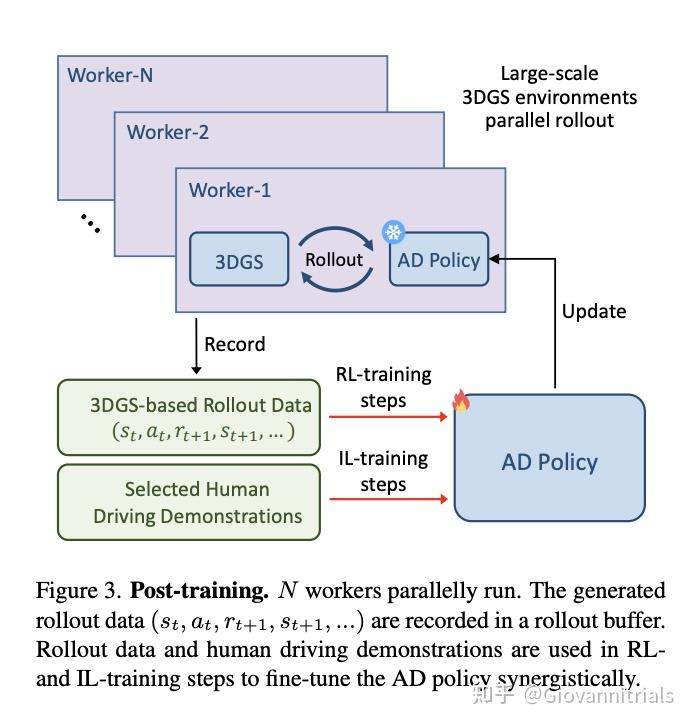
RL和IL交替训练
- 强化学习 + 模仿学习 新的训练范式
- 提出了第一个基于3DGS的RL框架,用于训练端到端AD策略。奖励、动作空间、优化目标和交互机制经过特别设计,以提高训练效率和效果。
- 结合RL和IL协同优化AD策略。RL通过建模因果关系和缩小开环差距来补充IL,而IL在人类对齐方面补充RL。
但是基于3DGS仿真环境来做强化学习,但目前所使用的3DGS环境运行方式缺乏反应性,即其他交通参与者不会根据自车的行为做出反应,仅以日志重放的形式行动。
Diffusion策略
DiffusionDrive
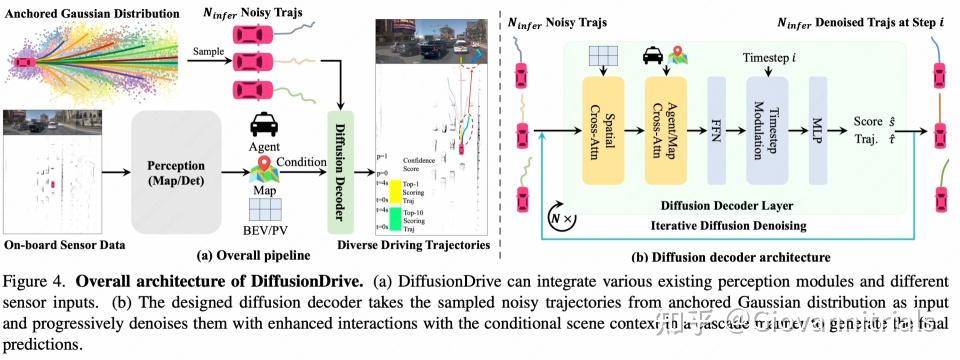
anchored-based预轨迹 + 扩散模型
- 监督学习 + 扩散模型
- 可适配不同感知模块
- anchored-based的锚轨迹从训练集中通过K-means聚类
但强依赖预先的anchored-based轨迹?
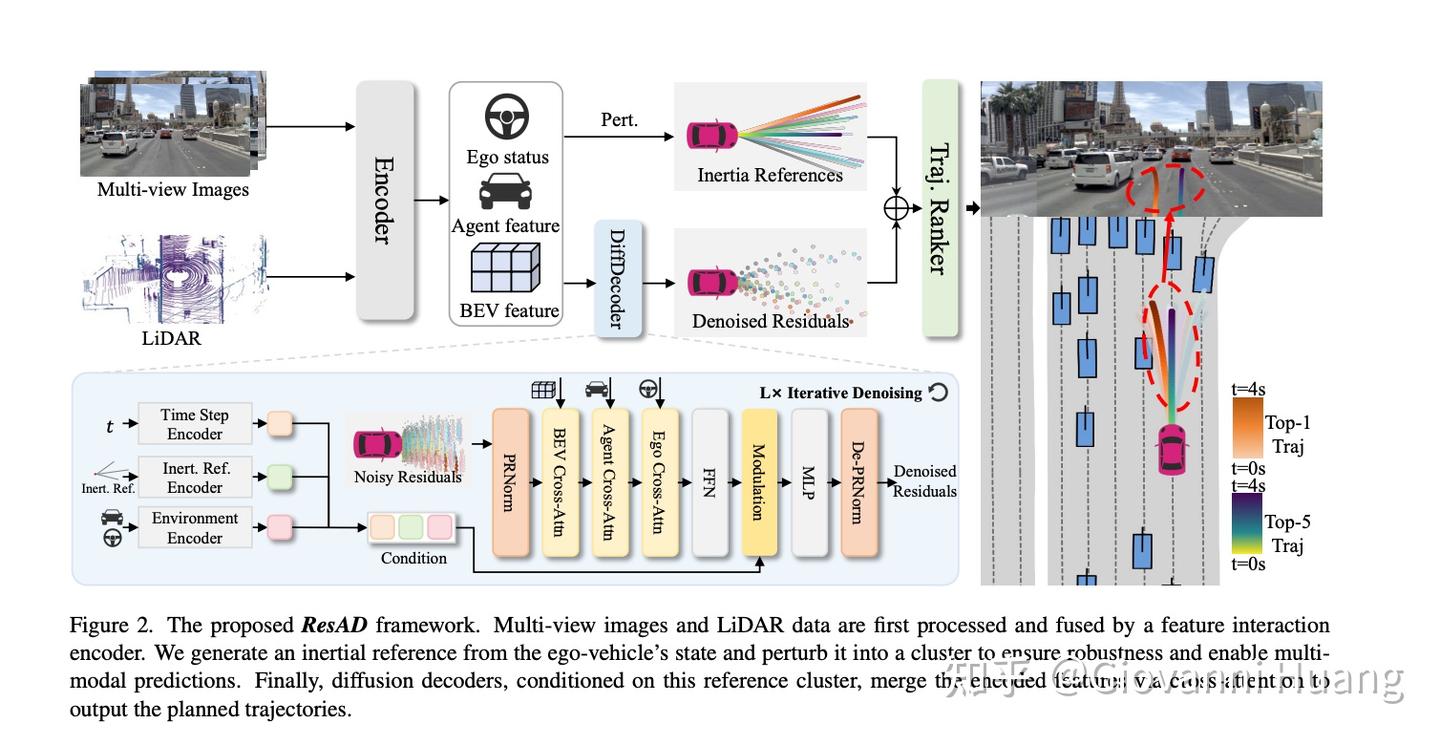
ResAD
类似方法,很有意思。ResAD: Normalized Residual Trajectory Modeling for End-to-End Autonomous Driving
大语言模型路线
EMMA
VLM&VLA路线
【RL+VLM】
AlphaDrive