洛谷P8681
完全二叉树按层求权值和最大深度问题
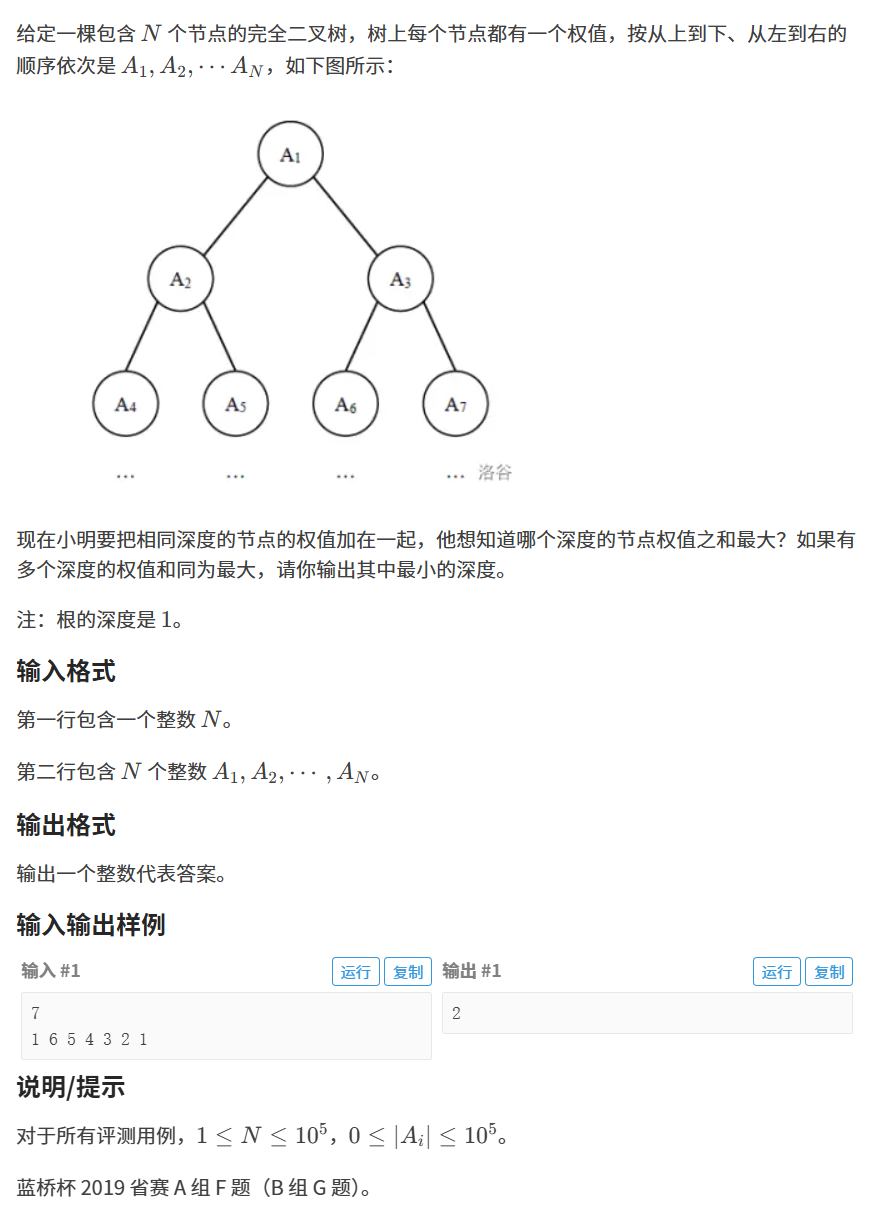
完全二叉树就像:
-
电影院座位:第一排坐满,第二排坐满,第三排从左到右连续坐人,不留空位
-
书本排版:每一行都排满文字,最后一行可能不满,但文字都是从左开始
不是完全二叉树就像:
- 电影院座位:第一排坐满,第二排坐满,第三排中间空一个座位才坐人
满二叉树 vs 完全二叉树(对比表格)
|------|------------------------|------------------------|
| 特性 | 满二叉树 | 完全二叉树 |
| 定义 | 所有层都满,每个节点都有两个孩子(除了叶子) | 最后一层可以不满,但必须靠左连续 |
| 形状 | 完美的三角形 | 可能缺右下角 |
| 节点数 | 固定:2^h - 1(h为高度) | 范围:2^(h-1) 到 2^h - 1 |
| 叶子位置 | 都在同一层 | 只在最后两层 |
| 严格程度 | 最严格 | 相对宽松 |
最近在做一道关于完全二叉树的小题,题目本身不复杂,但挺适合用来巩固对二叉树层序结构的理解。这里简单整理一下思路和实现过程,写成一篇小总结。
题目给定一个包含 N 个节点的完全二叉树,并且节点是按照从上到下、从左到右的顺序给出的,也就是典型的"层序存储"。我们需要做的是:把相同深度的节点权值加起来,找出权值和最大的那一层,如果有多层相同,则输出最小的深度。
一开始看到"完全二叉树 + 顺序存储",其实就应该想到一个关键点:不需要真的去建树。因为数组本身已经隐含了层序结构。
对于完全二叉树来说,每一层的节点数量是有规律的:
-
第 1 层:1 个节点
-
第 2 层:2 个节点
-
第 3 层:4 个节点
-
第 k 层:2^(k-1) 个节点
也就是说,我们可以直接按照这个规律在数组中"分段"处理。
核心思路其实很简单:
用一个指针 start 表示当前层的起始位置,用 depth 表示当前是第几层。每一层的节点个数是 2^(depth-1),然后从数组中取出这一段求和,更新最大值即可。
代码如下:
cpp
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
vector<int> arr;
int n;
int main()
{
cin >> n;
arr.resize(n + 5);
for (int i = 1; i <= n; i++)
cin >> arr[i];
int ans = 0; // 当前最大权值和
int endans; // 对应的深度
int start = 1; // 当前层起始位置
int depth = 1; // 当前深度
while (start <= n)
{
int nowsum = 1 << (depth - 1); // 当前层节点数
int sum = 0;
for (int i = start; i < start + nowsum && i <= n; i++)
{
sum += arr[i];
}
if (sum > ans)
{
ans = sum;
endans = depth;
}
start += nowsum;
depth++;
}
cout << endans << endl;
return 0;
}这里有几个细节值得注意一下。
首先是 1 << (depth - 1),这个是用位运算来计算 2 的幂,比用 pow 更高效,也更常见。
其次是循环里的边界控制:i <= n。因为最后一层不一定是满的,所以要防止越界。
还有一个点是 start 的更新,每处理完一层,就直接跳到下一层的起始位置,这样整体时间复杂度就是 O(N)。
整体来看,这道题的关键不是二叉树本身,而是"如何利用完全二叉树的结构特性,把问题转化为数组分段处理"。一旦想到这一点,实现就会变得很直接。
这类题目在算法题中很常见,尤其是在不需要真的建树的时候,多考虑一下"下标和结构的关系",往往能让问题简单很多。
洛谷P4715
淘汰赛求亚军问题的一种递归解法
这道题是一个比较典型的模拟淘汰赛过程的题目。给定 (2^n) 个国家,每个国家都有一个能力值,并且两两对决,能力强的胜出,最终决出冠军。题目要求输出的是"亚军"的编号。
一开始看到这种题,很多人可能会想着用循环一轮一轮模拟比赛,其实这样也可以做。但这道题有一个更自然的解法,就是用递归去还原整个比赛过程,本质上就是一棵"比赛树"。
可以这样理解:整个淘汰赛就是一棵二叉树,每一场比赛都是一个节点,左右子树分别代表两个子赛区的结果,而当前节点就是这两个子赛区冠军之间的对决。
因此,我们可以定义一个函数:在区间 (l, r) 内,返回这一段选手的"冠军"。
递归的思路非常直接:
如果区间里只有一个人,那么他就是冠军;
否则就把区间分成左右两部分,分别求出左半区冠军和右半区冠军,然后比较两者能力值,返回更强的那一个。
代码实现如下:
cpp
#include <iostream>
#include <vector>
#include <cmath>
using namespace std;
struct Team {
int id;
int ability;
};
// 返回区间 [l, r] 的冠军
Team find_champion(vector<int> ability, int l, int r) {
if (l == r) {
return {l, ability[l]};
}
int mid = (l + r) / 2;
Team left = find_champion(ability, l, mid);
Team right = find_champion(ability, mid + 1, r);
if (left.ability > right.ability) {
return left;
} else {
return right;
}
}
int main() {
int n;
cin >> n;
int m = 1 << n;
vector<int> ability(m + 1);
for (int i = 1; i <= m; i++) {
cin >> ability[i];
}
// 左右半区冠军
Team left_champion = find_champion(ability, 1, m / 2);
Team right_champion = find_champion(ability, m / 2 + 1, m);
// 亚军就是最终决赛输掉的人
if (left_champion.ability < right_champion.ability) {
cout << left_champion.id << endl;
} else {
cout << right_champion.id << endl;
}
return 0;
}这里有一个关键点需要理解清楚:为什么最后只需要比较"左右半区冠军"就能得到亚军?
因为淘汰赛的结构决定了,最终的冠军一定是全场最强的那个选手,而亚军一定是在"决赛"中输给冠军的人。也就是说,亚军只可能出现在另一个半区的冠军里,而不可能是更早被淘汰的人。
所以我们不需要关心整个比赛过程中每一轮的失败者,只需要找到左右两边的"最强者",然后取较小的那个,就是答案。
这道题的核心其实不在递归本身,而是在于把"淘汰赛"抽象成一棵二叉树结构。一旦有这个思路,代码就会变得很清晰。
另外还有一个可以优化的小点:find_champion 里的 vector<int> ability 是值传递,其实可以改成引用传递,避免不必要的拷贝,这在数据量更大时会更高效。
整体来说,这是一道很适合练习"递归建模"的题,把过程问题转化成结构问题,是算法题里一个很重要的思路。