作者:Xiaohong Liu, Yongrui Ma , Zhihao Shi, Jun Chen
机构:McMaster University
来源期刊:ICCV
发表时间:2019年
一、研究动机
1. 研究目标
构建一个高效、端到端的单幅图像去雾网络,摆脱传统大气散射模型依赖,实现:
1.无需显式估计transmission map(透射率)和 atmospheric light(大气光)
2.直接从 hazy image 到 clean image 的映射
3.在合成与真实场景中均获得更优视觉质量与定量性能
2. 过去方法
(1)物理模型驱动方法
基于大气散射模型:
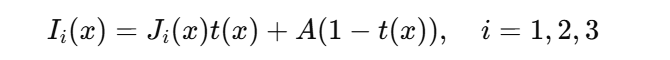
-

-
代表方法:
DCP(Dark Channel Prior)
-
Fattal 方法
-
问题:
-
强依赖先验假设
-
对天空/亮区域/复杂光照不鲁棒
-
-
(2)深度学习 + 物理模型方法
DehazeNet、MSCNN:
用 CNN 估计 transmission map
问题:
-
误差累积
-
优化困难
-
依赖模型正确性
(3)端到端去雾方法
-
AOD-Net:改写物理公式
-
GFN:多输入融合(手工预处理)
问题:
-
GFN 依赖手工设计输入
-
多尺度结构存在 bottleneck(信息流受限)
3. 本文方法
核心思想
完全抛弃物理模型,直接学习图像恢复映射
整体框架:GridDehazeNet
由三部分组成:
-
Pre-processing Module
-
Backbone(Grid Network)
-
Post-processing Module
关键模块
(1)Pre-processing Module
-
Conv + RDB
-
生成 16 个 learned inputs(学习得到的输入)
(2)Backbone:Grid Network
-
结构:3 行 × 6 列
-
每一行:一个尺度
-
每个节点:Residual Dense Block(RDB)
(3)Feature Fusion(Attention)
通道注意力融合:
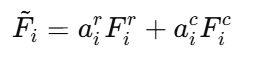
第 i个通道的融合结果,由行流特征和列流特征按不同权重相加得到。这样网络能自动决定当前更该相信哪个尺度的信息。
(4)Post-processing Module
对称结构(Conv + RDB)
去除 artifacts(伪影)
4. 优势与创新点
① 摆脱物理模型依赖
不再显式估计 t(x)、A
直接优化最终图像质量
② 可学习预处理(Learned Inputs)
-
自动生成多视角特征
-
优于手工增强方法
③ Grid 多尺度结构(核心创新)
-
避免 encoder-decoder bottleneck
-
强化跨尺度信息流
④ 通道注意力融合
-
自适应融合不同尺度特征
-
提升恢复质量
⑤ 模块化设计
- RDB + Grid 可迁移到其他恢复任务
二、算法主要思想与原理详解
1. 整体流程
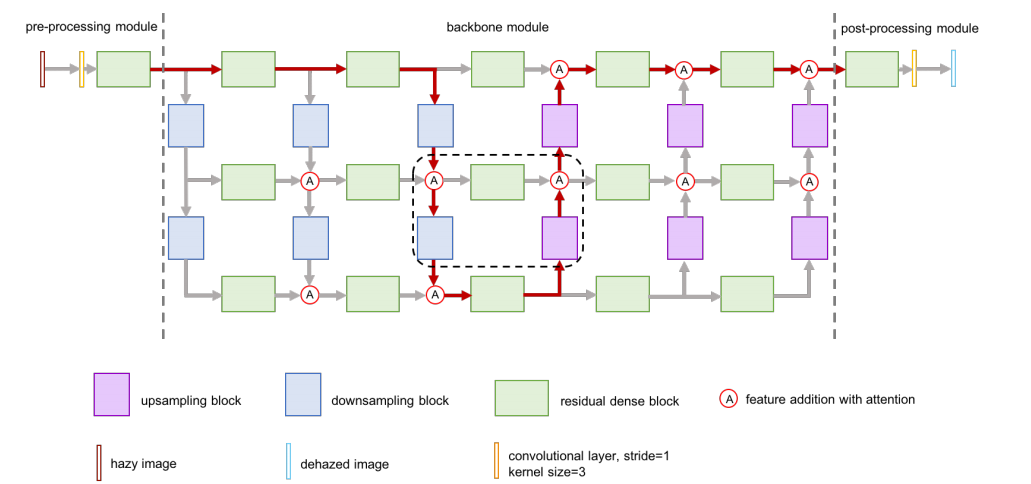
2. GridDehazeNet 核心结构
Backbone 结构:Grid Network
-
结构:3 行 × 6 列
-
每一行:一个尺度
-
每个节点:Residual Dense Block(RDB)
为什么用 Grid?
| 结构 | 问题 |
|---|---|
| Encoder-Decoder | 信息瓶颈 |
| Multi-scale串行 | 误差累积 |
Grid 优势:
1.多路径传播
2.多次跨尺度交互
3.无单点瓶颈
4.Residual Dense Block(RDB)
两个核心机制
(1)Dense Connection
每层接收前面所有层特征
特征复用 + 信息保留
(2)Residual Learning
学习残差
稳定训练
参数
growth rate = 16
4. Attention 融合机制
输入
同尺度特征(row stream)
跨尺度特征(column stream)
5. 损失函数
(1)Smooth L1 Loss
抗异常值
稳定训练
(2)Perceptual Loss(VGG16)
提取语义特征
提升视觉质量
三、实验结果
1. 数据集
训练集(RESIDE)
ITS(室内)
OTS(室外)
测试集
SOTS indoor(500)
SOTS outdoor(500)
Sun RGB-D(泛化测试)
2. 评价指标
PSNR
SSIM
3. 定量实验
SOTS结果(核心)
| 方法 | Indoor PSNR | Outdoor PSNR |
|---|---|---|
| DCP | 16.61 | 19.14 |
| DehazeNet | 19.82 | 24.75 |
| AOD-Net | 20.51 | 24.14 |
| GFN | 24.91 | 28.29 |
| GridDehazeNet | 32.16 | 30.86 |
结论
Indoor 提升 +7 dB(对比 GFN)
Outdoor 提升 +2.5 dB
- 消融实验
(1)Direct vs Indirect
| 方法 | PSNR |
|---|---|
| 间接 | 30.33 |
| 直接恢复 | 32.16 |
(2)Learned Inputs
| 输入类型 | PSNR |
|---|---|
| 原始图像 | 31.48 |
| 手工增强 | 30.21 |
| Learned | 32.16 |
(3)结构消融
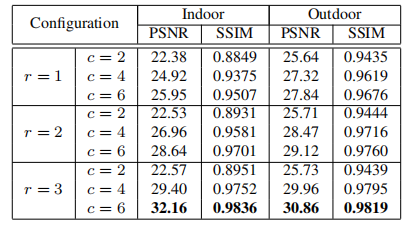 不同配置下SOTS的比较
不同配置下SOTS的比较
四、定性实验
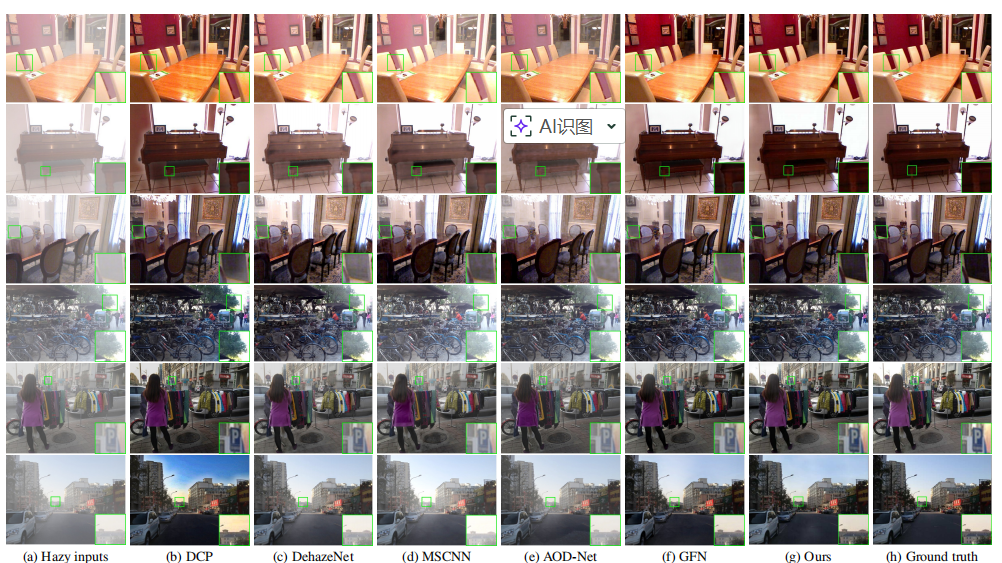 定性对比图
定性对比图
- 合成图像
DCP:偏色严
GFN:去雾不彻底
GridDehazeNet:
边缘清晰
无伪影
颜色自然
真实图像
去雾更彻底
无明显色偏
远景恢复更清晰
五、结论
GridDehazeNet 提出了一个:无需物理模型的端到端去雾框架
Learned Inputs(自动预处理)
Grid 多尺度结构(无瓶颈)
RDB(强特征表达)
Attention(自适应融合)