论文题目:Fusion-Mamba for Cross-Modality Object Detection(融合曼巴跨模态目标检测)
期刊:IEEE TRANSACTIONS ON MULTIMEDIA
摘要:跨模态物体检测旨在融合不同模态的互补信息以提高模型性能,从而实现更广泛的应用。然而,传统的基于cnn或Transformer的交叉模态融合方法不能很好地解决伪目标信息问题,导致模型注意力分散,降低物体检测性能。在本文中,我们研究了一种新的跨模态融合方法,该方法基于改进的mamba和门控注意机制将隐藏状态空间中的跨模态特征关联起来。我们提出融合曼巴块(Fusion-Mamba Block, FMB),旨在将跨模态特征映射到隐藏状态空间中进行交互,从而改进模型对真实目标区域的关注并提高整体性能。FMB包括两个关键模块:促进浅层特征融合的状态空间信道交换(SSCS)模块和实现深层融合并有效抑制隐藏状态空间内伪目标信息的双态空间融合(DSSF)模块。我们提出的方法优于最先进的方法,分别实现了5.9%,3.5%和2.1%的mAP onM3FD, drone - vehicle和flirt - aligned的改进。据我们所知,这项工作为跨模态物体检测建立了新的基线,为该领域的未来研究提供了鲁棒的的基础。
Fusion-Mamba:用Mamba重新定义跨模态目标检测
🎯 引言
在多模态感知系统中,如何有效融合RGB和红外图像一直是计算机视觉领域的重要挑战。来自北航、华东师大等机构的研究团队提出了Fusion-Mamba ,这是首个将Mamba架构应用于跨模态目标检测的工作,在多个公开数据集上刷新了SOTA记录。论文已发表在IEEE Transactions on Multimedia 2025。
🔍 问题背景:传统融合方法的"阿喀琉斯之踵"
为什么需要RGB-IR融合?
不同模态的图像具有天然的互补性:
- 红外图像:不受光照影响,提供清晰的热结构信息,但缺乏纹理细节
- 可见光图像:包含丰富的纹理和场景信息,但易受光照和天气影响
现有方法的痛点
作者通过深入分析发现,传统的CNN和Transformer融合方法存在一个被忽视的关键问题 ------伪目标信息(Pseudo-target Information):
如论文图1所示:
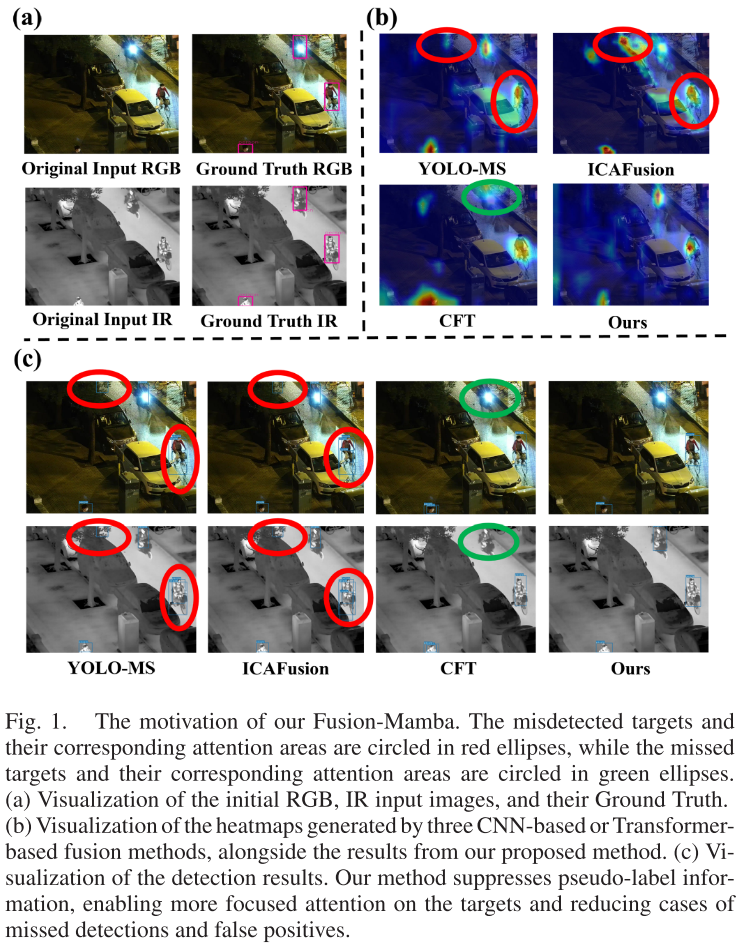
- YOLO-MS:注意力被背景噪声干扰,产生误检;噪声过度扩展目标区域,导致重复检测
- ICAFusion:类似问题,目标区域注意力过度扩散
- CFT:伪目标信息将注意力引向背景,导致真实目标漏检
这些问题的根源在于:融合过程中无法有效抑制原始模态中的噪声和干扰信息。
💡 Fusion-Mamba:开创性的解决方案
核心创新:在隐藏状态空间中融合
Fusion-Mamba的关键洞察是:不在原始特征空间直接融合,而是将特征映射到隐藏状态空间进行深度交互。这类似于在一个"中间地带"让两个模态的信息充分沟通,同时过滤掉各自的噪声。
整体架构
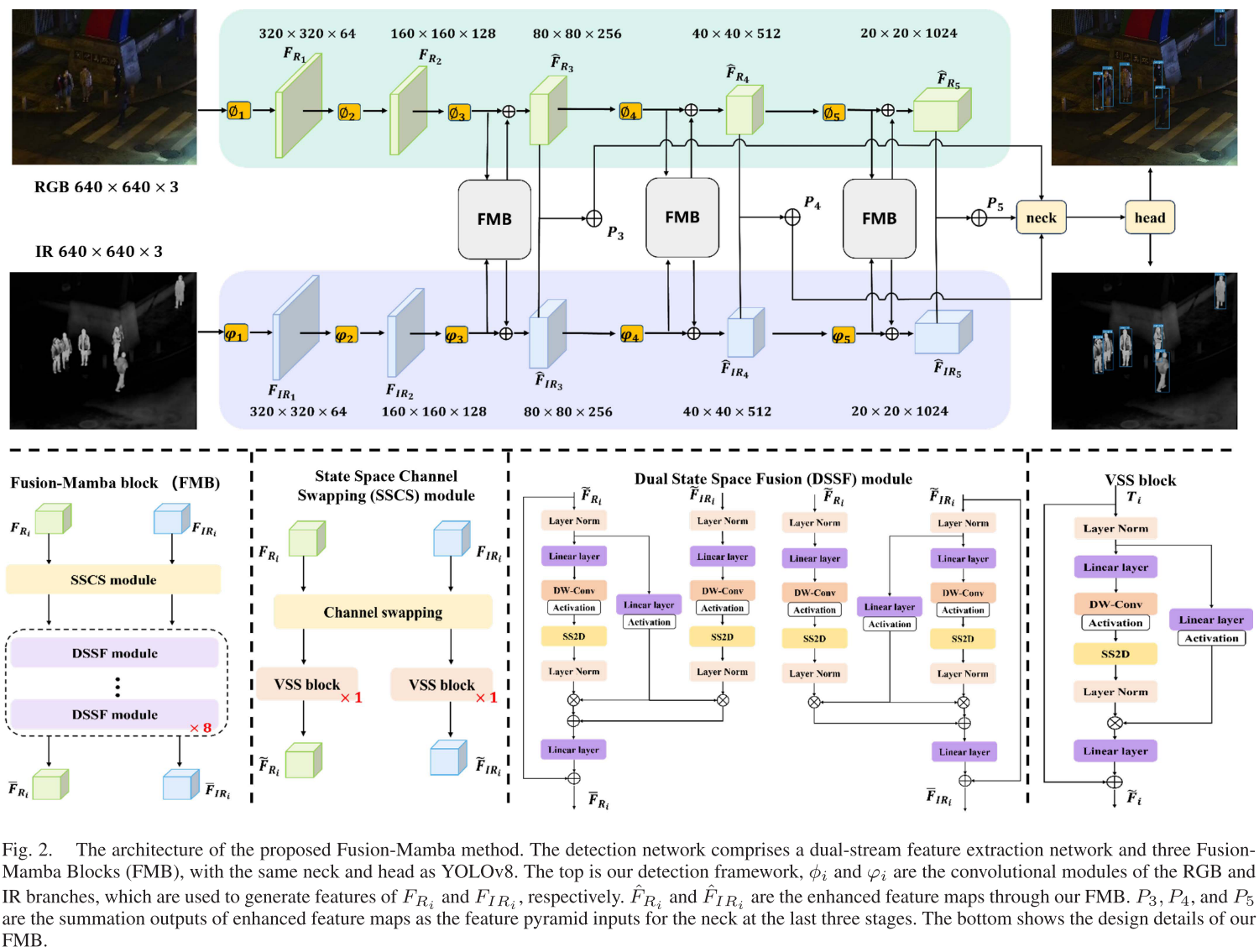
模型采用双流特征提取网络 + 三个Fusion-Mamba Blocks (FMB):
RGB分支: φ₁ → φ₂ → φ₃ → φ₄ → φ₅
↓ ↓ ↓
FMB₃ FMB₄ FMB₅
↑ ↑ ↑
IR分支: ϕ₁ → ϕ₂ → ϕ₃ → ϕ₄ → ϕ₅融合后的特征P₃, P₄, P₅送入YOLOv8的neck和head进行检测。
🔬 深入解析:Fusion-Mamba Block (FMB)
FMB是整个方法的核心,包含两个渐进式融合模块:
1️⃣ SSCS模块:浅层特征融合
State Space Channel Swapping (SSCS) 通过通道交换增强跨模态交互:
# 伪代码示意
F_R, F_IR = split_channels(RGB_feat, IR_feat) # 各分4份
T_R = concat([F_R[0], F_IR[1], F_R[2], F_IR[3]]) # 交叉组合
T_IR = concat([F_IR[0], F_R[1], F_IR[2], F_R[3]])
F̃_R = VSS_block(T_R) # 通过VSS块增强
F̃_IR = VSS_block(T_IR)设计思想:让每个分支都能获取另一个模态的丰富信息,为后续深度融合奠定基础。
2️⃣ DSSF模块:隐藏状态空间深度融合
Dual State Space Fusion (DSSF) 是论文的最大创新点:
步骤1:投影到隐藏状态空间
y_R = P_in(F̃_R) # RGB特征映射
y_IR = P_in(F̃_IR) # IR特征映射通过归一化、线性层、深度卷积和SS2D操作,将特征映射到隐藏状态空间。
步骤2:生成门控参数
z_R = f_θ(F̃_R) # RGB门控
z_IR = g_ω(F̃_IR) # IR门控步骤3:双向门控注意力融合(核心创新🌟)
y'_R = y_R ⊙ z_R + z_R ⊙ y_IR # ⊙表示逐元素乘法
y'_IR = y_IR ⊙ z_IR + z_IR ⊙ y_R这个设计极其巧妙:
- 第一项
y_R ⊙ z_R:自模态增强 - 第二项
z_R ⊙ y_IR:用RGB的门控参数处理IR特征
这种交叉门控机制实现了: ✅ 强化共性特征 :两个模态都关注的目标信息被增强
✅ 抑制伪目标:单模态特有的噪声被另一模态的门控抑制
步骤4:投影回原空间
F'_R = P_out(y'_R) + F̃_R # 残差连接
F'_IR = P_out(y'_IR) + F̃_IR
F̂_R = F_R + F'_R # 增强原始特征
F̂_IR = F_IR + F'_IR3️⃣ SS2D:四向扫描策略
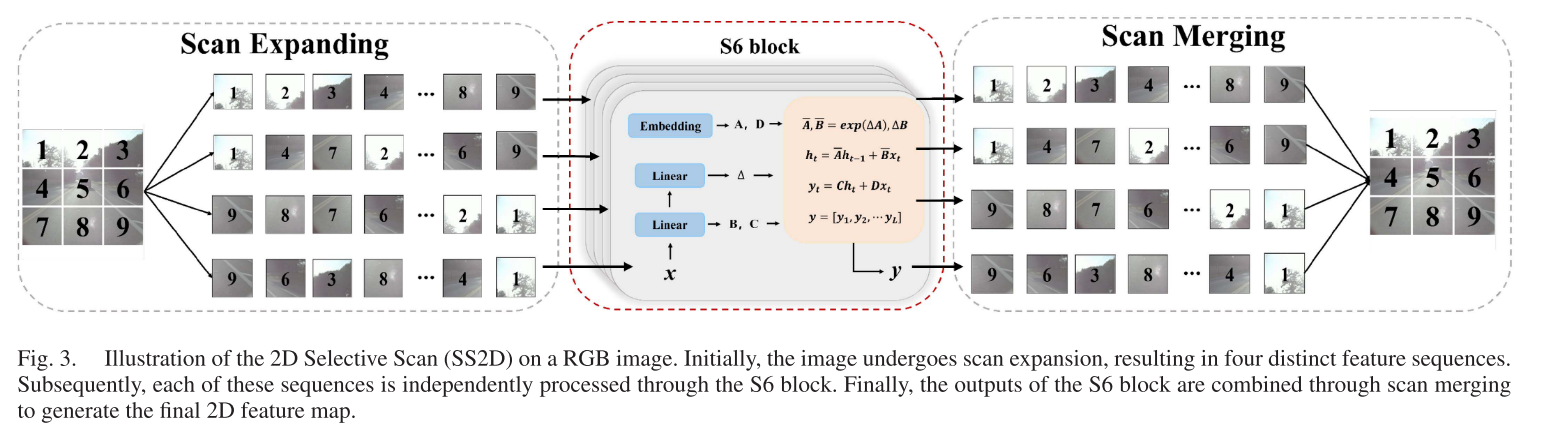
为了适配2D图像,Fusion-Mamba采用四向扫描:
- 从左上到右下
- 从右下到左上
- 从右上到左下
- 从左下到右上
每个方向生成一个序列,通过S6块处理后合并,确保每个位置都能感知全局信息。
📊 实验结果:全面超越SOTA
主要数据集性能
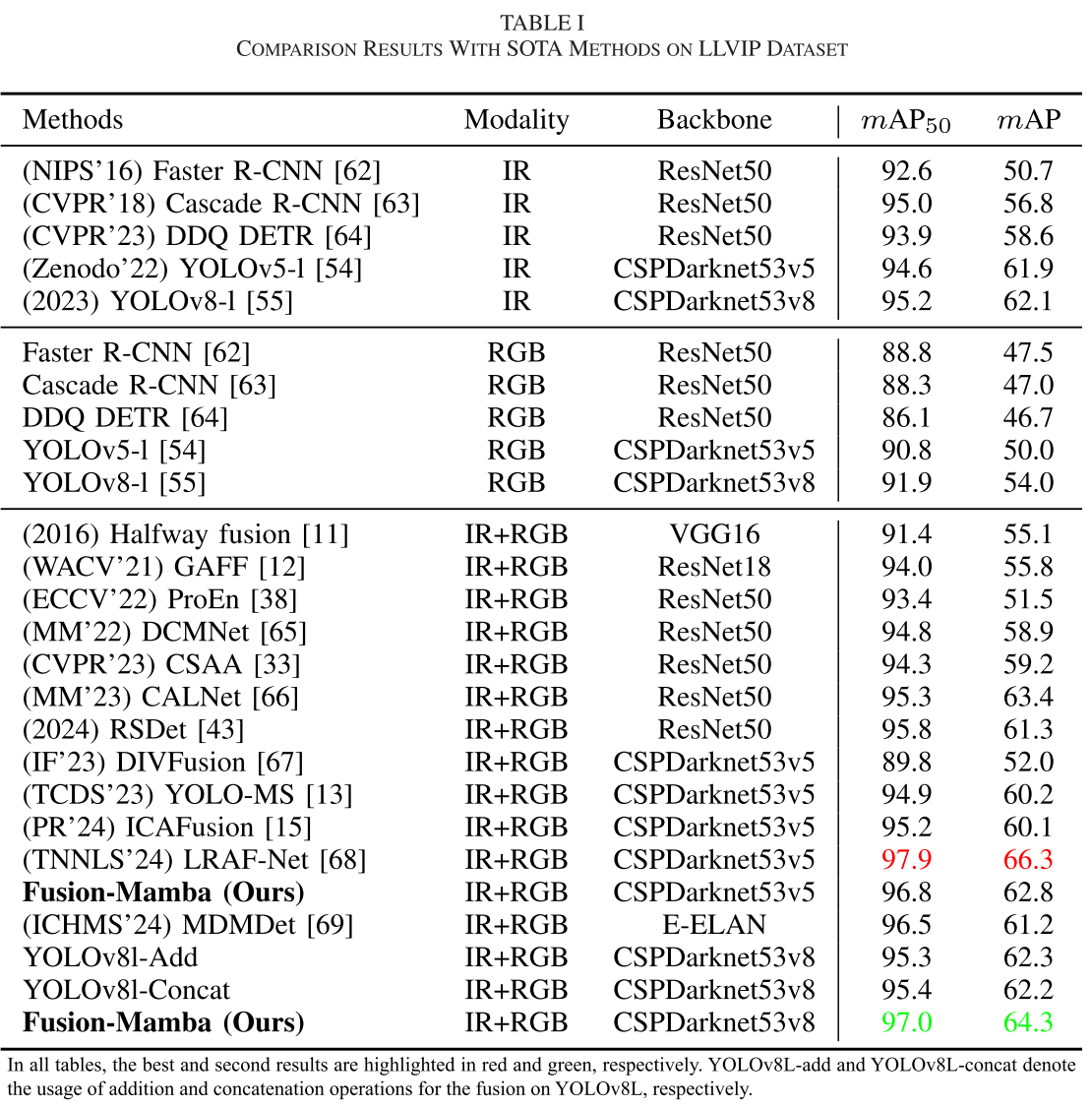
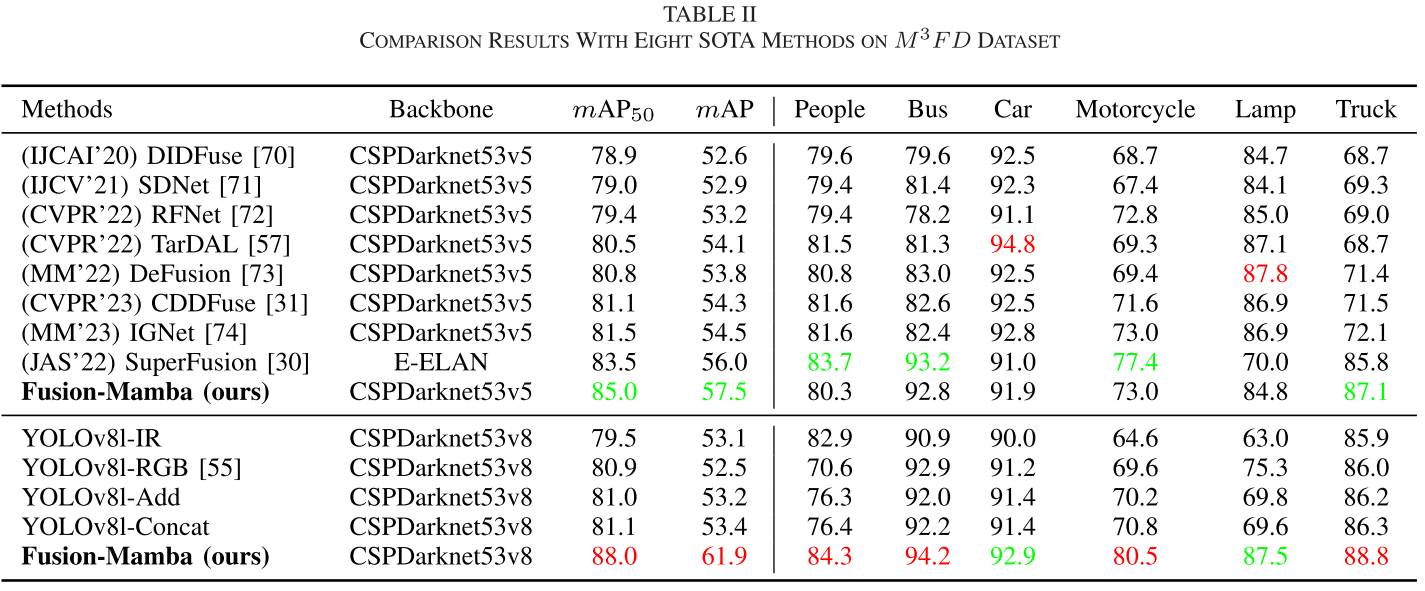
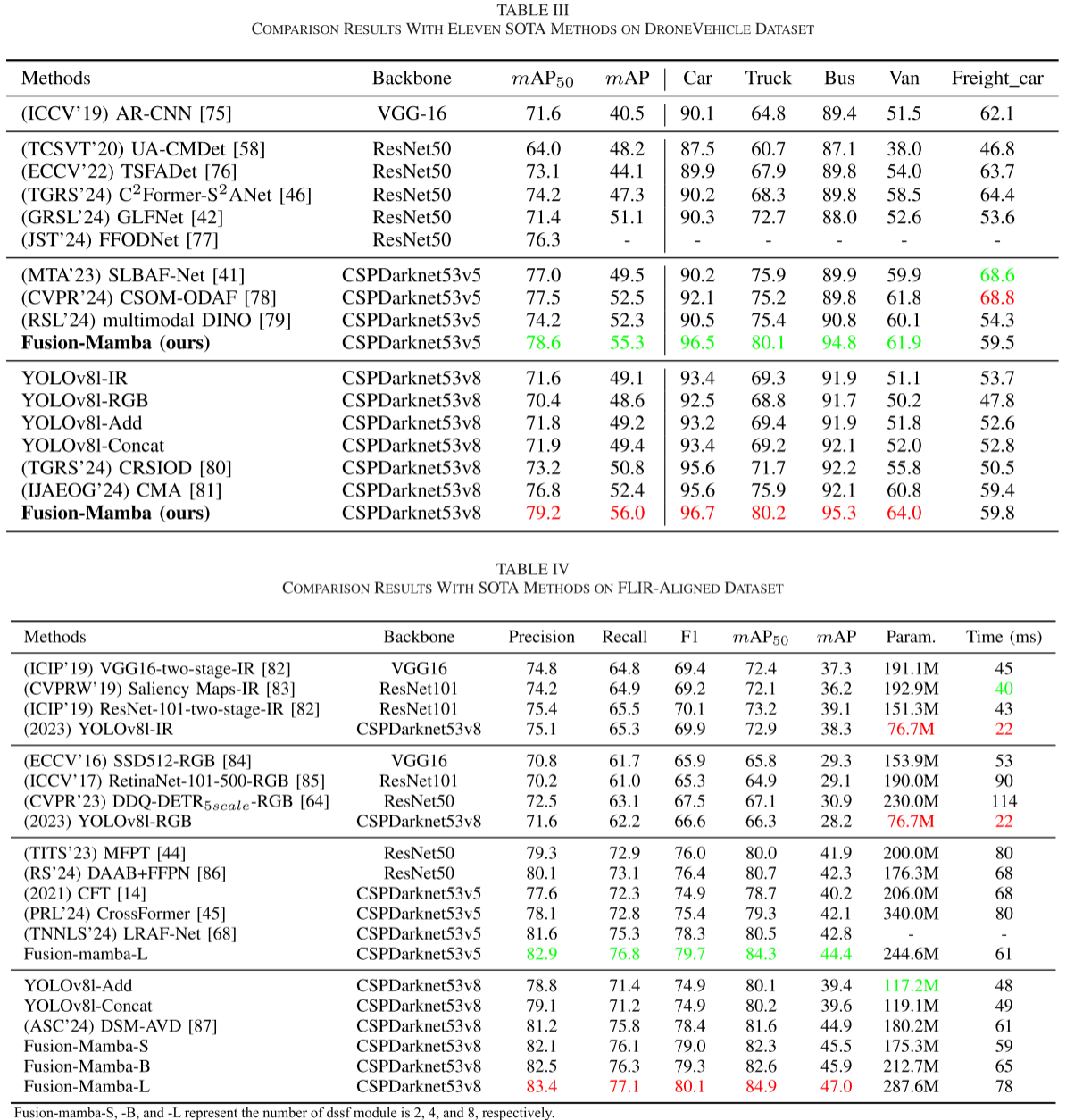
| 数据集 | 场景特点 | Fusion-Mamba | 前SOTA | 提升 |
|---|---|---|---|---|
| M3FD | 恶劣天气、多场景 | 73.3% mAP | 67.4% | +5.9% |
| DroneVehicle | 无人机俯视、密集标注 | 57.0% mAP | 53.5% | +3.5% |
| FLIR-Aligned | 昼夜场景、高难度 | 84.9% mAP₅₀ | 82.8% | +2.1% |
| LLVIP | 低光照环境 | 97.0% mAP₅₀ | 96.0% | +1.0% |
关键优势
1. 效率更高
与Transformer方法对比(同等检测架构):
- 推理速度:节省7-19ms (单对图像,A800 GPU)
- 复杂度:O(N) vs O(N²)
2. 可视化效果显著
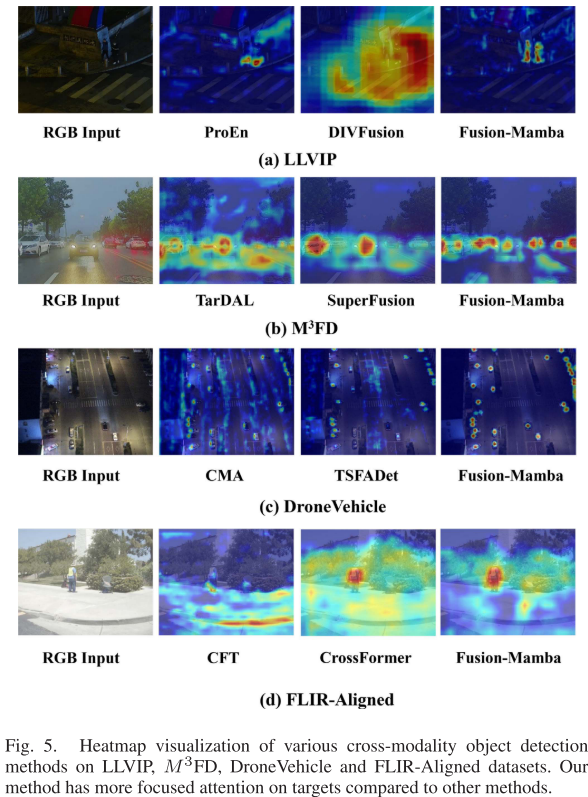
从热力图可以看出(图5):
- 其他方法:注意力分散,背景区域激活明显
- Fusion-Mamba:注意力高度集中在真实目标上,背景干净
3. 检测结果对比
论文图6展示了四个数据集的检测结果:
- 🟢 Fusion-Mamba:几乎没有漏检和误检
- 🔴 其他方法 :
- 低光照下漏检行人(LLVIP)
- 恶劣天气下漏检远处目标(M3FD)
- 密集场景下多次误检(DroneVehicle)
- 遮挡情况下漏检(FLIR)
🔬 消融实验:每个模块都很重要
SSCS和DSSF的作用
| 配置 | FLIR mAP₅₀ | LLVIP mAP₅₀ |
|---|---|---|
| 完整模型 | 84.9% | 97.0% |
| 移除SSCS | 82.9% (-2.0%) | 96.4% (-0.6%) |
| 移除DSSF | 82.4% (-2.5%) | 96.0% (-1.0%) |
| 仅相加融合 | 80.1% (-4.8%) | 95.3% (-1.7%) |
| 仅拼接融合 | 80.2% (-4.7%) | 95.4% (-1.6%) |
结论:
- SSCS提供必要的浅层交互,缺少会导致后续融合不充分
- DSSF是核心,缺少则无法抑制伪目标信息
- 简单的相加/拼接远不如隐藏状态空间融合
双向注意力的必要性
| 配置 | mAP₅₀ | 说明 |
|---|---|---|
| 完整双向注意力 | 84.9% | z_R⊙y_IR + z_IR⊙y_R |
| 移除IR→RGB | 83.3% (-1.6%) | 只保留z_IR⊙y_R |
| 移除RGB→IR | 83.8% (-1.1%) | 只保留z_R⊙y_IR |
| 移除全部 | 82.9% (-2.0%) | 退化为VSS堆叠 |
关键发现:双向交叉门控是抑制伪目标的关键!
DSSF模块数量
| 模块数 | mAP₅₀ | 参数量 | 推理时间 |
|---|---|---|---|
| 2 (S) | 82.9% | 67.1M | 59ms |
| 4 (B) | 83.8% | 102.7M | 69ms |
| 8 (L) | 84.9% | 287.6M | 78ms |
| 16 | 84.7% | - | - |
最佳实践:8个DSSF模块是性能-效率的最佳平衡点。
🌟 方法特色与启示
1. Mamba在视觉融合中的首次应用
- 证明了Mamba不仅适用于序列建模,在特征融合任务中同样强大
- 线性复杂度使其在高分辨率图像上更具优势
2. 隐藏状态空间融合范式
传统思路:F_fused = Fusion(F_RGB, F_IR) (直接融合)
Fusion-Mamba:
F_RGB, F_IR → 隐藏空间 → 深度交互 → 抑制噪声 → 增强融合这种范式为多模态融合提供了新思路。
3. 双向门控注意力机制
用一个模态的信息去调制另一个模态,这是一个简单但极其有效的设计:
- 理论上:共性特征在两个门控下都会被保留,独有噪声会被对方抑制
- 实践上:消融实验证明了2%的性能提升
4. 泛化能力强
成功扩展到语义分割任务(MSRS数据集),证明了方法的通用性。
💭 讨论与未来方向
优势
✅ 首个Mamba跨模态融合方法,开辟新研究方向
✅ 有效解决伪目标信息问题
✅ 线性复杂度,效率高
✅ 即插即用的FMB模块设计
✅ 多个数据集SOTA,泛化能力强
潜在改进方向
- 更多模态:扩展到RGB-D、RGB-Event等
- 实时性优化:进一步压缩模型用于边缘设备
- 自适应融合:根据场景动态调整融合策略
- 小目标检测:针对少样本小目标场景优化
论文作者展望
未来计划探索:
- 跨模态图像融合
- 跨模态目标跟踪
- 跨模态少样本小目标检测
🎓 结论
Fusion-Mamba为跨模态目标检测树立了新的baseline。它不仅在性能上全面超越现有方法,更重要的是:
- 问题导向:准确识别并解决了伪目标信息这一被忽视的关键问题
- 架构创新:首次将Mamba引入视觉融合,证明了其在这一领域的巨大潜力
- 设计巧妙:双向门控注意力机制简洁而有效
- 实用价值:线性复杂度使其更适合实际部署
对于从事多模态感知、自动驾驶、安防监控等领域的研究者和工程师,这篇论文提供了很好的方法论参考。
关键词:跨模态融合、目标检测、Mamba、状态空间模型、RGB-IR、伪目标抑制、门控注意力
希望这篇博客能帮助你深入理解Fusion-Mamba的创新之处!如有任何问题,欢迎讨论交流。🚀