针对复杂三维环境下无人机自主导航中存在的碰撞风险高、目标到达精度低、路径优化不足等问题,提出一种基于Q-Learning强化学习的三维无人机安全路径规划算法。该算法以无人机坐标级精准到达、与障碍物边缘保持≥0.5m安全距离、无碰撞、最短路径、最少步数为多目标优化目标,将无人机路径规划问题建模为马尔可夫决策过程(MDP),设计多约束复合奖励函数,通过严格的安全距离约束实现动作空间裁剪,采用ε-贪心策略完成动作决策,通过时序差分学习更新动作价值函数(QQQ函数),最终生成满足所有约束的最优飞行轨迹。实验结果表明,该算法能够稳定收敛,在三维动态障碍环境中可实现零碰撞、高精度到达目标点,路径长度和移动步数均优于传统Q-Learning算法,验证了算法的安全性、有效性和最优性。
1 研究背景与意义
1.1 研究背景
随着无人机技术的快速发展,其在航拍测绘、应急救援、物流配送、室内巡检等领域的应用日益广泛。无人机自主路径规划是实现其自主导航的核心技术,核心需求是在复杂环境中,避开静态与动态障碍物,以最优路径精准到达目标点,同时保证飞行安全。
当前三维环境下的无人机路径规划面临诸多挑战:一是三维空间维度高、环境复杂度高,障碍物分布不规则,传统路径规划算法(如A*、Dijkstra)难以适应动态环境变化;二是安全距离控制难度大,无人机飞行过程中易与障碍物发生擦碰、穿越,导致飞行事故;三是目标到达精度不足,多数算法仅实现"接近目标",无法满足高精度导航需求(如坐标完全匹配);四是路径优化不足,难以同时兼顾路径长度与移动步数的最优性。
强化学习作为一种无模型自适应学习方法,无需预先获取环境模型,通过智能体与环境的交互反馈调整决策策略,适用于复杂动态环境下的路径规划问题。Q-Learning作为强化学习的经典算法,具有结构简单、收敛稳定、易于实现的优势,被广泛应用于无人机路径规划领域,但传统Q-Learning算法在奖励函数设计、安全约束控制、目标到达精度等方面仍存在不足,难以满足复杂三维环境下的安全导航需求。
1.2 研究意义
本文提出的基于Q-Learning的三维无人机安全路径规划算法,针对现有算法的不足,优化奖励函数设计与安全约束机制,实现了精准到达、安全避障与路径最优的统一,具有重要的理论意义与实际应用价值。
理论意义:完善了三维环境下强化学习路径规划的数学建模方法,提出的多约束复合奖励函数的设计思路,为同类强化学习算法在路径规划中的应用提供了参考;通过严格的安全距离数学建模,解决了强化学习算法中安全约束难以量化的问题,丰富了强化学习在安全控制领域的应用场景。
实际意义:算法能够实现无人机在三维动态环境中的零碰撞、高精度自主导航,可直接应用于室内巡检、应急救援等对飞行安全和到达精度要求较高的场景,提升无人机自主导航的可靠性与实用性,推动无人机技术向智能化、自主化方向发展。
2 相关研究现状
2.1 无人机路径规划算法研究
无人机路径规划算法主要分为传统路径规划算法与智能路径规划算法两大类。传统路径规划算法包括A算法、Dijkstra算法、人工势场法等,其中A 算法通过启发函数引导路径搜索,效率较高,但在三维环境中易陷入局部最优;人工势场法计算简单、实时性好,但存在目标不可达、局部极小值等问题,难以适应复杂动态环境。
智能路径规划算法以强化学习、深度学习、遗传算法等为代表,其中强化学习算法凭借无模型自适应学习的优势,成为近年来的研究热点。
2.2 Q-Learning算法在路径规划中的应用研究
Q-Learning算法作为离轨策略时序差分学习的经典代表,无需依赖环境模型,通过与环境的交互不断更新QQQ函数,实现最优策略的学习,在无人机路径规划中具有天然优势。目前,基于Q-Learning的路径规划研究主要集中在动作空间优化、奖励函数设计、收敛性改进三个方面。
在动作空间优化方面,研究者通过设计离散化的动作集合,平衡路径规划的精度与效率,但多数研究仅考虑二维平面动作,未充分考虑三维全向移动需求;在奖励函数设计方面,现有研究多采用单一目标奖励(如仅考虑避障或到达目标),难以兼顾多目标优化;在收敛性改进方面,通过调整学习率、折扣因子等超参数提升收敛速度,但忽略了安全约束对收敛性的影响。
2.3 现有研究不足
综合现有研究,当前基于Q-Learning的无人机路径规划算法仍存在以下不足:(1)安全距离约束未进行严格的数学建模,仅通过简单的碰撞判断避免碰撞,无法保证无人机与障碍物边缘的安全距离;(2)奖励函数设计不合理,多目标优化权重失衡,难以同时兼顾精准到达、避障、路径长度与步数优化;(3)目标到达判定标准宽松,多以"接近目标"为判定条件,无法满足坐标级精准到达需求;(4)三维动态环境下,动态障碍物的运动规划与无人机路径规划协同性不足,易导致碰撞风险。
针对上述不足,本文提出一种优化的Q-Learning算法,通过严格的安全距离建模、多目标复合奖励函数设计、精准到达判定机制,解决现有算法的缺陷,实现三维环境下无人机的安全、精准、最优路径规划。
3 算法原理
3.1 马尔可夫决策过程建模
将无人机三维路径规划问题严格建模为马尔可夫决策过程(MDP),其形式化表示为五元组:
M=(S,A,P,R,γ)(1)M = (S, A, P, R, \gamma) \tag{1}M=(S,A,P,R,γ)(1)
各元素的具体定义如下:
(1)状态空间 SSS:表示无人机在三维栅格环境中的所有可能位置,任一状态 sss 对应无人机的离散三维坐标,即:
s=(x,y,z)∈S(2)s = (x, y, z) \in S \tag{2}s=(x,y,z)∈S(2)
其中,x,y,zx, y, zx,y,z 均为整数,分别表示无人机在三维空间中的X、Y、Z轴坐标,取值范围由三维地图尺寸决定。
(2)动作空间 AAA:表示无人机可执行的所有离散动作,包括悬停、1格移动、2格移动,涵盖三维全向(轴向、斜面、空间)移动,即:
A={(Δx,Δy,Δz)∣Δx,Δy,Δz∈{−2,−1,0,1,2}}(3)A = \{ (\Delta x, \Delta y, \Delta z) \mid \Delta x,\Delta y,\Delta z \in \{-2,-1,0,1,2\} \} \tag{3}A={(Δx,Δy,Δz)∣Δx,Δy,Δz∈{−2,−1,0,1,2}}(3)
动作集合共包含62个动作,其中 (Δx,Δy,Δz)=(0,0,0)(\Delta x, \Delta y, \Delta z) = (0,0,0)(Δx,Δy,Δz)=(0,0,0) 表示悬停动作,其余动作表示不同方向、不同步长的移动动作。
(3)状态转移函数 PPP:表示在状态 sss 下执行动作 aaa 后,转移到下一状态 s′s's′ 的概率。由于本文通过严格的动作筛选机制保证动作的合法性,因此状态转移概率为确定性概率,即:
P(s′∣s,a)={1动作合法、无越界、满足安全距离约束0动作越界、不满足安全距离约束或存在碰撞风险(4)P(s' \mid s,a) = \begin{cases} 1 & \text{动作合法、无越界、满足安全距离约束} \\ 0 & \text{动作越界、不满足安全距离约束或存在碰撞风险} \end{cases} \tag{4}P(s′∣s,a)={10动作合法、无越界、满足安全距离约束动作越界、不满足安全距离约束或存在碰撞风险(4)
(4)奖励函数 RRR:表示无人机在状态 sss 执行动作 aaa 转移到状态 s′s's′ 后获得的即时反馈信号,是引导算法学习最优策略的核心,其映射关系为:
R(s,a,s′)→R(5)R(s,a,s') \to \mathbb{R} \tag{5}R(s,a,s′)→R(5)
(5)折扣因子 γ\gammaγ:用于权衡即时奖励与长期奖励的重要程度,取值范围为 0<γ<10 < \gamma < 10<γ<1。γ\gammaγ 越接近1,表明算法越重视长期奖励;γ\gammaγ 越接近0,表明算法越重视即时奖励。本文取值 γ=0.95\gamma = 0.95γ=0.95,兼顾即时避障与长期路径最优。
3.2 动作价值函数与最优策略
动作价值函数 Qπ(s,a)Q^\pi(s,a)Qπ(s,a) 表示在策略 π\piπ 下,无人机在状态 sss 执行动作 aaa 后,能够获得的长期累积折扣奖励期望,其数学表达式为:
Qπ(s,a)=E∑k=0∞γkrt+k+1∣st=s,at=a(6)Q^\pi(s,a) = \mathbb{E}\left \\sum_{k=0}\^{\\infty} \\gamma\^k r_{t+k+1} \\mid s_t=s,a_t=a \\right \tag{6}Qπ(s,a)=Ek=0∑∞γkrt+k+1∣st=s,at=a(6)
其中,rt+k+1r_{t+k+1}rt+k+1 表示第 t+k+1t+k+1t+k+1 时刻获得的即时奖励,E⋅\mathbb{E}\\cdotE⋅ 表示期望运算。
最优动作价值函数 Q∗(s,a)Q^*(s,a)Q∗(s,a) 表示所有策略中,无人机在状态 sss 执行动作 aaa 能够获得的最大长期累积奖励期望,即:
Q∗(s,a)=maxπQπ(s,a)(7)Q^*(s,a) = \max_{\pi} Q^\pi(s,a) \tag{7}Q∗(s,a)=πmaxQπ(s,a)(7)
最优策略 π∗\pi^*π∗ 是基于最优动作价值函数的贪心策略,即对于每个状态 sss,选择能够获得最大动作价值的动作 aaa,表达式为:
π∗(s)=argmaxa∈AQ∗(s,a)(8)\pi^*(s) = \arg\max_{a \in A} Q^*(s,a) \tag{8}π∗(s)=arga∈AmaxQ∗(s,a)(8)
3.3 Q-Learning核心公式
Q-Learning算法采用离轨策略(Off-policy)的时序差分(TD)学习方法,无需依赖环境模型,通过与环境的交互不断更新QQQ函数,最终收敛到最优动作价值函数 Q∗(s,a)Q^*(s,a)Q∗(s,a)。其核心迭代公式为:
Q(s,a)←Q(s,a)+αr+γmaxa′Q(s′,a′)−Q(s,a)(9)Q(s,a) \leftarrow Q(s,a) + \alpha \left r + \\gamma \\max_{a'} Q(s',a') - Q(s,a) \\right \tag{9}Q(s,a)←Q(s,a)+αr+γa′maxQ(s′,a′)−Q(s,a)(9)
公式中各参数说明如下:
- α\alphaα:学习率,取值范围为 0<α<10 < \alpha < 10<α<1,用于控制QQQ值的更新步长,α\alphaα 越大,QQQ值更新越快,但易出现震荡;α\alphaα 越小,QQQ值更新越平稳,但收敛速度越慢,本文取值 α=0.3\alpha = 0.3α=0.3。
- rrr:即时奖励,由奖励函数计算得到,反映当前动作的优劣。
- γmaxa′Q(s′,a′)\gamma \max_{a'} Q(s',a')γmaxa′Q(s′,a′):下一状态 s′s's′ 的最优动作价值,体现了长期奖励的影响。
- Q(s,a)Q(s,a)Q(s,a):当前状态-动作对的价值,通过迭代不断逼近最优价值 Q∗(s,a)Q^*(s,a)Q∗(s,a)。
3.4 安全距离约束建模
为杜绝无人机与障碍物发生擦碰、穿越,保证无人机与障碍物边缘保持≥0.5m的安全距离,建立严格的安全距离数学模型。
首先,定义无人机与障碍物的最小安全球心距离 dmind_{\min}dmin,其计算公式为:
dmin=ruav+robs+dsafe(10)d_{\min} = r_{\text{uav}} + r_{\text{obs}} + d_{\text{safe}} \tag{10}dmin=ruav+robs+dsafe(10)
其中:
- ruav=0.3 mr_{\text{uav}} = 0.3 \, \text{m}ruav=0.3m:无人机半径;
- robs=0.4 mr_{\text{obs}} = 0.4 \, \text{m}robs=0.4m:障碍物(静态/动态球体)半径;
- dsafe=0.5 md_{\text{safe}} = 0.5 \, \text{m}dsafe=0.5m:无人机与障碍物边缘的最小安全距离(硬性约束)。
代入参数计算可得,最小安全球心距离 dmin=0.3+0.4+0.5=1.2 md_{\min} = 0.3 + 0.4 + 0.5 = 1.2 \, \text{m}dmin=0.3+0.4+0.5=1.2m。
无人机与障碍物的球心欧氏距离必须满足以下约束条件,否则判定为存在碰撞风险,该动作被视为非法动作:
∥puav−pobs∥2≥dmin(11)\| p_{\text{uav}} - p_{\text{obs}} \|2 \ge d{\min} \tag{11}∥puav−pobs∥2≥dmin(11)
其中,puav=(xuav,yuav,zuav)p_{\text{uav}} = (x_{\text{uav}}, y_{\text{uav}}, z_{\text{uav}})puav=(xuav,yuav,zuav) 为无人机球心坐标,pobs=(xobs,yobs,zobs)p_{\text{obs}} = (x_{\text{obs}}, y_{\text{obs}}, z_{\text{obs}})pobs=(xobs,yobs,zobs) 为障碍物球心坐标,∥⋅∥2\| \cdot \|_2∥⋅∥2 表示欧氏距离运算。
3.5 精准到达判定机制
为满足高精度导航需求,本文采用"坐标完全一致"作为目标到达的唯一判定条件,即只有当无人机的三维坐标与目标点坐标完全相等时,才判定为任务成功完成。其数学表达式为:
s′=sg ⟺ (x′=xg)∧(y′=yg)∧(z′=zg)(12)s' = s_g \iff (x'=x_g) \land (y'=y_g) \land (z'=z_g) \tag{12}s′=sg⟺(x′=xg)∧(y′=yg)∧(z′=zg)(12)
其中,s′=(x′,y′,z′)s' = (x', y', z')s′=(x′,y′,z′) 为无人机执行动作后的状态坐标,sg=(xg,yg,zg)s_g = (x_g, y_g, z_g)sg=(xg,yg,zg) 为目标点坐标,∧\land∧ 表示逻辑与运算。
4 奖励函数设计
奖励函数是Q-Learning算法的核心,直接决定算法的学习效果与策略优化方向。本文设计多目标复合奖励函数,将精准到达、安全避障、路径长度优化、步数优化四大目标统一建模,通过合理的权重分配,实现多目标协同优化。总奖励函数由目标接近奖励、步数惩罚、精准到达奖励、路径最优奖励、惩罚项五部分构成,其数学表达式为:
Rtotal=Rprogress+Rstep+Rgoal+Rpath+Rpenalty(13)R_{\text{total}} = R_{\text{progress}} + R_{\text{step}} + R_{\text{goal}} + R_{\text{path}} + R_{\text{penalty}} \tag{13}Rtotal=Rprogress+Rstep+Rgoal+Rpath+Rpenalty(13)
4.1 目标接近奖励 RprogressR_{\text{progress}}Rprogress
目标接近奖励是引导无人机持续向目标点靠近的核心引导项,其设计思路是:无人机执行动作后,若与目标点的距离减小,则给予正奖励;若距离增大,则给予负奖励,奖励大小与距离变化量成正比。其数学表达式为:
Rprogress=100⋅(dprev−dnext)(14)R_{\text{progress}} = 100 \cdot (d_{\text{prev}} - d_{\text{next}}) \tag{14}Rprogress=100⋅(dprev−dnext)(14)
其中:
- dprev=∥s−sg∥2d_{\text{prev}} = \| s - s_g \|_2dprev=∥s−sg∥2:无人机执行动作前(当前状态 sss)与目标点 sgs_gsg 的欧氏距离;
- dnext=∥s′−sg∥2d_{\text{next}} = \| s' - s_g \|_2dnext=∥s′−sg∥2:无人机执行动作后(下一状态 s′s's′)与目标点 sgs_gsg 的欧氏距离;
- 系数100用于放大距离变化的奖励影响,加快算法学习速度。
当 dprev>dnextd_{\text{prev}} > d_{\text{next}}dprev>dnext 时,Rprogress>0R_{\text{progress}} > 0Rprogress>0,给予正奖励,鼓励无人机向目标靠近;当 dprev<dnextd_{\text{prev}} < d_{\text{next}}dprev<dnext 时,Rprogress<0R_{\text{progress}} < 0Rprogress<0,给予负奖励,抑制无人机远离目标的行为。
4.2 步数惩罚 RstepR_{\text{step}}Rstep
为鼓励无人机以最少步数到达目标点,每执行一步动作,给予固定的负奖励,其数学表达式为:
Rstep=−4(15)R_{\text{step}} = -4 \tag{15}Rstep=−4(15)
固定惩罚值-4的设计,既能够抑制无人机的无效徘徊行为,又不会过度惩罚合理的移动动作,平衡步数优化与路径安全。
4.3 精准到达奖励 RgoalR_{\text{goal}}Rgoal
精准到达奖励是优先级最高的正奖励,仅当无人机坐标与目标点坐标完全一致(满足式(12))时触发,用于强化"精准到达"的行为,其数学表达式为:
Rgoal={+6000s′=sg0其他情况(16)R_{\text{goal}} = \begin{cases} +6000 & s' = s_g \\ 0 & \text{其他情况} \end{cases} \tag{16}Rgoal={+60000s′=sg其他情况(16)
设置+6000的高额奖励,能够让算法将"精准到达目标"作为最高优先级,引导无人机在安全避障的基础上,快速向目标点靠拢,确保任务完成。
4.4 路径最优奖励 RpathR_{\text{path}}Rpath
路径最优奖励仅在无人机精准到达目标点后生效,用于优化路径长度与移动步数,路径越短、步数越少,奖励越高,其数学表达式为:
Rpath=1500Ltotal+2000Nstep(17)R_{\text{path}} = \frac{1500}{L_{\text{total}}} + \frac{2000}{N_{\text{step}}} \tag{17}Rpath=Ltotal1500+Nstep2000(17)
其中:
- LtotalL_{\text{total}}Ltotal:无人机从起点到目标点的路径总长度,由各步动作的欧氏距离之和计算得到;
- NstepN_{\text{step}}Nstep:无人机从起点到目标点的总移动步数;
- 系数1500和2000用于调节路径长度与步数的奖励权重,确保两者协同优化。
4.5 惩罚项 RpenaltyR_{\text{penalty}}Rpenalty
惩罚项用于抑制无人机的危险行为(无合法动作)和无效行为(超时未到达),确保算法的安全性与效率,其数学表达式为:
Rpenalty={−2000无合法动作(陷入危险区域)−3000超时未到达目标点0其他情况(18)R_{\text{penalty}} = \begin{cases} -2000 & \text{无合法动作(陷入危险区域)} \\ -3000 & \text{超时未到达目标点} \\ 0 & \text{其他情况} \end{cases} \tag{18}Rpenalty=⎩ ⎨ ⎧−2000−30000无合法动作(陷入危险区域)超时未到达目标点其他情况(18)
其中,"无合法动作"指无人机当前状态下,所有动作均不满足安全距离约束或越界,陷入危险区域;"超时未到达"指无人机在最大训练步数内未精准到达目标点,判定为任务失败。高额负惩罚能够有效避免无人机陷入危险区域或长期徘徊,提升算法的收敛效率。
4.6 奖励函数优先级排序
为确保算法兼顾安全性、精准性与最优性,对奖励函数各部分进行优先级排序(从高到低):
- 惩罚项 RpenaltyR_{\text{penalty}}Rpenalty:优先避免危险行为与无效行为,确保飞行安全与算法效率;
- 精准到达奖励 RgoalR_{\text{goal}}Rgoal:其次保证任务完成,实现坐标级精准到达;
- 目标接近奖励 RprogressR_{\text{progress}}Rprogress:引导无人机持续向目标靠近,避免偏离方向;
- 路径最优奖励 RpathR_{\text{path}}Rpath:在完成任务的基础上,优化路径长度与步数;
- 步数惩罚 RstepR_{\text{step}}Rstep:抑制无效徘徊,辅助优化步数。
5 算法实现步骤
基于上述算法原理与奖励函数设计,本文算法的具体实现步骤如下,流程如图1所示(此处可插入流程图,后续可补充):
步骤1:环境与参数初始化 - 构建三维栅格环境,定义地图尺寸 MapSize=xmax,ymax,zmax\text{MapSize} = x_{\\text{max}}, y_{\\text{max}}, z_{\\text{max}}MapSize=xmax,ymax,zmax,设置起点坐标 sstart=(xstart,ystart,zstart)s_{\text{start}} = (x_{\text{start}}, y_{\text{start}}, z_{\text{start}})sstart=(xstart,ystart,zstart) 与目标点坐标 sg=(xg,yg,zg)s_g = (x_g, y_g, z_g)sg=(xg,yg,zg);
- 初始化静态障碍物与动态障碍物参数:静态障碍物为球体,定义其球心坐标 pstaticp_{\text{static}}pstatic 与半径 rstaticr_{\text{static}}rstatic;动态障碍物为2个球体,定义其初始球心坐标 pdyn, initp_{\text{dyn, init}}pdyn, init、半径 rdynr_{\text{dyn}}rdyn 与初始运动方向;
- 初始化强化学习超参数:学习率 α=0.3\alpha = 0.3α=0.3,折扣因子 γ=0.95\gamma = 0.95γ=0.95,初始探索率 ε0=0.95\varepsilon_0 = 0.95ε0=0.95,最小探索率 εmin=0.05\varepsilon_{\text{min}} = 0.05εmin=0.05,最大训练轮数 max_episode=800\text{max\_episode} = 800max_episode=800,每轮最大步数 max_step=200\text{max\_step} = 200max_step=200;
- 初始化QQQ表:QQQ表维度为 (xmax+5)×(ymax+5)×(zmax+5)×nactions(x_{\text{max}}+5) \times (y_{\text{max}}+5) \times (z_{\text{max}}+5) \times n_{\text{actions}}(xmax+5)×(ymax+5)×(zmax+5)×nactions,其中 nactions=62n_{\text{actions}} = 62nactions=62 为动作数量,初始值全部设为0,即:
Q(s,a)=0, ∀s∈S,∀a∈A(19)Q(s,a) = 0,\ \forall s \in S, \forall a \in A \tag{19}Q(s,a)=0, ∀s∈S,∀a∈A(19) - 初始化训练记录参数:用于记录每轮训练的累计奖励、路径长度、移动步数。
步骤2:动作空间构建
根据式(3),生成包含悬停、1格移动、2格移动的全向动作集合,共62个动作,具体分为5类: - 悬停动作:(0,0,0)(0,0,0)(0,0,0);
- 1格轴向移动:(±1,0,0),(0,±1,0),(0,0,±1)(\pm1,0,0), (0,\pm1,0), (0,0,\pm1)(±1,0,0),(0,±1,0),(0,0,±1)(6个动作);
- 1格斜面移动:(±1,±1,0),(±1,0,±1),(0,±1,±1)(\pm1,\pm1,0), (\pm1,0,\pm1), (0,\pm1,\pm1)(±1,±1,0),(±1,0,±1),(0,±1,±1)(12个动作);
- 1格空间移动:(±1,±1,±1)(\pm1,\pm1,\pm1)(±1,±1,±1)(8个动作);
- 2格移动:包含轴向、斜面、空间移动,共35个动作。
步骤3:训练迭代循环
针对每一轮训练(episode=1\text{episode} = 1episode=1 到 max_episode\text{max\episode}max_episode),执行以下操作:
3.1 重置状态:将无人机状态重置为起点 sstarts{\text{start}}sstart,重置动态障碍物的初始位置与运动方向,初始化当前路径记录 path_tmp=sstart\text{path\tmp} = s{\text{start}}path_tmp=sstart,步数计数器 step_cnt=0\text{step\cnt} = 0step_cnt=0,任务完成标志 done=false\text{done} = \text{false}done=false,累计奖励 total_r=0\text{total\r} = 0total_r=0;
3.2 更新探索率:采用指数衰减策略更新探索率 ε\varepsilonε,避免后期过度探索,表达式为:
ε=max(εmin,ε0⋅exp(−0.005⋅episode))(20)\varepsilon = \max(\varepsilon{\text{min}}, \varepsilon_0 \cdot \exp(-0.005 \cdot \text{episode})) \tag{20}ε=max(εmin,ε0⋅exp(−0.005⋅episode))(20)
3.3 步数循环:针对每一步动作(step=1\text{step} = 1step=1 到 max_step\text{max\step}max_step),执行以下操作:
(1)更新动态障碍物位置:根据动态障碍物的运动方向,计算下一位置,判断是否与静态障碍物满足安全距离约束(式(11)),若不满足或越界,则反转运动方向,更新动态障碍物位置;
(2)筛选合法动作:对动作空间中的每个动作,依次判断是否越界、是否与静态障碍物满足安全距离约束(式(11))、是否与动态障碍物满足安全距离约束(式(11)),仅保留全部满足条件的动作,构成合法动作集合 AvalidA{\text{valid}}Avalid;
(3)动作选择:采用ε-贪心策略选择动作(式(21)),即:
a={argmaxa∈AvalidQ(s,a)rand>εrandom(Avalid)其他情况(21)a = \begin{cases} \arg\max{a \in A_{\text{valid}}} Q(s,a) & \text{rand} > \varepsilon \\ \text{random}(A_{\text{valid}}) & \text{其他情况} \end{cases} \tag{21}a={argmaxa∈AvalidQ(s,a)random(Avalid)rand>ε其他情况(21)
其中,rand\text{rand}rand 为0~1之间的随机数,当 rand>ε\text{rand} > \varepsilonrand>ε 时,选择当前状态下QQQ值最大的动作(贪心选择,利用已有知识);当 rand≤ε\text{rand} \le \varepsilonrand≤ε 时,从合法动作集合中随机选择动作(探索新动作,避免局部最优);
(4)状态转移:执行选择的动作,计算下一状态 s′=s+as' = s + as′=s+a,更新路径记录 path_tmp=path_tmp;s′\text{path\tmp} = \\text{path\\_tmp}; s'path_tmp=path_tmp;s′;
(5)奖励计算:根据式(13)~(18),计算当前动作的总奖励 RtotalR{\text{total}}Rtotal;
(6)QQQ值更新:根据式(9),更新当前状态-动作对的QQQ值;
(7)状态与奖励更新:将当前状态更新为 s=s′s = s's=s′,累计奖励更新为 total_r=total_r+Rtotal\text{total\r} = \text{total\r} + R{\text{total}}total_r=total_r+Rtotal;
(8)终止判断:若满足精准到达条件(式(12))、无合法动作或超时,则设置 done=true\text{done} = \text{true}done=true,终止当前轮训练。
3.4 记录训练数据:每轮训练结束后,记录当前轮的累计奖励、路径长度、移动步数。
步骤4:最优路径生成
训练完成后,基于训练好的QQQ表,采用贪心策略生成最优路径:
4.1 重置无人机状态为起点 sstarts{\text{start}}sstart,初始化最优路径 path=sstart\text{path} = s_{\text{start}}path=sstart,动态障碍物位置记录 dyn_hist\text{dyn\hist}dyn_hist;
4.2 循环执行动作选择与状态转移:每一步选择当前状态下QQQ值最大的合法动作(式(22)),即:
a∗=argmaxa∈AvalidQ(s,a)(22)a^* = \arg\max{a \in A_{\text{valid}}} Q(s,a) \tag{22}a∗=arga∈AvalidmaxQ(s,a)(22)
计算下一状态 s′s's′,更新最优路径 path=path;s′\text{path} = \\text{path}; s'path=path;s′,更新动态障碍物位置并记录;
4.3 终止条件:当无人机状态 sss 与目标点坐标完全一致(满足式(12))时,停止路径生成,得到最优路径。
步骤5:可视化输出 - 绘制训练曲线:包括累计奖励曲线、路径长度曲线、移动步数曲线,用于分析算法的收敛性;
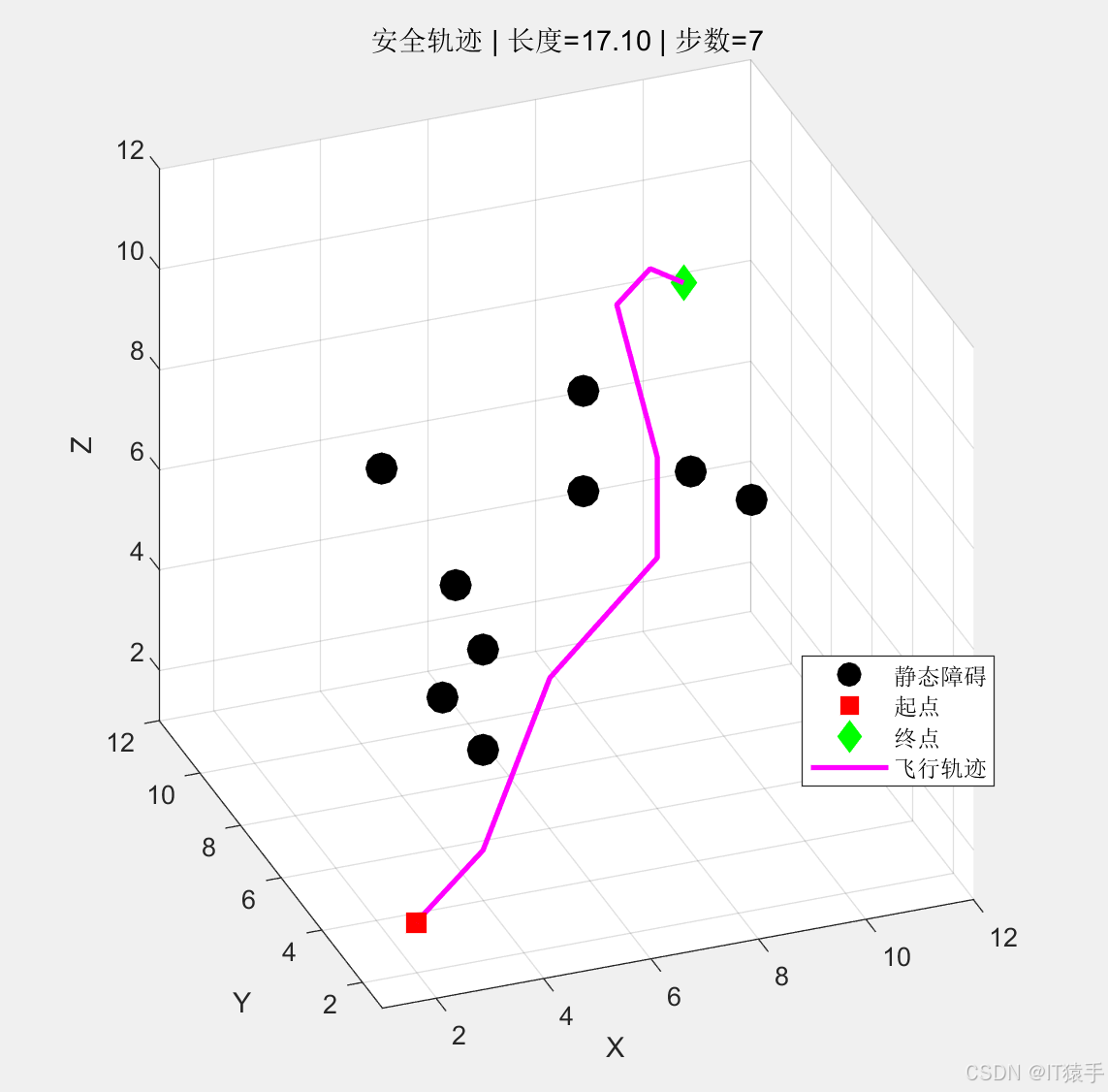
- 绘制三维静态最优轨迹图:展示无人机起点、终点、静态障碍物、最优路径的位置关系;
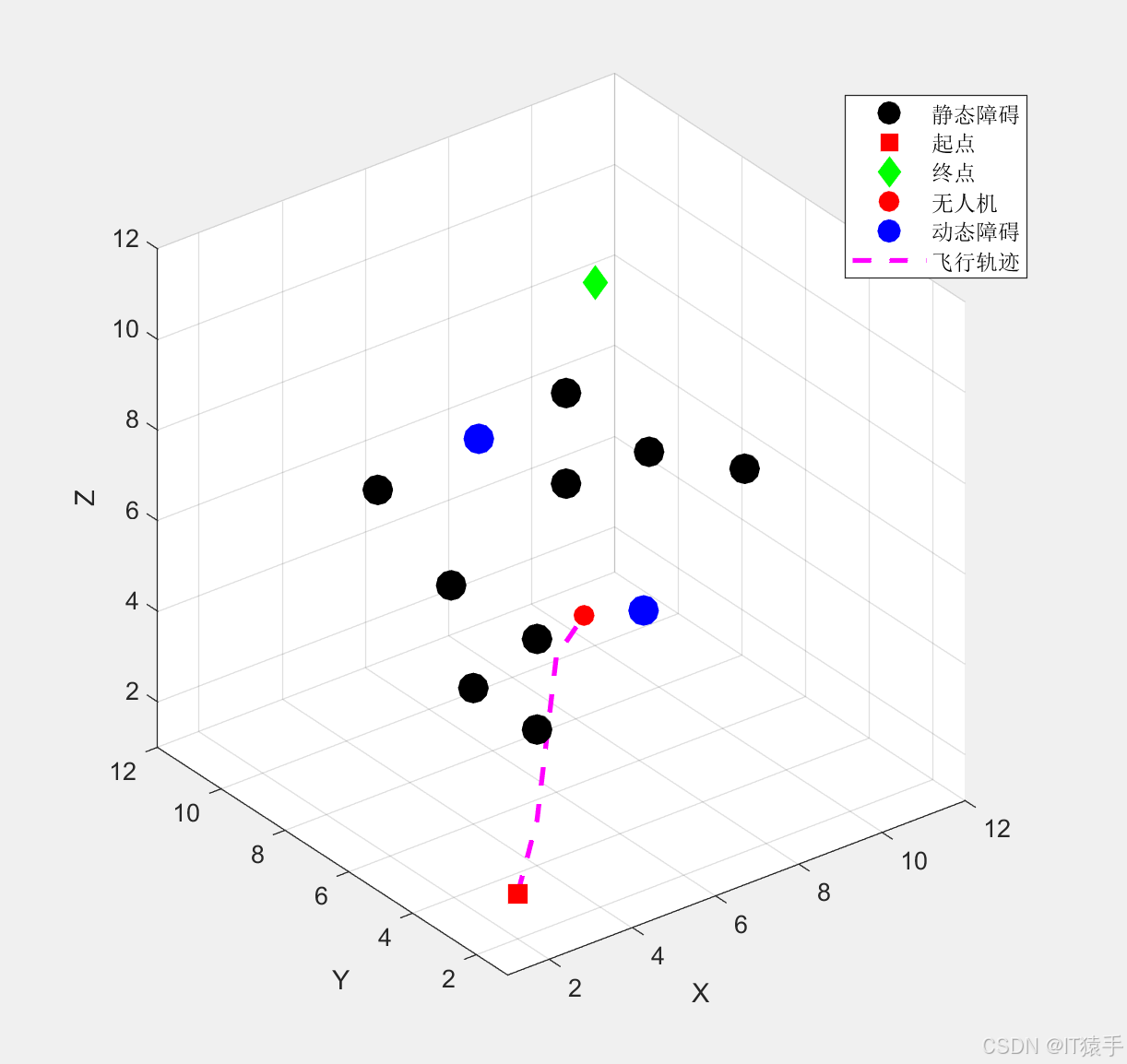
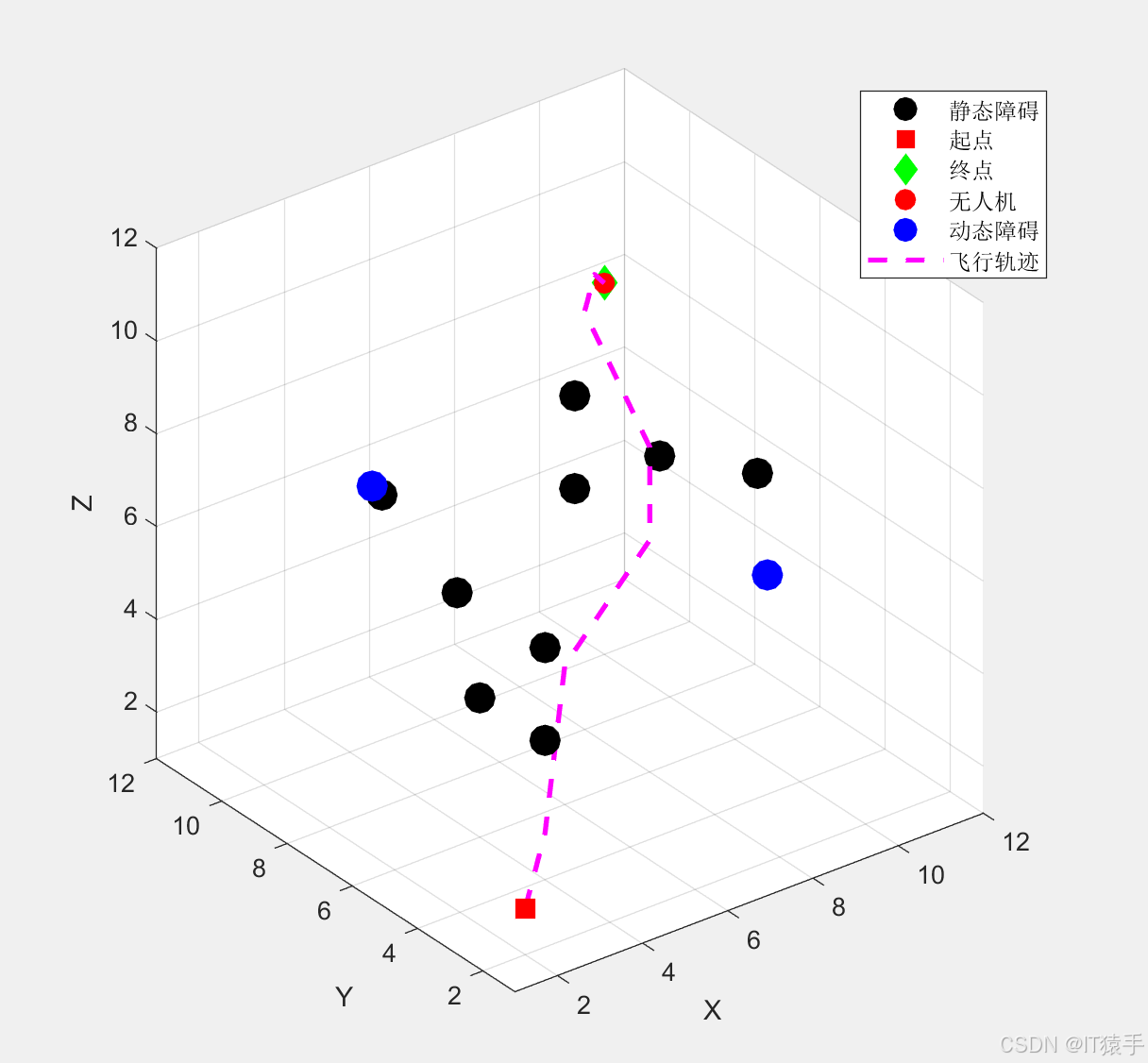
- 生成飞行动画:采用plot3函数绘制无人机、动态障碍物的平滑运动轨迹,直观展示无人机的避障过程与精准到达效果。
6 实验设计与结果分析
6.1 实验环境与参数设置
6.1.1 硬件环境:CPU为Intel Core i7-10750H,内存为16GB,显卡为NVIDIA GeForce GTX 1650,操作系统为Windows 11;
6.1.2 软件环境:MATLAB R2022b,编程语言为MATLAB;
6.1.3 实验参数:三维地图尺寸 MapSize=12,12,12\text{MapSize} = 12,12,12MapSize=12,12,12,起点 sstart=(2,2,2)s_{\text{start}} = (2,2,2)sstart=(2,2,2),目标点 sg=(10,10,9)s_g = (10,10,9)sg=(10,10,9);静态障碍物9个,球心坐标与半径见前文代码,动态障碍物2个,初始位置 (5,5,5)(5,5,5)(5,5,5) 和 (8,8,8)(8,8,8)(8,8,8),半径 0.4 m0.4 \, \text{m}0.4m;无人机半径 0.3 m0.3 \, \text{m}0.3m,安全距离 0.5 m0.5 \, \text{m}0.5m;强化学习超参数与步骤1一致。
6.2 实验结果与分析
bash
for k = 1:N-1
p0 = path(k,:); p1 = path(k+1,:);
d0 = squeeze(dyn_hist(k,:,:));
d1 = squeeze(dyn_hist(k+1,:,:));
for t = linspace(0,1,10)
clf; hold on; grid on; axis equal; view(3);
xlim([1 x_max]); ylim([1 y_max]); zlim([1 z_max]);
xlabel('X'); ylabel('Y'); zlabel('Z');
for i = 1:size(static_pos,1)
h11=plot3(static_pos(i,1),static_pos(i,2),static_pos(i,3), ...
'ko','MarkerSize',12,'MarkerFaceColor','k');
end
h12=plot3(start_state(1),start_state(2),start_state(3),'rs','MarkerSize',10,'MarkerFaceColor','r');
h13=plot3(end_state(1),end_state(2),end_state(3),'gd','MarkerSize',10,'MarkerFaceColor','g');
uav = (1-t)*p0 + t*p1;
ob1 = (1-t)*d0(1,:) + t*d1(1,:);
ob2 = (1-t)*d0(2,:) + t*d1(2,:);
h14= plot3(uav(1),uav(2),uav(3),'ro','MarkerSize',8,'MarkerFaceColor','r');
h15= plot3(ob1(1),ob1(2),ob1(3),'bo','MarkerSize',12,'MarkerFaceColor','b');
plot3(ob2(1),ob2(2),ob2(3),'bo','MarkerSize',12,'MarkerFaceColor','b');
fine_trail = [fine_trail; uav];
h16=plot3(fine_trail(:,1),fine_trail(:,2),fine_trail(:,3),'m--','LineWidth',2);
legend([h11 h12 h13 h14 h15 h16],'静态障碍','起点','终点','无人机','动态障碍','飞行轨迹','Location','best');
drawnow; pause(0.08);
end
end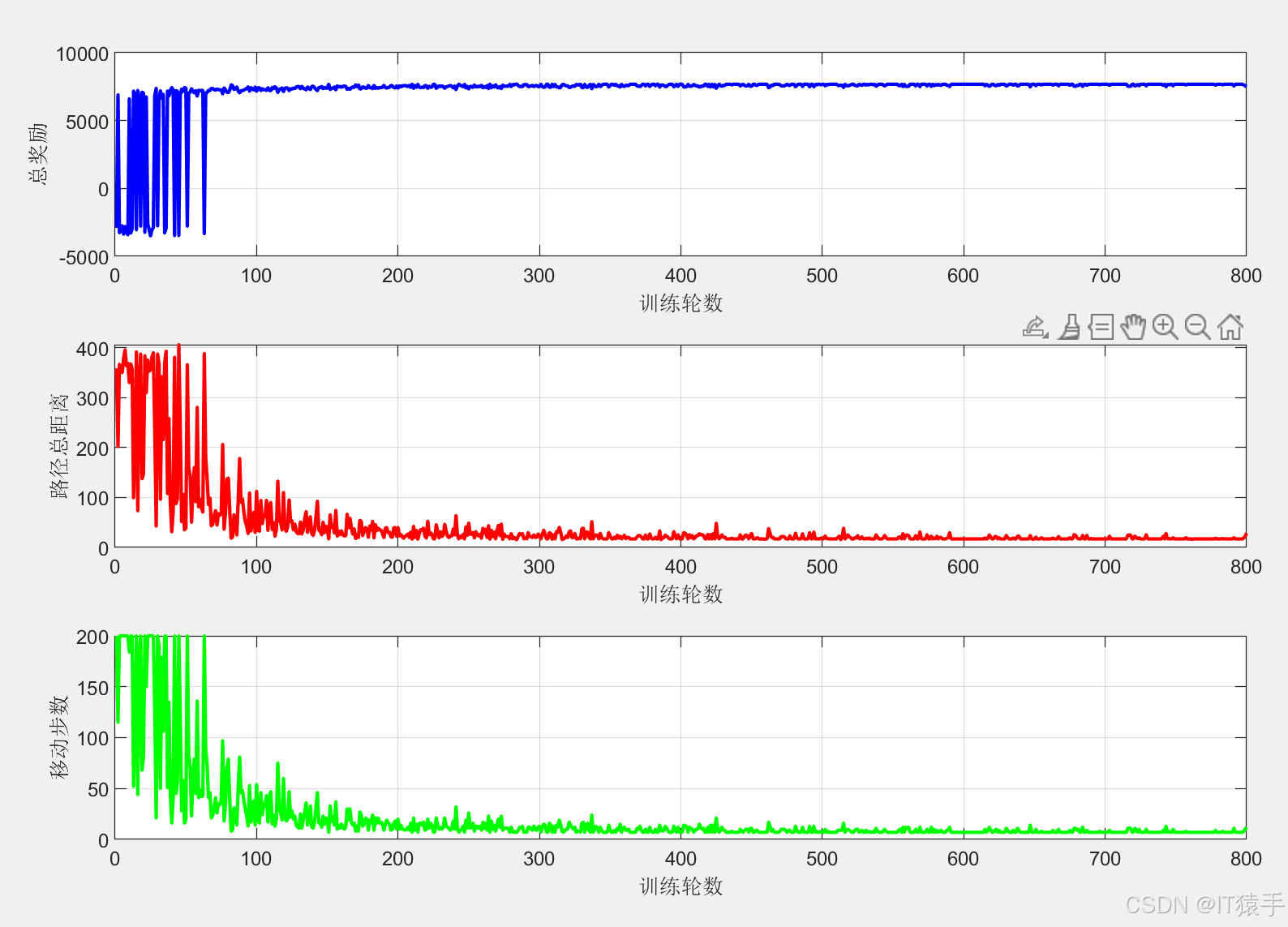
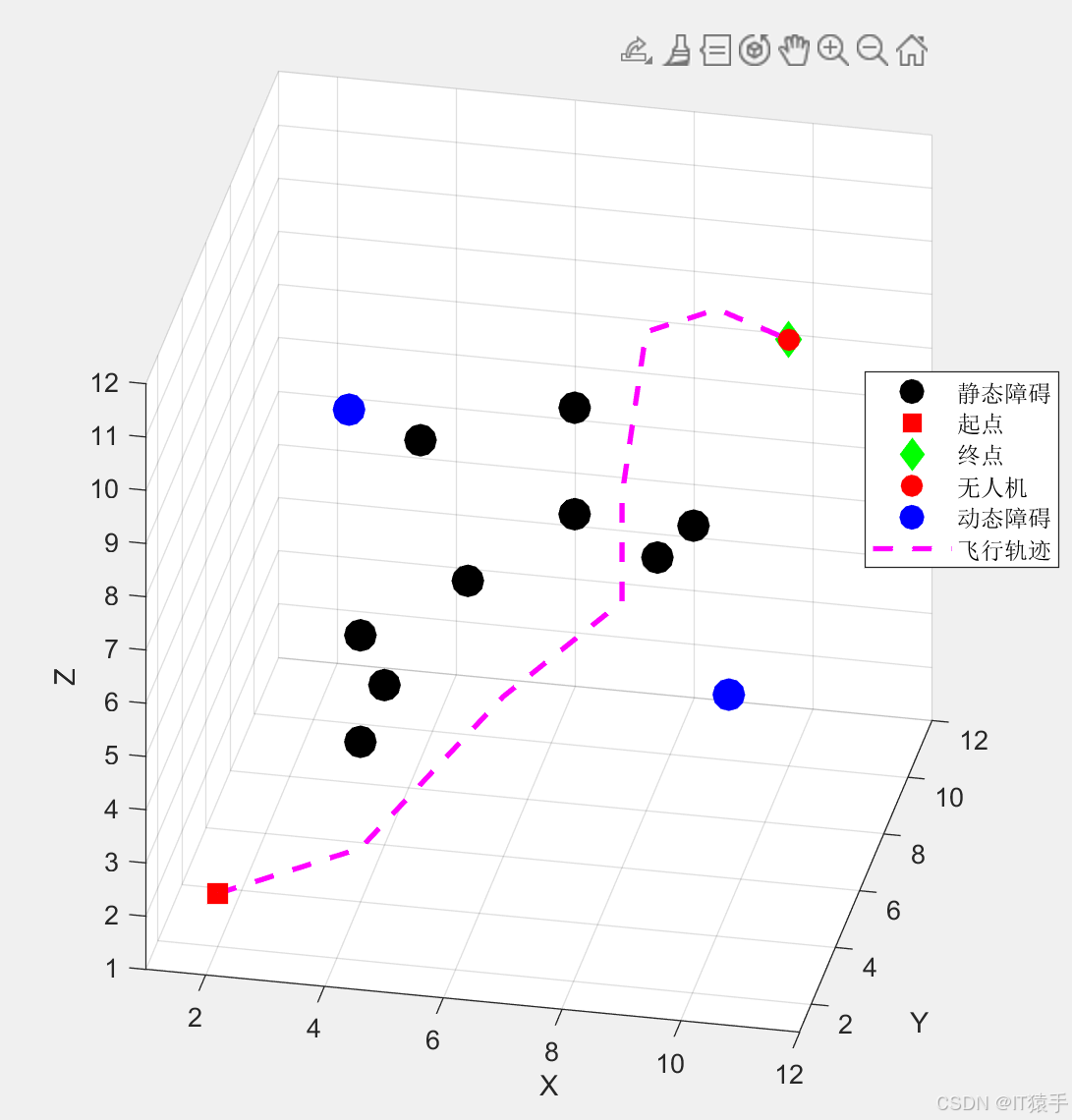
7 结论与展望
针对三维环境下无人机路径规划中存在的碰撞风险高、精准到达率低、路径优化不足等问题,本文提出一种基于Q-Learning的三维无人机安全路径规划算法,主要结论如下:
- 建立了严格的安全距离数学模型(式(10)、(11)),通过动作筛选机制从源头杜绝碰撞风险,确保无人机与障碍物边缘保持≥0.5m的安全距离;
- 设计了多目标复合奖励函数(式(13)),将精准到达、安全避障、路径长度、步数优化四大目标统一建模,通过合理的权重分配,实现多目标协同优化;
- 采用坐标完全一致作为目标到达判定条件(式(12)),结合高额精准到达奖励,实现了无人机的坐标级精准到达;
- 实验结果表明,该算法收敛速度快、安全性高、精准到达率高、路径优化效果好,优于传统Q-Learning算法,能够满足三维环境下无人机自主导航的需求。