文章目录
- 摘要
- Abstract
- [一、《LLaVA-Scissor: Token Compression with Semantic Connected Components for Video LLMs》](#一、《LLaVA-Scissor: Token Compression with Semantic Connected Components for Video LLMs》)
-
- [1. 摘要](#1. 摘要)
- [2. 介绍](#2. 介绍)
- [3. 相关工作](#3. 相关工作)
- [4. Llava-删除](#4. Llava-删除)
- [5. 实验](#5. 实验)
-
- [5.1 压缩类型](#5.1 压缩类型)
- [5.2 令牌压缩中的递减规律](#5.2 令牌压缩中的递减规律)
- [二、FastVLM: Efficient Vision Encoding for Vision Language Models](#二、FastVLM: Efficient Vision Encoding for Vision Language Models)
-
- [1. 摘要](#1. 摘要)
- [2. 介绍](#2. 介绍)
- [3. 结构](#3. 结构)
-
- [3.1 FastViT作为图像编码器](#3.1 FastViT作为图像编码器)
-
- [3.1.1 视觉编码器与语言解码器的协同作用](#3.1.1 视觉编码器与语言解码器的协同作用)
- [3.1.2 静态分辨率 vs. 动态分辨率](#3.1.2 静态分辨率 vs. 动态分辨率)
- [3.1.3 与Token剪枝/下采样方法的对比](#3.1.3 与Token剪枝/下采样方法的对比)
- [3.2 FastViTHD: 为高分辨率VLM量身定制的新编码器](#3.2 FastViTHD: 为高分辨率VLM量身定制的新编码器)
- [3.3 架构图](#3.3 架构图)
- [三、Question-Guided Visual Token Compression in MLLMs for Efficient VQA Qg-Vtc](#三、Question-Guided Visual Token Compression in MLLMs for Efficient VQA Qg-Vtc)
-
- [1. 摘要](#1. 摘要)
- [2. 介绍](#2. 介绍)
- [3. 相关工作](#3. 相关工作)
- [4. 方法](#4. 方法)
-
- [4.1 概述](#4.1 概述)
- [4.2 压缩模块](#4.2 压缩模块)
- [4.3 视觉编码器](#4.3 视觉编码器)
- [4.4 分层压缩策略:](#4.4 分层压缩策略:)
- [4.5 模型架构:](#4.5 模型架构:)
- [四、《Glyph Scaling Context Windows via Visual-Text Compression》](#四、《Glyph Scaling Context Windows via Visual-Text Compression》)
-
- [1. 摘要](#1. 摘要)
- [2. 介绍](#2. 介绍)
- [3. 相关工作](#3. 相关工作)
- [4. 方法](#4. 方法)
-
- [4.1 任务定义](#4.1 任务定义)
- [4.2 持续预训练(Continual Pre-training)](#4.2 持续预训练(Continual Pre-training))
- [4.3 LLM驱动的渲染搜索(LLM-Driven Rendering Search)](#4.3 LLM驱动的渲染搜索(LLM-Driven Rendering Search))
- [4.4 后训练(Post-Training):让模型"适应"压缩后的输入](#4.4 后训练(Post-Training):让模型“适应”压缩后的输入)
- [4.5 GLyph模型的流程](#4.5 GLyph模型的流程)
- 总结
摘要
本周主要阅读了视觉token压缩的四篇论文,压缩发方法为:语义感知合并,编码器优化和查询引导压缩。
其中《LLaVA-Scissor: Token Compression with Semantic Connected Components for Video LLMs》属于语义感知合并,即基于语义连通组件或对象级表征进行合并,符合人类视觉认知系统,减少幻觉。
《FastVLM: Efficient Vision Encoding for Vision Language Models》属于编码器优化,优化视觉编码器本身的效率 ,从源头减少token生成数量。
《Question-Guided Visual Token Compression in MLLMs for Efficient VQA Qg-Vtc》和《Glyph Scaling Context Windows via Visual-Text Compression》 属于查询引导压缩,利用用户指令/问题作为条件,引导压缩过程,同时保留任务相关关键信息,实现"按需压缩"。
Abstract
This week, I mainly read four papers on visual token compression. The compression methods covered include semantic-aware merging, encoder optimization, and query-guided compression.
Among them, 《LLaVA-Scissor: Token Compression with Semantic Connected Components for Video LLMs》 falls into semantic-aware merging. It performs token merging based on semantic connected components or object-level representations, which aligns with the human visual cognitive system and reduces hallucinations.
《FastVLM: Efficient Vision Encoding for Vision Language Models》 belongs to encoder optimization. It improves the efficiency of the vision encoder itself and reduces the number of generated tokens from the source.
《Question-Guided Visual Token Compression in MLLMs for Efficient VQA (Qg-Vtc)》and 《Glyph Scaling Context Windows via Visual-Text Compression》 are categorized as query-guided compression. These methods use user instructions or questions as conditions to guide the compression process, while preserving task-relevant key information to achieve "on-demand compression".
一、《LLaVA-Scissor: Token Compression with Semantic Connected Components for Video LLMs》
1. 摘要
本文提出了一种针对视频多模态大型语言模型设计的免训练token压缩策略LLaVA -删除。
以往的方法大多尝试基于注意力分数压缩标记,但未能有效捕获所有语义区域,往往导致标记冗余。
我们提出使用语义连接组件( SCC )的方法,将token分配到token集合中不同的语义区域,以确保全面的语义覆盖。结果是一个两步时空token压缩策略,在空间域和时间域都使用SCC。该策略通过用一组互不重叠的语义token来表示整个视频,可以有效地压缩token。
2. 介绍
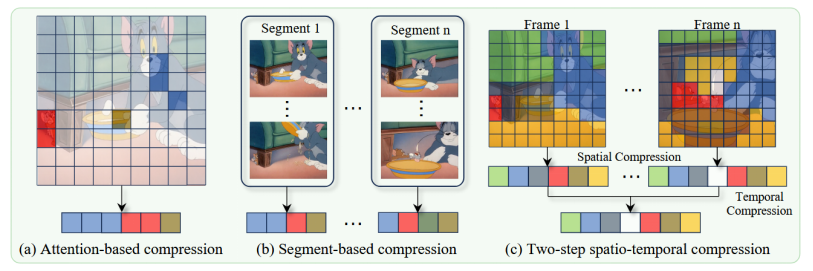
不同token压缩范式的说明。□(每个格子)表示视频token,颜色代表不同的语义。( a )基于注意力机制的方法不能覆盖所有的语义区域。( b )基于分段的方法通过叠加每个分段的token来引入时间冗余。( c )我们的两步时空压缩策略能够在每一帧中识别独特的语义信息,并消除时间冗余,从而产生不重叠的视频token。
论文主要贡献:
- 指出现有的基于注意力分数的方法不能完全表示整个token集,并提出了语义连接组件( SCC ),一种捕获token集中所有不同语义区域的token压缩策略。
- 提出了LLaVA -删除,一种为视频MLLMs设计的两步时空token压缩,可以生成更全面和有效的视频内容表示。实验表明,在各种视频理解基准上,LLaVA -删除优于其他token压缩方法。
3. 相关工作
介绍:
(1)视觉大语言模型,并且讲述当代视觉大语言模型存在的问题:处理长视频的计算效率不理想
(2)现存多模态大语言模型token压缩的方法存在的问题:忽略时间冗余以及语义相似的信息可能在时间上不相邻或空间上不一致的事实,导致在堆叠来自每个片段的标记时产生冗余,而LLaVA -删除在空间和时间上都执行token压缩
注:
(1)空间不一定一致:一辆飞驰的汽车,它可以从画面左侧到右侧,此时汽车对象不变,但是位置发生变化。
(2)传统的视频压缩方法存在一个隐含的错误假设:它们假设相同的东西会出现在固定的位置,或者时间上相邻的帧里内容变化不大,导致它们无法很好地处理物体的运动,最终会造成信息冗余(重复计算了没动的背景)或者信息丢失(漏掉了移动的物体)。
4. Llava-删除
语义连通组件(Semantic Connected Components, SCC)
核心思想:通过计算token之间的相似度,构建一个图结构,将token视为节点,相似度高于阈值则连边,然后找出图中的连通组件,每个组件代表一个独特的语义区域。
连通组件:类似连通图,内部任意两节点都可以相连,代价或多或少。由此可知,连通组件内部语义相同,每个组件代表一个独特语义区。
优势:
不依赖空间位置,能捕捉全局语义关系;
保证不同语义区域之间无重叠,语义覆盖更全面;
每个组件只保留一个代表性token,实现压缩。
两步时空压缩策略
(1)空间压缩
对每一帧单独应用SCC,提取该帧内所有独特的语义区域,得到每帧的代表性token集。
(2)时间压缩
将所有帧的代表性token拼接后,再次应用SCC,去除跨帧重复的语义信息,得到最终的非重叠语义token集。
(3)最终合并:
将原始所有token与最终代表性token进行相似度匹配,合并到最相似的语义组件中,得到最终的压缩token序列。
5. 实验
5.1 压缩类型
我们对LLaVA -删除的token压缩能力进行了广泛的评估,包括视频问答、长视频理解和综合多选题等多个视频理解基准。实验结果表明,本文提出的LLaVA -删除优于其他token压缩方法,在各种视频理解基准中取得了优异的性能,尤其是在低token保持率下。
视频问答

长视频理解
综合多选题
主要实验方法:消融实验(控制变量法)

实验相关参数:
分析相似度阈值 τ对压缩后令牌数量的影响:τ 越低,压缩越强,令牌数减少。
分析误差容忍度 ϵ 对连通组件计算的影响:ϵ≤0.05时组件数趋于稳定,因此设为0.05。
5.2 令牌压缩中的递减规律
- 冗余性验证:在保留比例从90%降至35%时,多数方法性能与原模型接近,甚至均匀采样也仅小幅下降,说明视频令牌存在大量冗余。
保留比例:整个视频经过压缩后,最终保留下来的令牌总数,占原始输入令牌总数的百分比。 - 语义损失分析:当保留比例低于35%(如10%、3%),所有方法性能急剧下降,但LLaVA-Scissor的下降幅度最小。例如在3%保留时,LLaVA-Scissor仍保持86.8%的原始性能,比FastV高出6.1%,证明其能更好地保留关键语义。
二、FastVLM: Efficient Vision Encoding for Vision Language Models
1. 摘要
对图像分辨率、视觉编码延迟、视觉token数量以及大语言模型大小之间的相互影响进行了全面的效率分析,并在此基础上提出了FastVLM。
该模型的核心是一个名为FastViTHD的新型混合视觉编码器,它专为高分辨率图像设计,能够输出更少的视觉token,并显著缩短编码时间。
FastVLM通过直接缩放输入图像,就能在视觉token数量与图像分辨率之间达到最佳平衡,无需额外的token剪枝,简化了模型设计。
性能表现:在LLaVA-1.5的设置下,与之前的工作相比,FastVLM在保持相似性能的同时,将首 token 生成时间(TTFT) 提升了3.2倍。与最高分辨率下的LLaVA-OneVision相比,在使用相同的0.5B LLM时,FastVLM在关键基准测试上取得了更好的性能,且TTFT提升了85倍,视觉编码器尺寸缩小了3.4倍。
2. 介绍
现存的问题:
1,高分辨率图像导致视觉 token 数量激增,增加 LLM 预填充时间;
2,视觉编码器本身在高分辨率下延迟高;
3,现有方法虽然提升分辨率,但引入额外延迟和语义断裂。
主要贡献
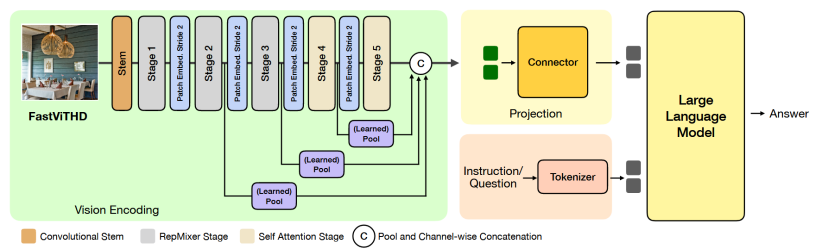
(1)提出FastViTHD视觉编码器:
混合架构(卷积 + Transformer),通过额外的下采样阶段,生成更少的视觉token,显著降低LLM预填充时间。
(2)系统性分析VLM的精度-延迟权衡:
综合考虑视觉编码延迟 + LLM预填充时间,在实际硬件上进行基准测试。提出Pareto最优曲线,指导不同LLM大小与分辨率的组合选择。
(3)多尺度特征融合与训练策略优化:
引入多阶段训练(Stage 1: 投影层训练;Stage 1.5: 分辨率适应;Stage 2: 指令微调;Stage 3: 高质量指令微调)。
使用深度可分离卷积(DWConv)融合多尺度特征,提升性能。
(4)显著的效率提升:
在多个VLM基准上表现更优
3. 结构
首先探索采用FastViT混合视觉编码器进行视觉语言建模。
然后,我们引入架构干预来提高VLM任务的表现。本文提出了一种新的混合视觉编码器Fast Vi THD,用于实现高效的高分辨率VLM。
3.1 FastViT作为图像编码器
核心发现1:混合架构是天然的"好苗子"。FastViT(一种混合了卷积和Transformer的架构)作为视觉编码器
优势:
1,分辨率可扩展:其卷积组件使其能很好地适应不同分辨率的输入
2,Token效率高:由于卷积的下采样特性,在相同输入分辨率下,它生成的token数量远少于ViT。
3,在 768 分辨率下,性能优于 ViT-L/14 在 336 分辨率的表现。
核心发现2:多尺度特征融合能"再加分"
1,提取不同阶段的特征:
2,使用深度可分离卷积(DWConv)进行融合,可以补充最后层的高层语义特征,提升性能。
小结: 一个设计良好的混合架构(FastViT)在VLM任务中,相比传统的ViT,已经展现出了显著的"速度-性能"优势。通过简单的多尺度融合,还能再进一步提升。
3.1.1 视觉编码器与语言解码器的协同作用
VLM中的精度-延迟权衡受到多种因素的影响。一方面,VLM的整体性能取决于( 1 )输入图像的分辨率,( 2 )视觉令牌的数量和质量,( 3 ) LLM的性能。
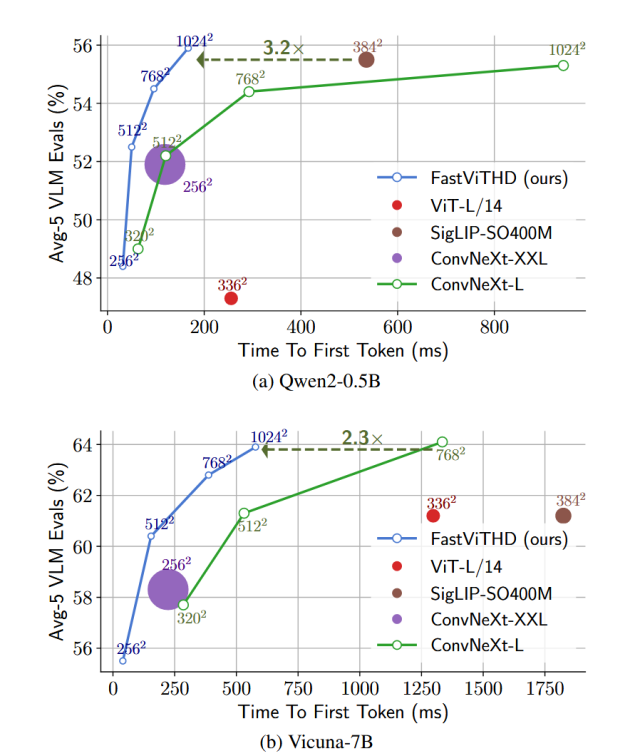
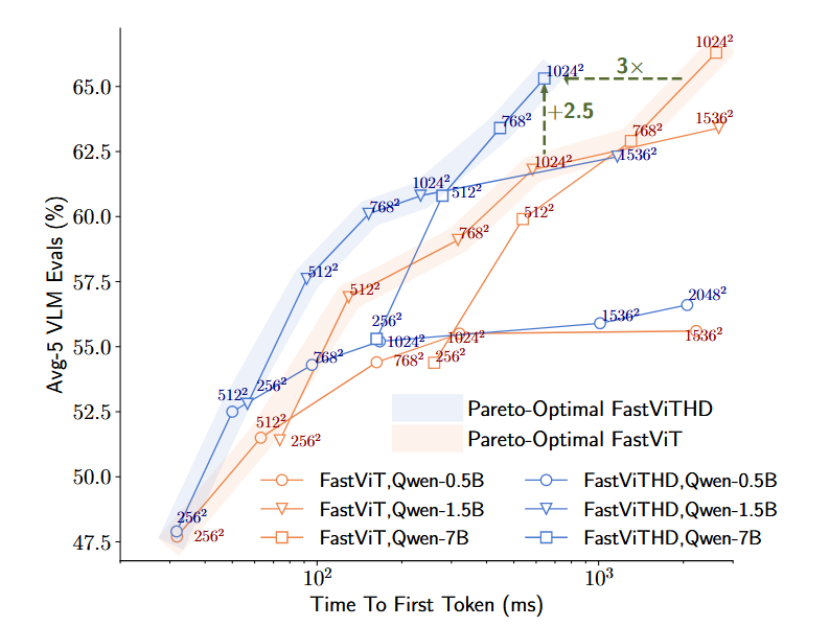
实验将FastViT和FastViTHD分别与三种不同大小的LLM (Qwen2-0.5B/1.5B/7B) 和多种分辨率配对,绘制出每个视觉编码器的Pareto最优曲线
结论:
1,FastViTHD全方面优于FastViT
2,揭示了最优搭配规律:例如,曲线显示,对于小LLM,一味提高分辨率收益不大,因为视觉编码延迟会占主导(图5也佐证了这一点)。FastViTHD为不同LLM找到了最佳的分辨率"甜点"。
3.1.2 静态分辨率 vs. 动态分辨率
静态分辨率:模型只接受一种固定尺寸的输入。无论你给的原始图片有多大或多小,模型都会通过缩放(Resize)的方式,把它变成这个固定的尺寸再进行处理。
动态分辨率:根据输入图像的原始尺寸和长宽比,动态地调整处理方式,最常见的就是我们之前聊过的瓦片推理
瓦片推理:切割,编码,拼接。将图片切成多个大小相同的小块(瓦片),将每个瓦片分别送入视觉编码器(将编码器的分辨率设置为瓦片大小)进行处理,最后,模型会将这些瓦片产生的视觉token按照原来的位置拼接起来,形成对整张图的理解,供LLM使用。
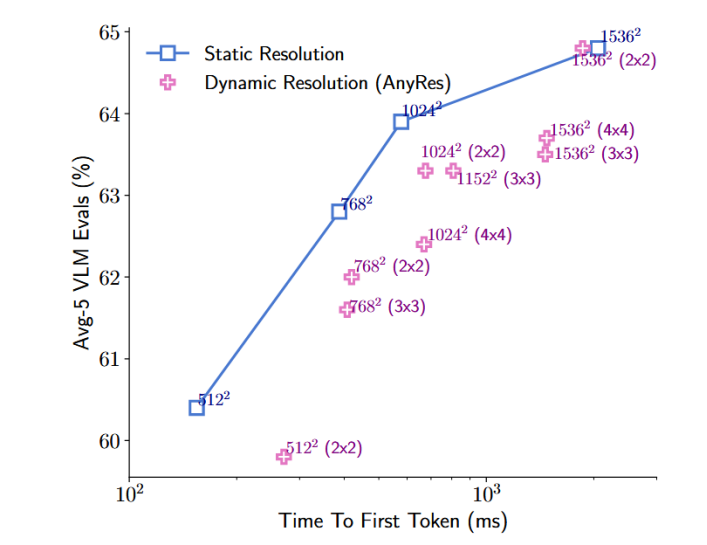
结论:直接将模型的输入分辨率设置为期望分辨率可以提供最好的精度-延迟平衡。 如果需要动态分辨率,使用更少的瓦片设置会表现出更好的精度-延迟权衡。
3.1.3 与Token剪枝/下采样方法的对比
FastViTHD减少token的方式(架构性下采样),与近年来流行的"先多生成token再剪枝"的方法相比,孰优孰劣?
结论:
1,架构性下采样完胜:FastViTHD通过训练在低分辨率下取得的性能,就已经超过了绝大多数剪枝方法在高分辨率下的性能。
2,"少而精"优于"多而剪":与其先生成大量token再费力剪枝,不如从一开始就通过精心设计的架构生成高质量、低数量的token。
3.2 FastViTHD: 为高分辨率VLM量身定制的新编码器
设计目标:更低延迟 + 更少 token;
核心设计1:极致地下采样,生成极少的Token
思路:VLM的延迟由"视觉编码延迟"和"LLM预填充延迟"两部分组成。FastViTHD的设计目标是同时降低这两者。
降低视觉编码延迟:通过高效的卷积和优化的架构设计实现。
降低LLM预填充延迟:通过生成更少的视觉token实现。
创新点:
增加一个下采样阶段:通常有4个阶段,总下采样倍率为16。FastViTHD引入了第5个阶段,将总下采样倍率提升到了64
下采样阶段:

核心设计2:混合阶段,各司其职

3.3 架构图
三、Question-Guided Visual Token Compression in MLLMs for Efficient VQA Qg-Vtc
1. 摘要
多模态大预言模型视觉问答任务中 集成视觉信息增加了处理令牌的数量,导致更高的GPU内存使用量和计算开销。图像较文本有更多冗余,并且并非所有细节为有效信息。
方法介绍:
QG - VTC,一种新颖的问题引导视觉令牌压缩方法,用于基于MLLM的视觉问答任务。
QG - VTC使用一个预训练的文本编码器和一个可学习的前馈层将用户问题嵌入到视觉编码器的特征空间中,然后计算问题嵌入和视觉令牌之间的相关性得分,最后,通过选择最相关的令牌并对其他令牌进行软压缩。
优势
该方法仅使用1 / 8的视觉令牌就可以达到与未压缩模型相当的性能,并且保证了与用户需求的微调相关性。
2. 介绍
本文的贡献总结如下:
- 提出了一种问题引导的视觉令牌压缩方法QG - VTC。它根据用户的问题选择性地保留最相关的视觉令牌,并使用加权平均的方法合并相关性较低的视觉令牌。该方法在尽可能减少图像信息损失的情况下大幅减少了令牌数量。
- 我们的方法使用分层策略将问题引导的视觉令牌压缩模块集成到视觉编码器中。该方法在保留局部图像细节的同时利用了深层的、语义丰富的信息,减少了LLM和视觉编码器本身的计算负荷。
- 通过大量实验,我们在多个基准上获得了最先进SOTA(State-Of-The-Art)结果。值得注意的是,我们仅用1 / 8的视觉令牌和大约30 %的原始计算负载来匹配性能。
3. 相关工作
对现有压缩方法进行介绍,得出现有方法的局限性。同时,较现有方法QG-VTC的优势在于:
1,问题引导:QG-VTC是第一个在视觉编码器内部引入用户问题作为压缩依据的方法。
2,压缩位置:QG-VTC实现了视觉编码器内部的分层压缩,从而在减少LLM负担的同时,也大幅降低了视觉编码器自身的计算量。
3,软压缩机制:相比于直接剪枝,QG-VTC采用注意力分数加权的软回收方式,进一步减少了信息丢失。
软回收:把不太相关图片的残余有用信息融合到保留的标记中
4. 方法
4.1 概述
QG - VTC,它通过基于用户问题的分层压缩方法来减少视觉编码器中的视觉令牌。方法本质上是利用用户问题的特征向量,在视觉编码器的多层中动态筛选出最相关的视觉标记,并将其他低相关标记的有效信息融合到这些保留的标记中,从而实现精细化的压缩。通过这种多次的、精细的筛选与融合,最终只留下一小部分与问题高度相关的视觉标记,同时最大程度地避免了重要信息的丢失
4.2 压缩模块
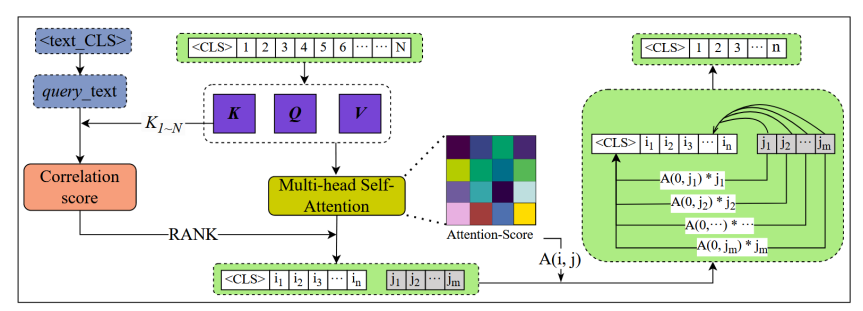
在具体的Transformer层内部,QG-VTC是如何利用用户问题来减少视觉令牌数量的。
流程:
1,输入:视觉token与文本查询
2,自注意力计算:计算每个视觉token对其他所有token的关注程度,得到注意力分数矩阵A
3,计算问题与视觉token的相关性:得到相关性分数C
4,划分token:根据相关性分数C对所有视觉token进行划分
保留组:令牌(总是保留)加上 C 分数最高的前 n 个视觉令牌。
压缩组:剩下的 m 个相关性最低的视觉令牌。
5,软压缩:
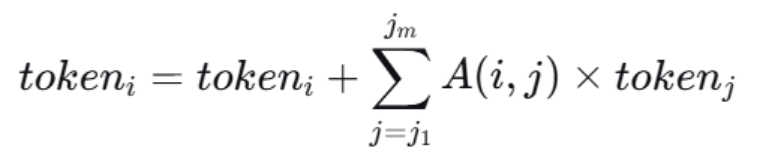
公式说明:
对于保留组中的某个令牌i,它要从压缩组的每个令牌j 那里回收一部分信息,回收的权重就是原来令牌i对令牌j的注意力大小 A(i,j)A(i,j)。这样,即便某个图像块整体上与问题不相关,它包含的少量有用细节(比如背景颜色)也能通过注意力机制被补充到关键区域去。
6,输出:保留组的n + =n+1 个token
4.3 视觉编码器
压缩位置的选择:浅层与深层
4.4 分层压缩策略:
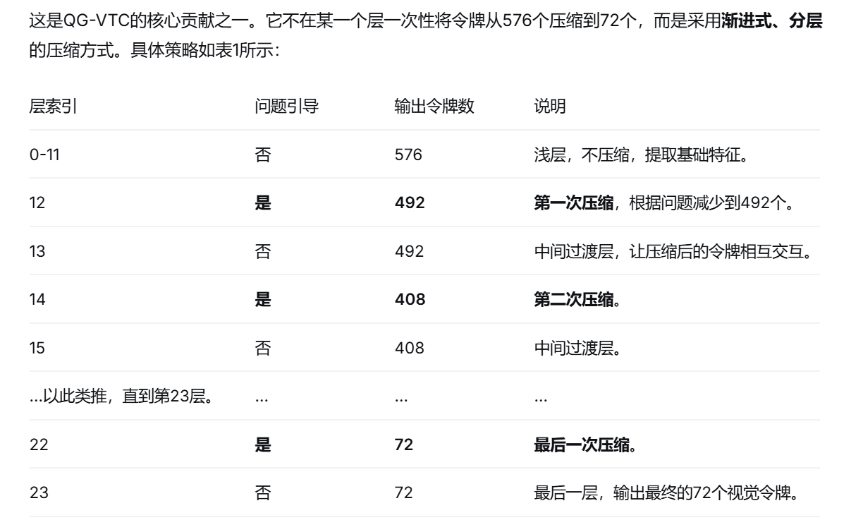
策略优势如下:
1,压缩平滑:避免了一次性大幅压缩带来的信息断崖式丢失。
2,信息交互:在两个压缩层之间插入一个普通层(如13层),让被压缩和融合后的新令牌有机会再次进行全局交互,为下一轮更精细的筛选做准备。
3,减少编码器负担:由于在编码器的中间层就开始减少令牌数量,后续层的计算量(特别是自注意力的二次计算部分)会显著下降,从而节省了视觉编码器自身的计算资源
4.5 模型架构:
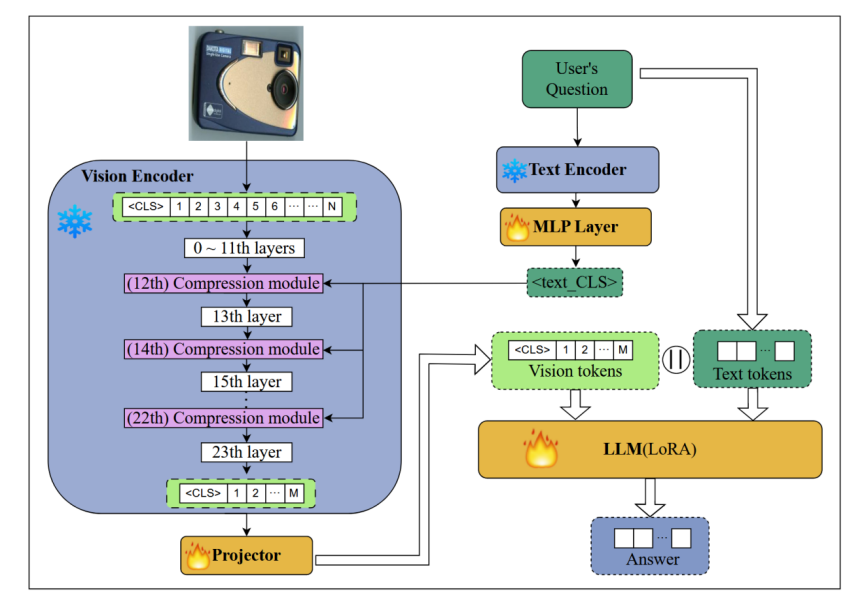
模型的计算细节:
四、《Glyph Scaling Context Windows via Visual-Text Compression》
1. 摘要
Glyph框架将长文本渲染成图像,并使用视觉语言模型( VLMs )对其进行处理。 该方法在保留语义信息的同时大幅压缩了文本输入,我们设计了一个LLM驱动的遗传搜索来确定最佳的视觉渲染配置,以平衡精度和压缩。
通过大量的实验证明了该方法实现了3 - 4倍的令牌压缩,同时保持了精度。这种压缩也导致大约4 ×快的预填充和解码,以及大约2 ×快的SFT训练。
2. 介绍
主要贡献
1,新范式提出:首次系统性地将视觉压缩引入长上下文建模
2,自动渲染搜索:设计了LLM驱动的遗传搜索算法,自动找到最优渲染配置,兼顾压缩与性能。
3,显著的效率提升:压缩比达 3-4倍;预填充速度提升 4.8倍,解码速度提升 4.4倍;SFT训练速度提升约 2倍
4,跨模态泛化能力:即使训练数据以渲染文本为主,Glyph在实际文档理解任务中仍表现优异
3. 相关工作
1,长上下文建模
通过对注意力,位置编码插值等进行改进(如优化数据,微调来扩展模型上下文窗口),降低长序列的计算复杂度。
方法局限性:并未减少输入Token数量
2,多模态大语言模型
关注多模态(视觉-语言)模型的发展:由早期注重将视觉信息和语言模型进行结合,到提升提升编码能力,使模型具备信息压缩潜力(OCR,一个token可以承载多个文字)
4. 方法
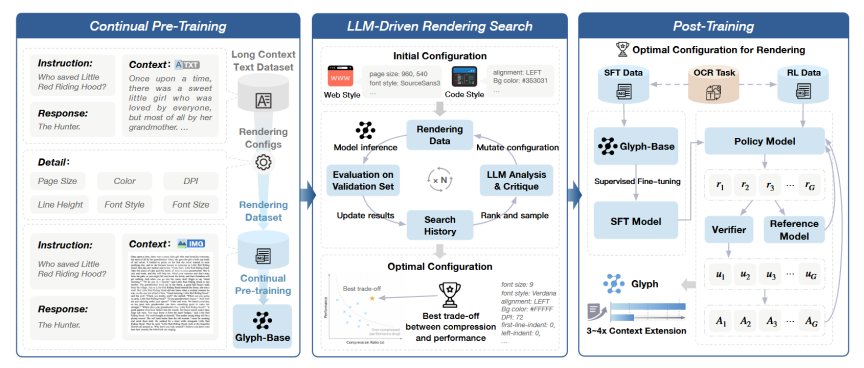
Glyph包括3个主要阶段:对渲染的长文本数据进行持续的预训练;LLM驱动的遗传搜索最优渲染配置;以及使用SFT、RL进行后训练。这些阶段共同实现了高效的长上下文建模和视觉-文本压缩。
4.1 任务定义
任务形式转变:

由于上下文太长,因此直接转变为页面图片进行理解C--->V,此时原本三元组变为:

目标变为:
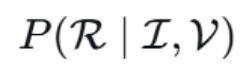
渲染管道
文本排版样式和视觉密度由【分辨率,页面尺寸,字体样式,字体大小,缩进方式...等】参数决定,渲染过程由配置向量θ控制
压缩比

θ 的选择直接影响信息密度(通过字体大小、dpi)和视觉清晰度(通过布局、间距),从而在压缩率与模型可读性之间取得平衡。
4.2 持续预训练(Continual Pre-training)
将大量长文本渲染为多种风格的图像(如文档风格、网页风格、代码风格等),训练VLM理解这些"视觉文本",使图片与原文本语义对齐。
-
数据构建
多样化的渲染配置:将文本渲染成多种图片样式,避免风格单一
排除不合理配置:如行高小于字体大小等无效组合
预定义风格主题:
-
包含三类任务:
三类任务联合训练,使模型具备在视觉压缩上下文下的阅读、推理和生成能力
(1)OCR任务:从图像中重构文本;
(2)交错语言建模:部分文本渲染为图片,剩余仍为文本;
(3)生成任务:根据部分图像,模型补全缺失内容。
4.3 LLM驱动的渲染搜索(LLM-Driven Rendering Search)
虽然预训练使用多种渲染样式,但是下游任务仍具有特定偏好,因此使用遗传算法搜索最优的渲染参数θ,以在压缩率与模型性能之间取得最佳平衡。
- 遗传算法流程
1,初始化种群:从预训练使用的渲染配置中随机采样一批候选配置 。
2,渲染验证集:用每个候选配置将验证集(一组长文本)渲染成图像。
3,评估:使用当前模型(Glyph-Base)对渲染后的数据进行推理,记录每个配置下的任务准确率和压缩比。
4,LLM分析与建议:利用一个强大的LLM分析当前种群配置与性能的关系,提出有价值的变异和交叉策略,生成新一代候选配置。
5,记录与选择:将所有配置及其性能记录在搜索历史中,根据性能排名采样优秀配置进入下一次遗传算法。
算法迭代进行,直到种群收敛(连续若干代无明显性能提升)。最终得到最优配置 θ 。这种LLM驱动的搜索能自动平衡压缩率和模型性能,比人工或随机调参更高效。
4.4 后训练(Post-Training):让模型"适应"压缩后的输入
确定θ后,此时模型已经看得懂图像,进一步优化,使模型能够在图像上完成文本任务。
包含三种优化方式:
(1)监督微调(SFT):教会模型"怎么答",让模型从"会读"变成"会答"
使用最优渲染配置θ生成训练数据,并引入"思考式"推理格式(如 ...),让训练模型学会输入图像 经过推理得到 输出答案的映射。
(2)强化学习(RL):教会模型"答得更好"
SFT数据中不一定包含最优回答;模型可能答对了但推理过程混乱,或格式不符合要求。
用强化学习直接优化最终答案质量。采用GRPO算法让模型自己生成多个候选答案,用外部LLM评分(准确率)+格式奖励,告诉模型什么样的答案更好。
(3)辅助OCR对齐任务:让模型"看得清"压缩后的字,而不是"猜"字
增强模型对图像中文字的识别能力,防止模型在追求压缩时牺牲文字识别精度。
4.5 GLyph模型的流程

总结
四篇论文均聚焦多模态模型的token 压缩,从不同维度提升效率:
LLaVA-Scissor:面向视频 LLM,提出免训练的语义连通分量(SCC) 时空两步压缩,先单帧空间语义聚类,再跨帧去时间冗余,保留完整语义。
FastVLM:提出FastViTHD混合视觉编码器,以卷积 + Transformer 架构级下采样,减少高分辨率图像 token 与编码延迟,无需额外剪枝,推理速度提升 3.2 倍。
Qg-VTC:针对 VQA,问题引导压缩,用文本编码器嵌入问题,筛选与问题相关的视觉 token,降低无关信息开销。
Glyph:创新视觉 - 文本压缩,将长文本渲染为图像用 VLM 处理,配合 LLM 驱动的遗传搜索优化渲染,实现 3--4 倍 token 压缩,扩展上下文窗口。