博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
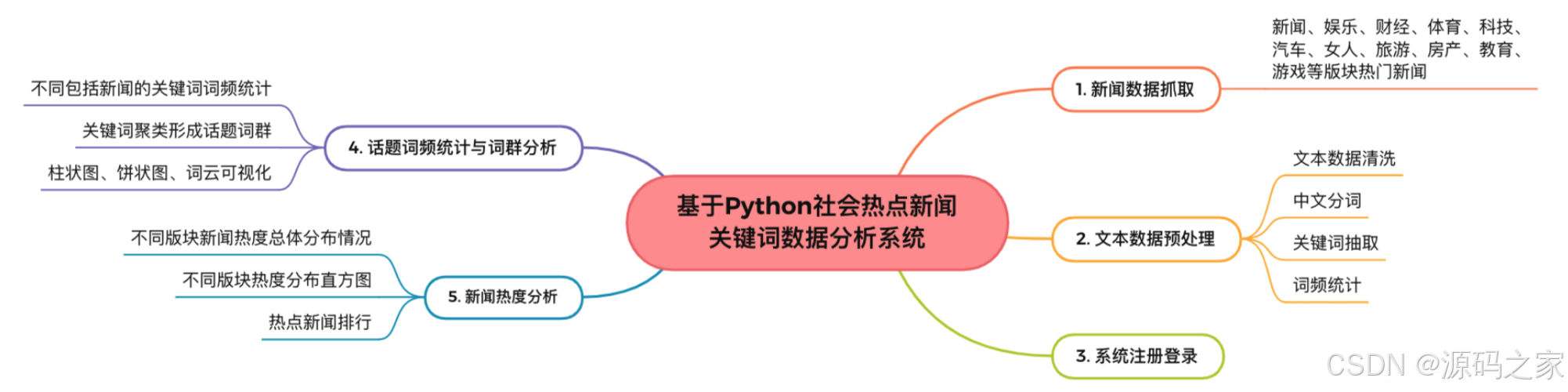
1、项目介绍
技术栈
Python语言、Flask框架、requests爬虫技术、BeautifulSoup解析库、SnowNLP情感分析、scikit-learn机器学习库、statsmodels统计模型、ARIMA时间序列预测模型、Echarts可视化工具、Bootstrap前端框架、jQuery库、新浪新闻数据源
功能模块
数据采集模块:基于requests+BeautifulSoup实现新浪新闻多版块(新闻、娱乐、财经、体育、科技等)定向爬取与数据清洗
用户管理模块:提供用户注册、登录认证功能,保障系统访问安全
新闻展示模块:支持新闻列表浏览、版块分类筛选、新闻关注榜展示
情感分析模块:集成SnowNLP进行新闻文本情感倾向分析,输出0-1情感得分
关键词分析模块:实现中文分词、关键词抽取、词频统计与词群聚类分析
热度分析模块:基于新闻关注人数进行密度分布统计,评估各版块热度水平
可视化呈现模块:采用Echarts构建词云、饼图、柱状图、散点图、密度分布直方图等可视化图表
趋势预测模块:应用ARIMA时间序列模型对话题发展趋势进行预测
项目介绍
本项目是一款智能新闻舆情分析平台,基于Python语言开发,专注于新浪新闻数据的深度挖掘与价值呈现。系统通过requests+BeautifulSoup爬虫技术定向抓取新浪新闻多个版块的最新数据,经清洗后分类存储。依托SnowNLP实现新闻情感量化分析,以0-1分值评估情感倾向;通过关键词抽取、词频统计及聚类分析形成词群,结合新闻关注人数完成热度分析。平台创新集成ARIMA预测模型,基于历史数据训练后可预测话题趋势走向。后端采用Flask构建RESTful接口,前端运用Bootstrap+Echarts+jQuery实现流畅交互,以词云、散点图、密度分布直方图等形式直观展示热词分布、情感倾向及趋势预测结果,实现从数据采集、分析、可视化到趋势预测的全链路智能化处理。
2、项目界面
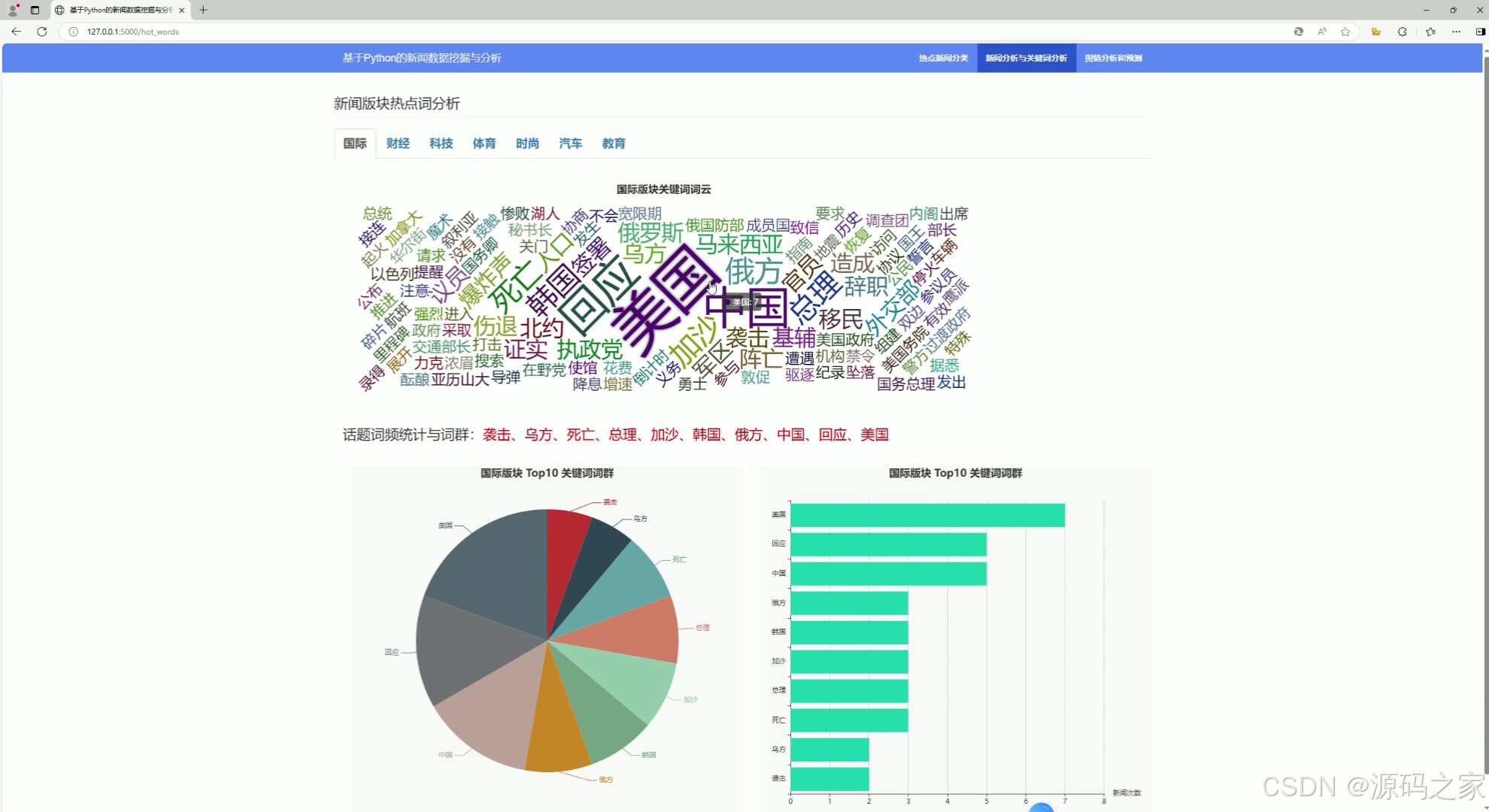
(1)新闻可视化分析、热词关键词分析
该页面是基于Python的新闻数据挖掘与分析系统中的新闻版块热点词分析功能页,可切换不同新闻版块查看对应关键词词云、话题词频统计与词群,通过词云、饼图、柱状图三种可视化形式直观呈现各版块关键词分布与频次情况。
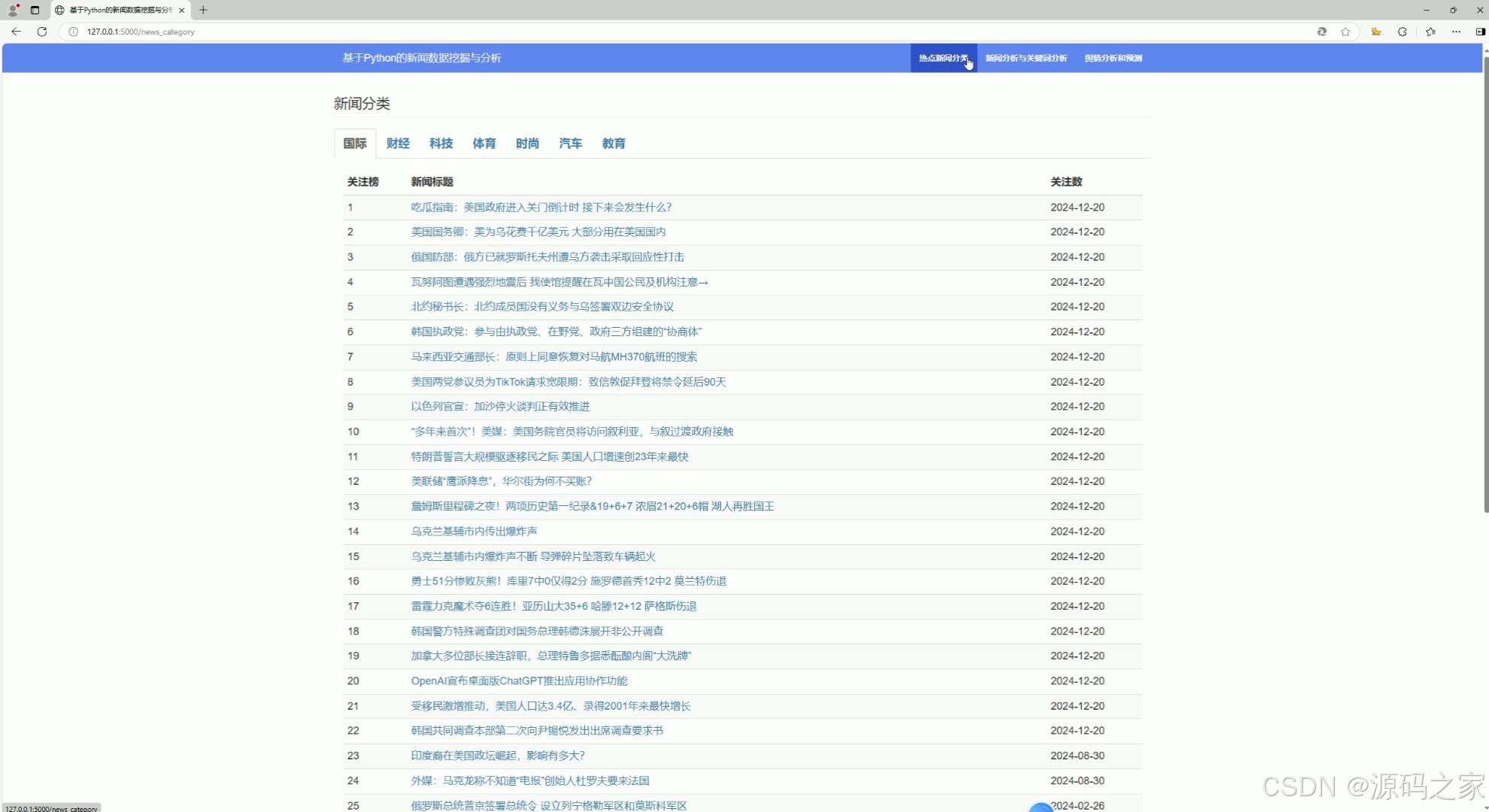
(2)新闻列表、新闻类型
该页面是基于Python的新闻数据挖掘与分析系统中的热点新闻分类功能页,可切换不同新闻版块,以列表形式展示对应版块的新闻关注榜,呈现新闻标题与关注数等信息,同时系统还设有新闻分析与关键词分析、舆情分析和预测等其他功能模块入口。
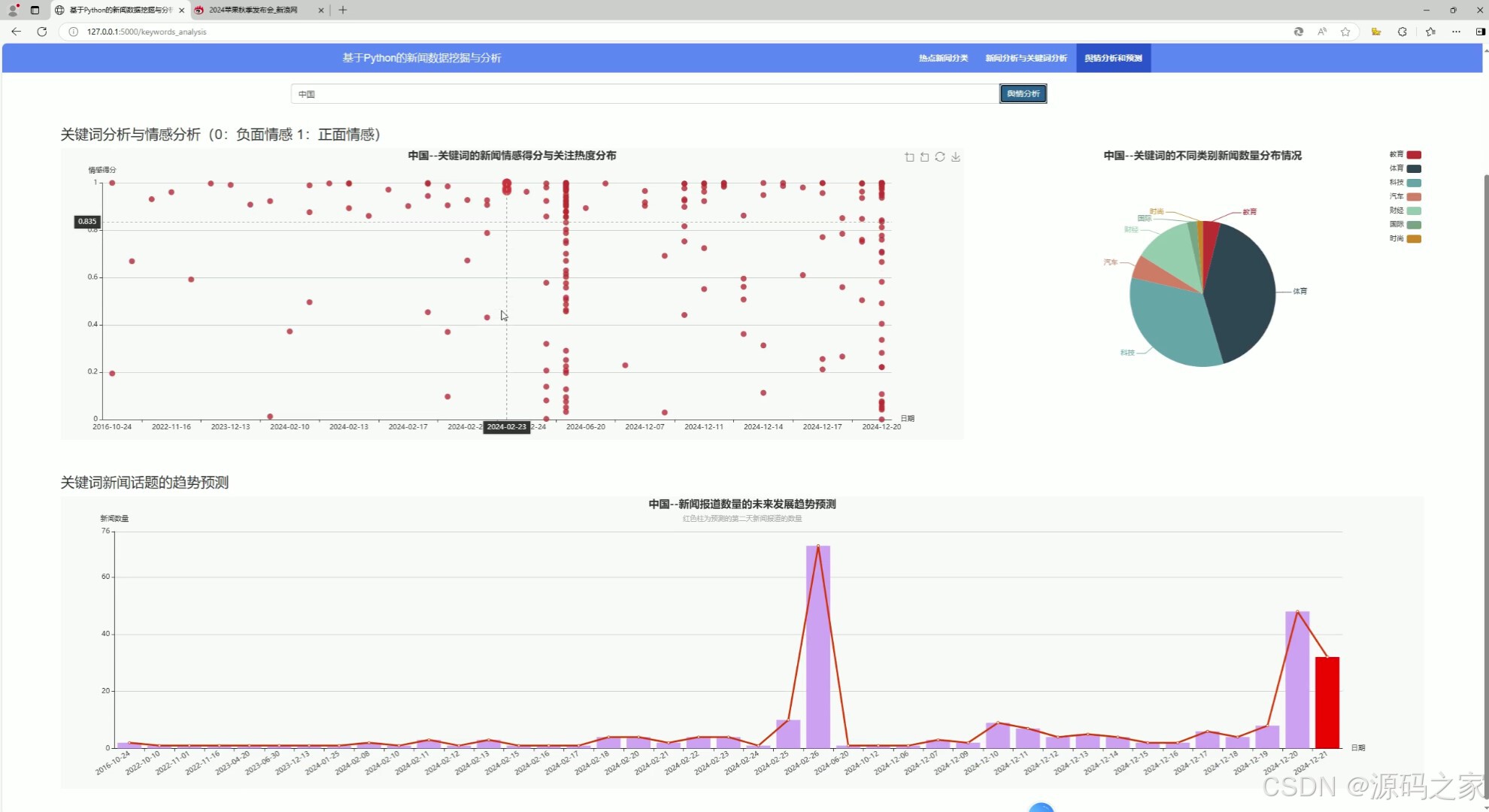
(3)新闻舆情分析与预测
该页面是基于Python的新闻数据挖掘与分析系统中的舆情分析和预测功能页,可针对指定关键词,通过散点图呈现新闻情感得分与关注热度分布,通过饼图展示不同类别新闻数量分布,还通过折线与柱状结合的图表实现新闻报道数量的未来发展趋势预测。
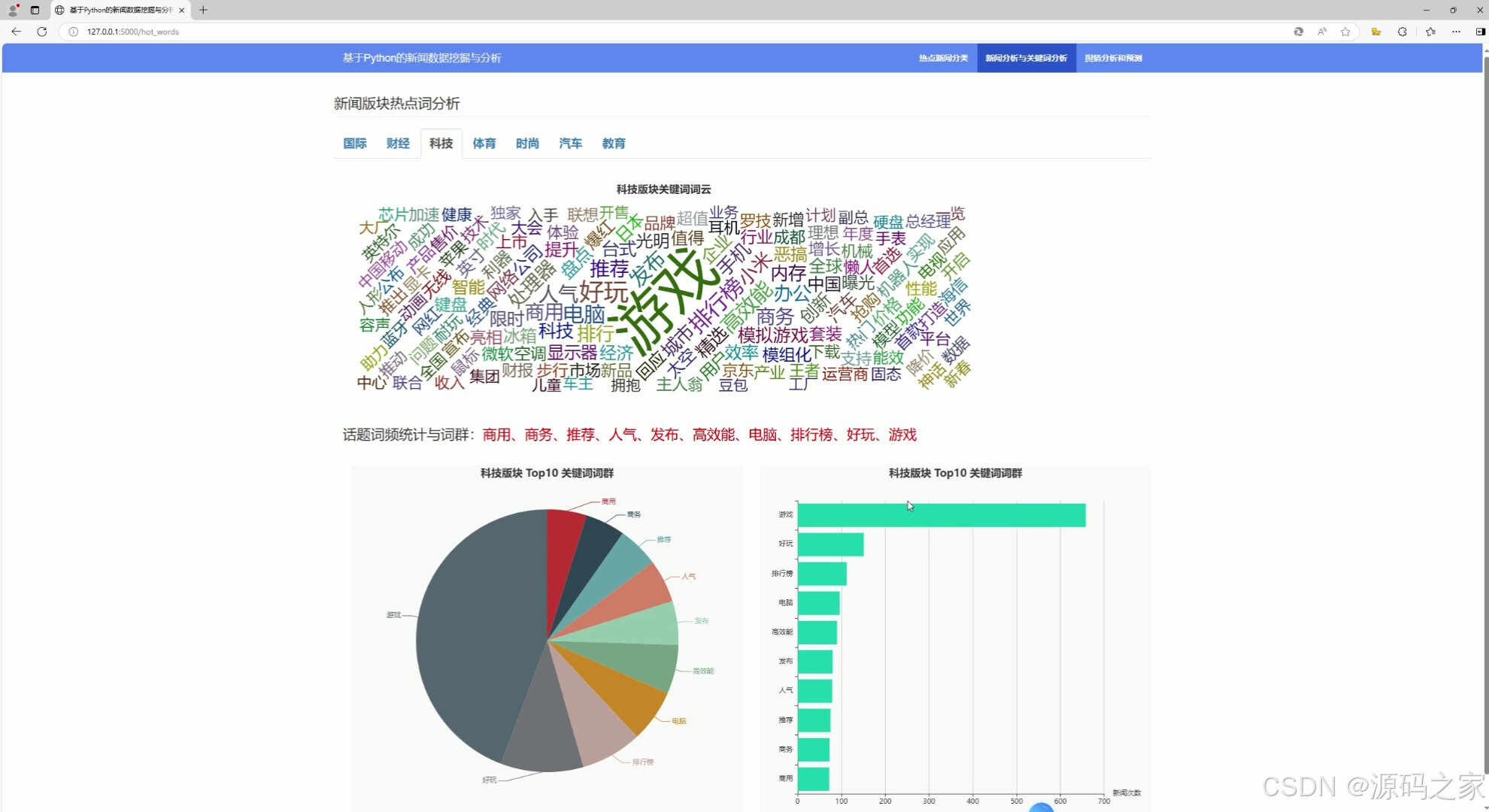
(4)新闻可视化分析、热词关键词分析
该页面是基于Python的新闻数据挖掘与分析系统中的新闻版块热点词分析功能页,可切换不同新闻版块,以词云形式展示对应版块关键词分布,同时通过饼图和柱状图呈现该版块话题词频统计与词群情况,系统还设有热点新闻分类、新闻分析与关键词分析、舆情分析和预测等其他功能模块入口。
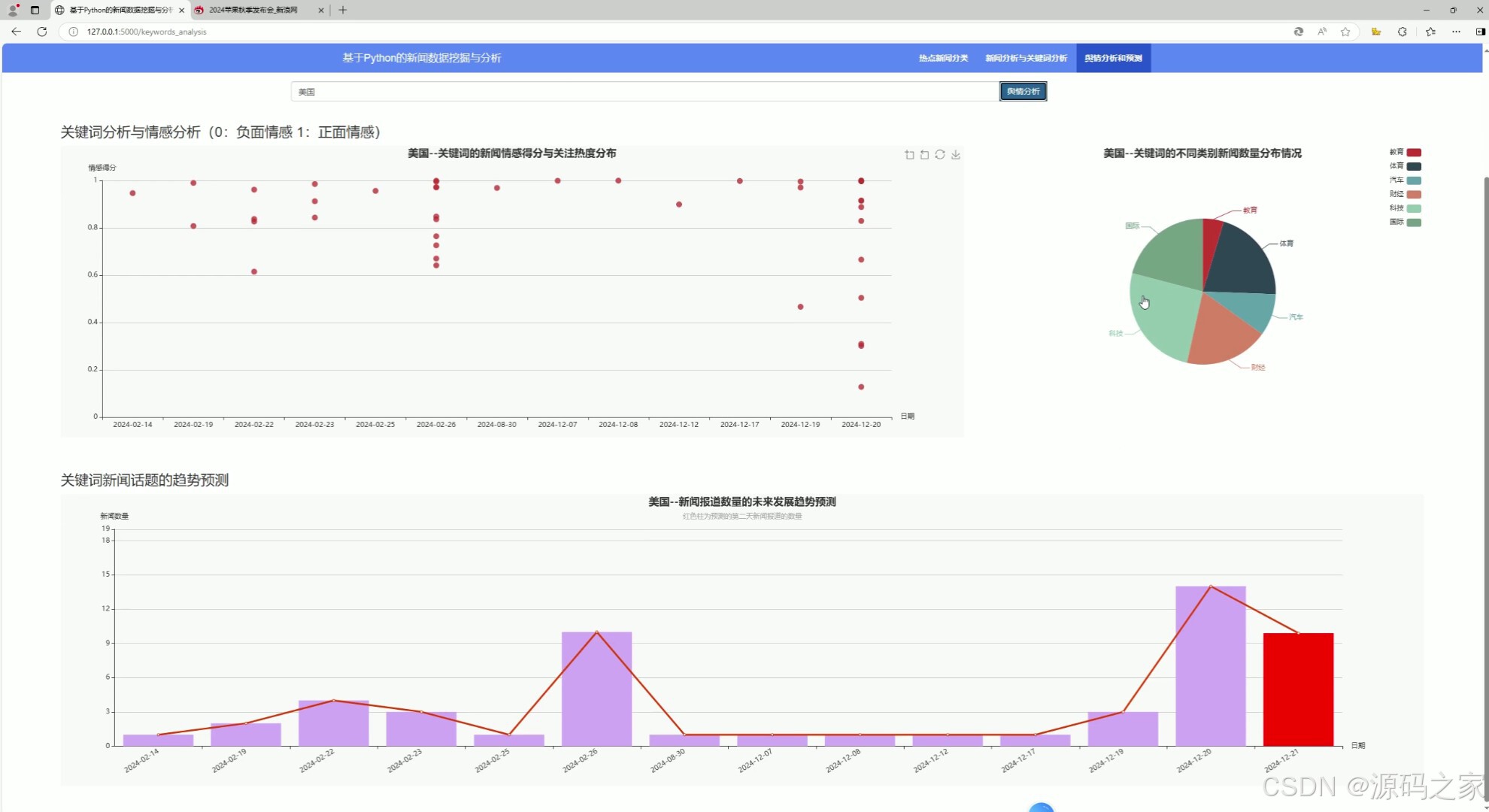
(5)新闻舆情分析与预测
该页面是基于Python的新闻数据挖掘与分析系统中的舆情分析和预测功能页,可针对指定关键词,通过散点图呈现新闻情感得分与关注热度分布,通过饼图展示不同类别新闻数量分布,还通过折线与柱状结合的图表实现新闻报道数量的未来发展趋势预测。
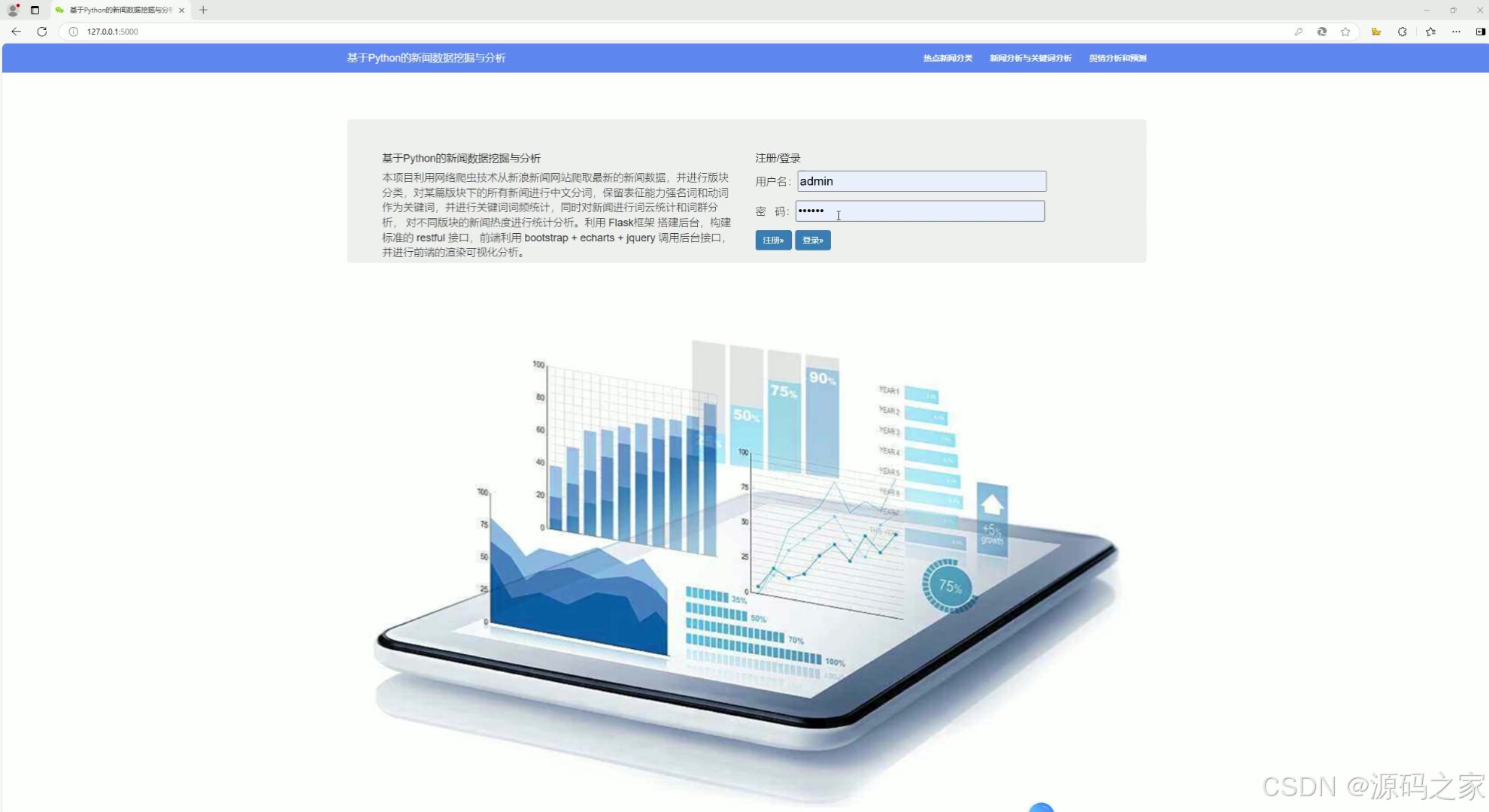
(6)注册登录
该页面是基于Python的新闻数据挖掘与分析系统的登录页,提供用户注册与登录功能,同时展示项目介绍,说明系统利用网络爬虫获取新闻数据并进行分词、统计与可视化分析,系统还包含热点新闻分类、新闻分析与关键词分析、舆情分析和预测等后续功能模块。
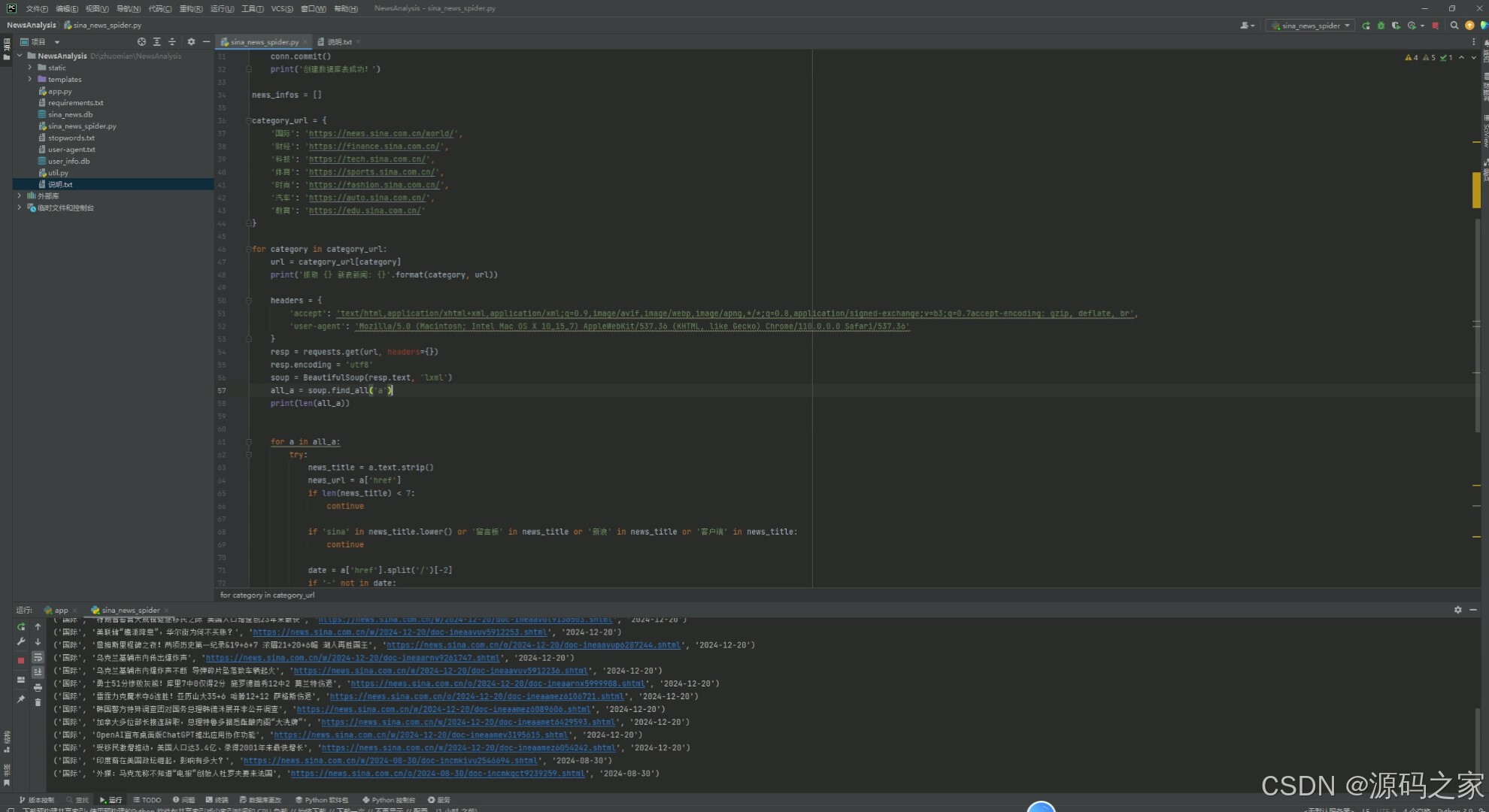
(7)数据爬取
该页面是基于Python的新闻数据挖掘与分析系统的爬虫代码编辑界面,实现了对不同版块新闻网站的新闻数据爬取功能,可提取新闻标题、链接及发布日期等信息,并能将爬取到的数据进行存储,为后续的新闻分类、关键词分析与可视化等功能提供数据支撑。
3、项目说明
一、技术栈简要说明
本平台基于Python语言构建核心业务逻辑,采用Flask轻量级框架搭建后端RESTful接口,实现高效的请求响应与数据交互。前端界面运用Bootstrap框架保障响应式布局,结合jQuery简化DOM操作与异步请求处理,通过Echarts可视化库完成各类图表的动态渲染。数据采集层使用requests库配合BeautifulSoup解析器,实现对新浪新闻多版块内容的定向抓取与结构化清洗。数据分析层面集成SnowNLP进行中文文本情感倾向计算,调用scikit-learn实现关键词聚类分析,借助statsmodels库中的ARIMA时间序列模型完成话题趋势预测。整个技术栈从前端展示到后端处理,从数据采集到分析预测,形成了完整的闭环技术体系。
二、功能模块详细介绍
数据采集模块
该模块作为系统的数据基础,通过requests库模拟浏览器请求,获取新浪新闻各版块(新闻、娱乐、财经、体育、科技等)的HTML页面内容。利用BeautifulSoup解析DOM结构,精准提取新闻标题、发布时间、原文链接、关注人数等关键字段。对采集到的原始数据进行去重、空值处理、格式统一化等清洗操作,最终将结构化数据存储至本地文件系统或数据库中,为后续分析提供高质量的数据支撑。
用户管理模块
系统设计了完善的用户认证机制,提供用户注册与登录功能接口。注册时对用户密码进行加密存储,登录时验证身份信息并生成会话凭证。该模块保障了系统的访问安全性,防止未授权用户查看舆情分析数据,同时为个性化功能扩展预留了用户权限管理的接口。
新闻展示模块
以列表形式呈现各版块的热点新闻,支持按新闻类型(如国内、国际、娱乐、体育等)进行分类筛选。每条新闻条目展示标题、所属版块、关注人数等核心信息,并按照关注度进行排序形成新闻关注榜。用户可通过点击标题跳转至原始新闻页面,实现了数据展示与信息溯源的功能结合。
情感分析模块
针对采集到的新闻标题及正文内容,调用SnowNLP进行情感倾向计算。系统将分析结果以0-1的浮点数形式输出,其中数值趋近0代表负面情感,趋近1代表正面情感,0.5左右则表示中性情感。该模块为舆情研判提供了量化依据,帮助用户快速把握媒体报道的情感基调。
关键词分析模块
对新闻文本进行中文分词处理,过滤掉停用词和无实际意义的虚词,保留名词、动词等表征能力强的词汇作为候选关键词。通过词频统计算法计算各词汇出现频次,并基于词汇共现关系进行聚类分析,形成具有语义关联的词群。该模块有效挖掘了热点话题的核心词汇及其关联结构。
热度分析模块
基于每篇新闻的关注人数数据,对不同版块进行热度统计。采用密度分布算法分析关注人数的分布特征,评估各版块的整体热度水平及波动情况。该模块为判断用户兴趣焦点和舆情热度峰值提供了数据支撑。
可视化呈现模块
前端通过Echarts库实现多维度的数据可视化展示。词云图直观呈现关键词权重分布,饼图展示不同类别新闻占比,柱状图对比各版块词频差异,散点图揭示情感得分与关注热度的关联关系,密度分布直方图呈现关注人数的统计特征。多样化的图表形式让数据分析结果更加直观易懂。
趋势预测模块
基于历史新闻数量及关注度数据,构建ARIMA时间序列预测模型。通过statsmodels库进行模型参数识别与训练,利用训练好的模型对下一个时间步的话题趋势进行预测,并以折线图与柱状图结合的形式展示预测结果,为舆情预判和决策支持提供科学依据。
三、项目总结
本项目构建了一个从数据采集到智能分析再到可视化呈现的完整新闻舆情分析平台。系统以新浪新闻为数据源,通过爬虫技术实现多版块新闻的自动化采集与清洗。在数据分析层面,融合了情感计算、关键词挖掘、热度统计等多种算法,从多个维度深度解析新闻内容。特别引入ARIMA时间序列模型,实现了话题趋势的前瞻性预测,增强了系统的决策辅助能力。前端采用Bootstrap与Echarts的组合,保证了界面美观性与交互流畅度,将复杂的数据分析结果以直观的图表形式呈现给用户。整个平台实现了新闻舆情分析的全链路智能化处理,为用户提供了精准、高效的舆情洞察工具。
4、核心代码
python
class WordSegmentPOSKeywordExtractor(TFIDF):
def extract_sentence(self, sentence, keyword_ratios=None):
"""
Extract keywords from sentence using TF-IDF algorithm.
Parameter:
- keyword_ratios: return how many top keywords. `None` for all possible words.
"""
words = self.postokenizer.cut(sentence)
freq = {}
seg_words = []
pos_words = []
for w in words:
wc = w.word
seg_words.append(wc)
pos_words.append(w.flag)
if len(wc.strip()) < 2 or wc.lower() in self.stop_words:
continue
freq[wc] = freq.get(wc, 0.0) + 1.0
if keyword_ratios is not None and keyword_ratios > 0:
total = sum(freq.values())
for k in freq:
freq[k] *= self.idf_freq.get(k, self.median_idf) / total
tags = sorted(freq, key=freq.__getitem__, reverse=True)
top_k = int(keyword_ratios * len(seg_words))
tags = tags[:top_k]
key_words = [int(word in tags) for word in seg_words]
return seg_words, pos_words, key_words
else:
return seg_words, pos_words
extractor = WordSegmentPOSKeywordExtractor()
def fetch_keywords(new_title):
"""新闻关键词抽取,保留表征能力强名词和动词"""
seg_words, pos_words, key_words = extractor.extract_sentence(new_title, keyword_ratios=0.8)
seg_key_words = []
for word, pos, is_key in zip(seg_words, pos_words, key_words):
if pos in {'n', 'nt', 'nd', 'nl', 'nh', 'ns', 'nn', 'ni', 'nz', 'v', 'vd', 'vl', 'vu', 'a'} and is_key:
if word not in STOPWORDS:
seg_key_words.append(word)
return seg_key_words
python
@app.route('/news_words_analysis/<category>')
def news_words_analysis(category):
conn = sqlite3.connect('sina_news.db')
cursor = conn.cursor()
sql = "SELECT title FROM news_info where category='{}' order by date desc".format(category)
cursor.execute(sql)
titles = cursor.fetchall()
word_count = {}
for title in titles:
words = fetch_keywords(title[0])
for word in words:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
wordclout_dict = sorted(word_count.items(), key=lambda d: d[1], reverse=True)
wordclout_dict = [{"name": k[0], "value": k[1]} for k in wordclout_dict]
# 选取 top10 的词作为话题词群
top_keywords = [w['name'] for w in wordclout_dict[:10]][::-1]
top_keyword_counts = [w['value'] for w in wordclout_dict[:10]][::-1]
return jsonify({'词云数据': wordclout_dict, '词群': top_keywords, '词群个数': top_keyword_counts})
# -----------3、预测---------------------
def arima_model_train_eval(history):
# 构造 ARIMA 模型
model = ARIMA(history, order=(1, 1, 0))
# 基于历史数据训练
model_fit = model.fit()
# 预测下一个时间步的值
output = model_fit.forecast()
yhat = output[0]
return yhat
@app.route('/keywords_yuqing_search/<search_input>')
def keywords_yuqing_search(search_input):
""" 3、舆情关键词检索分析 """
conn = sqlite3.connect('sina_news.db')
cursor = conn.cursor()
print(search_input)
sql = "SELECT * FROM news_info where title like '%{}%' order by date asc".format(search_input)
cursor.execute(sql)
news_infos = cursor.fetchall()
dates = []
sentiment_scores = []
category_count = {}
date_count = {}
for news_info in news_infos:
category, news_title, news_url, date = news_info
dates.append(date)
# 情感分析
sentiment_score = SnowNLP(news_title).sentiments
sentiment_scores.append(sentiment_score)
if category not in category_count:
category_count[category] = 0
category_count[category] += 1
for date in dates:
if date not in date_count:
date_count[date] = 0
date_count[date] += 1
# 事件发生的趋势预测
pred_dates = list(date_count.keys())
date_news_counts = list(date_count.values())
# 下一个日期及新闻数量预测,调用自建arima_model_train_eval函数
print(date_news_counts)
pred_next_count = arima_model_train_eval(date_news_counts)
date_news_counts.append(pred_next_count)
new_date = pred_dates[-1]
next_date = datetime.strptime(new_date, '%Y-%m-%d') + timedelta(days=1)
next_date = next_date.strftime('%Y-%m-%d')
pred_dates.append(next_date)
result = {
'情感得分': sentiment_scores,
'日期': dates,
'类别': list(category_count.keys()),
'新闻个数': list(category_count.values()),
"趋势日期": pred_dates,
"趋势数量": date_news_counts
}
return jsonify(result)5、项目列表



6、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看【用户名】、【专栏名称】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看 👇🏻获取联系方式👇🏻