目录
- 0 专栏介绍
- 1 Double DQN算法回顾
- 2 基于DDQN的路径规划
-
- 2.1 DDQN网络设计
- 2.2 动作空间设计
- 2.3 奖励函数设计
- 3 算法仿真
0 专栏介绍
本专栏以贝尔曼最优方程等数学原理为根基,结合PyTorch框架逐层拆解DRL的核心算法(如DQN、PPO、SAC)逻辑。针对机器人运动规划场景,深入探讨如何将DRL与路径规划、动态避障等任务结合,包含仿真环境搭建、状态空间设计、奖励函数工程化调优等技术细节,旨在帮助读者掌握深度强化学习技术在机器人运动规划中的实战应用
1 Double DQN算法回顾
深度强化学习作为机器学习领域的重要分支,实现了深度表征学习与序列决策优化的有机结合。传统浅层架构由于其有限的特征转换能力,仅能在低维特征空间建立简单映射关系,难以处理高维非线性问题。相较之下,深度学习的层级抽象机制通过多阶段非线性变换,可实现从原始输入到高阶语义特征的递进式提取,其核心优势体现在基于通用近似定理的复杂函数建模能力。强化学习框架则通过构建智能代理系统与环境的动态交互模型,建立"状态感知-行为执行-奖励反馈"的闭环学习机制。这种基于MDP的范式,使得智能体能够在未知或动态环境中通过试错策略实现自主决策优化。
在使用Q-Learning算法进行路径规划时,地图环境维度增加,相应的该算法的动作空间 A A A和状态空间 S S S的维度也会变大,致使存储和更新每个状态-动作对的 Q Q Q值表的维度也同样增加,会面临存储需求和计算成本的急剧增加,导致训练变得困难。状态空间和动作空间的增加使得探索变得更为复杂,可能导致维数灾难、训练效率低下或者算法难以收敛以及过度拟合的问题。DQN算法通过利用深度神经网络来解决具有高维状态的复杂问题,从而改进了强化学习。深度神经网络的主要工作是估计动作值函数,允许计算每个状态下所有可用动作的 Q Q Q值。
然而,无论Q-Learning算法还是DQN算法都存在过估计(overestimation)现象,过估计会导致智能体倾向于选择被高估的动作,可能陷入局部最优策略,降低学习效率和最终性能。例如,在复杂环境中,智能体可能反复选择某个次优动作,而忽略真正的高回报动作。缓解最大化偏差的方法之一是互监督机制,典型算法是双深度Q网络(Double DQN, DDQN),该方法令
y i = { r i , s ′ 是最后一个状态 r i + γ Q ^ ( s ′ , max a ( Q ( s ′ , a ; θ ) ) ; θ ^ ) , s ′ 不是最后一个状态 y_i=\begin{cases} r_i\,\, , s'\text{是最后一个状态}\\ r_i+\gamma \hat{Q}\left( \boldsymbol{s}',\max _{\boldsymbol{a}}\left( Q\left( \boldsymbol{s}',\boldsymbol{a};\boldsymbol{\theta } \right) \right) ;\boldsymbol{\hat{\theta}} \right) , s'\text{不是最后一个状态}\\\end{cases} yi={ri,s′是最后一个状态ri+γQ^(s′,maxa(Q(s′,a;θ));θ^),s′不是最后一个状态
理论上DDQN实现了对 Q Q Q的无偏估计,如下图所示是DDQN和DQN在一些常见强化学习任务上的过估计现象对比,可以看到DDQN算法很好地缓解了过估计现象,具体算法原理请参考深度强化学习 | 详解过估计现象与Double DQN算法(附Pytorch实现)

2 基于DDQN的路径规划
2.1 DDQN网络设计
为了避免训练过程中的不稳定现象,算法初始阶段需同步初始化经验缓存队列与双网络参数配置,IDQN算法采用双网络结构,即当前网络用于实时更新,而目标网络以较低频率同步主网络参数,从而提升训练的稳定性,如下图所示。
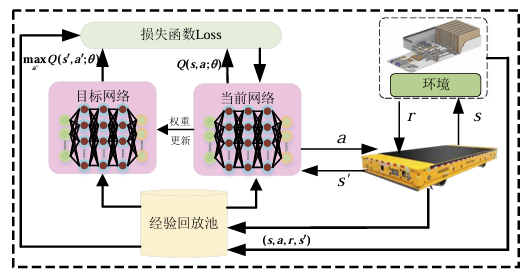
在网络组件配置上,模型采用特征提取器 + Q 值输出头的分层架构:
- 特征提取器(Feature Extractor):使用多层感知机对原始状态进行高维表征学习,隐层维度配置为 128, 256,最终输出固定维度特征 feature_dim=128,完成状态空间到紧凑特征空间的映射;
- Q 网络(Q-Net):在提取特征基础上进一步拟合动作价值,采用单隐层结构 mlp_dims=64,输出各动作对应的 Q 值,实现动作价值的精准估计。
该参数配置在状态表征能力与计算效率间取得平衡,适配 DDQN 离线更新与双网络解耦训练范式。
2.2 动作空间设计
在基于DDQN的差速驱动机器人路径规划算法中,动作空间的设计是决定算法收敛速度、路径最优性与运动稳定性的核心环节。DDQN作为深度强化学习算法,严格要求采用离散动作空间,差速驱动机器人的运动学模型遵循非完整约束特性,其位姿变化规律可通过以下微分方程精准描述
p ˙ = x ˙ y ˙ θ ˙ = cos θ 0 sin θ 0 0 1 v ω = S ( q ) u \boldsymbol{\dot{p}}=\left \\begin{array}{c} \\dot{x}\\\\ \\dot{y}\\\\ \\dot{\\theta}\\\\\\end{array} \\right =\left \\begin{matrix} \\cos \\theta\& 0\\\\ \\sin \\theta\& 0\\\\ 0\& 1\\\\\\end{matrix} \\right \left \\begin{array}{c} v\\\\ \\omega\\\\\\end{array} \\right =S\left( \boldsymbol{q} \right) \boldsymbol{u} p˙= x˙y˙θ˙ = cosθsinθ0001 vω=S(q)u
式中各参数 ( x , y ) (x, y) (x,y) 代表机器人在二维平面内的实时位置坐标, θ \theta θ 为机器人当前航向角, v v v 为机器人驱动线速度, ω \omega ω 为转向角速度;控制输入向量 u \boldsymbol{u} u 由线速度与角速度组成,是动作空间设计的核心调控变量。因此,本次路径规划场景下的动作空间,完全围绕核心控制变量 ( v , ω ) (v, \omega) (v,ω) 开展分层设计,兼顾路径规划的全局最优需求与机器人实际运动限制。结合路径规划的实际工况需求,兼顾规划效率与避障安全性,将机器人线速度划分为三个差异化级别,适配不同规划路段与环境复杂度,具体分级如下:
-
高速: v = v max v = v_{\text{max}} v=vmax,适用于开阔无障碍物、路径平直的长距离规划路段,可大幅提升路径规划与机器人行进效率
-
中低速: v = 0.2 × v max v = 0.2 \times v_{\text{max}} v=0.2×vmax,适用于存在轻微弯道、周边环境有轻微障碍物干扰的常规规划路段,平衡行进效率与转向灵活性
-
极低速: v = 0.1 × v max v = 0.1 \times v_{\text{max}} v=0.1×vmax,适用于狭窄空间、临近障碍物或需要精准调整位姿的复杂规划场景,保障运动安全性与位姿微调精度
转向方面也需要完整覆盖差速机器人的基本运动模式:
| 运动模式 | 数学描述 | 适用场景 |
|---|---|---|
| 直线前进 | ω = 0 \omega = 0 ω=0 | 路径直线段跟踪 |
| 弧线运动 | ω ≠ 0 , v ≠ 0 \omega \neq 0, v \neq 0 ω=0,v=0 | 路径曲线段跟踪 |
| 原地旋转 | v = 0 , ω ≠ 0 v = 0, \omega \neq 0 v=0,ω=0 | 未包含但可通过动作组合实现 |
本文设计的动作空间为
python
self.action_space = [
DiffCmd(v=0.2 * self.params["max_v"], w=self.params["max_w"]),
DiffCmd(v=self.params["max_v"], w=self.params["max_w"]),
DiffCmd(v=self.params["max_v"], w=0.0),
DiffCmd(v=self.params["max_v"], w=-self.params["max_w"]),
DiffCmd(v=0.2 * self.params["max_v"], w=-self.params["max_w"]),
DiffCmd(v=0.1 * self.params["max_v"], w=0.0),
]2.3 奖励函数设计
奖励函数设计采用多目标联合优化的混合奖励机制,通过时间惩罚、距离引导、目标达成奖励与碰撞惩罚的线性组合,构建了兼具探索激励与安全约束的强化学习回报,核心公式为:
R = r t i m e + α ( d t − 1 − d t ) + r r e a c h I w i n + r c o l l i s i o n I d e a d R=r_{\mathrm{time}}+\alpha \left( d_{t-1}-d_t \right) +r_{\mathrm{reach}}\mathbb{I} {\mathrm{win}}+r{\mathrm{collision}}\mathbb{I} _{\mathrm{dead}} R=rtime+α(dt−1−dt)+rreachIwin+rcollisionIdead
其中 d t d_t dt表示时刻 t t t智能体与目标的欧氏距离, I \mathbb{I} I为事件指示函数。时间惩罚项 r t i m e r_{\mathrm{time}} rtime作为基底奖励,通过固定负值施加步长成本压力,抑制智能体在环境中无效徘徊,驱动策略向高效路径收敛。距离引导项 α ( d t − 1 − d t ) \alpha \left( d_{t-1}-d_t \right) α(dt−1−dt)引入相对运动奖励机制,其中 α \alpha α为距离奖励系数,当智能体向目标靠近时 d t − 1 > d t d_{t-1}>d_t dt−1>dt产生正向激励,远离时 d t − 1 < d t d_{t-1}<d_t dt−1<dt施加负向惩罚,形成连续梯度信号引导策略优化方向。该设计相比绝对距离奖励更能话应动态环境,避免目标移动导致的奖励稀疏问题。目标达成奖励 r r e a c h r_{\mathrm{reach}} rreach作为稀疏奖励信号,仅在智能体进入目标区域时触发,通过显著的正向激励建立策略优化的全局目标导向。碰撞惩罚项 r c o l l i s i o n r_{\mathrm{collision}} rcollision则作为安全约束机制,当检测到与环境障碍物发生碰撞时施加高额负奖励,迫使策略学习规避高风险区域。
3 算法仿真
核心算法如下所示:
python
def plan(self, start: Point3d, goal: Point3d) -> Tuple[List[Point3d], List[Dict]]:
"""
DDQN motion plan function.
Parameters:
start (Point3d): The starting point of the planning path.
goal (Point3d): The goal point of the planning path.
Returns:
path (List[Point3d]): The planned path from start to goal.
visual_info (List[Dict]): Information for visualization
"""
warmstart, _ = self.coarse_searcher.plan(start, goal)
warmstart = self.pathInterpolation(warmstart, 50)
if not warmstart:
LOG.INFO("Planning Failed.")
return []
is_goal_reached = False
robot = DiffRobot(start.x(), start.y(), start.theta(), 0, 0)
for _ in range(self.max_iteration):
robot_pose = Point3d(robot.px, robot.py, robot.theta)
lookahead_dist = MathHelper.clamp(
abs(robot.v) * self.lookahead_time, self.min_lookahead_dist, self.max_lookahead_dist
)
curr_goal = self._getCurrentGoalPoint(warmstart, robot_pose, lookahead_dist)
dist_to_goal = math.hypot(robot.px - goal.x(), robot.py - goal.y())
if dist_to_goal < self.goal_dist_tol:
is_goal_reached = True
break
u = self.DDQNProcess(robot_pose, curr_goal, robot.v, robot.w)
robot.kinematic(u, self.dt)
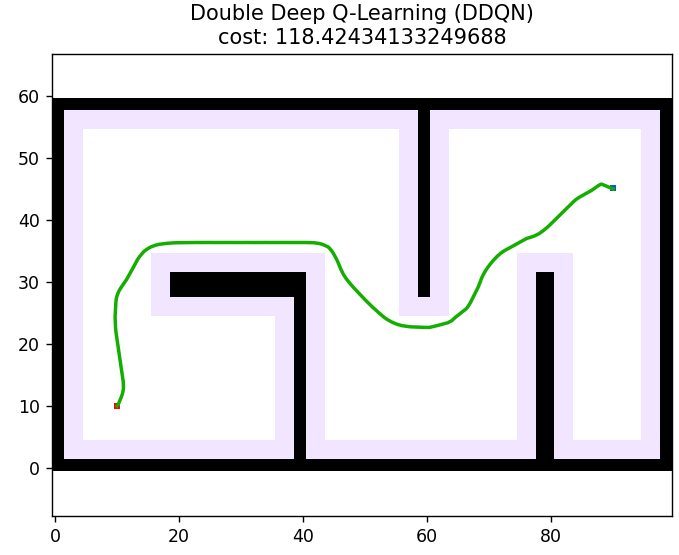
return path 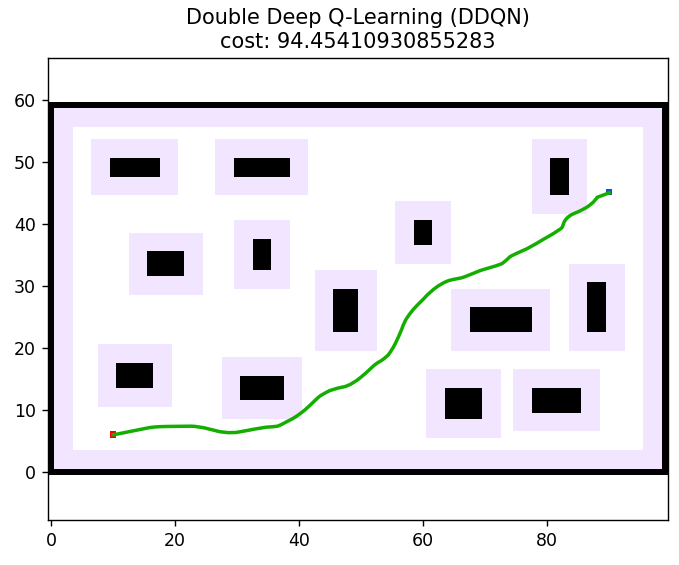
完整工程代码请联系下方博主名片获取
🔥 更多精彩专栏:
👇源码获取 · 技术交流 · 抱团学习 · 咨询分享 请联系👇