
✨ 把代码写进星轨,
用逻辑丈量宇宙。
| 导航 | 链接 |
|---|---|
| 个人主页 | 🏠 星轨初途 |
| 基础语言专栏 | 💻 C语言 、 📚 数据结构 |
| C++ 进阶专栏 | 🏆 C++学习(竞赛类) 、 ⚙️ C++专栏(开发类) |
| 刷题实战专栏 | 🚀 算法及编程题分享 |

文章目录
- 前言
- 一、再探构造函数:初始化列表
-
- [1. 必须用初始化列表的三种情况](#1. 必须用初始化列表的三种情况)
- [2. 语法格式](#2. 语法格式)
- [3. 🚨 致命踩坑点:初始化的真实顺序](#3. 🚨 致命踩坑点:初始化的真实顺序)
- [二、隐式类型转换与 explicit 关键字](#二、隐式类型转换与 explicit 关键字)
- [三、static 成员与牛客实战题拆解](#三、static 成员与牛客实战题拆解)
-
- [1. static 成员的硬核特性全景图](#1. static 成员的硬核特性全景图)
- [2. ⚔️ 实战演练:牛客网高频题(求1+2+...+n)](#2. ⚔️ 实战演练:牛客网高频题(求1+2+...+n))
- 四、终极笔试题:全局、局部、静态对象的构造与析构顺序
- 五、友元:打破封装的"合法后门"
-
- [1. 友元函数](#1. 友元函数)
- [2. 友元类](#2. 友元类)
- 六、内部类
-
- [1. 内部类的特性](#1. 内部类的特性)
- [2. 工程实战:专属内部类](#2. 工程实战:专属内部类)
- 七、匿名对象和有名对象
- 八、对象拷贝时的编译器优化(编译器的极致优化)
-
- 编译器的极致优化
-
- [场景 A:参数传递时的优化(合并构造)](#场景 A:参数传递时的优化(合并构造))
- [场景 B:传值返回的极致压榨](#场景 B:传值返回的极致压榨)
- 结束语
前言
嗨(。◕ˇ∀ˇ◕)!在上一篇《类和对象(中)》搞定了对象的"生老病死"(六大默认成员函数)后今天直接进入《类和对象》终结篇,带你彻底打通 C++ 面向对象的底层逻辑!本篇硬核拆解初始化列表、static 成员、构造析构顺序及现代编译器的极致优化机制,全是实战干货,直接起飞!

一、再探构造函数:初始化列表
在上一篇中,我们在构造函数体内给成员变量赋值,看起来一切正常:
cpp
class Date
{
public:
Date(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
private:
int _year;
int _month;
int _day;
};但在真实的开发世界里,严格来说,这根本不叫"初始化",这只能叫函数体内赋初值。
底层逻辑剖析: 对象在实例化时,分配好内存空间后,其实早就已经走过一遍"初始化"了。当你进入构造函数的 {} 内部时,所有的成员变量实际上已经"出生"并存在了。你在 {} 里做的,只不过是对已经存在的变量进行二次甚至多次的赋值操作。
这在遇到以下三种"刺头"成员变量时,编译器会直接翻脸报错,因为它们在 C++ 语法中必须在定义(出生)的瞬间就初始化,进到函数体内部再赋值就晚了!
1. 必须用初始化列表的三种情况
const成员变量:常量一旦定义,值就锁死了,不能事后赋值。- 引用成员变量:引用在定义时必须绑定一个实体,且不能更改指向。
- 没有默认构造函数(无参/全缺省)的自定义类型成员:因为它没有默认的出生方式,你必须在它出生时显式指定怎么构造它。
为了解决这个问题,C++ 引入了初始化列表。
2. 语法格式
以一个冒号 开始,接着是一个以逗号分隔的数据成员列表,每个成员变量后面跟一个放在括号中的初始值或表达式。
cpp
class A
{
public:
// 初始化列表才是成员变量真正定义(出生)的地方!
A(int a, int ref)
: _a1(a) // 初始化一般变量
, _n(10) // 初始化 const 变量
, _ref(ref) // 初始化引用变量
{
// 函数体内可以继续做一些打印或检查工作
}
private:
int _a1;
const int _n; // 必须走列表
int& _ref; // 必须走列表
};规则
- 初始化列表的基础规则 :每个成员变量在初始化列表中只能出现一次 ;从语法逻辑上,初始化列表是类成员变量定义并完成初始化的位置。
- 必须在初始化列表初始化的成员 :引用成员变量、const修饰的成员变量、无默认构造函数的自定义类类型成员变量,这三类成员必须在初始化列表中完成初始化,否则会编译报错。
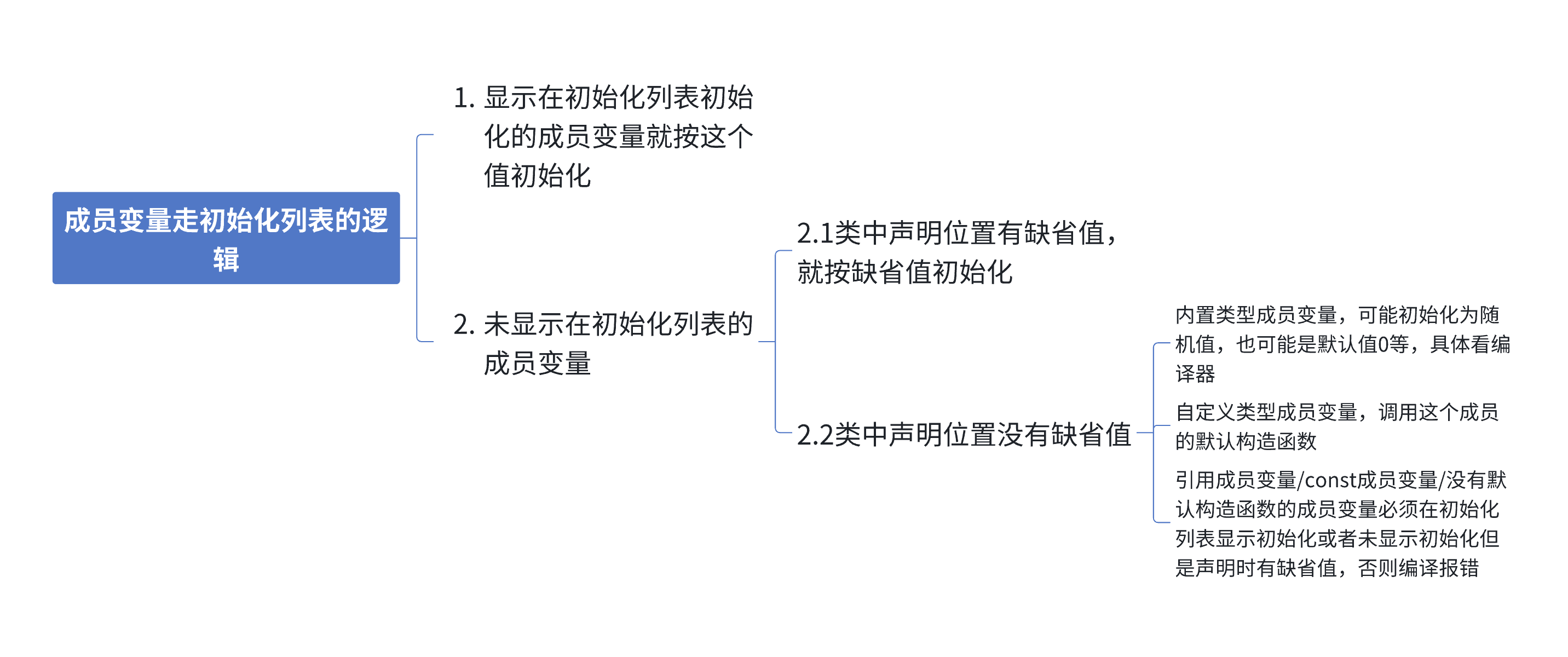
- C++11成员缺省值规则 :C++11支持在成员变量声明处设置缺省值 ,该缺省值仅提供给未在初始化列表中显式初始化的成员使用。
- 初始化列表的执行优先级与推荐用法 :
- 优先推荐使用初始化列表完成成员初始化,因为所有类成员都会经过初始化列表的流程,即使你没有在列表中显式初始化它。
- 成员声明处有缺省值:初始化列表会使用该缺省值完成初始化。
- 无缺省值、未显式初始化的内置类型成员:C++标准未强制规定其初始化行为,是否初始化、初始值均由编译器决定,值是不确定的。
- 无缺省值、未显式初始化的自定义类型成员:会自动调用该成员类型的默认构造函数,若该类型无默认构造函数,会直接编译报错。
- 初始化列表的执行顺序规则 :初始化列表的初始化执行顺序,仅由成员变量在类中的声明顺序决定,和成员在初始化列表中的书写先后顺序完全无关;建议将成员声明顺序与初始化列表的书写顺序保持一致,避免出现顺序依赖导致的bug。
💡 注意:
- 无论什么情况,尽量全部使用初始化列表进行初始化!
- 特别是对于自定义类型成员,即便你没写在初始化列表里,编译器也会默认先去走一遍初始化列表调用它的默认构造函数。如果直接写在初始化列表里,就能省去先默认构造、再赋值的二次开销。
- C++11 补丁 :C++11 支持在成员声明处给缺省值(如
int _year = 1;),这个缺省值其实就是专门给初始化列表备用的。如果你在初始化列表里没显式写,编译器就会拿这个缺省值去初始化。
3. 🚨 致命踩坑点:初始化的真实顺序
下面这段代码是各大厂笔试题的常客,请问它的输出结果是什么?
cpp
class A
{
public:
A(int a)
: _a1(a)
, _a2(_a1) // 踩坑点在这里
{}
void Print() { cout << _a1 << " " << _a2 << endl; }
private:
int _a2;
int _a1;
};
int main()
{
A obj(1);
obj.Print();
return 0;
}答案:输出 1 和一个随机垃圾值。
深度剖析(铁律): 成员变量在类中声明的顺序 ,就是它们在内存中的物理布局顺序,也是在初始化列表中的初始化顺序 !与它们在初始化列表里出现的先后顺序毫无关系!
在上面的代码中,_a2 先声明,所以编译器无视列表顺序,强行先执行 _a2(_a1)。此时 _a1 空间开好了但还没被初始化,是个随机垃圾值,所以 _a2 拿到了垃圾值。随后才初始化 _a1(a),_a1 变成 1。
(工程建议:类的成员变量声明顺序和初始化列表出现的顺序务必保持绝对一致!)
二、隐式类型转换与 explicit 关键字
在 C++ 中,单参数(或除第一个参数外其余都有默认值)的构造函数,承担了隐式类型转换的作用。
cpp
class A
{
public:
A(int a) : _a(a) {} // 单参数构造函数
private:
int _a;
};
int main()
{
A obj1(2); // 正常构造
A obj2 = 3; // 发生了隐式类型转换,在 C++ 中是合法的!
return 0;
}A obj2 = 3; 为什么能编译通过?
底层逻辑 :编译器极其聪明,它发现左右两边类型不匹配,于是先用整数 3 作为参数,调用 A(int) 构造出一个 A 类型的临时对象 ,然后再用这个临时对象拷贝构造 给 obj2。(注:现代编译器会直接优化为直接用 3 构造 obj2,但这不影响语法层面的转换逻辑)。
🛡️ 工程防御指南 (
explicit)这种隐式转换在写类似于
std::string s = "hello";时非常爽。但在大型工程中,它也极易引发莫名其妙的 Bug。比如你的函数明明需要一个对象,别人手滑传了个int进去,编译器居然不报错直接转了!如果我们为了严谨,不想让这种自动转换发生,可以在构造函数前加上
explicit关键字,强制禁止隐式转换!
cppexplicit A(int a) : _a(a) {} // 此时 A obj2 = 3; 将直接编译报错!强制提醒开发者必须写成 A obj2(3);
三、static 成员与牛客实战题拆解
有时候我们需要一个变量能被这个类的所有对象共享(比如统计这个类实例化了多少个对象,或者实现单例模式)。如果在 C 语言中我们只能用全局变量,但这极其破坏封装性。在 C++ 中,我们用 static 成员。
1. static 成员的硬核特性全景图
- 共享与存储 :静态成员变量为所有类对象所共享,不属于某个具体的对象。它不存在于对象内部 (不计入
sizeof(对象)的大小),而是存放在内存的静态区。 - 初始化铁律 :静态成员变量一定要在类外进行初始化 。严禁 在类内声明位置给缺省值!因为缺省值是给构造函数初始化列表准备的,而静态成员变量不属于某个具体的对象,根本不走构造函数初始化列表。
- static 成员函数与 this 指针 :静态成员函数最大的特点就是没有
this指针 !因此,静态成员函数中绝对不能访问非静态的成员,只能访问其他的静态成员。 - 非静态的"特权" :虽然静态函数有严格限制,但非静态的普通成员函数,可以随意访问任意的静态成员变量和静态成员函数。
- 突破类域的访问方式 :外部想要访问静态成员时,可以通过
类名::静态成员(最推荐,直接体现类级别的共享特质)或者对象.静态成员的方式来访问。 - 受制于访问限定符 :别以为加了
static就能在外部为所欲为,静态成员依然是类的成员,必须严格受public、protected、private访问限定符的限制。
参考下面代码帮助理解
cpp
// 实现一个类,计算程序中创建出了多少个类对象
#include<iostream>
using namespace std;
class A
{
public:
// 无参构造函数:对象创建时自动调用,对象计数+1
A()
{
++_scount;
}
// 拷贝构造函数:用已有对象创建新对象时调用,对象计数+1
A(const A& t)
{
++_scount;
}
// 析构函数:对象生命周期结束时自动调用,对象计数-1
~A()
{
--_scount;
}
// 静态成员函数:获取当前存活的类对象总数
static int GetACount()
{
return _scount;
}
private:
// 静态成员变量:统计对象总数,类内声明
static int _scount;
};
// 静态成员变量必须类外初始化,初始值为0
int A::_scount = 0;
int main()
{
// 未创建任何对象,输出初始计数0
cout << A::GetACount() << endl;
// 调用2次无参构造,创建2个对象,计数+2
A a1, a2;
// 调用拷贝构造,创建1个对象,计数+1
A a3(a1);
// 类名::静态成员函数 方式调用,输出当前对象总数
cout << A::GetACount() << endl;
// 对象.静态成员函数 方式调用,效果与上面完全一致
cout << a1.GetACount() << endl;
// 编译报错:error C2248: "A::_scount": 无法访问 private 成员(在"A"类中)
//cout << A::_scount << endl;
return 0;
}2. ⚔️ 实战演练:牛客网高频题(求1+2+...+n)
题目链接:牛客网高频题(求1+2+...+n)
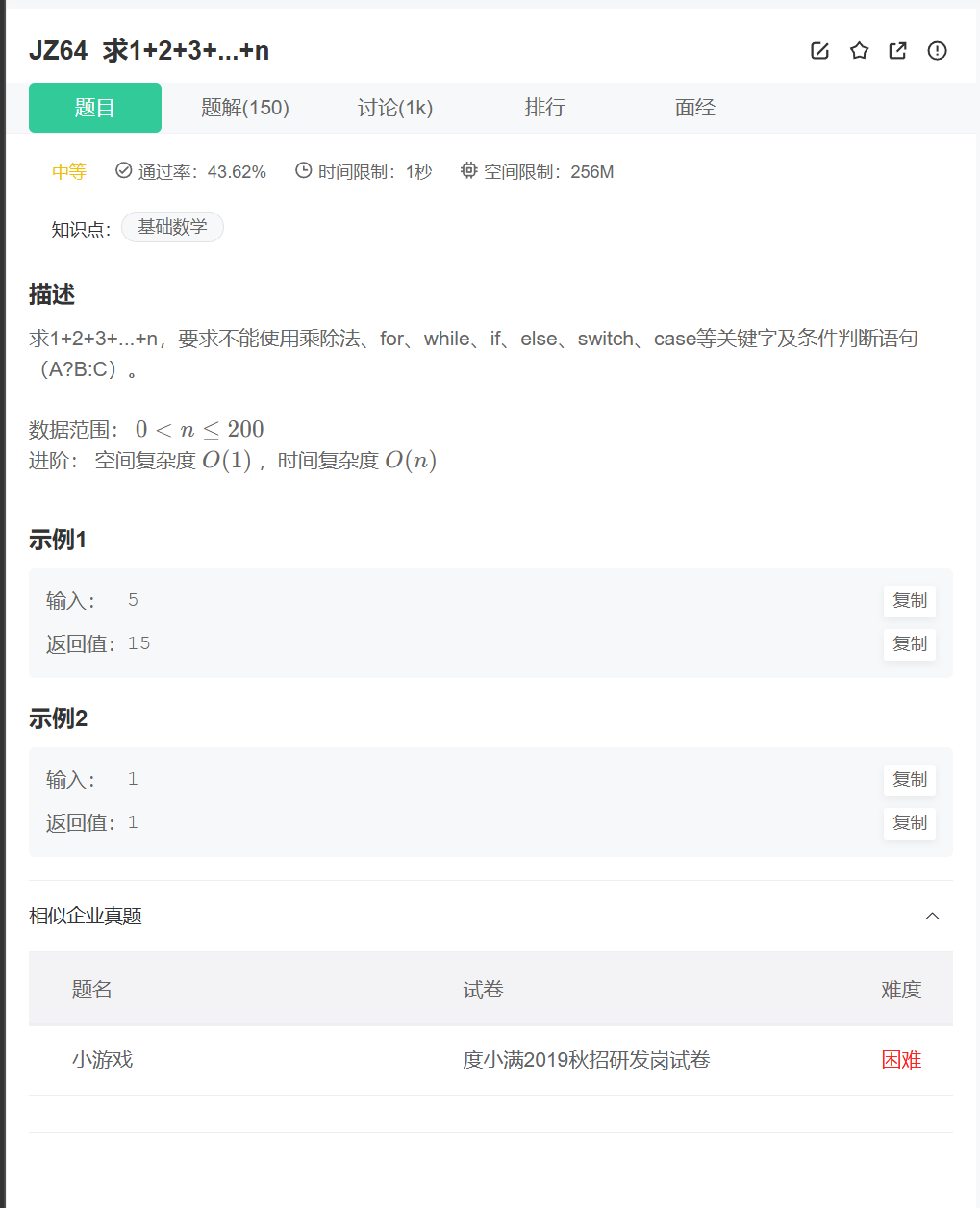
题目限制 :不能使用乘除法、for、while、if、else、switch、case 等关键字及条件判断语句。
开发思路剖析 :这简直是为 C++ 面向对象量身定制的题!不能写循环,那我们就利用对象的生命周期 。当我们需要实例化 n 个对象时,构造函数就会被雷打不动地自动调用 n 次 !
如果我们定义两个 static 全局变量,每次调用构造函数时让它们自增并累加,然后利用"变长数组"瞬间创建 n 个对象,循环的逻辑不就隐式实现了吗?
cpp
class Sum
{
public:
Sum()
{
_ret += _i;
++_i;
}
static int GetRet()
{
return _ret;
}
private:
static int _i;
static int _ret;
};
int Sum::_i = 1;
int Sum::_ret = 0;
class Solution
{
public:
int Sum_Solution(int n)
{
// 变长数组
Sum arr[n];
return Sum::GetRet();
}
};这道题完美地将 static 的共享特性与构造函数的自动化机制结合在了一起。
四、终极笔试题:全局、局部、静态对象的构造与析构顺序
在 C++ 面试和笔试中,关于对象生命周期的考查极其高频,且极易踩坑。请看下面这道大厂经典真题:
假设已经有 A, B, C, D 四个类的定义:
cpp
C c;
int main()
{
A a;
B b;
static D d;
return 0;
}灵魂拷问:它们的构造顺序和析构顺序分别是什么?
🔍 深度时间线解析:
-
构造顺序(按出生时间):
- 全局对象
C c;:它的作用域是全局,因此在main函数执行之前,操作系统装载程序时它就已经必须构造完成了!(所以c最先出生)。 - 局部对象
A a; B b;:程序执行流进入main,按代码从上到下的顺序依次构造(所以先a后b)。 - 静态局部对象
static D d;:静态局部变量比较特殊,它存放在静态区,但它的构造时机是程序第一次执行到该语句 时(所以d最后出生)。 - 结论:构造顺序是
C -> A -> B -> D(第一题选 E)。
- 全局对象
-
析构顺序(核心陷阱):
- 析构的宏观铁律是:后构造的先析构(栈的 LIFO 后进先出原则)。
- 局部对象先死 :当
main函数执行到return 0;时,局部变量立刻销毁。按后进先出,所以b先死,然后a死。 - 静态对象与全局对象后死 :它们都在静态区,生命周期伴随整个进程。当
main函数彻底结束后,进程才去统一清理静态区。清理顺序依然是"后构造的先析构"(因为d比c后构造,所以d先死,全局的c熬到最后才死)。 - 结论:析构顺序是
B -> A -> D -> C(第二题选 B)。
只要记住这句顺口溜:全局最先造、局部按顺序、静态首次造;析构看反向、局部先入土、静态全局熬到最后,这类题目绝对秒杀!
完全没问题!把"友元"和"内部类"混在一起确实容易让读者抓不住重点,而且干巴巴的文字缺乏说服力。
我根据你提供的课件截图和 PDF 文件,将这一块内容彻底拆分 成了两个独立的大模块:"五、友元(Friend)" 和 "六、内部类(Nested Class)" ,并且为你补充了极其直观的代码示例 和底层逻辑拆解。
你可以直接复制下面这部分内容,替换掉你原来文章里的第五部分:
五、友元:打破封装的"合法后门"
面向对象讲究极致的封装,类就像一个铁桶。但有时候封装太死,反而让特定的外部操作(比如两个类之间频繁的数据交互,或者重载 << 操作符)变得极其繁琐。为了在严格的封装中开辟一条绿色通道,C++ 引入了友元(friend)。
友元提供了一种突破类访问限定符封装的方式,分为友元函数 和友元类。
1. 友元函数
如果在类里面用 friend 声明一个外部函数,这就等于告诉编译器:"这个函数是我兄弟,放行!"这个外部函数就可以无视访问权限,直接访问类的 private 和 protected 成员。
核心规则:
- 友元函数不是类的成员函数,它仅仅是一种声明。
- 可以在类定义的任何地方声明,不受
public/private访问限定符的限制。 - 一个函数可以是多个类的友元函数。
代码演示
cpp
class A
{
// 友元声明:告诉A,func是我们的朋友
friend void func(const A& aa);
private:
int _a1 = 1;
};
// func 是一个普通的全局函数
void func(const A& aa)
{
// 因为是友元,所以可以直接访问 aa 的私有成员 _a1
cout << "友元函数访问私有成员: " << aa._a1 << endl;
}2. 友元类
如果你想让另一个类的所有成员函数都能访问当前类的私有成员,可以直接把那个类声明为友元类。
🚨 友元类规则:
- 单向性:A 是 B 的友元(A 能看 B 的隐私),不代表 B 是 A 的友元(B 不能看 A 的)。
- 不能传递 :A 是 B 的友元,B 是 C 的友元,这不代表 A 是 C 的友元。
代码演示:
cpp
class A
{
// 友元声明:类B是我的好朋友
friend class B;
private:
int _a1 = 1;
};
class B
{
public:
void PrintA(const A& aa)
{
// B的所有成员函数都能直接访问A的私有成员!
cout << "友元类B访问A的私有成员: " << aa._a1 << endl;
}
};💡 开发忠告 :友元虽然提供了便利,但它极大地增加了代码的耦合度,破坏了面向对象的封装性。在实际工程中,友元不宜多用,慎用!
六、内部类
内部类顾名思义就是一个类定义在另一个类的内部,内部那个类。很多初学者对内部类有误解,认为外部类包含了内部类,其实大错特错!
1. 内部类的特性
- 绝对的独立性 :内部类是一个完全独立的类!外部类定义的实例对象中,根本不包含 内部类。也就是说,
sizeof(外部类)的大小计算,和内部类没有半毛钱关系。内部类只是受外部类的类域和访问限定符限制而已。 - 天生的高级权限 :内部类默认就是外部类的友元类! 内部类可以直接访问外部类的所有
static成员和私有成员。但是反过来,外部类没有任何特权去访问内部类。
代码演示:内部类如何窃取外部类的机密
cpp
class Outer
{
private:
static int _k; // 外部类的静态私有成员
int _h = 1; // 外部类的普通私有成员
public:
// Inner 定义在 Outer 内部
class Inner
{
public:
void foo(const Outer& o)
{
// 内部类天生是友元,可以直接访问外部类的私有静态变量 _k
cout << "访问外部类 static 成员: " << _k << endl;
// 也可以直接访问外部类对象的私有成员 _h
cout << "访问外部类普通成员: " << o._h << endl;
}
};
};
int Outer::_k = 100;
int main()
{
Outer out;
Outer::Inner in; // 突破类域创建内部类对象
in.foo(out);
// cout << sizeof(Outer) << endl; // 结果为4(只包含_h,不包含_k和Inner)
return 0;
}2. 工程实战:专属内部类
内部类本质上是一种极致的封装手段 。
当类 A 和类 B 紧密关联,且类 A 的存在主要就是为了给类 B 提供服务时,我们可以直接把类 A 设计成类 B 的内部类。
绝杀技 :如果我们把内部类放到 private 或 protected 位置,那么这个内部类就成了外部类的专属内部类,整个系统里除了外部类,谁都用不了它!
(还记得我们在讲 static 成员时,拆解的那道牛客网求 1+2+...+n 的题目吗?)
在之前的写法中,我们把 Sum 类和 Solution 类分开写了。虽然功能实现了,但 Sum 暴露在了全局作用域中,这意味着别人也可以随意实例化 Sum 对象,这极大地破坏了封装性,也不够优雅。
现在,我们利用专属内部类的绝杀技,对这段代码进行终极改造:
cpp
class Solution
{
private:
// 将 Sum 隐藏在 private 区域,成为 Solution 的专属内部类!
class Sum
{
public:
Sum()
{
_ret += _i;
++_i;
}
};
static int _i;
static int _ret;
public:
int Sum_Solution(int n)
{
// 外部依然正常调用,但底层彻底隐藏了 Sum 的存在
Sum arr[n];
return _ret;
}
};
// 静态变量依然在类外初始化
int Solution::_i = 1;
int Solution::_ret = 0;七、匿名对象和有名对象
对于偏向工程开发的程序员来说,写出功能正确的代码只是及格,能洞察底层的内存开销并榨干编译器的性能,才是真正的进阶!
1.概念
-
用
类型(实参)定义出来的对象叫做匿名对象 ,相比之前我们定义的类型 对象名(实参)定义出来的叫有名对象。 -
匿名对象生命周期只在当前一行,一般临时定义一个对象当前用一下即可,就可以定义匿名对象。
如:A obj(1)------有名对象
A()或A(1)------匿名对象
2.实战场景
如果我们需要临时调用某个类里的函数,专门为它实例化一个有名对象实在太浪费内存存活时间了。这时候匿名对象简直就是神兵利器:
cpp
// 传统的土味写法:
Solution s;
s.Sum_Solution(10); // s 在整个函数结束前一直占用栈空间
// 高级极客写法(一行搞定,干净利落):
Solution().Sum_Solution(10); // 创建匿名对象,调完函数当场析构释放资源!八、对象拷贝时的编译器优化(编译器的极致优化)
编译器的极致优化
在 C++ 工程中,对象的传值传参 和传值返回 往往伴随着高昂的拷贝开销(调用拷贝构造函数)。
现代编译器(如 VS2019 / VS2022 / GCC 等)为了追求极致的执行效率,会在不影响代码逻辑正确性的前提下,偷偷帮我们砍掉大量不必要的"拷贝构造"步骤。
场景 A:参数传递时的优化(合并构造)
cpp
void f1(A aa) {}
int main()
{
// 1. 隐式类型转换:连续构造 + 拷贝构造 -> 优化为直接构造!
f1(1);
// 2. 匿名对象传参:连续构造 + 拷贝构造 -> 同样优化为一个构造!
f1(A(2));
return 0;
}底层逻辑 :编译器极其聪明,它发现你造了一个临时对象/匿名对象,唯一的目的就是为了拷贝给形参 aa,它觉得这纯属脱裤子放屁,于是直接在参数 aa 的空间里完成了原地构造!
场景 B:传值返回的极致压榨
这是一道极度考验 C++ 基本功的终极考题:下面这段代码到底产生了多少次拷贝?
cpp
A f2()
{
A aa; // 局部对象构造
return aa; // 传值返回
}
int main() {
A obj = f2();
return 0;
}为了让你彻底看清编译器的进化史,我们分三个维度来拆解:
无优化时代的理论开销(原教旨主义):
f2内部构造局部对象aa(1次构造)。return时,把aa拷贝给一个临时对象(1次拷贝构造)。aa析构销毁。- 把临时对象拷贝构造给外部的
obj(又1次拷贝构造)。 - 临时对象析构销毁。
(总计:1次构造 + 2次拷贝。开销极大!)
-
主流编译器(如 VS2019)的合并优化 :
它发现临时对象实在太多余了,于是在返回时,直接把局部的
aa拷贝构造给了外部的接收对象obj,省去了一个中间商(临时对象)。
(总计:1次构造 + 1次拷贝) -
现代超强编译器(如 VS2022 / 新版 GCC)的跨行终极优化(NRVO) :
编译器开了天眼,进行了跨行跨表达式的合并 !它发现你最终的目的就是要把局部的
aa交给外部的obj。于是它大笔一挥,根本就不在f2内部的栈帧里为aa开辟空间了,而是直接在外部obj的内存空间上完成构造 !底层实现上,aa变成了obj的引用。
(总计:合三为一!0 次拷贝!只有 1 次纯粹的直接构造!)
建议
- 如果对象的生命周期足够长(出了作用域还在),能用传引用返回 (
A&),就坚决用引用。- 如果因为是局部对象,必须传值返回 ,也千万别因为害怕性能损失而写出极其别扭的代码(比如强行把对象指针传进去当输出参数)。现代编译器会自动为你开启 RVO/NRVO 优化,直接把中间的拷贝抹平!放心大胆地传值返回,把优化的脏活累活丢给编译器,这才是现代 C++ 优雅的工程美学!
结束语
嗨ヾ(o´∀`o)ノ!至此,我们通过三篇长达数万字的硬核拆解,终于把"类和对象"这座 C++ 初学者面前最大的大山彻底挖穿了!
从第一篇的底层 this 指针,到第二篇手撕六大默认成员函数,再到本篇死磕初始化列表、内存模型生命周期以及现代编译器的极致性能榨取。
接下来的旅程,我们将迈入 C++ 的深水区------内存管理(new/delete)和神奇泛化武学(模板机制)。大家记得好好吸收这三篇的精华,别忘了点赞收藏,我们下一篇不见不散!φ(>ω<*)
