目录
[InfiniLM 技术架构演进](#InfiniLM 技术架构演进)
[1. 张量模块](#1. 张量模块)
[2. 算子模块](#2. 算子模块)
[3. 适配 Qwen-1.5B 文本生成](#3. 适配 Qwen-1.5B 文本生成)
[选项 1:CPU 加速](#选项 1:CPU 加速)
[选项 2:CUDA、类 CUDA 加速](#选项 2:CUDA、类 CUDA 加速)
[选项 3:实现聊天机器人](#选项 3:实现聊天机器人)
[选项 4、5、6](#选项 4、5、6)
本文将深入讲解 InfiniLM 的技术架构、作业项目要求、国产化部署策略以及实际工程案例。
InfiniLM 技术架构演进
框架版本迭代

InfiniLM 经历了重要的架构演进:
-
• Infra IM Rust:早期基于 Rust 的推理框架
-
• Infra Infer:新一代 C++ 推理框架,替代 Rust 版本
-
• Infra Core:底层算子库,保持稳定
选择 C 而非 Rust 的主要考虑是生态落地的便利性------尽管 Rust 在安全性和性能上有优势,但 C 在 AI 领域的工具链和社区支持更为成熟。
整体架构设计
InfiniLM 采用分层架构设计:
-
• Python 层:提供用户友好的 API 接口
-
• ctypes 层:C++ 与 Python 的桥梁
-
• C++ 核心层:包含内存管理、算子实现、模型适配等
-
• 设备运行时层:抽象不同硬件平台的差异
核心组件解析
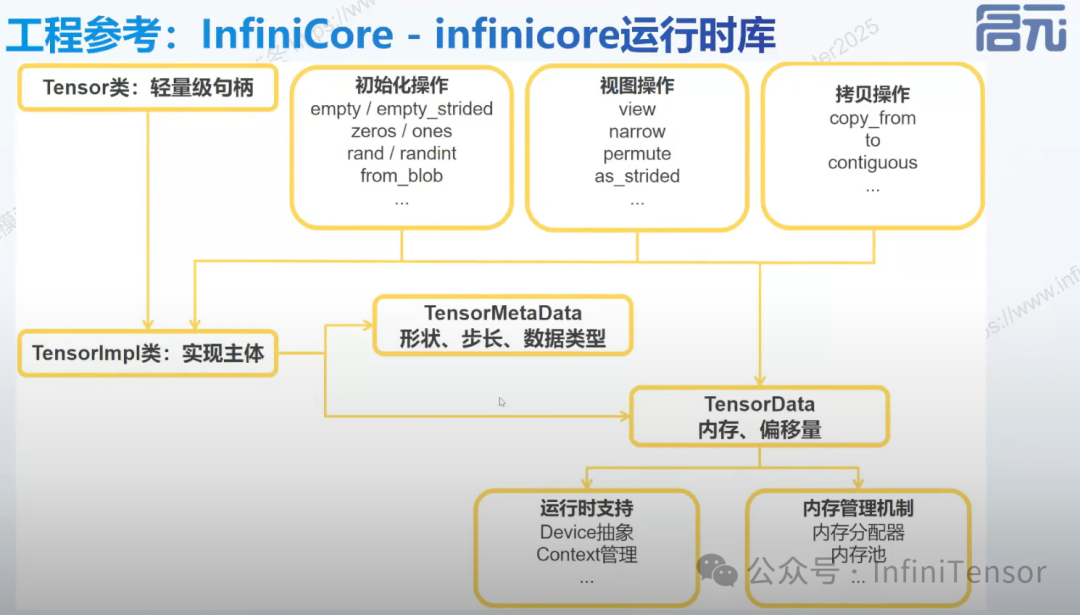
- 内存管理器(Allocator)
内存分配策略对推理性能影响巨大:
-
• 频繁分配/释放:带来不可忽略的开销
-
• 内存池设计:通过复用内存减少分配开销
-
• 优化建议:实现高效的内存池系统是性能优化的关键
- 上下文管理(Context)
上下文管理负责设备类型的识别:
-
• 设备检测:自动识别 CPU、NVIDIA GPU、国产 GPU 等
-
• 运行时切换:根据设备类型动态选择最优实现
- 张量操作(Tensor)
张量是大模型推理的核心数据结构:
-
• 生命周期管理:创建、销毁、引用计数
-
• 元信息操作:形状、步长、连续性判断
-
• 视图变换:narrow、permute、view 等操作
作业项目实战指南
环境配置要求
作业项目的环境配置包括:
-
• 编译工具:xmake、GCC/Clang、NVCC(GPU 平台)
-
• Python 依赖:PyTorch、Transformers
-
• 构建流程 :
xmake build→xmake install→pip install
核心模块实现
1. 张量模块

2. 算子模块
作业要求实现的核心算子包括:
-
• Argmax:用于确定性采样,选择概率最大的 token
-
• Embedding:将 token ID 转换为向量表示
-
• Linear:线性变换(矩阵乘法),大模型的核心算子
-
• RMS_Norm:归一化操作,提升训练稳定性
-
• RoPE:旋转位置编码,保持位置关系
-
• Self_Attention:注意力机制,可选择 Flash Attention 实现
-
• SwiGLU:激活函数,element-wise 计算
-
• Rearrange:张量重排,改变内存布局
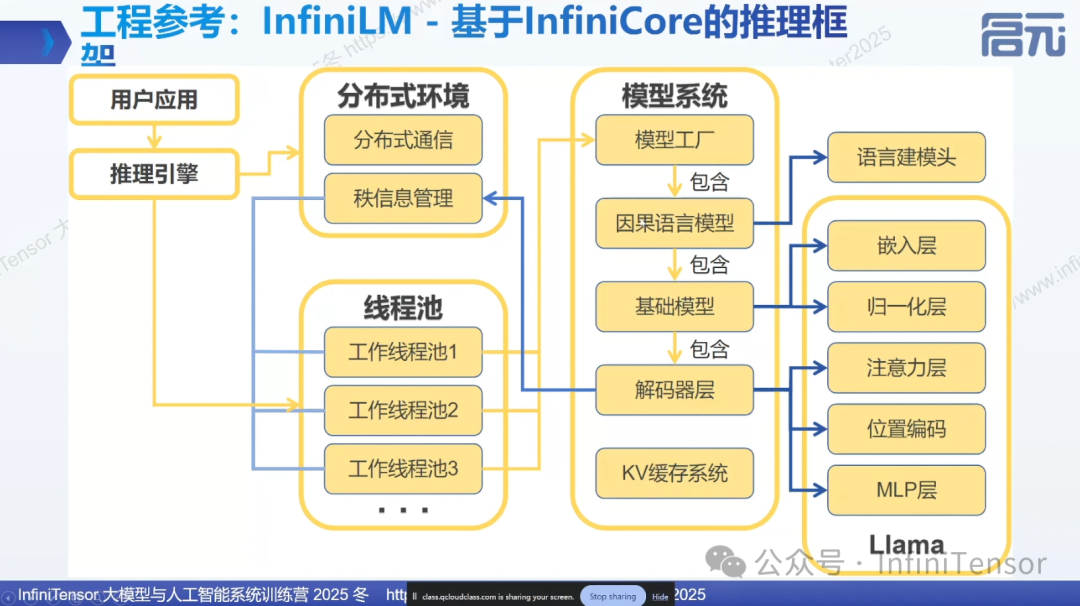
3. 适配 Qwen-1.5B 文本生成
-
• Python 前端:实现 Qwen 模型的 Python 接口
-
• 主要实现:src/
-
• ctypes 封装:python/llaisys/libllaisys/
-
• KV Cache:必须实现,避免重复计算
调试工具:
-
• debug 函数:打印张量信息,辅助精度调试
-
• 推理测试:
test/test_infer.py验证推理正确性
项目进阶方向
选项 1:CPU 加速

虽然作业要求在 CPU 上实现,但 CPU 推理性能较差,可通过以下方式优化:
-
• SIMD 指令:使用向量化指令并行处理多个数据
-
• OpenMP 并行 :通过
#pragma omp parallel for实现循环并行 -
• 第三方库:Eigen、OpenBLAS、MKL 等数学库
选项 2:CUDA、类 CUDA 加速
项目要求至少两个硬件平台:
-
• 天数 GPU:类 CUDA 架构,接口命名差异较低
-
• 沐曦 GPU:类 CUDA 架构,接口命名略有差异
-
• 摩尔 GPU:类 CUDA 架构,接口命名略有差异
国产平台优势:
-
• 战略意义:算力是重要的战略资源
-
• 技术兼容:类 CUDA 架构降低适配成本
-
• 生态支持:多家厂商已上市,生态日趋成熟
选项 3:实现聊天机器人

实现一个功能完整的聊天机器人:
-
• 随机采样:支持 Top-K 和 Top-P 采样策略
-
• HTTP 服务器:支持 OpenAI Chat-Completion API
-
• 流式输出:实现实时响应
-
• 会话管理:支持 KV Cache 缓存和历史对话编辑
选项 4、5、6
-
• 多用户推理:需要先完成 3,算子需要支持 batch
-
• 分布式推理:引入张量并行,使用 nccl、mccl、hccl 等通信库
-
• 支持新模型:适配架构差异较大的新模型
实际工程案例
基础库

-
• 运行时:infinirt
-
• 通信库:infiniccl
-
• 算子库:infiniop
运行时库

推理框架

总结
InfiniLM 不仅是一个学习大模型推理系统的优秀项目,更是推动国产 AI 芯片生态建设的重要工具。通过完整的工程实践,可以深入理解大模型推理的各个环节,同时为国产化部署积累宝贵经验。