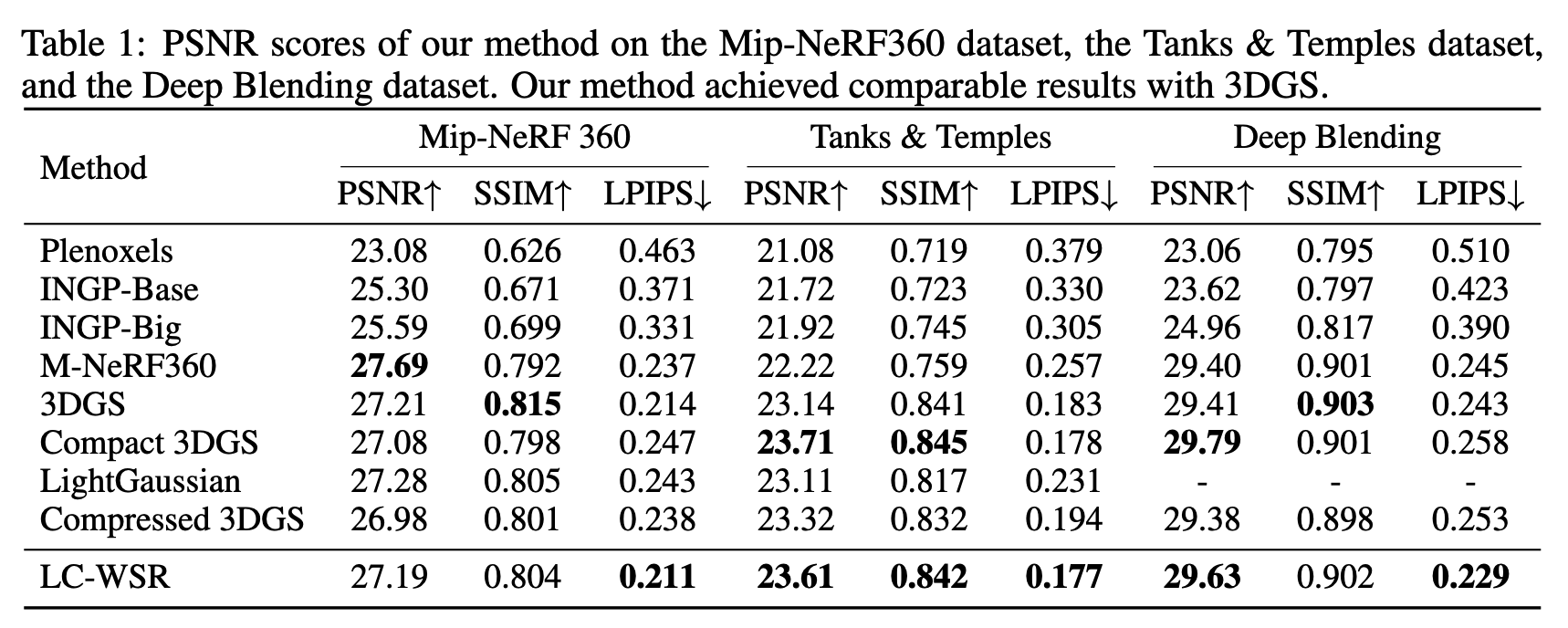
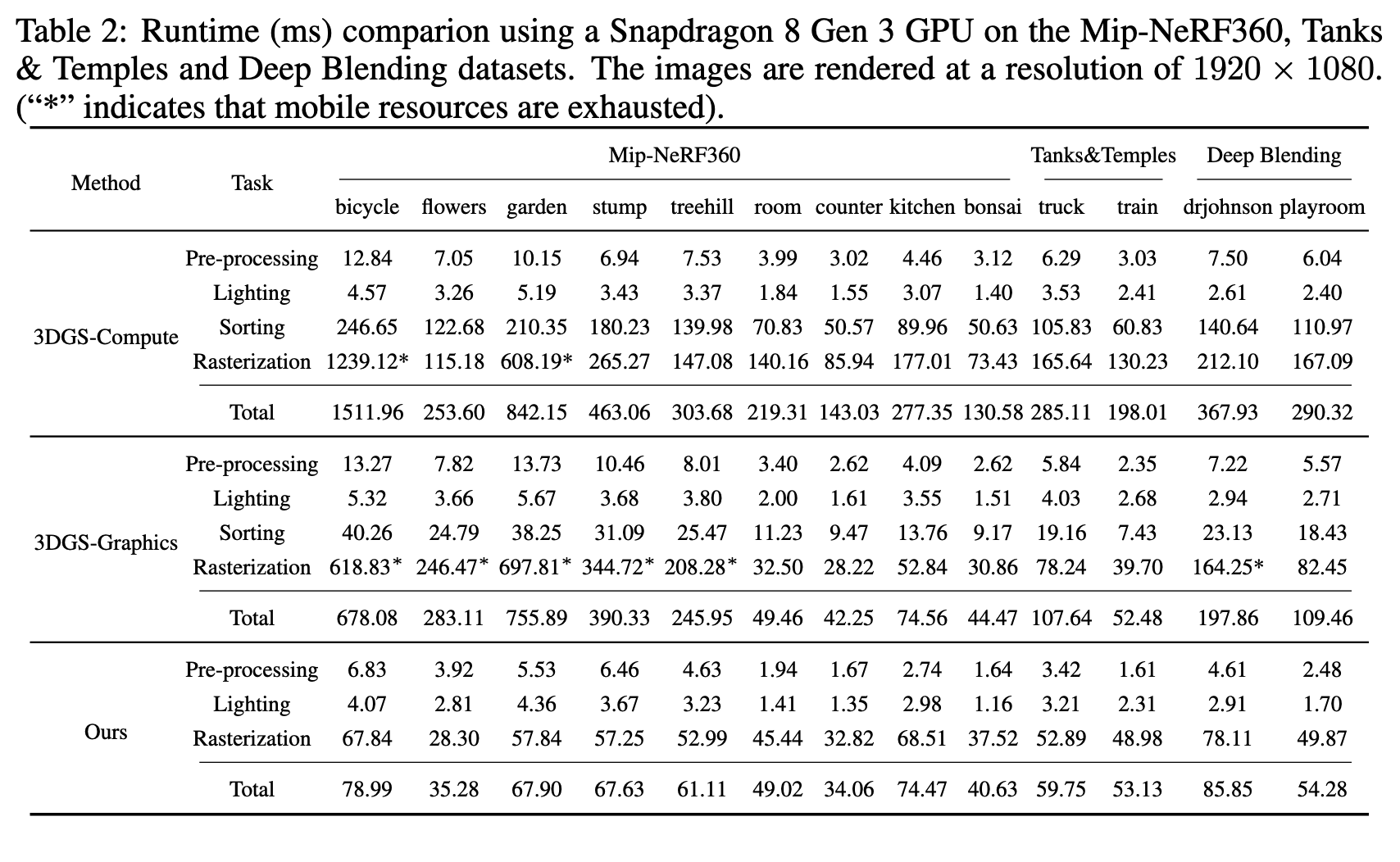
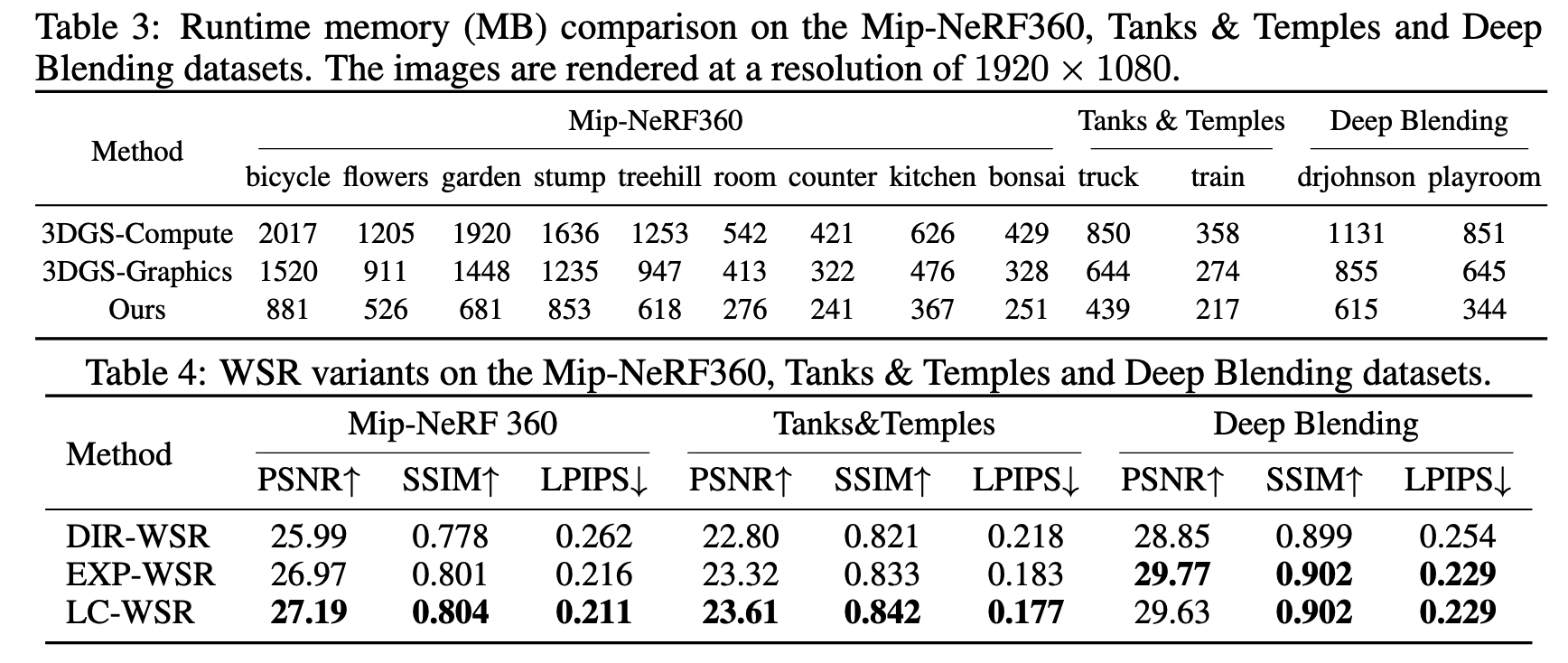
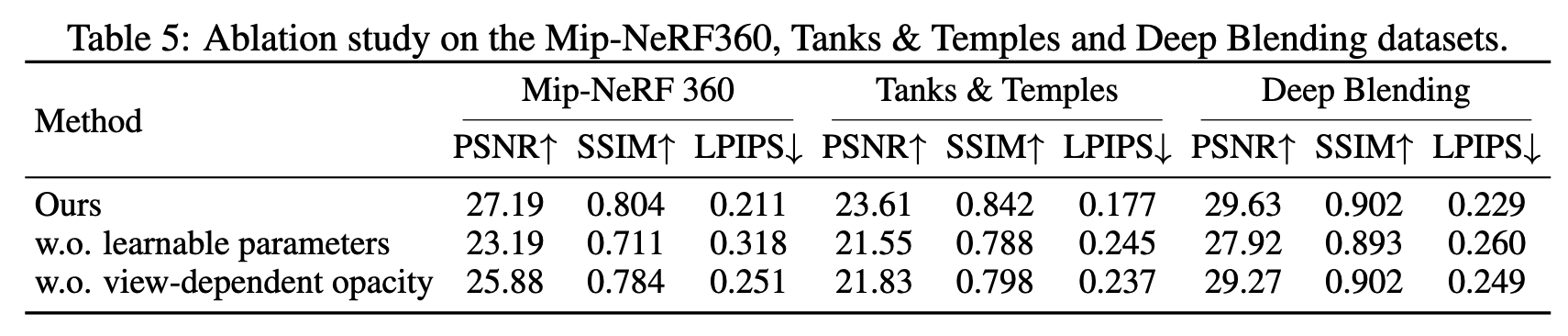
C = α 0 c 0 + ( 1 − α 0 ) c 1 ( 1 ) C=\alpha_0 c_0+(1-\alpha_0)c_1 \quad(1) C=α0c0+(1−α0)c1(1)
其中, α \alpha α 和 c c c 分别表示 alpha 和颜色。由于 OVER 算子不是可交换的,因此它要求按从后到前的顺序进行合成。传统方法通常通过逐层"剥离"深度层 Everitt (2001),或者像 A-buffer Carpenter (1984) 那样累积列表以便排序来加速。这些方法会引入时间和内存开销。
为了避免排序,人们提出了许多用于近似合成的方法,即顺序无关透明性(OIT)。例如,k-buffer 方法类似于深度剥离方法,但只在单次遍历中存储并累积前 k k k 层 Bavoil et al. (2007)。另一种方法是蒙特卡洛渲染中的随机透明性方法,它根据不透明度和深度对片元进行采样;在采样率较高时,这种方法可以产生很有前景的结果 Enderton et al. (2010)。关于这些方法的综述可参见 Wyman (2016)。
C = ∏ i = 1 N ( 1 − α i ) c 0 + ( 1 − ∏ i = 1 N ( 1 − α i ) ) ∑ i = 1 N c i α i w ( d i , α i ) ∑ i = 1 N α i w ( d i , α i ) ( 2 ) C=\prod_{i=1}^{N}(1-\alpha_i)c_0+\left(1-\prod_{i=1}^{N}(1-\alpha_i)\right)\frac{\sum_{i=1}^{N} c_i \alpha_i w(d_i,\alpha_i)}{\sum_{i=1}^{N}\alpha_i w(d_i,\alpha_i)} \quad(2) C=i=1∏N(1−αi)c0+(1−i=1∏N(1−αi))∑i=1Nαiw(di,αi)∑i=1Nciαiw(di,αi)(2)
其中, d i d_i di 是到相机的距离, c 0 c_0 c0 是背景颜色, w ( ⋅ ) w(\cdot) w(⋅) 是一个随距离增大而减小的函数,因此距离相机更近的物体会被赋予更大的权重。在式(2)的 OIT 渲染中,有两个求和项定义了像素值,并且由于加法是可交换的,它们可以按任意顺序计算。受 OIT 启发,论文通过引入可学习参数和视角相关不透明度,将其扩展到 Gaussian Splatting。此外,与 OIT 的指数权重相比,线性权重在 Gaussian Splatting 中能产生更好的 PSNR 结果。
3DGS 的场景模型 G = ( p i , t i , q i , s i , H i ) i = 1 N G={(p_i,t_i,q_i,s_i,H_i)}_{i=1}^{N} G=(pi,ti,qi,si,Hi)i=1N 表示一个由 N N N 个高斯组成的场景,其中中心位置 p ∈ R 3 p\in\mathbb{R}^3 p∈R3,最大不透明度 t i ∈ 0 , 1 t_i\in0,1 ti∈0,1,朝向 q ∈ R 4 q\in\mathbb{R}^4 q∈R4,尺度 s ∈ R 3 s\in\mathbb{R}^3 s∈R3,以及球谐系数 H H H,其形式遵循与高斯概率分布类似的方程。三维空间中位置 x x x 处每个元素的不透明度定义为:
α i ( x ) = t i exp ( − ( x − p i ) t Σ ( q i , s i ) − 1 ( x − p i ) 2 ) , i = 1 , 2 , ⋯ , N ( 3 ) \alpha_i(x)=t_i\exp\left(-\frac{(x-p_i)^t\\Sigma(q_i,s_i)^{-1}(x-p_i)}{2}\right),\ i=1,2,\cdots,N \quad(3) αi(x)=tiexp(−2(x−pi)tΣ(qi,si)−1(x−pi)), i=1,2,⋯,N(3)
并且,考虑一个焦点位于位置 f f f 的相机,视角相关的颜色定义为:
c i = Y ( ∣ f − p i ∣ , H i ) , i = 1 , 2 , ⋯ , N , ( 4 ) c_i=Y(|f-p_i|,H_i),\ i=1,2,\cdots,N, \quad(4) ci=Y(∣f−pi∣,Hi), i=1,2,⋯,N,(4)
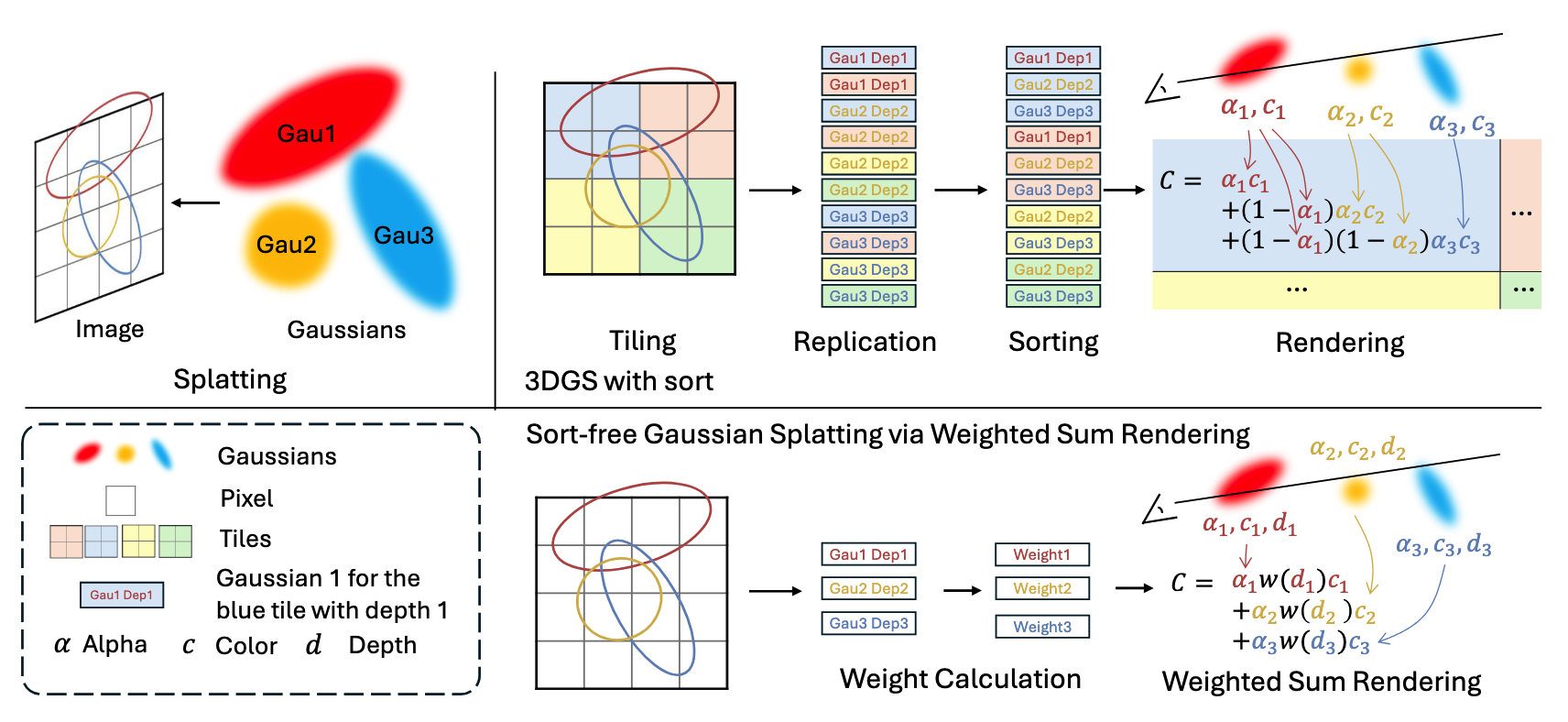
C = ∑ i = 1 N c i α i ∏ j = 1 i − 1 ( 1 − α j ) , ( 6 ) C=\sum_{i=1}^{N} c_i\alpha_i \prod_{j=1}^{i-1}(1-\alpha_j), \quad(6) C=i=1∑Nciαij=1∏i−1(1−αj),(6)
C = c B w B + ∑ i = 1 N c i α i w ( d i ) w B + ∑ i = 1 N α i w ( d i ) ( 7 ) C=\frac{c_B w_B+\sum_{i=1}^{N} c_i \alpha_i w(d_i)}{w_B+\sum_{i=1}^{N}\alpha_i w(d_i)} \quad(7) C=wB+∑i=1Nαiw(di)cBwB+∑i=1Nciαiw(di)(7)
其中, c B c_B cB 和 w B w_B wB 分别表示背景的颜色和可学习权重。 d d d 表示深度。 w ( ⋅ ) w(\cdot) w(⋅) 表示可学习的权重函数。论文网络在训练过程中学习 Gaussian 的参数。在 WSR 中使用式(7)进行渲染,对应于计算加权和。由于加法满足交换律,这些求和可以按任意顺序计算,从而克服了深度排序的限制。不同于依赖预定义参数的传统 OIT 方法 Meshkin (2007); McGuire & Bavoil (2013),论文方法在训练过程中对这种新表示的参数进行优化。
指数加权求和渲染(Exponential Weighted Sum Rendering,EXP-WSR)。为了更好地捕捉遮挡效应,论文引入 EXP-WSR,为更靠近相机的 Gaussian 分配更大的权重。其权重定义为:
w ( d i ) = exp ( − σ d i β ) , i = 1 , 2 , ⋯ , N , ( 9 ) w(d_i)=\exp(-\sigma d_i^{\beta}),\quad i=1,2,\cdots,N, \quad(9) w(di)=exp(−σdiβ),i=1,2,⋯,N,(9)
线性校正加权求和渲染(LC-WSR)。受可变形卷积 Dai et al. (2017) 和 KPConv Thomas et al. (2019) 的启发,论文使用线性校正根据深度来估计权重,即
w ( d i ) = max ( 0 , 1 − d i σ ) v i , i = 1 , 2 , ⋯ , N , ( 10 ) w(d_i)=\max\left(0,1-\frac{d_i}{\sigma}\right)v_i,\quad i=1,2,\cdots,N, \quad(10) w(di)=max(0,1−σdi)vi,i=1,2,⋯,N,(10)
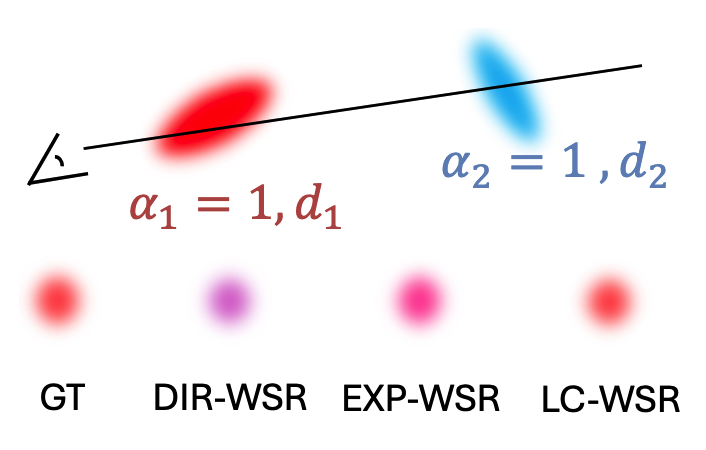
其中, σ , v i \sigma,v_i σ,vi 是可学习参数。该形式会为更靠近相机的 Gaussian 分配相对更大的权重。对于较远的 Gaussian,其权重可能会根据 σ \sigma σ 或 v i v_i vi 而减小到 0。如图3所示,由于该模型可以将权重设为 0,因此能够更准确地建模遮挡,其渲染结果最接近真实值。此外,与 EXP-WSR 相比,LC-WSR 的计算代价更低。
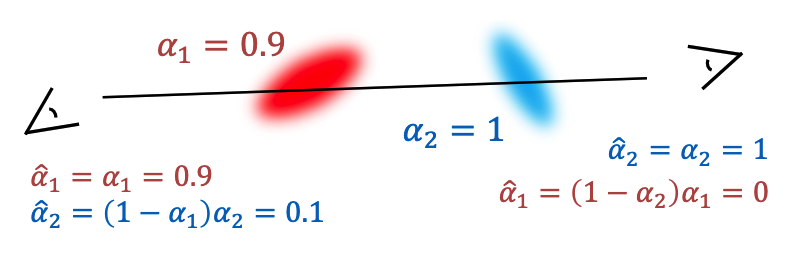
图4:视角相关不透明度。在3DGS中,累积的 α n \alpha_n αn 会根据观察者的方向而变化,这促使论文在无排序高斯溅射中分配与视图相关的不透明度。
论文用另一组用于视角相关性的球谐系数来替代不透明度值。这是论文减弱被遮挡 Gaussian 贡献的另一种机制。论文修改了式(3),该式定义了无排序 Gaussian 的不透明度,将 3DGS 元素的最大不透明度 t i ∈ 0 , 1 t_i\in0,1 ti∈0,1 替换为一个无约束值 u i u_i ui:
u i = Y ( ∣ f − p i ∣ , H i ) , i = 1 , 2 , ⋯ , N , ( 11 ) u_i=Y(|f-p_i|,H_i),\ i=1,2,\cdots,N, \quad(11) ui=Y(∣f−pi∣,Hi), i=1,2,⋯,N,(11)
其中, Y ( ⋅ ) Y(\cdot) Y(⋅) 表示球谐函数, ∣ ⋅ ∣ |\cdot| ∣⋅∣ 表示向量范数。 H i H_i Hi 表示用于不透明度的可学习球谐系数。因此,最大不透明度 u i u_i ui 根据学习得到的球谐参数向量 H i H_i Hi,依赖于视角方向 ∣ f − p i ∣ |f-p_i| ∣f−pi∣。
在论文的实现中,RGB 通道与不透明度的 SH 求值之间存在细微差别。最大不透明度 u i u_i ui 不进行截断。请注意,视角相关不透明度可能并不符合光学定律,但在实践中,它有助于减小 OIT 渲染式(7) 相对于体渲染式(6) 的局限性。