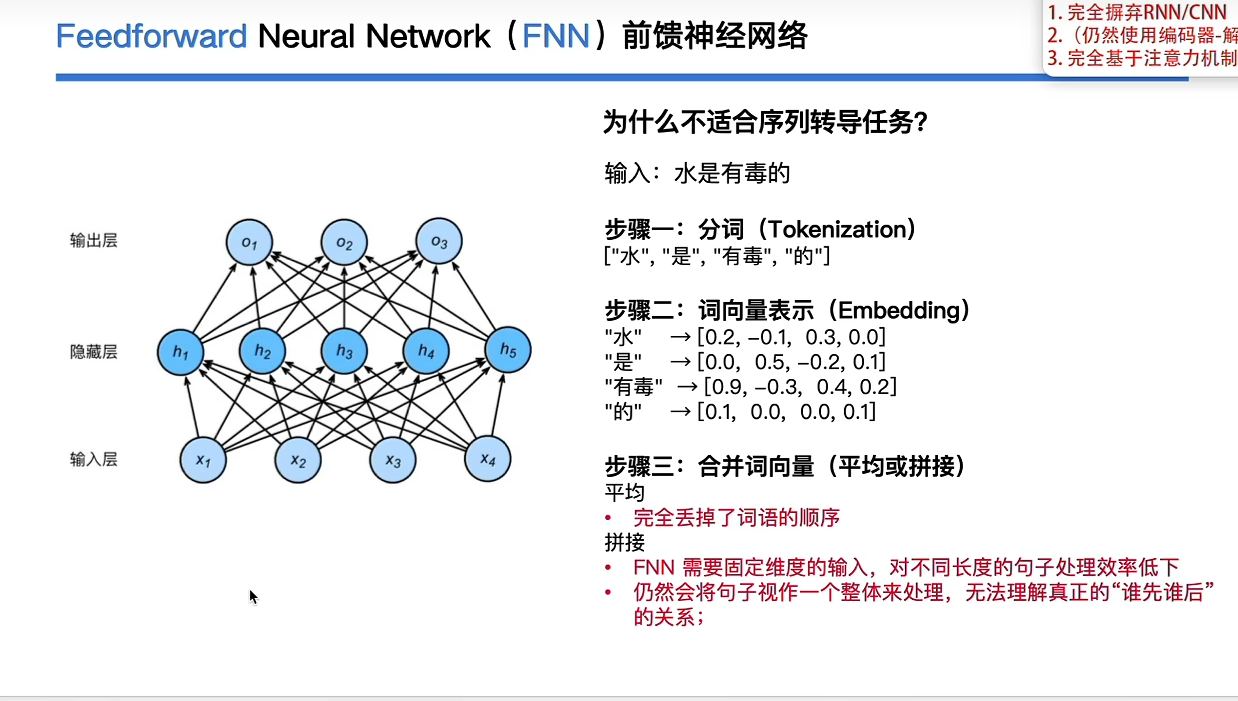
https://www.bilibili.com/video/BV1xoJwzDESD/?spm_id_from=333.788.top_right_bar_window_history.content.click&vd_source=f2dad693a9728ab4556a21aae7d6dfc3 https://www.bilibili.com/video/BV1xoJwzDESD/?spm_id_from=333.788.top_right_bar_window_history.content.click&vd_source=f2dad693a9728ab4556a21aae7d6dfc3https://www.bilibili.com/video/BV1pu411o7BE?spm_id_from=333.788.recommend_more_video.-1&trackid=web_related_0.router-related-2481894-74gx5.1774327367657.917&vd_source=f2dad693a9728ab4556a21aae7d6dfc3https://www.bilibili.com/video/BV1pu411o7BE?spm_id_from=333.788.recommend_more_video.-1&trackid=web_related_0.router-related-2481894-74gx5.1774327367657.917&vd_source=f2dad693a9728ab4556a21aae7d6dfc31.为什么前馈神经网络不适合序列转导任务
https://www.bilibili.com/video/BV1xoJwzDESD/?spm_id_from=333.788.top_right_bar_window_history.content.click&vd_source=f2dad693a9728ab4556a21aae7d6dfc3https://www.bilibili.com/video/BV1pu411o7BE?spm_id_from=333.788.recommend_more_video.-1&trackid=web_related_0.router-related-2481894-74gx5.1774327367657.917&vd_source=f2dad693a9728ab4556a21aae7d6dfc3https://www.bilibili.com/video/BV1pu411o7BE?spm_id_from=333.788.recommend_more_video.-1&trackid=web_related_0.router-related-2481894-74gx5.1774327367657.917&vd_source=f2dad693a9728ab4556a21aae7d6dfc31.为什么前馈神经网络不适合序列转导任务
**前馈神经网络主要是增强模型的非线性表达性
2.激活函数
先看:没有激活函数会怎样?
你之前学的:输入 × 权重 + 偏置全是 线性计算(就是加减乘)。
哪怕你叠 100 层神经网络:
- 线性 + 线性 + 线性 ...... 最终还是 线性
- 只能拟合直线、简单关系
- 根本学不会:图片分类、语音、复杂规律
没有激活函数 → 神经网络 = 高级线性回归,啥复杂任务都干不了。
激活函数干了啥?
它在每一层神经元后面,做一件事:把线性的结果 "掰弯",变成非线性。
就像给神经元加一个开关 / 过滤器:
- 有的信号太弱,直接过滤掉
- 有的信号够强,正常输出
- 把直线变成曲线
这样神经网络才能:
- 学曲线
- 学边缘、纹理、形状
- 学复杂逻辑、分类、识别
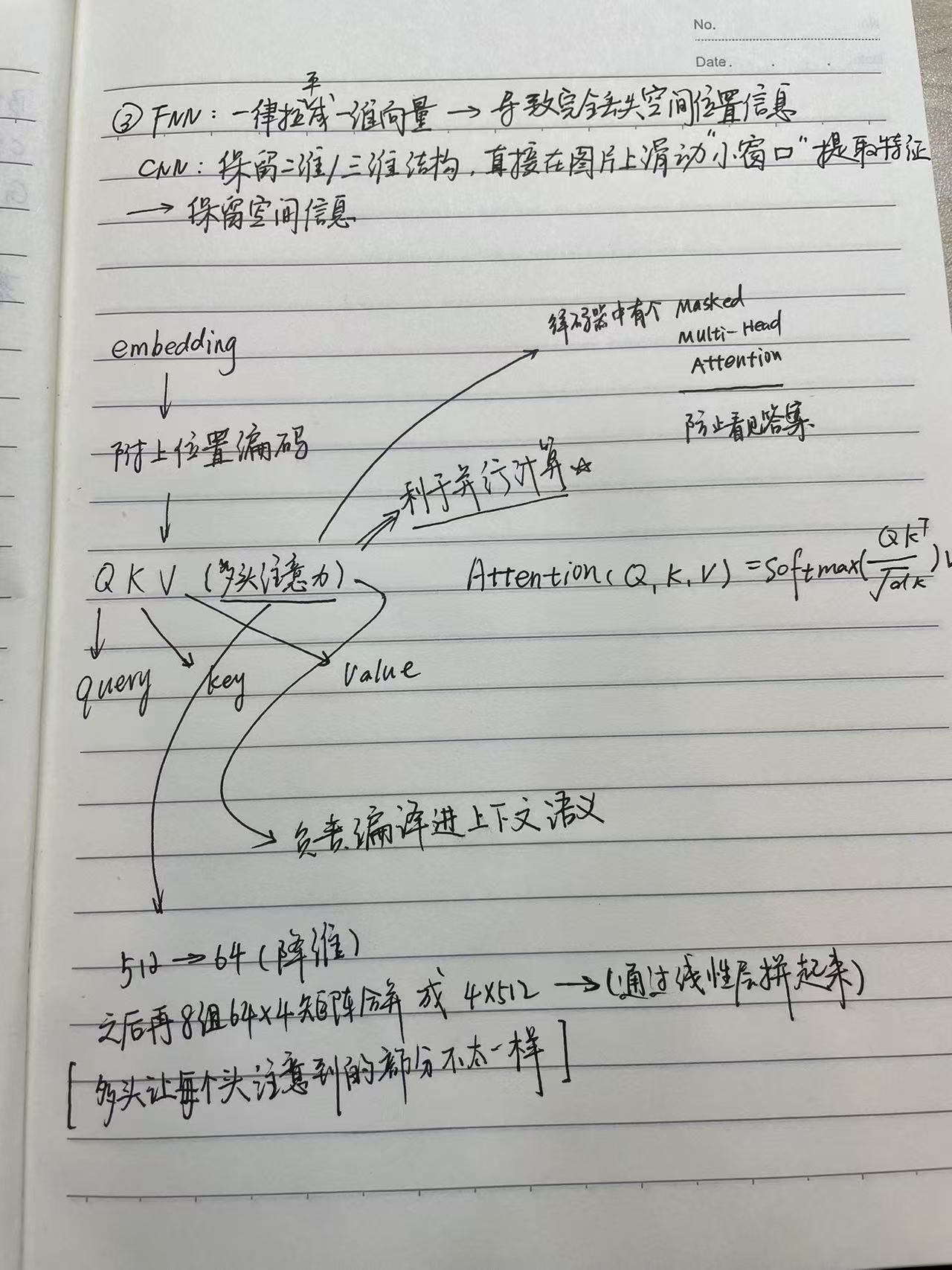
3.RNN
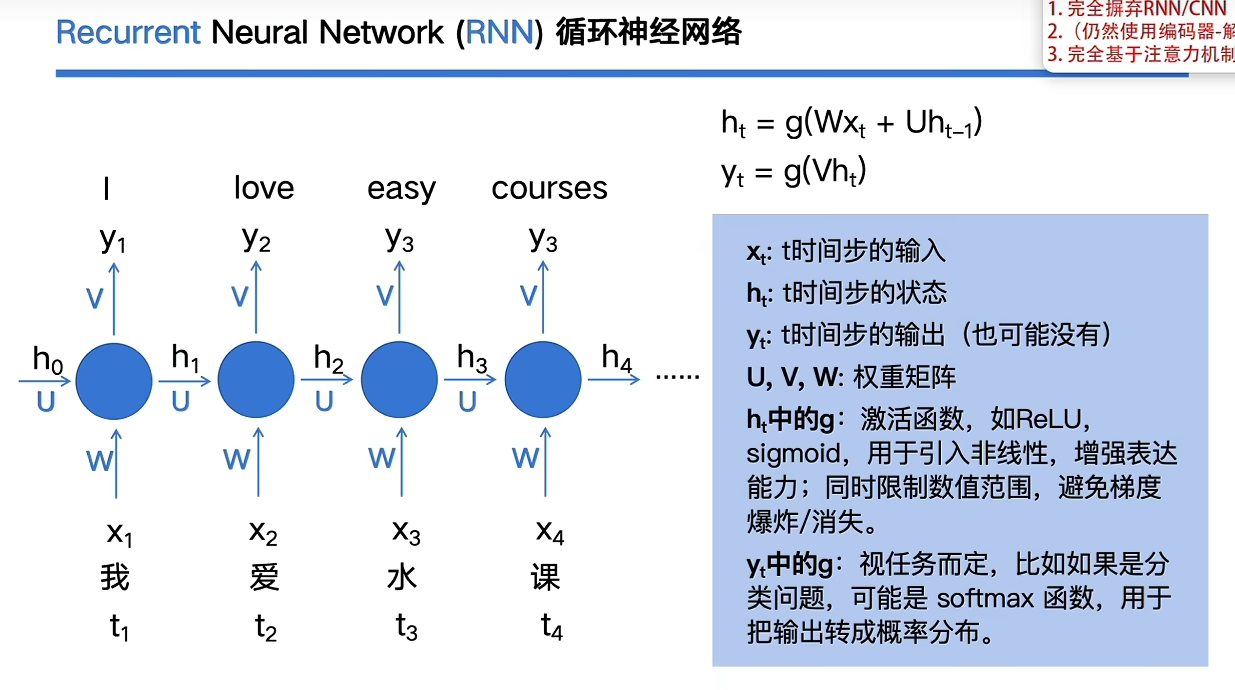
若输入输出不等长,那么rnn就不太能处理
因此就有了编码器-解码器结构
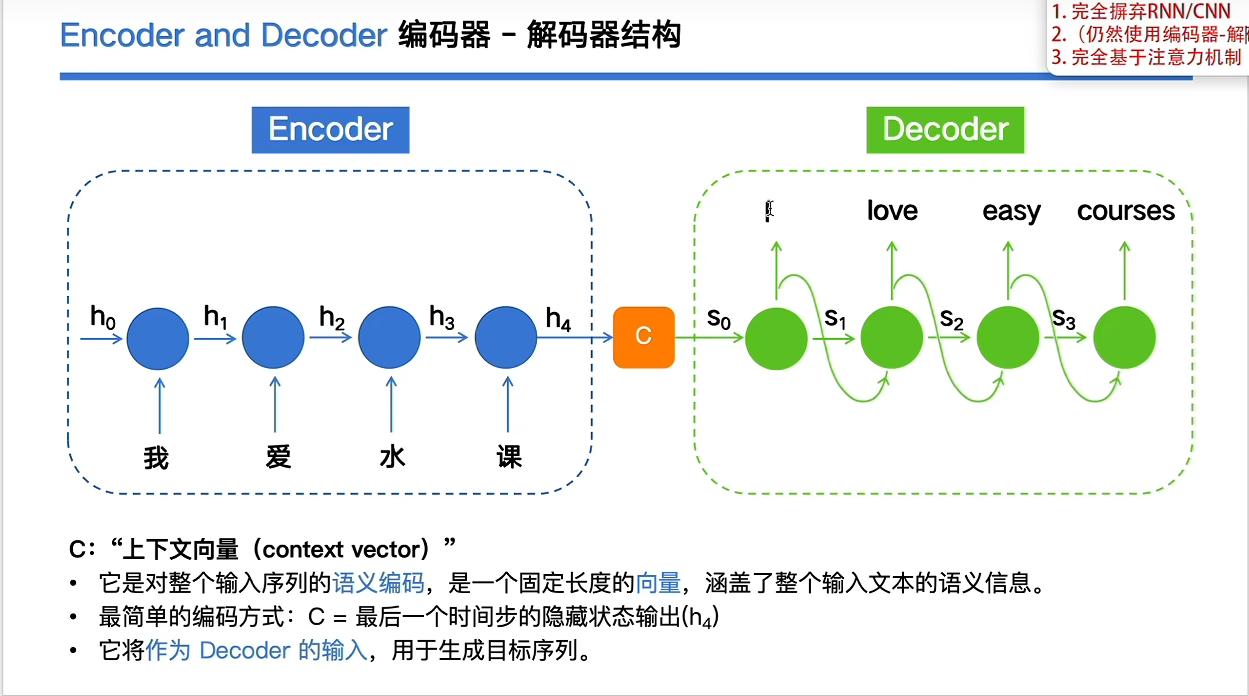
c携带上下文信息,之后就是输入到decoder之中,然后进行进一步的解码
4.注意力机制
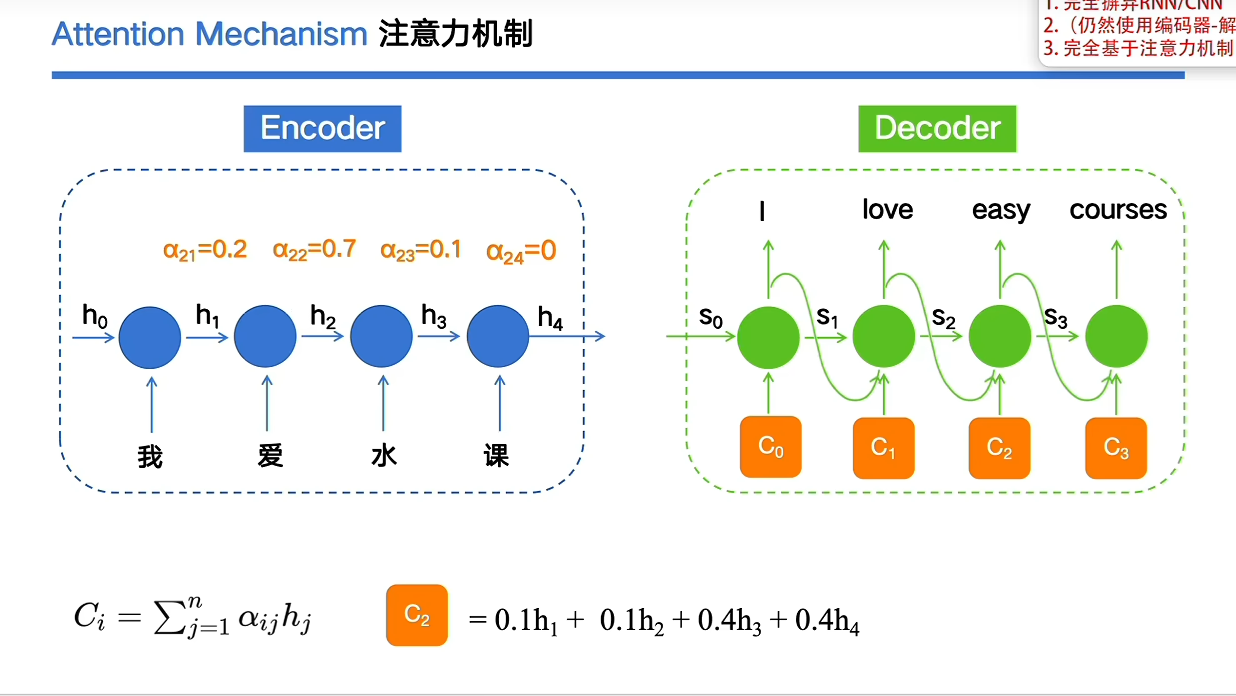
给每个词加上权重
5. Add & Norm
Add & Norm 是深度学习中特别是Transformer 架构 里的核心组件,由 Add(残差连接 / Residual Connection) 和 Norm(层归一化 / Layer Normalization) 两部分组成,通常按 "残差连接→层归一化" 的顺序执行,用于解决深层网络训练中的梯度消失 / 爆炸问题和内部协变量偏移问题,提高训练稳定性和效率。
- Add(残差连接):将子层(如自注意力层、前馈网络层)的输入 x 与其输出 SubLayer (x) 直接相加,形成残差路径
- Norm(层归一化):对相加结果进行层归一化处理
697
Transformer中的Add & Norm
- 在 Transformer 的 Encoder 和 Decoder 的每一层中,每个子层(自注意力层、前馈网络层)后都紧跟一个 Add & Norm 单元
- Encoder 块结构:Multi-Head Attention → Add & Norm → Feed Forward → Add & Norm
- Decoder 块结构:Masked Multi-Head Attention → Add & Norm → Encoder-Decoder Attention → Add & Norm → Feed Forward → Add & Norm
6.BLEU SCORE
BLEU = Bilingual Evaluation Understudy
- 用来自动评估 :机器翻译 / 文本生成 好不好
- 核心思想:生成的句子越像人类参考句子,分数越高
常见 n-gram:
- BLEU-1 :看单词是否对得上(精准)
- BLEU-2 :看两个词一组(流畅度)
- BLEU-3 / BLEU-4:更长片段,更接近人类表达
平时论文里最常用:👉 BLEU-4
7.超参数
超参数 = 训练开始前,人手动设置的参数
深度学习里最常见的超参数
-
学习率(learning rate)
控制每一步更新多大,最重要。 -
Batch size
一次喂给模型多少样本。 -
Epoch
把整个数据集训练几遍。 -
隐藏层大小 / 层数
如 Transformer 的 d_model、层数、头数。 -
Dropout rate
防止过拟合的概率。 -
优化器种类
SGD、Adam、AdamW