
💡Yupureki:个人主页
✨个人专栏:《C++》 《算法》《Linux系统编程》《高并发内存池》《MySQL数据库》
🌸Yupureki🌸的简介:

目录
[1. 引入文件系统](#1. 引入文件系统)
[1.1 '块'的概念](#1.1 '块'的概念)
[1.1.1 硬件层面的"扇区"](#1.1.1 硬件层面的“扇区”)
[1.1.2 文件系统层面的"块"](#1.1.2 文件系统层面的“块”)
[1.1.3 Linux 内核中的"块"抽象](#1.1.3 Linux 内核中的“块”抽象)
[1.2 '分区'的概念](#1.2 ‘分区'的概念)
[1.2.1 分区的作用](#1.2.1 分区的作用)
[1.2.2 Linux 中的分区管理](#1.2.2 Linux 中的分区管理)
[1.3 'inode'的概念](#1.3 'inode‘的概念)
[1.3.2 inode 里存了什么?](#1.3.2 inode 里存了什么?)
[1.3.3 一个类比](#1.3.3 一个类比)
[2. ext2文件系统](#2. ext2文件系统)
[2.1 宏观认识](#2.1 宏观认识)
[2.2 分块组](#2.2 分块组)
[2.2.1 超级块](#2.2.1 超级块)
[2.2.2 块描述符表](#2.2.2 块描述符表)
[2.2.3 块位图](#2.2.3 块位图)
[2.2.4 inode位图](#2.2.4 inode位图)
[2.2.5 inode表](#2.2.5 inode表)
[2.2.6 数据块(Data Block)](#2.2.6 数据块(Data Block))
[2.3 目录与文件名](#2.3 目录与文件名)
[2.3.1 路径解析](#2.3.1 路径解析)
[2.3.2 路径缓存](#2.3.2 路径缓存)
[3. 文件系统的底层操作](#3. 文件系统的底层操作)
[3.1 创建文件(例如 touch /home/user/newfile.txt)](#3.1 创建文件(例如 touch /home/user/newfile.txt))
[3.2 读取文件(例如 cat /home/user/newfile.txt)](#3.2 读取文件(例如 cat /home/user/newfile.txt))
[3.3 删除文件(例如 rm /home/user/newfile.txt)](#3.3 删除文件(例如 rm /home/user/newfile.txt))
[3.4 进入文件夹(例如 cd /home/user)](#3.4 进入文件夹(例如 cd /home/user))
[3.5 核心机制总结](#3.5 核心机制总结)
1. 引入文件系统
1.1 '块'的概念
1.1.1 硬件层面的"扇区"
磁盘硬件的最小寻址单位是扇区(sector),传统为 512 字节,现代硬盘多采用 4096 字节(4K)的物理扇区。但扇区对操作系统上层而言粒度太小,效率不高。
1.1.2 文件系统层面的"块"
文件系统在格式化时,会将连续的若干个扇区组成一个逻辑单位,称为块 (block)或簇(cluster)。例如 ext2 文件系统默认块大小为 4096 字节(即 8 个 512 字节扇区)。这也是我们所称的"一页"的大小
块是文件系统进行数据分配、读写的最小单位:
-
优点:减少元数据开销,提高 I/O 效率。
-
缺点:块太大可能造成内部碎片(小文件浪费空间)。
在 ext2/ext3/ext4 中,块大小可以在格式化时指定(1K、2K、4K),它直接影响:
-
单个文件最大容量(通过多级指针寻址)
-
文件系统最大总容量
-
空间利用率
1.1.3 Linux 内核中的"块"抽象
Linux 将磁盘、分区等设备视为块设备 (block device),并提供统一的通用块层(block layer)。
-
上层(文件系统)发起基于块的读写请求(如读一个 4K 块)。
-
通用块层将这些请求构建成 I/O 调度队列,合并相邻请求,再通过块设备驱动程序转换为底层的扇区操作。
因此,在 Linux 中,"块"既指文件系统管理的最小单位,也是内核 I/O 交互的基本单位。
1.2 '分区'的概念
其实磁盘是可以被分成多个分区(partition)的,以Windows观点来看,你可能会有一块磁盘并且将它分区成C,D,E盘。那个C,D,E就是分区。分区从实质上说就是对硬盘的一种格式化。
1.2.1 分区的作用
分区是将一块物理磁盘(如 /dev/sda)划分为多个逻辑上独立的区域。每个分区可以:
-
格式化为不同的文件系统(ext4、XFS、NTFS 等)
-
独立挂载、备份、修复
-
用于不同用途(系统分区、数据分区、交换分区)
1.2.2 Linux 中的分区管理
-
内核识别 :Linux 内核通过驱动读取分区表,为每个分区生成设备文件,如
/dev/sda1、/dev/nvme0n1p2。 -
用户空间工具:
-
fdisk/gdisk:创建、删除、查看分区表(分别用于 MBR/GPT) -
parted:支持两种格式的高级工具 -
lsblk:查看磁盘和分区树状关系
-
-
分区与文件系统的关系 :分区只是一个线性地址空间,必须在其上创建文件系统(即格式化)才能存储文件。例如
mkfs.ext4 /dev/sda1会将分区 1 格式化为 ext4,并建立超级块、块组、inode 表等结构
1.3 'inode'的概念
Linux 中的 inode,可以把它想象成文件的身份证 或索引节点 。它存储了文件的元数据(即"关于数据的数据"),但不包含文件名和文件内容本身。
1.3.1文件由什么组成?
在 Linux 中,一个文件通常由三部分组成:
-
目录项 :记录文件名和对应的 inode 编号。文件名只是给人看的入口,内核实际上通过 inode 编号识别文件。
-
inode :记录文件的属性信息以及数据块的位置。
-
数据块:存储文件的实际内容。
1.3.2 inode 里存了什么?
通过 stat 命令可以查看 inode 信息。它包含:
-
文件大小(字节数)
-
文件类型(普通文件、目录、设备文件、链接等)
-
权限(读、写、执行)
-
属主和属组(UID/GID)
-
时间戳:
-
atime:访问时间 -
mtime:内容修改时间 -
ctime:状态改变时间(权限、属主等变动)
-
-
链接数:有多少个文件名指向这个 inode。
-
指针:指向存储文件内容的磁盘块的地址(这是 inode 最核心的作用,它将文件名和物理存储位置关联起来)。
inode 不包含文件名。文件名存储在目录文件中,目录文件本质上是一个"文件名与 inode 编号的映射表"。
1.3.3 一个类比
想象一个大型仓库:
-
仓库管理员:是操作系统。
-
货物:是文件的数据内容。
-
货架格子:是磁盘数据块。
-
入库单 :就是 inode。
- 入库单上写着:货物体积(大小)、谁送的(所有者)、谁可以搬走(权限)、送货时间(时间戳),最重要的是,它记录了货物存放在哪个货架格子的编号(指针)。
-
货物标签 :就是 文件名。
- 你在仓库外面看到的标签(如
report.pdf),它只是一个指向"入库单编号"的指引。
- 你在仓库外面看到的标签(如
如果你把货物标签撕掉(删除文件名),只要入库单还在,仓库管理员就能根据入库单找到货物。但如果入库单也被销毁了(删除 inode),货物就成了无法被找到的"垃圾"(数据恢复的难点所在)。
2. ext2文件系统
我们想要在硬盘上储文件,必须先把硬盘格式化为某种格式的文件系统,才能存储文件。文件系统的目的就是组织和管理硬盘中的文件。在Linux系统中,最常见的是ext2系列的文件系统。其早期版本为ext2,后来又发展出ext3和ext4。ext3和ext4虽然对ext2进行了增强,但是其核心设计并没有发生变化,我们仍是以较老的ext2作为演示对象。
2.1 宏观认识
现代一整块磁盘几乎都是1000GB起步,这么大块的资源,我们如何处理?
很简单,利用分治的办法,我假设把磁盘分为几个几乎一样的盘,就如同Windows上面的C盘,D盘,E盘等
如果我管理好了一个盘,就相当于也能把其他盘管理好,把其他盘管理好了,就把整个磁盘管理好了
那一个盘有几百GB,还是不好管理,怎么办?
很简单,我再把一个盘分为几个几乎一样的快组,假设一个快组只有30GB
如果我管理好了一个快组,就相当于也能把其他快组管理好,把其他快组管理好了,就把整个盘管理好了
这就是分治的思想
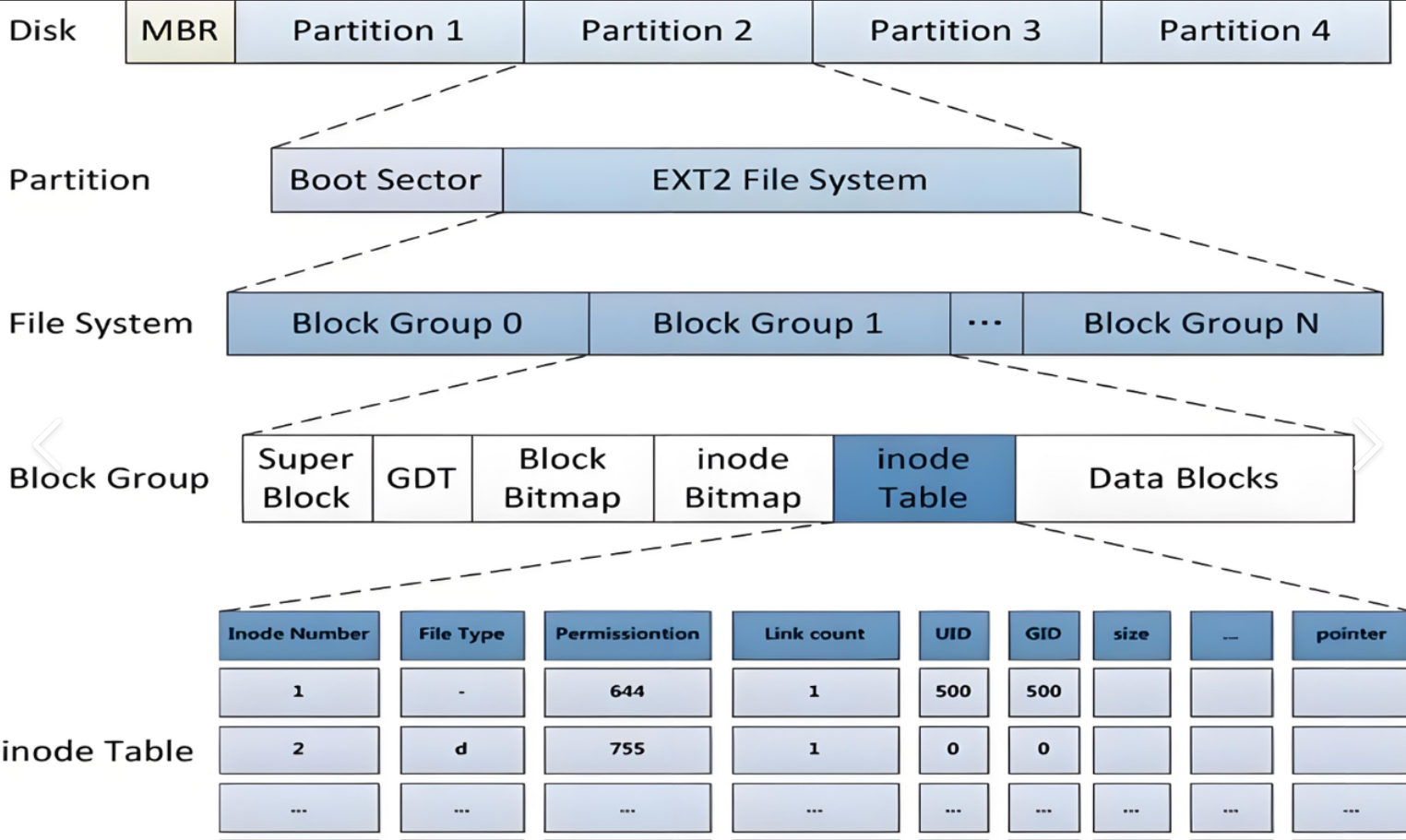
2.2 分块组
那一个区有30GB,我们怎么管理?
那么我们就需要对应的组件来管理这个块组
| 组件 | 作用 |
|---|---|
| 引导块 | 位于分区第一个块,通常只有第一个块组包含,存放引导加载程序。 |
| 超级块 | 描述整个文件系统的全局信息(大小、块数、inode数等)。 |
| 块组描述符表 | 记录每个块组的位置信息(位图、inode表起始块等)。 |
| 块位图 | 用比特位标记组内哪些数据块已使用。 |
| inode 位图 | 用比特位标记组内哪些 inode 已使用。 |
| inode 表 | 连续存放一组 inode 结构体。 |
| 数据块 | 实际存储文件内容和目录项。 |

2.2.1 超级块
存放文件系统本身的结构信息 ,描述整个分区的文件系统信息。记录的信息主要有:block和inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。SuperBlock的信息被破坏,可以说整个文件系统结构就被破坏了
超级块在每个块组的开头都有一份拷贝(第一个块组必须有,后面的块组可以没有)。为了保证文件系统在磁盘部分扇区出现物理问题的情况下还能正常工作,就必须保证文件系统的superblock信息在这种情况下也能正常访问。所以一个文件系统的superblock会在多个blockgroup中进行备份,这些super block区域的数据保持一致
结构体 ext2_super_block。包含关键信息:
-
s_inodes_count:文件系统总 inode 数 -
s_blocks_count:总块数 -
s_first_data_block:第一个数据块编号 -
s_log_block_size:块大小(以 1024 字节为单位的对数) -
s_blocks_per_group:每组的块数 -
s_inodes_per_group:每组的 inode 数 -
s_magic:魔数 0xEF53,用于识别 ext2
2.2.2 块描述符表
块组描述符表,描述块组属性信息 ,整个分区分成多个块组就对应有多少个块组描述符。每个块组描述符存储一个块组的描述信息,如在这个块组中从哪里开始是inodeTable,从哪里开始是Data
Blocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有一份拷贝。
每个块组对应一个描述符(ext2_group_desc),记录该组的:
-
bg_block_bitmap:块位图所在的块号 -
bg_inode_bitmap:inode 位图所在的块号 -
bg_inode_table:inode 表起始块号 -
bg_free_blocks_count:组内空闲块数 -
bg_free_inodes_count:组内空闲 inode 数
所有组描述符依次存放在超级块后面的块中(通常只占用少量块)。挂载时,系统读取这些描述符,获得各组的位置信息。
2.2.3 块位图
一个块有 8* 块大小(字节)个比特。每个比特代表一个数据块:0 表示空闲,1 表示已用。
2.2.4 inode位图
类似于块位图,标记本组 inode 是否被分配。
2.2.5 inode表
一组连续的块,每个块容纳多个 inode 结构体(ext2_inode)。每个 inode 大小为 128 字节(ext2 标准),存储文件元数据:
-
i_mode:文件类型和权限 -
i_uid/i_gid:所有者 -
i_size:文件大小 -
i_atime/i_mtime/i_ctime:时间戳 -
i_blocks:已占用块数(512 字节为单位) -
i_links_count:硬链接数 -
数据块指针数组(核心):
-
12 个直接指针
i_block[0..11] -
1 个单间接指针
i_block[12] -
1 个双间接指针
i_block[13] -
1 个三间接指针
i_block[14]
-
这种多级索引结构允许文件大小灵活扩展,且小文件只需直接指针,效率高。
2.2.6 数据块(Data Block)
存放实际内容,对于普通文件是数据,对于目录则是 目录项(Directory Entry) 的集合。
目录项结构 (ext2_dir_entry_2):
-
inode:文件的 inode 编号 -
rec_len:本条目录项的长度(对齐到 4 字节) -
name_len:文件名长度 -
file_type:文件类型(普通、目录、链接等) -
name:文件名(变长)
目录项简单地说就是一个"文件名 → inode 号"的映射表,按顺序存储。
2.3 目录与文件名
问题:
既然inode是描述文件的,但我们用的仍是路径+文件名,哪有什么乱七八糟的inode,为什么不用?
目录也是文件吗?如何理解
答案:目录也是文件,但是磁盘上没有目录的概念,只有文件属性+文件内容的概念。
是文件。可以把目录文件理解成一个"电话本",里面记录了"人名(文件名)"和"电话号码(inode 编号)"。你按人名查找,但真正拨号时用的是电话号码。
访问文件,必须打开当前目录,根据文件名,获得对应的inode号,然后进行文件访问
所以,访问文件必须要知道当前工作目录,本质是必须能打开当前工作目录文件,查看目录文件的
内容!
2.3.1 路径解析
问题:
- 打开当前工作目录文件,查看当前工作目录文件的内容?当前工作目录不也是文件吗?我们访问?
- 当前工作目录不也是只知道当前工作目录的文件名吗?要访问它,不也得知道当前工作目录inode吗?
- 答案1:所以也要打开:当前工作目录的上级目录,额.,上级目录不也是目录吗??不还是上面的问题吗?
- 答案2:所以类似"递归",需要把路径中所有的目录全部解析,出口是"/"根目录。
- 最终答案3:而实际上,任何文件,都有路径,访问目标文件,比如:/home/whb/code/test/test/test.c都要从根目录开始,依次打开每一个目录,根据目录名,依次访问每个目录下指定的目录,直到访问到test.c。这个过程叫做Linux路径解析。
一个例子:
当你执行 cat /home/user/test.txt 时,系统内核经历了这样的过程:
-
路径解析 :从根目录
/开始,内核读取根目录的 目录文件 (这也是一个文件),在里面找到home对应的 inode 编号。 -
获取 inode :根据编号找到
/home的 inode,再从它的目录数据块中找到user的 inode 编号。 -
重复 :最后找到
test.txt的 inode 编号。 -
使用 inode :内核拿到
test.txt的 inode 后,才从 inode 中读取权限、大小以及 数据块指针,然后根据指针去磁盘读取文件内容。
结论 :文件名只是给人看的"标签",系统真正操作的唯一标识是 inode 编号。文件名到 inode 的映射关系,就存储在 目录文件 里。
2.3.2 路径缓存
为什么需要路径缓存?
路径解析(比如访问 /home/user/test.txt)需要:
-
从根目录开始,读取其数据块找到
home对应的 inode。 -
根据
home的 inode,读取其数据块找到user的 inode。 -
再根据
user的 inode,读取其数据块找到test.txt的 inode。
每一步都可能涉及磁盘读取(目录数据块),而磁盘 I/O 是系统最慢的操作之一。如果每次访问文件都要走一遍完整路径,性能会极差。
因此,Linux 在内核中维护了一个 目录项缓存(dentry cache) ,通常简称为 dcache。它缓存了路径分量(文件名)与 inode 的映射关系,以及目录项之间的树形关系。
注意:
- ·每个文件其实都要有对应的dentry结构,包括普通文件。这样所有被打开的文件,就可以在内存中形成整个树形结构
- 整个树形节点也同时会隶属于LRU(LeastRecentlyUsed,最近最少使用)结构中,进行节点淘汰
- 整个树形节点也同时会隶属于Hash,方便快速查找
- 更重要的是,这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何文件,都在先在这棵树下根据路径进行查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry结构,缓存新路径
3. 文件系统的底层操作
我们可以将文件系统底层操作总结为四个典型场景。这些操作都涉及 路径解析 (依赖 dentry 缓存)、inode 管理 (元数据与数据块指针)、目录项修改 (在父目录的数据块中增删映射)以及 磁盘位图更新(分配或释放 inode 和数据块)。下面以 ext2 文件系统为背景,按操作逐一描述。
3.1 创建文件(例如 touch /home/user/newfile.txt)
1. 路径解析
-
内核从根目录开始,利用 dentry 缓存(dcache) 逐层查找:
/→home→user。 -
若缓存未命中,则读取相应目录的数据块,将目录项加载到 dcache。
-
最终获得父目录
/home/user的 dentry 和对应的 inode。
2. 在父目录中检查重名
-
父目录的 dentry 指向其 inode,通过 inode 找到目录数据块。
-
在目录数据块中遍历目录项,检查
newfile.txt是否已存在。若存在则返回错误。
3. 分配 inode
-
从 inode 位图 中查找空闲位,标记为已用,并更新块组描述符中的空闲 inode 计数。
-
初始化新的 inode 结构体(
ext2_inode):设置权限、时间戳、链接数(初始为 1)、文件类型(普通文件)等。 -
数据块指针数组全部清零(尚未分配数据块)。
4. 在父目录中添加目录项
-
在父目录的数据块中找到一个空闲位置(可能扩大目录文件大小),添加一条新目录项:
{ inode号, 文件名, 文件类型 }。 -
如果目录数据块空间不足,需要为目录文件分配新的数据块(通过块位图分配,并更新目录 inode 的指针)。
5. 更新元数据
-
父目录的 inode 大小增加(若新增了数据块),时间戳更新。
-
将新 inode 写入磁盘(inode 表对应位置)。
-
将修改过的父目录数据块和 inode 标记为脏,等待回写。
6. 缓存更新
- 在 dcache 中创建新的 dentry 对象,指向新文件的 inode,并插入父目录的哈希表。
3.2 读取文件(例如 cat /home/user/newfile.txt)
1. 路径解析
-
同样从根目录开始,利用 dcache 逐层查找路径分量,最终获得目标文件的 dentry。
-
若 dcache 中已有该文件的 dentry,则直接使用;否则从磁盘读取目录项并创建 dentry。
2. 获取 inode
-
通过 dentry 得到文件的 inode 对象(可能已在 inode 缓存中)。
-
检查进程权限(读权限)。
3. 读取数据块
-
根据 inode 中的直接指针、间接指针等,计算出文件内容所在的磁盘块号。
-
通过 页缓存(page cache) 读取数据块:
-
若数据已在页缓存中,直接返回。
-
否则从磁盘读取到页缓存,再拷贝到用户空间。
-
4. 更新访问时间
- 修改 inode 的
atime(访问时间),标记 inode 为脏,稍后回写磁盘。
3.3 删除文件(例如 rm /home/user/newfile.txt)
1. 路径解析
- 解析得到目标文件的 dentry 和 inode,以及父目录的 dentry 和 inode。
2. 检查权限与链接数
- 确认进程有父目录的写权限,且文件未被锁定等。
3. 从父目录中移除目录项
-
在父目录的数据块中找到
newfile.txt对应的目录项,将其标记为"空闲"。 -
可以调整相邻空闲项的
rec_len合并空间,或暂时保留以便后续重用。
4. 减少 inode 链接数
- 将目标文件 inode 的
i_links_count减 1。
5. 释放资源(若链接数降为 0)
-
如果链接数变为 0,则:
-
释放文件占用的所有数据块:根据 inode 中的数据块指针数组,将对应的块位图位清零,并更新块组描述符的空闲块计数。
-
释放 inode:将 inode 位图对应位清零,更新空闲 inode 计数。
-
将 inode 标记为已删除(在 inode 表中清除或标记无效)。
-
- 更新父目录元数据
-
父目录的 inode 大小可能减小(若删除的目录项导致数据块变空,可能释放目录数据块)。
-
父目录的
mtime和ctime更新。
7. 缓存清理
-
从 dcache 中移除该文件的 dentry(标记为无效或直接删除)。
-
若 inode 已释放,也从 inode 缓存中移除。
3.4 进入文件夹(例如 cd /home/user)
1. 路径解析
- 内核解析路径
/home/user,利用 dcache 逐层查找,最终获得目录user的 dentry。
2. 权限检查
- 检查该目录的 执行权限 (
x),若无权限则拒绝。
3. 进程上下文更新
-
内核修改当前进程的 当前工作目录(cwd) 指针,将其指向目标目录的 dentry。
-
不会对磁盘做任何修改,所有操作都在内存中完成。
4. 缓存影响
- 如果路径解析过程中某些分量不在 dcache 中,会触发磁盘读取目录项,并将它们加入 dcache,后续访问同一目录即可命中缓存。
3.5 核心机制总结
| 操作 | 涉及的关键底层组件 | 主要步骤 |
|---|---|---|
| 创建文件 | 父目录 inode、目录数据块、inode 位图、块位图、dcache | 分配 inode → 添加目录项 → 更新位图 → 创建 dentry |
| 读取文件 | 目标文件 inode、数据块指针、页缓存、dcache | 路径解析 → 通过 inode 定位数据块 → 从页缓存或磁盘读取 |
| 删除文件 | 父目录 inode、目录数据块、inode 位图、块位图、dcache | 删除目录项 → 减少链接数 → 若链接数为 0 则释放 inode 和数据块 |
| 进入文件夹 | 目标目录 dentry、dcache、进程 cwd | 路径解析 → 权限检查 → 更新进程当前目录指针(纯内存操作) |
关键思想:文件名与 inode 通过目录项解耦,所有路径操作都经过 dcache 加速,实际磁盘访问仅限于元数据和数据块读写的必要时机。理解这些底层细节,就能更好地把握 Linux 文件系统的性能特点和故障排查思路。