一、什么是双向链表?
- 核心定义
双向链表是一种线性表,它的每个数据节点不仅存储了指向下一个节点的指针 next ,还多了一个指向前一个节点的指针 prev 。
这意味着:
-
单链表:只能从头走到尾(单向)。
-
双向链表:可以从头走到尾,也可以从尾走到头(双向)。
- 节点结构 (Node Structure)
每个节点包含三个部分:
-
prev :前驱指针,指向前一个节点。
-
val / data :存储的数据。
-
next :后继指针,指向后一个节点。
在 C 语言中定义如下:

二、双向链表 vs 单链表:优缺点对比
表格
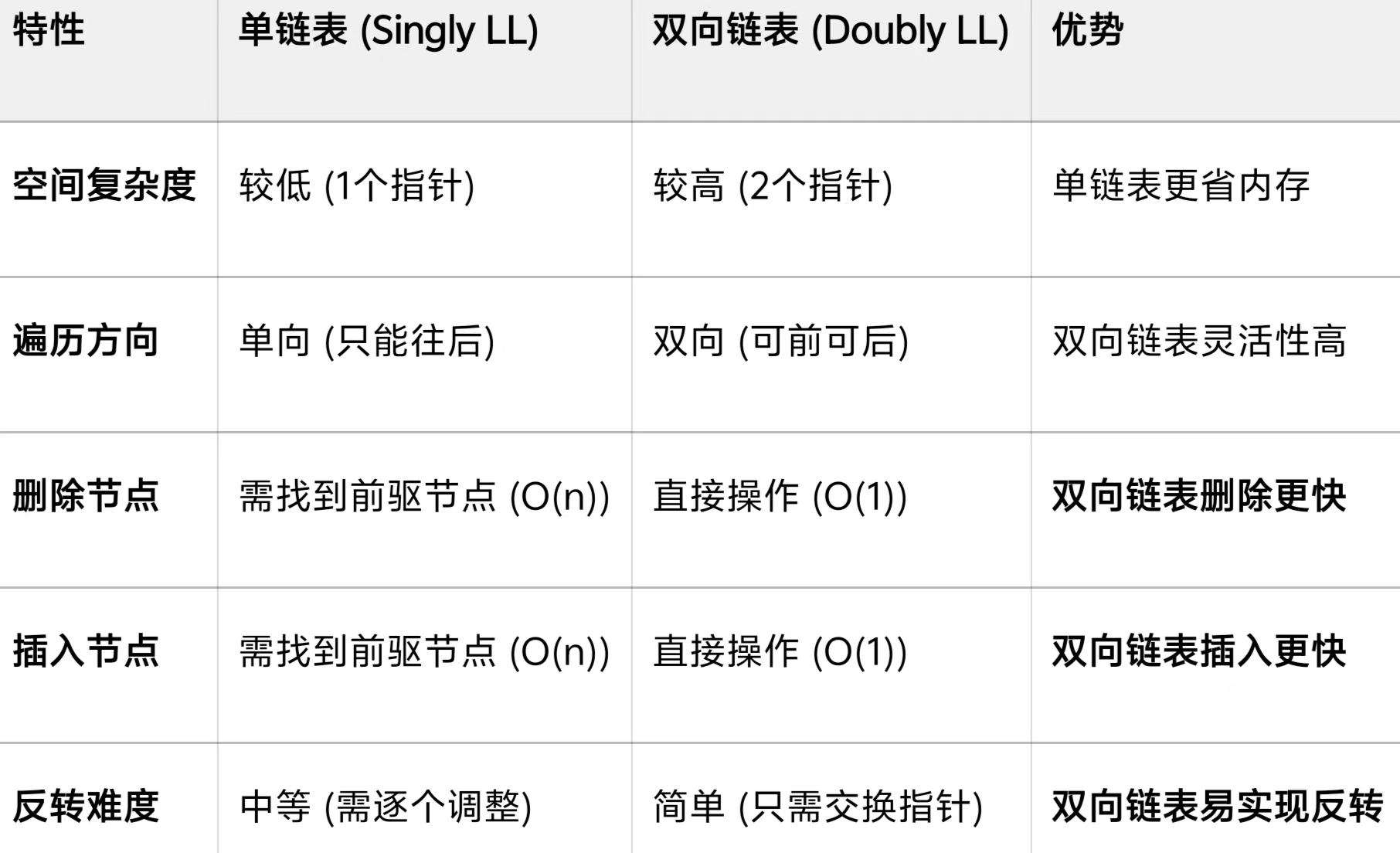 结论:在对插入、删除操作频繁,且需要双向遍历的场景中,双向链表是首选。
结论:在对插入、删除操作频繁,且需要双向遍历的场景中,双向链表是首选。
三、六大核心操作详解
- 基础工具:创建新节点

- 核心操作一:头插法 (Push Front)
原理:新节点成为新的头,它的 next 指向旧头,旧头的 prev 指向新节点。

- 核心操作二:尾插法 (Push Back)
原理:找到链表尾部,将尾部节点的 next 指向新节点,新节点的 prev 指向尾部节点。

- 核心操作三:头删法 (Pop Front)
原理:删除头节点,将新头节点的 prev 置为 NULL 。

- 核心操作四:尾删法 (Pop Back)
原理:找到尾节点,将其前驱节点的 next 置为 NULL ,然后释放尾节点。

- 核心操作五:指定位置插入 (Insert After)
场景:在某个指定节点 pos 的后面插入新节点。

- 核心操作六:指定位置删除 (Delete Node)
场景:删除链表中指定的某个节点 delNode 。

四、辅助函数:打印与释放

五、核心算法:反转双向链表

六、主函数:测试所有功能

七、运行结果

八、深度总结:双向链表的精髓
-
永远先保存:在修改指针前,务必用临时变量保存可能丢失的节点地址,避免链表断裂。
-
双向更新:插入/删除操作时,要同时更新 prev 和 next 指针,保证双向指向正确。
-
边界检查:必须处理链表为空、只有一个节点等边界情况,防止空指针访问。
-
内存管理:删除节点后要及时释放内存,避免内存泄漏。
九、总结
双向链表是在单链表基础上扩展出的高效线性表结构,核心思想是为每个节点增加 prev 前驱指针,实现双向遍历与更灵活的操作。
它最大的优势是插入、删除操作效率更高(无需遍历查找前驱节点),支持双向遍历;最大的代价是额外占用一个指针的存储空间,空间复杂度略高于单链表。
掌握双向链表,是深入学习循环链表、LRU缓存、跳表等更高级数据结构的基础,也是面试与考研中高频考察的核心知识点。
如果这篇文章对你有帮助,欢迎点赞、收藏、关注,后续会持续更新数据结构与算法干货,我们一起进步!🚀