Part I:前馈式 3DGS 的起步范式:从像素到高斯
- [0. 导言:路线一为什么值得单独讲](#0. 导言:路线一为什么值得单独讲)
-
- [0.1 路线一不是"最强答案",而是前馈式 3DGS 的第一个成立范式](#0.1 路线一不是“最强答案”,而是前馈式 3DGS 的第一个成立范式)
- [0.2 为什么说路线一解决了"能不能成立",但没有解决"怎样合理组织"](#0.2 为什么说路线一解决了“能不能成立”,但没有解决“怎样合理组织”)
- [0.3 理解路线一,为什么是理解后续所有路线的前提](#0.3 理解路线一,为什么是理解后续所有路线的前提)
- [1. 为什么前馈式 3DGS 一开始几乎都选择 pixel-aligned](#1. 为什么前馈式 3DGS 一开始几乎都选择 pixel-aligned)
-
- [1.1 从张量形态出发:2D 编码器天然产生 pixel-aligned 表征](#1.1 从张量形态出发:2D 编码器天然产生 pixel-aligned 表征)
- [1.2 从几何 lifting 出发:pixel-aligned 本质上是 2D-driven 3D lifting](#1.2 从几何 lifting 出发:pixel-aligned 本质上是 2D-driven 3D lifting)
- [1.3 为什么最先出现的不是 voxel-aligned、pointmap、adaptive placement](#1.3 为什么最先出现的不是 voxel-aligned、pointmap、adaptive placement)
-
- [(1)不是 voxel-aligned:因为第一代目标不是建立 3D 规则结构,而是最低成本打通前馈闭环](#(1)不是 voxel-aligned:因为第一代目标不是建立 3D 规则结构,而是最低成本打通前馈闭环)
- [(2)不是 pointmap / set prediction:因为集合预测对第一代系统并不"最短路径"](#(2)不是 pointmap / set prediction:因为集合预测对第一代系统并不“最短路径”)
- [(3)不是 adaptive placement:因为第一代系统优先要"可训练",不是先要"最优稀疏"](#(3)不是 adaptive placement:因为第一代系统优先要“可训练”,不是先要“最优稀疏”)
- [1.4 pixel-aligned 为什么在训练上简单、在实现上直接、在渲染上高效](#1.4 pixel-aligned 为什么在训练上简单、在实现上直接、在渲染上高效)
- [1.5 为什么它在直觉上也最"像"一个能工作的系统](#1.5 为什么它在直觉上也最“像”一个能工作的系统)
- [1.6 一个形式化判断:pixel-aligned 为什么是"工程上最自然的起点"](#1.6 一个形式化判断:pixel-aligned 为什么是“工程上最自然的起点”)
- [1.7 pixel-aligned 的阶段性优缺点总表](#1.7 pixel-aligned 的阶段性优缺点总表)
- [1.8 本章结论:pixel-aligned 不是偶然选项,而是第一代 feed-forward 3DGS 的必然工程形态](#1.8 本章结论:pixel-aligned 不是偶然选项,而是第一代 feed-forward 3DGS 的必然工程形态)
- [2. pixelSplat 的核心思想:概率分布而不是硬回归](#2. pixelSplat 的核心思想:概率分布而不是硬回归)
-
- [2.1 pixelSplat 真正要解决的,不是"预测高斯",而是"让高斯中心可训练"](#2.1 pixelSplat 真正要解决的,不是“预测高斯”,而是“让高斯中心可训练”)
- [2.2 为什么 Gaussian mean prediction 比 scale / opacity / color 更难](#2.2 为什么 Gaussian mean prediction 比 scale / opacity / color 更难)
- [2.3 直接硬回归 mean,为什么会不稳定](#2.3 直接硬回归 mean,为什么会不稳定)
- [2.4 pixelSplat 的改写:不是预测一个深度,而是预测一条视线上的存在概率](#2.4 pixelSplat 的改写:不是预测一个深度,而是预测一条视线上的存在概率)
- [2.5 为什么说 pixelSplat 的历史意义,在于把 center prediction 变成"可训练问题"](#2.5 为什么说 pixelSplat 的历史意义,在于把 center prediction 变成“可训练问题”)
- [3. 可微采样如何缓解 local minima](#3. 可微采样如何缓解 local minima)
-
- [3.1 稀疏视角、局部支撑表示与局部最优之间的关系](#3.1 稀疏视角、局部支撑表示与局部最优之间的关系)
- [3.2 为什么 center 一旦错位,后续优化很难自我纠正](#3.2 为什么 center 一旦错位,后续优化很难自我纠正)
- [3.3 可微采样做了什么:不是直接求最优位置,而是先在分布上优化](#3.3 可微采样做了什么:不是直接求最优位置,而是先在分布上优化)
- [3.4 reparameterization trick 在这里如何起作用](#3.4 reparameterization trick 在这里如何起作用)
- [3.5 可微采样缓解了什么,又没有解决什么](#3.5 可微采样缓解了什么,又没有解决什么)
- [4. pixel-aligned 方案为什么天然简单](#4. pixel-aligned 方案为什么天然简单)
-
- [4.1 "简单"不是贬义,而是路线一最大的工程魅力](#4.1 “简单”不是贬义,而是路线一最大的工程魅力)
- [4.2 它为什么容易与已有 2D backbone 兼容](#4.2 它为什么容易与已有 2D backbone 兼容)
- [4.3 它为什么便于高效渲染与端到端训练](#4.3 它为什么便于高效渲染与端到端训练)
- [4.4 为什么这条路线具有直觉性、可视化性、可解释性](#4.4 为什么这条路线具有直觉性、可视化性、可解释性)
- [4.5 但"天然简单"也意味着:它更像 2D-driven 3D lifting,而不是 3D 结构化推理](#4.5 但“天然简单”也意味着:它更像 2D-driven 3D lifting,而不是 3D 结构化推理)
- [4.6 本章结论:路线一的"简单",是一种高度成功的最小系统设计](#4.6 本章结论:路线一的“简单”,是一种高度成功的最小系统设计)
- [5. 为什么开始走向 latent Gaussian](#5. 为什么开始走向 latent Gaussian)
-
- [5.1 latentSplat 不是重复 pixelSplat,而是在路线一内部把"显式回归"推向"潜变量表示"](#5.1 latentSplat 不是重复 pixelSplat,而是在路线一内部把“显式回归”推向“潜变量表示”)
- [5.2 latent Gaussian 与显式 RGB Gaussian 的根本差异,不在"存什么",而在"把不确定性放在哪里"](#5.2 latent Gaussian 与显式 RGB Gaussian 的根本差异,不在“存什么”,而在“把不确定性放在哪里”)
- [5.3 latentSplat 为什么体现出"回归式 + 生成式"的混合趋势](#5.3 latentSplat 为什么体现出“回归式 + 生成式”的混合趋势)
- [5.4 为什么 latent Gaussian 比显式像素颜色高斯更有潜力](#5.4 为什么 latent Gaussian 比显式像素颜色高斯更有潜力)
- [5.5 本章结论:latentSplat 标志着路线一从"显式高斯回归"走向"概率化的语义高斯表示"](#5.5 本章结论:latentSplat 标志着路线一从“显式高斯回归”走向“概率化的语义高斯表示”)
- [6. 这条路线的优势:训练直接、渲染高效、编辑友好](#6. 这条路线的优势:训练直接、渲染高效、编辑友好)
-
- [6.1 路线一最宝贵的地方,是它把前馈式 3D Gaussian reconstruction 变成了清晰问题](#6.1 路线一最宝贵的地方,是它把前馈式 3D Gaussian reconstruction 变成了清晰问题)
- [6.2 架构简洁:2D backbone + Gaussian head + splatting renderer 的短闭环](#6.2 架构简洁:2D backbone + Gaussian head + splatting renderer 的短闭环)
- [6.3 训练效率与推理速度:高效 renderer 让显式高斯前馈化真正可行](#6.3 训练效率与推理速度:高效 renderer 让显式高斯前馈化真正可行)
- [6.4 表示可解释、可编辑、具有资产感](#6.4 表示可解释、可编辑、具有资产感)
- [6.5 路线一的优势总结:它让前馈式 3DGS 成为可复现、可比较、可工程化的话题](#6.5 路线一的优势总结:它让前馈式 3DGS 成为可复现、可比较、可工程化的话题)
- [7. 这条路线的硬伤:3D 交互弱、密度分配偏置、遮挡不稳](#7. 这条路线的硬伤:3D 交互弱、密度分配偏置、遮挡不稳)
-
- [7.1 3D 交互能力弱:它仍然主要是 2D 局部特征驱动](#7.1 3D 交互能力弱:它仍然主要是 2D 局部特征驱动)
- [7.2 Gaussian density 分配容易受视图偏置影响](#7.2 Gaussian density 分配容易受视图偏置影响)
- [7.3 多视图一致性瓶颈:局部 pixel-aligned 特征天然难以保证全局几何一致](#7.3 多视图一致性瓶颈:局部 pixel-aligned 特征天然难以保证全局几何一致)
- [7.4 Gaussian mean localization 仍然是主瓶颈](#7.4 Gaussian mean localization 仍然是主瓶颈)
- [7.5 它更像"2D 驱动的 3D lifting",而不是"真正从 3D 出发的结构化推理"](#7.5 它更像“2D 驱动的 3D lifting”,而不是“真正从 3D 出发的结构化推理”)
- [8. 这条路线对后续所有方法留下了什么遗产](#8. 这条路线对后续所有方法留下了什么遗产)
-
- [8.1 它留下了前馈式 3DGS 的问题定义](#8.1 它留下了前馈式 3DGS 的问题定义)
- [8.2 它留下了 per-pixel Gaussian prediction 这一最小可行接口](#8.2 它留下了 per-pixel Gaussian prediction 这一最小可行接口)
- [8.3 它留下了一个最关键的认识:Gaussian mean localization 是主矛盾](#8.3 它留下了一个最关键的认识:Gaussian mean localization 是主矛盾)
- [8.4 它确认了 Gaussian renderer 是高效训练与推理的底座](#8.4 它确认了 Gaussian renderer 是高效训练与推理的底座)
- [8.5 它留下了显式资产感与可编辑性这条产品化线索](#8.5 它留下了显式资产感与可编辑性这条产品化线索)
- [8.6 它也留下了未解问题,并自然导向后续路线](#8.6 它也留下了未解问题,并自然导向后续路线)
- [9. 结语](#9. 结语)
- 参考文献
-
- [1. Splatter Image](#1. Splatter Image)
- [2. pixelSplat](#2. pixelSplat)
- [3. latentSplat](#3. latentSplat)
- [4. MVSplat](#4. MVSplat)
- [5. TGS(Triplane Meets Gaussian Splatting)](#5. TGS(Triplane Meets Gaussian Splatting))
系列文章全文导航(总览篇)
Part I:前馈式 3DGS 的起步范式:从像素到高斯
[Part II:前馈式 3DGS 的 depth-first 转向](#Part II:前馈式 3DGS 的 depth-first 转向)
[Part III:Transformer 如何重写前馈式 3DGS 的信息聚合方式](#Part III:Transformer 如何重写前馈式 3DGS 的信息聚合方式)
[Part IV:Pose-Free 前馈式 3DGS:从实验室输入走向真实世界图像集合](#Part IV:Pose-Free 前馈式 3DGS:从实验室输入走向真实世界图像集合)
[Part V:结构化潜空间与高斯体:前馈式 3DGS 的下一代表示基座](#Part V:结构化潜空间与高斯体:前馈式 3DGS 的下一代表示基座)
[Part VI:Adaptive Placement and Generative Coupling in Feed-Forward 3DGS](#Part VI:Adaptive Placement and Generative Coupling in Feed-Forward 3DGS)
0. 导言:路线一为什么值得单独讲
0.1 路线一不是"最强答案",而是前馈式 3DGS 的第一个成立范式
如果把 feed-forward 3DGS 看成一个研究方向,那么它的第一个真正问题并不是"怎样做到最优",而是"能不能把多视图图像经过一次前向传播,直接变成一组可渲染、可训练、可编辑的 3D Gaussian primitives"。
从这个意义上说,pixelSplat 的历史作用,不在于它已经给出了最佳 3D 组织方式,而在于它第一次把"图像 → \rightarrow → 高斯集合 → \rightarrow → 新视角渲染"这条链路做成了一个清晰、可微、可复现的前馈范式;latentSplat 则在此基础上进一步把显式高斯推进到 latent / semantic Gaussian,使路线一第一次触碰表示泛化、语义承载与生成式解码的问题。
换句话说,路线一真正解决的是 feed-forward 3DGS 作为问题形式能否成立 ,而不是 3D Gaussian 应该以何种最合理的结构被组织。这一点,恰恰是理解后续路线分叉的起点。
形式上,可将 feed-forward 3DGS 写为一个条件生成映射:
F θ : { ( I v , Π v ) } v = 1 M ⟶ G , G = { G i } i = 1 N . (1) \mathcal{F}{\theta}: \left\{(I_v,\Pi_v)\right\}{v=1}^{M} \longrightarrow \mathcal{G}, \qquad \mathcal{G}=\left\{G_i\right\}_{i=1}^{N}. \tag{1} Fθ:{(Iv,Πv)}v=1M⟶G,G={Gi}i=1N.(1)
其中 I v I_v Iv 表示第 v v v 个输入视图, Π v \Pi_v Πv 表示相机内外参, G \mathcal{G} G 是输出的 3D Gaussian 集合,而
G i = ( μ i , Σ i , α i , ϕ i ) . (2) G_i=\big(\mu_i,\Sigma_i,\alpha_i,\phi_i\big). \tag{2} Gi=(μi,Σi,αi,ϕi).(2)
这里 μ i ∈ R 3 \mu_i\in\mathbb{R}^3 μi∈R3 是 Gaussian mean, Σ i \Sigma_i Σi 是协方差或其参数化形式, α i \alpha_i αi 是 opacity, ϕ i \phi_i ϕi 可以是 RGB / SH 系数,也可以是 latent feature。
原始 3DGS 已经证明:一旦有了这样一组高斯,借助 visibility-aware、anisotropic splatting 的快速可微 renderer,就可以同时支持高质量训练与实时渲染。也正因为底座已经成立,后续问题就从"如何优化一组现成高斯"转向"如何通过神经网络一次性预测这组高斯"。
这也是为什么路线一必须单独讲。因为后面几条路线------无论是把问题改写成深度 / cost volume 的路线二,还是提升到全局 token 聚合的大重建模型路线三,抑或引入 triplane / voxel / structured latent 的结构化路线------都不是凭空出现的。它们几乎都建立在路线一留下的两个前提之上:第一,用高斯作为显式、可渲染、可编辑的 3D 资产是可行的 ;第二,把输入图像的局部表征直接 lift 成 3D 高斯,是最容易起步的方式。前者来自 3DGS renderer 的工程成熟度,后者则被 Splatter Image、pixelSplat、latentSplat 这条线相继验证。
0.2 为什么说路线一解决了"能不能成立",但没有解决"怎样合理组织"
需要明确的是,feed-forward 3DGS 至少同时包含三个层次的问题:
- representation 问题:输出到底是不是一组显式 3D Gaussian;
- primitive placement 问题:这些 Gaussian 的中心应该放在哪里、放多少、如何分配密度;
- multi-view consistency 问题:不同输入视图提供的局部证据,如何在 3D 中合成为一致的结构。
路线一在第一个层次上几乎是成功的。它把任务稳定地压缩成"预测一组高斯参数,再用 Gaussian renderer 监督",从而让问题边界变得清楚:不再需要测试时逐场景优化,不再需要慢速体渲染器,也不再需要隐式场再额外抽取显式表示。
工程上,这意味着训练、推理、渲染、下游编辑第一次被统一进一个显式资产接口中。pixelSplat 明确强调其输出是 interpretable and editable 的 3D radiance field;latentSplat 则进一步说明,这个接口不必局限于显式 RGB 属性,也可以是 latent-space 中的 variational feature Gaussians。
但路线一在第二、第三层次上并未真正解决问题。因为它的基本出发点仍然是 2D-driven 3D lifting:先从 2D 编码器得到 pixel-aligned features,再让这些局部特征去决定高斯的 3D 位置、尺度和属性。这样做的优点是自然、直接、可微、效率高;缺点则同样明确:它并没有让网络"先在 3D 里想清楚场景结构,再决定高斯怎么摆",而是让网络"先在 2D 局部里产生候选,再把候选 lift 到 3D"。
真正的分歧不在于能不能产出高斯,而在于 高斯的组织原则究竟来自 2D 对齐张量,还是来自 3D 结构化推理。后面路线二引入 cost volume 来强化几何定位,路线三引入全局 token 聚合,路线五引入 triplane / voxel 这类结构化中间表示,本质上都在回答这个问题。
因此,本文的核心判断可以提前写成一句话:
Route-1 solves feed-forward feasibility, but not 3D organization optimality. (3) \text{Route-1 solves feed-forward feasibility, but not 3D organization optimality.} \tag{3} Route-1 solves feed-forward feasibility, but not 3D organization optimality.(3)
换句话说,路线一证明了"前馈式 3DGS 可以做",却没有证明"像素对齐高斯就是最终最优的 3D 表达方式"。这也是它为何重要,又为何必须被超越。这个判断,将贯穿后文对 pixelSplat 与 latentSplat 的全部分析。
0.3 理解路线一,为什么是理解后续所有路线的前提
如果不理解路线一,后续很多方法的"改进方向"会显得像局部工程技巧;但一旦把路线一看清楚,就会发现后续几乎所有改动都围绕同一主矛盾展开:Gaussian mean localization。因为 scale、opacity、appearance 都是在"位置基本合理"的前提下才有意义;而一旦 mean 位置错了,局部支撑 primitive 的后续渲染梯度往往难以把它拉回正确位置。pixelSplat 之所以采用 dense 3D probability distribution 加 differentiable sampling,本质上正是在承认:对路线一而言,最难的不是"给每个高斯填什么颜色",而是"把高斯放到哪里"。而 MVSplat 之所以转向 cost volume / depth estimation,也恰恰是在承认:这件事最终越来越像一个显式几何定位问题。
从研究方法论上说,路线一留下了五项遗产,后文会反复回到它们:
- 它给出了前馈式 3DGS 的问题定义;
- 它给出了 per-pixel Gaussian prediction 这一最小可行接口;
- 它暴露了 Gaussian mean localization 是主矛盾;
- 它确认了 Gaussian renderer 是训练与推理的高效底座;
- 它证明了显式 Gaussian 作为"3D 资产"具有天然的可解释性与可编辑性。
这也是为什么本篇不是在"复盘两篇论文",而是在建立一个判断框架:路线一的历史意义,在于它定义了问题;路线一的历史局限,在于它没有最终定义好 3D 组织原则。
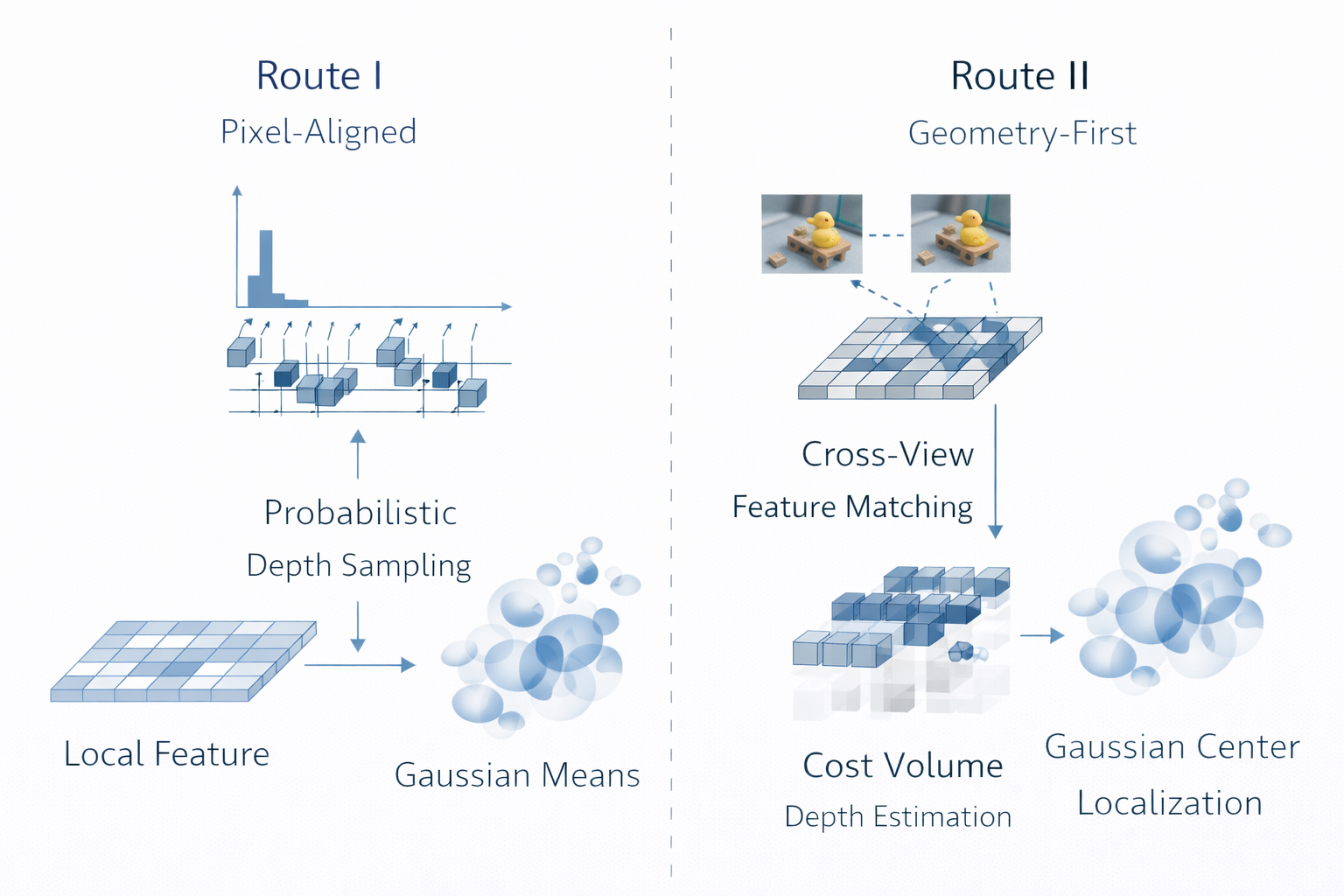
1. 为什么前馈式 3DGS 一开始几乎都选择 pixel-aligned
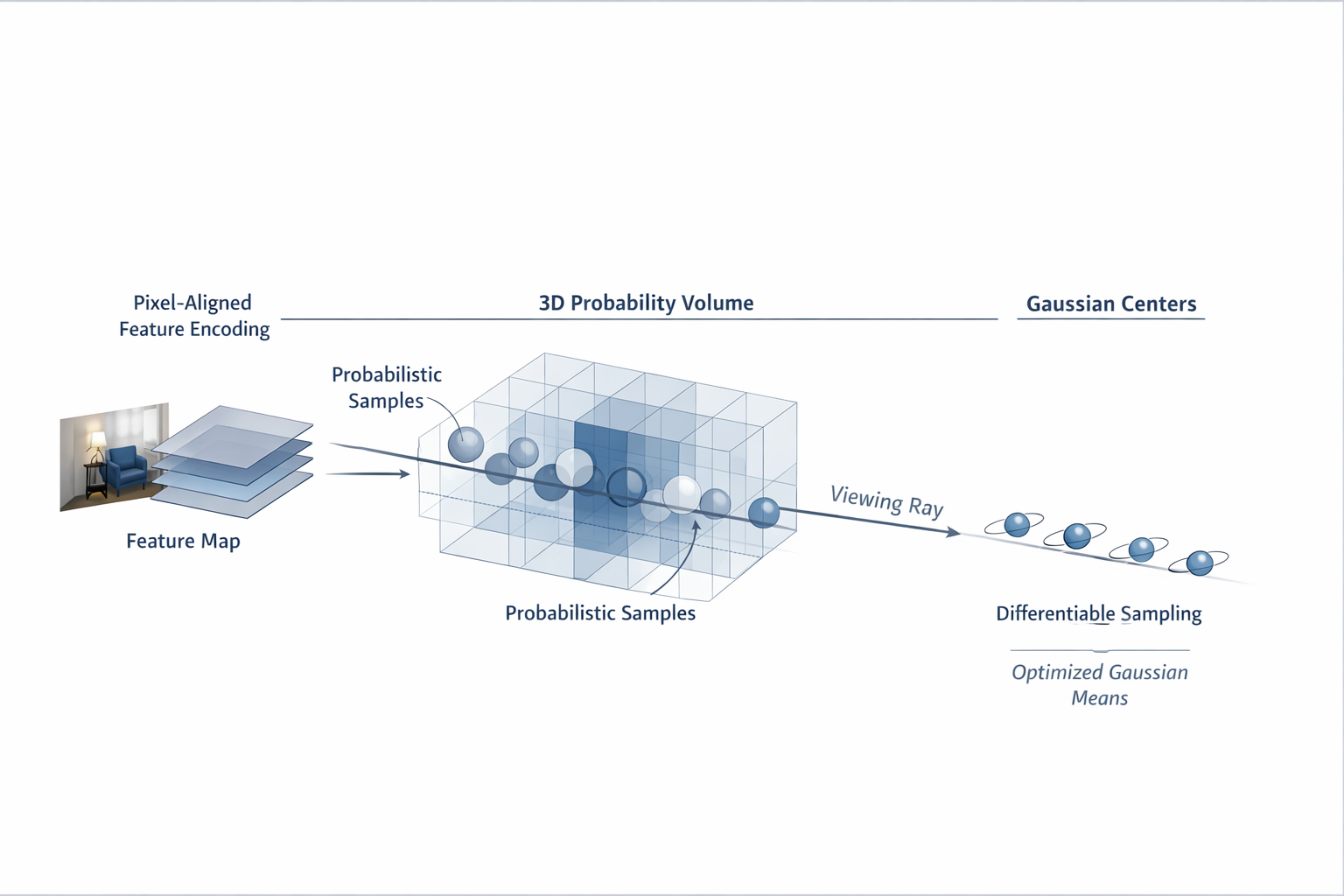
1.1 从张量形态出发:2D 编码器天然产生 pixel-aligned 表征
前馈式 3D 重建的第一代自然参数化,几乎必然会从 pixel-aligned 开始,这首先不是因为它在理论上最优,而是因为它在 张量形态 上最自然。标准视觉 backbone------无论是 CNN、U-Net、FPN,还是基于 patch / token 的视觉编码器------其最稳定、最成熟、最廉价的输出形态,本质上都是一个与图像平面保持对应关系的二维特征场:
F = E θ ( I ) ∈ R H × W × C . (4) F = E_{\theta}(I)\in\mathbb{R}^{H\times W\times C}. \tag{4} F=Eθ(I)∈RH×W×C.(4)
只要输出还是一个 H × W H\times W H×W 的二维特征网格,那么最顺手的下游建模方式就不是"先摆一个 3D 体素场",也不是"先构造一个无序点集拓扑",而是直接在每个像素位置附着若干个待 lift 的 Gaussian 参数:
Ψ u , v = h θ ( F u , v ) ⟶ G u , v , k k = 1 K . (5) \Psi_{u,v} = h_{\theta}(F_{u,v}) \longrightarrow {G_{u,v,k}}_{k=1}^{K}. \tag{5} Ψu,v=hθ(Fu,v)⟶Gu,v,kk=1K.(5)
这里 K K K 可以是每像素一个,也可以是固定少量多个。Splatter Image 正是把这一点做到极致:它明确把高斯集合当作"存放在一张 2D 图像容器中的无序集合",用 image-to-image 网络为每个输入像素预测一个 3D Gaussian;其作者甚至直接强调,这样做的关键好处,就是可以只用高效的 2D operators 来实现 reconstruction。
本质上,这意味着前馈式 3DGS 的第一代设计,不是从"3D 世界应该怎样离散化"出发,而是从"现成的 2D 视觉网络最容易输出什么"出发。换句话说,pixel-aligned 先解决的是 网络接口自然性 ,而不是 3D 组织最优性。
这是一种非常典型的工程路径:谁能最少改动现有图像网络、最少引入 3D 昂贵算子、最短闭环地接上 Gaussian renderer,谁就最可能先成为起步范式。Splatter Image 的"一像素一高斯"与 pixelSplat 的"pixel-aligned features + Gaussian prediction"都属于这个逻辑链条上的自然产物。
从复杂度角度看,这条路也几乎是默认最优。若采用 voxel-aligned 表达,则需要先定义体素边界、分辨率、坐标归一化方式,并引入 3D 卷积或等价的 3D 稠密处理;若采用 pointmap / adaptive placement,则网络必须额外学习集合 cardinality、空间采样规律与排序不变性。而 pixel-aligned 直接继承了图像域已有的空间索引:第 ( u , v ) (u,v) (u,v) 个位置的 feature 就是第 ( u , v ) (u,v) (u,v) 个位置的 prediction seed。工程上这意味着实现更直接、显存更友好、训练更稳定,且天然兼容大量成熟的 2D backbone。
这个事实,不是某一篇论文单独发明的,而是整个视觉系统工程成熟度共同推出来的结果。Splatter Image 对"image as container of 3D Gaussians"的表述,正是这一点的最鲜明写照。
1.2 从几何 lifting 出发:pixel-aligned 本质上是 2D-driven 3D lifting
仅从网络接口看,pixel-aligned 只是"方便";但它之所以真正成立,是因为它同时满足一个几何事实:图像中的每个像素,本身就对应一条穿过相机中心的 3D 视线。 这使得"从像素到高斯"的 lift 不再是无锚点生成,而是一个有明确几何母体的提升过程。
令像素坐标为 p = ( u , v ) p=(u,v) p=(u,v),相机内参为 K K K,外参为 ( R , t ) (R,t) (R,t),则该像素在世界坐标系中的视线可写为
r p ( λ ) = o + λ , d p , d p = R ⊤ K − 1 p ~ , (6) r_p(\lambda)=o + \lambda, d_p, \qquad d_p = R^{\top}K^{-1}\tilde{p}, \tag{6} rp(λ)=o+λ,dp,dp=R⊤K−1p~,(6)
其中 o o o 为相机中心, p ~ = ( u , v , 1 ) ⊤ \tilde p=(u,v,1)^\top p~=(u,v,1)⊤ 为齐次像素坐标, λ > 0 \lambda>0 λ>0 为沿射线的深度参数。于是,每像素高斯预测在最简单的情形下可以写成
μ p , k = o + λ p , k d p + Δ ⊥ ∗ p , k , (7) \mu_{p,k} = o + \lambda_{p,k} d_p + \Delta^{\perp}*{p,k}, \tag{7} μp,k=o+λp,kdp+Δ⊥∗p,k,(7)
其中 λ ∗ p , k \lambda*{p,k} λ∗p,k 表示沿视线方向的放置深度, Δ p , k ⊥ \Delta^{\perp}_{p,k} Δp,k⊥ 表示小的离轴修正。这个公式揭示了路线一最核心的几何本质:它不是在全空间中自由搜索 primitive placement,而是在每个像素诱导出的局部几何管道中做 3D 提升。
这也是为什么 pixel-aligned 会成为第一代自然选择。因为与 voxel-aligned 相比,它不需要先离散整个 3D 空间;与 point-based global prediction 相比,它不需要先解决"点从哪里来"的无锚点初始化。每一个像素天然就是一个候选 primitive 的产生位置,每一条相机光线天然就是一个 primitive 的几何载体。Splatter Image 明确指出,其 predicted Gaussians 主要位于从相机到物体的 rays 上,但也允许 off-ray placement,从而实现 360° 表达;这恰好说明了 per-pixel 高斯并不是死板地贴在像平面上,而是利用 pixel-to-ray correspondence 作为 3D 提升的几何起点。
本质上,这种建模方式可理解为:
2D local evidence ; → camera geometry ; ray-conditioned 3D hypothesis ; → renderer supervision ; Gaussian scene . (8) \text{2D local evidence} ;\xrightarrow{\text{camera geometry}}; \text{ray-conditioned 3D hypothesis} ;\xrightarrow{\text{renderer supervision}}; \text{Gaussian scene}. \tag{8} 2D local evidence;camera geometry ;ray-conditioned 3D hypothesis;renderer supervision ;Gaussian scene.(8)
这里真正的先验,不是 3D structure-aware reasoning,而是 相机几何约束下的局部 lifting。它之所以强大,是因为把一个极难的"从图像直接构建 3D 资产"问题,分解成了大量局部、同构、共享参数的小问题;它之所以有限,也恰恰因为这些小问题在一开始是分散的、局部的、以视图为中心的,而不是统一在一个显式 3D 结构坐标系里进行全局决策。这个结论,是后续所有批判性分析的前提。
1.3 为什么最先出现的不是 voxel-aligned、pointmap、adaptive placement
先回答一下这个问题,不然"pixel-aligned 是自然起点"显得只是一句经验判断。
(1)不是 voxel-aligned:因为第一代目标不是建立 3D 规则结构,而是最低成本打通前馈闭环
若一开始采用 voxel-aligned 表达,那么模型必须先决定:3D 边界框如何定义、空间分辨率如何设定、空域稀疏性如何处理、视锥外区域如何裁剪。更关键的是,3D 稠密张量天然带来更重的内存和计算负担,而 feed-forward 3DGS 的早期价值主张恰恰是"利用 Gaussian Splatting 的高效显式 renderer 做快速训练与推理"。原始 3DGS 之所以引发方法爆发,一个重要原因就是它在保持高质量的同时,通过 3D Gaussian 表示与 visibility-aware rasterization 避免了空空间的大量无效计算。第一代前馈方法若再退回大体素场,实际上会主动放弃这一天然优势。
(2)不是 pointmap / set prediction:因为集合预测对第一代系统并不"最短路径"
无序点集或无序高斯集合当然更"像 3D",但这类设计对第一代系统来说会立即引入两个困难:其一,输出 cardinality 与排序不变性需要额外处理;其二,网络缺少稳定的空间索引去承接来自图像 backbone 的局部特征。相比之下,pixel-aligned 直接让第 ( u , v ) (u,v) (u,v) 个位置的 feature 对应第 ( u , v ) (u,v) (u,v) 个 Gaussian 槽位,避免了集合匹配、动态分配、slot discovery 等额外问题。Splatter Image 甚至明确把"集合存进图像容器"作为设计核心,其真正含义正是:先借助二维有序存储,回避三维无序集合学习的难题。
(3)不是 adaptive placement:因为第一代系统优先要"可训练",不是先要"最优稀疏"
adaptive placement 看似更合理,因为它允许高斯数量和位置随场景复杂度自适应变化;但这类方案要求网络先学会"哪里值得放 primitive、放几个、怎样分裂或合并"。这在研究后期是高价值问题,但在早期会显著提高训练不稳定性。pixelSplat 的贡献恰恰说明:即便是在固定 pixel-aligned 框架下,单是 Gaussian mean localization 都已经足够困难,甚至需要用 dense 3D probability distribution 和 differentiable sampling 才能缓解 local minima。既然 mean prediction 本身已是瓶颈,那么在第一代范式里继续叠加 adaptive placement,几乎必然会让问题复杂度失控。
换句话说,最先出现的不是"最像 3D 的方案",而是"最短时间内能把输入图像、2D backbone、显式 Gaussian 表示、快速渲染器接成端到端闭环的方案"。这正是 pixel-aligned 的工程合理性所在。
1.4 pixel-aligned 为什么在训练上简单、在实现上直接、在渲染上高效
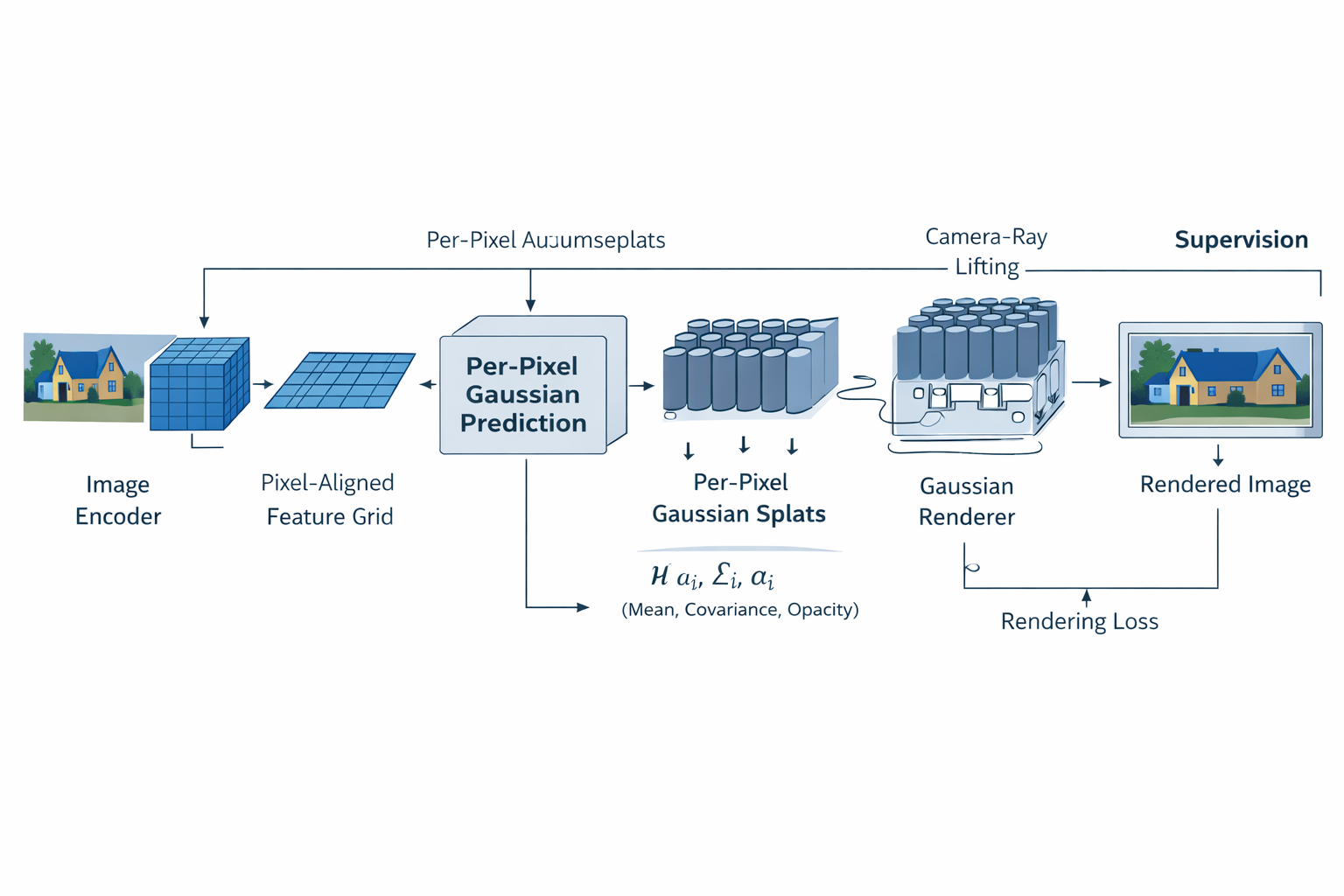
从系统架构上看,路线一的最小闭环几乎可以压缩成四步:
Image Encoder ; → ; Per-pixel Prediction Head ; → ; Unprojection / 3D Gaussian Construction ; → ; Gaussian Renderer . (9) \text{Image Encoder} ;\rightarrow; \text{Per-pixel Prediction Head} ;\rightarrow; \text{Unprojection / 3D Gaussian Construction} ;\rightarrow; \text{Gaussian Renderer}. \tag{9} Image Encoder;→;Per-pixel Prediction Head;→;Unprojection / 3D Gaussian Construction;→;Gaussian Renderer.(9)
这条链路的强大之处,在于它的每一环都已有成熟技术积累:图像编码器可复用大规模 2D 视觉模型;prediction head 只是标准 dense prediction;3D Gaussian construction 是显式参数生成;renderer 则由原始 3DGS 提供高效可微底座。于是,训练目标也自然回到最熟悉的像素监督或感知监督:
L = λ 1 L ∗ p h o t o + λ 2 L ∗ p e r c + λ 3 L ∗ r e g , (10) \mathcal{L}= \lambda_1 \mathcal{L}*{photo} + \lambda_2 \mathcal{L}*{perc} + \lambda_3 \mathcal{L}*{reg}, \tag{10} L=λ1L∗photo+λ2L∗perc+λ3L∗reg,(10)
其中 L ∗ p h o t o \mathcal{L}*{photo} L∗photo 可以是重建误差, L ∗ p e r c \mathcal{L}*{perc} L∗perc 可以是 LPIPS 一类感知损失, L ∗ r e g \mathcal{L}*{reg} L∗reg 是对 opacity、scale、density 等的规则化。因为 renderer 足够快,这种"预测显式高斯---渲染完整图像---直接回传"的训练范式才真正可行。3DGS 明确强调其 visibility-aware anisotropic splatting 兼顾训练效率与实时渲染;Splatter Image 也明确把 renderer 的高速视为训练 bottleneck 被解除的关键原因,并据此直接优化完整视图与感知指标。
工程上这意味着四个直接收益。
第一,训练直接。不需要测试时逐场景优化,也不需要中间再求一个隐式场再导出显式表示。pixelSplat 直接从图像对前馈输出高斯,latentSplat 直接输出 variational 3D feature Gaussians,再经过 splatting 与 2D decoder 得到结果。
第二,推理直接。输出本身就是 Gaussian scene asset,而不是一个还要后处理的中间体。pixelSplat 甚至将其结果定义为 interpretable and editable 3D radiance field,这一表述非常关键:它说明路线一不是只追求 NVS 图像质量,而是已经开始把"显式可操作资产"作为价值主张。
第三,实现直接。只要你有一个成熟的 2D backbone,就能快速原型化一代 feed-forward 3DGS。Splatter Image 几乎把这点展示得淋漓尽致:一张图像进去,一张"高斯图像容器"出来;pixelSplat 则把这个简单原型提升到稀疏双视图广基线 generalizable reconstruction。
第四,渲染高效。路线一不需要为了一次前馈推理再运行慢速体渲染器。高斯显式化之后,rendering pipeline 与原始 3DGS 高度兼容。也正因此,路线一不是单纯"学一个更快的 NeRF",而是在用显式 primitive 重构整个训练---推理---交付闭环。
1.5 为什么它在直觉上也最"像"一个能工作的系统
路线一之所以迅速被接受,还有一个常被低估的原因:它具有极强的 可视化直觉 与 调试友好性。
对研究者而言,per-pixel Gaussian prediction 几乎天然可解释。你可以直接可视化某一块图像区域究竟产生了多少高斯、这些高斯位于哪条视线附近、scale 是否发散、opacity 是否塌缩、颜色或 latent feature 是否异常。相比完全隐式的 3D 表征,这种"局部像素 ↔ \leftrightarrow ↔ 局部 primitive 槽位"的映射,极大降低了方法分析难度。pixelSplat 把这一点推进到更进一步:它不只输出可解释的高斯,还把 mean prediction 显式建模为一个 3D probability distribution 上的 differentiable sampling 问题。工程上这意味着,当系统失败时,研究者至少知道失败发生在"深度 / 位置假设的概率建模"而不是某个完全黑箱的隐藏状态。
对研发工程师而言,路线一也更像资产生产链而不是纯渲染链。高斯本身就是显式实体:有中心、有协方差、有 opacity、有颜色或 latent feature。它天然兼容可视化、剪裁、选择、编辑、下游渲染和潜在资产化流程。这也是为什么 pixelSplat 在 abstract 里直接把"editable"写进结果描述,这不是附带卖点,而是路线一的结构性意义:一旦你把 reconstruction 做成显式高斯输出,表示本身就开始具有资产感。
1.6 一个形式化判断:pixel-aligned 为什么是"工程上最自然的起点"
现在可以把上面的逻辑压缩成一个更形式化的判断。
设前馈式 3DGS 的设计目标为同时最小化以下代价:
J = C ∗ a r c h ⏟ ∗ 网络结构复杂度 + C ∗ t r a i n ⏟ ∗ 训练代价 + C ∗ r e n d e r ⏟ ∗ 渲染代价 + C ∗ r e p r ⏟ ∗ 表示与接口复杂度 . (11) \mathcal{J}= \underbrace{\mathcal{C}*{arch}}*{\text{网络结构复杂度}} + \underbrace{\mathcal{C}*{train}}*{\text{训练代价}} + \underbrace{\mathcal{C}*{render}}*{\text{渲染代价}} + \underbrace{\mathcal{C}*{repr}}*{\text{表示与接口复杂度}}. \tag{11} J= C∗arch∗网络结构复杂度+ C∗train∗训练代价+ C∗render∗渲染代价+ C∗repr∗表示与接口复杂度.(11)
对于第一代方法而言,pixel-aligned 的优势在于它同时降低了这四项:
- C a r c h \mathcal{C}_{arch} Carch:复用 2D backbone 与 dense head;
- C t r a i n \mathcal{C}_{train} Ctrain:输出槽位固定,避免集合匹配与动态 cardinality;
- C r e n d e r \mathcal{C}_{render} Crender:直接接入 Gaussian renderer;
- C r e p r \mathcal{C}_{repr} Crepr:输出就是显式高斯,不需要额外解码成资产。
因此,对"先把问题做成"的目标而言,pixel-aligned 不是偶然选择,而是一个近乎必然的局部最优。Splatter Image 证明了这条路对单视图对象 reconstruction 可以极度直接;pixelSplat 证明了它可以进一步扩展到稀疏双视图 generalizable 3D reconstruction;latentSplat 则说明,哪怕继续沿这条路前进,路线一内部也会自然走向 latent Gaussian 与生成式解码。
但需要提前埋下一个判断:"工程上最自然"并不等于"几何上最合理"。
因为 pixel-aligned 的全部便利,都建立在一个前提之上:让 2D 局部对齐结构承担 3D primitive placement 的主导责任。这个前提在起步阶段极其高效,在规模化与高精度阶段却会逐步变成瓶颈。TGS 后来明确指出,直接在同一 latent space 中学习高斯多种参数之间的复杂关系仍具挑战;MVSplat 更是直接把 Gaussian center localization 转向由 plane sweeping cost volume 提供几何线索的 depth estimation 问题。它们都在用不同方式说明:pixel-aligned 虽然自然,但它并不具备完整的 3D 组织能力。
1.7 pixel-aligned 的阶段性优缺点总表
下面这张表,可以作为本路线后续分析的总索引。
| 维度 | pixel-aligned / per-pixel Gaussian prediction 的收益 | pixel-aligned / per-pixel Gaussian prediction 的代价 |
|---|---|---|
| 网络接口 | 与 H × W H\times W H×W 特征图天然对齐,易于复用 2D backbone | 结构先验主要停留在 2D 局部邻域 |
| 训练实现 | 输出槽位固定,端到端训练直接 | primitive placement 缺少显式 3D 全局协调 |
| 渲染闭环 | 与 3DGS renderer 高度兼容,训练与推理高效 | 高效并不自动带来几何一致性 |
| 表示形式 | 输出显式高斯,具有可解释性与可编辑性 | 显式并不等于结构化,组织规则仍薄弱 |
| 几何起点 | 每个像素天然对应一条视线,便于 lifting | 本质仍是 ray-conditioned local hypothesis |
| 密度控制 | 固定每像素若干高斯,系统最容易落地 | 难以按真实 3D 复杂度自适应分配密度 |
| 多视图一致性 | 多视图输入可通过共享网络或轻量交互整合 | 局部 pixel-aligned 证据难以天然保证全局 3D 一致 |
| 遮挡与歧义 | 可借渲染监督间接修正 | 遮挡、重复纹理、低纹理区域仍易出错 |
这张表的结论很简单:pixel-aligned 是第一代前馈式 3DGS 的最优起点,不是 3D 结构建模的终点答案。
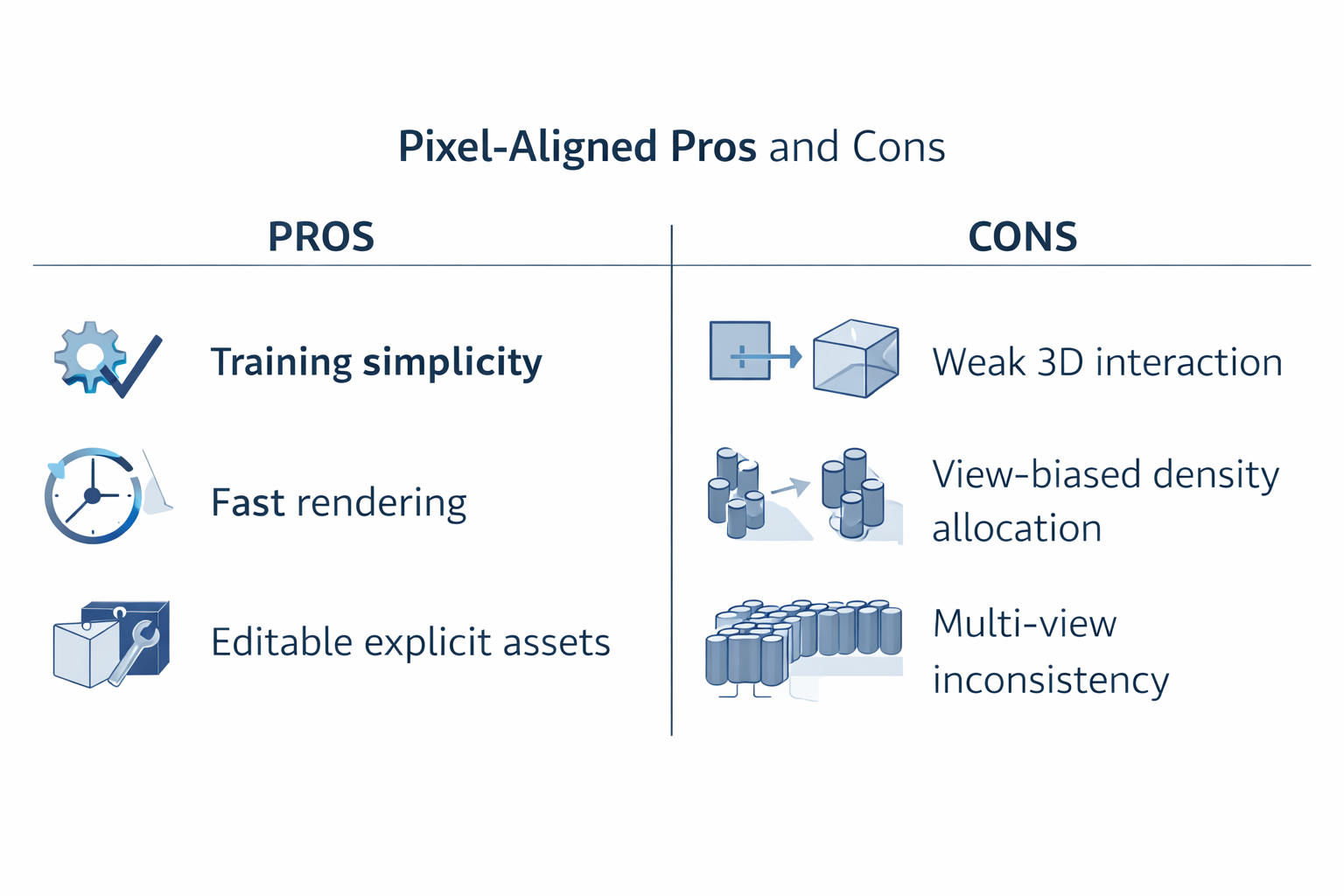
1.8 本章结论:pixel-aligned 不是偶然选项,而是第一代 feed-forward 3DGS 的必然工程形态
现在可以给出本章的最终判断。
前馈式 3DGS 之所以一开始几乎都选择 pixel-aligned,不是因为研究者"恰好喜欢像素对齐",而是因为在 3DGS renderer 已经成熟、2D 视觉 backbone 已经高度工业化的背景下,这条路线同时满足了四个条件:
- 网络输出自然:2D 编码器直接给出 pixel-aligned 特征;
- 几何 lifting 自然:每个像素天然诱导一条 3D 射线;
- 训练闭环自然:显式高斯可直接送入高速 renderer;
- 工程交付自然:输出本身就是可解释、可编辑的 3D 资产。
因此,pixel-aligned / per-pixel Gaussian prediction 是前馈式 3DGS 的第一代自然范式,几乎具有历史必然性。真正的分歧不在于它是否"足够聪明",而在于它是否已经具备了足够强的 3D structure-aware reasoning。对此,答案是否定的。而这,正是下一章讨论 pixelSplat 为何必须把 Gaussian center prediction 改写成"概率分布 + 可微采样"问题的前提。
2. pixelSplat 的核心思想:概率分布而不是硬回归
2.1 pixelSplat 真正要解决的,不是"预测高斯",而是"让高斯中心可训练"
从论文表述看,pixelSplat 的关键创新并不在于"第一次把图像变成高斯"这一表层动作,而在于它明确识别出:在 primitive-based、尤其是 locally supported 的显式表示里,Gaussian mean localization 才是最难、最不稳定、最决定成败的一环。
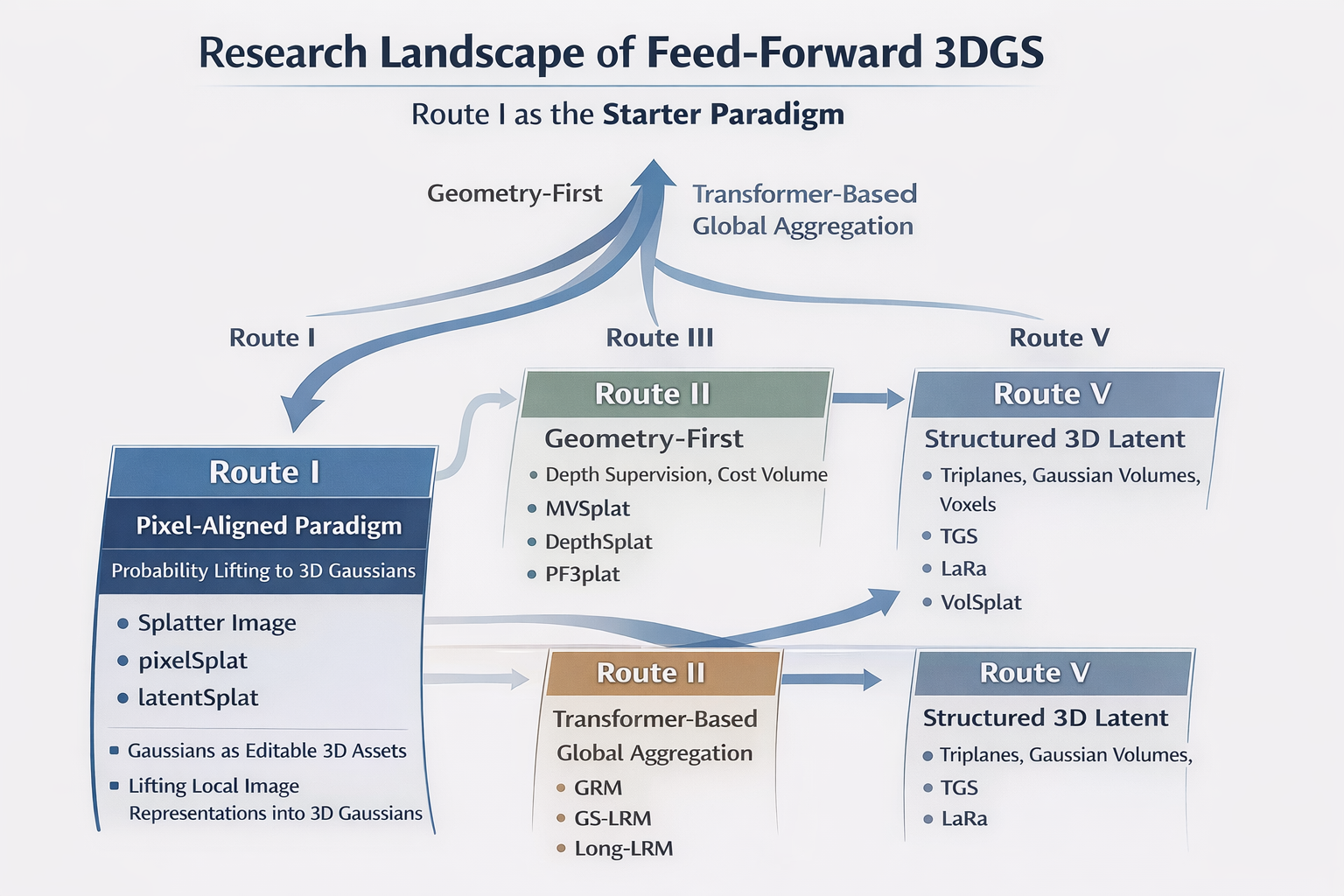
因此,作者并没有把问题停留在"每像素直接回归一个 3D 点",而是把每个像素沿视线方向的几何不确定性,显式写成一个 3D 概率分布,再从该分布中采样 Gaussian means,并通过可微机制回传梯度。论文摘要、方法章节与局部极值分析都明确指出:这是为了解决 sparse and locally supported representations 中的 local minima,而不是单纯为了让网络多一个 probabilistic 的包装.
形式上,设参考视图中像素 p = ( u , v ) p=(u,v) p=(u,v) 对应相机中心为 o o o、视线方向为 r p r_p rp,则最朴素的点估计版本是直接回归一 个深度 d p d_p dp,再做 unprojection:
μ p = o + d p , r p . (12) \mu_p = o + d_p, r_p. \tag{12} μp=o+dp,rp.(12)
这就是"硬回归 Gaussian center"的最直接形式。pixelSplat 的判断是:这个形式在表达上虽最短,但在优化上极其脆弱,因为一旦 d p d_p dp 偏离正确深度,primitive 的可见性、投影位置与渲染贡献会同步错位,导致梯度路径很差。于是它改为预测沿射线的离散深度分布,再从中采样深度桶索引。论文第 4.2 节明确写到:他们不直接预测 depth,而是预测"a Gaussian exists at a depth along the ray"的概率分布,并在前向时从该分布采样 Gaussian location。
这意味着,路线一内部真正的主问题不是
How to regress Gaussian parameters? \text{How to regress Gaussian parameters?} How to regress Gaussian parameters?
而是
How to localize Gaussian means under sparse supervision and local support? (13) \text{How to localize Gaussian means under sparse supervision and local support?} \tag{13} How to localize Gaussian means under sparse supervision and local support?(13)
换句话说,pixelSplat 的历史意义,首先在于它把"高斯中心定位"从一个看似普通的 dense regression 子任务,提升成了前馈式 3DGS 的核心难题。后面路线二之所以走向 depth / cost volume,本质上也是在承认这一点。
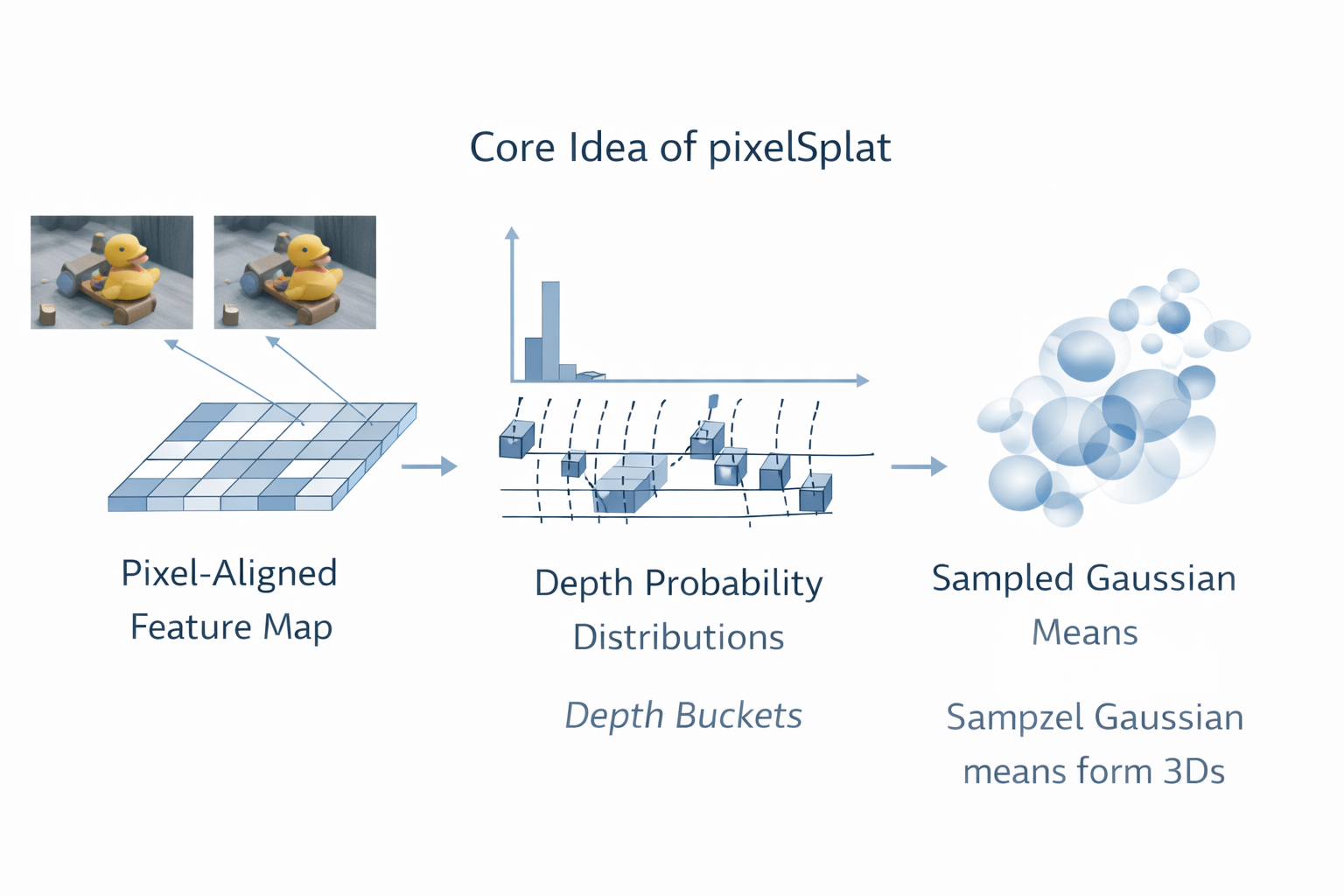
2.2 为什么 Gaussian mean prediction 比 scale / opacity / color 更难
这是路线一必须反复回答的第一学术问题。
设目标图像上的像素损失为
L = ∑ x ∈ Ω ℓ ( C ( x ; G ) , , I ⋆ ( x ) ) , (14) \mathcal{L}= \sum_{x\in\Omega} \ell\big(C(x;\mathcal{G}),, I^\star(x)\big), \tag{14} L=x∈Ω∑ℓ(C(x;G),,I⋆(x)),(14)
其中 C ( x ; G ) C(x;\mathcal{G}) C(x;G) 是由高斯集合 G \mathcal{G} G 经过 splatting renderer 得到的颜色。对单个 Gaussian G i = ( μ i , Σ i , α i , ϕ i ) G_i=(\mu_i,\Sigma_i,\alpha_i,\phi_i) Gi=(μi,Σi,αi,ϕi) 而言, ϕ i \phi_i ϕi 可以表示颜色或 SH 系数。若暂不考虑复杂遮挡,仅从局部线性化角度看,color / opacity / scale 的作用主要体现在"已有贡献"的幅值和扩散形态上;但 mean 的作用首先决定的是 这个 Gaussian 究竟是否会对正确像素区域产生贡献。
可以把某个 Gaussian 对像素 x x x 的投影权重抽象写成
w i ( x ) ∝ α i , exp ! ( − 1 2 ( π ( μ i ) − x ) ⊤ S i − 1 ( π ( μ i ) − x ) ) , (15) w_i(x) \propto \alpha_i , \exp!\Big( -\tfrac12 (\pi(\mu_i)-x)^\top \mathbf{S}_i^{-1} (\pi(\mu_i)-x) \Big), \tag{15} wi(x)∝αi,exp!(−21(π(μi)−x)⊤Si−1(π(μi)−x)),(15)
其中 π ( μ i ) \pi(\mu_i) π(μi) 是 3D 中心投影到像平面的结果, S i \mathbf{S}_i Si 是投影后的二维协方差。于是:
- 改颜色 ϕ i \phi_i ϕi,主要是在已有权重 w i ( x ) w_i(x) wi(x) 的地方改"画什么";
- 改 opacity α i \alpha_i αi,主要是在已有位置上改"画多强";
- 改 scale / covariance,主要是在已有中心附近改"覆盖多大范围";
- 改 mean μ i \mu_i μi,则是在改"它究竟画在哪里、是否还在正确可见表面上"。
因此,mean prediction 的困难不是参数维度更高,而是它控制了 support assignment:哪个 primitive 对哪个表面、哪个像素、哪个可见层负责。只要中心错位,后面的 scale / opacity / color 再精确,往往也只是把错误的位置渲染得更稳定。这个逻辑与 pixelSplat 对"the most consequential question is how to parameterize the position of each Gaussian"的强调是一致的。
从优化角度进一步看,若 μ i \mu_i μi 已接近正确表面,则对 ϕ i , α i , Σ i \phi_i,\alpha_i,\Sigma_i ϕi,αi,Σi 的梯度往往仍具有较强局部可修正性;但若 μ i \mu_i μi 本身落在错误深度层、错误可见面甚至空域中,那么渲染器给它分配到的监督信号要么极弱、要么方向混乱、要么被遮挡关系截断。这就是为什么 mean prediction 比其他属性更像一个 latent assignment + geometric localization 问题,而不是普通回归问题。换句话说,scale / opacity / color 更多是在"已知谁负责什么"的条件下做局部拟合;而 mean prediction 是在决定"谁该为哪里负责"。这两者难度不是同一层级。这个判断,也是后面所有路线分叉的理论起点。
2.3 直接硬回归 mean,为什么会不稳定
若直接让网络输出 d p d_p dp 或 μ p \mu_p μp,那么 loss 对中心的梯度链路可抽象为
∂ L ∂ μ p = ∑ x ∈ Ω ∂ L ∂ C ( x ) ∂ C ( x ) ∂ w p ( x ) ∂ w p ( x ) ∂ π ( μ p ) ∂ π ( μ p ) ∂ μ p . (16) \frac{\partial \mathcal{L}}{\partial \mu_p}= \sum_{x\in\Omega} \frac{\partial \mathcal{L}}{\partial C(x)} \frac{\partial C(x)}{\partial w_p(x)} \frac{\partial w_p(x)}{\partial \pi(\mu_p)} \frac{\partial \pi(\mu_p)}{\partial \mu_p}. \tag{16} ∂μp∂L=x∈Ω∑∂C(x)∂L∂wp(x)∂C(x)∂π(μp)∂wp(x)∂μp∂π(μp).(16)
表面上,这只是正常的链式法则;但问题在于 ∂ w p ( x ) ∂ π ( μ p ) \frac{\partial w_p(x)}{\partial \pi(\mu_p)} ∂π(μp)∂wp(x) 对 support 极其敏感。若当前 Gaussian 投影位置与目标表面投影相距较远,则高斯核的局部支撑会让该项迅速衰减;若中间还叠加 visibility / transmittance,则梯度甚至会被错误前景完全截断。于是,网络虽在数学上"可导",在优化上却接近"不可到达"。
pixelSplat 在第 3 节专门把这一点写成 primitive fitting 的 local minima 问题,并把其类比到 Gaussian mixture model 的非凸拟合。论文明确指出两层障碍:第一,Gaussian primitives have local support,若离正确位置超过若干标准差,梯度会消失;第二,即便已经靠近正确位置,也仍需存在一条 loss 单调下降的路径把 primitive 推到最终位置,而在 differentiable rendering 中这往往不成立,因为 Gaussian 穿越空域或错误遮挡关系时会产生非单调损失。
这句话非常关键。因为它说明 pixelSplat 并不是在说"网络回归能力不够强",而是在说 参数化本身诱发了坏优化地形。坏的不是网络容量,而是 primitive placement 的坐标化方式。换句话说,若我们坚持把每个像素的几何假设压成一个点估计,那么网络必须在一个高度不平滑、非凸、含遮挡切换的 loss landscape 里直接搜索正确位置;而 sparse-view 场景又会进一步放大这类不稳定性,因为多视图几何约束本身就不足。pixelSplat 的 probabilistic prediction,本质上是对这一优化地形进行重新参数化,而不是简单增加监督。
2.4 pixelSplat 的改写:不是预测一个深度,而是预测一条视线上的存在概率
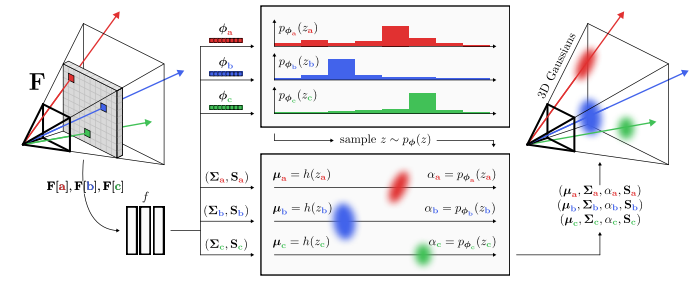
pixelSplat 的具体做法,是把单点深度回归改写成沿 ray 的离散概率密度预测。设射线为
r p ( d ) = o + d , r p , d ∈ d min , d max , (17) r_p(d)=o+d,r_p, \qquad d\ind_{\\min},d_{\\max}, \tag{17} rp(d)=o+d,rp,d∈dmin,dmax,(17)
作者在这一区间上离散出若干 depth buckets,并在 disparity space 中进行参数化。对每个像素特征 f p f_p fp,网络输出一组 logits,经 softmax 后得到
q p ( b ) = s o f t m a x ( z p ) ∗ b , b ∈ 1 , ... , B , (18) q_p(b)=\mathrm{softmax}(z_p)*b, \qquad b\in{1,\dots,B}, \tag{18} qp(b)=softmax(zp)∗b,b∈1,...,B,(18)
其中 q p ( b ) q_p(b) qp(b) 表示"该 ray 在第 b b b 个深度桶处存在表面 / Gaussian 的概率"。同时,网络还为每个 bucket 预测一个局部 offset δ ∗ p , b \delta*{p,b} δ∗p,b,用于在桶内细化中心位置。于是,Gaussian mean 的构造可写为
d p = d b + δ p , b , μ p = o + d p , r p , b ∼ C a t ( q p ) . (19) d_p = d_b + \delta_{p,b}, \qquad \mu_p = o + d_p, r_p, \qquad b\sim \mathrm{Cat}(q_p). \tag{19} dp=db+δp,b,μp=o+dp,rp,b∼Cat(qp).(19)
这正是论文第 4.2 节的核心:他们不预测 depth directly,而是预测 depth probability density,再 sample Gaussian location。
这一改写的结构性意义在于,它把"沿 ray 只能选一个答案"的硬回归,变成了"先保留多个候选,再通过训练逐步收缩概率质量"的软决策。于是,网络不必在训练初期就赌中唯一正确深度,而可以先把若干 plausible hypothesis 保留在分布中,再让渲染监督去压缩不合理的深度桶。这就是为什么我更愿意把它理解为一种 可训练的 hypothesis management,而不仅仅是 probabilistic depth regression。
从表征角度看,这一步还有一个更深的意义:一旦中心位置由分布而不是点值控制,primitive 的"出现 / 消失"就不再依赖显式的非可微 spawning / pruning 规则,而可以通过概率质量的集中与消散来隐式实现。pixelSplat 论文明确指出,这种机制使 Gaussian primitives can implicitly be spawned or deleted during training,同时保持 gradient flow;这与原始 3DGS 中依赖 adaptive density control 的非可微启发式形成鲜明对比。
2.5 为什么说 pixelSplat 的历史意义,在于把 center prediction 变成"可训练问题"
这一章最核心的判断,可以写成一句话:
pixelSplat does not remove geometric ambiguity; it makes ambiguity trainable. (20) \text{pixelSplat does not remove geometric ambiguity;} \quad \text{it makes ambiguity trainable.} \tag{20} pixelSplat does not remove geometric ambiguity;it makes ambiguity trainable.(20)
需要明确的是,pixelSplat 并没有神奇地消除 sparse-view 的几何歧义。两个视图仍然可能面对低纹理、重复纹理、遮挡与尺度不确定性;ray 上仍然可能存在多个相互竞争的深度假设。它真正做的是:把原先"一个错误点估计导致整个 primitive 失去梯度"的离散失败模式,改写成"多个候选深度桶之间的概率竞争",从而给优化过程保留了一条更宽的梯度通道。论文在消融中也直接比较了 "No Sampling" 与其完整方案,并把 speckling artifacts 与 local minima 联系起来。
因此,pixelSplat 的方法贡献,不能简单描述成"提出了一种概率预测头"。更准确的说法是:它第一次把 Gaussian center prediction 从一个不稳定的 primitive regression,重写成一个带有显式不确定性管理的 differentiable sampling 问题。后续无论你选择几何优先、深度优先、体素优先还是 latent 优先,都无法绕开这个认识:在前馈式 3DGS 中,center placement 是主矛盾。
3. 可微采样如何缓解 local minima
3.1 稀疏视角、局部支撑表示与局部最优之间的关系
这是本文的第二个核心问题。
先看"局部支撑表示"本身。3D Gaussian primitive 不是像密集体渲染那样沿整条射线连续分布,而是以有限数量、局部影响域的显式核函数来近似场景。原始 3DGS 正是利用了这一点,才避免了空域中大量无效计算,并通过 visibility-aware anisotropic splatting 获得高速渲染。可也正因为 primitive 是局部支撑的,每个 Gaussian 只在自己附近产生显著影响。这对渲染效率是优点,对优化则是双刃剑:一旦初始化或预测位置偏得太远,梯度就会变得很弱。
从稀疏视角的角度看,问题进一步恶化。设真实表面点为 X ⋆ X^\star X⋆,当前 Gaussian center 为 μ \mu μ。在只有少量输入视图时,图像监督并不会直接告诉你"3D 中心应该朝哪个方向移动多少";它只会通过若干目标图像上的重投影误差,间接地、经过遮挡与可见性关系后给出信号。因此,优化实际上在求解一个高度欠定的逆问题:
Find μ ∈ R 3 s.t. Π v ( μ ) explains sparse observed images I v . (21) \text{Find } \mu \in \mathbb{R}^3 \quad \text{s.t.} \quad \Pi_v(\mu) \text{ explains sparse observed images } {I_v}. \tag{21} Find μ∈R3s.t.Πv(μ) explains sparse observed images Iv.(21)
若输入视图足够少,则多个 3D 点可能在观测上近似等价;若表示又是局部支撑的,则错误候选之间不会彼此平滑过渡,而是呈现多个分离的吸引域。于是,稀疏视角与局部支撑叠加,就自然形成了对 local minima 友好的优化地形。pixelSplat 正是在这个意义上说 local minima 是 sparse and locally supported representations 的内在问题。
3.2 为什么 center 一旦错位,后续优化很难自我纠正
可以把 Gaussian 对某个目标表面点附近的贡献抽象为
κ ( μ ; X ⋆ ) = exp ! ( − 1 2 ( μ − X ⋆ ) ⊤ Σ − 1 ( μ − X ⋆ ) ) . (22) \kappa(\mu;X^\star)= \exp!\Big( -\frac{1}{2} (\mu-X^\star)^\top \Sigma^{-1} (\mu-X^\star) \Big). \tag{22} κ(μ;X⋆)=exp!(−21(μ−X⋆)⊤Σ−1(μ−X⋆)).(22)
则
∇ μ κ = − κ ( μ ; X ⋆ ) , Σ − 1 ( μ − X ⋆ ) . (23) \nabla_{\mu}\kappa= -\kappa(\mu;X^\star),\Sigma^{-1}(\mu-X^\star). \tag{23} ∇μκ=−κ(μ;X⋆),Σ−1(μ−X⋆).(23)
这个式子说明,只要 ∣ μ − X ⋆ ∣ |\mu-X^\star| ∣μ−X⋆∣ 相对协方差尺度足够大, κ \kappa κ 与其梯度都会指数衰减。也就是说,中心错位不是"还能慢慢拉回来"的连续退化,而常常是"直接失去有效梯度"的塌陷。
更麻烦的是,渲染并非单个高斯独立成像,而是带有前后层叠、alpha compositing 和 visibility 排序。于是,从错误位置移动到正确位置,并不一定存在一条 loss 单调下降的路径。pixelSplat 论文把这一点说得非常直接:即使某个 Gaussian 已经足够接近正确位置,仍需要存在一条 loss decreases monotonically 的路径;但在 differentiable rendering 中,这通常不成立,因为 Gaussian 需要穿越空域,而在这段过程中它可能错误遮挡背景特征。
这可以进一步形式化为路径问题。设 μ ( t ) \mu(t) μ(t) 是从错误位置 μ 0 \mu_0 μ0 到正确位置 μ 1 \mu_1 μ1 的连续轨迹,若要靠梯度下降把 Gaussian 拉回去,理想情况应满足
d d t L ( μ ( t ) ) < 0 , t ∈ 0 , 1 . (24) \frac{d}{dt}\mathcal{L}(\mu(t)) < 0, \qquad t\in0,1. \tag{24} dtdL(μ(t))<0,t∈0,1.(24)
但在遮挡切换点、可见表面切换点以及背景前景交错区域, L ( μ ( t ) ) \mathcal{L}(\mu(t)) L(μ(t)) 往往会出现非单调波动,甚至先升后降。此时,标准梯度下降会停在某个局部稳定但几何错误的位置。换句话说,primitive regression 的困难并不只是"信号弱",而是"路径坏"。这也是为什么单纯加大 backbone 或训练数据,并不能从根本上消除 mean localization 的不稳定。
3.3 可微采样做了什么:不是直接求最优位置,而是先在分布上优化
pixelSplat 的关键转向,是把对 μ \mu μ 的直接优化,改成对深度分布 q p ( b ) q_p(b) qp(b) 的优化。也就是说,优化变量从一个连续点估计,变成一组概率质量:
μ p ; ⟸ ; b ∼ q p ( ⋅ ) , d p = d b + δ p , b . (25) \mu_p ;\Longleftarrow; b\sim q_p(\cdot),\quad d_p=d_b+\delta_{p,b}. \tag{25} μp;⟸;b∼qp(⋅),dp=db+δp,b.(25)
这样一来,训练初期不需要让网络立刻把全部概率质量压到唯一正确位置,而可以先在若干 plausible buckets 上分配概率,再通过渲染损失逐步强化正确桶、削弱错误桶。论文第 4.2 节明确写道:他们在前向时采样 bucket,并让网络预测 probabilities 而不是 depth directly。
从优化几何上看,这相当于把原本在 3D 空间中难以穿越的离散吸引域,先搬到一个概率单纯形上处理。原先的困难是:Gaussian 必须真的从错误空间位置移动到正确空间位置;现在的策略是:Gaussian 可以"在每次前向中重新出生"于不同深度桶,而训练则在更平滑的概率空间中逐步收缩支持集。于是,网络不必依赖一条从错误位置连续滑向正确位置的几何路径,而是通过改变采样分布,让正确假设出现得越来越频繁。
这正是 pixelSplat 论文所说 "implicitly spawned or deleted during training" 的含义。需要强调的是,这里所谓"spawn / delete"并不是显式结构编辑,而是概率质量重排带来的统计意义上的出现 / 消失。相比原始 3DGS 的非可微 density control,它更适合 generalizable、需要端到端反传的设定。
3.4 reparameterization trick 在这里如何起作用
问题随之而来:采样本身是非可导的。若 b ∼ C a t ( q p ) b\sim \mathrm{Cat}(q_p) b∼Cat(qp),则 μ p \mu_p μp 对 q p q_p qp 的梯度无法直接通过标准反传获得。pixelSplat 的解决办法,是一个很有代表性的工程-优化折中:把采样到的深度桶概率,复用为该 Gaussian 的 opacity。论文明确写道,他们将 sampled bucket 的概率值赋给 Gaussian opacity,从而把 loss 对 opacity 的梯度转移给 depth probability buckets。作者并给出直观解释:如果采样到正确深度,梯度会增大其 opacity,也就提高其后续被采样的概率;若采样到错误深度,则梯度会减小 opacity,降低其继续被采样的概率。
抽象地写,可记
b ∼ q p ( ⋅ ) , α p = q p ( b ) . (26) b \sim q_p(\cdot),\qquad \alpha_p = q_p(b). \tag{26} b∼qp(⋅),αp=qp(b).(26)
于是反向中,损失对 α p \alpha_p αp 的梯度会影响到对应 bucket 概率:
∂ L ∂ q p ( b ) ≈ ∂ L ∂ α p . (27) \frac{\partial \mathcal{L}}{\partial q_p(b)} \approx \frac{\partial \mathcal{L}}{\partial \alpha_p}. \tag{27} ∂qp(b)∂L≈∂αp∂L.(27)
这当然不是严格意义上对离散采样的无偏梯度估计,但它构造出了一条足够实用、与 renderer 兼容、且能把"采样结果是否有用"反馈给 bucket probability 的学习通道。
从学术上看,这一招的价值不在于它多么"纯粹",而在于它非常准确地抓住了问题结构:Gaussian 在渲染中本就通过 opacity 参与 compositing,因此把"这个深度桶是否值得保留"的信用分配,借道 opacity 传给 depth distribution,是一种极其贴合表示本身的重参数化。换句话说,它不是外加的 trick,而是把 representation semantics 和 gradient routing 对齐了。
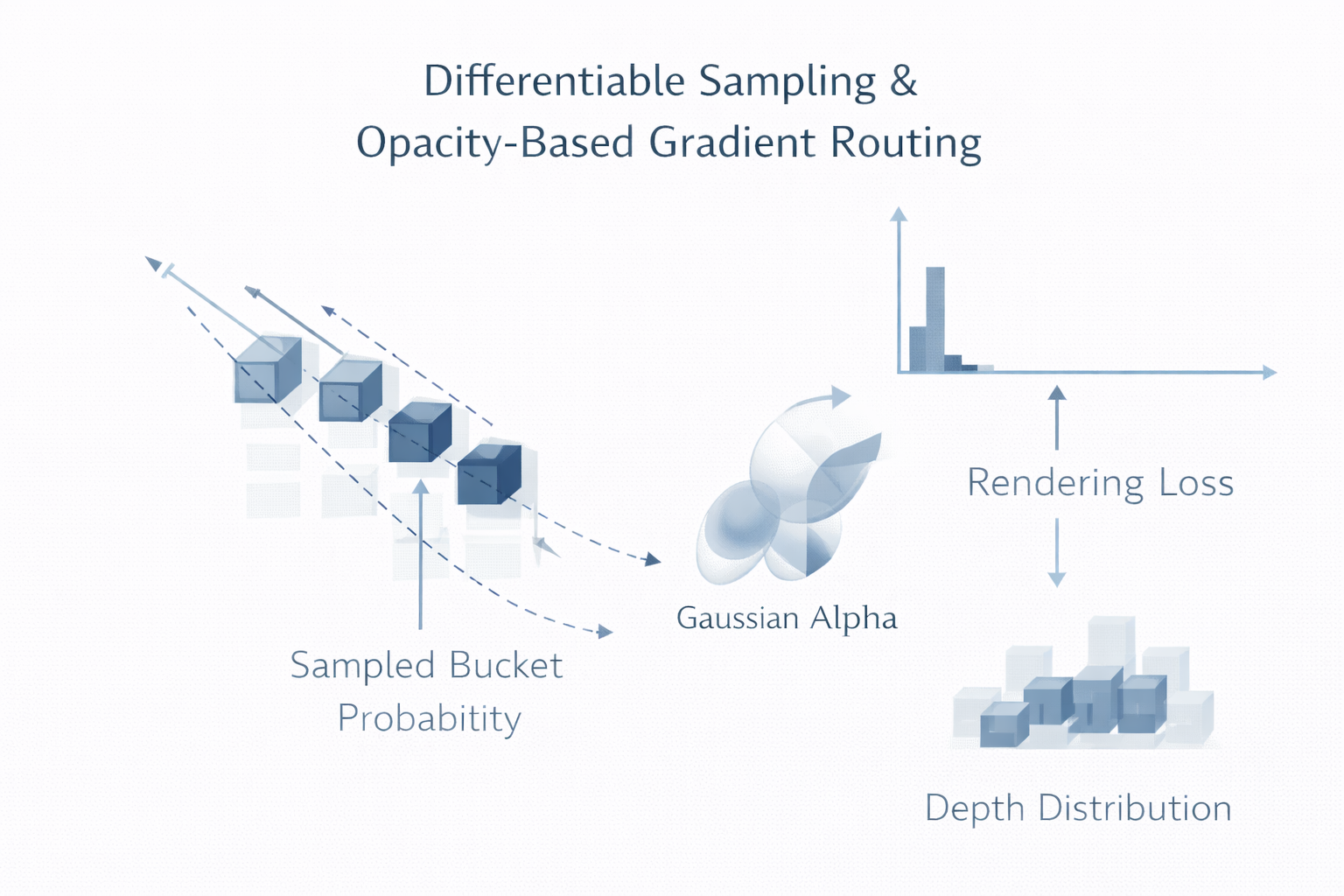
3.5 可微采样缓解了什么,又没有解决什么
必须克制地说,pixelSplat 的 differentiable sampling 缓解 了 local minima,但没有从根本上消除几何歧义。
它缓解的,是下面这类失败模式:
- 初期只能猜到若干候选深度,无法一次命中唯一正确值;
- 错误单点回归导致 primitive 完全失去有效梯度;
- generalizable 场景下不能依赖非可微 pruning / splitting heuristic;
- 需要在 end-to-end 系统中维持 Gaussian representation 的可微性。
但它没有解决的,是更根本的结构性问题:
- 候选深度仍主要沿单个 ray 组织,而不是在真正的 3D structure-aware latent 中组织;
- 多视图之间的一致性主要依赖编码器与渲染监督间接形成,而不是显式几何 matching;
- 遮挡、重复纹理、低纹理区域仍然可能让多个深度桶长期竞争;
- 正确中心定位仍然是主瓶颈,因此后续方法很自然会把问题进一步转化为 depth / geometry estimation。MVSplat 就明确把"accurately localize the Gaussian centers"作为目标,并引入 plane-sweeping cost volume 来提供几何线索。
因此,本章可以收束成一个非常关键的判断:
Differentiable sampling improves gradient access to the right hypothesis, \text{Differentiable sampling improves gradient access to the right hypothesis,} Differentiable sampling improves gradient access to the right hypothesis,
but it does not yet make the hypothesis space itself truly 3D-structured. (28) \text{but it does not yet make the hypothesis space itself truly 3D-structured.} \tag{28} but it does not yet make the hypothesis space itself truly 3D-structured.(28)
这句话,正是路线一与后续路线二、路线五分叉的理论边界。
4. pixel-aligned 方案为什么天然简单
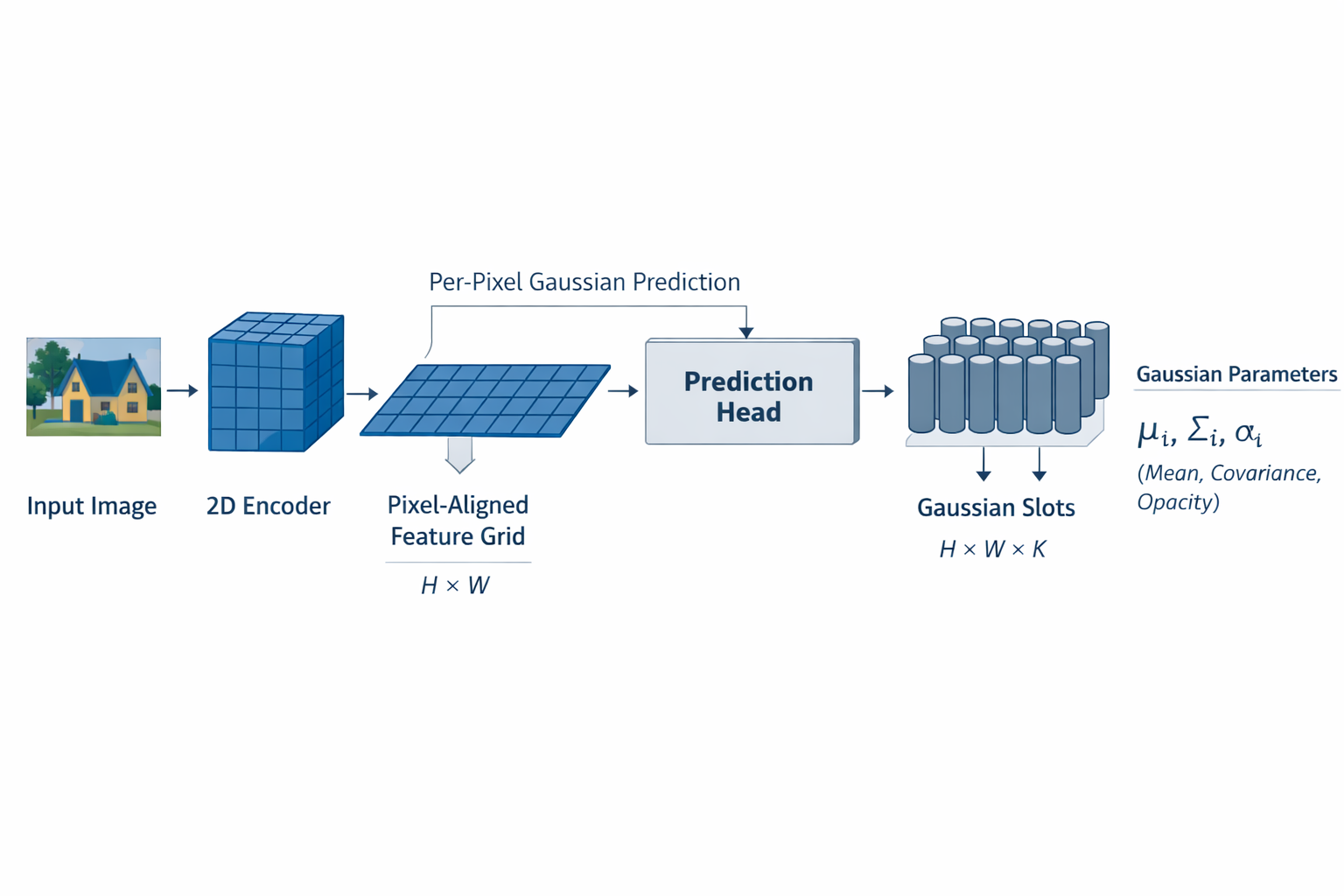
4.1 "简单"不是贬义,而是路线一最大的工程魅力
到这里可以更准确地理解"pixel-aligned 方案为什么天然简单"。这里的"简单"并不意味着任务容易,而是指它在系统闭环上极其短:输入是图像,编码器是 2D backbone,输出头是 dense per-pixel prediction,几何 lifting 通过相机射线完成,渲染则直接复用 3DGS 的 fast visibility-aware splatting。Splatter Image 把这一点说得非常明确:用 2D image 作为 3D Gaussians 的 container,可以把 reconstruction 问题直接化约为一个 image-to-image neural network,并只使用高效的 2D operators;而原始 3DGS 已经证明了 Gaussian renderer 同时支持高质量训练与实时渲染。
如果把路线一的最小系统写成函数复合,可以得到
G = U ∘ H ∘ E ( I v , Π v v = 1 M ) , (29) \mathcal{G}= \mathcal{U} \circ H \circ E \big({I_v,\Pi_v}_{v=1}^M\big), \tag{29} G=U∘H∘E(Iv,Πvv=1M),(29)
其中 E E E 是图像编码器, H H H 是 per-pixel Gaussian prediction head, U \mathcal{U} U 是 unprojection / Gaussian construction。随后通过 renderer R \mathcal{R} R 得到监督图像:
I ^ t = R ( G , Π t ) . (30) \hat I_t = \mathcal{R}(\mathcal{G},\Pi_t). \tag{30} I^t=R(G,Πt).(30)
这条链路的每个模块都是"视觉系统里最标准、最成熟、最容易替换"的部件,因此路线一特别适合作为起步范式:它没有强迫研究者先解决新的 3D 数据结构、复杂集合操作或昂贵体渲染,而是用最短路径把 2D perception 与 3D explicit rendering 连起来。
4.2 它为什么容易与已有 2D backbone 兼容
pixel-aligned 的另一个"天然简单",来自它与视觉工业栈的高度兼容。
在路线一中,编码器输出通常仍是二维特征图
F v = E θ ( I v ) ∈ R H × W × C , (31) F_v = E_\theta(I_v)\in\mathbb{R}^{H\times W\times C}, \tag{31} Fv=Eθ(Iv)∈RH×W×C,(31)
而 prediction head 只需在每个像素位置读出一个特征向量,再映射成若干 Gaussian 参数:
h ( F v ( u , v ) ) ⟶ ( depth / depth-distribution , Σ , α , ϕ ) . (32) h(F_v(u,v)) \longrightarrow (\text{depth / depth-distribution},\Sigma,\alpha,\phi). \tag{32} h(Fv(u,v))⟶(depth / depth-distribution,Σ,α,ϕ).(32)
这意味着,研究者可以几乎零摩擦地继承已有的 U-Net、FPN、ViT feature pyramid、cross-view attention 模块与 dense prediction 训练范式。Splatter Image 直接使用 image-to-image 架构,并特别强调这种方式能够只依赖 2D convolution;pixelSplat 也把自己的方法明确描述为 two-view image encoder + pixel-aligned Gaussian prediction module。
工程上这有三个直接后果。
第一,数据接口简单。输入依然是标准多视图图像与相机参数,不需要额外的 3D supervision 才能启动。pixelSplat 与 MVSplat 都强调仅依赖 photometric supervision 训练 feed-forward 3DGS;只是路线一和路线二在 center localization 的处理上分道扬镳。
第二,模块替换方便。你可以升级编码器、换 attention、加 epipolar sampling,但只要最终还能在 pixel grid 上产生 feature,整条管线就不需要重写。pixelSplat 正是在这样的兼容框架下,把图像对编码、尺度歧义处理、概率深度采样拼成了统一系统。
第三,可视化与调试直接。因为每个输出槽位仍绑定到输入像素或局部像素区域,开发者可以很容易检查:哪个位置的概率分布发散、哪个区域的高斯密度异常、哪个视图的 lifting 出错。这种"从 feature grid 到 explicit primitives"的可检查性,是路线一能快速形成研究共识的重要原因。pixelSplat 与 Splatter Image 都把"interpretable / explicit"作为结果表达的一部分。
4.3 它为什么便于高效渲染与端到端训练
前馈式 3DGS 若没有高速 renderer,所谓"简单"其实只是一种前端简化;真正让路线一成立的是,后端渲染闭环同样足够短。原始 3DGS 的贡献之一,正是在显式高斯表示之上建立了 fast visibility-aware rendering,支持 anisotropic splatting、快速反传与实时渲染。正因为 renderer 足够高效,像 Splatter Image 这样的方法才敢在训练中直接生成完整图像,并使用 LPIPS 一类 image-level loss;pixelSplat 也才能把 generalizable reconstruction 建立在显式 Gaussian representation 上,而不是退回采样密集、内存昂贵的体渲染。
若把训练开销粗略写成
C ∗ t r a i n ≈ C ∗ e n c o d e + C ∗ p r e d i c t + C ∗ r e n d e r , (33) \mathcal{C}*{train} \approx \mathcal{C}*{encode} + \mathcal{C}*{predict} + \mathcal{C}*{render}, \tag{33} C∗train≈C∗encode+C∗predict+C∗render,(33)
那么在路线一中:
- C e n c o d e \mathcal{C}_{encode} Cencode 主要来自标准 2D backbone;
- C p r e d i c t \mathcal{C}_{predict} Cpredict 主要来自 per-pixel dense head;
- C r e n d e r \mathcal{C}_{render} Crender 来自 Gaussian splatting,而非射线上大量采样的 volume rendering。
这就是为什么路线一经常给人一种"训练直接、推理直接、渲染快"的整体印象。注意,这并不是因为它在几何上没有难题,而是因为它把几何难题尽可能压缩在"中心怎么放"这一个局部模块里,而没有把整套系统都做重。
换句话说,pixel-aligned 的"简单"是一种 pipeline simplicity ,不是 problem simplicity。问题仍然很难,只是难点被集中在 primitive placement,而其余部分则尽可能复用成熟工业部件。
4.4 为什么这条路线具有直觉性、可视化性、可解释性
路线一还有一个很重要但常被忽略的优点:它不仅在实现上短闭环,在认知上也短闭环。
当模型输出的是 pixel-aligned Gaussians 时,研究者天然会把它理解为一种"从图像局部证据 lift 出局部 3D primitive"的过程。这种过程非常便于解释:
- 某个像素区域为何生成一簇高斯;
- 某个 ray 上为何出现多峰深度概率;
- 某个表面为何因为中心错位而出现 speckle / ghosting;
- 某个高斯为何可直接被编辑、裁剪、可视化。
pixelSplat 把输出结果描述为 interpretable and editable 3D radiance field;Splatter Image 也反复强调显式高斯集合既渲染快又空间效率高。对研究社区而言,这种"结果长得像资产、错误长得像几何问题"的表达形式,比纯隐式场更利于形成共同语言。
从方法论角度看,这种可解释性还有一个更深的意义:它使路线一成为后续所有路线的对照基线。因为只有当你先拥有一个"足够直观的起点范式",你才知道后来引入 cost volume、latent Gaussian、triplane、voxel 或 adaptive placement 到底在修复什么。也正因此,路线一虽然不是终点答案,却是最适合作为研究地图起点的那条路线。
4.5 但"天然简单"也意味着:它更像 2D-driven 3D lifting,而不是 3D 结构化推理
这正是本文必须显式回答的第三个学术问题。
pixel-aligned 方案之所以简单,是因为它把 3D reconstruction 的很多复杂性,都推迟到"局部像素证据如何被 lift 到 3D"这个过程里解决。于是,它天然更接近下面这种计算图:
2D features → ray-conditioned hypotheses → explicit Gaussians → rendering supervision . (34) \text{2D features} \rightarrow \text{ray-conditioned hypotheses} \rightarrow \text{explicit Gaussians} \rightarrow \text{rendering supervision}. \tag{34} 2D features→ray-conditioned hypotheses→explicit Gaussians→rendering supervision.(34)
而不是
global 3D structure reasoning → adaptive primitive placement → renderable Gaussian scene . (35) \text{global 3D structure reasoning} \rightarrow \text{adaptive primitive placement} \rightarrow \text{renderable Gaussian scene}. \tag{35} global 3D structure reasoning→adaptive primitive placement→renderable Gaussian scene.(35)
这两种范式的真正分歧,不在于谁最终都输出高斯,而在于 高斯的组织原则到底来自 2D 局部 lifting,还是来自 3D 结构先验主导的全局决策。
路线一选择前者,因此它的系统显得很轻、很直观、很易训练;但这也意味着它天然缺少强 3D interaction。MVSplat 之所以随后把 Gaussian center localization 转向 cost volume / depth estimation,本质上就是在说:只靠 pixel-aligned local features 不足以稳定地完成 center placement,需要更显式的 cross-view geometry cues。这个分歧,不是局部技巧,而是路线层面的分叉。
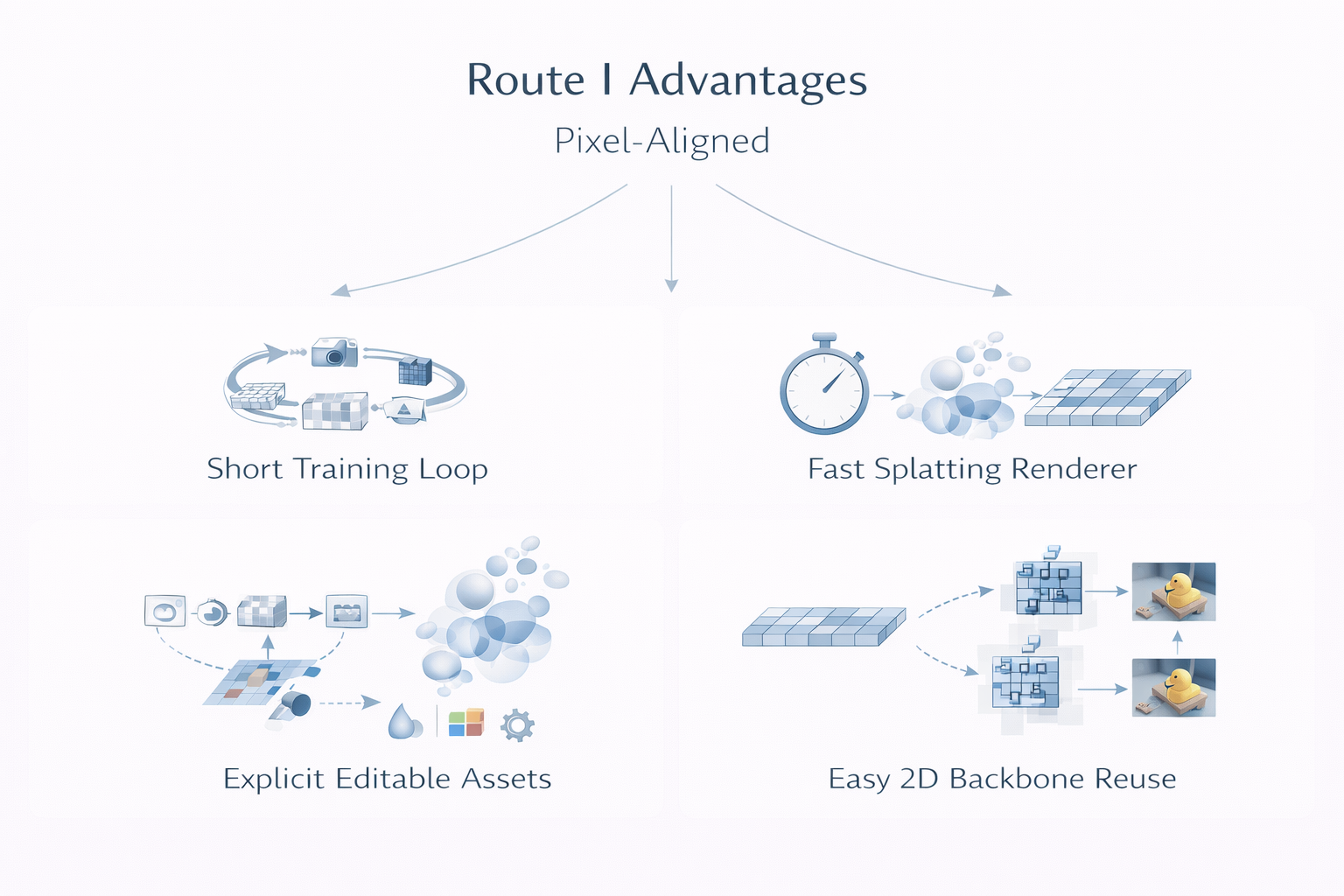
4.6 本章结论:路线一的"简单",是一种高度成功的最小系统设计
pixel-aligned 方案之所以天然简单,不是因为问题本身简单,而是因为它在系统层面做了极其成功的最小化设计:
它复用了 2D backbone,复用了相机射线几何,复用了显式 Gaussian representation,复用了 3DGS 的高速 renderer,于是把 feed-forward 3D reconstruction 压缩成一条极短、极清晰、极可操作的工程闭环。Splatter Image 与 pixelSplat 分别从单视图对象与双视图 generalizable reconstruction 两端证明了这种闭环可以成立;这也是路线一成为"起步范式"而不是普通分支的根本原因。
但也必须同时指出:这套最小系统设计的前提,是让 2D 局部对齐特征承担 3D primitive placement 的主要责任。工程上这非常划算,几何上却埋下了结构性瓶颈。也正因为如此,路线一在证明"前馈式 3DGS 可以成立"之后,几乎立刻把研究问题推向了下一个层面:
- 既然高斯已经能前馈预测,那么高斯到底该怎样在 3D 中被更合理地组织?
5. 为什么开始走向 latent Gaussian
5.1 latentSplat 不是重复 pixelSplat,而是在路线一内部把"显式回归"推向"潜变量表示"
如果说 pixelSplat 解决的是"前馈式高斯能否被直接预测"这一成立性问题,那么 latentSplat 的推进点在于:它开始明确承认,给定少量输入视图,场景重建并不是单一确定解,而更接近一个带条件先验的分布族。
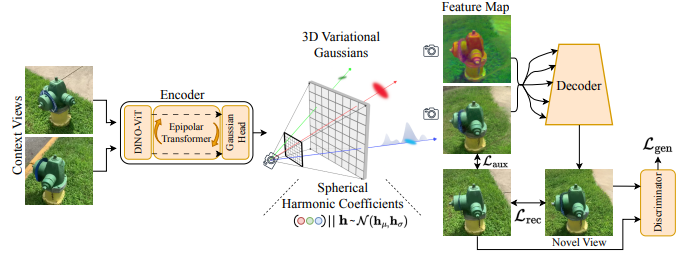
因此,latentSplat 没有停留在"把每个高斯显式回归成 RGB / SH 系数"的框架里,而是把高斯推进到一个 3D latent space 中,用一组 variational feature Gaussians 表示条件分布,再通过轻量 generative 2D decoder 把 splatted latent features 解码为图像。
论文摘要与方法部分都明确写到:latentSplat 预测的是 semantic Gaussians in a 3D latent space,其核心表示是 variational 3D Gaussians,最终通过 Gaussian splatting 与一个 light-weight generative 2D architecture 完成新视角合成。
形式上,latentSplat 把路线一的输出从"显式属性高斯"改写为"带潜变量分布的高斯集合":
h i = h μ , i + ϵ i ⊙ h σ , i , ϵ i ∼ N ( 0 , I ) . (39) \mathbf{h}i= \mathbf{h}{\mu,i} + \epsilon_i \odot \mathbf{h}_{\sigma,i}, \qquad \epsilon_i \sim \mathcal{N}(\mathbf{0},\mathbf{I}). \tag{39} hi=hμ,i+ϵi⊙hσ,i,ϵi∼N(0,I).(39)
其中 x i \mathbf{x}_i xi 是 3D 位置, S i , R ∗ i \mathbf{S}_i,\mathbf{R}*i Si,R∗i 描述 Gaussian 的尺度与朝向, o i o_i oi 是 opacity, c ∗ i \mathbf{c}*i c∗i 是显式 RGB 相关系数,而 h ∗ μ , i , h ∗ σ , i \mathbf{h}*{\mu,i},\mathbf{h}*{\sigma,i} h∗μ,i,h∗σ,i 则参数化该 Gaussian 在 feature / spherical-harmonic coefficient 空间中的正态分布。latentSplat 论文在其表示定义中就是这样组织 scene representation 的,并明确强调这些 variational parameters 用于刻画不同位置的不确定性。
这意味着,latentSplat 并不是简单地"把颜色换成特征"。更准确地说,它把路线一内部的 high-level assumption 从
one input → one deterministic Gaussian set \text{one input} \rightarrow \text{one deterministic Gaussian set} one input→one deterministic Gaussian set
改成了
one input → a conditional distribution over Gaussian scenes . (37) \text{one input} \rightarrow \text{a conditional distribution over Gaussian scenes}. \tag{37} one input→a conditional distribution over Gaussian scenes.(37)
一旦承认 reconstruction 是 underconstrained 的,网络就不该只学习一个均值解;它还需要学习"合理解族"在表示空间中的分布。latentSplat 在引言中明确批评纯回归方法通常只学习 all possible solutions 的 mean,而 generative approaches 更擅长建模多解分布;它的方法目标正是结合 regression-based 与 generative approaches 的优点。
5.2 latent Gaussian 与显式 RGB Gaussian 的根本差异,不在"存什么",而在"把不确定性放在哪里"
路线一早期的显式 Gaussian,可以抽象写成
G i explicit = ( μ i , Σ i , α i , ϕ i ) , (38) G_i^{\text{explicit}}= (\mu_i,\Sigma_i,\alpha_i,\phi_i), \tag{38} Giexplicit=(μi,Σi,αi,ϕi),(38)
其中 ϕ i \phi_i ϕi 常被理解为 RGB 或 SH 颜色系数。这样的表示当然清晰,也便于直接渲染;但它默认每个 Gaussian 的 appearance 是一个确定值,因而更像一个 point estimate of scene explanation。latentSplat 则把 appearance / semantic content 的一部分提升为随机变量,对每个 Gaussian 单独存储 feature distribution 的均值与方差,再通过重参数化采样得到具体 semantic Gaussian。论文方法部分明确区分了 variational Gaussians 与 semantic Gaussians:前者描述 conditioned on input views 的所有可能 3D reconstructions 的分布,后者则是从该分布采样出的某一个具体实例,用于一致的新视角渲染。
其采样过程可形式化写为
h i = h ∗ μ , i + ϵ i ⊙ h ∗ σ , i , ϵ i ∼ N ( 0 , 1 ) , (39) \mathbf{h}_i= \mathbf{h}*{\mu,i} + \epsilon_i \odot \mathbf{h}*{\sigma,i}, \qquad \epsilon_i \sim \mathcal{N}(0,\mathbf{1}), \tag{39} hi=h∗μ,i+ϵi⊙h∗σ,i,ϵi∼N(0,1),(39)
从而得到一组具体的 semantic Gaussians:
G v a r = { ( x i , S i , R i , o i , c i , h μ , i , h σ , i ) } i = 1 N . (36) \mathcal{G}_{\mathrm{var}}= \left\{ \left( \mathbf{x}_i,\mathbf{S}i,\mathbf{R}i,o_i,\mathbf{c}i, \mathbf{h}{\mu,i},\mathbf{h}{\sigma,i} \right) \right\}{i=1}^{N}. \tag{36} Gvar={(xi,Si,Ri,oi,ci,hμ,i,hσ,i)}i=1N.(36)
这正对应 latentSplat 论文中的 sampling semantic Gaussians 公式与解释:通过 reparameterization trick 对 feature coefficients 采样,使 sampled coefficients 的梯度能够回传到 reference-view encoder。
需要强调的是,这里的"latent"并不只是为了压缩维度。它真正改变的是 不确定性的承载位置。在显式 RGB Gaussian 里,不确定性通常只能通过模糊颜色、平均化外观或不稳定的几何来间接体现;在 latent Gaussian 里,不确定性被显式编码在 feature distribution 中。这意味着模型可以在保持几何与渲染管线高效的同时,把"少视图条件下存在多个合理解释"这一事实放进表示本身,而不是留给后续误差去被动承受。
5.3 latentSplat 为什么体现出"回归式 + 生成式"的混合趋势
latentSplat 的关键判断,是纯回归与纯生成各自都不够。论文引言明确指出,regression-based approaches 效率高,但通常只预测所有可能解的均值;generative approaches 虽能建模多样性,却往往牺牲推理效率与高分辨率扩展性。latentSplat 因此选择了一条中间道路:前半段仍保留路线一熟悉的 feed-forward regression pipeline,用编码器直接产生 3D Gaussian representation;后半段则引入 variational latent sampling 与轻量 VAE-GAN decoder,让输出不再局限于单一确定场景解释。
从系统角度看,它的计算图可以写成
I v , Π v ∗ v = 1 2 ; → E ∗ epi ; G ∗ v a r ; → sample ; G ∗ s e m ; → R ∗ g s ; F t ; → D ∗ gen ; I ^ t . (41) {I_v,\Pi_v}*{v=1}^{2} ;\xrightarrow{E*{\text{epi}}}; \mathcal{G}*{var} ;\xrightarrow{\text{sample}}; \mathcal{G}*{sem} ;\xrightarrow{\mathcal{R}*{gs}}; F_t ;\xrightarrow{D*{\text{gen}}}; \hat I_t. \tag{41} Iv,Πv∗v=12;E∗epi ;G∗var;sample ;G∗sem;R∗gs ;Ft;D∗gen ;I^t.(41)
其中 E epi E_{\text{epi}} Eepi 是由双视图输入驱动的编码器,论文明确说明其 encoder 是在 pixelSplat 的 epipolar transformer 基础上适配而来; R ∗ g s \mathcal{R}*{gs} R∗gs 是 Gaussian splatting renderer; D ∗ gen D*{\text{gen}} D∗gen 则是轻量的 VAE-GAN / VAE-style decoder,用于将 rendered feature image 解码为最终 RGB 图像。论文还说明该 decoder 是 purely convolutional,并以 multi-scale features 作为输入。
这也是为什么 latentSplat 在路线一内部显得非常关键。它没有放弃路线一"从图像直接前馈到高斯"的基本接口,却把路线一的表达能力从 deterministic explicit regression 推向了 probabilistic latent representation。换句话说,pixelSplat 主要在问"center 能否被稳定预测",而 latentSplat 已经开始问"预测出来的高斯是否应当生活在一个更有表达力、能承载多解与语义的空间里"。这正是路线一内部第一次明显的升级。
5.4 为什么 latent Gaussian 比显式像素颜色高斯更有潜力
这一点不能只从"指标更好"来理解,而必须从表示论角度理解。
第一,latent Gaussian 允许把高斯的外观表示从 low-level color coefficients 提升到更抽象的 feature domain。论文明确说明 latentSplat 的 scene appearance 是通过 attached view-dependent feature vectors 来描述的,并利用 spherical harmonic coefficient space 建模 feature 分布。这样做的直接好处是:decoder 可以在 2D image space 中使用更强的 learned prior 来补偿仅靠显式 RGB 难以恢复的细节与统计规律。
第二,latent Gaussian 让"一个场景有多种合理解释"可以在表示内部被组织。论文明确写到,variational Gaussians 对应所有可能 3D reconstructions 的分布,而 semantic Gaussians 对应其中一个 sample。这意味着模型不再被迫把多解压成平均值。对于少视图、遮挡或未观测区域,这种能力尤其关键,因为"平均化的显式解"往往在视觉上对应模糊、ghosting 或缺失,而"从条件分布中采样出的某个具体解释"则更容易形成一致的新视角结果。
第三,latent Gaussian 把路线一推进到更强的泛化设定。latentSplat 的摘要与引言都强调,它旨在同时兼顾 fast inference、high resolution scalability 与 extrapolated view generalization,并且只依赖 real video data 训练。这里的关键不只是训练数据来源,而是:一旦表示空间更偏 semantic / latent,模型就更可能把重建从"记住显式颜色模式"提升为"学习条件先验"。
当然,这并不意味着 latent Gaussian 已经解决了路线一的结构瓶颈。它提升的是 表示弹性与不确定性建模能力,不是彻底改写 primitive placement 机制。几何位置、opacity 与 shape 依旧需要在路线一的基本框架内被预测;论文甚至明确提到,它仍保留 explicit RGB coefficients,因为 Gaussian 的 shape parameters 更适合在 RGB signals 上优化。换句话说,latentSplat 代表的是路线一内部的升级,而不是对路线一本体的背离。
5.5 本章结论:latentSplat 标志着路线一从"显式高斯回归"走向"概率化的语义高斯表示"
pixelSplat asks how to place Gaussians; latentSplat starts asking what space Gaussians should live in. (42) \text{pixelSplat asks how to place Gaussians;} \qquad \text{latentSplat starts asking what space Gaussians should live in.} \tag{42} pixelSplat asks how to place Gaussians;latentSplat starts asking what space Gaussians should live in.(42)
这句话的含义是,pixelSplat 把中心定位变成可训练问题,而 latentSplat 则把高斯表示从显式颜色参数推进到了 latent / semantic / variational space。它依旧保留路线一最核心的接口------前馈预测高斯、用 Gaussian splatting 进行高效渲染------但同时开始触碰三个更大的主题:不确定性建模、生成式解码以及更强的数据先验。也正因为此,latentSplat 可以被看作路线一内部的第一次真正升级:不是改变路线的起点范式,而是在这一范式内部显式扩展其表达边界。
6. 这条路线的优势:训练直接、渲染高效、编辑友好
6.1 路线一最宝贵的地方,是它把前馈式 3D Gaussian reconstruction 变成了清晰问题
路线一的重要性,不在于它已经给出了最合理的 3D 结构组织方式,而在于它第一次把 feed-forward 3D Gaussian reconstruction 定义成一个可以清晰比较、清晰实现、清晰迭代的问题。pixelSplat 明确把目标定义为:从图像对前馈预测由 3D Gaussian primitives 参数化的 radiance field;latentSplat 则把这一接口扩展到 variational feature Gaussians,但仍保持"输入少量视图,输出显式 Gaussian scene"的问题定义不变。这个统一接口,使得后续工作不再需要反复证明"是否应该输出高斯",而可以把研究焦点转移到 center localization、view aggregation、structured latent、primitive placement 等更细的问题上。
形式上,路线一把任务固定成
I v , Π v v = 1 M ⟶ G ⟶ I ^ t , (43) {I_v,\Pi_v}_{v=1}^{M} \longrightarrow \mathcal{G} \longrightarrow \hat I_t, \tag{43} Iv,Πvv=1M⟶G⟶I^t,(43)
其中中间变量 G \mathcal{G} G 是显式、可渲染、可检查的 3D Gaussian 表示。这个中间接口本身就是路线一最大的遗产之一。因为一旦中间表示显式化,训练目标、渲染闭环、调试手段与下游资产操作都被统一到了同一个对象上。相比隐式 radiance field 只在 query 时显式化颜色 / 密度,Gaussian scene 是一种"训练中即资产化"的表示。
6.2 架构简洁:2D backbone + Gaussian head + splatting renderer 的短闭环
路线一在工程上最有吸引力的点,是系统闭环极短。Splatter Image 把 2D image 当作 3D Gaussians 的 container,并为每个像素预测一个 Gaussian;pixelSplat 则在双视图场景下引入 epipolar transformer 和 probabilistic Gaussian prediction;latentSplat 继续沿用这一基本骨架,只是在高斯 feature 表示与 decoder 端引入 variational / generative 组件。尽管方法不断演化,但其主干始终没有变:图像编码器、每像素或局部对齐 prediction head、相机几何 lifting、Gaussian renderer。
这条链路可以抽象写为
E θ → H θ → U → R ∗ g s , (44) E_{\theta} \rightarrow H_{\theta} \rightarrow \mathcal{U} \rightarrow \mathcal{R}*{gs}, \tag{44} Eθ→Hθ→U→R∗gs,(44)
其中 E ∗ θ E*{\theta} E∗θ 负责提取图像特征, H θ H_{\theta} Hθ 负责预测 Gaussian-related parameters, U \mathcal{U} U 负责完成 ray-conditioned unprojection / placement, R g s \mathcal{R}_{gs} Rgs 则完成 fast differentiable splatting。因为原始 3DGS 已经提供了高效的 visibility-aware renderer,路线一不需要重新发明训练后端,而只需把"怎么产出 Gaussian"做好即可。
工程上这意味着三件事:训练代码路径更短、模块更容易替换、错误更容易定位。对研究原型和企业研发都一样重要。因为一个可扩展方向往往先需要"最小闭环成立",再谈结构优化。路线一恰恰完成了这一步。
6.3 训练效率与推理速度:高效 renderer 让显式高斯前馈化真正可行
原始 3DGS 的重要基础作用在于:它通过 3D Gaussians、anisotropic covariance 与 fast visibility-aware splatting,避免了 volumetric methods 在空空间中的大量无效计算,并实现了高质量实时渲染。路线一得以快速成立,正是因为它站在这个渲染底座之上。pixelSplat 的摘要明确把 real-time and memory-efficient rendering 作为其可扩展 generalizable reconstruction 的关键组成部分;latentSplat 同样强调 efficient Gaussian splatting 与 fast decoder 的组合,使高分辨率 generalizable reconstruction 成为可能。
这使路线一在训练和推理上都具备明显优势。训练时,loss 可以直接定义在完整渲染图像上,而不必忍受高代价 volume rendering;推理时,输出本身就是 Gaussian scene,而不是还需要 per-scene optimization 或额外显式化的隐式场。也正因为这一点,路线一的方法更容易具备"立即可用"的系统气质:输入视图之后,不是得到一个慢速待优化的模型,而是得到一个可以立刻被渲染、检查甚至操作的场景表示。
6.4 表示可解释、可编辑、具有资产感
pixelSplat 在其 Open Access 页面和摘要中直接把输出描述为 interpretable and editable 3D radiance field;这不是修饰语,而是路线一的结构性优势。因为 Gaussian 是显式 primitive,每个元素都有位置、尺度、朝向、opacity 和 appearance / latent feature。相比隐式 representation,这类输出天然适合做可视化分析、局部裁剪、属性修改以及后续资产化处理。Splatter Image 同样强调其显式 Gaussian set 的渲染速度和空间效率,这本质上都在指向一种"可以被系统工程接住"的表示。
从企业研发视角看,这一点尤其重要。因为真正能接入产品和工作流的表示,往往不只是"能渲染",还必须"能定位、能检查、能调试、能下游利用"。路线一恰好满足这个条件。你可以把它看成一种介于传统点云 / mesh 与纯隐式场之间的中间资产:它比隐式场更可操作,又比传统几何更贴近 differentiable rendering 与学习范式。
6.5 路线一的优势总结:它让前馈式 3DGS 成为可复现、可比较、可工程化的话题
因此,第 6 章的判断可以压缩为:
Route-1 matters because it turns feed-forward 3DGS \text{Route-1 matters because it turns feed-forward 3DGS} Route-1 matters because it turns feed-forward 3DGS
from a possibility into a reproducible research program. (45) \text{from a possibility into a reproducible research program.} \tag{45} from a possibility into a reproducible research program.(45)
它的架构足够简洁,训练链路足够直接,渲染底座足够高效,表示形式足够显式,结果资产感足够强。真正宝贵的不是某个 benchmark 数字,而是它把"前馈式 3D Gaussian reconstruction"稳定地定义为一个清晰、可复现、可比较、可工程化的研究问题。后续路线之所以能快速分化,恰恰因为这个起点已经被路线一建立起来了。
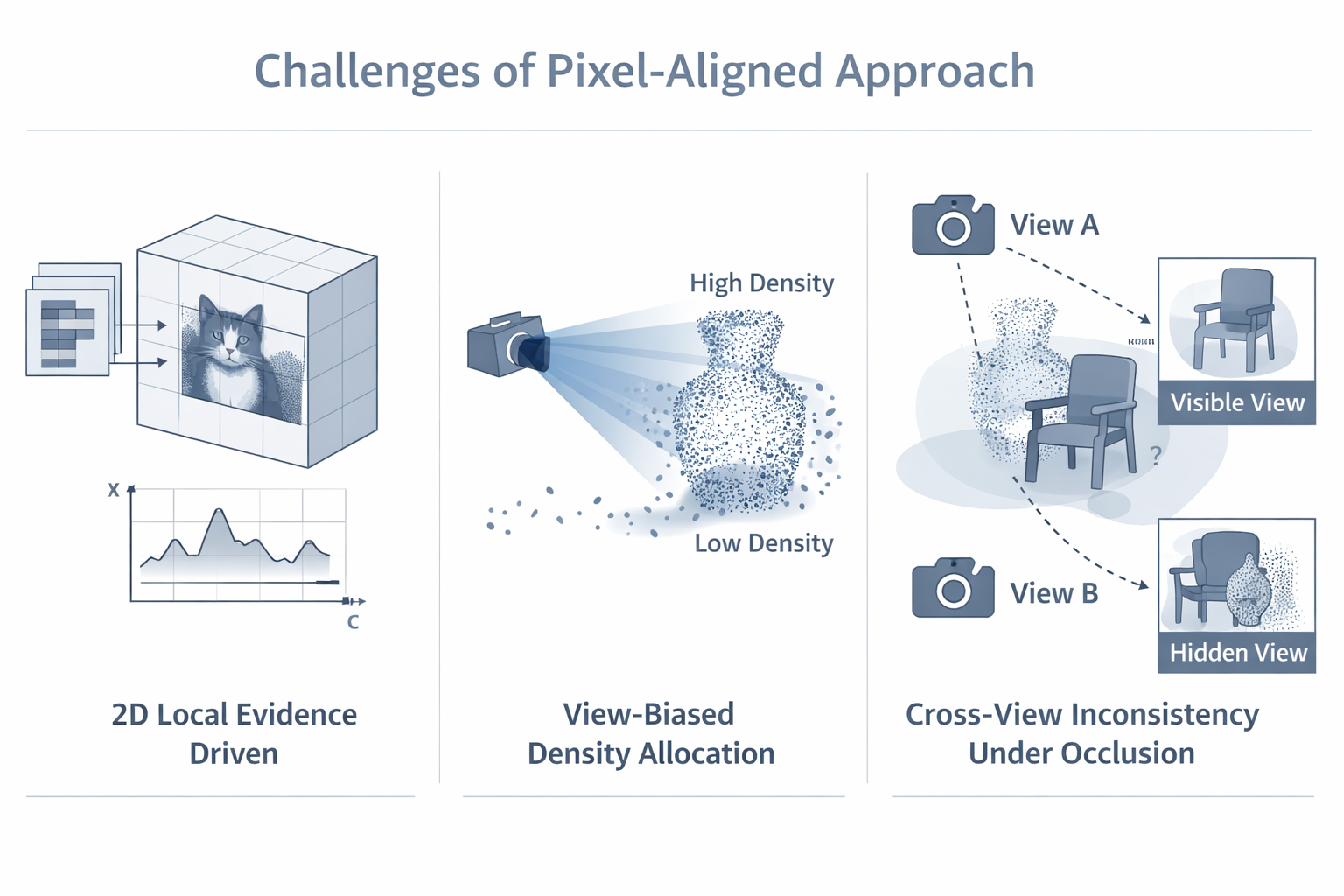
7. 这条路线的硬伤:3D 交互弱、密度分配偏置、遮挡不稳
7.1 3D 交互能力弱:它仍然主要是 2D 局部特征驱动
路线一最大的结构性局限,不是某个具体模块不够强,而是它的推理主轴仍是 2D-driven 3D lifting。无论是 Splatter Image 的"每像素一个 Gaussian",还是 pixelSplat 的"pixel-aligned features + ray-wise probability distribution",抑或 latentSplat 在 pixelSplat epipolar encoder 基础上的扩展,它们的共同点都是:3D Gaussian 的产生首先绑定于图像平面的局部特征槽位,而不是先在显式 3D 结构坐标中建立全局推理,再决定 primitive placement。Splatter Image 明确把 2D image 当作 3D Gaussians 的 container;latentSplat 则明确说明其 encoder 适配自 pixelSplat 的 epipolar transformer。
这意味着,路线一的"3D reasoning"更准确地说是 ray-conditioned local lifting ,而不是真正的 structure-aware global 3D reasoning。它当然可以利用多视图输入和 epipolar context,但其高斯组织原则仍主要由 2D feature grid 驱动。
换句话说,网络更像是在回答"这条 ray 上哪里可能有一个合适的 Gaussian",而不是"整个 3D 场景应如何被结构化地分解和占用"。这就是为什么后续一旦需要更强几何一致性或更稳定中心定位,研究路线很自然会转向 cost volume、voxel / triplane latent 或更全局的 token aggregation。
7.2 Gaussian density 分配容易受视图偏置影响
路线一的第二个核心问题,是高斯密度分配与输入视图采样方式深度绑定。Splatter Image 直接采用"每像素一个 Gaussian"的设计,甚至明确写到每个像素存一个 Gaussian 参数,且这些 Gaussians 主要位于 camera rays 上;pixelSplat 虽然在 mean prediction 上更灵活,但其高斯仍然由 pixel-aligned feature slots 触发。于是,高斯数量和初始候选分布,本质上是由"图像里有多少像素、哪些区域被看见、从什么视角被看见"决定的,而不是由"场景在 3D 中哪里更复杂、哪里需要更高密度 primitive"直接决定的。
这会带来一个非常本质的偏置。设输入视图集合为 V \mathcal{V} V,则路线一中的高斯数量分布更接近
ρ G ( x ) ≈ f ! ( ∑ v ∈ V 1 x is visible in v , image feature saliency ) , (46) \rho_{\mathcal{G}}(\mathbf{x}) \approx f!\Big( \sum_{v\in\mathcal{V}} \mathbf{1}{\mathbf{x}\ \text{is visible in } v}, \ \text{image feature saliency} \Big), \tag{46} ρG(x)≈f!(v∈V∑1x is visible in v, image feature saliency),(46)
而不是
ρ G ( x ) ≈ g ! ( true 3D scene complexity at x ) . (47) \rho_{\mathcal{G}}(\mathbf{x}) \approx g!\big( \text{true 3D scene complexity at }\mathbf{x} \big). \tag{47} ρG(x)≈g!(true 3D scene complexity at x).(47)
换句话说,高斯密度更容易被 observation pattern 驱动,而不是被 intrinsic scene structure 驱动。对前表面、强纹理区域、主视角覆盖区域,pixel-aligned 方法通常更容易生成足够多的高斯;对背面、遮挡区、低纹理区或需要跨视角整合才能明确的区域,则更容易密度不足或分配失衡。这个问题在路线一起步阶段可以被容忍,因为它优先解决的是成立性;但一旦追求结构稳定性,它就会成为核心瓶颈。
7.3 多视图一致性瓶颈:局部 pixel-aligned 特征天然难以保证全局几何一致
这是本文必须明确回答的第二个学术问题。
多视图一致性要求的是:来自不同输入视图的局部证据,最终应在同一 3D 结构上达成一致解释。然而在路线一中,不同视图的证据最初是以各自图像平面上的局部特征存在的。即便采用 epipolar transformer 或 cross-view aggregation,这些证据的原始承载体仍是 2D-aligned slots,而不是一个共享的显式 3D occupancy / surface / cost structure。于是,多视图一致性更多是通过"网络学会在局部特征层面对齐"和"renderer 用输出图像误差间接惩罚不一致"来获得,而不是通过先验上严格的 3D matching structure 来强制建立。
从几何上看,问题可以写成:对两个视图中的匹配像素 p 1 , p 2 p_1,p_2 p1,p2,理想情况应有
μ ( p 1 ) ≈ μ ( p 2 ) ≈ X ⋆ , (48) \mu(p_1) \approx \mu(p_2) \approx X^\star, \tag{48} μ(p1)≈μ(p2)≈X⋆,(48)
其中 X ⋆ X^\star X⋆ 是同一真实表面点。但在 pixel-aligned 框架里, μ ( p 1 ) \mu(p_1) μ(p1) 与 μ ( p 2 ) \mu(p_2) μ(p2) 往往先由各自局部特征产生候选,再通过网络参数共享与渲染损失间接趋同。若局部纹理重复、遮挡严重或基线过大,则两者容易落入不同的局部极值,从而在 3D 中形成 duplicated or inconsistent Gaussians。pixelSplat 已经把 sparse and locally supported representation 的 local minima 视为核心问题;MVSplat 则更进一步,把"accurately localize the Gaussian centers"直接转写为 cost volume / plane sweeping 所支持的 depth estimation 问题,这恰恰说明局部 pixel-aligned 证据不足以稳定实现跨视图几何一致。
低纹理、重复纹理与遮挡区尤其容易暴露这一瓶颈。因为在这些区域,2D 局部外观本身就不足以唯一标识 3D 对应关系;若没有更强的 3D structure-aware aggregation,pixel-aligned features 往往会把不确定性转化为多峰深度猜测、错误中心定位或不稳定 opacity 分配。latentSplat 的 variational 表示在一定程度上能够更好地承载这种不确定性,但它并没有从根本上改变"证据首先活在 2D local grid 上"的事实,因此多视图一致性的结构性瓶颈仍然存在。
7.4 Gaussian mean localization 仍然是主瓶颈
即使 pixelSplat 已经把中心定位改写为"概率分布 + 可微采样",这一问题也并没有被彻底解决。相反,它被更清楚地暴露出来了:路线一中最难的不是渲染器,不是颜色预测,甚至不主要是尺度与 opacity,而是 Gaussian center 到底应放在哪里。pixelSplat 的摘要直接把其方法动机写成"to overcome local minima inherent to sparse and locally supported representations, we predict a dense probability distribution over 3D and sample Gaussian means";MVSplat 的摘要则更进一步明确写出:"To accurately localize the Gaussian centers, we build a cost volume representation via plane sweeping." 两篇工作在不同方向上实际上都承认了同一件事:center localization 是主矛盾。
这也解释了为什么后续路线会迅速分化。只要你承认 mean localization 是瓶颈,就会出现至少三种自然反应:
- 把它进一步转化为显式几何 / 深度问题,于是出现路线二的 cost volume / depth-first;
- 把它放进更结构化的 3D latent 或中间表示里,于是出现 TGS 这类 hybrid representation 与更广义的 structured latent 路线;TGS 在方法与限制部分都明确指出,directly regressing 3D Gaussians from images remains challenging,并因此采用了 hybrid Triplane-Gaussian intermediate representation。
- 重新思考 primitive placement 本身,不再接受"由 pixel slots 触发高斯"的默认分配规则,而去寻找更自适应的 placement 机制。这个方向在路线一内部尚未真正完成,但其问题意识已经被路线一清楚地暴露出来。
7.5 它更像"2D 驱动的 3D lifting",而不是"真正从 3D 出发的结构化推理"
这是本文必须明确回答的第三个学术问题,而它其实是前述所有局限的总根源。
路线一并不是没有 3D 几何,而是其 3D 几何主要以 相机射线约束 + renderer feedback 的形式存在,而不是以一个统一的 3D structure-aware intermediate representation 存在。Splatter Image 的 image-as-container 设计、pixelSplat 的 ray-wise probability distribution、latentSplat 对 pixelSplat epipolar encoder 的延续,都在说明:路线一的默认出发点始终是"从 2D 局部槽位出发,向 3D 提升"。
真正的分歧不在于最终都输出 Gaussians,而在于 Gaussians 是被 3D structure 组织,还是被 2D evidence 驱动。若是前者,表示会更自然地支持全局几何一致性、自适应密度分配和复杂遮挡推理;若是后者,系统则更轻、更快、更容易实现,但必须承受 observation bias、弱 3D interaction 和 center localization 的长期压力。TGS 选择 hybrid Triplane-Gaussian representation,正是因为 authors 认为 directly regressing 3D Gaussians is challenging;MVSplat 选择 cost volume,则是因为 authors 认为 center localization should be geometry-guided。它们都在用不同方式回答路线一留下的同一个问题。
因此:
Route-1 is successful as a 2D-driven lifting paradigm, \text{Route-1 is successful as a 2D-driven lifting paradigm,} Route-1 is successful as a 2D-driven lifting paradigm,
but weak as a fully 3D-structured reasoning paradigm. (49) \text{but weak as a fully 3D-structured reasoning paradigm.} \tag{49} but weak as a fully 3D-structured reasoning paradigm.(49)
这句话既解释了它为何成功,也解释了它为何很快暴露出硬伤。
8. 这条路线对后续所有方法留下了什么遗产
8.1 它留下了前馈式 3DGS 的问题定义
路线一留下的第一项核心遗产,是问题定义本身。pixelSplat 已经把"从少量输入图像,前馈预测显式 3D Gaussian radiance field"建立成可操作任务;latentSplat 则在保持这一任务边界的同时,把表示推进到 variational latent Gaussian。自此之后,后续方法不再需要重新定义 feed-forward 3D reconstruction 应该输出什么表示,而是默认接受"显式 Gaussian scene"作为一个强有力的候选接口。
这一定义的价值在于,它统一了训练、推理与交付:训练时直接通过 renderer 监督;推理时直接得到场景资产;比较时可以在统一渲染与表示基础上讨论方法差异。换句话说,路线一把一个原本分散的研究议题,组织成了一个有共同输入、共同中间表示和共同输出语义的研究程序。
8.2 它留下了 per-pixel Gaussian prediction 这一最小可行接口
第二项遗产,是 per-pixel / pixel-aligned Gaussian prediction 作为最小可行接口。即便后续方法未必继续坚持这一形式,它们也几乎都必须先回应它:是沿用、修补,还是替换。Splatter Image 把 image 作为 3D Gaussian container;pixelSplat 把 per-pixel prediction 推向 probabilistic center localization;latentSplat 则在此基础上引入 variational latent feature Gaussians。它们共同证明:前馈式 3DGS 至少有一条很短的、可运行的接口可以站住脚。
这条接口之所以重要,不是因为它最终必胜,而是因为它给后来者提供了一个非常明确的 baseline form:
如果你想做得更好,你必须说明自己相对于 pixel-aligned interface 修复了什么。是 center localization?是 multi-view consistency?是 density allocation?还是 global 3D reasoning?这使得整个领域的改进方向变得可诊断、可分解。
8.3 它留下了一个最关键的认识:Gaussian mean localization 是主矛盾
第三项遗产,是路线一帮整个领域识别出了真正的主矛盾。pixelSplat 明确把 Gaussian mean prediction 从普通回归里剥离出来,并围绕 local minima、dense probability distribution 与 differentiable sampling 展开;MVSplat 则进一步把"accurately localize the Gaussian centers"当作路线二的核心起点。后续方法表面上使用了不同结构,但其共同动机很大程度上都指向同一个事实:高斯怎么放,比高斯长什么样更难。
从研究方法论上说,这一认识极其重要。因为它改变了问题分解方式:
scale、opacity、appearance 不再被看作同等难度的并列属性,而被放在"中心位置基本合理"之后考虑。换句话说,路线一迫使大家承认:feed-forward 3DGS 的瓶颈不是只靠更大 backbone 或更多数据就能自然吞掉的,它涉及 primitive placement 这一更底层的表示问题。
8.4 它确认了 Gaussian renderer 是高效训练与推理的底座
第四项遗产,是对 Gaussian renderer 角色的重新确认。原始 3DGS 已经证明显式高斯与 fast visibility-aware splatting 可以同时支持高质量和实时渲染;路线一则进一步证明,这个 renderer 不只适合 per-scene optimization,同样适合作为 generalizable feed-forward reconstruction 的训练与推理底座。pixelSplat 和 latentSplat 都是沿着这个思路构建的:前者用 renderer 直接监督显式高斯,后者则把 renderer 扩展到 feature splatting,再接轻量 decoder。
这项遗产的意义在于,它让后续方法的创新重心不必再放在"要不要换渲染器"上,而可以更多放在前端表示与推理结构上。也就是说,renderer 变成了相对稳定的底座,而 representation learning 成为真正的竞争焦点。
8.5 它留下了显式资产感与可编辑性这条产品化线索
第五项遗产,是显式 Gaussian scene 的资产感。pixelSplat 直接把输出描述为 editable radiance field;Splatter Image 也强调显式 Gaussian container 的高效与可操作性。这些表述指向的是同一件事:路线一不是只在做 NVS score,它实际上让 feed-forward reconstruction 输出了一种可被系统工程接住的中间资产。
这条线索对后续研究与应用都很关键。因为一旦表示本身具备可编辑性,那么 reconstruction、editing、generation、asset authoring 之间就不再是彼此割裂的任务,而可能共享同一组 primitives。后续很多围绕 controllability、editing 和场景资产化的工作,都可以被看作在继承路线一所证明的这一点。
8.6 它也留下了未解问题,并自然导向后续路线
同样重要的是,路线一不是只留下成功经验,也留下了一组非常清晰的未解问题,而这些问题几乎直接决定了后续路线的分叉方向。
第一,若 Gaussian mean localization 仍不稳,那么很自然会转向 geometry / depth-first,这就是路线二,MVSplat 用 plane-sweeping cost volume 明确走上了这条路。
第二,若局部 pixel-aligned evidence 的 3D 组织能力太弱,那么很自然会引入 global token aggregation 或更强先验模型,这就是更偏大重建模型与 Transformer 聚合的路线三。虽然本文不展开,但其问题动机与路线一的局限高度相关。
第三,若直接回归 3D Gaussians 被证明很难,那么很自然会引入更结构化的 3D latent / hybrid representation,这就是 TGS 等方法所提示的路线五。TGS 明确指出 directly regressing 3D Gaussians from images remains challenging,并以 hybrid Triplane-Gaussian intermediate representation 作为回应。
第四,若每像素固定槽位的高斯分配方式存在 view bias,那么就会进一步催生对 primitive placement 本身的重新思考,这对应更广义的 adaptive placement、structured allocation 或 alternative primitives 路线。路线一没有解决它,但路线一把问题暴露得足够清楚。
因此,路线一最大的历史作用之一,不只是给出了一个可行答案,而是把"真正困难在哪里"公开化了。
9. 结语
路线一解决了"前馈式 3DGS 能不能成立",但没有解决"高斯到底该怎样在 3D 中被更合理地组织"。
这句话之所以重要,是因为它同时给出了路线一的历史定位与理论边界。它的历史定位在于:pixelSplat 与 latentSplat 证明了,少量图像经过前向传播,的确可以直接产出一组显式 3D Gaussian scene,并借助 Gaussian splatting 完成高效的新视角合成;它的理论边界在于:这些高斯的组织原则仍主要来自 pixel-aligned local evidence 的 2D-driven lifting,而不是一个真正强结构、强几何、强全局一致性的 3D 推理过程。
pixelSplat 通过 probabilistic Gaussian prediction 与 differentiable sampling 把 center localization 变成了可训练问题;latentSplat 又把这一范式内部推进到 variational latent Gaussian 与生成式解码。但它们都没有从根本上回答:高斯应当如何依据 3D 结构本身,而不是仅依据图像局部槽位,被分配、组织与约束。
也正因此,路线一不是终点答案,却是整个前馈式 3DGS 研究地图里最值得单独讲的起点范式。它第一次让问题成立,第一次让表示显式,第一次让高效 renderer 与前馈 reconstruction 真正合流,第一次让"Gaussian mean localization 是主矛盾"这件事被整个领域共同看到。后续路线之所以会迅速走向 geometry-first、cost volume、structured latent、global aggregation,恰恰不是因为路线一失败了,而是因为路线一成功地把问题压缩到了一个更本质的层面:既然高斯已经可以被前馈预测,那么下一步的关键,不再是能不能预测,而是能不能更合理地组织。 这也正是下一篇进入"几何优先 / cost volume / depth-first"路线时的真正起点。
参考文献
- Splatter Image: Ultra-Fast Single-View 3D Reconstruction
- pixelSplat: 3D Gaussian Splats from Image Pairs for Scalable Generalizable 3D Reconstruction
- latentSplat: Autoencoding Variational Gaussians for Fast Generalizable 3D Reconstruction
1. Splatter Image
论文原图核心链路是:输入图像 → image-to-image 网络(U-Net)→ 每像素一个 3D Gaussian 参数图(opacity / RGB / Σ / xyz)→ Gaussian Splatting → 360° novel views。作者明确强调这是"one 3D Gaussian per pixel"的 image container 设计。
Input Image
Image-to-Image Network
U-Net
Splatter Image
per-pixel Gaussian parameters
Opacity
RGB
Covariance Σ
Position xyz
Gaussian Splatting Renderer
360° Novel Views
可直接记成一句话:Splatter Image = 用 2D U-Net 直接生成"高斯参数图",再用 Gaussian Splatting 渲染。
2. pixelSplat
pixelSplat 的完整架构图在补充材料 Fig.8。主链路是:双输入图像 → per-image encoder → epipolar sampling → epipolar attention(重复 2 次)→ Gaussian prediction 。其 per-image encoder 由 ResNet-50(DINO-pretrained)+ DINO ViT-B/8 组成,epipolar 模块负责从对视图中沿极线采样,再做 cross-view attention。
Encoder
Image 1
Per-image Encoder
Image 2
ResNet-50
DINO-pretrained
DINO ViT-B/8
Project / Upsample
Image Features
Epipolar Sampling
Ray Features + Epipolar Samples + Depths
Epipolar Attention x2
Gaussian Prediction
3D Gaussians
Gaussian Splatting Renderer
Novel Views
更本质一点看,pixelSplat 的架构不是"直接回归高斯",而是先用 epipolar 机制构造更稳定的 ray-conditioned 特征,再做 Gaussian prediction;这也是它区别于纯 image-to-image 方案的关键。
3. latentSplat
latentSplat 的官方总览是一个autoencoder 结构 :左侧用两张 context views 经过 DINO-ViT encoder + epipolar transformer + Gaussian head 得到 3D variational Gaussians ;中间从 variational Gaussians 采样 spherical harmonic feature coefficients,形成某个具体的 semantic Gaussian 实例;右侧再经 Gaussian splatting + 轻量 VAE-GAN decoder 解码为 novel view。
Context View 1
DINO-ViT Encoder
Context View 2
Epipolar Transformer
Gaussian Head
3D Variational Gaussians
Sample SH Feature Coefficients
via reparameterization
Semantic / Feature Gaussians
Gaussian Splatting
Feature Map
Light-weight VAE-GAN Decoder
Novel View
Discriminator
training only
一句话概括:latentSplat = pixelSplat 风格的两视图编码器 + variational feature Gaussians + 2D generative decoder。 它把显式 RGB Gaussian 推进成了可采样的 latent Gaussian。
4. MVSplat
MVSplat 的原图核心非常清晰:多视图输入 → multi-view transformer 特征提取 → plane sweeping cost volume → 与 transformer features 拼接后送入 2D U-Net(含 cross-view attention)→ 预测 per-view depth maps 与 Gaussian 参数 → 深度反投影并做 union,得到 3D Gaussians → render novel view。作者明确把 cost volume 作为 center localization 的关键几何模块。
Input View i
Multi-view Transformer
Input View j
Per-view Features
Plane Sweeping
Per-view Cost Volumes
Concat Features + Cost Volumes
2D U-Net
with cross-view attention
Per-view Depth Maps
Opacity / Covariance / Color
Unproject to 3D
Union of Per-view Centers
3D Gaussians
Renderer
Novel View
和 pixelSplat 的最大差异可以压成一句:pixelSplat 主要靠 probability density depth;MVSplat 主要靠 feature matching cost volume。
5. TGS(Triplane Meets Gaussian Splatting)
TGS 的官方总览是典型的双分支混合表示架构 :单视图输入 + camera embedding → image encoder ,然后分两路进入 point cloud decoder 和 triplane decoder ;二者通过 projection-aware condition 与 geometry-aware encoding 融合,形成 hybrid triplane-Gaussian representation ,再经 Gaussian decoder 输出 3D Gaussians,最后 splatting 渲染 novel views。
Single-view Input
Image Encoder
Camera Embedding
Point Cloud Decoder
Triplane Decoder
Point Clouds
Triplane Features
Projection-aware Condition
Hybrid Triplane-Gaussian Representation
Gaussian Decoder
3D Gaussians
Splatting Renderer
Novel Views
TGS 的关键不是"直接从图像回归全部 Gaussian 属性",而是先用 point cloud 提供显式几何骨架,再用 triplane 提供隐式属性场,最后再解码成高斯。这正是它引入 hybrid representation 的原因。